
一、Flink-CDC 1.x 痛点
Flink CDC 1.x 使用 Debezium 引擎集成来实现数据采集,支持全量加增量模式,确保数据的一致性。然而,这种集成存在一些痛点需要注意:
- 一致性通过加锁保证:在保证数据一致性时,Debezium 需要对读取的库或表加锁。全局锁可能导致数据库出现挂起情况,而表级锁会影响表的写操作。
- 只支持单并发读取:Flink CDC 1.x版本只支持单并发读取,对于大表读取非常耗时。如果需要读取的数据量较大,可能会导致性能瓶颈。
- 全量读取阶段不支持 checkpoint:CDC 的initial模式下读取分为两个阶段,全量和增量。然而,在全量读取阶段,不支持 checkpoint 的功能。如果出现故障,必须重新进行全量读取操作。
1.1、全局锁
在 Flink CDC 1.x 中,全量读取时的锁机制流程如下:
- 开始全量读取:当 Flink CDC 启动全量读取任务时,它会与 MySQL 数据库建立连接,并开始读取源表的数据。
- 获取读取的锁:为了保证数据的一致性,Flink CDC 在全量读取过程中需要获取读取的锁。在默认情况下,Flink CDC 使用全局锁(Global Lock)来确保数据的一致性。
- 全局锁的获取:Flink CDC 通过向 MySQL 数据库发送命令来获取全局锁。全局锁将阻塞其他对源表进行写操作的事务,确保在全量读取期间不会有数据的变更。
- 全量读取数据:一旦获得全局锁,Flink CDC 开始进行全量读取。它会扫描源表的所有数据,并将其传输到目标系统(如 Doris)进行加载和处理。
- 释放全局锁:当全量读取完成后,Flink CDC 会释放全局锁,允许其他事务对源表进行写操作。
全局锁的获取可能会导致一些潜在的问题:
- 长时间锁定:全局锁通常需要在全量读取过程中长时间持有,这可能会对其他业务操作产生影响。如果全量读取任务的持续时间较长,其他事务可能需要等待较长时间才能执行读写操作。
- 性能影响:获取全局锁可能导致性能下降。当全局锁被获取时,其他事务需要等待锁的释放,这可能导致并发性下降,特别是在高负载的情况下。长时间的等待可能会导致数据库挂起(hang),影响整体系统的吞吐量和响应时间。
1.2、表级锁
在 Flink CDC 1.x 中,全量读取表时的表锁机制流程如下:
- 开始全量读取:当 Flink CDC 启动全量读取任务时,它会与 MySQL 数据库建立连接,并准备开始读取源表的数据。
- 获取表级锁:为了确保数据的一致性,在全量读取期间需要获取源表的表级锁。表级锁将阻塞其他事务对源表进行写操作,以保证读取过程中数据不会发生变化。
- 发起锁请求:Flink CDC 向 MySQL 数据库发送请求,尝试获取源表的表级锁。这个请求将被发送到 MySQL 的锁管理器。
- 等待锁释放:如果源表的表级锁已经被其他事务占用,Flink CDC 将等待锁释放的信号。在等待期间,Flink CDC 将一直保持连接并监测锁的状态。
- 获取锁成功:一旦源表的表级锁被成功获取,Flink CDC 可以开始进行全量数据的读取操作。它会扫描源表的所有数据,并将其传输到目标系统进行加载和处理。
- 释放表级锁:当全量读取完成后,Flink CDC 会释放源表的表级锁,允许其他事务对源表进行写操作。
表级锁的获取和释放可能会带来一些潜在的问题:
- 数据一致性问题:表级锁在全量读取期间会锁定整张表,以保证数据的一致性。然而,在某些情况下,如果全量读取过程中出现了长时间的阻塞或异常情况,可能会导致数据一致性问题。
- 长时间锁定:表级锁通常需要在读取过程中长时间持有,特别是在全量读取时。这可能会对其他事务产生长时间的阻塞,影响系统的响应性能。
二、Flink-CDC 2.x 新特性
Flink 2.x不仅引入了增量快照读取机制,还带来了一些其他功能的改进。以下是对Flink 2.x的主要功能的介绍:
- 增量快照读取:Flink 2.x引入了增量快照读取机制,这是一种全新的数据读取方式。该机制支持并发读取和以chunk为粒度进行checkpoint。在增量快照读取过程中,Flink首先根据表的主键将其划分为多个块(chunk),然后将这些块分配给多个读取器并行读取数据。这一机制极大地提高了数据读取的效率。
- 精确一次性处理:Flink 2.x引入了Exactly-Once语义,确保数据处理结果的精确一次性。MySQL CDC 连接器是Flink的Source连接器,可以利用Flink的checkpoint机制来确保精确一次性处理。
- 动态加表:Flink 2.x支持动态加表,通过使用savepoint来复用之前作业的状态,解决了动态加表的问题。
- 无主键表的处理:Flink 2.x对无主键表的读取和处理进行了优化。在无主键表中,Flink可以通过一些额外的字段来识别数据记录的唯一性,从而实现准确的数据读取和处理。
