
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
反向传播是神经网络通过调整神经元的权重和偏差来最小化其预测输出误差的过程。但是这些变化是如何发生的呢?如何计算隐藏层中的误差?微积分和这些有什么关系?在本文中,你将得到所有问题的回答。让我们开始吧。
在了解反向传播的细节之前,让我们先浏览一下整个神经网络学习过程:
神经网络是如何进行学习的?
神经网络中的学习过程分为三个步骤。
第 1 步:将数据输入神经网络。该输入数据顺序通过神经网络的不同层,并在最终输出层产生输出或预测。数据从输入层流向输出层的整个过程称为前向传播。我们将在下面看到前向传播的细节。
第 2 步:现在有了输出,我们计算输出中的损失。我们有很多计算损失的选项,例如均方误差、二元交叉熵等,如何计算损失是根据不同的目标来定义的。
第 3 步:计算损失后,我们必须告诉神经网络如何改变它的参数(权重和偏差)以最小化损失。这个过程称为反向传播。
神经网络中的前向传播
NN 基本上由三种类型的层组成。输入层、隐藏层和输出层。通过 NN 的数据流是这样的:
- 数据第一次在网络中向前流动时,将需要训练神经网络的输入或特征输入到输入层的神经元中。
- 然后这些输入值通过隐藏层的神经元,首先乘以神经元中的权重,然后加上一个偏差。我们可以称之为预激活函数。
- 预激活函数之后就是激活函数。有很多激活函数,例如 sigmoid、tanh、relu 等,激活函数的作用是加入非线性的因素。
- 最后一层是输出层,其中显示了神经网络的计算输出。
损失函数
当输入通过向前传播产生输出后,我们可以在输出中找出误差。误差是预测输出和期望的真实值之间的差异。但在神经网络中通常不计算输出中的误差,而是使用特定的损失函数来计算损失,并随后在优化算法中使用该函数来将损失降低到最小值。
