
flink sql 大全
摘要
写在前面:坐标上海,房补1500 三餐管饭, 有意向的请私聊简历砸过来,注意:不要无经验,不要无经验,要3-5年经验的开发者。🐧1466927252,游戏公司,游戏公司,此话有效期:2023/03/01-2023/04/30
在阅读下面给文章之前你需要了解:flink table api 之 time Attributes
Flink parses SQL using Apache Calcite, which supports standard ANSI SQL(ANSI SQL是sql语言标准).
Calcite 是什么?
如果用一句话形容 Calcite,Calcite 是一个用于优化异构数据源的查询处理的基础框架。
最近十几年来,出现了很多专门的数据处理引擎。例如列式存储 (HBase)、流处理引擎 (Flink)、文档搜索引擎 (Elasticsearch) 等等。这些引擎在各自针对的领域都有独特的优势,在现有复杂的业务场景下,我们很难只采用当中的某一个而舍弃其他的数据引擎。当引擎发展到一定成熟阶段,为了减少用户的学习成本,大多引擎都会考虑引入 SQL 支持,但如何避免重复造轮子又成了一个大问题。基于这个背景,**Calcite 横空出世,它提供了标准的 SQL 语言、多种查询优化和连接各种数据源的能力,将数据存储以及数据管理的能力留给引擎自身实现。更多 **
SELECT语句是通过TableEnvironment的sqlQuery()方法指定的。该方法将SELECT语句的结果作为Table对象返回。Table对象可以在后续的SQL和Table API查询中使用,可以转换为DataStream,也可以写入到tableink。SQL和Table API查询可以无缝混合,可以整体优化并转换为单个程序。
Table对象是flink Table Api/Sql 的核心, 不仅可以直接用sql查询,也可以用table对象对sql封装的方法查询,比如下面的两种方式一样:
Table table =...;//调用table封装的方法
table.select($("*"))//调用table sql
tableEnv.sqlQuery("select * from "+ table)//上面两种查询方法是一样的,但是本篇文章不讲见table封装的原生调用方式,本文章的重点是flink sql.//这两种用法本质上都是一样的,近乎能实现所有同样的功能。 //后面有时间的话我会单独出一篇文章讲解tabel原生的调用方式。
先来看一个例子
StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tableEnv =StreamTableEnvironment.create(env);// 定义sourceDataStream<Tuple3<Long,String,Integer>> ds = env.addSource(...);// datastream-to-table转换并给字段按照顺序命名Table table = tableEnv.fromDataStream(ds, $("user"), $("product"), $("amount"));//执行sql查询,计算结果会作为一个新的Table 对象返回。Table result = tableEnv.sqlQuery("SELECT SUM(amount) FROM "+ table +" WHERE product LIKE '%Rubber%'");//datastream-to-table视图, 并给字段按照顺序命名
tableEnv.createTemporaryView("Orders", ds, $("user"), $("product"), $("amount"));// 对视图执行sql查询, 计算结果会作为一个新的Table 对象返回。Table result2 = tableEnv.sqlQuery("SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'");// schema 定义列的信息finalSchema schema =newSchema().field("product",DataTypes.STRING()).field("amount",DataTypes.INT());//定义table sink(注意这种方式一般不用了,可直接用ddl建表的形式代替)
tableEnv.connect(newFileSystem().path("/path/to/file")).withFormat(...).withSchema(schema).createTemporaryTable("RubberOrders");//用 INSERT INTO将计算结果输出
tableEnv.executeSql("INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'");
核心注意的点:sqlQuery 返回一个新的Table 对象
1.executeSql(…)
通过TableEnvironment.executeSql()可以执行SELECT语句,该方法可以将执行结果作为TableResult返回。与sqlQuery 语句类似,sqlQuery 可以使用Table.execute()方法执行Table对象,将查询的内容收集到本地客户端。
TableResult中的collect()方法返回一个可关闭的行迭代器。除非收集了所有结果数据,否则选择作业不会完成。我们应该通过CloseableIterator#close()方法主动关闭作业,以避免资源泄漏。我们还可以通过TableResult.print()方法将选择结果打印到客户端控制台。TableResult中的结果数据只能被访问一次。因此,collect()和print()只能选择一个去调用。
StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tableEnv =StreamTableEnvironment.create(env, settings);
tableEnv.executeSql("CREATE TABLE Orders (`user` BIGINT, product STRING, amount INT) WITH (...)");// execute SELECT statementTableResult tableResult1 = tableEnv.executeSql("SELECT * FROM Orders");// use try-with-resources statement to make sure the iterator will be closed automaticallytry(CloseableIterator<Row> it = tableResult1.collect()){while(it.hasNext()){Row row = it.next();// handle row}}// execute TableTableResult tableResult2 = tableEnv.sqlQuery("SELECT * FROM Orders").execute();
tableResult2.print();
2. hints
2.1 sql hits
sql hints 可以和sql语句混杂在一起,其可以修改sql的执行计划( execution plans).
Generally a hint can be used to:
- Enforce planner: there’s no perfect planner, so it makes sense to implement hints to allow user better control the execution; (没有完美的planner, 故而更好地控制执行计划有重大意义。)
- Append meta data(or statistics): some statistics like “table index for scan” and “skew info of some shuffle keys” are somewhat dynamic for the query, it would be very convenient to config them with hints because our planning metadata from the planner is very often not that accurate;(为查询返回元数据和某些统计数据,比如返回 扫描的索引信息又或者发生了倾斜的key信息等, 这很方便,因为我们从planner中获得的源数据信息不够精确。通过sql hints我们可以控制这个行为。)
- Operator resource constraints: for many cases, we would give a default resource configuration for the execution operators, i.e. min parallelism or managed memory (resource consuming UDF) or special resource requirement (GPU or SSD disk) and so on, it would be very flexible to profile the resource with hints per query(instead of the Job). (资源约束:在大多数情况下,我们可以通过configration配置执行参数,比如并行度,内存等。这些配置作用在job作用域,如果我们想控制某个sql query则可以通过sql hints )
2.2.Dynamic Table Options
Dynamic table options allows to specify or override table options dynamically, different with static table options defined with SQL DDL or connect API, these options can be specified flexibly in per-table scope within each query.(Dynamic table options允许动态的指定或者覆盖tabe的参数,和静态参数不同的是,动态表参数可以将作用域和当前table对象绑定。 而静态参数作用在全局)
Note: Dynamic table options default is forbidden to use because it may change the semantics of the query. You need to set the config option table.dynamic-table-options.enabled to be true explicitly (default is false), See the Configuration for details on how to set up the config options.