本文主要介绍了Flink 2.x引入的重要特性之一:增量快照读取机制。该机制带来了并发读取、chunk粒度的checkpoint等优势,提升了数据读取的效率。
三、增量快照读取机制
3.1、功能
增量快照读取基本功能:
- 并发读取:在增量快照读取期间,源(Source)可以支持并发读取。这意味着多个读取器可以同时读取数据,从而提高读取的速度和效率。
- Chunk级别的checkpoint:增量快照读取期间,源可以进行chunk级别的checkpoint。这意味着在读取过程中,可以对数据进行更细粒度的检查点,提高故障恢复的准确性和效率。
- 全量增量无锁读取算法:相比于旧的快照机制,全量快照读取不需要源具有数据库锁权限。这降低了对数据库的依赖和权限要求,简化了配置和部署的过程。
3.2、并发读取
增量快照读取的并行读取功能利用了Flink的Source并行度来控制源的并行度。你可以通过设置作业的并行度(parallelism.default)来实现。
在SQL CLI中,可以使用以下命令进行设置:
Flink SQL> SET 'parallelism.default'=4;
通过将并行度设置为4,Flink CDC Source算子将占用4个slot来并行读取数据。这样可以最大程度地利用系统资源,提高数据读取的效率和速度。
3.3、Chunk级别的checkpoint
3.3.1、Chunk
为了充分利用并行Source,MySQL CDC Source在增量快照读取过程中使用主键列将表划分为多个分片(chunk)。默认情况下,MySQL CDC Source会识别表的主键列,并使用主键中的第一列作为分片列。如果表中没有主键,增量快照读取将失败。你可以通过禁用
scan.incremental.snapshot.enabled
来回退到旧的快照读取机制。
对于数值和自动增量拆分列,MySQL CDC Source会按照固定步长高效地拆分块。例如,如果你有一个主键列为
id
的表,类型为自动增量的BIGINT,最小值为
0
,最大值为
100
,并设置表选项
scan.incremental.snapshot.chunk.size
的值为
25
,那么表将被拆分为以下块:
(-∞, 25),
[25, 50),
[50, 75),
[75, 100),
[100, +∞)
对于其他类型的主键列,MySQL CDC Source执行类似以下形式的语句来获取每个块的低值和高值:
SELECT MAX(STR_ID) AS chunk_high FROM (SELECT * FROM TestTable WHERE STR_ID > 'uuid-001' limit 25)
,然后将块集分割如下:
(-∞, 'uuid-001'),
['uuid-001', 'uuid-009'),
['uuid-009', 'uuid-abc'),
['uuid-abc', 'uuid-def'),
[uuid-def, +∞).
通过这种分片方式,MySQL CDC Source可以高效地划分表数据,以实现并行的增量快照读取。每个读取器将负责读取和处理一个或多个分片的数据,从而提高整体的读取性能和效率。
注意,
scan.incremental.snapshot.chunk.size
的默认值为
8096
3.3.2、原理
在 Flink CDC 中实现 Chunk 级别的 checkpoint 本质是使用 Flink 的 Checkpointing 机制和相应的配置,启用 Chunk 级别的 checkpoint 后,Flink CDC 将在每个 Chunk 完成读取后进行一次 checkpoint,以确保数据的一致性和容错性。
注意,Flink 的 checkpoint 机制包括两种类型的 checkpoint:时间驱动和计数驱动。但Flink CDC 中 Chunk 级别的 checkpoint 并不是直接利用Flink 计数驱动的 checkpoint 来实现的,相反,它是 Flink CDC 根据自身的机制自己实现的。它提供了在每个 Chunk 完成读取时进行一次 checkpoint 的能力,以实现更细粒度的数据一致性和容错性保障。
3.4、全量增量无锁读取算法【重点】
3.4.1、原理
3.4.1.1、全量无锁读取算法流程
- 首先,FlinkCDC 会先根据主键和粒度将要读取的表划分为多个分片(chunk)。
- 每个 MySQL CDC Source 负责读取一个分片,多个Source 可以并发读取多个chunk,完成当前分片处理后才可以读取下一个分片,直到读取完所有分片。
- 在读取每个分片时,FlinkCDC 使用一种名为偏移信号算法的方法来获取快照区块的最终一致输出。以下是该算法的简要步骤:- (1) 在读取chunk数据前先记录当前的 binlog 位置,即