计算损失的方法有很多,如均方误差、二元交叉熵等。这些使用那个损失是根据我们要解决的问题来选择的。
梯度下降算法
反向传播的全部思想是最小化损失。我们有很多优化算法来做到这一点。但为了简单起见,让我们从一个基本但强大的优化算法开始,梯度下降算法。
这里的想法是计算相对于每个参数的损失变化率,并在减少损失的方向上修改每个参数。任何参数的变化都会导致损失发生改变。如果变化为负,那么我们需要增加权重以减少损失,而如果变化为正,我们需要减少权重。我们可以用数学方式将其写为,
new_weight = old_weight - learning_rate * gradient
其中梯度是损失函数相对于权重的偏导数。学习率只是一个缩放因子,用于放大或缩小梯度。在接下来的文本中更详细地解释了它。相同的公式适用于偏差:
new_bias = old_bias - learning_rate * gradient
其中梯度是损失函数相对于偏差的偏导数。
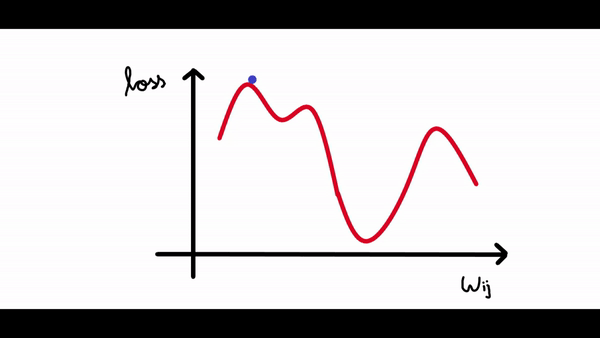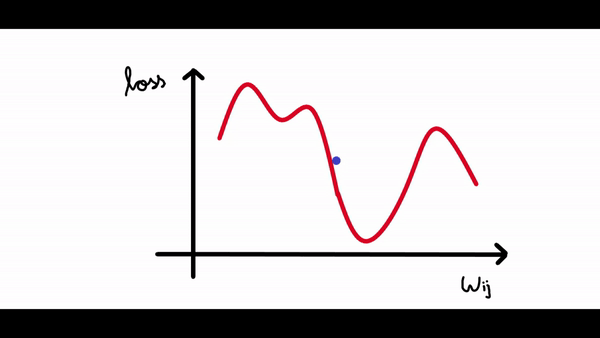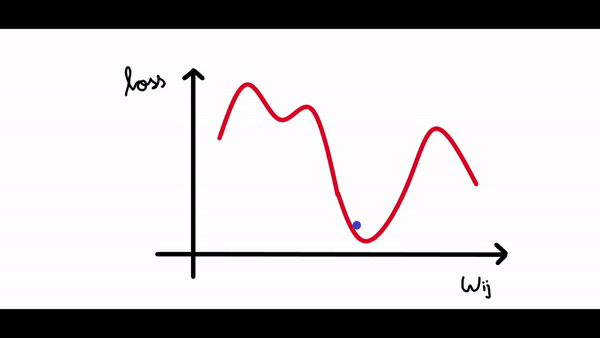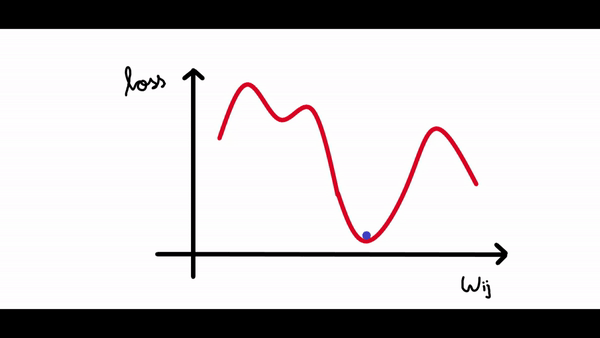
看看下面的图表。我们绘制了神经网络的损失与单个神经元权重变化的关系图。
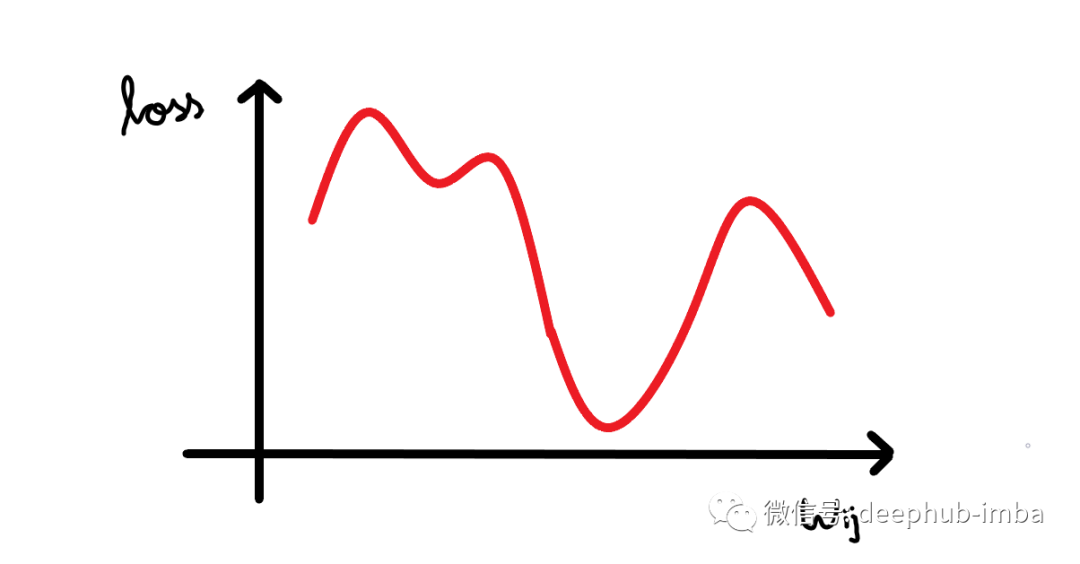
现在我们可以看到曲线中有很多局部最小值(所有下凹曲线),但我们感兴趣的是将损失降低到全局最小值(最大的下凹曲线)。假设我们的权重值现在接近示例图中的原点(假设为 1,因此我们的损失接近 4)。
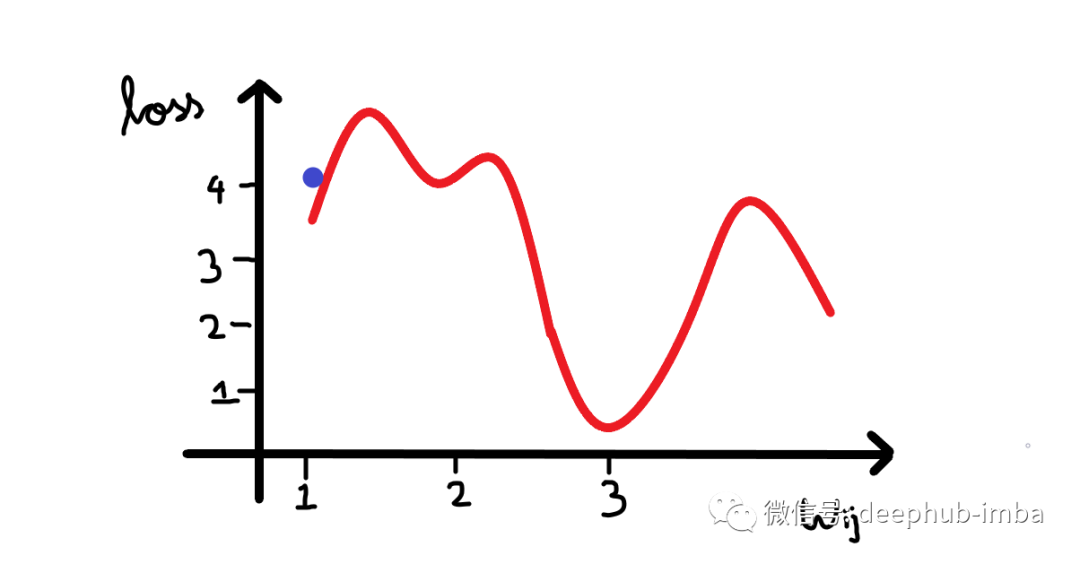
在上图中权重值约为3的时候损失最小。