(此行为默认禁用, table.dynamic-table-options.enabled设置为true方可启用,请参考:table api configration查询如何设置启用)
2.3 语法demo
CREATETABLE kafka_table1 (id BIGINT, name STRING, age INT)WITH(...);CREATETABLE kafka_table2 (id BIGINT, name STRING, age INT)WITH(...);-- override table options in query source
select id, name from kafka_table1 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */;-- override table options in join
select * from
kafka_table1 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ t1
join
kafka_table2 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ t2
on t1.id = t2.id;-- override table options forINSERT target table
insert into kafka_table1 /*+ OPTIONS('sink.partitioner'='round-robin') */ select * from kafka_table2;
3.数据准备
学习flink sql之前先准备数据, mysql我用的8+版本。
CREATETABLE `person` (
`id` int unsigned NOTNULLAUTO_INCREMENT,
`name` varchar(260)CHARACTERSET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOTNULLDEFAULT '' COMMENT'姓名',
`age` intNOTNULLCOMMENT'年龄',
`sex` tinyint NOTNULLCOMMENT '0:女,1男',
`email` varchar(255)CHARACTERSET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULTNULLCOMMENT'邮箱',
`event_time` varchar(255)DEFAULTNULL,
`num` intDEFAULTNULL,PRIMARYKEY(`id`)USINGBTREE)ENGINE=InnoDBAUTO_INCREMENT=41DEFAULTCHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC;INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(1,'pg01',12,1, 'www.johngo689.com', '2022-09-1923:01:01',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(2,'pg01',13,0, 'www.johngo689.com', '2022-09-1923:01:02',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(3,'pg01',14,0, 'www.johngo689.com', '2022-09-1923:01:03',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(4,'pg01',15,0, 'www.johngo689.com', '2022-09-1923:01:04',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(5,'pg01',16,1, 'www.johngo689.com', '2022-09-1923:01:05',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(6,'pg01',17,1, 'www.johngo689.com', '2022-09-1923:01:06',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(7,'pg01',18,0, 'www.johngo689.com', '2022-09-1923:01:07',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(8,'pg01',19,0, 'www.johngo689.com', '2022-09-1923:01:08',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(9,'pg01',20,1, 'www.johngo689.com', '2022-09-1923:01:09',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(10,'pg01',21,0, 'www.johngo689.com', '2022-09-1923:01:10',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(16,'pg01',21,0, 'www.johngo689.com', '2022-09-1923:01:11',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(17,'pg01',21,0, 'www.johngo689.com', '2022-09-1923:01:12',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(18,'pg01',21,0, 'www.johngo689.com', '2022-09-1923:01:13',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(19,'pg02',13,0, 'www.johngo689.com', '2022-09-1923:01:01',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(20,'pg02',14,0, 'www.johngo689.com', '2022-09-1923:01:02',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(21,'pg02',15,0, 'www.johngo689.com', '2022-09-1923:01:03',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(22,'pg02',20,1, 'www.johngo689.com', '2022-09-1923:01:04',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(23,'pg02',21,0, 'www.johngo689.com', '2022-09-1923:01:05',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(24,'pg02',16,1, 'www.johngo689.com', '2022-09-1923:01:06',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(25,'pg02',17,1, 'www.johngo689.com', '2022-09-1923:01:07',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(26,'pg02',18,0, 'www.johngo689.com', '2022-09-1923:01:08',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(27,'pg02',19,0, 'www.johngo689.com', '2022-09-1923:01:09',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(28,'pg02',21,0, 'www.johngo689.com', '2022-09-1923:01:10',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(29,'pg02',21,0, 'www.johngo689.com', '2022-09-1923:01:11',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(30,'pg02',21,0, 'www.johngo689.com', '2022-09-1923:01:12',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(31,'pg02',21,0, 'www.johngo689.com', '2022-09-1923:01:13',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(32,'pg02',21,0, 'www.johngo689.com', '2022-09-1923:01:14',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(33,'pg02',21,0, 'www.johngo689.com', '2022-09-1923:01:15',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(34,'pg02',21,0, 'www.johngo689.com', '2022-09-1923:01:16',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(35,'pg02',21,0, 'www.johngo689.com', '2022-09-1923:01:17',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(36,'pg02',21,0, 'www.johngo689.com', '2022-09-1923:01:18',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(37,'pg02',21,0, 'www.johngo689.com', '2022-09-1923:01:19',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(38,'pg02',21,0, 'www.johngo689.com', '2022-09-1923:01:20',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(39,'pg02',21,0, 'www.johngo689.com', '2022-09-1923:01:21',1);INSERTINTO `TestDB`.`person`(`id`, `name`, `age`, `sex`, `email`, `event_time`, `num`)VALUES(40,'pg02',21,0, 'www.johngo689.com', '2022-09-1923:01:22',1);CREATETABLE `order` (
`id` intNOTNULLAUTO_INCREMENT,
`order_name` varchar(255)DEFAULTNULL,
`price` double(10,2)NOTNULL,PRIMARYKEY(`id`))ENGINE=InnoDBAUTO_INCREMENT=5DEFAULTCHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;INSERTINTO `TestDB`.`order`(`id`, `order_name`, `price`)VALUES(1,'香蕉',1.00);INSERTINTO `TestDB`.`order`(`id`, `order_name`, `price`)VALUES(2,'香蕉',1.00);INSERTINTO `TestDB`.`order`(`id`, `order_name`, `price`)VALUES(3,'苹果',2.00);INSERTINTO `TestDB`.`order`(`id`, `order_name`, `price`)VALUES(4,'苹果',2.00);
