
Hadoop 完全分布式部署
前期准备
分析:
- 准备3台客户机(关闭防火墙、静态IP、主机名称) 【CentOS 7】
- 安装JDK 【jdk1.8】
- 安装Hadoop 【hadoop 3.3.4】
- 配置环境变量
- 配置ssh
- 配置集群
- 单点启动
- 群起并测试集群
Hadoop 集群规划:
node1node2node3IP10.90.100.12110.90.100.12210.90.100.123HDFS
NameNode、
DataNodeDataNodeDataNode、
SecondaryNameNodeYARN
NodeManagerResourcemanager、
NodeManagerNodeManager
一、安装Linux操作系统
这里以CentOS 7为例,最小安装,关闭防火墙、静态IP、主机名称。
具体安装步骤:略
虚拟机准备
1 通网络
能ping通外网,例如:
ping baidu.com
如果ping不通,修改如下文件:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
将ONBOOT=no改为ONBOOT=yes
重启网络或重启机器
重启网络
systemctl restart network
重启机器
reboot
2 修改默认主机名
查询主机名
[root@localhost ~]# hostname
localhost.localdomain
修改主机名,这里以主机名为node1为例
[root@localhost ~]# hostnamectl set-hostname node1[root@localhost ~]# hostname
node1
重启生效
[root@localhost ~]# reboot...
[root@node1 ~]#
3 新建普通用户
因为root用户权限太高,误操作可能会造成不可挽回的损失,所以我们需要新建一个普通用户来安装操作
添加一个普通用户,用户名例如:hadoop,方法如下:
[root@node1 ~]# adduser hadoop[root@node1 ~]# passwd hadoop
Changing password for user hadoop.
New password:
BAD PASSWORD: The password is shorter than 8 characters
Retype new password:
passwd: all authentication tokens updated successfully.
给普通用户添加sudo执行权限,且执行sudo不需要输入密码
[root@node1 ~]# sudo vi /etc/sudoers
在%wheel ALL=(ALL) ALL一行下面添加如下语句:
hadoop ALL=(ALL) NOPASSWD: ALL
4 设置静态IP
设置静态IP
[root@node1 ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改核心内容如下
BOOTPROTO=static
IPADDR=10.90.100.121
GATEWAY=10.90.100.2
NETMASK=255.255.255.0
DNS1=10.90.100.2
IP地址根据实际的网段设置
注意:
