
在flink-connector-jdbc中增加对国产数据库达梦(V8)的支持
本文将展示如何在flink-connector-jdbc中增加对国产数据库达梦(V8)的支持。演示基于Java语言,使用Maven。
1. 关于flink-connector-jdbc
flink-connector-jdbc是Apache Flink框架提供的一个用于与关系型数据库进行连接和交互的连接器。它提供了使用Flink进行批处理和流处理的功能,可以方便地将关系型数据库中的数据引入Flink进行分析和处理,或者将Flink计算结果写入关系型数据库。
flink-connector-jdbc可以实现以下核心功能:
- 数据源连接:可以通过flink-connector-jdbc连接到各种支持JDBC标准的关系型数据库,如MySQL、PostgreSQL、Oracle等。
- 数据写入:可以将Flink的计算结果写入关系型数据库中,实现数据的持久化。
- 数据读取:可以从关系型数据库中读取数据,并将其作为Flink计算的输入数据。
- 数据格式转换:可以将关系型数据库中的数据转换为适合Flink计算的数据格式。
- 并行处理:可以根据数据源的并行度将数据进行分区和并行处理,以加速数据处理的速度。
flink-connector-jdbc为Flink提供了与关系型数据库集成的能力,可以方便地进行数据的导入、导出和处理,为开发人员提供了更强大和灵活的数据处理能力。
2. flink-connector-jdbc包含对哪些关系型数据库的支持
截止目前,flink最新版到flink-1.17.1,但是不管是flink-1.17.0还是flink-1.17.1,都没有找到关于flink-connector-jdbc的实现,从flink-1.16.2中能相关实现找到;
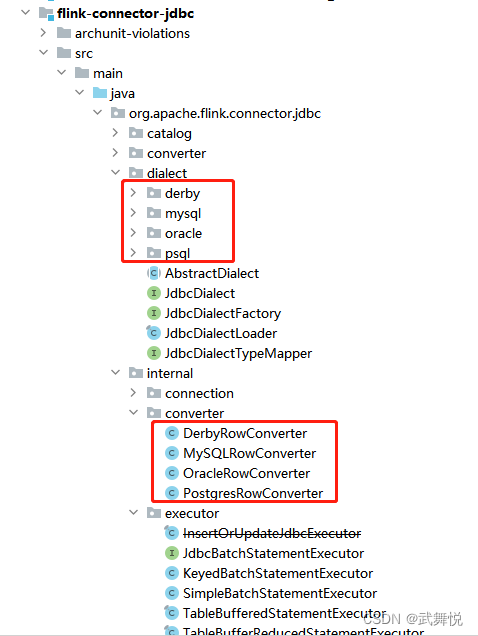
可以看到,flink-connector-jdbc目前只支持4种关系型数据库:derby、mysql、oracle、psql,
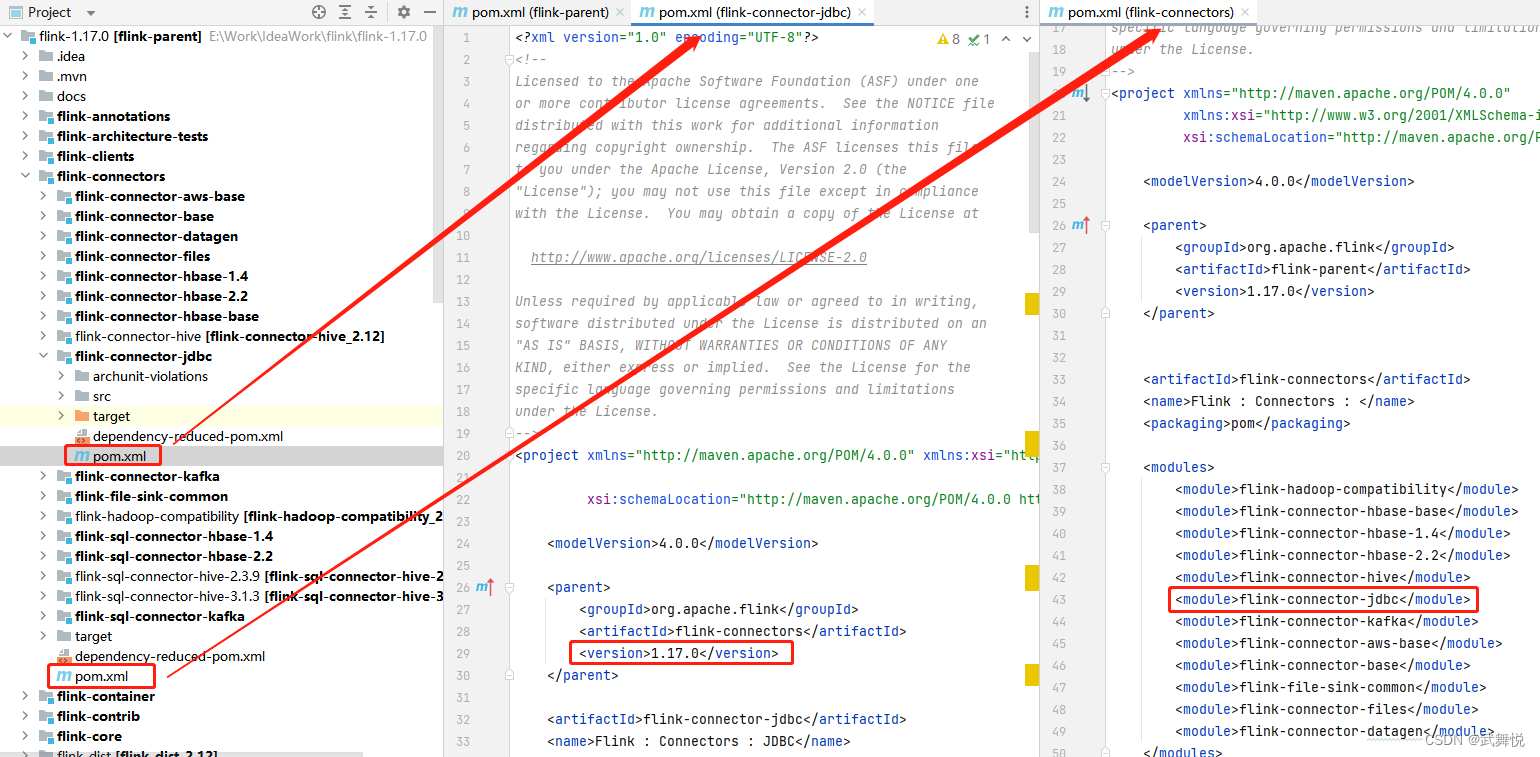
3. 在flink-1.17中添加对flink-connector-jdbc支持