# 下面的表格用于存储滚动窗口的计算结果
CREATETABLE `pgtest` (
`name` varchar(255)CHARACTERSET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOTNULL,
`start_ts` timestamp(6)NOTNULL,
`end_ts` timestamp(6)NOTNULL,
`su` intDEFAULTNULL,PRIMARYKEY(`name`,`start_ts`,`end_ts`))ENGINE=InnoDBDEFAULTCHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
#下面的表格用于存储滑动窗口的计算结果
CREATETABLE `pgtest2` (
`name` varchar(255)CHARACTERSET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOTNULL,
`start_ts` timestamp(6)NOTNULL,
`end_ts` timestamp(6)NOTNULL,
`su` intDEFAULTNULL,PRIMARYKEY(`name`,`start_ts`,`end_ts`))ENGINE=InnoDBDEFAULTCHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
#下面的表格用于存储累累窗口的计算结果
CREATETABLE `pgtest3` (
`name` varchar(255)CHARACTERSET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOTNULL,
`start_ts` timestamp(6)NOTNULL,
`end_ts` timestamp(6)NOTNULL,
`su` intDEFAULTNULL,PRIMARYKEY(`name`,`start_ts`,`end_ts`))ENGINE=InnoDBDEFAULTCHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
4. with clause
此语句可以创建一个仅供查询的视图,
importorg.apache.flink.table.api.EnvironmentSettings;importorg.apache.flink.table.api.TableEnvironment;importorg.apache.flink.table.api.TableResult;publicclassSqlWithDemo{publicstaticvoidmain(String[] args){EnvironmentSettings settings =EnvironmentSettings.newInstance().inStreamingMode()// .inBatchMode().build();TableEnvironment tEnv =TableEnvironment.create(settings);TableResult tableResult = tEnv.executeSql("CREATE TABLE MyUserTable (\n"+" id BIGINT,\n"+" name STRING,\n"+" age INT,\n"+" sex TINYINT,\n"+" email STRING,\n"+" event_time STRING,\n"+" num INT \n"+") WITH (\n"+" 'connector' = 'jdbc',\n"+" 'url' = 'jdbc:mysql://192.168.37.128:3306/TestDB',\n"+" 'driver'='com.mysql.jdbc.Driver',\n "+" 'username'='root',\n"+" 'password'='123456',\n"+" 'table-name' = 'person'\n"+")");System.out.println(tableResult.getResolvedSchema());
tEnv.sqlQuery("select * from MyUserTable").execute().print();// tEnv.sqlQuery("WITH view AS (select * from MyUserTable) select id,name,age from view").execute().print();}}
5.where
table_expression引用任何数据源。它可以是一个现有的表、视图或VALUES子句、多个现有表的连接结果或一个子查询。
tEnv.sqlQuery("select * from MyUserTable where id=1").execute().print();//基于values集合查询
tEnv.sqlQuery("SELECT order_id, price FROM (VALUES (1, 2.0), (2, 3.1)) AS t (order_id, price)").execute().print();//调用自定义的udf, 此处只需要知道udf可直接调用即可,不需要测试代码
tEnv.sqlQuery("SELECT PRETTY_PRINT(order_id) FROM MyUserTable ").execute().print();
6.distinct
tEnv.sqlQuery("select DISTINCT name as na from MyUserTable ").execute().print();
7.INNER JOIN
importorg.apache.flink.table.api.EnvironmentSettings;importorg.apache.flink.table.api.TableEnvironment;importorg.apache.flink.table.api.TableResult;publicclassSqljoinDemo{publicstaticvoidmain(String[] args){EnvironmentSettings settings =EnvironmentSettings.newInstance().inStreamingMode()// .inBatchMode().build();TableEnvironment tEnv =TableEnvironment.create(settings);TableResult tableResult = tEnv.executeSql("CREATE TABLE MyUserTable (\n"+" id BIGINT,\n"+" name STRING,\n"+" age INT,\n"+" sex TINYINT,\n"+" email STRING,\n"+" event_time STRING,\n"+" num INT \n"+") WITH (\n"+" 'connector' = 'jdbc',\n"+" 'url' = 'jdbc:mysql://192.168.37.128:3306/TestDB',\n"+" 'driver'='com.mysql.jdbc.Driver',\n "+" 'username'='root',\n"+" 'password'='123456',\n"+" 'table-name' = 'person'\n"+")");TableResult tableResult2 = tEnv.executeSql("CREATE TABLE MyOrder (\n"+" id INT,\n"+" order_name STRING\n"+") WITH (\n"+" 'connector' = 'jdbc',\n"+" 'url' = 'jdbc:mysql://192.168.37.128:3306/TestDB',\n"+" 'driver'='com.mysql.jdbc.Driver',\n "+" 'username'='root',\n"+" 'password'='123456',\n"+" 'table-name' = 'order'\n"+")");// tEnv.sqlQuery("select * from MyUserTable").execute().print();
tEnv.sqlQuery("select * from MyUserTable as a inner join MyOrder as b on a.id=b.id ").execute().print();}}
上面的join sql也可以这样写:
tEnv.sqlQuery("select * from MyUserTable inner join MyOrder on MyUserTable.id=MyOrder.id ").execute().print();
8.flink window TVF
TVF 是 window table-valued functions 首字母的缩写。 目前关于窗口的计算推荐window TVF 而不是用老旧的window aggregate 。
TVF 结构为:
SELECT...FROMTABLE(TVF function>GROUPBY window_start, window_end,...
先来看张图,TVF function 返回的值在原来所有值不变的情况下,添加了三个新的列,请注意红色箭头的部分: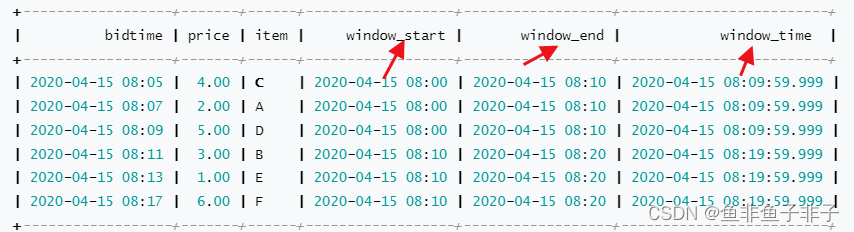
8.1 TVF 分类
- Tumble Windows(滚动)
- Hop Windows(滑动)
- Cumulate Windows(累积窗口)
- Session Windows (will be supported soon)(目前1.13版本暂未支持)
不管是Tumple 还是Hop 此函数返回的时候默认会给当前table添加三个字段:window_start ,
window_end,window_time . 如果想深入理解此三个字段请参考:24.flink windows 窗口,彻底站起来。
1.tumble
场景每间隔五秒钟对分桶数据做一次统计,此时对应下图window size=5s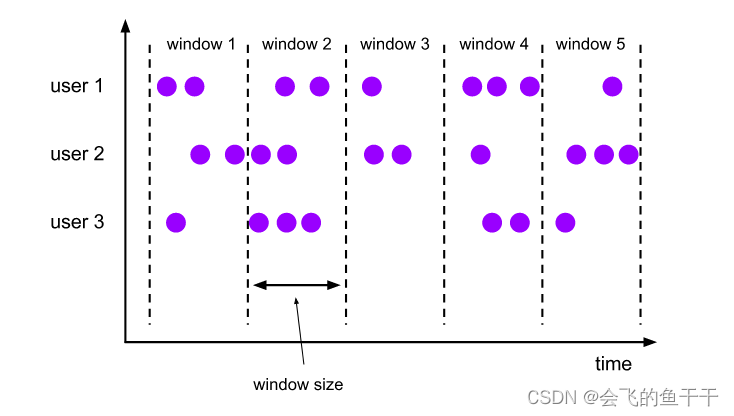
importorg.apache.flink.table.api.EnvironmentSettings;importorg.apache.flink.table.api.TableEnvironment;publicclassSqlTumbleWindowDemo{publicstaticvoidmain(String[] args){EnvironmentSettings settings =EnvironmentSettings.newInstance().inStreamingMode()// .inBatchMode().build();TableEnvironment tableEnv =TableEnvironment.create(settings);//定义事件时间和水位线
tableEnv.executeSql("CREATE TABLE MyTable ("+"name string ,"+"num INT,"+"event_time STRING,"+"ts AS TO_TIMESTAMP(event_time),"+"WATERMARK FOR ts as ts -INTERVAL '2' SECOND,"+"PRIMARY KEY (name) NOT ENFORCED"+") WITH ("+"'connector' = 'jdbc',"+"'url' = 'jdbc:mysql://192.168.37.128:3306/TestDB'"+",'table-name' = 'person',"+"'username'='root',"+"'password'='123456',"+"'driver'='com.mysql.cj.jdbc.Driver')");//定义事件时间和水位线
tableEnv.executeSql("CREATE TABLE sinkTable("+"name string ,"+"su INT,"+"start_ts TIMESTAMP(0),"+"end_ts TIMESTAMP(0),"+"PRIMARY KEY (name,start_ts,end_ts) NOT ENFORCED"+") WITH ("+"'connector' = 'jdbc',"+"'url' = 'jdbc:mysql://192.168.37.128:3306/TestDB'"+",'table-name' = 'pgtest', "+"'username'='root',"+"'password'='123456',"+"'driver'='com.mysql.cj.jdbc.Driver')");// //第一种写法:这是传统的老旧的window aggregate 写法// tableEnv.executeSql("insert into sinkTable select name,sum(num) As su," +// "TUMBLE_START(ts, INTERVAL '2' SECOND) AS start_ts," +// 取出窗口开始时间// "TUMBLE_END(ts, INTERVAL '2' SECOND) AS end_ts " +//取出窗口结束时间// "from MyTable group by " +// "name, TUMBLE(ts, INTERVAL '2' SECOND)");//直接sql查询// 第二种写法