BOOTPROTO设置为
static,表示IP为静态的。
GATEWAY设置为上一步查询到的实际网关地址。
IPADDR设置为网关所在的网段,这里查到的网段为10.90.100.0
5. 关闭防火墙
[root@node1 ~]# systemctl stop firewalld[root@node1 ~]# systemctl disable firewalld
6.克隆主机
(1)选中node1用来克隆出node2和node3主机,点击 虚拟机–>管理–>克隆
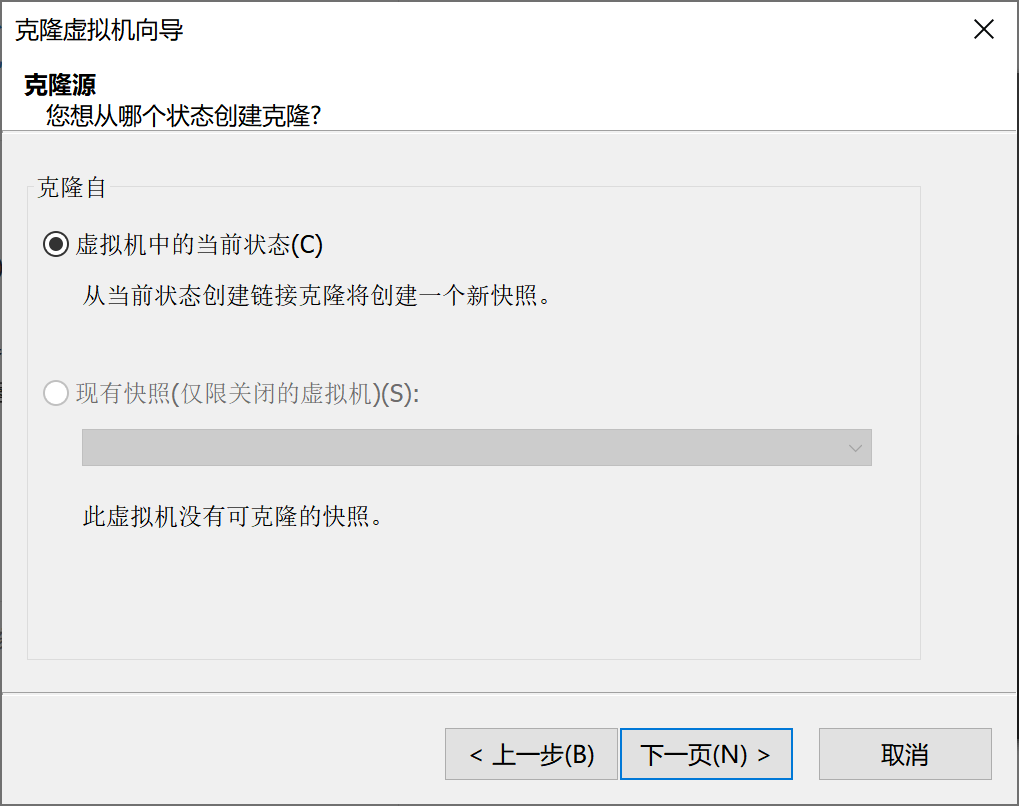
完整克隆
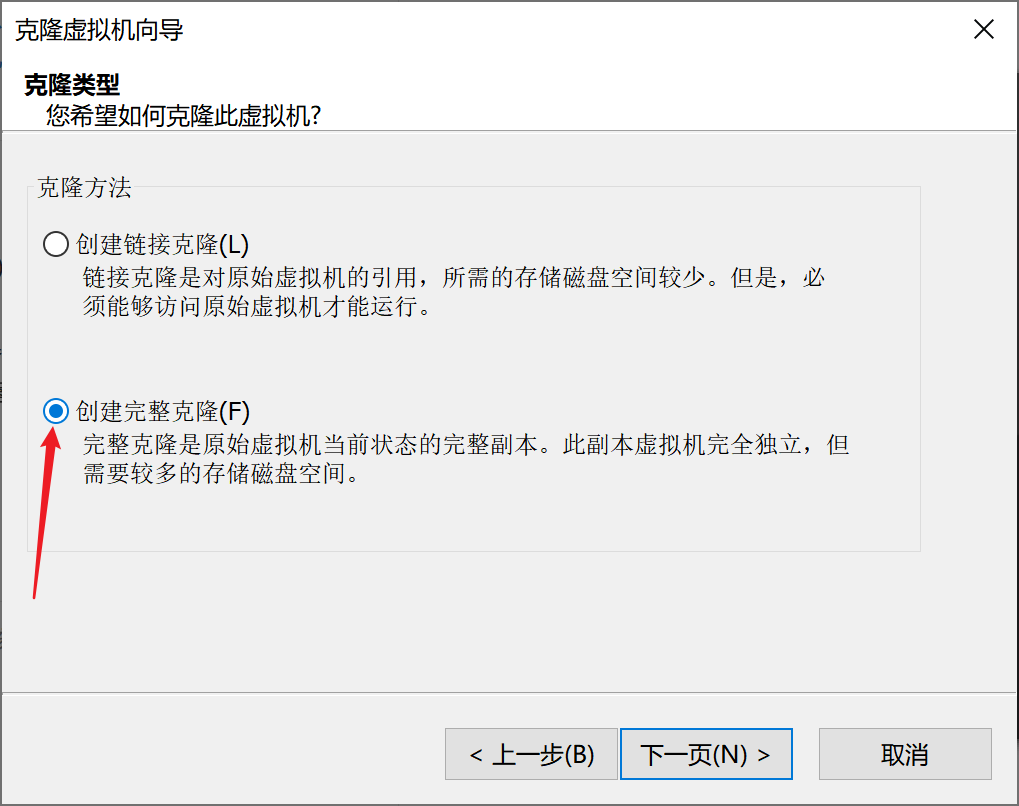
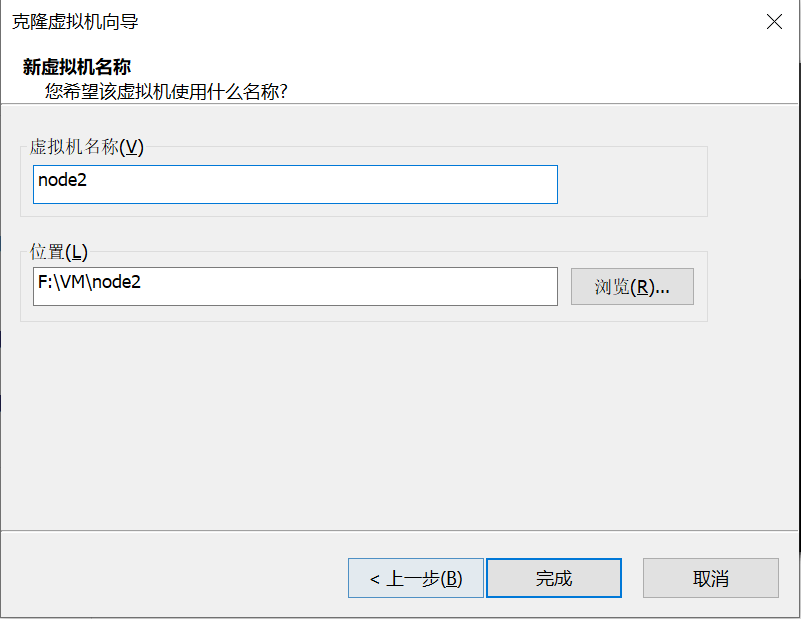
用同样的方法克隆出node3
修改主机名
在node2上登录普通用户hadoop进行操作
修改主机名
[hadoop@node1 ~]$ sudo hostnamectl set-hostname node2
[sudo] password for hadoop:
查看主机名
[hadoop@node1 ~]$ hostname
node2
重启机器
[hadoop@node1 ~]$ sudoreboot
同样的方法:
修改node3的主机名为
node3
设置静态IP
静态IP的设置过程参照第一部分
node2 ip设置为 10.90.100.122
node3 ip设置为 10.90.100.123
修改ip与主机名的映射
[hadoop@node1 ~]$ sudo vi /etc/hosts
添加如下内容
10.90.100.121 node1
10.90.100.122 node2
10.90.100.123 node3
重启机器
[hadoop@node1 ~]$ sudoreboot
同样的方法,修改node2、node3机器。
7.配置机器之间免密登录
在node1机器操作:
ssh-keygen -t rsa
执行命令后,连续敲击三次回车键
[hadoop@node1 ~]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter fileinwhich to save the key (/home/hadoop/.ssh/id_rsa):
Created directory '/home/hadoop/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:MOzp1MyZUfA69Wi3JEVoOXB4qkbRXr0t47ZCR2AgE2s hadoop@node1
The key's randomart image is:
+---[RSA 2048]----+
| +o+=o+. ||..+o+X..|| Eo.*oo.o || o.Bo* +=.|| .+.S +o+o || oo o.++. ||... o..||..||.|
+----[SHA256]-----+
拷贝公钥
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
执行ssh-copy-id命令后,根据提示输入yes,再输入机器登录密码
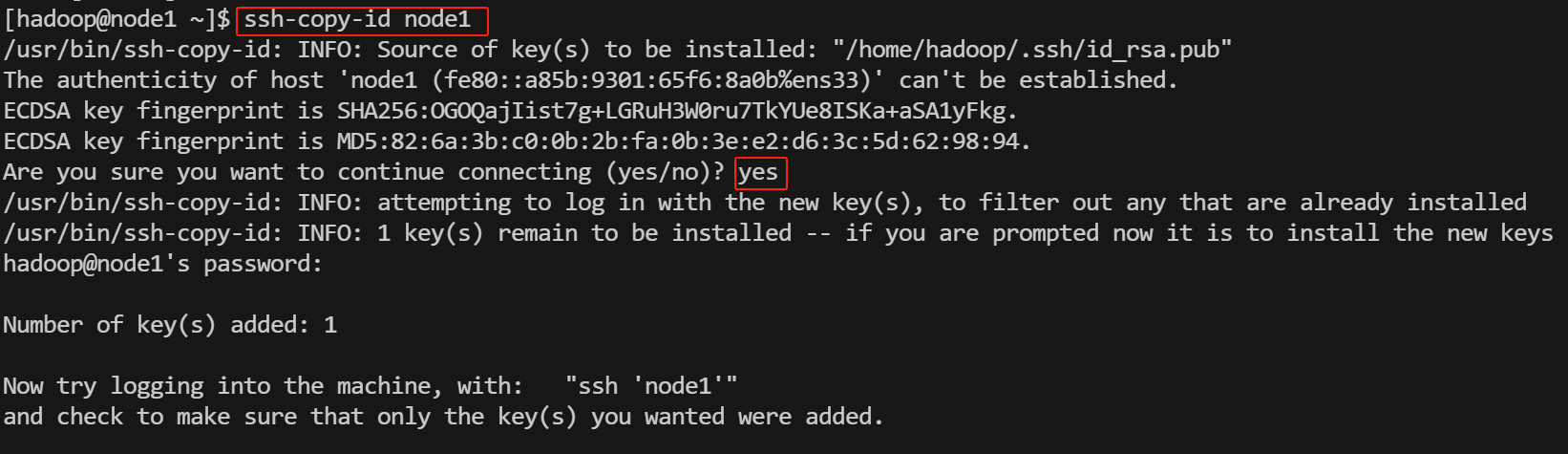
