
selenium,一个第三方库,可以通过给driver发送命令来操作浏览器,以达到模拟人操作浏览器,实现网页自动化、测试等,减少了重复性工作。
selenium的工作的基本架构如下: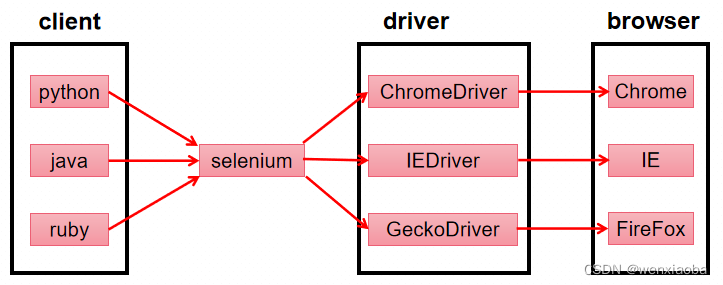
安装
本文是在python环境下使用selenium,使用浏览器是Chrome,系统是win10系统。
python环境的配置这里就不多说了
selenium安装:
pip install selenium
Driver安装:
- chromedriver下载: - 国内镜像下载地址:https://registry.npmmirror.com/binary.html?path=chromedriver- 打开chrome浏览器,打开
chrome://settings/help页面,即可查看chrome版本号- 根据Chrome的版本号下载对应版本或稍微高于该版本的chromedirver,然后解压 - 环境变量配置: - 配置系统环境变量path,将chromedirver的解压包所在目录添加进去,然后点击确定进行保存
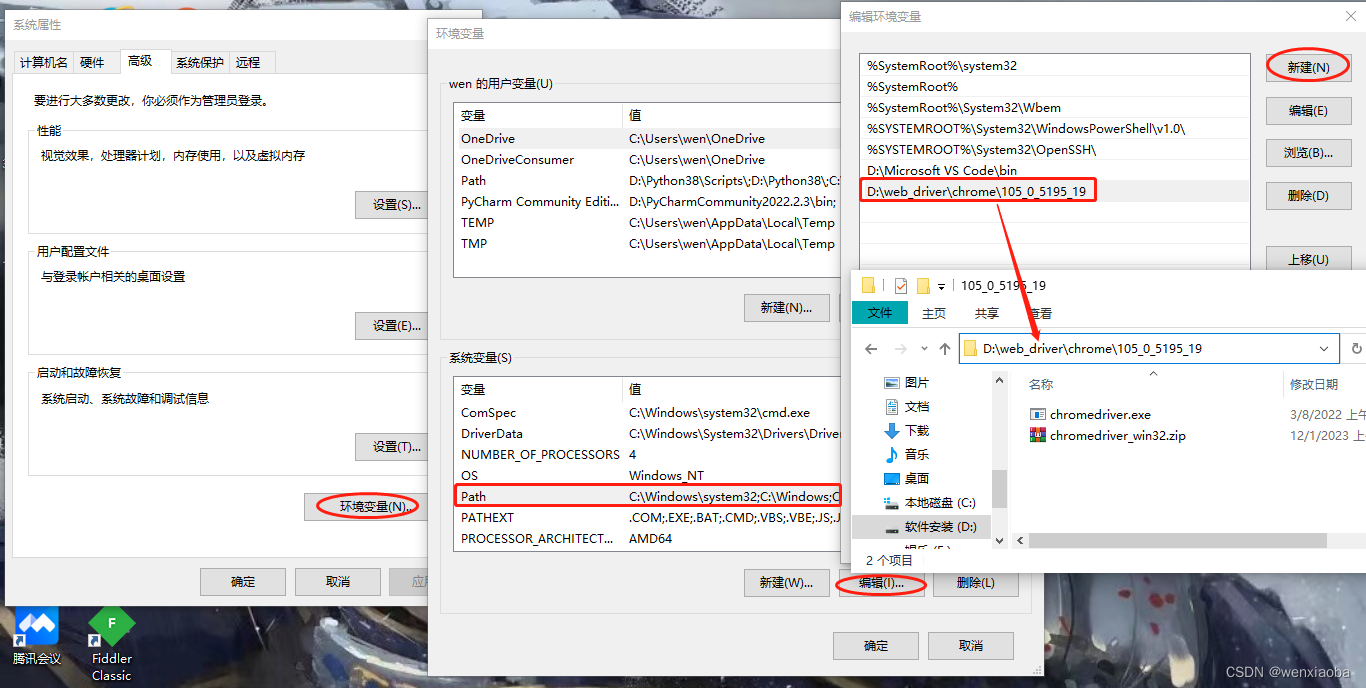 - 查看是否配置成功
- 查看是否配置成功
使用
selenium的使用基本思路如下:
- 步骤1:打开浏览器
- 步骤2:操作浏览器或验证页面数据等
- 步骤3:关闭浏览器进程
示例:
from selenium import webdriver
if __name__ =="__main__":# 由于selenium是通过driver去操作浏览器的,所以我们需要对应浏览器的driver对象
driver = webdriver.Chrome()# 打开百度首页
driver.get("https://www.baidu.com")# 操作浏览器或验证页面数据等print("xxx")# 关闭浏览器进程
driver.quit()
浏览器驱动
从前面的selenium工作原理我们可以了解到,我们的代码并不是直接去操作浏览器的,而是通过给浏览器驱动driver发送命令,driver去操作浏览器的,简单点理解就是跟selenium对接的是driver,所以我们都是先创建一个driver去进行后面的操作。
驱动对象WebDriver
selenium支持的浏览器驱动有:Firefox、Chrome、Ie、Edge、Safari等浏览器的驱动(需要自己手动安装对应的浏览器驱动)
selenium创建浏览器驱动对象的语法如下:
import time
from selenium import webdriver
# 创建 Firefox 浏览器驱动对象
driver = webdriver.Firefox()
# 创建 Chrome 浏览器驱动对象
driver = webdriver.Chrome()
# 创建 IE 浏览器驱动对象
driver = webdriver.Ie()
# 创建 Edge 浏览器驱动对象
driver = webdriver.Edge()
# 创建 Safari 浏览器驱动对象
driver = webdriver.Safari()
打开网页
驱动对象WebDriver的创建相当于打开了浏览器,我们打开浏览器肯定是想访问某个网页的,所以接下来就是打开网页,对应的方法是:
get(url)
get(url)
是WebDriver对象的方法,所以需要先创建WebDriver对象。
关闭浏览器
相关操作执行完成后,最后肯定是要关闭浏览器的,不然打开太多浏览器,会占用资源。关闭浏览器有2种方式:
close()
和
quit()
方法描述
close()
关闭当前标签页面
quit()
关闭浏览器
注:如果当前浏览器只有一个标签页,close()有时能达到quit()的效果,因为有些浏览器判断没有标签页的时候会默认为关闭浏览器,比如Chrome。
示例:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
if __name__ =="__main__":
driver = webdriver.Chrome()
driver.implicitly_wait(10)# 打开百度首页