tableEnv.executeSql("insert into sinkTable SELECT name,sum(`num`) As su,window_start as start_ts, window_end as end_ts \n"+" FROM TABLE(\n"+" TUMBLE(TABLE MyTable, DESCRIPTOR(ts), INTERVAL '5' seconds))\n"+" GROUP BY name, window_start, window_end").print();
下面的介绍以第二种写法为主。
}}
窗口函数TUMBLE(TABLE data, DESCRIPTOR(timecol), size)
data:指的是table
timecol:指的是时间属性(用于产生水位线的时间字段)
size:窗口大小
2.hop
滑动窗口:每隔2秒钟,统计过去4秒中的数据。 落入窗口中的数据可能会有重复
importorg.apache.flink.table.api.EnvironmentSettings;importorg.apache.flink.table.api.TableEnvironment;publicclassSqlSildingWindowDemo{publicstaticvoidmain(String[] args){EnvironmentSettings settings =EnvironmentSettings.newInstance().inStreamingMode()// .inBatchMode().build();TableEnvironment tableEnv =TableEnvironment.create(settings);//定义事件时间和水位线
tableEnv.executeSql("CREATE TABLE MyTable ("+"name string ,"+"num INT,"+"event_time STRING,"+"ts AS TO_TIMESTAMP(event_time),"+"WATERMARK FOR ts as ts -INTERVAL '2' SECOND,"+"PRIMARY KEY (name) NOT ENFORCED"+") WITH ("+"'connector' = 'jdbc',"+"'url' = 'jdbc:mysql://192.168.37.128:3306/TestDB'"+",'table-name' = 'person',"+"'username'='root',"+"'password'='123456',"+"'driver'='com.mysql.cj.jdbc.Driver')");//定义事件时间和水位线
tableEnv.executeSql("CREATE TABLE sinkTable("+"name string ,"+"su INT,"+"start_ts TIMESTAMP(0),"+"end_ts TIMESTAMP(0),"+"PRIMARY KEY (name,start_ts,end_ts) NOT ENFORCED"+") WITH ("+"'connector' = 'jdbc',"+"'url' = 'jdbc:mysql://192.168.37.128:3306/TestDB'"+",'table-name' = 'pgtest2', "+"'username'='root',"+"'password'='123456',"+"'driver'='com.mysql.cj.jdbc.Driver')");// //第一种写法:这是传统的老旧的window aggregate 写法// tableEnv.executeSql("insert into sinkTable select name,sum(num) As su," +// "HOP_START(ts, INTERVAL '2' seconds, INTERVAL '4' seconds) AS start_ts," +// 取出窗口开始时间// "HOP_END(ts, INTERVAL '2' seconds, INTERVAL '4' seconds) AS end_ts " +//取出窗口结束时间// "from MyTable group by " +// "name, HOP(ts, INTERVAL '2' seconds, INTERVAL '4' seconds)");//直接sql查询//第二种写法
tableEnv.executeSql("insert into sinkTable SELECT name,sum(`num`) As su,window_start as start_ts, window_end as end_ts \n"+" FROM TABLE(\n"+" HOP(TABLE MyTable, DESCRIPTOR(ts), INTERVAL '2' seconds, INTERVAL '4' seconds))\n"+" GROUP BY name, window_start, window_end").print();
下面的介绍以第二种写法为主。
}}
窗口函数HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ])
data:指的是table
timecol:指的是时间属性(用于产生水位线的时间字段)
slide:滑动的步长
size:窗口大小(注意此参数必须是slide参数的整数倍)
offset:可选参数,指的是窗口的偏移量,官网没给例子,暂时不说
3.cumulate
24.flink windows 窗口,彻底站起来。
在DataStream api介绍窗口的时候并没有此窗口,这个窗口应该是Flink table窗口独有的。毫无疑问这是个累积窗口,理解此窗口请仔细看下面的图:此窗口适用场景: 当前天的数据,每隔一分钟统计一次。 到第二天的时候重复第一天的逻辑,以此类推。请仔细看下图的窗口划分。
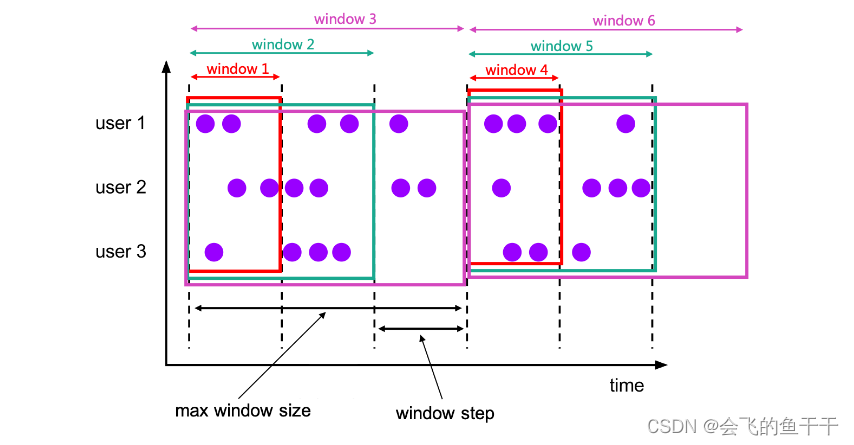
importorg.apache.flink.table.api.EnvironmentSettings;importorg.apache.flink.table.api.TableEnvironment;//累积窗口publicclassSqlCumulateWindowDemo{publicstaticvoidmain(String[] args){EnvironmentSettings settings =EnvironmentSettings.newInstance().inStreamingMode()// .inBatchMode().build();TableEnvironment tableEnv =TableEnvironment.create(settings);//定义事件时间和水位线
tableEnv.executeSql("CREATE TABLE MyTable ("+"name string ,"+"num INT,"+"event_time STRING,"+"ts AS TO_TIMESTAMP(event_time),"+"WATERMARK FOR ts as ts -INTERVAL '2' SECOND,"+"PRIMARY KEY (name) NOT ENFORCED"+") WITH ("+"'connector' = 'jdbc',"+"'url' = 'jdbc:mysql://192.168.37.128:3306/TestDB'"+",'table-name' = 'person',"+"'username'='root',"+"'password'='123456',"+"'driver'='com.mysql.cj.jdbc.Driver')");//定义事件时间和水位线
tableEnv.executeSql("CREATE TABLE sinkTable("+"name string ,"+"su INT,"+"start_ts TIMESTAMP(0),"+"end_ts TIMESTAMP(0),"+"PRIMARY KEY (name,start_ts,end_ts) NOT ENFORCED"+") WITH ("+"'connector' = 'jdbc',"+"'url' = 'jdbc:mysql://192.168.37.128:3306/TestDB'"+",'table-name' = 'pgtest3', "+"'username'='root',"+"'password'='123456',"+"'driver'='com.mysql.cj.jdbc.Driver')");
tableEnv.executeSql("insert into sinkTable SELECT name,sum(`num`) As su,window_start as start_ts, window_end as end_ts \n"+" FROM TABLE(\n"+" CUMULATE(TABLE MyTable, DESCRIPTOR(ts), INTERVAL '2' seconds, INTERVAL '6' seconds))\n"+" GROUP BY name, window_start, window_end").print();}}
格式:CUMULATE(TABLE data,DESCRIPTOR(timecol), step, size)
data:指的是table
timecol:指的是时间属性(用于产生水位线的时间字段)
slide:前进的步长(每前进一次发出一次计算结果)
size:窗口最大大小(注意此参数必须是slide参数的整数倍)
4.group by set
当用于窗口的时候要求group by 必须包含: window_start 和window_end 字段
importorg.apache.flink.table.api.DataTypes;importorg.apache.flink.table.api.EnvironmentSettings;importorg.apache.flink.table.api.Table;importorg.apache.flink.table.api.TableEnvironment;importorg.apache.flink.types.Row;publicclassSqlGroupBySet{publicstaticvoidmain(String[] args){EnvironmentSettings settings =EnvironmentSettings.newInstance().inStreamingMode()// .inBatchMode().build();TableEnvironment tenv =TableEnvironment.create(settings);Table table = tenv.fromValues(DataTypes.ROW(DataTypes.FIELD("supplier_id",DataTypes.STRING()),DataTypes.FIELD("product_id",DataTypes.STRING()),DataTypes.FIELD("rating",DataTypes.INT())),Row.of("supplier1","product1","4"),Row.of("supplier1","product2","3"),Row.of("supplier2","product3","3"),Row.of("supplier2","product4","4"));
tenv.createTemporaryView("t", table);
tenv.executeSql("
select supplier_id,rating,count(*) total
from t
group by grouping sets (supplier_id,rating)
").print();}}
代码中的sql等价于mysql中的:
SELECT supplier_id,null as rating ,count(*)
total FROM t
group by supplier_id
UNION all
SELECTnull,rating,count(*) total FROM t
GROUPBY rating
5.rollup
