
本文收录于专栏:精通AI实战千例专栏合集
https://blog.csdn.net/weixin_52908342/category_11863492.html
从基础到实践,深入学习。无论你是初学者还是经验丰富的老手,对于本专栏案例和项目实践都有参考学习意义。
每一个案例都附带关键代码,详细讲解供大家学习,希望可以帮到大家。正在不断更新中~
一.AIGC安全与伦理问题【技术挑战与解决方案】
近年来,人工智能生成内容(AIGC)技术取得了巨大的进步,特别是在自然语言处理、图像生成和视频合成等领域。然而,随着这些技术的普及,AIGC的安全与伦理问题也逐渐成为亟待解决的挑战。本文将探讨AIGC技术在安全与伦理方面面临的问题,并提出可能的解决方案。

AIGC的安全问题
1. 数据隐私和安全
AIGC模型通常需要大量的训练数据,这些数据可能包含个人隐私信息。如果这些数据在训练过程中未能得到适当的保护,可能导致数据泄露和滥用。以下是一个简单的数据脱敏示例:
import pandas as pd
# 示例数据
data ={'name':['Alice','Bob','Charlie'],'age':[25,30,35],'email':['[email protected]','[email protected]','[email protected]']}
df = pd.DataFrame(data)# 数据脱敏函数defanonymize_data(df):
df['name']='REDACTED'
df['email']='REDACTED'return df
# 脱敏后的数据
df_anonymized = anonymize_data(df)print(df_anonymized)
2. 生成虚假信息
AIGC技术可以生成高度逼真的文本、图像和视频,这给虚假信息的传播提供了便利。例如,Deepfake技术可以生成看似真实的视频,可能用于政治诽谤或诈骗。
3. 模型滥用
开放的AIGC模型可能被恶意使用。例如,GPT-3可以生成欺诈性邮件或钓鱼网站内容,从而增加网络攻击的风险。
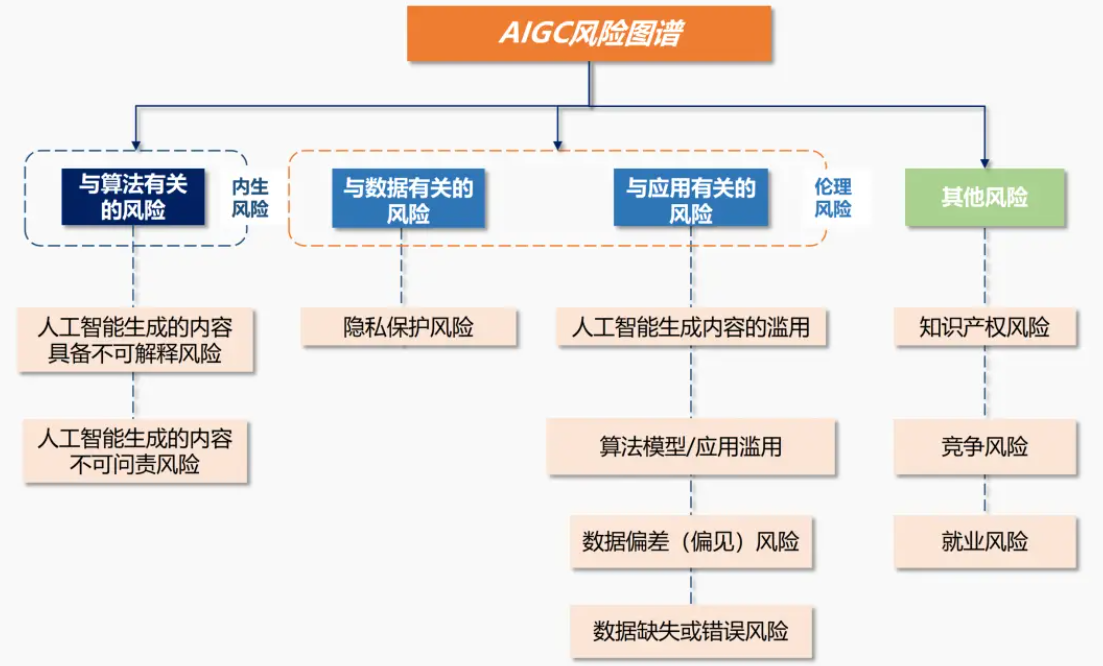
AIGC的伦理问题
1. 偏见与歧视
AIGC模型的训练数据如果包含偏见,生成的内容也可能反映这些偏见。例如,如果训练数据中存在性别歧视,生成的文本可能也会表现出性别歧视。
2. 内容所有权
AIGC生成的内容的版权问题目前尚未明确。如果模型生成的内容与某个艺术家的作品非常相似,是否会侵犯版权?