所以我们的算法必须能够找到这个权重值(3),来使得损失最小。所以权重的改变应该与损失成某个比例。这就是为什么梯度是由损失相对于权重的偏导数给出的。所以梯度下降算法的步骤是:
- 计算梯度(损失函数相对于权重/偏差的偏导数)
- 梯度乘以学习速率。
- 然后从权重/偏差中减去梯度乘以学习速率。
对以上操作进行迭代,直到损失收敛到全局最小值。
关于梯度的更多信息
由于直线的斜率可以使用通用斜率公式计算:
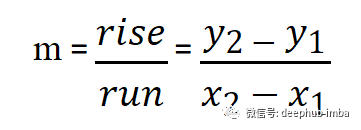
取直线上相距一定距离的两点,计算斜率。当图形是一条直线时,这种计算梯度的方法给出了精确的计算。但是当我们有不均匀的曲线时,使用这种方式计算梯度一个好主意。因为这些图中的每个点的损失都在不断变化,尤其是当曲线不规则时,如果我们可以使我们计算斜率的邻域或距离无限小呢?这样不就可以计算最准确的梯度值了吗?
对,这正是通过计算 y 相对于 x 的导数所做的。这为我们提供了 y 相对于 x 的瞬时变化率。瞬时变化率为我们提供了比我们之前的运行递增法方更精确的梯度,因为这个梯度是瞬时的。在计算相对于权重或偏差的损失变化率时,应遵循相同的方法。损失函数相对于权重的导数为我们提供了损失相对于权重的瞬时变化率。
学习率
在计算完梯度之后需要一些东西来缩放梯度。因为有时候神经网络试图朝着损耗曲线的最低点前进时,它可能会在每次调整其权重时采取很大的调整,调整过大可能永远不会真正收敛到全局最小值。你可以在下面的图表中看到:
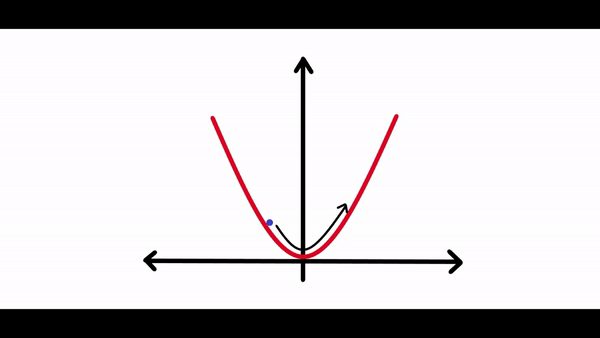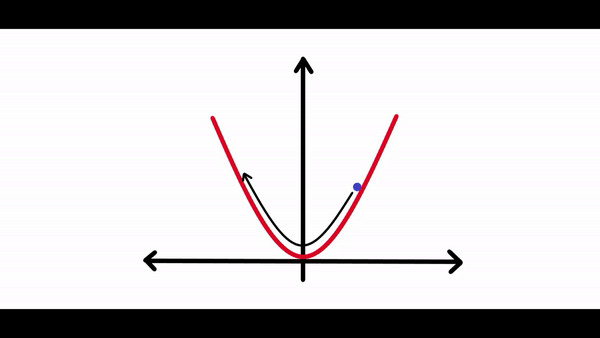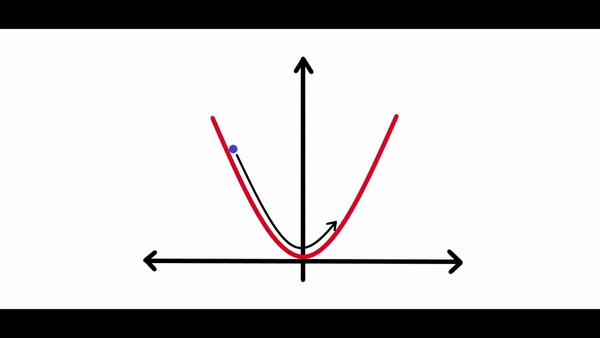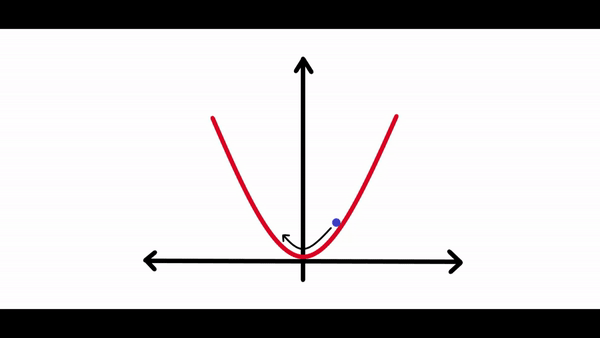
