
Flink提交任务的方式有两种,第一种是自带的UI页面,但是这种提交方式很少有团队正式使用,因为这种方式的资源分配是按照task为单位,设置并行度的,而不是continer,一个并行度就要占用一个task,国内九成九的都是普通公司,不是大厂,根本用不起,这也是flink很少在国内使用的原因之一。第二种提交方式就是命令行模式,这种方式下就和UI提交是同源的,也可以提交给yarn。说白了就算国内的公司跳不开必须使用flink时,也只是提交给了yarn,很少有公司有那个经济实力,直接把任务交给flink自身的jobmanager。一般测试环境为了方便可能用才页面。
第一种UI提交
UI页面你需要浏览器访问flink的jobmanager节点,默认端口号是8081
点击左侧导航栏最后一项
点击
add new
,会弹出文件框,你要选择你的jar包上传
上传后点击后边的
Upload
,在进度条完成后就会生成任务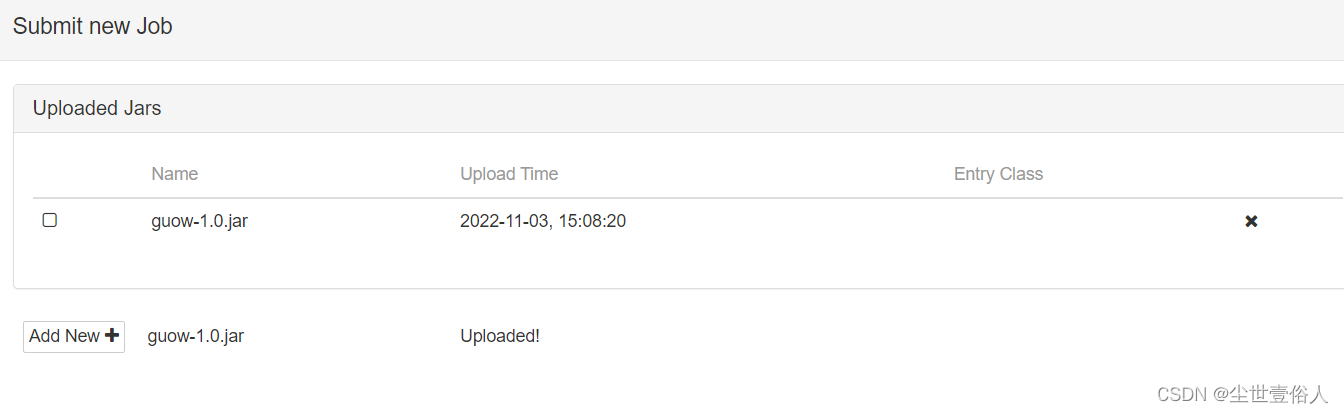
选择任务前面的复选框,点击后会弹出基本配置内容,分别是运行的类的包路径、并行度、参数,以及最后一个SavePath一般不用,它的作用和Spark的Checkpoint一样,都是设置一个检查点。
区别在于checkpoint是增量做的,每次的时间短,数据量小,只要在程序里面启用后会自动触发,用户无需感知;savepoint是全量做的,时间长,数据量大,需要用户主动触发。