验证从node1发起ssh登录到node2,过程中不需要登录密码为配置成功。使用
exit退出免密登录。
同样的方法,在node2、node3机器上配置机器之间免密登录操作。
8.编写分发脚本
安装
rsync
命令
[hadoop@node1 ~]$ rsync--help
-bash: rsync: command not found
[hadoop@node1 ~]$ sudo yum installrsync-y
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
在主目录创建
bin
目录
[hadoop@node1 ~]$ mkdir ~/bin
创建分发脚本文件
xsync
[hadoop@node2 ~]$ vim ~/bin/xsync
内容如下
#!/bin/bash#1. 判断参数个数if[$#-lt1]thenecho Not Enough Arguement!exit;fi#2. 遍历集群所有机器forhostin node1 node2 node3
doecho====================$host====================#3. 遍历所有目录,挨个发送forfilein$@do#4. 判断文件是否存在if[-e$file]then#5. 获取父目录pdir=$(cd-P$(dirname $file);pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh$host"mkdir -p $pdir"rsync-av$pdir/$fname$host:$pdirelseecho$file does not exists!fidonedone
修改权限
[hadoop@node1 ~]$ chmod +x ~/bin/xsync
测试
分别在node2、node3机器安装xsync命令
sudo yum installrsync-y
把xsync命令发送到node2、node3
xsync /home/hadoop/bin
二、安装JDK
① 上传jdk文件到已经安装好的node1,上传方式有很多,任选一种方式即可:
② 上传成功后,通过 ls 命令查看是否上传成功
**③ 解压
jdk-8u202-linux-x64.tar.gz
到
/opt/module/hadoop
目录下:**
[hadoop@node1 ~]$ tar-zxvf jdk-8u202-linux-x64.tar.gz -C /opt/module/hadoop
没有/opt/module/hadoop目录先创建,因为是使用hadoop普通用户,把hadoop目录的所属用户改为hadoop
[hadoop@node1 ~]$ sudochown hadoop:hadoop -R /opt/module/hadoop
④建立 JDK 软链接,以方便后续使用:
[hadoop@node1 hadoop]$ cd /opt/module/hadoop/
[hadoop@node1 hadoop]$ ln-s /opt/module/hadoop/jdk1.8.0_202 jdk
⑤ 配置 JDK 环境变量 :
[hadoop@node1 hadoop]$ sudovim /etc/profile
vim 为打开文件命令
在文件内容的末尾添加如下代码(注意:等号两侧不要有空格)。