正如你所看到的,损失会持续朝任何方向移动,并且永远不会真正收敛到最小值。如果学习速度太小,损失可能需要数年的时间才能收敛到最小。因此最佳学习率对于任何神经网络的学习都是至关重要的。
因此,每次参数更新时,我们使用学习速率来控制梯度的大小。让我重申一下上面看到的更新参数的公式。
new_weight = old_weight - learning_rate * gradient
所以学习速率决定了每一步的大小同时收敛到最小值。
计算梯度
计算的损失是由于网络中所有神经元的权重和偏差造成的。有些权重可能比其他权重对输出的影响更大,而有些权重可能根本没有影响输出。
前面已经说了我们训练的目标是减少输出中的误差。要做到这一点必须计算每个神经元的梯度。然后将这个梯度与学习速率相乘,并从当前的权重(或偏差)中减去这个值。这种调整发生在网络中的每一个神经元中。现在让我们考虑只有一个神经元的神经网络。
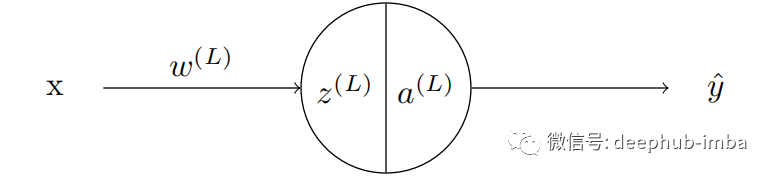
- L-层数
- w-权重
- z- 预激活函数
- a- 激活函数
- y-输出
预激活 z 可以写为,
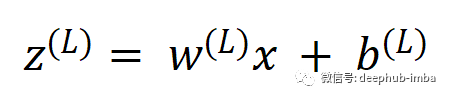
为了简单起见,让我们暂时忽略偏差b。
然后 z 的值由激活函数激活。这个例子中我们使用 sigmoid 激活函数。sigmoid 激活函数由符号 σ 表示。
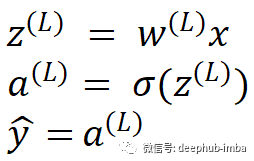
这个网络的输出是 y-hat。通过使用可用的各种损失函数之一来完成计算损失。让我们用字母 C 表示损失函数。现在该进行反向传播了,计算损失函数的梯度:
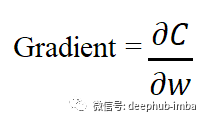
这个值告诉我们权重的任何变化如何影响损失。
