
文章目录
前言
本文对如何开发基于spark和Hadoop的大数据分析平台进行了广泛和深入的研究,其范围包括python爬虫、Java、spark离线数据分析、Hadoop。
Spark的四大优点
- 快:与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上;而基于磁盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效地处理数据流。
- 容易使用:Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同应用。而且Spark支持交互式的Python和Scala的Shell,这意味着可以非常方便的在这些Shell中使用Spark集群来验证解决问题的方法,而不是像以前一样,需要打包、上传集群、验证等。这对于原型开发非常重要。
- 通用性:Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(通用Spark SQL)、实时流处理(通过Spark Streaming)、机器学习(通过Spark MLlib)和图计算(通过Spark GraphX)。 这些不同类型的处理都可以在同一应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台处理问题,减少开发和维护的人力成本和部署平台的物理成本。当然还有,作为统一的解决方案,Spark并没有以牺牲性能为代价。相反,在性能方面Spark具有巨大优势。
背景
房地产数据是非常有价值的数据资源,可以帮助政府监管房地产市场、协助开发商决策、指导银行贷款和投资决策等。而 Spark 作为大数据处理框架,可以处理大规模的房地产数据,进行数据分析、预测和挖掘,为房地产业提供更多的洞察和启示。
数据介绍
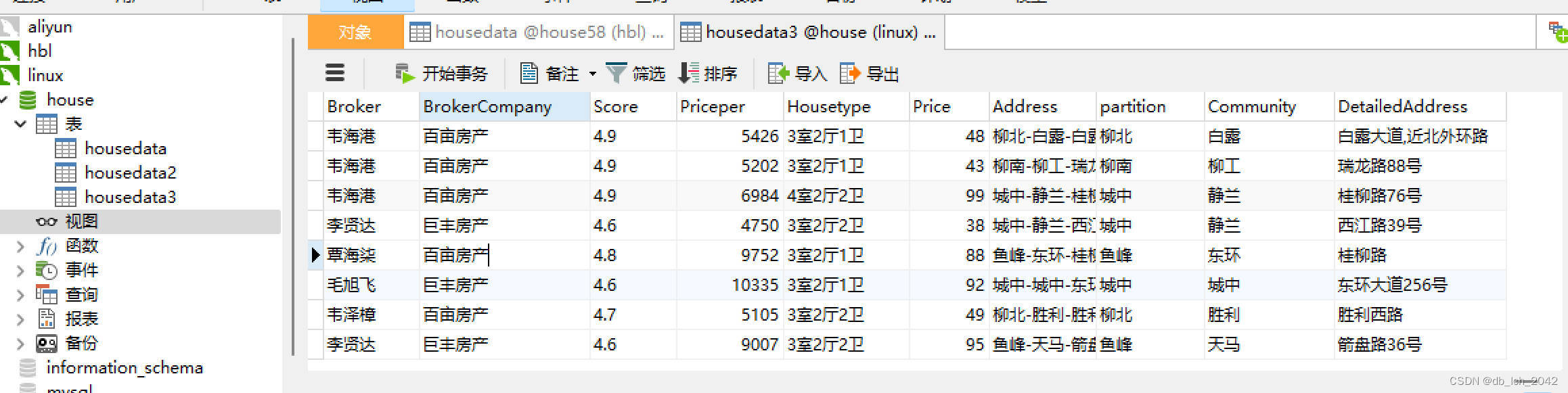
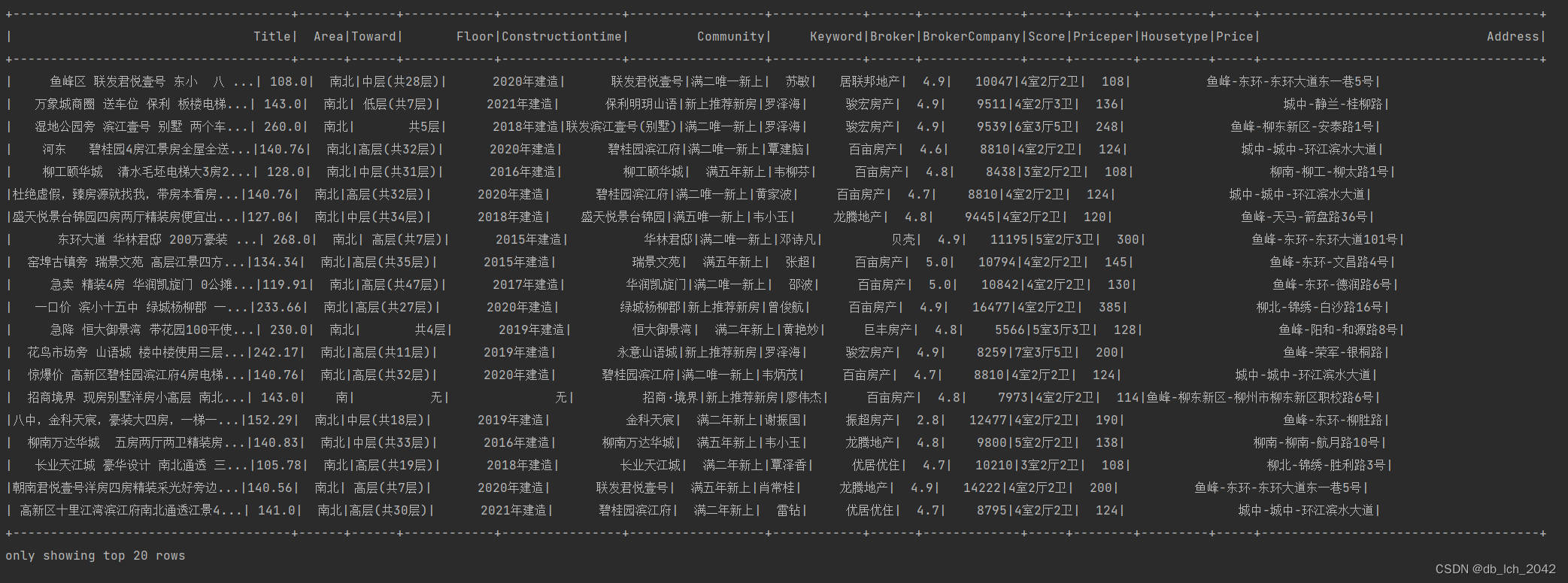
数据是58同城网站爬虫爬取的数据并在python中数据清洗 导入到mysql数据库,数据如下

指标介绍
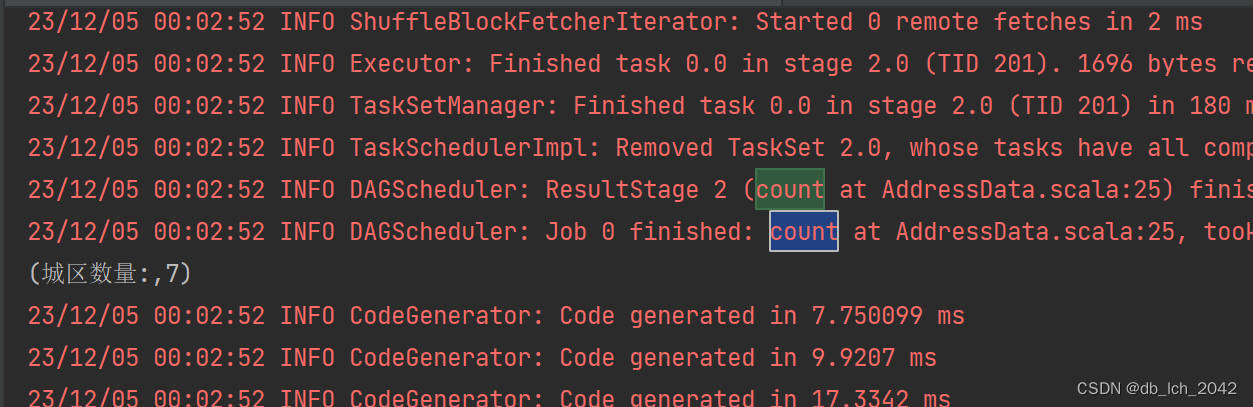
1.城区和街道进行数量统计,分析房产分布和热门地区。
主要步骤介绍
- 地址信息分离: 通过
split函数将原始地址字段分离为不同的部分,例如城市、社区和详细地址,并将这些信息分别存储在新的列中,如“partition”、“Community”和“DetailedAddress”。- 统计城区数量: 使用