exportJAVA_HOME=/opt/module/hadoop/jdk
exportJRE_HOME=${JAVA_HOME}/jre
exportCLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:.
exportPATH=${JAVA_HOME}/bin:$PATH
⑥ 使配置生效 :
[hadoop@node1 hadoop]$ source /etc/profile
⑦ 检验是否安装成功 :
[hadoop@node1 hadoop]$ java-versionjava version "1.8.0_202"
Java(TM) SE Runtime Environment (build 1.8.0_202-b08)
Java HotSpot(TM)64-Bit Server VM (build 25.202-b08, mixed mode)
三、Hadoop集群安装部署
1.安装Hadoop
(1) 上传hadoop安装包到已经安装好的node1,上传方式有很多,任选一种方式即可
(2)上传成功后,通过 ls 命令查看是否上传成功
**(3)解压
hadoop-3.3.4.tar.gz
到
/opt/module/hadoop/
目录下**
[hadoop@node1 ~]$ tar-xzvf hadoop-3.3.4.tar.gz -C /opt/module/hadoop/
(4)建立 hadoop软链接,以方便后续使用
[hadoop@node1 hadoop]$ cd /opt/module/hadoop/
[hadoop@node1 hadoop]$ ln-s /opt/module/hadoop/hadoop-3.3.4 hadoop
(5)配置 hadoop 环境变量
[hadoop@node1 hadoop]$ sudovim /etc/profile
在文件内容的末尾添加如下代码(注意:等号两侧不要有空格)。
exportHADOOP_HOME=/opt/module/hadoop/hadoop
exportPATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
(6) 使配置生效 :
[hadoop@node1 software]$ source /etc/profile
(7) 校验
[hadoop@node1 software]$ hadoop version
Hadoop 3.3.4
Source code repository https://github.com/apache/hadoop.git -r a585a73c3e02ac62350c136643a5e7f6095a3dbb
Compiled by stevel on 2022-07-29T12:32Z
Compiled with protoc 3.7.1
From source with checksum fb9dd8918a7b8a5b430d61af858f6ec
This command was run using /opt/module/hadoop/hadoop-3.3.4/share/hadoop/common/hadoop-common-3.3.4.jar
[hadoop@node1 software]$
