
前言
千万、亿级别数据批量写入ES的调优和原理解析
Elasticsearch version (bin/elasticsearch --version):
7.8Plugins installed:
kibanaJVM version (java -version):
java version "1.8.0_102"OS version (uname -a if on a Unix-like system):
Linux 4.9.0-4-amd64 #1 SMP Debian 4.9.65-3 (2017-12-03) x86_64 GNU/LinuxES节点:3台,4C16G,JVM8G
概念篇
一、Elasticsearch为什么吃内存
ES 是 JAVA 应用——底层存储引擎是基于 Lucene 的
1.1、是JAVA应用,就离不开JVM和GC
内存从大的方面分为堆内内存和堆外内存
1.2、堆外内存概念
堆外一般指堆外内存,英文全称:off-heap memory
堆外内存=物理机内存
堆外内存指的是java虚拟机堆以外的内存,这个区域是受操作系统管理,而不是jvm。
1.3、堆内内存概念
堆内一般指堆内内存,英文全称:on-heap memory (heap:堆,java的内存区)
堆内内存 = 新生代+老年代+持久代
对于JVM,在jvm参数中可使用-Xms,-Xmx等参数就可以设置堆的大小和最大值
1.4、Elasticsearch内部是如何使用这些内存的呢?下面这张图说明了Elasticsearch和Lucene对内存的使用情况。

上图解析:Elasticsearch 限制的内存大小是 JAVA 堆空间的大小,不包括Lucene 缓存倒排索引数据空间。
- Lucene/Segment Memory:倒排索引 segments 存储在文件中,为提高访问速度,都会把它加载到内存中(这个内存叫做OS cache,也就是堆外内存或者物理内存)从而提高 Lucene 性能。所以建议至少留系统一半内存给Lucene,段的数量越多,消耗的多文件句柄数及CPU 就越多。
- Node Query Cache:负责缓存filter 查询结果,每个节点都有一个,被所有 shards 共享,filter query查询结果要么是 yes 要么是no,不涉及 scores 的计算。data节点必须配置
Node Query Cache的默认大小:indices.queries.cache.size:10% // 也可以设置为绝对值,比如512mbindex.queries.cache.enabled:true - Indexing Buffer:索引缓冲区,用于存储最近被索引的文档,所有shards共享-公用。当该buffer满了之后,buffer里面的文档会被写入一个segment。默认这个参数的值是10%,也就是jvm heap的10%,如果我们给jvmheap分配10gb内存,那么这个index buffer就有1gb
Indexing Buffer的默认大小:indices.memory.index_buffer_size:10%indices.memory.min_index_buffer_size:48mbindices.memory.max_index_buffer_size:unbounded``````修改jvm heap大小:vim /opt/elasticsearch/config/jvm.options 设置-Xms10g-Xms10g接着停止es集群(kill -9 pid),再启动 su es ./bin/elasticsearch -d查看是否生效ps -ef | grep elasticsearch - Shard Request Cache:用于缓存请求结果,只有reqeust size是0的才会被cache,比如aggregations、hits.total、counts和suggestions。不建议将它用于更新频繁的index,因为shard被更新时,该缓存会自动失效
Shard Request Cache的默认大小:indices.requests.cache.size:1% - Field Data Cache:在analyzed字符串上对field进行聚合计算时,Elastisearch会加载该field的所有值到内存中,这些值缓存在Field Data Cache里面。所以Fielddata是懒加载,并且是在query过程中生成的。indices.fielddata.cache.size控制了分配给fielddata的heap大小。它的默认值是unbounded,这么设计的原因是fielddata不是临时性的cache,它能够极大地提升性能,而且构建fielddata又比较耗时的操作,所以需要一直cache。 如果没有足够的内存保存fielddata时,Elastisearch会不断地从磁盘加载数据到内存,并剔除掉旧的内存数据。剔除操作会造成严重的磁盘I/O,并且引发大量的GC,会严重影响Elastisearch的性能。