这个不难,直接把flink-1.16.2中flink-connector-jdbc的代码实现拷贝到flink-1.17.0中相应位置即可,但注意修改flink-connectors和flink-connector-jdbc下的pom.xml文件
4. 在flink-connector-jdbc中添加对国产数据库达梦(V8)的支持
4.1 新增DamengRowConverter
在flink-connector-jdbc模块的org.apache.flink.connector.jdbc.internal.converter包下新增DamengRowConverter.java
packageorg.apache.flink.connector.jdbc.internal.converter;importorg.apache.flink.connector.jdbc.converter.AbstractJdbcRowConverter;importorg.apache.flink.table.data.DecimalData;importorg.apache.flink.table.data.StringData;importorg.apache.flink.table.data.TimestampData;importorg.apache.flink.table.types.logical.DecimalType;importorg.apache.flink.table.types.logical.LogicalType;importorg.apache.flink.table.types.logical.RowType;importdm.jdbc.driver.DmdbBlob;importdm.jdbc.driver.DmdbClob;importjava.io.IOException;importjava.io.InputStream;importjava.math.BigDecimal;importjava.math.BigInteger;importjava.sql.Date;importjava.sql.Time;importjava.sql.Timestamp;/**
* Runtime converter that responsible to convert between JDBC object and Flink internal object for
* Dameng.