看到hadoop版本号输出,说明环境变量配置成功
2.配置Hadoop 集群
1)核心配置文件
配置
core-site.xml
[hadoop@node1 bin]$ cd$HADOOP_HOME/etc/hadoop
[hadoop@node1 hadoop]$ vim core-site.xml
内容如下:
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://node1:9820</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop/hadoop-3.3.4/data</value></property><!-- 配置HDFS网页登录使用的静态用户为hadoop --><property><name>hadoop.http.staticuser.user</name><value>hadoop</value></property><!-- 配置该hadoop(superUser)允许通过代理访问的主机节点 --><property><name>hadoop.proxyuser.hadoop.hosts</name><value>*</value></property><!-- 配置该hadoop(superUser)允许通过代理用户所属组 --><property><name>hadoop.proxyuser.hadoop.groups</name><value>*</value></property><!-- 配置该hadoop(superUser)允许通过代理的用户--><property><name>hadoop.proxyuser.hadoop.users</name><value>*</value></property></configuration>
**2)配置
hdfs-site.xml
**
[hadoop@node1 hadoop]$ vim hdfs-site.xml
内容如下:
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>node1:9870</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>node3:9868</value></property></configuration>
**3)配置
yarn-site.xml
**
[hadoop@node1 hadoop]$ vim yarn-site.xml
内容如下:
<?xml version="1.0"?><configuration><!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>node2</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><!-- yarn容器允许分配的最大最小内存 --><property><name>yarn.scheduler.minimum-allocation-mb</name><value>512</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>2048</value></property><!-- yarn容器允许管理的物理内存大小 --><property><name>yarn.nodemanager.resource.memory-mb</name><value>2048</value></property><!-- 关闭yarn对物理内存和虚拟内存的限制检查 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property></configuration>