LOW偏移量。- (2) 执行语句SELECT * FROM MyTable WHERE id > chunk_low AND id <= chunk_high,读取chunk分片内的数据并缓存至快照区块。- (3) 读取完chunk后再次记录当前的 binlog 位置记录,即HIGH偏移量,如下图: - (4) 读取binlog:从
- (4) 读取binlog:从 LOW偏移量到HIGH偏移量之间的 binlog 记录,读取到的数据 append 到上个队列后面,并将此时binlog的最终offset保存至最后,如下图: - (5) 检查读取到的 binlog 每条记录,如果属于chunk分片范围,则对之前缓存的chunk队列里的数据进行修正,最后将修正后的记录作为快照区块的最终输出,如下图:
- (5) 检查读取到的 binlog 每条记录,如果属于chunk分片范围,则对之前缓存的chunk队列里的数据进行修正,最后将修正后的记录作为快照区块的最终输出,如下图: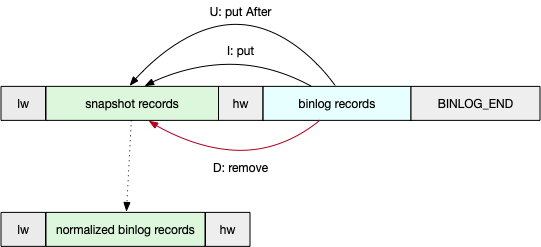 - (6) 将此次chunk的元信息【lw,hw等】保存至
- (6) 将此次chunk的元信息【lw,hw等】保存至MySqlSourceReader进行备份【checkponit阶段也会保存此数据】,为后续增量读取做准备。 - 当所有chunk都被消费完毕后,即全量阶段同步完毕,此时将结束Source的并发读取,改为单线程读取binlog日志进行后续同步,此步骤在3.4.1.2、增量无锁读取算法流程。
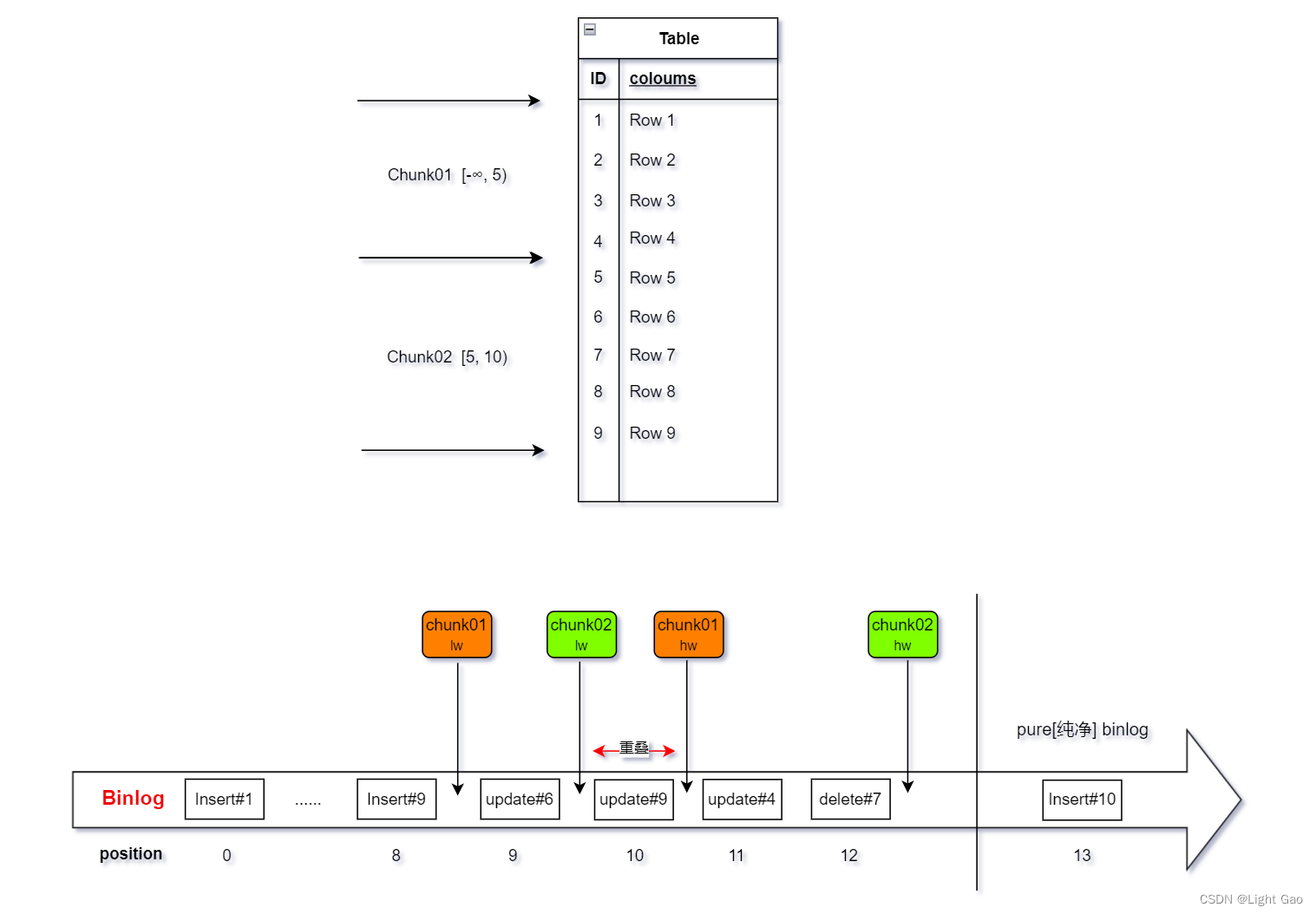
- 为了方便理解举例:表当前总数据为9条,Chunk切分粒度
scan.incremental.snapshot.chunk.size=5;作业的并发数为2,故Mysql CDC Source 会有两个Task并行读取Chunk01,Chunk02,读取过程如下:
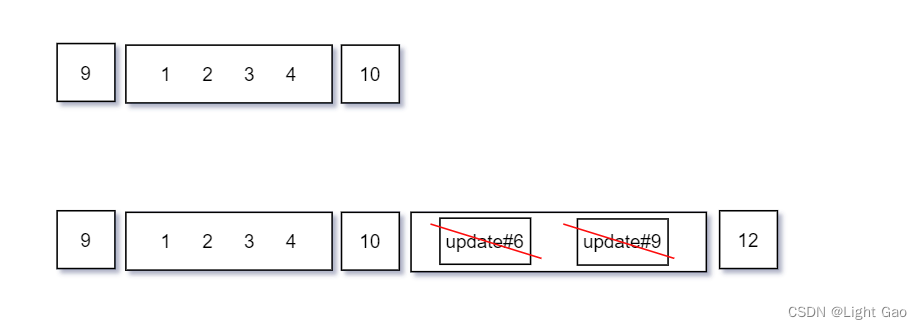
- chunk01的数据流转过程如下:由于update#6、update#9 不属于chunk01分片范围故不做处理。
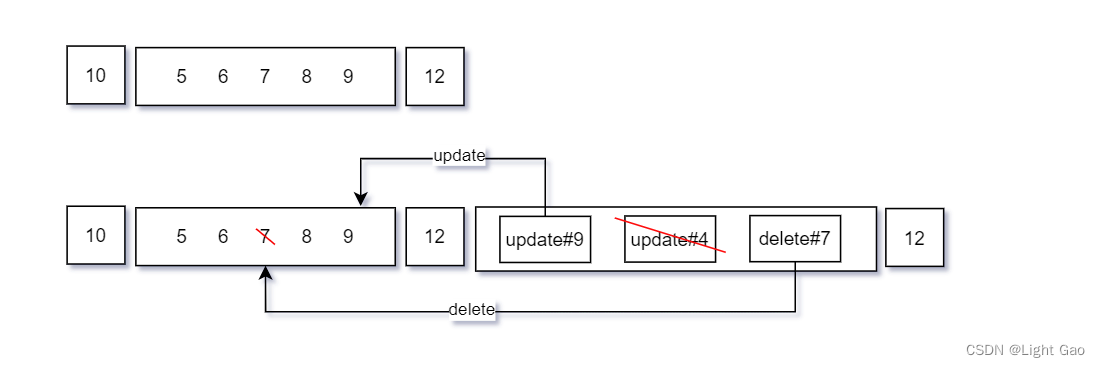
- chunk02的数据流转过程如下:update#9、delete#7属于切片范围故修正缓存数据,而 update#4 不属于chunk02分片范围故不做处理。
FAQ[常见问题]:
- chunk01 与 chunk02阶段有重叠部分,即 update#9,是否会影响数据准确性?- 答:不会,因为chunk只会对属于该分片范围的数据进行处理,故不会重复执行。
- chunk01 与 chunk02 均未处理 update#4 日志,是否会影响数据准确性?- 答:不会,因为当所有chunk阶段结束后,
MySqlSourceEnumerator调查员会根据所有chunk中的min(lw) 再次读取binlog,选择性补全数据,具体细节在:3.4.1.2、增量无锁读取算法流程 - chun02 没有读取update#6的日志,是否会影响数据准确性?- 答:不会,因为update#6的日志 < lw,说明chunk02在lw时已经读取到了update#6后的最新数据,故不会影响数据准确性。
3.4.1.2、增量无锁读取算法流程
- 当全量阶段同步完毕后,
MySqlSourceReader会将每个 chunk 的 lw,hw等元数据汇报给MySqlSourceEnumerator调查员,如下图:
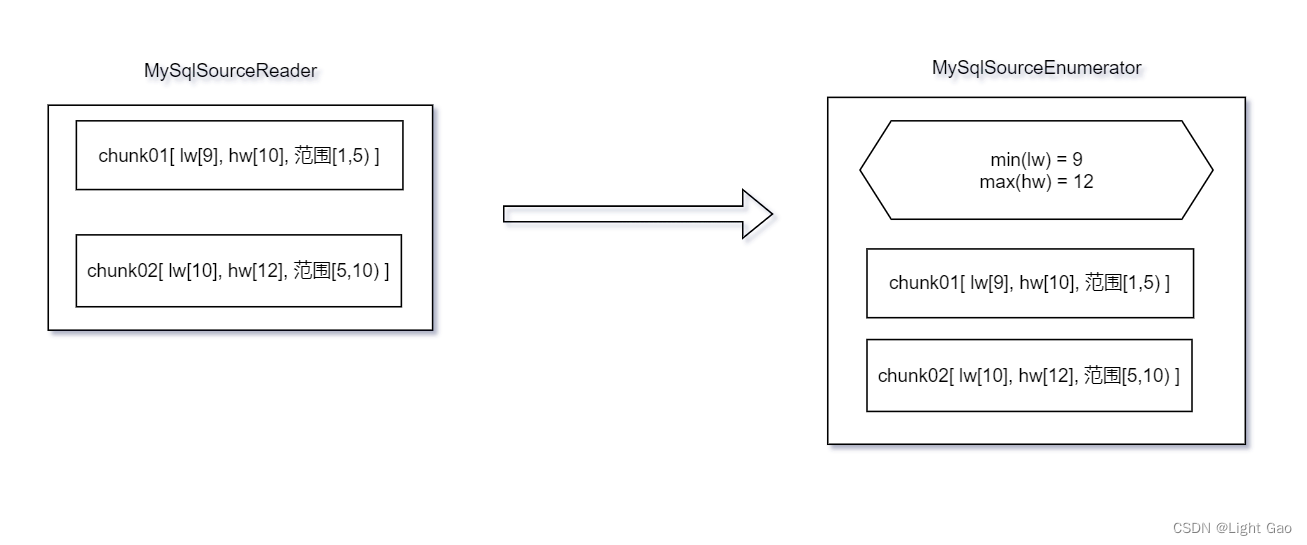
MySqlSourceEnumerator调查员取所有chunk中最小的lw 作为offset 来读取binlog日志,如下图: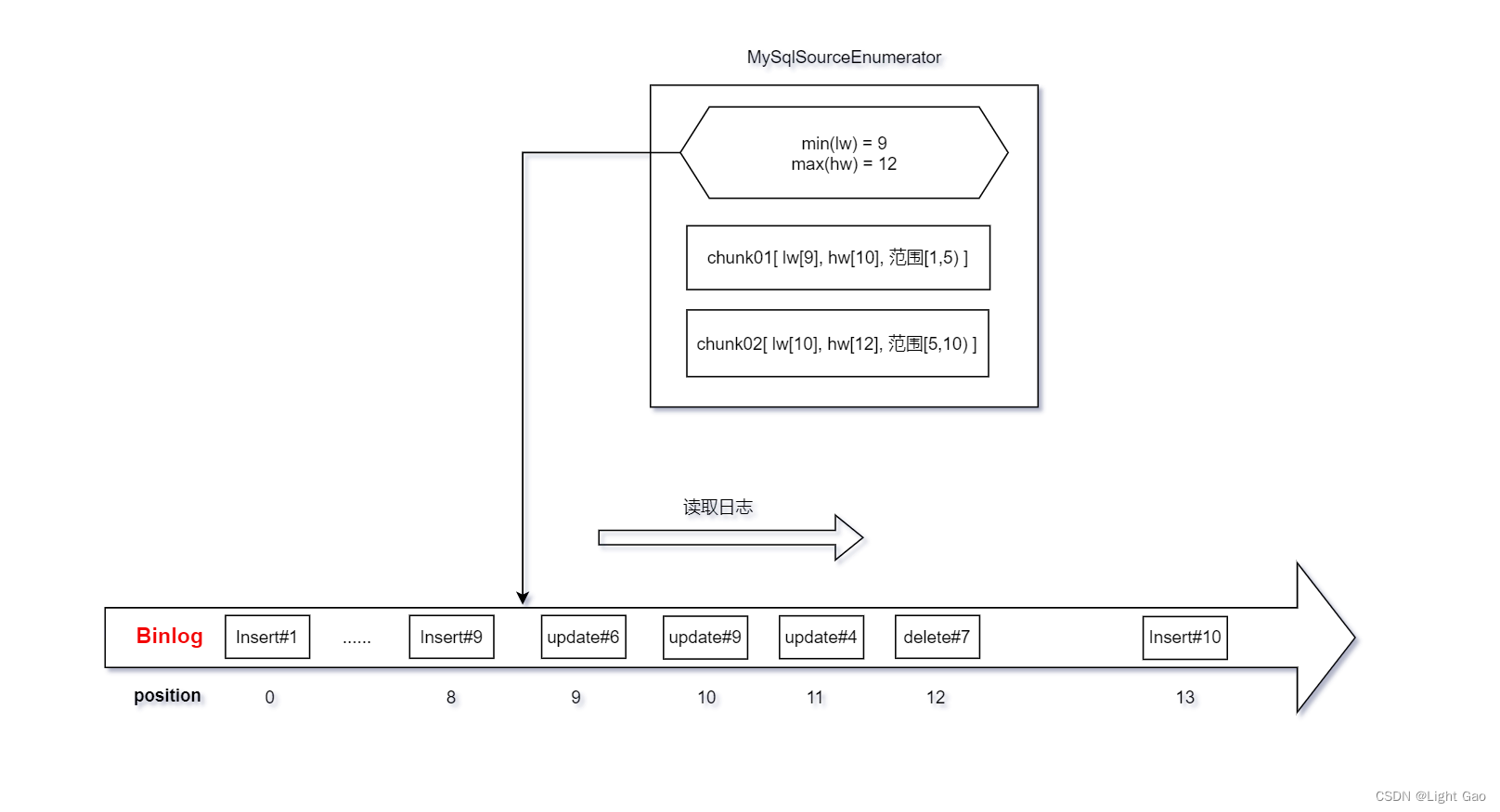
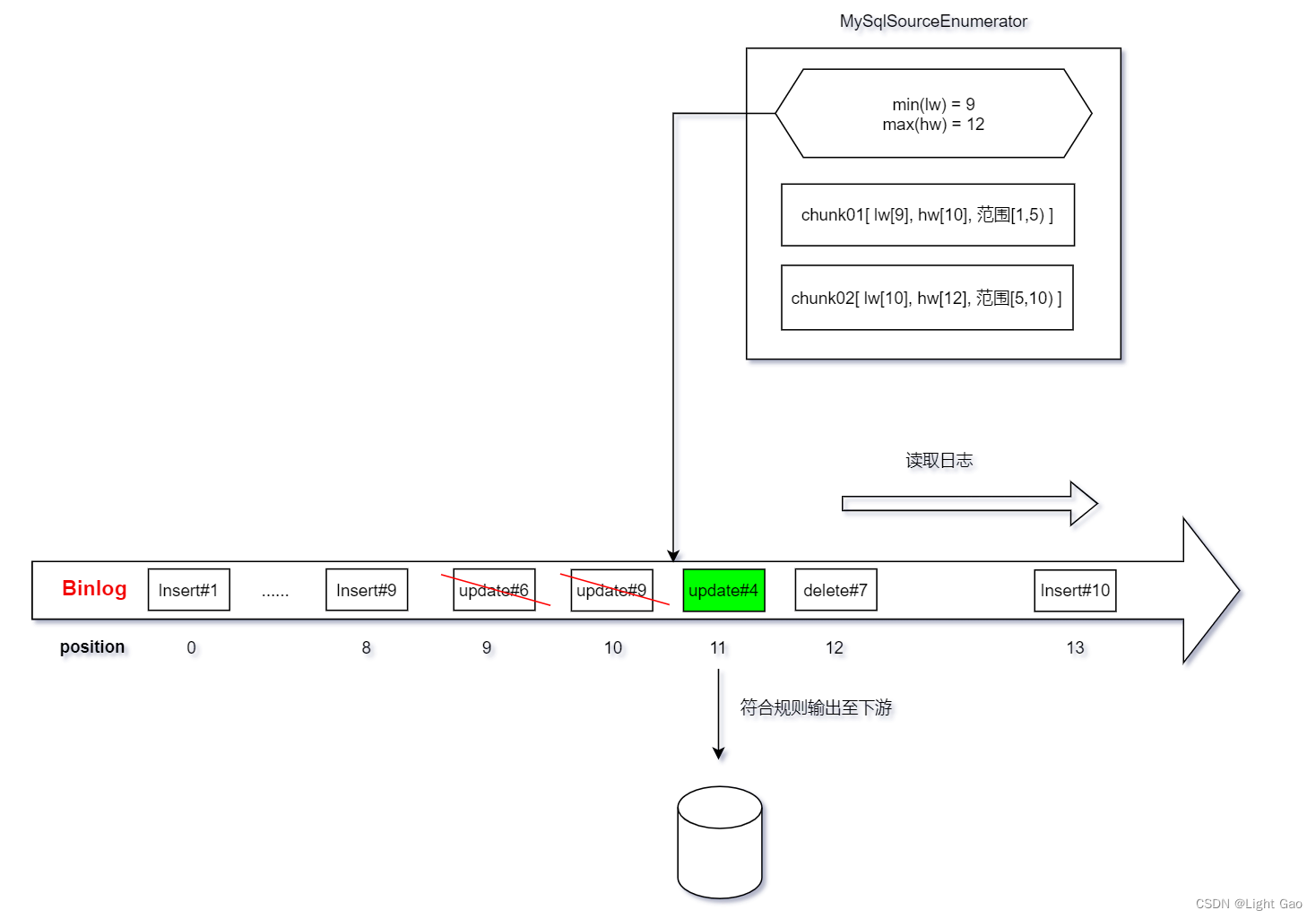
- 当一个 binlog 记录属于一个分片的主键范围内时,如果该记录在这个分片的 hw 之后,则该记录应该发送给下游,如下图:update#6、update#9虽然数据chunk02分片范围但<=hw 故舍弃;而update#4属于chunk01分片范围 且 >hw 代表缺失该条记录故发送至下游。
- 当一个 binlog 记录已经处于所有chunk中最大的hw时,即表示日志记录已经进入 Pure Binlog Phase,对于这样的 binlog 记录,不需进行比较,直接发送给下游,如下图:
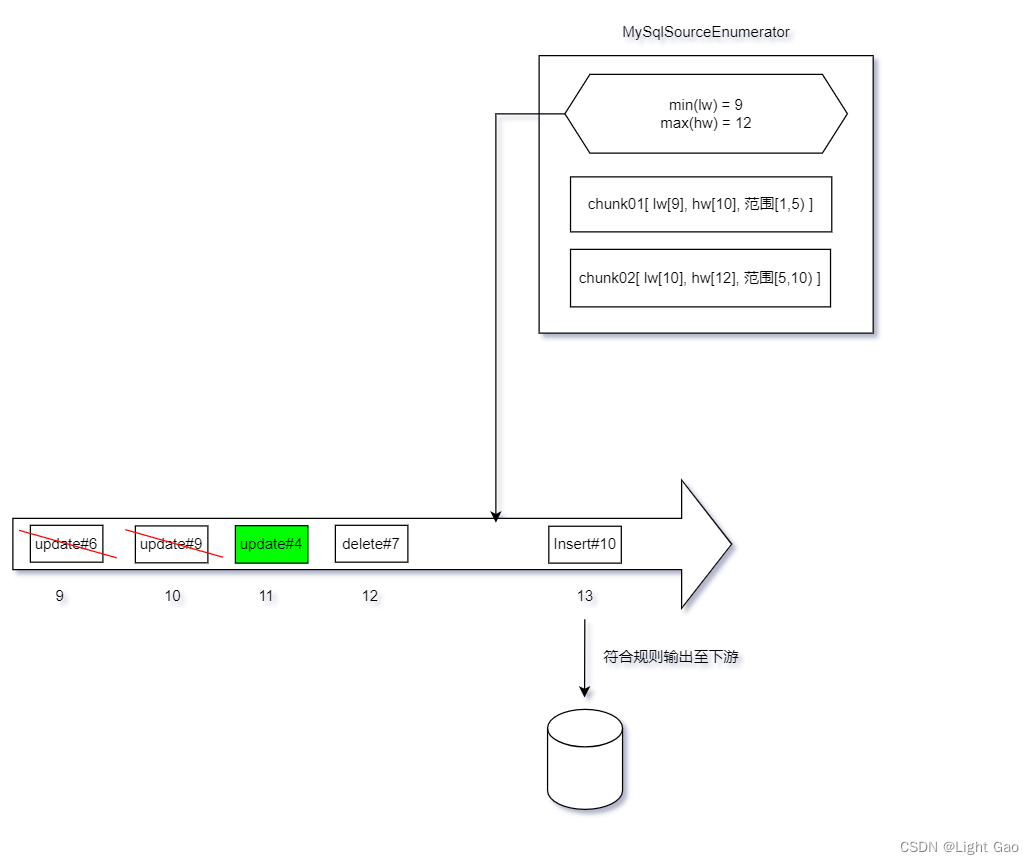
至此增量无锁读取算法流程完毕
3.4.2、源码分析
- MySql cdc 类图关系如下:

- 快照读取chunk分片逻辑:MySqlSnapshotSplitReadTask#doExecute