driver.get("https://www.baidu.com")# 点击 新闻 ,新标签页打开百度新闻
driver.find_element(By.LINK_TEXT,"新闻").click()# 在百度首页点击 视频,打开百度视频
driver.find_element(By.LINK_TEXT,"视频").click()
time.sleep(2)# 关闭百度首页这个标签页
driver.close()
time.sleep(2)# 关闭浏览器
driver.quit()
执行结果如下:
从关闭浏览器这里可以看出来,WebDriver对象的当前页面并不是我们看到的新标签页,如果想切换到其他页面,就需要用到switch_to()方法,这个后面系列再具体介绍。
定位元素
浏览器页面除了给我们展示数据外,还需要我们去操作页面,比如点击、长按、拖拽、双击指定元素等,在操作元素时,我们得让driver知道要操作的元素,即selenium需要给到元素的定位。
find_element()
早期的selenium提供了针对id、name、xpath等多种方式的具体方法来定位到具体的元素,比如find_element_by_id()、find_element_by_name()等,在后续的升级中,这些方法被弃用了,现在统一使用
find_element(by=By.ID, value=None)
方法,该方法包含了id、name、xpath等定位方式
find_element(by=By.ID, value=None)是WebDriver对象用于定位元素的方法,返回对应元素对象(WebElement),我们的点击、拖拽等操作都是在元素对象的基础上进行的
参数说明
- by:指定按照对应的方式来定位元素 - By.ID,根据查找标签中的id属性来定位元素- By.NAME,根据查找标签中的name属性来定位元素- By.CLASS_NAME,根据class属性指定的值来查找元素- By.CSS_SELECTOR,根据css选择器的方式来查找元素- By.XPATH,根据XPath语法来查找元素- By.LINK_TEXT,查找文本精确匹配的a标签元素- By.PARTIAL_LINK_TEXT,查找文本模糊匹配的a标签元素- By.TAG_NAME,根据标签名称来查找元素,不太好用,不常用
value:元素位置,字符串类型
注意:XPath使用范围比较广,但是查找速度比较慢,id、name、class其实是根据css_selector来实现的,css_selector查找元素比较快;一个页面中,id和name一般是唯一的(人为的约定俗成,非强制),具体使用哪种方式,要依据页面的改动程度、前端页面的层级等确定。
XPath语法参考:XPath入门
css_selector语法参考:Python + selenium 元素定位(五)-----css selector 的高级用法
示例:
如下示例是打开百度首页,搜索”春节“,然后点击”百度首页“返回百度首页,在首页中点击”帮助中心“进入帮助中心页面
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
if __name__ =="__main__":# 定义一个WebDriver对象
driver = webdriver.Chrome()# 打开百度首页
driver.get("https://www.baidu.com/")# 常用的属性定位方式来定位搜索框# we = driver.find_element(By.ID, "kw") # 根据ID属性定位搜索框# we = driver.find_element(By.NAME, "wd") # 根据NAME属性定位搜索框# we = driver.find_element(By.CLASS_NAME, "s_ipt") # 根据CLASS_NAME属性定位搜索框# 通过CSS选择器定位搜索框# we = driver.find_element(By.CSS_SELECTOR, "#kw") # '#'符号表示id,#kw表示id="kw"# we = driver.find_element(By.CSS_SELECTOR, ".s_ipt") # '.'符号表示class,.s_ipt表示class="s_ipt"# we = driver.find_element(By.CSS_SELECTOR, '[autocomplete="off"]') # []内指定属性及其值,表示根据属性来定位元素# 通过xpath定位搜索框