Field Data Cache的默认大小:indices.fielddata.cache.size:unbounded如果不在analyzed string fields上使用聚合,就不会产生Field Data Cache,也就不会使用大量的内存,所以可以考虑分配较小的heap给Elasticsearch。因为heap越小意味着Elasticsearch的GC会比较快,并且预留给Lucene的内存也会比较大。
1.5、其他影响内存项
- Bulk Queue:每个Elasticsearch节点内部都维护着多个线程池,如index、search、get、bulk等,建议使用固定大小的线程池配置,线程池最大线程数默认配置为CPU核心数+1;Bulk queue不会消耗很多的 heap,如果一个 bulk 的数据量大小*queue 的大小,超出heap内存阈值,就会OOM。一般采用官方默认的 thread pool 设置即可。 eg:thread_pool.bulk.queue_size: 1024(bulk队列线程数);thread_pool配置参考官网:
https://www.elastic.co/guide/en/elasticsearch/reference/6.7/modules-threadpool.html - Cluster State Buffer:ES 每个node 都可以响应用户的 api 请求,每个 node的内存里都包含有一份集群状态的拷贝。这个 cluster state 包含诸如集群有多少个 node,多少个 index,每个 index 的 mapping 是什么?有少 shard,每个 shard 的分配情况等等 (ES 有各类 stats api 获取这类数据)。在一个规模很大的集群,这个状态信息可能会非常大的,耗用的内存空间就不可忽视。并且在 ES2.0 之前的版本,state的更新是由 master node 做完以后全量散播到其他结点的。频繁的状态更新就可以给 heap 带来很大的压力。在超大规模集群的情况下,可以考虑分集群并通过 tribe node 连接做到对用户 api 的透明,这样可以保证每个集群里的 state 信息不会膨胀得过大。
二、ES内存查看方式
- 查看segments使用的内存;通过查看cat segments查看index的segments使用内存的情况
GET /_cat/segments?v
- 查看Node Query Cache、Indexing Buffer和Field Data Cache使用的内存;通过cat nodes可以查看他们使用内存的情况
GET /_cat/nodes?v&h=id,ip,port,v,master,name,heap.current,heap.percent,heap.max,
ram.current,ram.percent,ram.max,
fielddata.memory_size,fielddata.evictions,query_cache.memory_size,query_cache.evictions,
request_cache.memory_size,request_cache.evictions,request_cache.hit_count,request_cache.miss_count
- 谨慎对待unbounded的内存:unbounded内存是不可控的,会占用大量的heap(Field Data Cache)或者off heap(segments),从而会导致Elasticsearch OOM;或者因segments占用大量内存导致swap。segments和Field Data Cache都属于这类unbounded。
- segments:segments会长期占用内存,其初衷就是利用OS的cache提升性能。只有在Merge之后,才会释放掉标记为Delete的segments,释放部分内存。