**4)配置
mapred-site.xml
**
[hadoop@node1 hadoop]$ vim mapred-site.xml
内容如下:
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
**5)配置
workers
**
[hadoop@node1 hadoop]$ vim workers
把原有的内容替换成如下内容:
node1
node2
node3
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
6)配置历史服务器
修改
mapred-site.xml
[hadoop@node1 hadoop]$ vim mapred-site.xml
mapred-site.xml
添加如下配置
<!-- 历史服务器端地址 --><property><name>mapreduce.jobhistory.address</name><value>node1:10020</value></property><!-- 历史服务器web端地址 --><property><name>mapreduce.jobhistory.webapp.address</name><value>node1:19888</value></property>
文件最终结果:
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- 历史服务器端地址 --><property><name>mapreduce.jobhistory.address</name><value>node1:10020</value></property><!-- 历史服务器web端地址 --><property><name>mapreduce.jobhistory.webapp.address</name><value>node1:19888</value></property></configuration>
7)配置日志聚集
修改
yarn-site.xml
[hadoop@node1 hadoop]$ vim yarn-site.xml
yarn-site.xml
在
<configuration></configuration>
之间添加如下配置
<!-- 开启日志聚集功能 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 设置日志聚集服务器地址 --><property><name>yarn.log.server.url</name><value>http://node1:19888/jobhistory/logs</value></property><!-- 设置日志保留时间为7天 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property>