we = driver.find_element(By.XPATH,"//input[@id='kw']")# 往搜索框里输入”春节“的搜索内容
we.send_keys("春节")
time.sleep(3)# 精准匹配a标签的文本内容”百度首页“,然后点击,进入百度首页
we1 = driver.find_element(By.LINK_TEXT,"百度首页")
we1.click()
time.sleep(2)# 模糊匹配a标签的文本内容包含”帮助“,点击,进入 帮助中心 页面
we2 = driver.find_element(By.PARTIAL_LINK_TEXT,"帮助")
we2.click()
time.sleep(2)# 终止相关进程
driver.quit()
find_elements()
find_element(by=By.ID, value=None)
是返回单个的WebElement对象,
find_elements(by=By.ID, value=None)
是返回一个列表(List)对象,列表中都是WebElement对象。
如图,想获取百度首页的百度热搜下词条内容,当前页面一共有6条,find_element()肯定不符合预期,find_elements()满足要求。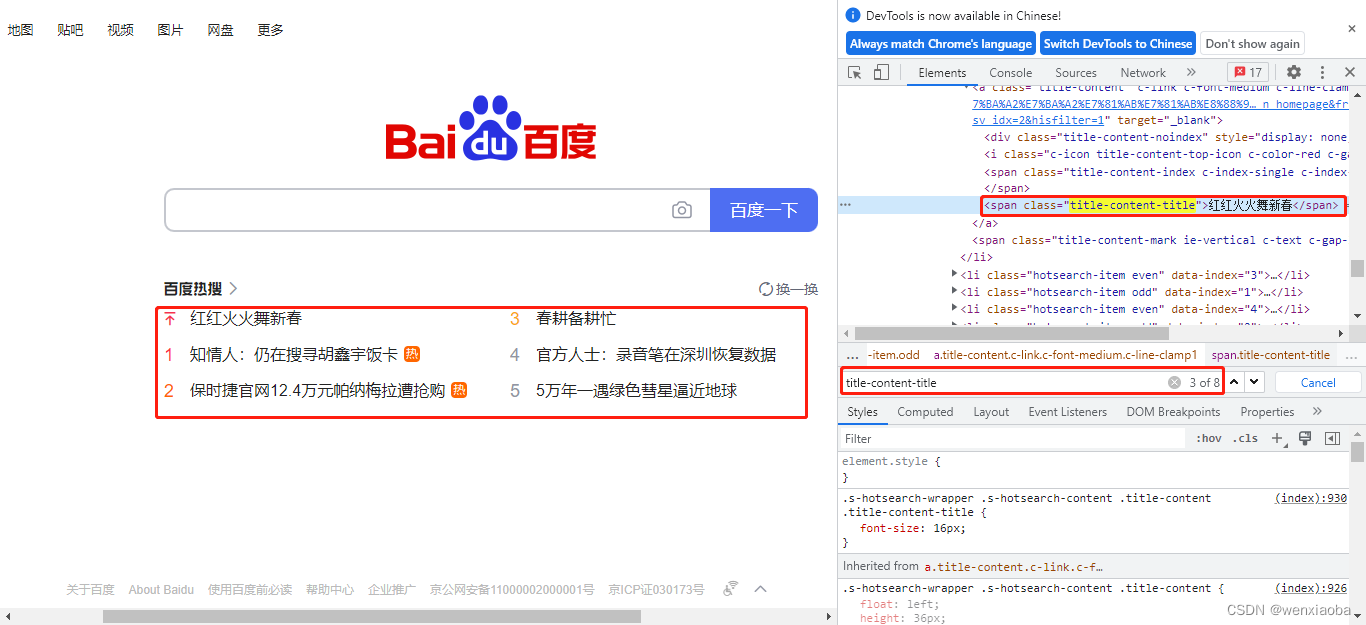
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
if __name__ =="__main__":# 定义一个WebDriver对象
driver = webdriver.Chrome()# 打开百度首页
driver.get("https://www.baidu.com/")# 通过class属性定位元素
wes = driver.find_elements(By.CLASS_NAME,"title-content-title")print(f"find_elements()返回的数据类型是:{type(wes)}")for we in wes:print("----------------------------")print(we)print(we.text)
time.sleep(3)# 终止相关进程
driver.quit()
执行结果如下:
find_elements()返回的数据类型是:<class 'list'>
----------------------------
<selenium.webdriver.remote.webelement.WebElement (session="daf7a5e628209860b164358803cd4801", element="02a46e1c-eeed-446d-b78f-2fd261c5d189")>
红红火火舞新春
----------------------------
<selenium.webdriver.remote.webelement.WebElement (session="daf7a5e628209860b164358803cd4801", element="c7fe0312-9739-4256-ae6b-6be8a4d5f610")>
春耕备耕忙
----------------------------
<selenium.webdriver.remote.webelement.WebElement (session="daf7a5e628209860b164358803cd4801", element="b2effc84-5b55-4cfc-814c-3d8509f30647")>
知情人:仍在搜寻胡鑫宇饭卡
----------------------------
<selenium.webdriver.remote.webelement.WebElement (session="daf7a5e628209860b164358803cd4801", element="bb8af466-32ad-45c4-b9e2-e2eb1af0bb6f")>