3. 社会责任
AIGC技术的开发者和使用者需要对其可能带来的社会影响负责。例如,Deepfake技术的开发者需要考虑如何防止其技术被用于恶意目的。
解决方案
1. 加强数据保护
使用数据脱敏和加密技术保护训练数据,确保个人隐私信息不被泄露。可以采用差分隐私技术来保护数据隐私:
from diffprivlib.mechanisms import Laplace
# 差分隐私示例
laplace = Laplace(epsilon=1, sensitivity=1)
noisy_data = laplace.randomise(10)print(noisy_data)
2. 内容鉴别
开发能够鉴别虚假内容的技术,例如,通过水印技术标识生成内容,通过机器学习模型检测Deepfake视频。
3. 模型审查与监管
建立AIGC模型的审查和监管机制,确保模型不会被恶意使用。开发者可以设置使用限制和访问控制,防止滥用。
4. 多样性与公平性
在模型训练中使用多样化的数据集,减少偏见和歧视。例如,采用公平性优化算法:
from aif360.algorithms.inprocessing import PrejudiceRemover
# 公平性优化示例
pr = PrejudiceRemover(sensitive_attr='sex')
pr.fit(X_train, y_train)
y_pred = pr.predict(X_test)
5. 明确版权和责任
制定明确的法律法规,保护AIGC生成内容的版权,并明确开发者和使用者的责任。例如,可以在AIGC生成内容时自动附加版权声明。
6. 透明度与可解释性
AIGC模型的决策过程往往是黑箱操作,难以解释其生成内容的依据和逻辑。这种透明度的缺乏会增加用户对AIGC模型的不信任,也可能掩盖其中潜在的偏见和错误。因此,提高AIGC模型的透明度和可解释性是解决伦理问题的重要一环。
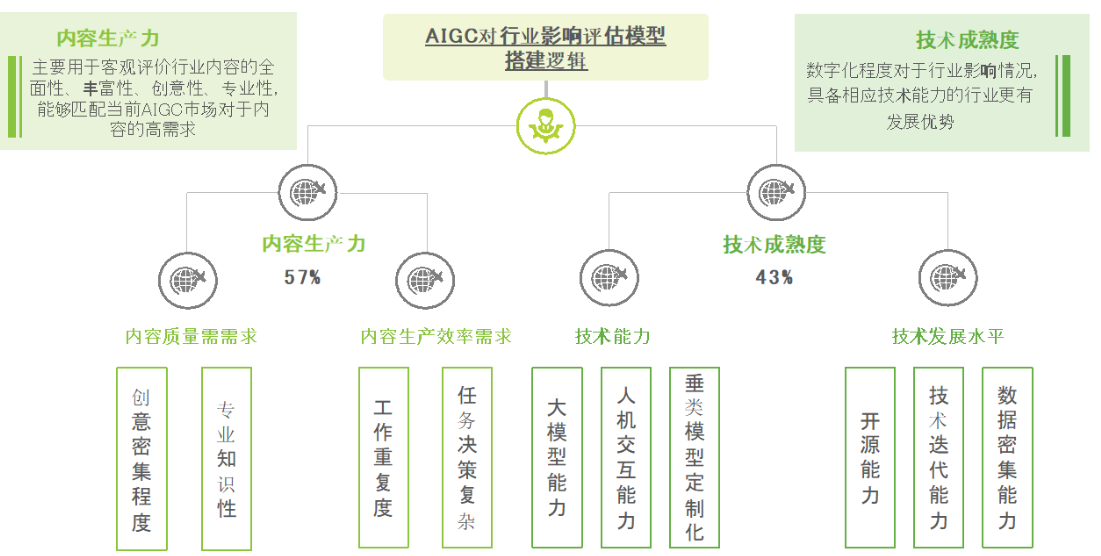
实现透明度和可解释性的方法
- 模型可解释性工具:开发和使用可以解释模型决策过程的工具,如SHAP(Shapley Additive Explanations)和LIME(Local Interpretable Model-agnostic Explanations)。
import shap
import xgboost
# 训练示例模型
X, y = shap.datasets.boston()
model = xgboost.XGBRegressor().fit(X, y)# 解释模型预测
explainer = shap.Explainer(model)
shap_values = explainer(X)# 绘制解释结果
shap.summary_plot(shap_values, X)
- 模型透明性报告:在发布AIGC模型时,附带详细的模型透明性报告,解释模型的训练数据来源、训练过程、评估指标以及潜在的偏见和限制。
7. 用户教育与公众意识
加强公众对AIGC技术的认知和理解是解决安全与伦理问题的基础。通过教育和培训,提高用户识别虚假信息和理解AIGC技术潜力与风险的能力,从而减少其滥用和误用。
用户教育的关键内容
- 识别虚假内容的技能:通过培训和资源,教会公众如何识别Deepfake视频和其他虚假内容。
- 了解数据隐私的重要性:提高公众对数据隐私保护的认识,鼓励用户在使用AIGC服务时注意数据的共享和保护。
8. 跨学科合作