protectedSnapshotResultdoExecute(ChangeEventSourceContext context,SnapshotContext snapshotContext,SnapshottingTask snapshottingTask)throwsException{finalRelationalSnapshotChangeEventSource.RelationalSnapshotContext ctx =(RelationalSnapshotChangeEventSource.RelationalSnapshotContext) snapshotContext;
ctx.offset = offsetContext;finalSignalEventDispatcher signalEventDispatcher =newSignalEventDispatcher(
offsetContext.getPartition(),
topicSelector.topicNameFor(snapshotSplit.getTableId()),
dispatcher.getQueue());finalBinlogOffset lowWatermark =currentBinlogOffset(jdbcConnection);LOG.info("Snapshot step 1 - Determining low watermark {} for split {}",
lowWatermark,
snapshotSplit);((SnapshotSplitReader.SnapshotSplitChangeEventSourceContextImpl)(context)).setLowWatermark(lowWatermark);
signalEventDispatcher.dispatchWatermarkEvent(
snapshotSplit, lowWatermark,SignalEventDispatcher.WatermarkKind.LOW);LOG.info("Snapshot step 2 - Snapshotting data");createDataEvents(ctx, snapshotSplit.getTableId());finalBinlogOffset highWatermark =currentBinlogOffset(jdbcConnection);LOG.info("Snapshot step 3 - Determining high watermark {} for split {}",
highWatermark,
snapshotSplit);
signalEventDispatcher.dispatchWatermarkEvent(
snapshotSplit, highWatermark,SignalEventDispatcher.WatermarkKind.HIGH);((SnapshotSplitReader.SnapshotSplitChangeEventSourceContextImpl)(context)).setHighWatermark(highWatermark);returnSnapshotResult.completed(ctx.offset);}
- chunk分片数据读取后进行格式处理归一逻辑:RecordUtils#normalizedSplitRecords
/**
* Normalize the records of snapshot split which represents the split records state on high
* watermark. data input: [low watermark event] [snapshot events ] [high watermark event]
* [binlog events] [binlog-end event] data output: [low watermark event] [normalized events]
* [high watermark event]
*/publicstaticList<SourceRecord>normalizedSplitRecords(MySqlSnapshotSplit snapshotSplit,List<SourceRecord> sourceRecords,SchemaNameAdjuster nameAdjuster){List<SourceRecord> normalizedRecords =newArrayList<>();Map<Struct,SourceRecord> snapshotRecords =newHashMap<>();List<SourceRecord> binlogRecords =newArrayList<>();if(!sourceRecords.isEmpty()){SourceRecord lowWatermark = sourceRecords.get(0);checkState(isLowWatermarkEvent(lowWatermark),String.format("The first record should be low watermark signal event, but is %s",