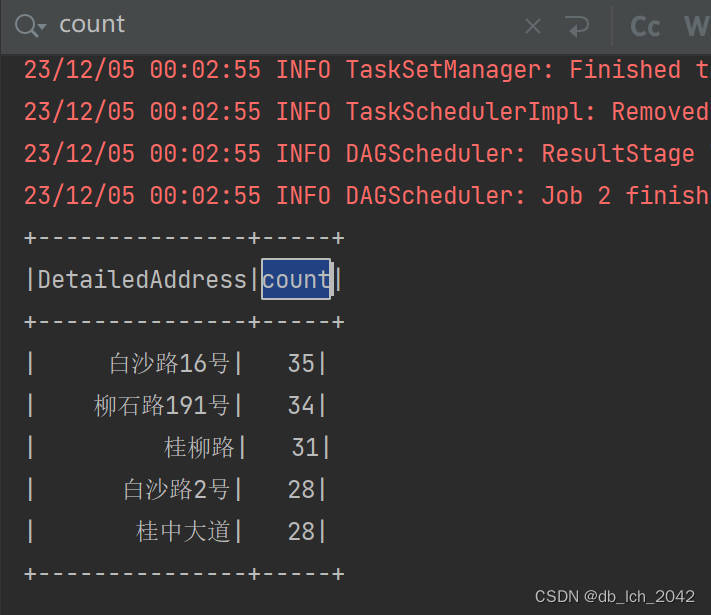
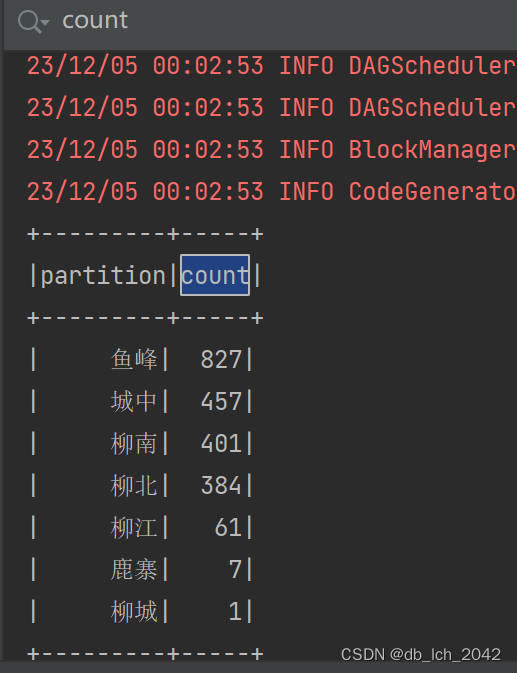
distinct和count函数统计不同城区的数量,得到城区的唯一计数。- 计算热门城区和街道: 通过对城区和详细地址进行分组统计,计算每个城区和街道的房产数量。热门城区是按房产数量降序排列的所有城区列表,而热门街道是按房产数量降序排列并选择前五的街道列表。
- 数据写回: 提供了可选的代码片段,指示如何将分离后的结果写回到数据库,使用了
write.format和相应的数据库连接选项。
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
object AddressData {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder
.appName("AddressDataSeparation")
.master("local[*]")
.getOrCreate()
// 从数据库读取数据
val jdbcDF = spark.read.format("jdbc")
.option("url", "jdbc:mysql://xxxxxxxxxx:3306/house?useUnicode=true&characterEncoding=utf8&useSSL=false")
.option("dbtable", "housedata2")
.option("user", "root")
.option("password", "")
.load()
// 分离地址信息
val separatedDF = jdbcDF.withColumn("partition", split(col("Address"), "-").getItem(0))
.withColumn("Community", split(col("Address"), "-").getItem(1))
.withColumn("DetailedAddress", split(col("Address"), "-").getItem(2))
// 统计城区数量
val distinctCityCount = separatedDF.select("partition").distinct().count()
// 计算热门城区
val popularCities = separatedDF.groupBy("partition").count().orderBy(desc("count"))
// 计算热门街道