checkpoint 是任务结束的时候自动使用,不需要用户指定,savepoint 一般用于程序版本更新、bug修复、A/B Test 等场景,需要用户指定。
需要特别注意的是并行度,最大不能超过Overview页面中显示的
Available Task Slots可用数
,而且并行度的生效权重遵循
页面权重<代码中StreamExecutionEnvironment权重<算子权重
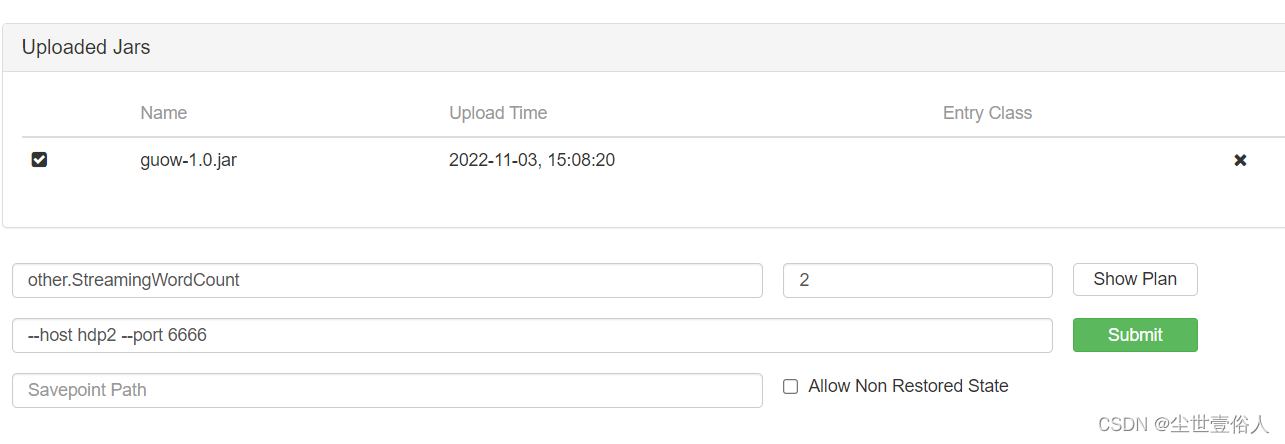
设置好这些就可以点击
Submit
提交了,然后就会跳转到任务的监控页面,你可以在这个页面中看到每一个详情算子的状态,以及整个任务的相关信息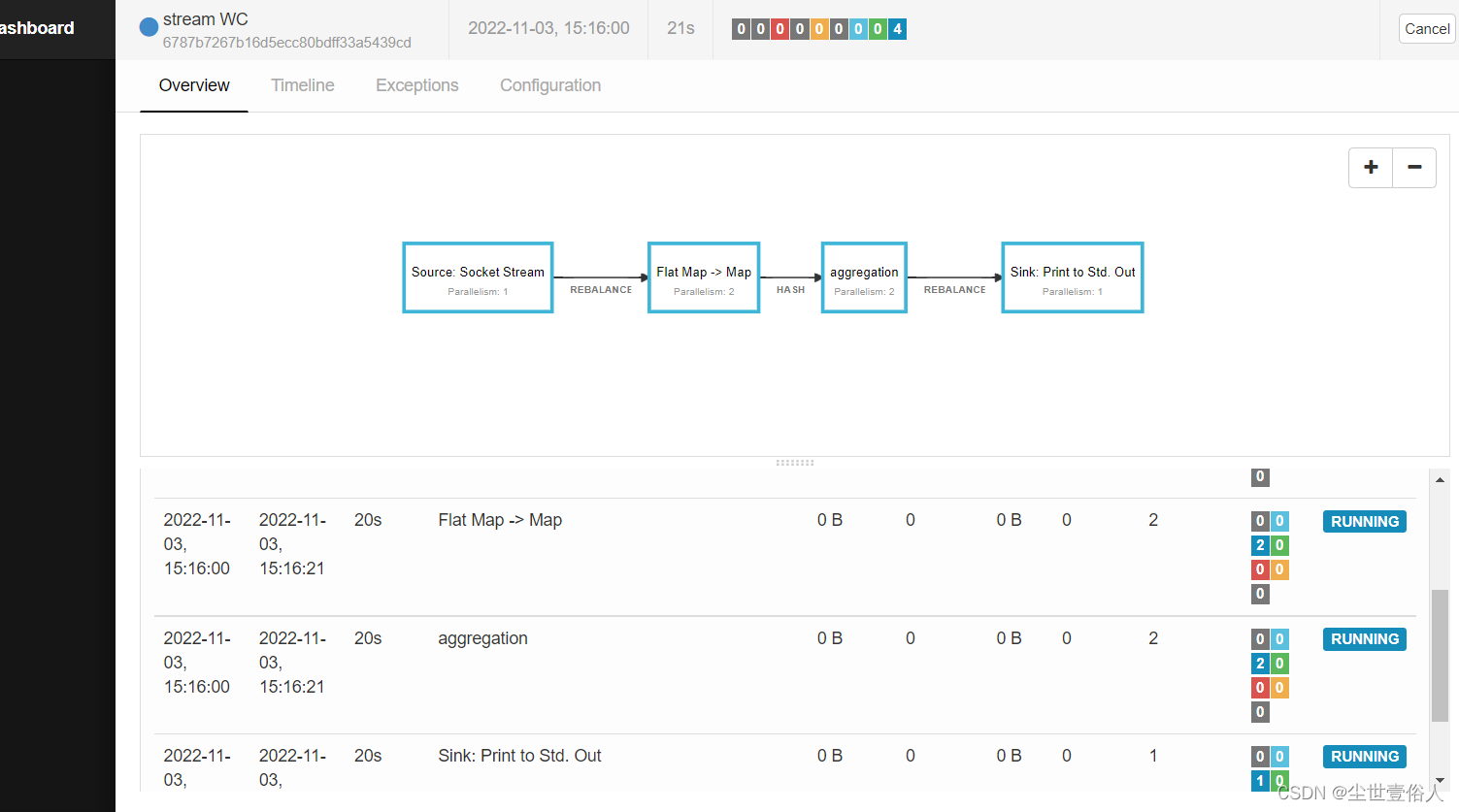
你要关注的重点是下面算子列表的状态,确保正常运行,此时你就可以不用管了,在,
Running Jobs
中可以看到这个任务,如果你想结束就进入任务详情,点击右上角的
Cancel
第二种就是命令行
命令行模式下就是使用
${FLINK_HOME}/bin
下的
flink
命令提交任务,和前面说的一样在使用flink的jobmanager下和页面操作没差别。命令使用方法如下
flink命令执行模板:flink run [option]
-c,--class : 执行的类路径
-C,--classpath : 向每个用户代码添加url,通过UrlClassLoader加载。url需要指定文件的schema如(file://)
-d,–-detached : 在后台运行
-p,–-parallelism : job需要的并行度,这个一般都需要设置。