8)在hadoop-env.sh文件配置
[hadoop@node1 hadoop]$ vim hadoop-env.sh
内容:
exportJAVA_HOME=/opt/module/hadoop/jdk
9)分发hadoop安装文件
把hadoop安装配置文件从node1机器分发到node2、node3机器
[hadoop@node1 hadoop]$ xsync /opt/module/hadoop
查看node2和node3机器是否有hadoop和jdk文件
10)修改环境变量
修改node2、node3环境变量,分别在node2、node3机器上操作
sudovim /etc/profile
文件末尾添加:
#JAVAexportJAVA_HOME=/opt/module/hadoop/jdk
exportJRE_HOME=${JAVA_HOME}/jre
exportCLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:.
exportPATH=${JAVA_HOME}/bin:$PATH#HadoopexportHADOOP_HOME=/opt/module/hadoop/hadoop
exportPATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
让环境变量生效
source /etc/profile
验证是否已经安装好。
11)格式化文件系统
在node1机器执行格式化hdfs
[hadoop@node1 ~]$ hdfs namenode -format
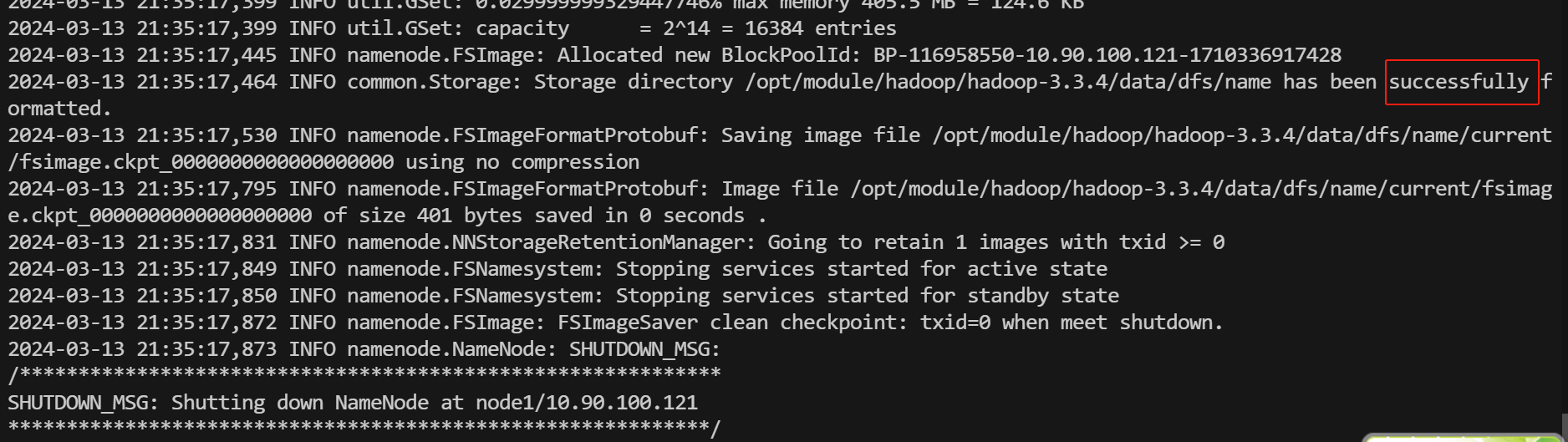
看到
successfully formatted
为格式化成功。
注意:格式化成功后,以后就不能再次格式化了。
12) 启动hdfs
在node1机器上执行启动hdfs命令
[hadoop@node1 hadoop]$ start-dfs.sh
13)启动yarn
在node2机器上执行启动yarn命令
[hadoop@node2 hadoop]$ start-yarn.sh
至此,如果过程中没有报错就已经部署完成,接下来可以进行验证。
3.验证
3.1 进程验证
分别在不同机器执行jps命令
node1:
[hadoop@node1 hadoop]$ jps
4049 NodeManager
4145 Jps
3619 NameNode
3742 DataNode
node2:
[hadoop@node2 hadoop]$ jps
2064 DataNode
2231 ResourceManager
2345 NodeManager
2698 Jps
node3:
[hadoop@node3 ~]$ jps
2419 Jps
2199 SecondaryNameNode
2120 DataNode
2317 NodeManager
3.2 浏览器验证
浏览器访问namenode,输入namenode所在的节点IP及配置的端口
http://10.90.100.121:9870
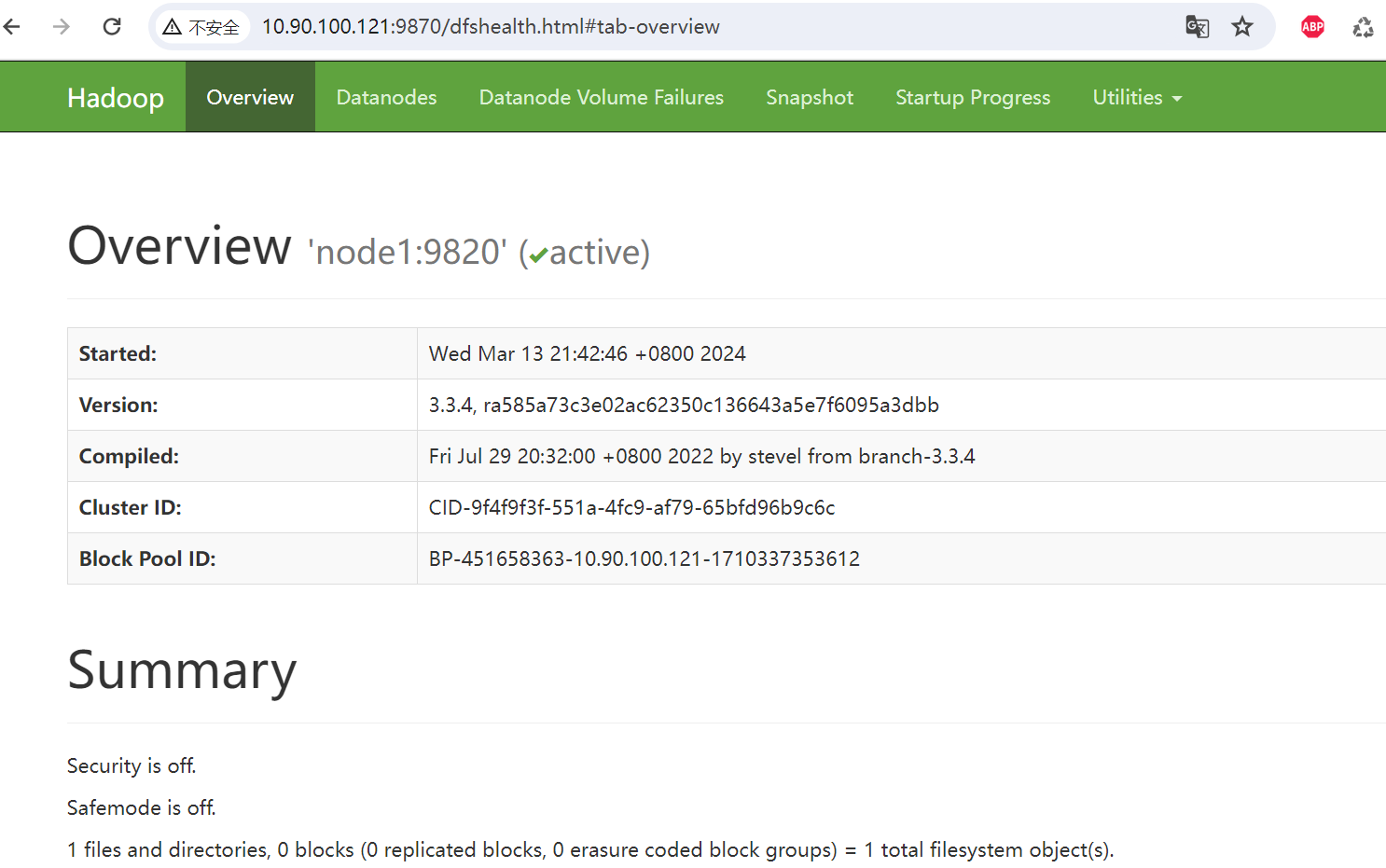
浏览器访问yarn,输入yarn所在的节点IP及配置的端口
http://10.90.100.122:8088
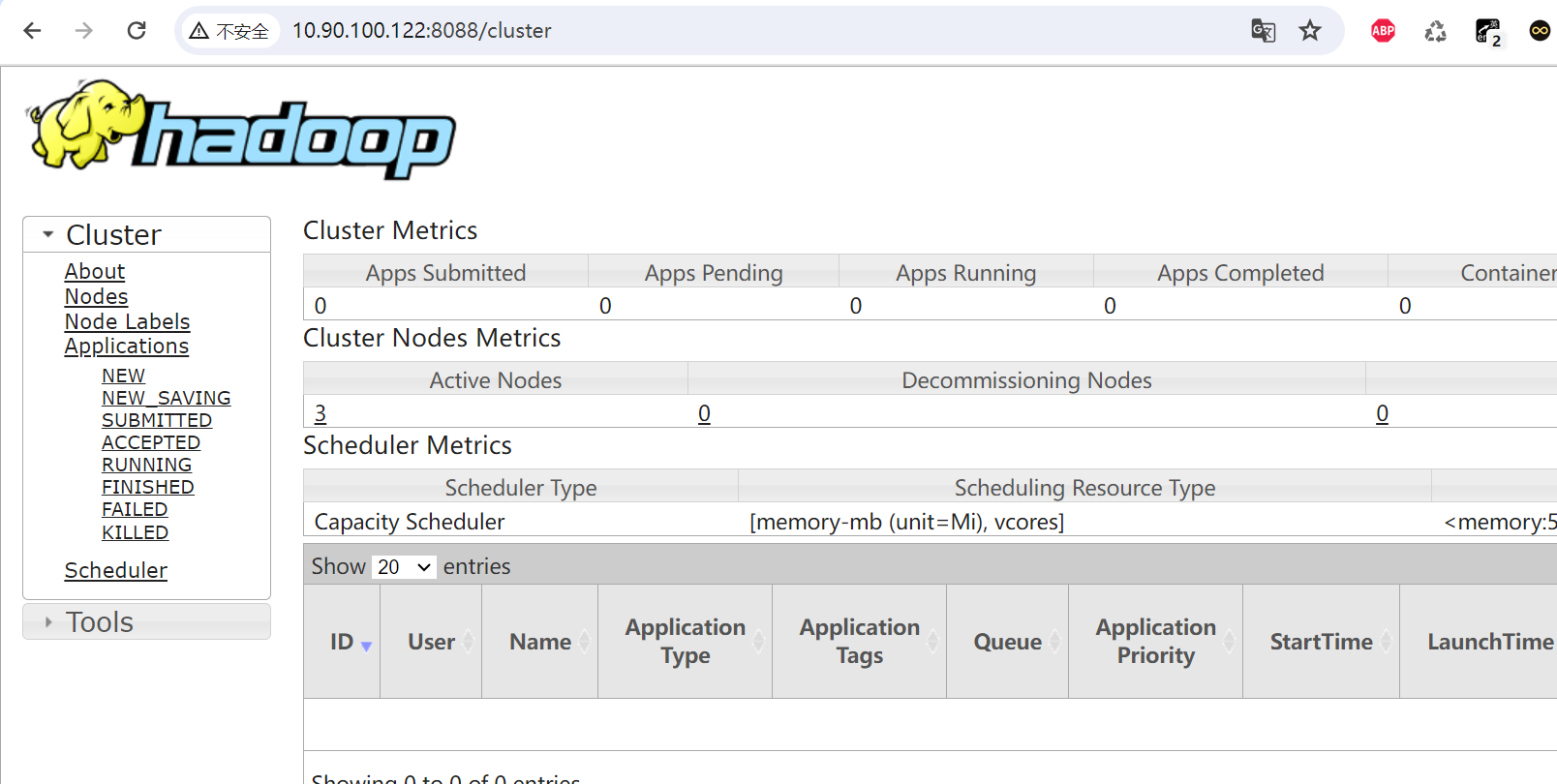