- Field Data Cache:默认情况下Fielddata会不断占用内存,直到它触发了fielddata circuit breaker。 fielddata circuit breaker会根据查询条件评估这次查询会使用多少内存,从而计算加载这部分内存之后,Field Data Cache所占用的内存是否会超过indices.breaker.fielddata.limit。如果超过这个值,就会触发fielddata circuit breaker,abort这次查询并且抛出异常,防止OOM。
indices.breaker.fielddata.limit:60% (默认heap的60%)如果设置了indices.fielddata.cache.size,当达到size时,cache会剔除旧的fielddata。indices.breaker.fielddata.limit 必须大于 indices.fielddata.cache.size,否则只会触发fielddata circuit breaker,而不会剔除旧的fielddata。
三、ES内存分配技巧
1)Elasticsearch默认安装后设置的内存是1GB,这是远远不够用于生产环境的。有两种方式修改Elasticsearch的堆内存:
- 设置环境变量:
export ES_HEAP_SIZE=10g在es启动时会读取该变量; - 启动时作为参数传递给es:
./bin/elasticsearch -Xmx10g -Xms10g
2)分配给 es 的内存最好不要超过 32G
- 这里有另外一个原因不分配大内存给 Elasticsearch,事实上 jvm 在内存小于 32 G 的时候会采用一个内存对象指针压缩技术。
- 在 Java 中,所有的对象都分配在堆上,然后有一个指针引用它。指向这些对象的指针大小通常是 CPU 的字长的大小,不是 32 bit 就是 64 bit,这取决于处理器,指针指向了你的值的精确位置。
- 对于 32 位系统,内存最大可使用 4 G。对于 64 系统可以使用更大的内存。但是 64 位的指针意味着更大的浪费,因为你的指针本身大了。浪费内存不算,更糟糕的是,更大的指针在主内存和缓存器(例如 LLC,L1 等)之间移动数据的时候,会占用更多的带宽。
- Java 使用一个叫内存指针压缩的技术来解决这个问题。它的指针不再表示对象在内存中的精确位置,而是表示偏移量。这意味着 32 位的指针可以引用 40 亿个对象,而不是 40 亿个字节。最终,也就是说堆内存长到 32 G 的物理内存,也可以用 32 bit 的指针表示。
- 一旦你越过那个神奇的 30 - 32 G 的边界,指针就会切回普通对象的指针,每个对象的指针都变长了,就会使用更多的 CPU 内存带宽,也就是说你实际上失去了更多的内存。事实上当内存到达 40 - 50 GB 的时候,有效内存才相当于使用内存对象指针压缩技术时候的 32 G 内存。
- 还有一点就是确保堆内存最小值(Xms)与最大值(Xmx)的大小是相同的,防止程序在运行时改变堆内存大小,这是一个很耗系统资源的过程。
- 综上:即便内存足够,也尽量不要超过 32 G,因为它浪费了内存,降低了 CPU 的性能,还要让 GC 应对大内存
我有一个 1 TB 内存的机器!
这个 32 GB 的分割线是很重要的。那如果你的机器有很大的内存怎么办呢? 一台有着 512–768 GB内存的服务器愈发常见。
首先,我们建议避免使用这样的高配机器(参考 硬件)。
但是如果你已经有了这样的机器,你有三个可选项:
- 你主要做全文检索吗?考虑给 Elasticsearch 4 - 32 GB 的内存, 让 Lucene 通过操作系统文件缓存来利用余下的内存。那些内存都会用来缓存 segments,带来极速的全文检索。
- 你需要更多的排序和聚合?而且大部分的聚合计算是在数字、日期、地理点和
非分词字符串上?你很幸运,你的聚合计算将在内存友好的 doc values 上完成! 给 Elasticsearch 4 到 32 GB 的内存,其余部分为操作系统缓存内存中的 doc values。- 你在对分词字符串做大量的排序和聚合(例如,标签或者 SigTerms,等等)不幸的是,这意味着你需要 fielddata,意味着你需要堆空间。考虑在单个机器上运行两个或多个节点,而不是拥有大量 RAM 的一个节点。仍然要坚持 50% 原则。
假设你有个机器有 128 GB 的内存,你可以创建两个节点,每个节点内存分配不超过 32 GB。 也就是说不超过 64 GB 内存给 ES 的堆内存,剩下的超过 64 GB 的内存给 Lucene。
如果你选择这一种,你需要配置
cluster.routing.allocation.same_shard.host: true。 这会防止同一个分片(shard)的主副本存在同一个物理机上(因为如果存在一个机器上,副本的高可用性就没有了)。