解决AIGC的安全与伦理问题需要技术专家、法律专家、伦理学家以及政策制定者的跨学科合作。通过多方参与,制定全面、协调的解决方案。
跨学科合作的具体措施
- 多方利益相关者的参与:建立包括技术专家、法律学者、伦理学家和政策制定者在内的跨学科工作组,共同探讨AIGC技术的安全和伦理问题。
- 举办跨学科研讨会:定期举办研讨会,促进不同领域专家之间的交流与合作,共同制定规范和政策。
9. 法规与政策
针对AIGC技术的安全和伦理问题,制定适当的法规和政策是必不可少的。法律应跟随技术发展,及时更新和调整,以适应新的挑战和需求。
法规与政策的建议
- 数据保护法:制定和加强数据保护法律,确保用户数据在AIGC应用中的安全和隐私。
- 反虚假信息法:制定打击虚假信息传播的法律,明确AIGC生成虚假信息的法律责任和处罚措施。
- 技术使用规范:制定AIGC技术使用的行业标准和规范,确保技术的开发和应用符合伦理和社会责任。
案例研究
为了更好地理解AIGC安全与伦理问题的具体挑战和解决方案,我们可以通过一些具体的案例研究来进行深入探讨。
案例一:Deepfake视频的识别与防护
问题背景
Deepfake视频技术通过深度学习算法生成逼真的伪造视频,这些视频可能被用来传播虚假信息、进行政治诽谤或者实施欺诈。如何识别和防护Deepfake视频成为一个重要的技术挑战。
解决方案
- 技术检测方法:使用机器学习算法和计算机视觉技术来检测Deepfake视频。例如,可以通过分析视频中的细微面部特征变化和异常的光影效果来识别伪造视频。
- 生成技术的改进:在生成Deepfake视频时,添加不可见的水印或标识,使其在被识别时能够被轻易检测。
import cv2
import numpy as np
# 载入示例视频帧
frame = cv2.imread('frame.jpg')# 添加水印
watermark = cv2.putText(frame.copy(),'DEEPFAKE',(10,30), cv2.FONT_HERSHEY_SIMPLEX,1,(0,0,255),2, cv2.LINE_AA)# 显示结果
cv2.imshow('Watermarked Frame', watermark)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 法律和政策措施:制定相关法律法规,明确制作和传播Deepfake视频的法律责任和处罚措施。政府机构可以建立专门的监管机构来监督和管理Deepfake技术的使用。
案例二:AIGC在新闻生成中的伦理问题
问题背景
一些新闻机构开始使用AIGC技术生成新闻报道,这可以提高新闻生产效率。然而,AIGC生成的新闻可能存在准确性和真实性问题,甚至可能引发社会偏见和误导公众。
解决方案
- 内容审核机制:在AIGC生成的新闻发布之前,必须经过严格的人工审核和校对,确保内容的准确性和真实性。
- 透明度声明:明确标识AIGC生成的新闻内容,并在内容中附加透明度声明,告知读者该内容是由人工智能生成的。
# AIGC生成新闻示例
news_content ="Today, a major breakthrough was made in the field of artificial intelligence..."# 添加透明度声明
transparency_statement ="\n\n(Note: This article was generated by an artificial intelligence system.)"