lowWatermark));SourceRecord highWatermark =null;int i =1;for(; i < sourceRecords.size(); i++){SourceRecord sourceRecord = sourceRecords.get(i);if(!isHighWatermarkEvent(sourceRecord)){
snapshotRecords.put((Struct) sourceRecord.key(), sourceRecord);}else{
highWatermark = sourceRecord;
i++;break;}}if(i < sourceRecords.size()-1){List<SourceRecord> allBinlogRecords =
sourceRecords.subList(i, sourceRecords.size()-1);for(SourceRecord binlog : allBinlogRecords){if(isDataChangeRecord(binlog)){Object[] key =getSplitKey(snapshotSplit.getSplitKeyType(), binlog, nameAdjuster);// 当获取chunk lw hw 的binlog后会先判断是否数据chunk的区间内,只有负责chunk区间内的数据才会被更正if(splitKeyRangeContains(
key, snapshotSplit.getSplitStart(), snapshotSplit.getSplitEnd())){
binlogRecords.add(binlog);}}}}checkState(isHighWatermarkEvent(highWatermark),String.format("The last record should be high watermark signal event, but is %s",
highWatermark));// chunk数据修正逻辑函数:upsertBinlog
normalizedRecords =upsertBinlog(
snapshotSplit,
lowWatermark,
highWatermark,
snapshotRecords,
binlogRecords);}return normalizedRecords;}
- chunk数据修正逻辑:RecordUtils#upsertBinlog
privatestaticList<SourceRecord>upsertBinlog(MySqlSplit split,SourceRecord lowWatermarkEvent,SourceRecord highWatermarkEvent,Map<Struct,SourceRecord> snapshotRecords,List<SourceRecord> binlogRecords){finalList<SourceRecord> normalizedBinlogRecords =newArrayList<>(); normalizedBinlogRecords.add(lowWatermarkEvent);// upsert binlog events to snapshot events of splitif(!binlogRecords.isEmpty()){for(SourceRecord binlog : binlogRecords){Struct key =(Struct) binlog.key();Struct value =(Struct) binlog.value();if(value !=null){Envelope.Operation operation =Envelope.Operation.forCode( value.getString(Envelope.FieldName.OPERATION));switch(operation){caseUPDATE:Envelope envelope =Envelope.fromSchema(binlog.valueSchema());Struct source = value.getStruct(Envelope.FieldName.SOURCE);Struct updateAfter = value.getStruct(Envelope.FieldName.AFTER);Instant