当用于窗口的时候要求group by 必须包含: window_start 和window_end 字段
ROLLUP是grouping set 的某种简写。它表示给定的表达式列表和列表的所有前缀,包括空列表)即查询按照column1,column2汇总->按照column1汇总 -> 所有汇总,得到以上三个维度的所有数据
importorg.apache.flink.table.api.DataTypes;importorg.apache.flink.table.api.EnvironmentSettings;importorg.apache.flink.table.api.Table;importorg.apache.flink.table.api.TableEnvironment;importorg.apache.flink.types.Row;publicclassSqlRollupBySet{publicstaticvoidmain(String[] args){EnvironmentSettings settings =EnvironmentSettings.newInstance().inStreamingMode()// .inBatchMode().build();TableEnvironment tenv =TableEnvironment.create(settings);Table table = tenv.fromValues(DataTypes.ROW(DataTypes.FIELD("supplier_id",DataTypes.STRING()),DataTypes.FIELD("product_id",DataTypes.STRING()),DataTypes.FIELD("rating",DataTypes.INT())),Row.of("supplier1","product1","4"),Row.of("supplier1","product2","3"),Row.of("supplier2","product3","3"),Row.of("supplier2","product4","4"));
tenv.createTemporaryView("t", table);
tenv.executeSql("select supplier_id,rating,count(*) total from t group by rollup(supplier_id,rating)").print();}}
里面的sql等价于:select supplier_id,rating,count(*) total from t
group by
grouping sets((supplier_id,rating),(supplier_id),())
也就是说rollup 其实是 group by set 多组聚合的简写形式。
6.cube
当用于窗口的时候要求group by 必须包含: window_start 和window_end 字段
(CUBE是用于指定grouping set 的全聚合简写形式。它表示给定的列表及其所有可能的子集-幂集)即查询按照column1汇总>按照column2汇总>按照column1,column2>按照所有结果汇总以上四个维度的数据
packagecom.test.demo.table.sql;importorg.apache.flink.table.api.DataTypes;importorg.apache.flink.table.api.EnvironmentSettings;importorg.apache.flink.table.api.Table;importorg.apache.flink.table.api.TableEnvironment;importorg.apache.flink.types.Row;publicclassSqlCubeBySet{publicstaticvoidmain(String[] args){EnvironmentSettings settings =EnvironmentSettings.newInstance().inStreamingMode()// .inBatchMode().build();TableEnvironment tenv =TableEnvironment.create(settings);Table table = tenv.fromValues(DataTypes.ROW(DataTypes.FIELD("supplier_id",DataTypes.STRING()),DataTypes.FIELD("product_id",DataTypes.STRING()),DataTypes.FIELD("rating",DataTypes.INT())),Row.of("supplier1","product1","4"),Row.of("supplier1","product2","3"),Row.of("supplier2","product3","3"),Row.of("supplier2","product4","4"));
tenv.createTemporaryView("t", table);
tenv.executeSql("select supplier_id,rating,count(*) total from t group by cube (supplier_id,rating)").print();}}
里面的sql等价于:
select supplier_id,rating,count(*) total
from t
group by grouping sets((supplier_id,rating),(supplier_id),(rating),())
7.关于时间属性time attribute传播的问题
你需要了解:flink table api 之 time Attributes。
window_start和window_end列是常规的时间戳列,表示当前窗口开窗和闭窗的时间,不是 time attributes。 因此,window_start和window_end不能在后续的基于时间的操作中用作时间属性(意思是它们不能被flink识别为event_time 或者是processing time)。
为了传播time attributes ,你需要再group by 的时候添加window_time列字段。window_time是 时间窗口产生的第三列,前两列是window_start和window_end。window_time。
把官网英文粘贴上:
The window_start and window_end columns are regular timestamp columns, not time attributes. Thus they can’t be used as time attributes in subsequent time-based operations. In order to propagate time attributes, you need to additionally add window_time column into GROUP BY clause. The window_time is the third column produced by Windowing TVFs which is a time attribute of the assigned window. Adding window_time into GROUP BY clause makes window_time also to be group key that can be selected. Then following queries can use this column for subsequent time-based operations, such as cascading window aggregations and Window TopN.
下面显示了一个级联窗口聚合,其中第一个窗口聚合为第二个窗口聚合传播时间属性。
-- tumbling 5 minutes for each supplier_id
CREATEVIEW window1 ASSELECT window_start, window_end, window_time as rowtime,SUM(price) as partial_price
FROMTABLE(TUMBLE(TABLEBid,DESCRIPTOR(bidtime),INTERVAL'5'MINUTES))GROUPBY supplier_id, window_start, window_end, window_time;-- tumbling 10 minutes on the first window
SELECT window_start, window_end,SUM(partial_price) as total_price
FROMTABLE(TUMBLE(TABLE window1,DESCRIPTOR(rowtime),INTERVAL'10'MINUTES))GROUPBY window_start, window_end;
8.create view 和with … as (select …)
importorg.apache.flink.table.api.EnvironmentSettings;importorg.apache.flink.table.api.TableEnvironment;publicclassSqlCreateViewWindowDemo{publicstaticvoidmain(String[] args){EnvironmentSettings settings =EnvironmentSettings.newInstance().inStreamingMode()// .inBatchMode().build();TableEnvironment tableEnv =TableEnvironment.create(settings);//定义事件时间和水位线
tableEnv.executeSql("CREATE TABLE MyTable ("+"name string ,"+"num INT,"+"event_time STRING,"+"ts AS TO_TIMESTAMP(event_time),"+"WATERMARK FOR ts as ts -INTERVAL '2' SECOND,"+"PRIMARY KEY (name) NOT ENFORCED"+") WITH ("+"'connector' = 'jdbc',"+"'url' = 'jdbc:mysql://192.168.37.128:3306/TestDB'"+",'table-name' = 'person',"+"'username'='root',"+"'password'='123456',"+"'driver'='com.mysql.cj.jdbc.Driver')");// tableEnv.executeSql("create view mv as SELECT name,sum(`num`) As su,window_start as start_ts, window_end as end_ts \n" +// " FROM TABLE(\n" +// " tumble(TABLE MyTable, DESCRIPTOR(ts), INTERVAL '5' seconds))\n" +// " GROUP BY name, window_start, window_end ").print();// tableEnv.executeSql("select * from mv").print();
tableEnv.executeSql("with mv as (SELECT name,sum(`num`) As su,window_start as start_ts, window_end as end_ts \n"+" FROM TABLE(\n"+" tumble(TABLE MyTable, DESCRIPTOR(ts), INTERVAL '5' seconds))\n"+" GROUP BY name, window_start, window_end) select * from mv ").print();}}
注意注释掉的代码和想在运行的代码时同样的。换句话说create view 可以和 with 语法实现同样的功能
9.Window Aggregation
前面讲window TVF的时候也提到过Window Aggregation, 这是一个老的接口,为了章节内容的完整性,这里还是提一下。
官网说
Group Window Aggregation被废弃,建议大家用window TVF代替
window TVF 更强大有效)
Compared to Group Window Aggregation, Window TVF Aggregation have many advantages, including:
- Have all performance optimizations mentioned in Performance Tuning.