浏览器访问SecondaryNameNode
http://10.90.100.123:9868
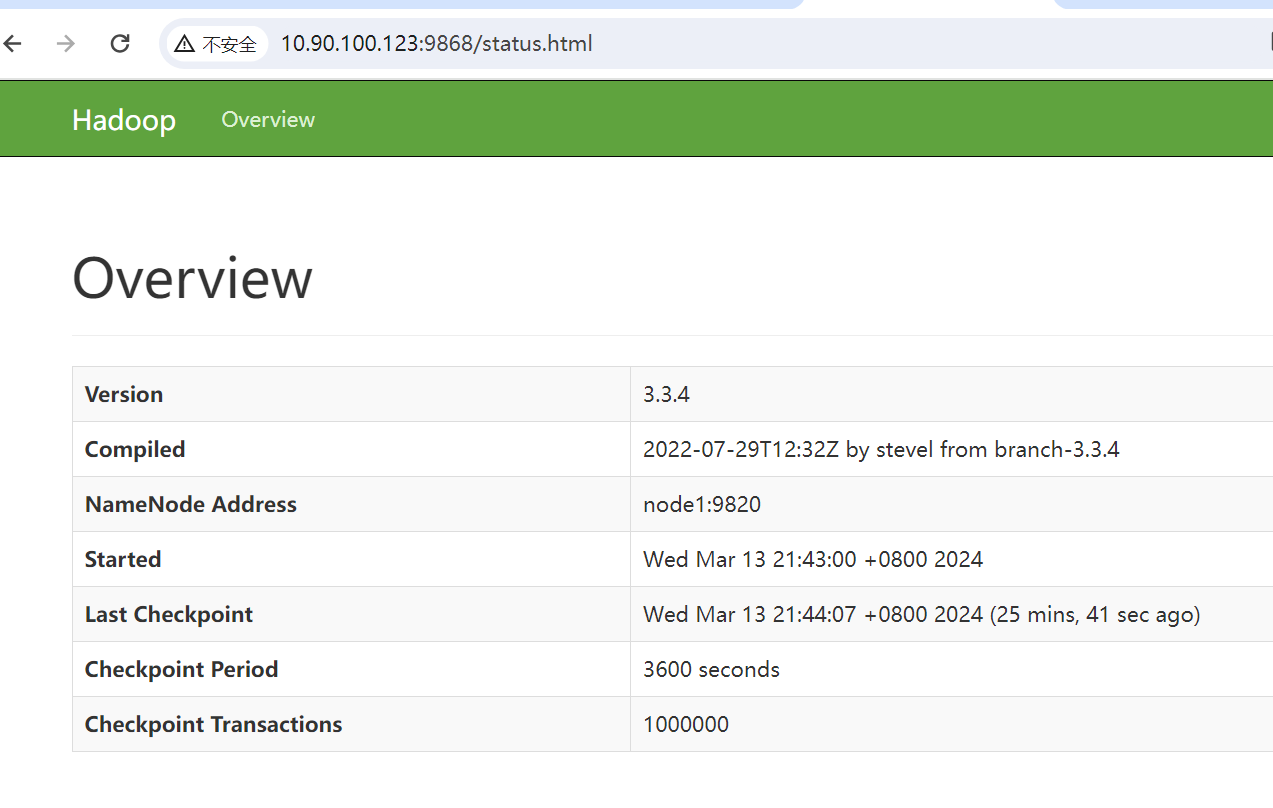
附: Hadoop群起脚本
为了更加便捷的启动和停止集群运行,可以写一个脚本实现。
(1)在/home/hadoop/bin目录下创建hdp.sh脚本文件
[hadoop@node1 ~]$ vim ~/bin/hdp.sh(2)hdp.sh写入以下内容:
#!/bin/bashif[$#-lt1]thenecho"No Args Input..."exit;ficase$1in"start")echo" =================== 启动 hadoop集群 ==================="echo" --------------- 启动 hdfs ---------------"ssh node1 "/opt/module/hadoop/hadoop/sbin/start-dfs.sh"echo" --------------- 启动 yarn ---------------"ssh node2 "/opt/module/hadoop/hadoop/sbin/start-yarn.sh"echo" --------------- 启动 historyserver ---------------"ssh node1 "/opt/module/hadoop/hadoop/bin/mapred --daemon start historyserver";;"stop")echo" =================== 关闭 hadoop集群 ==================="echo" --------------- 关闭 historyserver ---------------"ssh node1 "/opt/module/hadoop/hadoop/bin/mapred --daemon stop historyserver"echo" --------------- 关闭 yarn ---------------"ssh node2 "/opt/module/hadoop/hadoop/sbin/stop-yarn.sh"echo" --------------- 关闭 hdfs ---------------"ssh node1 "/opt/module/hadoop/hadoop/sbin/stop-dfs.sh";;"jps")forhostin node1 node2 node3 doecho====================$host====================ssh$host"/opt/module/hadoop/jdk1.8.0_202/bin/jps"done;; *)echo"Input Args Error...";;esac(3)增加权限
[hadoop@node1 ~]$ chmod777 ~/bin/hdp.sh (4) 启动集群
[hadoop@node1 ~]$ hdp.sh start (5)查看进程
[hadoop@node1 ~]$ hdp.sh jps(6)停止集群
[hadoop@node1 ~]$ hdp.sh stop
版权归原作者 shisjin 所有, 如有侵权,请联系我们删除。