参考2.x官方文档
堆内存:大小和交换 | Elasticsearch: 权威指南 | Elastic
原理篇

ES写入/索引流程分析如上图,简单分析一下索引写入流程
1、client发起write请求
2、数据写到index buffer和translog中
3、经过1s或者达到10%堆内存阈值后将数据从buffer中的数据写入到segment file,refresh到os cache(FileSystem cache)中,打开供搜索,并清空buffer
4、当translog达到flush_threshold_size大小后,触发commit操作
4-1)将此时buffer中的数据写入到新的segment,并写入到os cache,打开被搜索,然后清空buffer
4-2)一个commit point被写入磁盘文件,标记了被写入的所有index segment file
4-3)同时将os cache中的所有segment file都fsync到DISK中,这个过程叫flush
4-4)清空现有translog日志文件,新建一个translog
调优篇
四、Spark写入ES调优
文章参考:
Spark连接ES实现kerberos认证_dkjhl的博客-CSDN博客_spark连接es
配置项参考该类:elasticsearch-hadoop-6.8.21.jar
org.elasticsearch.hadoop.cfg#ConfigurationOptions
主要的配置项如下
1、连接参数配置
"es.http.timeout" -> "5m" ①
"es.http.retries" -> "50" ②
*① ② *这两个参数是控制http接口层面的超时及重试,覆盖读请求和写请求,默认值比较小,默认超时时间为1分钟,重试次数为3,建议调整为超时时间5分钟,重试次数50次。
2、写入批次配置
"es.batch.size.bytes" -> "10mb" *①* "es.batch.size.entries" -> "20000" *②* "es.batch.write.refresh" -> "false" *③* "es.batch.write.retry.count" -> "10" *④* "es.batch.write.retry.wait" -> "60s" *⑤*
① ② 这两个参数控制单次批量写入的数据量大小和条数,数据积累量先达到哪个参数设置,都会触发一次批量写入。增大单次批量写入的数据,可以提高写入ES的整体吞吐。
因为ES的写入一般是顺序写入,在一次批量写入中,很多数据的写入处理逻辑可以合并,大量的IO操作也可以合并。
默认值设置的比较小,可以适当根据集群的规模调大这两个值,建议为20MB和2w条。
③ 是否每次bulk操作后都进行refresh。 每次refresh后,ES会将当前内存中的数据生成一个新的segment。如果refresh速度过快,会产生大量的小segment,大量segment在进行合并时,会消耗磁盘的IO。默认值为开启,如果写时查询要求没那么高,建议设置为false。在索引的settings中通过refresh_interval配置项进行控制,可以根据业务的需求设置为30s或-1,index_buffer默认是堆的10%,满了就会refresh
④ ⑤ 这两个参数会控制单次批量写入请求的重试次数,以及重试间隔。当超过重试次数后,Yarn任务管理会将该任务标记为failed,造成整个写数据任务的失败。默认值为3,为了防止集群偶发的网络抖动或压力过大造成的集群短暂熔断,建议将这个值调大,设置为50。
当每条数据比较均匀的时候,用es.batch.size.entries限制批量写入条数比较合适,但是当每条数据不均匀时,建议用es.batch.size.bytes限制每批次的写入数据量比较合适。当然,bulk size不能无限的增大,会造成写入任务的积压。
实际效果:spark调优过程比较便捷,基于上述配置,可以达到 “单机4C16G——10个线程——20w/s的写入速度”,5KW数据量-45min左右可写入完成
五、Java RestHighLevel 批量写入ES参数调优
ElasticSearch的配置选项分为静态设置和动态设置两种,静态设置必须在结点级别(node-level)设置,或配置在elasticsearch.yml配置文件中,或配置在环境变量中,或配置在命令行中,在结点启动之后,静态设置不能修改;动态索引可以创建时添加或者创建后再添加或者修改
5.1、bulk批量写入