- Support standard GROUPING SETS syntax.
- Can apply Window TopN after window aggregation result.
- and so on. 组窗口聚合在SQL查询的Group BY子句中定义,直接把函数放在group by中就行,结果会根据该窗口分组,就像使用常规GROUP BY子句的查询一样,支持以下组窗口函数。 TUMBLE(time_attr, interval):滚动窗口 HOP(time_attr, interval, interval):滑动窗口 SESSION(time_attr, interval):sessoin窗口 下面的都是方法,大都用来获取时间

上面就三类方法
- xx_start 获取窗口开始时间,
- xx_end 获取窗口结束时间,
- xx_rowtime 获取第一个不属于此窗口元素的时间,其本质上xx_end=xx_rowtime - 1, 此时间可作为time attribute 被子查询用于再次开窗。
- demo:
"select name,sum(num) As su,"+"TUMBLE_START(ts, INTERVAL '2' SECOND) AS start_ts,"+// 取出窗口开始时间"TUMBLE_END(ts, INTERVAL '2' SECOND) AS end_ts "+//取出窗口结束时间"from MyTable group by "+"name, TUMBLE(ts, INTERVAL '2' SECOND)"
10.Group Aggregation
与大多数数据系统一样,Apache Flink支持聚合函数;内置的和用户定义的都有。用户定义函数在使用之前必须在catlog中注册。
聚合函数从多个输入行计算单个结果。例如,聚合函数可以在一组行上计算COUNT、SUM、AVG(平均值)、MAX(最大值)和MIN(最小值)。
对于流查询,重要的是要理解Flink运行的是永不终止的连续查询。相反,它们会根据输入表的更新来更新结果表。对于(select count(*) from orders )查询,每次在orders表中插入新行时,Flink都会输出一个更新的计数。其本质上则是为该sql维护了一个存储中间计数的状态,每当有新行到来更新此状态,并且将结果发出。
对于流查询,计算查询结果所需的状态可能无限增长。状态大小取决于组的数量以及聚合函数的数量和类型。例如MIN/MAX对状态大小的要求很高,而COUNT则很便宜。您可以提供一个具有适当状态存活时间(TTL)的查询配置,以防止状态大小过大。注意,这可能会影响查询结果的正确性。具体请参见查询配置。(table.exec.state.ttl: 默认永不清除状态,可配duration 参数控制,注意此参数清除的是空闲的不被更新的状态)
Apache Flink为Group Aggregation提供了一套性能调优方法,详见性能调优。 参数配置参考:configration
group by 支持的函数还有:grouping sets rollup cube having . 具体就不多说了。
11. Over Aggregation
在讲解此知识之前,先来回忆下mysql的窗口函数over.
11.1 mysql中的over
移步:mysql 窗口函数
11.2 flink over
了解了mysql中的over就可以来说flink中的over了, 首先二者的概念基本雷同,总比不过语法上略有不同:
SELECTagg_func(agg_col)OVER([PARTITIONBY col1[, col2,...]]ORDERBY time_col
range_definition),...FROM...
agg_func:指的是我们要对每个组内的数据做什么操作
agg_col:被计算的列
PARTITIONBY:分区的字段
order by:用于排序的字段, 目前只支持time atribute属性
range_definition:表示对当前参与计算数据做范围划分
比如下面的代码,每当当前行到来的时候, 取当前行和过去两秒的行参与计算,计算结果存入新的字段中。
现在mysql中准备好表格:
CREATETABLE `goods` (
`id` intNOTNULLAUTO_INCREMENT,
`category_id` intDEFAULTNULL,
`category` varchar(15)DEFAULTNULL,
`NAME` varchar(30)DEFAULTNULL,
`price` decimal(10,2)DEFAULTNULL,
`stock` intDEFAULTNULL,
`upper_time` datetime DEFAULTNULL,PRIMARYKEY(`id`))ENGINE=InnoDBAUTO_INCREMENT=13DEFAULTCHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;INSERTINTO `TestDB`.`goods`(`id`, `category_id`, `category`, `NAME`, `price`, `stock`, `upper_time`)VALUES(1,1, '女装/女士精品', 'T恤',39.90,1000, '2020-11-1011:10:01');INSERTINTO `TestDB`.`goods`(`id`, `category_id`, `category`, `NAME`, `price`, `stock`, `upper_time`)VALUES(2,1, '女装/女士精品', '连衣裙',79.90,2500, '2020-11-1011:10:02');INSERTINTO `TestDB`.`goods`(`id`, `category_id`, `category`, `NAME`, `price`, `stock`, `upper_time`)VALUES(3,1, '女装/女士精品', '卫衣',89.90,1500, '2020-11-1011:10:03');INSERTINTO `TestDB`.`goods`(`id`, `category_id`, `category`, `NAME`, `price`, `stock`, `upper_time`)VALUES(4,1, '女装/女士精品', '牛仔裤',89.90,3500, '2020-11-1011:10:04');INSERTINTO `TestDB`.`goods`(`id`, `category_id`, `category`, `NAME`, `price`, `stock`, `upper_time`)VALUES(5,1, '女装/女士精品', '百褶裙',29.90,500, '2020-11-1011:10:05');INSERTINTO `TestDB`.`goods`(`id`, `category_id`, `category`, `NAME`, `price`, `stock`, `upper_time`)VALUES(6,1, '女装/女士精品', '呢绒外套',399.90,1200, '2020-11-1011:10:06');INSERTINTO `TestDB`.`goods`(`id`, `category_id`, `category`, `NAME`, `price`, `stock`, `upper_time`)VALUES(7,2,'户外运动','自行车',399.90,1000, '2020-11-1011:10:07');INSERTINTO `TestDB`.`goods`(`id`, `category_id`, `category`, `NAME`, `price`, `stock`, `upper_time`)VALUES(8,2,'户外运动','山地自行车',1399.90,2500, '2020-11-1011:10:08');INSERTINTO `TestDB`.`goods`(`id`, `category_id`, `category`, `NAME`, `price`, `stock`, `upper_time`)VALUES(9,2,'户外运动','登山杖',59.90,1500, '2020-11-1011:10:09');INSERTINTO `TestDB`.`goods`(`id`, `category_id`, `category`, `NAME`, `price`, `stock`, `upper_time`)VALUES(10,2,'户外运动','骑行装备',399.90,3500, '2020-11-1011:10:10');INSERTINTO `TestDB`.`goods`(`id`, `category_id`, `category`, `NAME`, `price`, `stock`, `upper_time`)VALUES(11,2,'户外运动','运动外套',799.90,500, '2020-11-1011:10:11');INSERTINTO `TestDB`.`goods`(`id`, `category_id`, `category`, `NAME`, `price`, `stock`, `upper_time`)VALUES(12,2,'户外运动','滑板',499.90,1200, '2020-11-1011:10:12');//下面是flink代码importorg.apache.flink.table.api.EnvironmentSettings;importorg.apache.flink.table.api.TableEnvironment;publicclassSqlOverDemo{publicstaticvoidmain(String[] args){EnvironmentSettings settings =EnvironmentSettings.newInstance().inStreamingMode()// .inBatchMode().build();TableEnvironment tableEnv =TableEnvironment.create(settings);//定义事件时间和水位线
