
消息队列zookeeper集群+kafka
kafka 3.0之前依赖于zookpeeper
zookeeper开源分布式架构,提供协调服务(Apache项目)
基于观察者模式设计的分布式服务管理架构
存储和管理数据。分布式节点的服务结束观察者的注册,一旦分布式节点上的数据发生变化,由zookeeper来负责通知分布式节点上的服务
kafka1+zookpeeper1
Kafka+zookpeeper2
kafka3+zookpeeper3

主要用于大数据分析场景
zookpeeper分为领导者 追随者 ieader和follower组成的集群
只要由半数以上的集群存活zookeeper集群就可以正常工作,适用于安装奇数台的集群
全局数据一致,每个zookpeeper么个节点都保存相同的数据,维护监控的服务数据一致
数据更新的原子性,要么都成功,要么都失败
实时性,只要有变化,立刻同步
zookpeeper的应用场景
1、统一命名服务,在分布式的环境下,对所有的应用和服务进行统一命名
2、统一配置管理,配置文件同比,kafka的配置文件被i修改,可以快速同步到其他节点
3、统一集群管理,实时掌握所有节点的状态
4、服务器动态上下线
5、负载均衡,把访问服务器的数据发送到访问最少的服务器处理
领导者和追随者:zookpeeper的选举机制
三台服务器 A B C
A先启动,发起一次选举,投票给自己,只有1票,不满半数,A的状态是looking
B启动,在发起一次选举,A和B分别投自己一票,交换选票信息,myid,A发现B的myid比A大,A的这一票转而投给B
A 0 B2 没有半数以上结果 A B会进入looking
C启动 MYID c的myid最大 A和B都会把票投给C
A是0 B是0 C是3
C的状态变为leader,A和B会变为follower
只要leader确定,后续的服务器都是追随者
1、初始化
2、服务器之间和leader丢失了连接状态
特殊情况
leader已经存在建立连接即可
leader不存在或者挂了,
1、服务器ID大的会胜出
2、EPOCH大,直接胜出
3、如EPOCH相同,事务id大的会胜出
EPOCH是每个leader任期的代号,如果没有leader,大家的逻辑地位是相同的,每投完一次数据是递增的
事务id,就是用来标识服务器的每一次变更,每变更一次,事务id会变化一次
服务器id,是用来标识zookpeeper集群当中的机器都有一个id,每台机器不重复和myid
保持一致
zookeeper集群+kafka(2.7.0)
kafka(3.4.1)
zookeeper集群+kafka(2.7.0)实现过程
1、zookeeper集群
三台服务器
20.0.0.140:zookeeper+kafka
20.0.0.141:zookeeper+kafka
20.0.0.142:zookeeper+kafka
tickTime=2000
服务器和客户端之间心跳时间,2秒检测一次服务器和客户端之间的通信
initLimit=10
领导者和追随者之间初始连接时能够容忍的超时时间 10*2s 20s
syncLimit=5
同步超时时间,领导者和追随者之间,同步通信超时的时间,5*2s 10s,超过这个时间leader就会任务follower丢失,会把它移除集群
dataDir=/tmp/zookeeper
保存数据的目录要单独创建
clientPort=2181
客户端端口2181
server.1=20.0.0.140:3188:3288
1是每个zookeeper集群的初始myid,
20.0.0140:服务器的ip地址
3188:领导者和追随者之间交换信息的端口(内部通信端口)
3288:一旦leader丢失响应,开启选举,3288就是用来进行选举时服务器通信端口
消息队列kafka
为什么要引入消息队列(mq)他也是一个中间件,在高并发环境下,同步请求来不及处理,来不及处理的请求会形成阻塞
比方说数据库就会形成行锁或者表锁,请求线程满了,超标了,too many connection整个系统雪崩
消息队列的作用:异步处理请求,流量肖锋 应用解耦
解耦
耦合:在系统当中,修改一个组件需要修改所有其他组件,高度耦合
低度耦合:改一个组件,对其他组件影响不大,无需修改所有