news_content += transparency_statement
print(news_content)
- 多样化训练数据:使用多样化和无偏见的数据集来训练AIGC模型,减少模型生成内容中的偏见和歧视。
案例三:艺术作品的版权问题
问题背景
AIGC技术可以生成高度原创性的艺术作品,如绘画、音乐和文学作品。然而,这些作品的版权归属问题目前尚未明确,可能引发法律纠纷。
解决方案
- 法律明确版权归属:通过法律法规明确规定AIGC生成作品的版权归属,可以考虑将版权归属于模型的开发者或使用者,或设立特定的AIGC作品版权制度。
- 使用许可协议:在AIGC模型的使用协议中,明确规定生成作品的版权归属和使用权利,避免法律纠纷。
- 版权保护技术:在AIGC生成作品中嵌入数字水印或版权标识,防止未经授权的复制和传播。
from PIL import Image, ImageDraw, ImageFont
# 载入示例图片
image = Image.open('artwork.jpg')# 添加版权标识
draw = ImageDraw.Draw(image)
font = ImageFont.truetype('arial.ttf',36)
draw.text((10,10),'© AIGC Generator', fill='red', font=font)# 显示结果
image.show()
前沿技术和未来展望
1. 先进的检测技术
随着AIGC技术的发展,虚假信息和内容生成技术也在不断演进。为了应对日益复杂的虚假信息,研究人员正在开发更为先进的检测技术。
对抗性生成网络 (GAN)
对抗性生成网络(GAN)是一种常用的AIGC技术,用于生成逼真的图像和视频。然而,GAN不仅可以用于生成内容,还可以用于检测内容。通过训练检测模型来识别虚假内容,可以提高检测的准确性。
from keras.datasets import mnist
from keras.layers import Input, Dense
from keras.models import Model
from keras.optimizers import Adam
import numpy as np
# 加载数据(x_train, _),(x_test, _)= mnist.load_data()
x_train = x_train.astype('float32')/255.
x_train = x_train.reshape((x_train.shape[0],-1))
x_test = x_test.astype('float32')/255.
x_test = x_test.reshape((x_test.shape[0],-1))# 定义生成器模型
input_gen = Input(shape=(100,))
gen = Dense(256, activation='relu')(input_gen)
gen = Dense(512, activation='relu')(gen)
gen = Dense(1024, activation='relu')(gen)
output_gen = Dense(784, activation='sigmoid')(gen)
generator = Model(input_gen, output_gen)# 定义判别器模型
input_disc = Input(shape=(784,))
disc = Dense(1024, activation='relu')(input_disc)
disc = Dense(512, activation='relu')(disc)
disc = Dense(256, activation='relu')(disc)
output_disc = Dense(1, activation='sigmoid')(disc)
discriminator = Model(input_disc, output_disc)# 编译判别器
discriminator.compile(optimizer=Adam(), loss='binary_crossentropy')# 定义对抗模型
discriminator.trainable =False
gan_input = Input(shape=(100,))
generated_image = generator(gan_input)
gan_output = discriminator(generated_image)
gan = Model(gan_input, gan_output)# 编译对抗模型
gan.compile(optimizer=Adam(), loss='binary_crossentropy')
2. 自动化伦理审查
未来的AIGC系统可以集成自动化伦理审查模块,在生成内容的过程中自动检测和纠正偏见、不公正或不道德的内容。这种审查可以基于自然语言处理和机器学习算法。
自动化伦理审查工具
- 基于规则的审查:通过预定义的规则和关键词过滤不合适的内容。
- 基于机器学习的审查:使用训练好的伦理模型来审查内容的伦理合规性。
import spacy
# 加载语言模型
nlp = spacy.load('en_core_web_sm')# 定义伦理审查函数defethical_review(text):
doc = nlp(text)for token in doc:if token.text.lower()in['bias','discrimination','hate']:return"Unethical content detected"return"Content is ethical"# 示例文本
text ="This AI model demonstrates bias in gender classification."