官方人士:录音笔在深圳恢复数据
----------------------------
<selenium.webdriver.remote.webelement.WebElement (session="daf7a5e628209860b164358803cd4801", element="fdfeb919-1070-4c04-9e71-e6c17975efcd")>
保时捷官网12.4万元帕纳梅拉遭抢购
----------------------------
<selenium.webdriver.remote.webelement.WebElement (session="daf7a5e628209860b164358803cd4801", element="4ea5b289-73a5-4cf2-8782-06d8ad08e1f3")>
5万年一遇绿色彗星逼近地球
元素操作
我们获取到元素之后,需要对元素进行操作,比如在输入框中输入内容,点击按钮等操作。
WebElement对象有多个属性和方法,但常用的就几个:
WebElement常用属性:
属性属性描述size高和宽rect高、宽和xy坐标tag_name标签名称
text
文本内容
WebElement常用方法:
属性属性描述
send_keys()
输入内容(对同一个元素多次进行,除非是页面自有的逻辑,否则是按照追加的方式输入的)clear()清空内容
click()
单击,如果单击后,当前标签页跳转页面时,WebDriver对象会更新为当前跳转后的页面,如果是新标签页打开其他页面时,WebDriver对象还是在原标签页,不会更新为新标签页get_attribute()获得属性值is_selected()是否被选中is_enabled()是否可用is_displayed()是否显示
实例:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
if __name__ =="__main__":# 定义一个WebDriver对象
driver = webdriver.Chrome()# 打开百度首页
driver.get("https://www.baidu.com/")# 定位 搜索输入框
search = driver.find_element(By.ID,"kw")# 在搜索输入框中输入“百度翻译”,百度首页会自动搜索
search.send_keys("百度翻译")
time.sleep(3)# 清空搜索框的内容
search.clear()
time.sleep(3)# 定位 “百度首页”
more = driver.find_element(By.LINK_TEXT,"更多")print("”更多“的部分方法值:")print(f"get_attribute():{more.get_attribute('href')}")print(f"is_selected():{more.is_selected()}")print(f"is_enabled():{more.is_enabled()}")print(f"is_displayed():{more.is_displayed()}")print("\n“更多“的部分属性值:")print(f"size值:{more.size}")print(f"rect值:{more.rect}")print(f"tag_name值:{more.tag_name}")print(f"text内容:{more.text}")# 点击”更多“
more.click()
time.sleep(3)# 终止相关进程
driver.quit()
等待
在打开网页时,某些内容会立马显示,但是有些内容显示的又比较慢,当网速卡的时候,页面就更慢显示了,但是程序执行的速度又是非常快的,就会导致一个问题:页面元素还在加载中,程序(代码)就去定位元素了,导致程序定位失败、退出执行。
为了避免这种情况发生,我们在定位元素前,就设置一定的延迟时间,尽量让相关元素显示后再去定位元素,可以有效的降低程序失败的情况发生。
有3种等待方式:
- 直接等待:
time.sleep(秒数),即直接等待指定的秒数再执行后续语句,不够灵活 - 隐式等待:WebDriver().implicitly_wait(秒数),每0.5秒轮询查找元素,如果在指定的时间内找到了元素,则继续执行,如果没有找到,则报错,是针对该WebDriver对象的find_element()和find_elements(),相当于全局的,没有对元素的“个性化”,不太建议使用
- 显示等待:
直接等待
直接等待,也叫强制等待,就是必须等待指定的时间,才执行下一步。需要导入
time
,使用
time.sleep(秒数)
。除非页面特有的逻辑(比如非会员必须观看30秒广告等),否则不建议大量使用time.sleep()方法。
示例:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
if __name__ =="__main__":# 定义一个WebDriver对象
driver = webdriver.Chrome()# 打开百度首页
driver.get("https://www.baidu.com/")# 直接等待2秒
time.sleep(2)# 点击更多,跳转到百度应用列表页面
driver.find_element(By.LINK_TEXT,"更多").click()#等待2秒后,关闭浏览器进程
time.sleep(2)
driver.quit()
隐式等待
隐式等待是在WebDriver对象上设置并生效的,当WebDriver对象通过
implicitly_wait(秒数)
方法设置了隐式等待的时间后,通过当前WebDriver对象使用的
find_element()
和
find_elements()
方法时,会每个一段时间(0.5秒)去页面查找,查找到后直接进行下一步,没有查找到则继续查询,若超过了设置的等待时间还没找到对应的元素,则直接报错。
隐式等待相当于全局性的,即WebDriver对象一次设置,对其调用的
find_element()
和
find_elements()
方法都生效。
隐式等待的时间设置比较方便,但是对于某些场景又不合适,设置的等待时间需要考虑到所有用到元素的最大的等待时间,但是一个页面中,不同的功能所需的时间又不一样,比如上传\下载文件和页面元素加载所花费的时间显然时不在同一个阶段的(比如上传完一个大容量视频后的视频上传成功提示元素和只是单纯在页面显示文字,显然后者能很快显示),隐式时间设置过长时,若被测产品运行有问题,会导致执行时间的拉长,不利于自动化等的批量执行和总体分析。
示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
if __name__ =="__main__":# 定义一个WebDriver对象
driver = webdriver.Chrome()# 打开百度首页
driver.get("https://www.baidu.com/")# 设置隐式等待的时间
driver.implicitly_wait(12)# 在搜索输入框中输入“一人之下”
driver.find_element(By.ID,"kw").send_keys("一人之下")# 点击搜索页中,搜索输入框左侧的百度图标回到百度首页
driver.find_element(By.ID,"result_logo").click()# 关闭浏览器进程
driver.quit()
显示等待
显示等待与隐式等待正好相反,显示等待是针对某一个元素的,不是全局性质的,当然,定位元素过多的时候,又觉得一次性设置的隐式等待很香O(∩_∩)O。
显示等待使用的是
WebDriverWait
对象的
until()
和
until_not()
方法(可以说是
WebDriverWait
的左右护法了)
显示等待中,等待的时间设置是在创建WebDriverWait对象时:
WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)参数说明:
- driver:WebDriver对象
- timeout:等待时间,即超时时间,如果在指定时间内没有找到,则报错
- poll_frequency:轮询查找的时间,单位为秒,默认0.5秒
WebDriverWait对象的until()和until_not()方法则用来判断是否继续执行