为了计算梯度,我们使用链式法则来寻找导数。我们使用链式法则是因为误差不受权重的直接影响, 权重影响预激活函数,进而影响激活函数,进而影响输出,最后影响损失。下面的树显示了每个术语如何依赖于上面网络中的另一个术语。
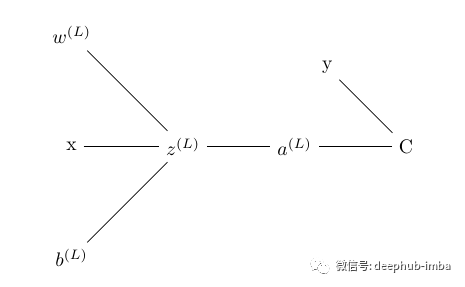
预激活函数取决于输入、权重和偏差、激活函数依赖于预激活函数、损失取决于激活函数
图像右上角的 y 是与预测输出进行比较并计算损失的真实值。
所以当我们应用链式法则时,我们得到:
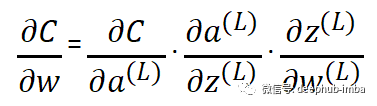
我们有另一个词来指代这个梯度,即损失相对于权重的瞬时变化率。将这些从单个神经元网络的梯度计算中获得的知识外推到具有四层的真正神经网络:一个输入层、两个隐藏层和一个输出层。
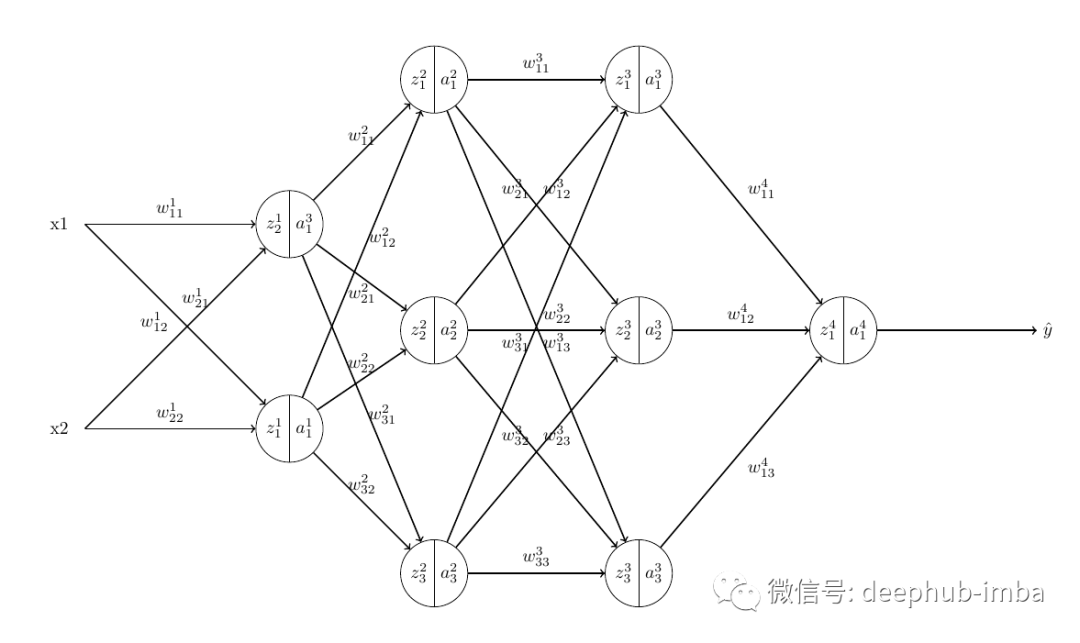
每个神经元的预激活函数由下式给出
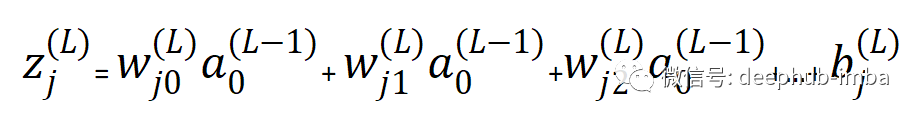
- L-层数
- j- 计算预激活函数的神经元的索引
- z- 预激活函数
- w-神经元的权重
- a- 前一个神经元的激活输出
除了我们没有激活函数的输入层之外的所有神经元都是如此。因为在输入层中z 只是输入与其权重相乘的总和(不是前一个神经元的激活输出)。
这里的梯度由下式给出,
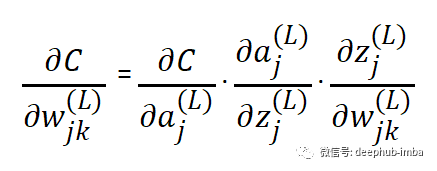
其中 w 是分别连接 L-1 层和 L 层节点 k 和 j 的权重。k 是前一个节点,j 是后继节点。但是这可能会引发一个新的问题:为什么是wjk而不是wkj呢?这只是在使用矩阵将权重与输入相乘时要遵循的命名约定。(所以暂时先不管他)
下面的树可以看到它们之间相互依赖
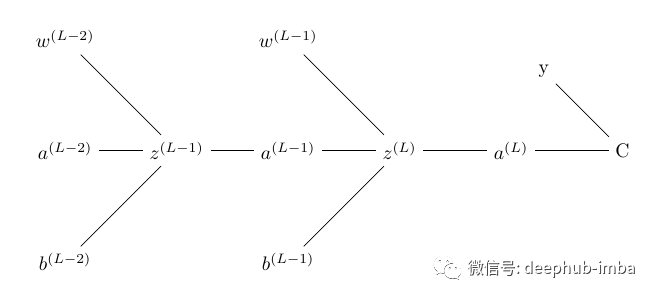
可以看到,前一层节点的激活函数的输出作为后一层节点的输入。如果知道以下项的值,就可以轻松计算输出节点中的梯度:
- 误差对激活函数的导数
- 激活函数相对于预激活函数的导数
- 预激活函数相对于权重的导数。
但是当我们在隐藏层计算梯度时,我们必须单独计算损失函数相对于激活函数的导数,然后才能在上面的公式中使用它。
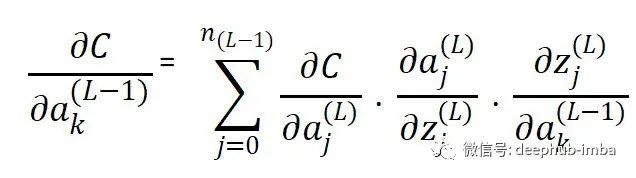
这个方程与第一个方程几乎相同(损失函数相对于权重的推导)。但在这里有一个总结。这是因为与权重不同,一个神经元的激活函数可以影响它所连接的下一层中所有神经元的结果。
需要说明的是 :这里没有编写用于推导与输出层中的激活函数相关的损失函数的链式法则的单独方程。那是因为输出层的激活函数直接影响误差。但隐藏层和输入层的激活函数并非如此。它们通过网络中的不同路径间接影响最终输出。
通过以上的计算,在计算网络中所有节点的梯度后,乘以学习率并从相应的权重中减去。
这就是反向传播和权重调整的方式。经过多次迭代这个过程,将损失减少到全局最小值,最终训练结束。
还差一个偏差
偏差也以与重量相同的方式经历一切!
与权重一样,偏差也会影响网络的输出。因此在每次训练迭代中,当针对权重的损失计算梯度时,同时计算相对于偏差的损失的梯度。
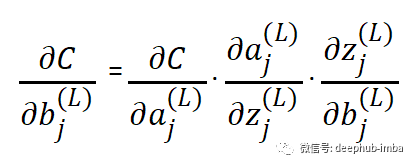
对于隐藏层,损失函数相对于前一层激活函数的推导也将使用链式法则单独计算。因此梯度被反向传播并且每个节点的偏差被调整。
总结
当损失被反向传播和最小化时,这就是在每个训练循环期间发生的所有事情。我希望这篇文章已经消除了数学中的晦涩难懂的概念,并使用了一种简单的方式将整个反向传播的过程描述清楚了。如果你有什么建议,欢迎留言。
作者:Maximinusjoshus
喜欢就关注一下吧:
 点个 在看 你最好看!********** **********
点个 在看 你最好看!********** **********