- 如果业务场景支持将一批数据聚合起来,一次性写入Elasticsarch,那么尽量采用bulk的方式,bulk批量写入的速度远高于一条一条写入大量document的速度。
- 并不是bulk size越大越好,而是根据写入数据量具体来定的,因为越大的bulk size会导致内存压力过大,因此最好一个请求不要发送超过10MB的数据量,以5-10MB为最佳值。
- 计算公式为:一次bulk写入的数据量大小=一次bulk批量写入的文档数*每条数据量的大小
5.2、多线程写入
- 单线程发送bulk请求是无法最大化Elasticsearch集群写入的吞吐量的。如果要利用集群的所有资源,就需要使用多线程并发将数据bulk写入集群中。多线程并发写入同时可以减少每次底层磁盘fsync的次数和开销。
- 一旦发现ES返回了TOO_MANY_REQUESTS的错误,JavaClient也就是EsRejectedExecutionException。此时说明Elasticsearch已经达到了一个并发写入的最大瓶颈了。
- 推荐使用CPU核数的2倍线程数,比如机子是4C16G,那么线程是4*2=8。
5.3、修改translog flush 间隔
- 从ES2.x开始,在默认设置下,translog的持久化策略未:每个请求都“flush"。对应配置 index.translog.durability: request
- 这是影响ES写入速度的最大因素,但是只有这样,写操作才有可能是可靠的,如果系统可以接受一定概率的数据丢失,则调整translog持久化策略和flush阈值
index.translog.durability: async // 刷新策略,默认requestindex.translog.sync_interval:120s // 默认5s,translog buffer到文件的刷新时间index.translog.flush_threshold_size:1gb /** flush阈值,默认512MB;超过512M,触发flush操作会将index buffer中的数据,refresh到os cache中产生新的segment file,如果这个值太小,就会频繁发生refresh、merge和flush**/
5.4、修改索引刷新时间及副本数
- 默认“index.refresh_interval”为“1s”,即每秒都会强制生成1个新的segments文件,增大索引刷新时间,可以生成更大的segments文件,减少segment merge的次数,实质有效降低IO并减少segments merge的压力,该配置项可以建索引时指定(或者配置到template里去)。
- 如果只是单纯导入数据,不需要做实时查询,可以把refresh禁用(即设置index.refresh_interval为-1),并设置“index.number_of_replicas”为“0”,当然这样设置会有数据丢失风险。等到数据完成导入后,再把参数设置为合适的值
- 命令为单索引下操作如下所示 >
> curl -XPUT "http://localhost:9200/myindex/_settings" -H 'Content-Type: application/json' -d'> {> "index.number_of_replicas": 0,> "index.refresh_interval": "120s"> }'> - Elasticsearch数据刷新策略RefreshPolicy -
// org.elasticsearch.action.support.WriteRequest.RefreshPolicy#WriteRequestBuilderdefault B setRefreshPolicy(RefreshPolicy refreshPolicy) { request().setRefreshPolicy(refreshPolicy); return (B) this; }枚举org.elasticsearch.action.support.WriteRequest.RefreshPolicy定义了三种策略:NONE,IMMEDIATE,WAIT_UNTIL;可知有以下三种刷新策略:-RefreshPolicy#IMMEDIATE:请求向ElasticSearch提交了数据,立即进行数据刷新,然后再结束请求。 优点:实时性高、操作延时短。 缺点:资源消耗高。-RefreshPolicy#WAIT_UNTIL:请求向ElasticSearch提交了数据,等待数据完成刷新,然后再结束请求。 优点:实时性高、操作延时长。 缺点:资源消耗低。-RefreshPolicy#NONE:默认策略。 请求向ElasticSearch提交了数据,不关系数据是否已经完成刷新,直接结束请求。 优点:操作延时短、资源消耗低。 缺点:实时性低。