tableEnv.executeSql("CREATE TABLE MyTable ("+"id INT ,"+"category_id INT,"+"category STRING,"+"NAME STRING,"+"price decimal(10,2),"+"stock INT,"+"upper_time TIMESTAMP(0),"+"WATERMARK FOR upper_time as upper_time -INTERVAL '2' SECOND"+") WITH ("+"'connector' = 'jdbc',"+"'url' = 'jdbc:mysql://192.168.37.128:3306/TestDB'"+",'table-name' = 'goods',"+"'username'='root',"+"'password'='123456',"+"'driver'='com.mysql.cj.jdbc.Driver')");
tableEnv.sqlQuery("select *,sum(price) over(partition by category order by upper_time RANGE BETWEEN INTERVAL '2' SECOND PRECEDING AND CURRENT ROW ) as su from MyTable ").execute().print();}}
范围有两种一种是时间一种是条数:
- RANGE BETWEEN INTERVAL ‘30’ MINUTE PRECEDING AND CURRENT ROW 意思是每来一条数据计算过去30分钟内的数据
- ROWS BETWEEN 10 PRECEDING AND CURRENT ROW WINDOW 意思是每来一条数据计算过去十条的数据
12.join/left join/right join/full join
Flink SQL支持动态表上复杂而灵活的连接操作。有几种不同类型的连接来考虑可能需要的各种语义查询。
默认情况下,连接的顺序没有优化。表按照在FROM子句中指定的顺序连接。你可以调整联接查询的性能,方法是先列出更新频率最低的表,最后列出更新频率最高的表。请确保以不产生交叉连接(笛卡尔积)的顺序指定表,交叉连接不受支持,会导致查询失败。
常规连接是最通用的连接类型,其中任何新记录或连接两端的更改都是可见的,并且会影响整个连接结果。例如,如果左侧有一个新记录,当产品id等于时,它将与右侧所有以前和将来的记录连接。
SELECT*FROMOrdersINNERJOINProductONOrders.productId =Product.id
对于流查询,常规连接的语法是最灵活的,并且允许任何类型的更新(插入、更新、删除)输入表。然而,该操作具有重要的操作含义:它需要将连接输入的两端永远保持在Flink状态。因此,计算查询结果所需的状态可能无限增长,这取决于所有输入表和中间连接结果的不同输入行数。可以为查询配置提供适当的状态存活时间(TTL),以防止状态过大。注意,这可能会影响查询结果的正确性。具体请参见查询配置。
对于流查询,计算查询结果所需的状态可能无限增长,这取决于聚合的类型和不同分组键的数量。请提供具有有效保留间隔的查询配置,以防止状态大小过大。详细信息请参见查询配置。
这就是为什么在DataStream Api中只提供了window join, 因为窗口触发之后会清除当前窗口的状态,不会导致状态无限激增。
然而对于sql来说,可以说sql提供了更加灵活丰富的功能,但是也有一定的风险行为,比如某些计算涉及到的状态可能无限时间的存在, 但是新手很可能难以掌握这一点。
建议大家在遇到需求的时候首先想如果用DataStream Api应该怎么实现,DataStream Api本质上是安全的,如果你发现用DataStream 来写代码的时候你需要手动创建状态,那就意味着你的操作是不安全的行为,那么再换回来思考用sql实现,那么也就意味着sql本质上也是维护了状态的。此时就需要额外注意状态套配置清除策略。
sql本质上被转化为了DataStream程序,因此关于状态二者完全一样。 比如考虑分组求和的操作。
如果用DataStream API 则是:
ds.keyBy(…).reduce((x1,x2)->{x1.value+v2.value})
此时其实对每个key而言只维护了一个中间结果状态,因此状态的大小和key的种类有关系,正常来说key其实是有限的,也就意味着状态其实也是有限的。 那么对于Table api :
tableEnv.sqlQuery(“select sum(value) from ds group by name”)
其状态也是有限的。
再比如如果我想对某个key的数据进行去重,然后再求和输出计算结果。
如果用DataStream API 则是:
ds.keyBy().process(ProcessFunction{…})
在ProcessFunction中我们需要维护状态,该状态记录了所有的数据,为什么呢?因为要去重,那也就意味着每次都需要知道原来的数据是什么。 那就意味着用DataStream API 会导致状态无线增加
那么对于Table api :
select count(distinct value) from order group by name
则table Api也会维护无限的状态, 这就是定期清理策略存在的价值,否则程序总有一天会gg.
所以在日常开发中,如果你不清楚你的sql有没有重大的影响,请先思考用DataStream 实现的时候是否涉及到巨大的手动维护的状态,如果DataStream Api 实现会产生无限增长的状态,则Table sql 也一定会产生无限增长的状态。
所以对于join来说,每次来一条数据都要加入原来的join组中,这意味着join需要巨大的状态, 因此join本省是一个风险行为sql。读者用的时候一定要小心,记得配置状态过期清理,值域过期时间其实和业务相关,比如对你来说你的同一个join的id不可能跨天到来,那么其实你的清理策略设置为48小时基本上是安全的。
join/left join /right join /full join 和mysql的语法完全一致,治理就不讲了。
Interval Joins
time attributes 连接两个流。
对于流查询,与常规连接相比,间隔连接只支持具有时间属性的仅追加表。由于时间属性是准单调递增的,所以Flink可以在不影响结果正确性的情况下从其状态中删除旧值。 因此interval join其实是安全的sql连接。
SELECT*FROM Orders o, Shipments s
WHERE o.id = s.order_id
AND o.order_time BETWEEN s.ship_time -INTERVAL'4'HOURAND s.ship_time
时间范围可以用下面的语法:
ltime = rtime
ltime >= rtime AND ltime < rtime +INTERVAL'10'MINUTE
ltime BETWEEN rtime -INTERVAL'10'SECONDAND rtime +INTERVAL'5'SECOND
Temporal Joins
此join比较复杂,我尽量尝试说清楚。
packagecom.test.demo.table.sql;importorg.apache.flink.streaming.api.datastream.DataStream;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.table.api.Schema;importorg.apache.flink.table.api.Table;importorg.apache.flink.table.api.bridge.java.StreamTableEnvironment;importorg.apache.flink.types.Row;importorg.apache.flink.types.RowKind;importstaticorg.apache.flink.table.api.Expressions.$;publicclassSqlTemporalJoinDemo{publicstaticvoidmain(String[] args){// create environments of both APIsStreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tableEnv =StreamTableEnvironment.create(env);//通过row对象构造changelog流数据DataStream<Row> order = env.fromElements(Row.of(1,"1970-01-03 00:00:00"),Row.of(2,"1970-01-01 01:00:00"),Row.of(3,"1970-01-04 00:00:00"));DataStream<Row> du = env.fromElements(Row.ofKind(RowKind.INSERT,1,"1970-01-03 00:00:00","11"),Row.ofKind(RowKind.INSERT,2,"1970-01-01 00:00:01","12"),Row.ofKind(RowKind.UPDATE_BEFORE,2,"1970-01-01 00:00:01","12"),Row.ofKind(RowKind.UPDATE_AFTER,2,"1970-01-01 00:00:02","13"),// Row.ofKind(RowKind.DELETE, 2, "1970-01-01 00:00:02","13"),Row.ofKind(RowKind.INSERT,3,"1970-01-03 00:00:00","44"));Schema s1=Schema.newBuilder().columnByExpression("myrowtime","CAST(f1 AS TIMESTAMP_LTZ(0))").watermark("myrowtime","myrowtime- INTERVAL '10' SECOND").build();Schema s2=Schema.newBuilder().columnByExpression("my2rowtime","CAST(f1 AS TIMESTAMP_LTZ(0))").watermark("my2rowtime","my2rowtime- INTERVAL '10' SECOND").primaryKey("f0").build();Table table01= tableEnv.fromDataStream(order,s1).as("id","t1");Table table02 = tableEnv.fromChangelogStream(du,s2).as("id","t2","price");
tableEnv.createTemporaryView("aa",table01);
tableEnv.createTemporaryView("bb",table02);