val popularStreets = separatedDF.groupBy("DetailedAddress").count().orderBy(desc("count")).limit(5)
println("城区数量:",distinctCityCount)
//热门城区
popularCities.show()
//热门街道
popularStreets.show()
//显示分离结果
separatedDF.show()
//可以选择将分离后的结果写回数据库
separatedDF.write.format("jdbc")
.option("url", "jdbc:mysql://your_mysql_host:port/your_database")
.option("dbtable", "new_table")
.option("user", "your_username")
.option("password", "your_password")
.save()
spark.stop()
}
}
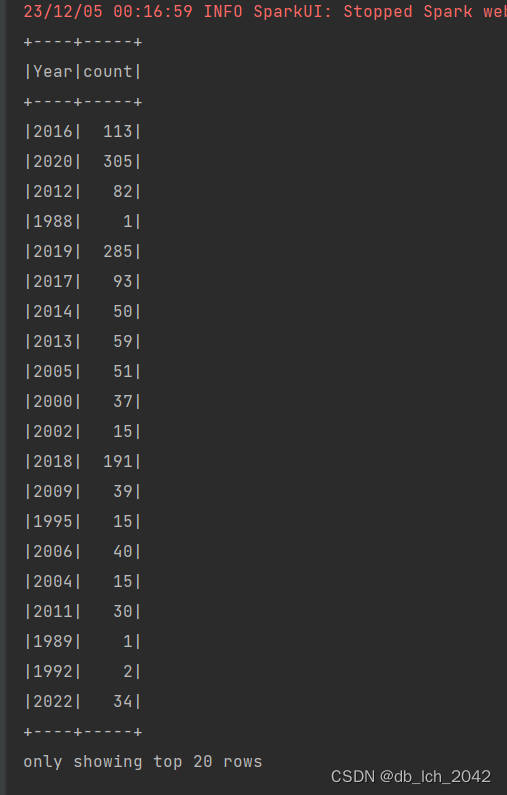
2.分析房产数据表中不同建造年份的房产数量情况
主要步骤介绍
- 提取年份信息: 通过对建造时间字段进行处理,使用
substring函数提取了年份信息,并创建了一个名为 "Year" 的新列。- 按年份分组计数: 对提取出的年份信息进行分组,并使用
groupBy和count方法计算每个年份出现的次数,即统计了每个年份对应的房产数量。
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
object ConstructionYear {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder
.appName("ConstructionYearStatistics")
.master("local[*]")
.getOrCreate()
// MySQL连接信息
val mysqlHost = "xxxxxxxxxxxx"
val mysqlPort = 3306
val database = "house"
val tableName = "housedata2"
val username = "root"
val password = ""
// 读取MySQL数据库的建造时间信息
val jdbcUrl = s"jdbc:mysql://$mysqlHost:$mysqlPort/$database?useUnicode=true&characterEncoding=utf8&useSSL=false"