5.5、修改merge参数以及线程数
- Elasticsearch写入数据时,refresh刷新后会生成1个新的segment,segments会按照一定的策略进行索引段合并merge。merge的频率对写入和查询的速度都有一定的影响,如果merge频率比较快,会占用较多的IO,影响写入的速度,但同时segment个数也会比较少,可以提高查询速度。所以merge频率的设定需要根据具体业务去权衡,同时保证写入和查询都相对快速。Elasticsearch默认使用TieredMergePolicy,可以通过参数去控制索引段合并merge的频率:
- index.merge.policy.floor_segment ① index.merge.policy.max_merge_at_once ② index.merge.policy.max_merged_segment ③ index.merge.policy.segments_per_tier ④ index.merge.scheduler.max_thread_count ⑤
- ① 小于这个阀值的segment会merge,直到达到这个floor_size,默认2MB ② 索引操作期间,一次最多只merge多少个segments,默认是10 ③ 超过多大size的segment不会再做merge,默认是5g。 ④ 表示每个tier允许的segment个数,默认为10。越小的参数值会导致更少的索引段数量,这也意味着更多的合并操作以及更低的索引性能;tier值建议设置为≥max_merge_at_once值,否则tier值会先于最大可操作数到达,就会立刻做merge,造成频繁merge。 ⑤ 单个shard上可能同时合并的最大线程数。默认会启动 Math.max(1, Math.min(4, Runtime.getRuntime().availableProcessors() / 2)) 个线程进行merge操作。如果是机械硬盘,建议设置为1;固态硬盘视情况而定
cat /sys/block/*/queue/rotational-- 0 SSD // 固态硬盘-- 1 HDD // 机械硬盘 - 一般情况下,通过调节参数下列参数,去控制merge的频率,降低CPU压力。
- 参数修改好处坏处index.merge.policy.max_merge_at_once index.merge.policy.segments_per_tier (eg :50)提升indexing速度减少了segment merge动作的发生,意味着更多的segments,会降低searching速度index.merge.policy.max_merge_at_once index.merge.policy.segments_per_tier (eg :5)Segments更少,即能够提升searching速度更多的segments merge操作,会花费更多系统资源(CPU/IO/RAM),会降低indexing速度
- 整体修改参数命令如下示例:
curl -XPUT "https://localhost:9200/index/_settings?pretty" -H 'Content-Type: application/json' -d' { "index": { "merge": { "scheduler": { "max_thread_count": "1" }, "policy": { "segments_per_tier": "24", "max_merge_at_once": "24", "floor_segment": "2m", "max_merged_segment": "2g" } } } }'
5.6、禁用Doc Values
- 默认情况下,支持doc values 的所有字段都是开启的。因为 Doc Values 默认启用,可以选择对数据集里面的大多数字段进行聚合和排序操作。但是如果确定不需要在字段上进行排序和聚合,或从脚本中访问字段值,则可以禁用 doc values 来节省磁盘空间。
- 要禁用 Doc Values ,在字段的映射(mapping)设置 “doc_values”为“false”即可。例如,这里我们创建了一个新的索引,字段 “session_id” 禁用了 Doc Values:
curl -XPUT "http://localhost:9200/myindex" -H 'Content-Type: application/json' -d'
{
"mappings": {
"my_type": {
"properties": {
"session_id": {
"type": "keyword",
"doc_values": false
}
}
}
}
}'
5.7、禁用_source字段
- “_source”字段包含在索引时传递的原始JSON文档正文。该“_source”字段本身不被索引(因此是不可搜索的),但它被存储,以便在执行撷取请求时可以返回,例如get或search。
- 虽然很方便,但是“_source”字段确实在索引中有不小的存储开销。因此,可以使用如下方式禁用:
curl -XPUT 'https://ip:port/index?pretty' -H 'Content-Type: application/json' -d' { "mappings": { "tweet": { "_source": { "enabled": false } } } }'
说明: 在禁用_source 字段之前请注意:如果_source字段不可用,则不支持以下功能:
- update,update_by_query,reindex APIs.
- 高亮
- 将索引从一个Elasticsearch索引reindex(重索引)到另一个索引的能力,以便更改映射或分析,或将索引升级到新的主要版本。
- 通过查看索引时使用的原始文档来调试查询或聚合的能力。
- 潜在的未来可能会自动修复索引损坏的能力。
5.8、自动生成DOC_ID
- 指定doc_id后,ES会尝试读取原先doc的版本号,判断是否需要更新,这涉及一次读取磁盘的操作
5.9、禁用 _source 和禁用 _all 字段
- _source字段用于存储doc原始数据,对于不需要存储的字段,可以通过includes/excludes过滤,或者禁用_source,一般用于索引和数据分离;实际上禁用_source用处不大
- _all字段从ES6.0开始,默认不启用;禁用_all字段可以明显降低CPU和I/O的压力
5.10、bulk api解决超时问题
BulkRequest request = new BulkRequest();
request.timeout("2m"); // 索引操作超时时间
// option-1
RestClientBuilder builder = RestClient.builder(
new HttpHost("localhost", 9200))
.setRequestConfigCallback(
new RestClientBuilder.RequestConfigCallback() {
@Override
public RequestConfig.Builder customizeRequestConfig(
RequestConfig.Builder requestConfigBuilder) {
return requestConfigBuilder
.setConnectTimeout(5000)
.setSocketTimeout(60000)
.setConnectionRequestTimeout(5000); // 获取连接的超时时间
}
});
// option-2
RequestConfig requestConfig = RequestConfig.custom()
.setConnectTimeout(5000)
.setSocketTimeout(60000)
.setConnectionRequestTimeout(5000)
.build();
RequestOptions options = RequestOptions.DEFAULT.toBuilder()
.setRequestConfig(requestConfig)
.build();
RequestConfig有三个超时如下
- connectTimeout:设置连接超时时间,单位毫秒(默认1s)。指的是连接一个url的连接等待时间
- socketTimeout:请求获取数据的超时时间,单位毫秒(默认30s)。如果访问一个接口,多少时间内无法返回数据,就直接放弃此次调用。指的是连接上一个url,获取response的返回等待时间。
- connectionRequestTimeout:设置从connect Manager获取Connection 超时时间,单位毫秒。这个属性是新加的属性,因为目前版本是可以共享连接池的。
