
问题:SyntaxError: Non-ASCII character
往往是编译环境是py2.7,而代码本身是在py3里写的
Python3 对 Unicode 字符的原生支持,Python2 中使用 ASCII 码作为默认编码方式
解决方式:加一下代码
# -*-coding:utf-8-*
如图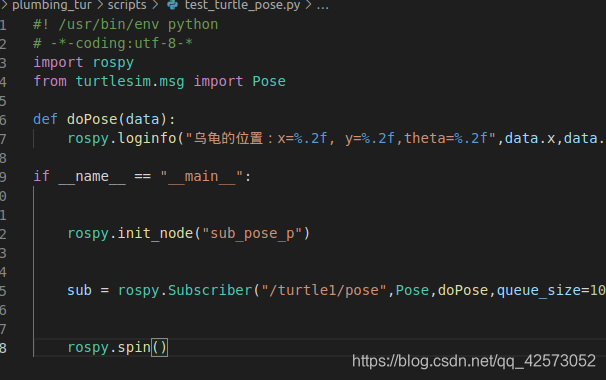
官方解释是编写代码时要有正确的规范,在前面就应该声明编码类型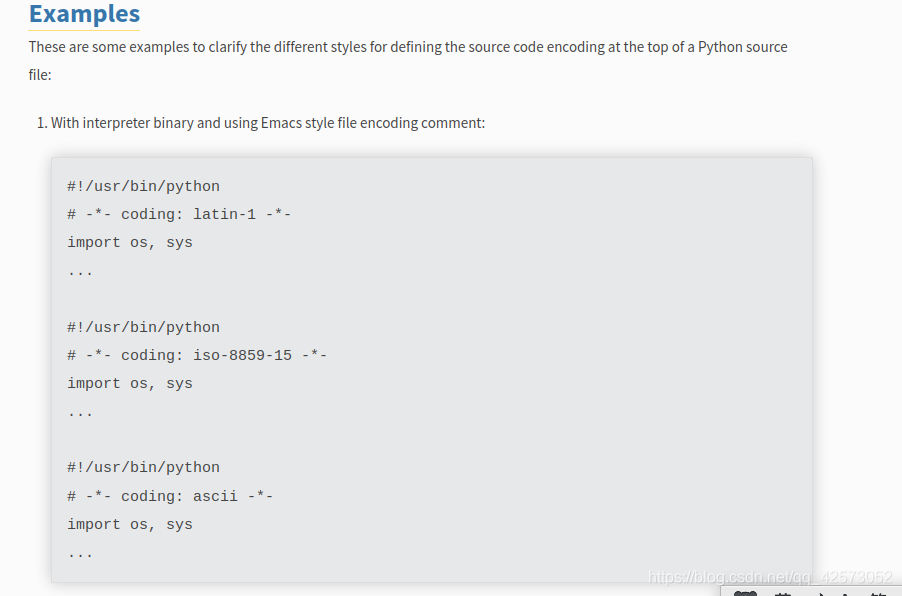
Abstract
This PEP proposes to introduce a syntax to declare the encoding of a Python source file. The encoding information is then used by the Python parser to interpret the file using the given encoding. Most notably this enhances the interpretation of Unicode literals in the source code and makes it possible to write Unicode literals using e.g. UTF-8 directly in an Unicode aware editor.
Problem
In Python 2.1, Unicode literals can only be written using the Latin-1 based encoding “unicode-escape”. This makes the programming environment rather unfriendly to Python users who live and work in non-Latin-1 locales such as many of the Asian countries. Programmers can write their 8-bit strings using the favorite encoding, but are bound to the “unicode-escape” encoding for Unicode literals.
Proposed Solution
I propose to make the Python source code encoding both visible and changeable on a per-source file basis by using a special comment at the top of the file to declare the encoding.
To make Python aware of this encoding declaration a number of concept changes are necessary with respect to the handling of Python source code data.
Defining the Encoding
Python will default to ASCII as standard encoding if no other encoding hints are given.
To define a source code encoding, a magic comment must be placed into the source files either as first or second line in the file, such as:
# coding=<encoding name>
or
#!/usr/bin/python# -*- coding: <encoding name> -*-
版权归原作者 霍迪迪 所有, 如有侵权,请联系我们删除。