ts =Instant.ofEpochMilli((Long) source.get(Envelope.FieldName.TIMESTAMP));SourceRecord record =newSourceRecord( binlog.sourcePartition(), binlog.sourceOffset(), binlog.topic(), binlog.kafkaPartition(), binlog.keySchema(), binlog.key(), binlog.valueSchema(), envelope.read(updateAfter, source, ts)); snapshotRecords.put(key, record);break;caseDELETE: snapshotRecords.remove(key);break;caseCREATE: snapshotRecords.put(key, binlog);break;caseREAD:thrownewIllegalStateException(String.format("Binlog record shouldn't use READ operation, the the record is %s.", binlog));}}}} normalizedBinlogRecords.addAll(snapshotRecords.values()); normalizedBinlogRecords.add(highWatermarkEvent);return normalizedBinlogRecords;} - 全量快照结束后MySqlSourceReader 整合各个split,汇报给MySqlSourceEnumerator逻辑:handleSourceEvents
@OverridepublicvoidhandleSourceEvents(SourceEvent sourceEvent){if(sourceEvent instanceofFinishedSnapshotSplitsAckEvent){FinishedSnapshotSplitsAckEvent ackEvent =(FinishedSnapshotSplitsAckEvent) sourceEvent;LOG.debug("The subtask {} receives ack event for {} from enumerator.",
subtaskId,
ackEvent.getFinishedSplits());for(String splitId : ackEvent.getFinishedSplits()){this.finishedUnackedSplits.remove(splitId);}}elseif(sourceEvent instanceofFinishedSnapshotSplitsRequestEvent){// report finished snapshot splitsLOG.debug("The subtask {} receives request to report finished snapshot splits.",
subtaskId);reportFinishedSnapshotSplitsIfNeed();}elseif(sourceEvent instanceofBinlogSplitMetaEvent){LOG.debug("The subtask {} receives binlog meta with group id {}.",
subtaskId,((BinlogSplitMetaEvent) sourceEvent).getMetaGroupId());fillMetaDataForBinlogSplit((BinlogSplitMetaEvent) sourceEvent);}else{super.handleSourceEvents(sourceEvent);}}privatevoidreportFinishedSnapshotSplitsIfNeed(){if(!finishedUnackedSplits.isEmpty()){finalMap<String,BinlogOffset> finishedOffsets =newHashMap<>();for(MySqlSnapshotSplit split : finishedUnackedSplits.values()){
finishedOffsets.put(split.splitId(), split.getHighWatermark());}FinishedSnapshotSplitsReportEvent reportEvent =newFinishedSnapshotSplitsReportEvent(finishedOffsets);