Bulk API | Java REST Client [7.12] | Elastic
Timeouts | Java REST Client [7.12] | Elastic
六、Kibana监控
kibana监控模块通过调用es索引存储的监控数据,制作了许多开箱即用报表供用户使用。主要分为集群层面、节点层面和索引层面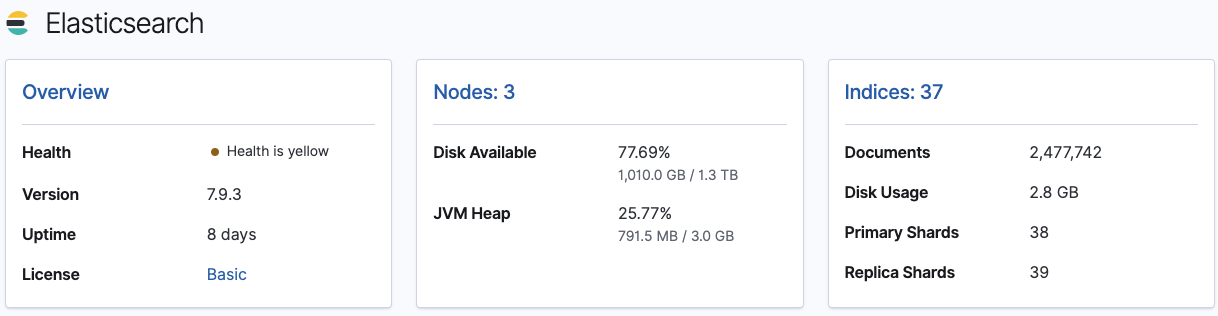
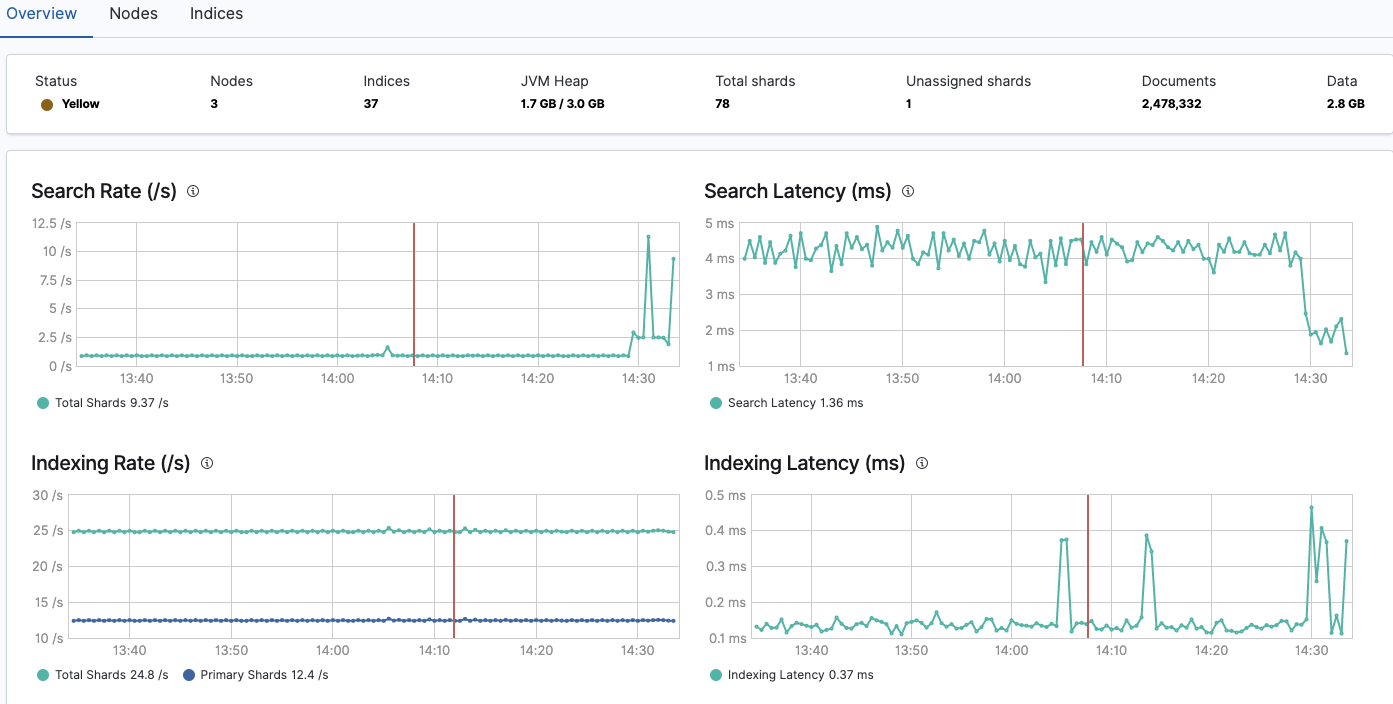 kibana通过es索引中存储的数据计算出了许多指标报表,如上图所示包含了查询(加载)速率和查询(加载)延时,除此之外还有cpu、内存、存储以及负载占用等等许多指标
kibana通过es索引中存储的数据计算出了许多指标报表,如上图所示包含了查询(加载)速率和查询(加载)延时,除此之外还有cpu、内存、存储以及负载占用等等许多指标
参考文章
es实战-Monitoring原理讲解及kibana可视化实战_casterQ的博客-CSDN博客_kibana的monitoring
七、实战记录
1、3台4C16G的ES集群
2、字段数100个,
3、字段长度50字节,
4、一条记录打满5KB,
5、数据量5000w,
6、运行资源标准1C4G(倍数增长),
7、并发度即程序线程数,8、UUID作为DOC_ID
调优过程比较多,截取有针对性提升的时间节点对应的调优项
调优项批次/条运行资源并发度同步效率同步时间jvm heap 1G50002C8G4/211.08minjvm heap 8G30004C16G850w/min159minjvm heap 8G20004C16G850w/min154min+refresh_interval:10s
+max_thread_count:1
+number_replicas:020006C24G1275w/min77min+index_buffer_size:20%50006C24G1276w/min72.73min+refresh_interval:20s
+max_merge_at_once:50
+segment_per_tier:5050006C24G1678w/min70min+number_of_shards:3
+translog.durability:async
+translog.sync_interval:60s
+flush_threshold_size:1g50006C24G1690w/min57.62min继承上述调优项50002C8G460w/min92.77min+refresh_interval:60s50002C8G462w/min86.87min继承上述调优项50004C16G1292w/min59.35min
- 总结:运行过程中监控运行资源发现,6C24G实际上未打满,C峰值是3.5,G峰值是12G,实际配置可以参考4C16G;线程数可以参考12;批次2000-5000均可
- 过程分析:上述调优项没有遵循单一变量原则,原因:从kibana监控界面结合上述文章分析后,得出相应调优项,进行相应的测试;性能测试过程中,瓶颈主要在CPU
- 总的索引修改项配置如下:
{ "settings": { "index": { "refresh_intervals": "60s", "translog": { "flush_threshold_size": "1g", "sync_interval": "60s", "durability": "async" }, "unassigned": { "node_left": { "delayed_timeout": "3h" } }, "number_of_replicas": 0, "merge": { "scheduler": { "max_thread_count": 1 }, "policy": { "segment_per_tier": 50, "max_merge_at_once": 50 } } } }}
八、思考与总结
1)方法比结论重要。一个系统性问题往往是多种因素造成的,在处理集群的写入性能问题上,了解原理后,需要将问题分解,在单台机子上进行压测,观察哪种系统资源达到极限;例如:CPU、磁盘利用率、I/O block、线程切换、堆栈状态;然后分析并调整参数,优化单台能力,先解决局部问题,在此基础上解决整体问题效率更高
2)可以使用更好的CPU,或者SSD,对写入性能提升明显
3)若能达到3w/s的写入性能,优化就差不多了
版权归原作者 dkjhl 所有, 如有侵权,请联系我们删除。