-q,–-sysoutLogging : 禁止logging输出作为标准输出。
-s,--fromSavepoint : savepoint路径。
-sae,–-shutdownOnAttachedExit : 任务随着客户端终端而停止,这个参数和-d不是共存的
比如我上面例子,使用的命令,可以是下面这样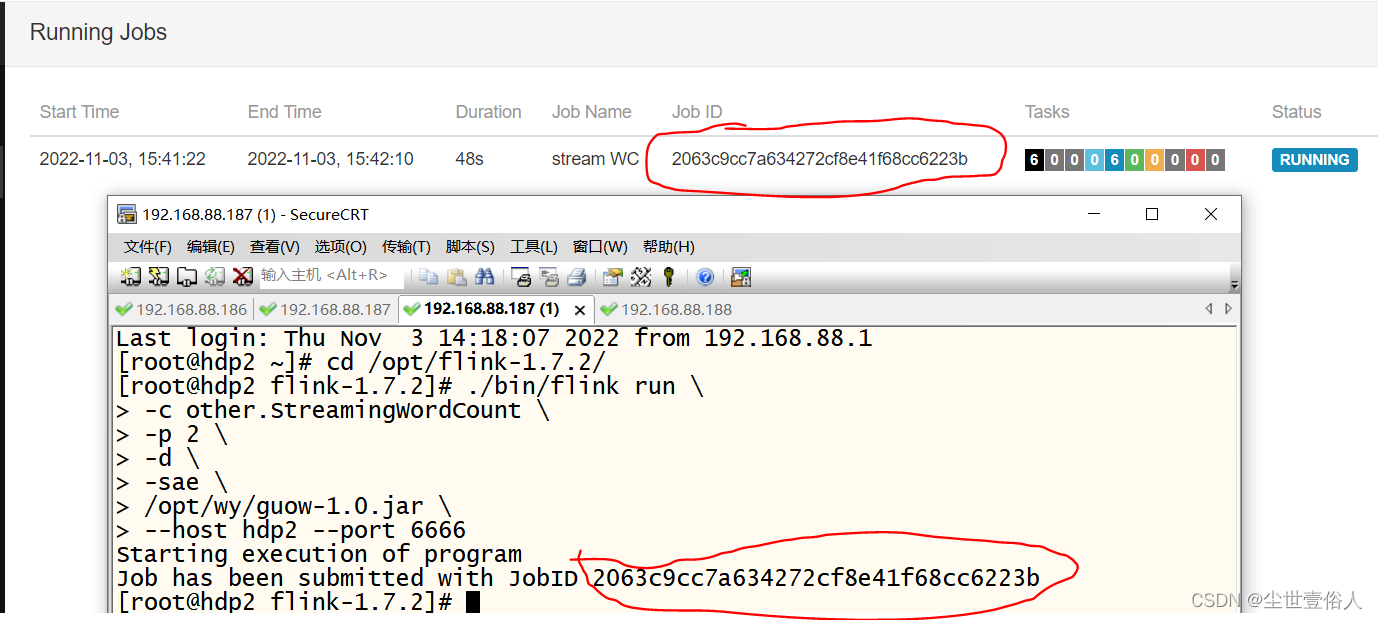
如果你要on yarn那在参数上就有些不同,你需要用如下参数
-m,–-jobmanager yarn模式
-yd,–-yarndetached 后台运行
-yjm,–-yarnjobManager jobmanager的内存
-ytm,–-yarntaskManager taskmanager的内存
-yn,–-yarncontainer TaskManager的个数
-yid,–-yarnapplicationId job依附的applicationId,一般不用,无实际使用意义
-ynm,–-yarnname application的名称
-ys,–-yarnslots 分配的slots个数
例:
./bin/flink run \-m yarn-cluster \-yjm 1024m \-ytm 1024m \-ys2\-c other.StreamingWordCount \
/opt/wy/guow-1.0.jar \192.168.88.187 6666
在服务器后台不报错,并提示任务