*/publicclassDamengRowConverterextendsAbstractJdbcRowConverter{privatestaticfinallong serialVersionUID =1L;publicDamengRowConverter(RowType rowType){super(rowType);}@OverridepublicJdbcDeserializationConvertercreateInternalConverter(LogicalType type){switch(type.getTypeRoot()){caseNULL:return val ->null;caseBOOLEAN:caseFLOAT:caseDOUBLE:caseINTERVAL_YEAR_MONTH:caseINTERVAL_DAY_TIME:caseINTEGER:caseBIGINT:return val -> val;caseTINYINT:return val ->{if(val instanceofByte){return(Byte) val;}elseif(val instanceofShort){return((Short) val).byteValue();}else{return((Integer) val).byteValue();}};caseSMALLINT:// Converter for small type that casts value to int and then return short value,// since// JDBC 1.0 use int type for small values.return val -> val instanceofInteger?((Integer) val).shortValue(): val;caseDECIMAL:finalint precision =((DecimalType) type).getPrecision();finalint scale =((DecimalType) type).getScale();// using decimal(20, 0) to support db type bigint unsigned, user should define// decimal(20, 0) in SQL,// but other precision like decimal(30, 0) can work too from lenient consideration.return val ->
val instanceofBigInteger?DecimalData.fromBigDecimal(newBigDecimal((BigInteger) val,0), precision, scale):DecimalData.fromBigDecimal((BigDecimal) val, precision, scale);caseDATE:return val ->(int)((Date.valueOf(String.valueOf(val))).toLocalDate().toEpochDay());caseTIME_WITHOUT_TIME_ZONE:return val ->(int)((Time.valueOf(String.valueOf(val))).toLocalTime().toNanoOfDay()/1_000_000L);caseTIMESTAMP_WITH_TIME_ZONE:caseTIMESTAMP_WITHOUT_TIME_ZONE:return val ->TimestampData.fromTimestamp((Timestamp) val);caseCHAR:caseVARCHAR:return val ->{// support text typeif(val instanceofDmdbClob){try{returnStringData.fromString(inputStream2String(((DmdbClob) val).getAsciiStream()));}catch(Exception e){thrownewUnsupportedOperationException("failed to get length from text");}}elseif(val instanceofDmdbBlob){try{returnStringData.fromString(inputStream2String(((DmdbBlob) val).getBinaryStream()));}catch(Exception e){thrownewUnsupportedOperationException("failed to get length from text");}}else{returnStringData.fromString((String) val);}};caseBINARY:caseVARBINARY:return val ->
val instanceofDmdbBlob?((DmdbBlob) val).getBytes(1,(int)((DmdbBlob) val).length()): val.toString().getBytes();caseARRAY:caseROW:caseMAP:caseMULTISET:caseRAW:default:returnsuper.createInternalConverter(type);}}@OverridepublicStringconverterName(){return"Dameng";}/**
* get String from inputStream.
*
* @param input inputStream
* @return String value
* @throws IOException convert exception
*/privatestaticStringinputStream2String(InputStream input)throwsIOException{StringBuilder stringBuffer =newStringBuilder();byte[] byt =newbyte[1024];for(int i;(i = input.read(byt))!=-1;){
stringBuffer.append(newString(byt,0, i));}return stringBuffer.toString();}}
在Flink的flink-connector-jdbc中,createInternalConverter是一个方法,用于创建将JDBC ResultSet中的数据转换为Flink的内部数据结构的转换器。这个方法通常在JDBCInputFormat中被调用。
在Flink中,使用JDBCInputFormat从关系型数据库中读取数据时,它会将JDBC的ResultSet对象作为输入,然后通过createInternalConverter方法将ResultSet中的每一行数据转换为Flink的内部数据结构(例如Tuple或Row),以便后续的处理和计算。