context.sendSourceEventToCoordinator(reportEvent);LOG.debug("The subtask {} reports offsets of finished snapshot splits {}.",
subtaskId,
finishedOffsets);}}
- MySqlSourceEnumerator 收到全量快照结束后处理逻辑:createBinlogSplit
当 MySqlSourceEnumerator 将所有 split 的 hw 收齐之后,会创建一个 binlog split,该分片包含了需要读取 binlog 的起始位置(所有分片 hw 的最小值)和所有分片的 hw 信息。
privateMySqlBinlogSplitcreateBinlogSplit(){finalList<MySqlSnapshotSplit> assignedSnapshotSplit =
snapshotSplitAssigner.getAssignedSplits().values().stream().sorted(Comparator.comparing(MySqlSplit::splitId)).collect(Collectors.toList());Map<String,BinlogOffset> splitFinishedOffsets =
snapshotSplitAssigner.getSplitFinishedOffsets();finalList<FinishedSnapshotSplitInfo> finishedSnapshotSplitInfos =newArrayList<>();BinlogOffset minBinlogOffset =null;for(MySqlSnapshotSplit split : assignedSnapshotSplit){// find the min binlog offsetBinlogOffset binlogOffset = splitFinishedOffsets.get(split.splitId());if(minBinlogOffset ==null|| binlogOffset.isBefore(minBinlogOffset)){
minBinlogOffset = binlogOffset;}
finishedSnapshotSplitInfos.add(newFinishedSnapshotSplitInfo(
split.getTableId(),
split.splitId(),
split.getSplitStart(),
split.getSplitEnd(),
binlogOffset));}// the finishedSnapshotSplitInfos is too large for transmission, divide it to groups and// then transfer themboolean divideMetaToGroups = finishedSnapshotSplitInfos.size()> splitMetaGroupSize;returnnewMySqlBinlogSplit(BINLOG_SPLIT_ID,
minBinlogOffset ==null?BinlogOffset.INITIAL_OFFSET: minBinlogOffset,BinlogOffset.NO_STOPPING_OFFSET,
divideMetaToGroups ?newArrayList<>(): finishedSnapshotSplitInfos,newHashMap<>(),
finishedSnapshotSplitInfos.size());}
- 增量阶段逻辑:shouldEmit
当
MySqlSourceEnumerator
将 binlog 分片分配给
MySqlSourceReader
时,任务从全量阶段转变为增量阶段。
MySqlSourceReader
在读取 binlog 数据后,使用
shouldEmit
来判断是否应该将该记录发送给下游。
/**
* Returns the record should emit or not.
*
* <p>The watermark signal algorithm is the binlog split reader only sends the binlog event that
* belongs to its finished snapshot splits. For each snapshot split, the binlog event is valid
* since the offset is after its high watermark.
*
* <pre> E.g: the data input is :