starting execution of progarm
就表示成功提交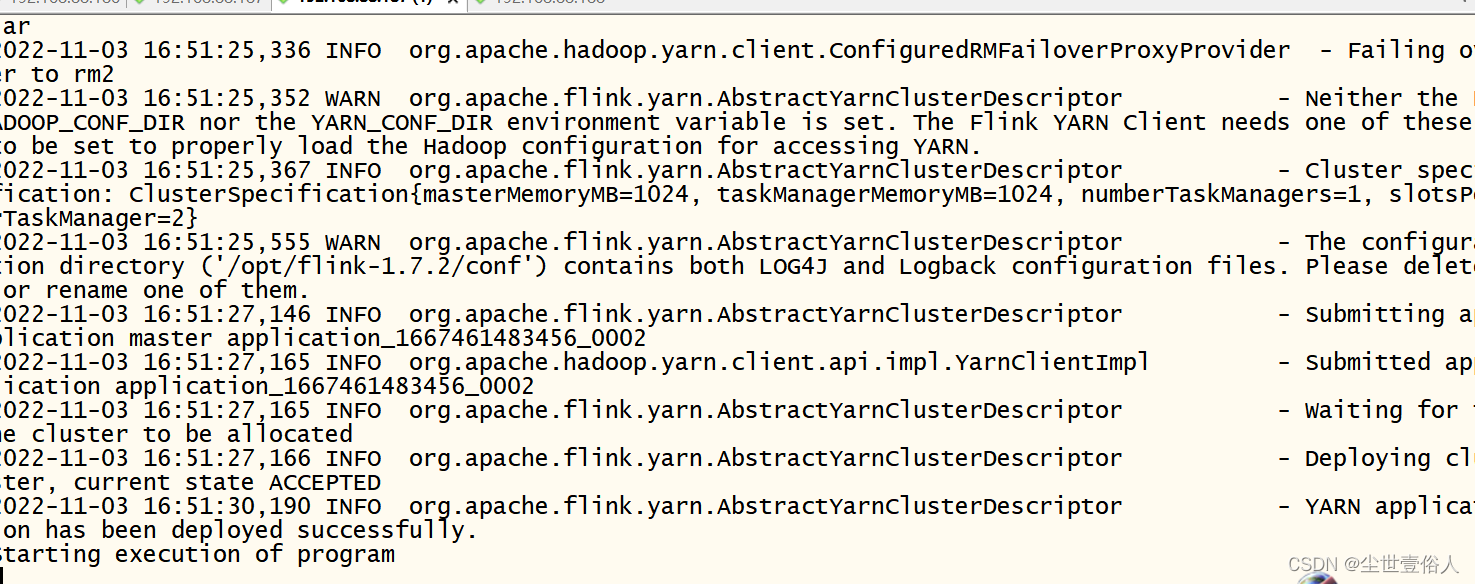
on yarn的时候flink自己的ui上是不显示任务的,你需要在yarn上看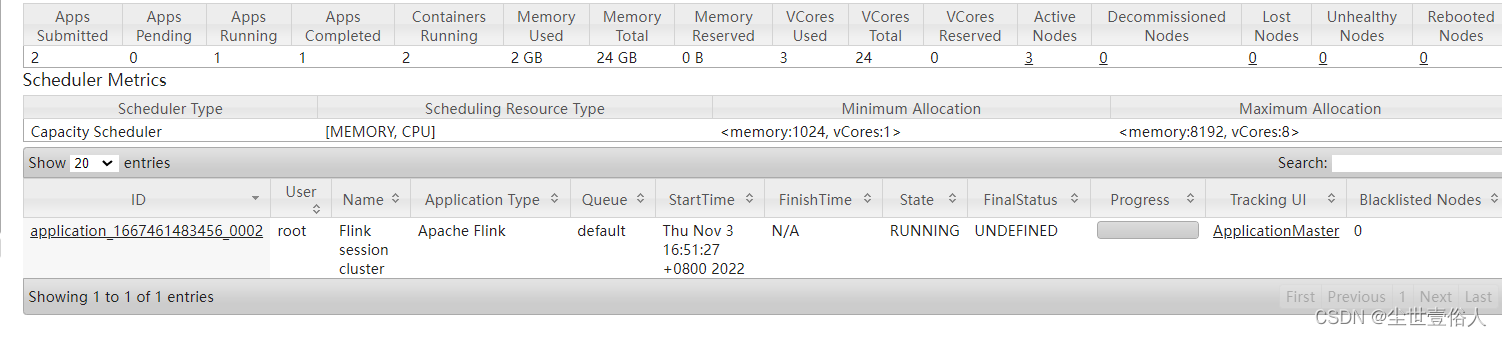
on yarn有个尴尬的点,你想结束一个任务需要在yarn上kill掉
当然flink这个脚本不止能用来提交命令,也有其他作用。
可以展示任务列表
flink list:列出flink的job列表。
flink list -r/--runing :列出正在运行的job
flink list -s/--scheduled :列出已调度完成的job
可以取消某个任务
flink cancel [options] <job_id> : 取消正在运行的任务
flink cancel -s/--withSavepoint <job_id> : 取消正在运行的任务,并保存检查点
如果要取消的任务再其他的jobmanager上可以通过-m只能目标jobmanager
bin/flink cancel -m 127.0.0.1:8081 5e20cb6b0f357591171dfcca2eea09de
可以停止某个任务
#stop只能操作流任务,同上支持-m参数
flink stop [options] <job_id>
flink stop <job_id>:停止对应的流任务
取消和停止的差别在于,取消是立刻执行,停止是优雅的
还可以用来修改并行度
flink modify <job_id> [options]
flink modify <job_id> -p/--parallelism 数量
例: flink modify -p 并行数 <job_pid>
如果提交的任务设置了savepointpath,就可以触发保存
保存
flink savepoint [options] <job_id>
将flink的快照保存到hdfs目录
flink savepoint <job_id> hdfs://xxxx/xx/x
使用yarn触发保存点
flink savepoint <job_id> <target_directory> -yid <application_id>
使用savepoint取消作业
flink cancel -s <tar_directory> <job_id>
从保存点恢复
flink run -s <target_directoey> [runArgs]
如果复原的程序,对逻辑做了修改,比如删除了算子可以指定allowNonRestoredState参数复原。
flink run -s <target_directory> -n/--allowNonRestoredState [runArgs]
常用的就是如上这些命令参数,其他的你可以通过flink --help去了解,都是一些不常用的。
最后说一点flink on yarn需要服务器配置hadoop的home
版权归原作者 尘世壹俗人 所有, 如有侵权,请联系我们删除。