until(method, message="")和
until_not(method, message="")参数说明:
- method:函数名(函数必须要有一个参数) - until():如果函数执行返回的是False(或0或None或空列表、空集合等等所有不为真的数据),则TimeoutException报错,若返回的数据为真,则执行下一句- until_not():与until()相反,若函数返回为真的数据,则TimeoutException报错,若函数返回不为真的数据,则执行下一句
- message:若函数执行返回了不为真的数据,则TimeoutException报错时,报错信息为message
until()的示例:
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
if __name__ =="__main__":# 定义一个WebDriver对象
driver = webdriver.Chrome()deffun1(x):returnTruedeffun2(x):returnFalse
wd = WebDriverWait(driver,3)
wd.until(fun1,"方法fun1返回了假")print("fun1执行完成,找到元素")
wd.until(fun2,"方法fun2返回了假")print("fun2执行完成,找到元素")# 终止相关进程
driver.quit()
执行结果如下:
fun1执行完成,找到元素
Traceback (most recent call last):
File "G:\python_project\web\demo.py", line 14, in <module>
wd.until(fun2, "方法fun2返回了假")
File "G:\python_project\web\lib\site-packages\selenium\webdriver\support\wait.py", line 95, in until
raise TimeoutException(message, screen, stacktrace)
selenium.common.exceptions.TimeoutException: Message: 方法fun2返回了假
从执行结果来看,程序并没有执行到
print("fun2执行完成,找到元素")
,
wd.until(fun2, "方法fun2返回了假")
这一步报错了,并打印了我们传入的message内容
until_not()示例
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
if __name__ =="__main__":# 定义一个WebDriver对象
driver = webdriver.Chrome()deffun1(x):returnTruedeffun2(x):returnFalse
wd = WebDriverWait(driver,3)
wd.until_not(fun2,"方法fun2返回了真")print("fun2执行完成,找到元素")
wd.until_not(fun1,"方法fun1返回了真")print("fun1执行完成,找到元素")# 终止相关进程
driver.quit()
执行结果如下:
fun2执行完成,找到元素
Traceback (most recent call last):
File "G:\python_project\web\demo.py", line 14, in <module>
wd.until_not(fun1, "方法fun1返回了真")
File "G:\python_project\web\lib\site-packages\selenium\webdriver\support\wait.py", line 118, in until_not
raise TimeoutException(message)
selenium.common.exceptions.TimeoutException: Message: 方法fun1返回了真
从以上2个示例来看,如果想要做到显示等待某个元素,我们需要在