val connectionProperties = new java.util.Properties()
connectionProperties.put("user", username)
connectionProperties.put("password", password)
val df = spark.read.jdbc(jdbcUrl, tableName, connectionProperties)
// 提取年份信息并分组计数
val yearCounts = df.withColumn("Year", substring(col("Constructiontime"), 1, 4))
.groupBy("Year")
.count()
// 打印结果
yearCounts.show()
spark.stop()
}
}
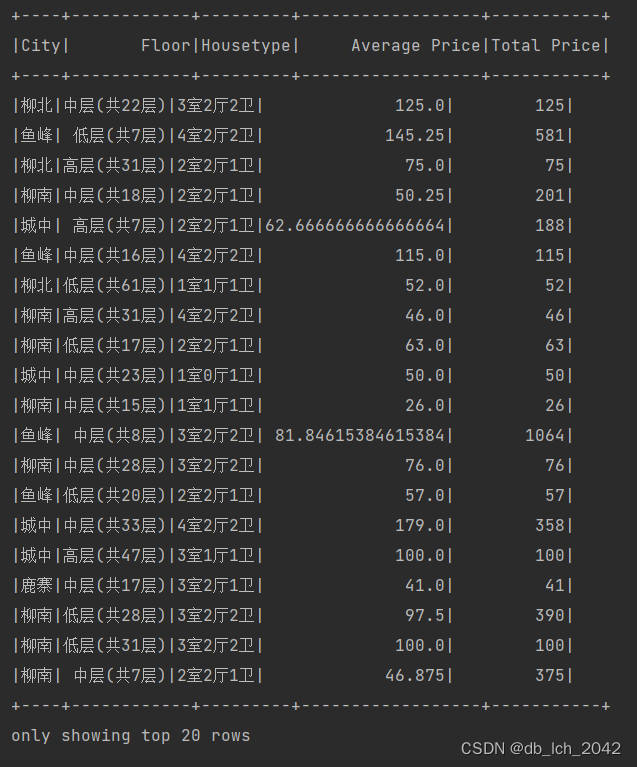
3.分析不同地区、楼层和户型的房产平均单价和总价的计算,高价房产的识别(价格超过 100 万),以及不同户型房产数量占总量的比例。
主要步骤介绍
- 按地区、楼层或户型分组计算平均单价和总价:- 使用
groupBy对地区、楼层和户型进行分组。- 使用agg函数计算每个组的平均单价和总价。- 识别高价房产:- 过滤出价格高于 100 万的房产数据。
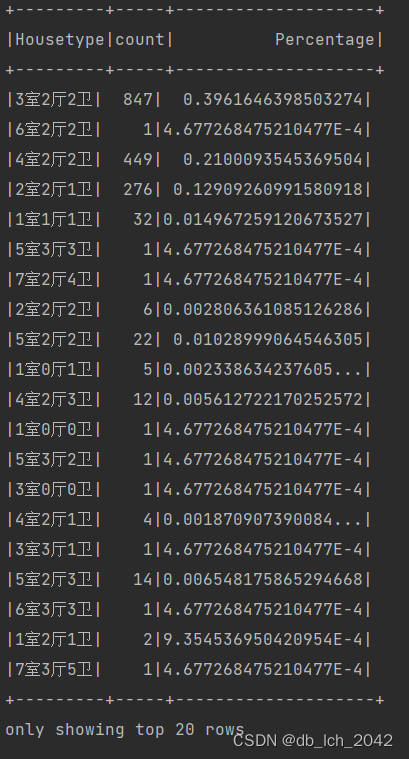
- 计算不同户型的房产数量占总量的比例:- 通过
groupBy对不同户型进行分组。- 使用count统计每种户型的数量。- 使用withColumn计算每种户型数量在总房产数量中的比例。
import org.apache.spark.sql.{SparkSession, functions => F}
import org.apache.spark.sql.functions._
object RealEstateAnalysis {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder
.appName("Real Estate Analysis")
.master("local[*]")
.getOrCreate()
import spark.implicits._
// 从数据库读取数据
val jdbcDF = spark.read.format("jdbc")
.option("url", "jdbc:mysql://xxxxxxxxx:3306/house?useUnicode=true&characterEncoding=utf8&useSSL=false")