只要通信保证,其他的修改不影响整个集群,每个组件可以独立的扩展,修改,降低的组件之间的依赖性
依赖点的就是接口约束,通过不同端口,保证集群通信。
可恢复性:系统当中的有一部分组件小时,不影响整个系统,也就是消息队列当中,即使一个处理消息的进程失败,一旦恢复还可以重新加入到队列当中继续处理消息。
缓冲:可以控制和优化数据经过系统的时间和速度,解决生产消息和消费消息处理速度不一致的问题
峰值处理能力:消息队列在峰值情况之下,能够顶住突发的访问压力,避免专门为了突发情况而对系统进行修改
核心异步通信:允许用户把一个消息放入队列,但是不立即处理,等用户象处理时在处理。
消息队列的模式:
点对点 一对一:消息的生产者发送消息到队列中,消息者从队列中提取消息,消息者提取完消息之后,队列中被提取的消息将会被移除
续消费者不能再队列当中的消息,消息队列可以有多个消费者,但是一个消息,只能有一个消费者提取。
RABBITMQ
发布/订阅模式:一对多,又叫做观察者模式,消费者提取数据之后队列当中的消息不会被清除
生产者发布一个消息到主题,所有消费者都是通过主题获取消息。
主题:topic topic类似一个数据管道,生产者把消息发布到主题,消费者从主题当中订阅数据。每一个主题可以分区,每个分区都有自己的偏移量
分区:partition 每个主题都可以分成多个分区。每个分区都是数据的有序子集,分区可以允许kafka进行水平拓展,以处理大量数据
消息再分区中按照偏移量存储,消费者可以独立读取每个分区的数据
偏移量:是每个消息再分区中的唯一标识,消费者可以通过偏移量来跟踪获取已读或者未读消息的位置,也可以提交偏移量来记录以处理的信息

其他的组件
生产者:producer生产者把数据发送到kafka主题当中,负责写入消息
消费者:consumer 从主题当中读取数据消费者可以是一个或者多个。每一个消费者都有一个消费者组id,kafka通过消费者来实现负载均衡和容错性
经纪人:broker每个kafka节点都有一个 borker,每个负责一台kafka,id唯一,存储主题分区当中数据,处理生产和消费者的请求,
维护元数据(zookeeper)
zookeeper:zookeeper负责保存元数据,元数据就是topic的相关信息,(发布在哪台主机上,指定了多少分区,以及副本数,偏移量)
zookeeper自建一个主题:_consumer_offsets.
3.0之后不依赖zookeeper的核心就是元数据由kafka自己管理
kafka的工作流程:
roker.id=1
broker.id=2
broker.id=3
num.network.threads=3
处理网络请求的线程数量默认即可
num.io.threads=8
处理磁盘的io线程数量,一定要比磁盘数大
socket.send.buffer.bytes=102400
发送套接字的缓冲区大小
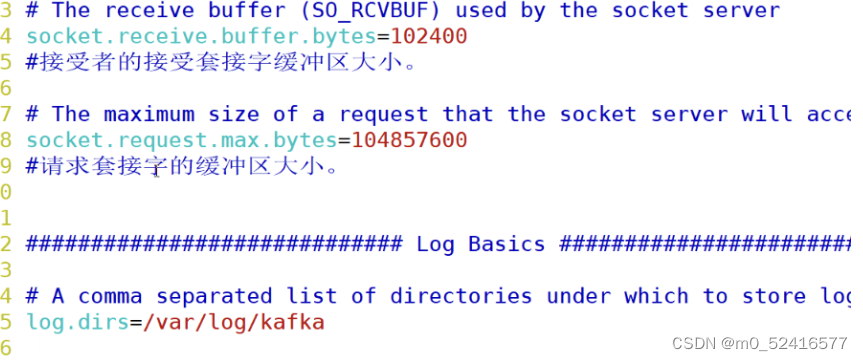
socket.receive.buffer.bytes=102400
接收者的接受套接字缓冲区大小
socket.request.max.bytes=104857600
请求套接字的缓冲区大小
log.dir=/var/log/kafka
num.partitions=1
再次kafka服务器上创建topic,默认分区数,如果指定了,这个配置无效
num.recovery.threads.per.data.dir=1
用来恢复,回收,清理data下的数据的线程数量,kafka默认不允许删除主题

log.retention.hours=168
生产者发布的数据文件在主题当中保存的时间。168小时
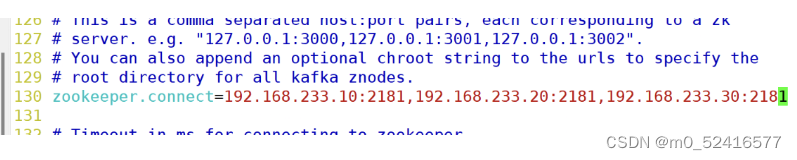
zookeeper.connect=20.0.0.140:2181,20.0.0.141:2181,20.0.0.142:2181
vim /etxc/init.d/kafka
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/opt/kafka'
case $1 in
start)
echo "---------- Kafka 启动 ------------"
