

什么是 Browserless?
Browserless 是一款基于云的浏览器解决方案,旨在实现高效的浏览器自动化、网页抓取和测试。
它利用 Nstbrowser 的指纹库,实现随机指纹切换,确保流畅的数据收集和自动化。得益于其强大的云基础设施,Browserless 简化了对多个浏览器实例的访问,从而更轻松地管理自动化任务。
您对网页抓取和 Browserless 有什么奇思妙想和疑问吗?
让我们看看其他开发者在 Discord 和 Telegram 上分享了什么!
Browserless 如何运作?
Browserless 通过提供一个无头浏览器服务来运作,允许用户在无需图形界面的情况下执行浏览器自动化任务。
它使开发者能够通过 API 运行基于浏览器的任务,例如网页抓取、自动化测试和渲染网页。通过在云环境中运行,Browserless 简化了浏览器自动化过程,无需手动设置或维护浏览器基础设施。
Browserless 支持 Puppeteer 和 Playwright 等流行库,允许用户以编程方式与网站交互。其基于 Docker 的基础设施支持可扩展和灵活的部署,使其适用于小型和企业级应用程序。它可以集成到工作流程中,以自动化重复性任务或从需要浏览器的网站收集数据。
如何在 Docker 中部署 Headlesschrome?
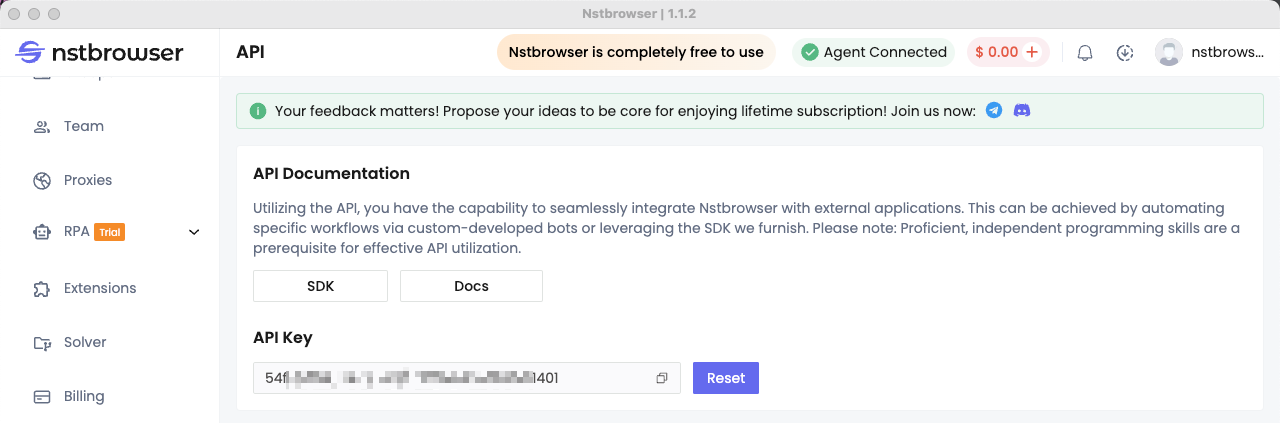
第 1 步:获取您的 API 密钥
为了获得更好的体验,请在 Nstbrowser 上创建一个新帐户。
使用您注册的信息登录 Nstbrowser 客户端。成功登录后,不要忘记从 API 菜单中生成您的唯一 API 密钥!
第 2 步:获取 Nstbrowserless 镜像并运行
您需要获取
API Key
并替换以下
{YOUR_API_KEY}
部分。
docker run -it -e TOKEN={YOUR_API_KEY} -e SERVER_PORT=8848 -p 8848:8848 --name nstbrowserless nstbrowser/browserless:0.0.1-beta

如何在 Docker 容器中使用 Browserless?
您可以通过 Puppeteer、Playwright、Chromedp 或其他 CDP 库连接到无头浏览器,以实现无头浏览器的操作和截图功能。
Puppeteer
Puppeteer 是一个 Node.js 库,它提供了一个高级 API 来控制 Chrome 浏览器,并支持通过 DevTools 协议进行操作。
安装 Puppeteer
npm install puppeteer
准备 puppeteer.js 文件
const puppeteer = require("puppeteer");
(async () => {
const host = "127.0.0.1:8848"; // 替换为您的 Docker 容器 IP
const browserWSEndpoint = `ws://${host}/ws/connect`;
try {
const browser = await puppeteer.connect({
browserWSEndpoint: browserWSEndpoint,
});
const page = await browser.newPage();
await page.goto("https://google.com", { waitUntil: 'networkidle2' }); // 等待网络空闲
await page.screenshot({ path: "screenshot.png", fullPage: true }); // 拍摄全页面截图
console.log("Screenshot taken and saved as screenshot.png");
await browser.close(); // 关闭浏览器连接
} catch (err) {
console.error("Error occurred:", err);
}
})();
运行您的脚本
node puppeteer.js
运行后,您可以看到无头浏览器按我们预期工作:

现在,项目已完成,您可以找出生成的
screenshot.png
:

Playwright CDP
Playwright 是一个用于 Web 测试和自动化的框架,允许通过单个 API 测试 Chrome 浏览器。
安装 Playwright
npm install playwright
准备 playwright.js 文件
import { chromium } from "playwright";
(async () => {
const host = "127.0.0.1:8848"; // 替换为您的 Docker 容器 IP
const browserWSEndpoint = `ws://${host}/ws/connect`;
try {
const browser = await chromium.connectOverCDP(browserWSEndpoint);
const context = await browser.newContext();
const page = await context.newPage();
await page.goto("https://www.google.com/", { waitUntil: 'networkidle' }); // 等待网络空闲
await page.screenshot({ path: "screenshot.png" }); // 拍摄全页面截图
console.log("Screenshot taken and saved as screenshot.png");
await browser.close(); // 关闭浏览器连接
} catch (err) {
console.error("Error occurred:", err);
}
})();
运行您的脚本
node playwright.js
与 Puppeteer 相同,运行后,您也可以找出生成的
screenshot.png
。

总结
Browserless 使网页抓取和自动化变得容易。在本博客中,您可以看到:
- 在 Docker 中部署 headlesschrome 的有效方法。
- 在 Docker 容器中使用 Browserless 的详细步骤。 在容器中运行浏览器提供了很大的灵活性和可扩展性。它也比传统的基于 VM 的实例便宜得多。
版权归原作者 wellshake 所有, 如有侵权,请联系我们删除。