.option("dbtable", "housedata2")
.option("user", "root")
.option("password", "")
.load()
// 分离地址信息
val separatedDF = jdbcDF.withColumn("City", split(col("Address"), "-").getItem(0))
.withColumn("Community", split(col("Address"), "-").getItem(1))
.withColumn("DetailedAddress", split(col("Address"), "-").getItem(2))
// 1.按地区、楼层或户型分组计算平均单价和总价
val averagePriceAnalysis = separatedDF
.groupBy($"City", $"Floor", $"Housetype")
.agg(
F.avg($"Price").as("Average Price"),
F.sum($"Price").as("Total Price")
)
// 2. 识别高价房产(这里假设阈值是100万)
val highValueProperties = jdbcDF.filter($"Price" > 100)
// 3. 计算不同户型的房产数量占总量的比例
val housetypeComposition = jdbcDF
.groupBy($"Housetype")
.count()
.withColumn("Percentage", $"count" / F.sum("count").over())
// // 显示结果
averagePriceAnalysis.show()
highValueProperties.show()
housetypeComposition.show()
// 停止Spark会话
spark.stop()
}
}
总结
这些代码可以展示了如何使用Spark进行房地产数据分析。从分离地址信息到计算平均价格和高价房数量,再到不同户型的房产比例,这些指标为理解房产市场提供了重要见解。通过数据分析,可以更深入了解房产市场的地区趋势、价格分布和市场结构。这些工具和指标为房地产决策者提供了更全面的数据支持,帮助他们做出更明智的决策。
本文转载自: https://blog.csdn.net/qq_17347837/article/details/130718589
版权归原作者 db_lch_2042 所有, 如有侵权,请联系我们删除。
版权归原作者 db_lch_2042 所有, 如有侵权,请联系我们删除。