${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)
echo "---------- Kafka 停止 ------------"
${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)
$0 stop
$0 start
;;
status)
echo "---------- Kafka 状态 ------------"
count=$(ps -ef | grep kafka | egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
echo "kafka is not running"
else
echo "kafka is running"
fi
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
cd bin
cd /opt/kafka/bin
kafka-topics.sh --create --zookeeper 20.0.0.140:2181,20.0.0.141:2181,20.0.0.142 --replication-factor 2 --partitions 3 --topic test1
--topic test1:指定主题名称
创建主题
1、再kafka的bin目录下创建,bin目录是所有的kafka可执行命令文件
2、--zookeeper 指定是zookeeper的地址和端口,保存kafka的元数据
3、--replication-factor 2:定义每个分区的副本数
4、--partitions 3 :指定主题的分区数
5、--topic test1 指定主题的名称
如何查看topic的详情
kafka-topics.sh --describe --zookeeper 20.0.0.140:2181,20.0.0.141:2181,20.0.0.2181
Partition:分区编号
Leader:每个分区都有一个领导者(Leader),领导者负责处理分区的读写操作。
在上述输出中,领导者的编号分别为 3、1、3。
Replicas:每个分区可以有多个副本(Replicas),用于提供冗余和容错性。
在上述输出中,Replica 3、1、2 分别对应不同的 Kafka broker。
Isr:ISR(In-Sync Replicas)表示当前与领导者保持同步的副本。
ISR 3、1分别表示与领导者同步的副本。
主题映射三台服务器做主题映射
k1
20.0.0.140 test1
20.0.0.141 test2
20.0.0.142 test3
如何发布消息
kafka-console-producer.sh --broker-list 20.0.0.140:9092,20.0.0.142:9092,20.0.0.141:9092 --topic test1
如何消费
kafka-console-consumer.sh --bootstrap-server 20.0.0.140:9092,20.0.0.141:9092,20.0.0.142:9092 --topic test1 --from-beginning
如何实时获取
修改分区数
kafka-topics.sh --zookeeper 20.0.0.20:2181 --alter --topic gq1 --partitions 3
kafka-topics.sh --describe --zookeeper 20.0.0.20:2181 --alter --topic gq1
kafka-topics.sh --delete --zookeeper 20.0.0.140:2181 --topic gq1
如何查看元数据信息
cd /opt/zookeeper/bin
1、zookeeper:主要是分布式,观察者模式,统一各个服务器节点的服务器
再kafka当中,收集保存kafka的元数据
2、kafka消息队列订阅发布模式
rabbit mq (实现rabbit mq 消息队列)****
版权归原作者 m0_52416577 所有, 如有侵权,请联系我们删除。