createInternalConverter方法接受参数ResultSetExtractor,它是一个接口,定义了将ResultSet中的数据转换为Flink内部数据结构的方法。实际上,Flink的flink-connector-jdbc提供了一些默认的ResultSetExtractor实现,可以根据数据的类型自动选择适当的转换规则。例如,对于数字类型的数据,可以使用JDBCTypeInformation来进行转换,对于字符串类型的数据,可以使用JDBCTypeUtils进行转换。
除了默认的转换器之外,也可以根据具体的需求自定义createInternalConverter方法。这样可以根据数据的特定类型或格式,定义自己的转换规则,并将ResultSet中的数据转换为特定的数据类型。
4.2 新增Dameng的dialect
4.2.1 DamengDialectFactory
packageorg.apache.flink.connector.jdbc.dialect.dameng;importorg.apache.flink.annotation.Internal;importorg.apache.flink.connector.jdbc.dialect.JdbcDialect;importorg.apache.flink.connector.jdbc.dialect.JdbcDialectFactory;@InternalpublicclassDamengDialectFactoryimplementsJdbcDialectFactory{@OverridepublicbooleanacceptsURL(String url){return url.startsWith("jdbc:dm:");}@OverridepublicJdbcDialectcreate(){returnnewDamengDialect();}}
在flink-connector-jdbc中,JdbcDialectFactory是一个工厂类,用于创建特定数据库的JdbcDialect实例。
JdbcDialectFactory的主要作用是根据用户提供的JDBC连接URL,确定要连接的数据库类型,并创建对应的JdbcDialect实例。JdbcDialect是一个接口,定义了与特定数据库相关的SQL语法和行为。不同类型的数据库可能具有一些特定的SQL方言,并且可能有不同的行为和限制。JdbcDialectFactory利用JDBC连接URL中所指定的数据库类型信息,根据配置中的各种数据库方言实现,创建适用于该数据库的JdbcDialect实例。
通过JdbcDialect实例,flink-connector-jdbc可以为特定类型的数据库提供更高级的功能和最佳性能。例如,JdbcDialect可以优化生成的SQL查询,使用特定的语法和函数。它还可以检测数据库支持的特性,以避免不支持的操作。
使用JdbcDialectFactory时,通常在flink-connector-jdbc的连接器配置中指定JDBC连接URL,以确定要连接的数据库类型。之后,会调用JdbcDialectFactory.create方法,提供JDBC连接URL,根据该URL创建并返回适当的JdbcDialect实例。然后,该JdbcDialect实例可以与JDBCInputFormat和JDBCOutputFormat等组件一起使用,以实现特定数据库的查询和操作。
4.2.2 DamengDialect
packageorg.apache.flink.connector.jdbc.dialect.dameng;importorg.apache.flink.connector.jdbc.converter.JdbcRowConverter;importorg.apache.flink.connector.jdbc.dialect.AbstractDialect;importorg.apache.flink.connector.jdbc.internal.converter.OracleRowConverter;importorg.apache.flink.table.types.logical.LogicalTypeRoot;importorg.apache.flink.table.types.logical.RowType;importjava.util.Arrays;importjava.util.EnumSet;importjava.util.Optional;importjava.util.Set;importjava.util.stream.Collectors;/** JDBC dialect for Dameng. */classDamengDialectextendsAbstractDialect{privatestaticfinallong serialVersionUID =1L;privatestaticfinalintMAX_TIMESTAMP_PRECISION=9;privatestaticfinalintMIN_TIMESTAMP_PRECISION=1;privatestaticfinalintMAX_DECIMAL_PRECISION=38;privatestaticfinalintMIN_DECIMAL_PRECISION=1;@OverridepublicJdbcRowConvertergetRowConverter(RowType rowType){returnnewOracleRowConverter(rowType);}@OverridepublicStringgetLimitClause(long limit){return"FETCH FIRST "+ limit +" ROWS ONLY";}@OverridepublicOptional<String>defaultDriverName(){returnOptional.of("dm.jdbc.driver.DmDriver");}@OverridepublicStringdialectName(){return"Dameng";}@OverridepublicStringquoteIdentifier(String identifier){return identifier;}@OverridepublicOptional<String>getUpsertStatement(String tableName,String[] fieldNames,String[] uniqueKeyFields){String sourceFields =Arrays.stream(fieldNames).map(f ->":"+ f +" "+quoteIdentifier(f)).collect(Collectors.joining(", "));String onClause =Arrays.stream(uniqueKeyFields).map(f ->"t."+quoteIdentifier(f)+"=s."+quoteIdentifier(f)).collect(Collectors.joining(" and "));finalSet<String> uniqueKeyFieldsSet =Arrays.stream(uniqueKeyFields).collect(Collectors.toSet());String updateClause =Arrays.stream(fieldNames).filter(f ->!uniqueKeyFieldsSet.contains(f)).map(f ->"t."