review_result = ethical_review(text)print(review_result)
3. 伦理设计的模型
设计符合伦理的AIGC模型需要在开发阶段就考虑伦理问题。例如,使用公平性增强算法来减少模型中的偏见,确保模型生成的内容公平、公正。
公平性增强算法
- 数据预处理:在训练之前,确保数据集的多样性和公平性。
- 模型训练:使用公平性优化算法,如对抗性训练或公平性约束。
- 结果评估:在评估模型时,考虑公平性指标,如均等机会(Equal Opportunity)和均等误差(Equal Error Rate)。
4. 多领域合作
解决AIGC的安全和伦理问题需要技术专家、法律学者、伦理学家和政策制定者的合作。通过多领域合作,可以制定更全面的解决方案,推动AIGC技术的健康发展。
多领域合作的具体措施
- 跨学科研讨会:定期举办研讨会,促进不同领域专家的交流与合作。
- 行业标准和规范:制定AIGC技术的行业标准和规范,确保技术的开发和应用符合伦理和社会责任。
- 公众参与:鼓励公众参与AIGC技术的讨论和决策,确保技术发展符合社会需求和伦理规范。
5. 教育和培训
加强公众对AIGC技术的认知和理解,通过教育和培训,提高公众识别虚假信息和理解AIGC技术潜力与风险的能力。
教育和培训的内容
- AIGC技术基础:介绍AIGC技术的基本原理和应用。
- 识别虚假信息:教会公众如何识别Deepfake视频和其他虚假内容。
- 数据隐私保护:提高公众对数据隐私保护的认识,鼓励用户在使用AIGC服务时注意数据的共享和保护。
总结
人工智能生成内容(AIGC)技术在推动社会和经济发展的过程中展示了巨大的潜力,但也带来了复杂的安全与伦理挑战。本文探讨了AIGC技术在数据隐私和安全、虚假信息生成、模型滥用、偏见与歧视、内容所有权以及社会责任等方面面临的问题,并提出了一系列技术和非技术的解决方案。
主要挑战
- 数据隐私和安全:AIGC模型的训练数据中可能包含敏感信息,需要采取措施保护数据隐私。
- 生成虚假信息:虚假信息的生成和传播变得更加容易,增加了信息安全的风险。
- 模型滥用:开放的AIGC模型可能被恶意使用,造成社会危害。
- 偏见与歧视:训练数据中的偏见可能导致模型生成内容也存在偏见。
- 内容所有权:AIGC生成内容的版权归属问题尚未明确。
- 社会责任:开发者和使用者需要对AIGC技术可能带来的社会影响负责。
解决方案
- 加强数据保护:使用数据脱敏和加密技术,确保个人隐私信息不被泄露。
- 内容鉴别:开发检测和鉴别虚假内容的技术,如水印和机器学习模型。
- 模型审查与监管:建立审查和监管机制,防止模型被滥用。
- 多样性与公平性:使用多样化和公平的数据集进行模型训练,减少偏见。
- 明确版权和责任:制定明确的法律法规,保护AIGC生成内容的版权,并明确责任。
- 透明度与可解释性:提高模型的透明度和可解释性,增强用户信任。
- 用户教育与公众意识:通过教育和培训,提高公众对AIGC技术的认知和理解。
- 跨学科合作:通过多领域合作,制定全面的解决方案。
- 法规与政策:制定适当的法规和政策,保障AIGC技术的安全和伦理使用。
前沿技术和未来展望
未来,AIGC技术的发展将进一步依赖于先进的检测技术、自动化伦理审查、伦理设计的模型、多领域合作以及公众教育和培训。通过不断提升技术手段和完善社会机制,我们可以在发挥AIGC技术优势的同时,有效应对其带来的安全与伦理挑战。
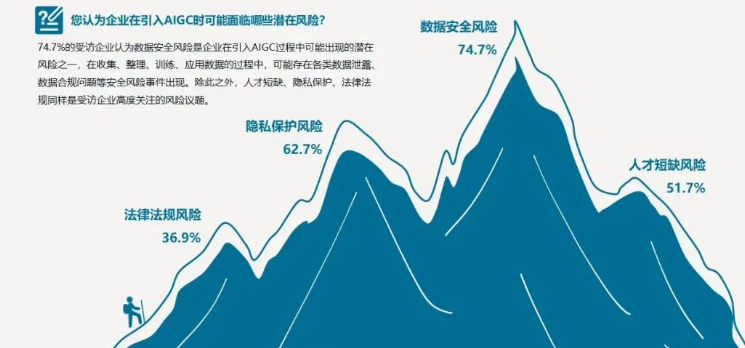
AIGC技术在带来巨大创新潜力的同时,也伴随着安全与伦理问题。通过多方面的努力,包括技术创新、政策法规、跨学科合作和公众教育,我们可以在最大限度上发挥AIGC技术的优势,同时减少其潜在的负面影响。只有在技术进步和伦理考量之间找到平衡点,才能确保AIGC技术在未来的发展中造福全人类。
版权归原作者 一键难忘 所有, 如有侵权,请联系我们删除。