* snapshot-split-0 info : [0, 1024) highWatermark0
* snapshot-split-1 info : [1024, 2048) highWatermark1
* the data output is:
* only the binlog event belong to [0, 1024) and offset is after highWatermark0 should send,
* only the binlog event belong to [1024, 2048) and offset is after highWatermark1 should send.
* </pre>
*/privatebooleanshouldEmit(SourceRecord sourceRecord){if(isDataChangeRecord(sourceRecord)){TableId tableId =getTableId(sourceRecord);BinlogOffset position =getBinlogPosition(sourceRecord);// 判断是否处于纯净的binlog区域if(hasEnterPureBinlogPhase(tableId, position)){returntrue;}// only the table who captured snapshot splits need to filterif(finishedSplitsInfo.containsKey(tableId)){RowType splitKeyType =ChunkUtils.getSplitType(
statefulTaskContext.getDatabaseSchema().tableFor(tableId));Object[] key =getSplitKey(
splitKeyType,
sourceRecord,
statefulTaskContext.getSchemaNameAdjuster());for(FinishedSnapshotSplitInfo splitInfo : finishedSplitsInfo.get(tableId)){if(RecordUtils.splitKeyRangeContains(
key, splitInfo.getSplitStart(), splitInfo.getSplitEnd())&& position.isAfter(splitInfo.getHighWatermark())){// 判断该binlog是否属于chunk区间且是否>该chunk的hwreturntrue;}}}// not in the monitored splits scope, do not emitreturnfalse;}// always send the schema change event and signal event// we need record them to state of Flinkreturntrue;}privatebooleanhasEnterPureBinlogPhase(TableId tableId,BinlogOffset position){// the existed tables those have finished snapshot readingif(maxSplitHighWatermarkMap.containsKey(tableId)&& position.isAtOrAfter(maxSplitHighWatermarkMap.get(tableId))){returntrue;}// capture dynamically new added tables// TODO: there is still very little chance that we can't capture new added table.// That the tables dynamically added after discovering captured tables in enumerator// and before the lowest binlog offset of all table splits. This interval should be// very short, so we don't support it for now.return!maxSplitHighWatermarkMap.containsKey(tableId)&& capturedTableFilter.isIncluded(tableId);}
四、相关文档
- 官方文档
- Flink CDC 设计文档
- FAQ
版权归原作者 Light Gao 所有, 如有侵权,请联系我们删除。