+quoteIdentifier(f)+"=s."+quoteIdentifier(f)).collect(Collectors.joining(", "));String insertFields =Arrays.stream(fieldNames).map(this::quoteIdentifier).collect(Collectors.joining(", "));String valuesClause =Arrays.stream(fieldNames).map(f ->"s."+quoteIdentifier(f)).collect(Collectors.joining(", "));// if we can't divide schema and table-name is risky to call quoteIdentifier(tableName)// for example [tbo].[sometable] is ok but [tbo.sometable] is notString mergeQuery =" MERGE INTO "+ tableName
+" t "+" USING (SELECT "+ sourceFields
+" FROM DUAL) s "+" ON ("+ onClause
+") "+" WHEN MATCHED THEN UPDATE SET "+ updateClause
+" WHEN NOT MATCHED THEN INSERT ("+ insertFields
+")"+" VALUES ("+ valuesClause
+")";returnOptional.of(mergeQuery);}@OverridepublicOptional<Range>decimalPrecisionRange(){returnOptional.of(Range.of(MIN_DECIMAL_PRECISION,MAX_DECIMAL_PRECISION));}@OverridepublicOptional<Range>timestampPrecisionRange(){returnOptional.of(Range.of(MIN_TIMESTAMP_PRECISION,MAX_TIMESTAMP_PRECISION));}@OverridepublicSet<LogicalTypeRoot>supportedTypes(){// The data types used in Dameng are list at:// https://www.techonthenet.com/oracle/datatypes.phpreturnEnumSet.of(LogicalTypeRoot.CHAR,LogicalTypeRoot.VARCHAR,LogicalTypeRoot.BOOLEAN,LogicalTypeRoot.VARBINARY,LogicalTypeRoot.DECIMAL,LogicalTypeRoot.TINYINT,LogicalTypeRoot.SMALLINT,LogicalTypeRoot.INTEGER,LogicalTypeRoot.BIGINT,LogicalTypeRoot.FLOAT,LogicalTypeRoot.DOUBLE,LogicalTypeRoot.DATE,LogicalTypeRoot.TIME_WITHOUT_TIME_ZONE,LogicalTypeRoot.TIMESTAMP_WITHOUT_TIME_ZONE,LogicalTypeRoot.TIMESTAMP_WITH_LOCAL_TIME_ZONE,LogicalTypeRoot.ARRAY);}}
在flink-connector-jdbc中,JdbcDialect是一个接口,用于定义与特定数据库相关的SQL语法和行为。每种不同类型的数据库可能有一些特定的SQL方言和行为,JdbcDialect提供了一种方式来处理这些差异,以确保在不同类型的数据库上执行的SQL操作正确执行,并且能够提供最佳的性能。
JdbcDialect接口定义了以下几种方法:
- String quoteIdentifier(String identifier): 将标识符(例如表名、列名)包装在适当的引号中,以在SQL语句中正确引用它。这是为了处理不同数据库对标识符的命名规则的差异。
- JdbcRowConverter getRowConverter(RowTypeInfo rowTypeInfo): 根据给定的RowTypeInfo,创建一个JdbcRowConverter实例,用于将Flink的Row数据对象转换为适用于特定数据库的JDBC数据对象。这是为了处理不同数据库对数据类型的差异。
- Optional defaultDriverName(): 获取JDBC驱动程序的默认名称,以在使用未指定驱动程序名称的情况下与数据库建立连接。
- Optional getUpsertStatement(String tableName, String[] fieldNames, String[] uniqueKeyFields): 用于生成用于"upsert"(插入或更新)操作的SQL语句。"Upsert"操作是指当目标表中存在指定的记录时,执行更新操作;如果不存在,则执行插入操作;在具体的JdbcDialect的实现中,getUpsertStatement方法会根据特定数据库的语法和行为生成相应的SQL语句。不同数据库对于"upsert"操作的语法可能有所不同,因此JdbcDialect会根据数据库类型来生成适当的语句。
JdbcDialect的具体实现类会根据特定数据库的特性来实现这些方法,以确保flink-connector-jdbc在不同类型的数据库上能够正确工作。例如,MySQLDialect、PostgresDialect和OracleDialect等都是JdbcDialect的实现类,分别处理MySQL、PostgreSQL和Oracle数据库的特定语法和行为。
5. 实测
编译打包不难,这里略过,我们测试一下;
我这边第一次测试时,就遇到一个大坑,数据写入失败,日志如下:
2023-09-01 17:38:58,545 ERROR org.apache.flink.connector.jdbc.internal.JdbcOutputFormat [] - JDBC executeBatch error, retry times = 0
dm.jdbc.driver.DMException: Unbinded parameter: 0
at dm.jdbc.driver.DBError.throwz(DBError.java:727) ~[DmJdbcDriver18-8.1.2.79.jar:- 8.1.2.79 - Production]
at dm.jdbc.driver.DmdbPreparedStatement.checkBindParameters(DmdbPreparedStatement.java:347) ~[DmJdbcDriver18-8.1.2.79.jar:- 8.1.2.79 - Production]