until()
和
until_not()
中传入method参数来实现,method参数传入的是函数,函数中需要实现对元素是否存在的判断,示例如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
if __name__ =="__main__":# 定义一个WebDriver对象
driver = webdriver.Chrome()# 打开百度翻译页面,翻译triggered
driver.get("https://fanyi.baidu.com/#en/zh/triggered")defshow_banner(x):# 只有在有翻译的时候才会显示广告位returnlen(driver.find_elements(By.CLASS_NAME,"app-side-banner"))>0
wd = WebDriverWait(driver,3)
wd.until(show_banner,"未显示广告位")print("显示了广告位")# 终止相关进程
driver.quit()
show_banner(x)实现了判断某个元素存不存在逻辑,until()方法传入了show_banner函数,相当于在3秒内查询该元素存不存在,不存在则报错,执行结果如下:
显示了广告位
从执行结果来看,确实显示了广告位
但是如果每一个元素都需要实现一个函数(或者使用匿名函数),岂不是很麻烦,所以selenium也提供了一系列元素判断方法,这些方法封装在了expected_conditions中,使用示例如下:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions
if __name__ =="__main__":# 定义一个WebDriver对象
driver = webdriver.Chrome()# 打开百度翻译页面
driver.get("https://fanyi.baidu.com/#en/zh")# 首次打开百度翻译页面,有百度翻译的引导弹窗,等待弹窗显示后,关闭该弹窗# 确定引导弹窗显示
WebDriverWait(driver,4).until(expected_conditions.element_to_be_clickable((By.CLASS_NAME,"app-guide-close")))# 点击引导弹窗的关闭按钮,关闭引导弹窗
driver.find_element(By.CLASS_NAME,"app-guide-close").click()# 为了确认是否关闭了引导弹窗,强制等待3秒查看效果(人眼查看)
time.sleep(3)# 使用expected_conditions下的visibility_of_element_located()判断广告位是否不存在,不存在返回True
banner_show = expected_conditions.visibility_of_element_located((By.CLASS_NAME,"app-side-banner"))print("广告位不存在"if banner_show else"广告位存在")# 终止相关进程
driver.quit()
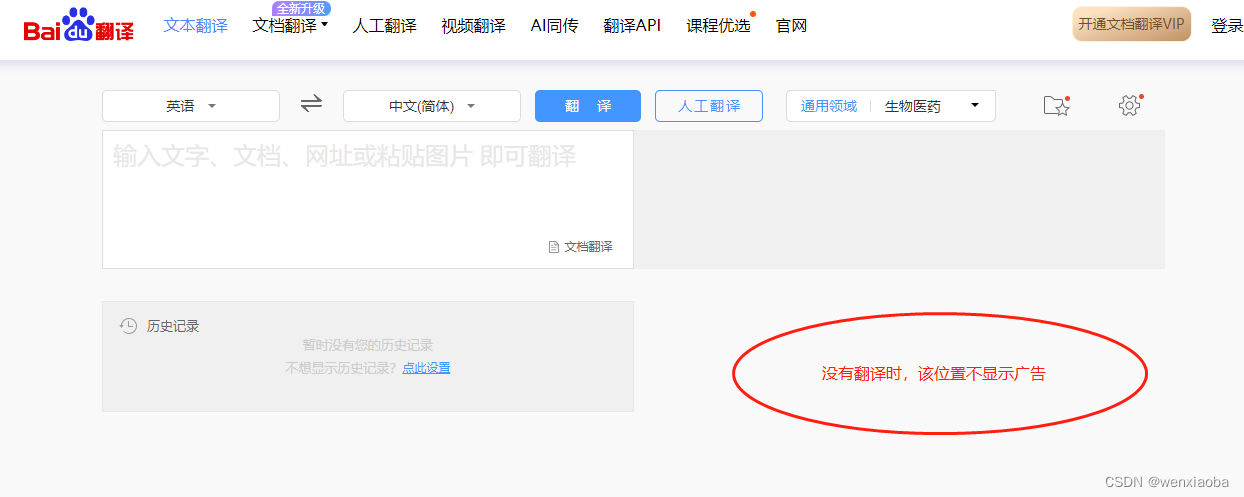
执行结果如下:
广告位不存在
expected_conditions
有提供了很多方法,基本上从方法名可以判断出来,详细的可以网上找找,这里不详细展开了,可以去selenium官网查看,也可以参考的一些博客,如下:
selenium自动化测试(八)-- expected_conditions详解
selenium中的expected_conditions模块详解
selenium细节实战02–>好用的expected_conditions模块
等待说明
三种等待方式可以混合使用,虽然expected_conditions的诸多方法底层其实是调用了find_element()方法,但implicitly_wait()和WebDriverWait()一起使用时,等待时间是两者间设置时长最长的那个(貌似说不能混合使用,但是我混了后还没报错。。。暂时就先不管了)
版权归原作者 wenxiaoba 所有, 如有侵权,请联系我们删除。