tableEnv.sqlQuery("select * from aa as l \n"+"left join bb for system_time as of l.myrowtime as r \n"+"on l.id = r.id").execute().print();}}
此join 是为了让左流监测右流的变化, 右侧流是一个changelog流, 左侧数据会根据id和右侧流join,因为右侧流是change流,因此数据是会变化的,当右侧数据有新的到来,因为时间变大了因此会更新join的结果。 请读者自行将代码中注释掉的
Row.ofKind(RowKind.DELETE, 2, "1970-01-01 00:00:02","13"),
打开, 会发现join结果表不会保留以前的版本,只保存最新的结果,这可能是为了减轻状态存储带来的压力。
此join适用的场景:左侧是一个任意的数据流, 右侧必须是一个changelog流数据, join结果会随着changelog流数据的推进变化。
比如:左侧为买盘表, 右侧为实时汇率, 那么可以join汇率表实现实时的汇率监测。
- 支持inner join, left join。
- 右流版本表既要定义为事件时间(水位线)也要定义主键;左流需要定义为事件时间(水位线)。
- 关联等式条件必须有维表的主键,但是可以加入其它辅助条件。
- 水位线起到一个触发写出的作用,在写出之前,左右流的元素在缓存中join。
- 左流元素才会触发join的作用,join的结果只会看到从左流探针侧触发的join。
- 在缓存中的join结果没有merge,而是将每次触发join的结果依次输出。 当触发写出后,在缓存中只保留元素最新版本,过期版本将删除。 参考:temporal join
sql 格式:
SELECT[column_list]FROM table1 [AS<alias1>][LEFT]JOIN table2 FOR SYSTEM_TIME ASOF table1.{ proctime | rowtime } [AS<alias2>]ON table1.column-name1 = table2.column-name1
window top-n
1.准备数据
CREATETABLE `Bid` (
`ts` datetime DEFAULTNULL,
`price` intDEFAULTNULL,
`item` varchar(255)DEFAULTNULL,
`supplier_id` varchar(255)DEFAULTNULL)ENGINE=InnoDBDEFAULTCHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;INSERTINTO `TestDB`.`Bid`(`ts`, `price`, `item`, `supplier_id`)VALUES('2020-04-1508:05:00', 4, 'A', 'supplier1');INSERTINTO `TestDB`.`Bid`(`ts`, `price`, `item`, `supplier_id`)VALUES('2020-04-1508:06:00', 4, 'C', 'supplier2');INSERTINTO `TestDB`.`Bid`(`ts`, `price`, `item`, `supplier_id`)VALUES('2020-04-1508:07:00', 2, 'G', 'supplier1');INSERTINTO `TestDB`.`Bid`(`ts`, `price`, `item`, `supplier_id`)VALUES('2020-04-1508:08:00', 2, 'B', 'supplier3');INSERTINTO `TestDB`.`Bid`(`ts`, `price`, `item`, `supplier_id`)VALUES('2020-04-1508:09:00', 5, 'D', 'supplier4');INSERTINTO `TestDB`.`Bid`(`ts`, `price`, `item`, `supplier_id`)VALUES('2020-04-1508:11:00', 2, 'B', 'supplier3');INSERTINTO `TestDB`.`Bid`(`ts`, `price`, `item`, `supplier_id`)VALUES('2020-04-1508:13:00', 1, 'E', 'supplier1');INSERTINTO `TestDB`.`Bid`(`ts`, `price`, `item`, `supplier_id`)VALUES('2020-04-1508:15:00', 3, 'H', 'supplier2');INSERTINTO `TestDB`.`Bid`(`ts`, `price`, `item`, `supplier_id`)VALUES('2020-04-1508:17:00', 6, 'F', 'supplier5');
2.代码实现
importorg.apache.flink.table.api.EnvironmentSettings;importorg.apache.flink.table.api.TableEnvironment;importorg.apache.flink.table.api.TableResult;publicclassSqlTopNDemo{publicstaticvoidmain(String[] args){EnvironmentSettings settings =EnvironmentSettings.newInstance().inStreamingMode()// .inBatchMode().build();TableEnvironment tEnv =TableEnvironment.create(settings);TableResult tableResult = tEnv.executeSql("CREATE TABLE Bid (\n"+" ts TIMESTAMP(0),\n"+" price INT,\n"+" item STRING,\n"+" supplier_id STRING,\n"+" WATERMARK FOR ts as ts -INTERVAL '0.01' SECOND"+") WITH (\n"+" 'connector' = 'jdbc',\n"+" 'url' = 'jdbc:mysql://192.168.37.128:3306/TestDB',\n"+" 'driver'='com.mysql.jdbc.Driver',\n "+" 'username'='root',\n"+" 'password'='123456',\n"+" 'table-name' = 'Bid'\n"+")");
tEnv.executeSql("create view t_window as ("+"SELECT supplier_id,window_start as start_ts, window_end as end_ts,sum(price) as price,count(*) as cnt \n"+"FROM TABLE(tumble(TABLE Bid, DESCRIPTOR(ts), INTERVAL '10' MINUTES)) GROUP BY supplier_id, window_start, window_end "+")");//窗口数据如下//+----+--------------------------------+-------------------------+-------------------------+-------------+----------------------+//| op | supplier_id | start_ts | end_ts | price | cnt |//+----+--------------------------------+-------------------------+-------------------------+-------------+----------------------+//| +I | supplier1 | 2020-04-15 08:00:00.000 | 2020-04-15 08:10:00.000 | 6 | 2 |//| +I | supplier1 | 2020-04-15 08:10:00.000 | 2020-04-15 08:20:00.000 | 1 | 1 |//| +I | supplier5 | 2020-04-15 08:10:00.000 | 2020-04-15 08:20:00.000 | 6 | 1 |//| +I | supplier4 | 2020-04-15 08:00:00.000 | 2020-04-15 08:10:00.000 | 5 | 1 |//| +I | supplier3 | 2020-04-15 08:00:00.000 | 2020-04-15 08:10:00.000 | 2 | 1 |//| +I | supplier3 | 2020-04-15 08:10:00.000 | 2020-04-15 08:20:00.000 | 2 | 1 |//| +I | supplier2 | 2020-04-15 08:00:00.000 | 2020-04-15 08:10:00.000 | 4 | 1 |//| +I | supplier2 | 2020-04-15 08:10:00.000 | 2020-04-15 08:20:00.000 | 3 | 1 |//+----+--------------------------------+-------------------------+-------------------------+-------------+----------------------+//下面的查询基于上面的结果,上表中的数据基于:upplier_id, window_start, window_end聚合统计//下面我们将对 window_start, window_end 分组,然后求每个时间范围内,price最大的那条数据
tEnv.sqlQuery("select * from (SELECT *, ROW_NUMBER() OVER (PARTITION BY start_ts, end_ts ORDER BY price DESC) as rownum from t_window) as over_data where over_data.rownum=1 ").execute().print();}}
版权归原作者 以后不会再写文章了 所有, 如有侵权,请联系我们删除。