at dm.jdbc.driver.DmdbPreparedStatement.beforeExectueWithParameters(DmdbPreparedStatement.java:372) ~[DmJdbcDriver18-8.1.2.79.jar:- 8.1.2.79 - Production]
at dm.jdbc.driver.DmdbPreparedStatement.do_executeLargeBatch(DmdbPreparedStatement.java:535) ~[DmJdbcDriver18-8.1.2.79.jar:- 8.1.2.79 - Production]
at dm.jdbc.driver.DmdbPreparedStatement.do_executeBatch(DmdbPreparedStatement.java:514) ~[DmJdbcDriver18-8.1.2.79.jar:- 8.1.2.79 - Production]
at dm.jdbc.driver.DmdbPreparedStatement.executeBatch(DmdbPreparedStatement.java:1494) ~[DmJdbcDriver18-8.1.2.79.jar:- 8.1.2.79 - Production]
at org.apache.flink.connector.jdbc.statement.FieldNamedPreparedStatementImpl.executeBatch(FieldNamedPreparedStatementImpl.java:65) ~[flink-connector-jdbc-1.17.0.jar:1.17.0]
at org.apache.flink.connector.jdbc.internal.executor.TableInsertOrUpdateStatementExecutor.executeBatch(TableInsertOrUpdateStatementExecutor.java:104) ~[flink-connector-jdbc-1.17.0.jar:1.17.0]
at org.apache.flink.connector.jdbc.internal.executor.TableBufferReducedStatementExecutor.executeBatch(TableBufferReducedStatementExecutor.java:101) ~[flink-connector-jdbc-1.17.0.jar:1.17.0]
at org.apache.flink.connector.jdbc.internal.JdbcOutputFormat.attemptFlush(JdbcOutputFormat.java:246) ~[flink-connector-jdbc-1.17.0.jar:1.17.0]
at org.apache.flink.connector.jdbc.internal.JdbcOutputFormat.flush(JdbcOutputFormat.java:216) ~[flink-connector-jdbc-1.17.0.jar:1.17.0]
at org.apache.flink.connector.jdbc.internal.JdbcOutputFormat.lambda$open$0(JdbcOutputFormat.java:155) ~[flink-connector-jdbc-1.17.0.jar:1.17.0]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) [?:1.8.0_221]
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308) [?:1.8.0_221]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180) [?:1.8.0_221]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294) [?:1.8.0_221]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_221]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_221]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_221]
2023-09-01 17:38:58,679 ERROR org.apache.flink.connector.jdbc.internal.JdbcOutputFormat [] - JDBC executeBatch error, retry times = 1
dm.jdbc.driver.DMException: Unbinded parameter: 0
这个异常很奇怪:dm.jdbc.driver.DMException: Unbinded parameter: 0
总之,代码看不出问题来,正百思不得其解的时候,决定升级DmJdbcDriver试试,从8.1.2.79升到了8.1.2.141,终于成功了!
原始代码下载可以参考: https://gitee.com/flink_acme/flink-connector-jdbc.git
6. 附
达梦数据库版本:
SQL> select *,id_code from v$version;
LINEID BANNER id_code
---------- ------------------------- ---------------------------------------
1 DM Database Server 64 V8 1-2-38-21.07.09-143359-10018-ENT Pack1
2 DB Version: 0x7000c 1-2-38-21.07.09-143359-10018-ENT Pack1
used time: 00:00:07.719. Execute id is 2300.
SQL>
SQL> select * from v$instance;
LINEID NAME INSTANCE_NAME INSTANCE_NUMBER HOST_NAME SVR_VERSION DB_VERSION
---------- -------- ------------- --------------- --------- -------------------------- -------------------
START_TIME STATUS$ MODE$ OGUID DSC_SEQNO DSC_ROLE
------------------- ------- ------ ----------- ----------- --------
1 DMSERVER DMSERVER 1 bd161 DM Database Server x64 V8 DB Version: 0x7000c
2023-08-28 13:51:41 OPEN NORMAL 0 0 NULL
used time: 565.918(ms). Execute id is 2301.
版权归原作者 武舞悟 所有, 如有侵权,请联系我们删除。