
一 前言
在某些场景中,比方GROUP BY聚合之后的后果,须要去更新之前的结果值。这个时候,须要将 Kafka 记录的 key 当成主键解决,用来确定一条数据是应该作为插入、删除还是更新记录来解决。在 Flink1.11 中,能够通过 flink-cdc-connectors 项目提供的 changelog-json format 来实现该性能。
在 Flink1.12 版本中, 新增了一个 upsert connector(upsert-kafka),该 connector 扩大自现有的 Kafka connector,工作在 upsert 模式(FLIP-149)下。新的 upsert-kafka connector 既能够作为 source 应用,也能够作为 sink 应用,并且提供了与现有的 kafka connector 雷同的基本功能和持久性保障,因为两者之间复用了大部分代码。
二 upsert kafka connector
Upsert Kafka Connector容许用户以upsert的形式从Kafka主题读取数据或将数据写入Kafka主题。
作为 source,upsert-kafka 连接器生产 changelog 流,其中每条数据记录代表一个更新或删除事件。更准确地说,数据记录中的 value 被解释为同一 key 的最后一个 value 的 UPDATE,如果有这个 key(如果不存在相应的 key,则该更新被视为 INSERT)。用表来类比,changelog 流中的数据记录被解释为 UPSERT,也称为 INSERT/UPDATE,因为任何具有相同 key 的现有行都被覆盖。另外,value 为空的消息将会被视作为 DELETE 消息。
作为 sink,upsert-kafka 连接器可以消费 changelog 流。它会将 INSERT/UPDATE_AFTER 数据作为正常的 Kafka 消息写入,并将 DELETE 数据以 value 为空的 Kafka 消息写入(表示对应 key 的消息被删除)。Flink 将根据主键列的值对数据进行分区,从而保证主键上的消息有序,因此同一主键上的更新/删除消息将落在同一分区中。
其中每条数据记录代表一个更新或删除事件,原理如下:
- Kafka Topic中存在相应的Key,则以UPDATE操作将Key的值更新为数据记录中的Value。
- Kafka Topic中不存在相应的Key,则以INSERT操作将Key的值写入Kafka Topic。
- Key对应的Value为空,会被视作DELETE操作。
三 案例
3.1 kafka 处理后写入kafka
3.1.1 创建kafka topic
$ kafka-topics --create--topic user-behavior --partitions3 --replication-factor 2 --bootstrap-server cdh68:9092,cdh69:9092,cdh70:9092
$ kafka-topics --create--topic after-user-behavior --partitions3 --replication-factor 2 --bootstrap-server cdh68:9092,cdh69:9092,cdh70:9092
$ kafka-console-producer --topic user-behavior --broker-list cdh68:9092,cdh69:9092,cdh70:9092
$ kafka-console-consumer --topic user-behavior --from-beginning --group test-user --bootstrap-server cdh68:9092,cdh69:9092,cdh70:9092
$ kafka-console-consumer --topic after-user-behavior --from-beginning --grouptest --bootstrap-server cdh68:9092,cdh69:9092,cdh70:9092
3.2 Flink SQL
3.2.1 source
%flink.ssql
droptableifexists user_behavior;CREATETABLE user_behavior (
id BIGINT,
name STRING,
flag STRING
)WITH('connector'='kafka',-- 使用 kafka connector'topic'='user-behavior',-- kafka topic'properties.group.id'='cdc',-- 消费者组'scan.startup.mode'='latest-offset',-- 从起始 offset 开始读取'json.fail-on-missing-field'='false','json.ignore-parse-errors'='true','properties.bootstrap.servers'='cdh68:9092,cdh69:9092,cdh70:9092',-- kafka broker 地址'format'='json'-- 数据源格式为 json);
3.2.2 sink
%flink.ssql
droptableifexists after_user_behavior;CREATETABLE after_user_behavior (
name STRING,
pv BIGINT,PRIMARYKEY(name)NOT ENFORCED
)WITH('connector'='upsert-kafka','topic'='after-user-behavior','properties.bootstrap.servers'='cdh68:9092,cdh69:9092,cdh70:9092','value.json.fail-on-missing-field'='false','key.json.ignore-parse-errors'='true','key.format'='json','value.format'='json');
一定要设置主键 Primar要使用 upsert-kafka connector,DDL语句中,一定要设置 PRIMARY KEY 主键,并为键(key.format)和值(value.format)指定序列化反序列化格式。
当数据源端进行了增删改,对应的 pv 结果就会同步更新,这就是 upsert kafka 的魅力。
这是基于kafka的统计计算,前提条件是 topic user-behavior中的数据是 changelog 格式的。
3.2.3 transform
%flink.ssql
INSERTINTO after_user_behavior
SELECT
name,COUNT(*)FROM user_behavior
GROUPBY name;
注意:after_user_behavior 必须为 upsert-kafka connector
如果after_user_behavior为 kafka connector,执行此语句则会报如下错误:
java.io.IOException: org.apache.flink.table.api.TableException: Table sink 'default_catalog.default_database.after_user_behavior' doesn't support consuming update changes which is produced by node GroupAggregate(groupBy=[name], select=[name, COUNT(*) AS EXPR$1])
因为语句
SELECT name, COUNT(*) FROM user_behavior GROUP BY name;
通过group by后数据是不断更新变化的,因此只能用 upsert-kafka connector。
3.3 输出结果
3.3.1 kafka user-behavior producer
[song@cdh68 ~]$ kafka-console-producer --topic user-behavior --broker-list cdh68:9092,cdh69:9092,cdh70:9092
>{"schema":"presto","flag":false,"name":"Mars","id":"85","type":"INSERT","table":"user","ts":6852139698555588608}>{"schema":"presto","flag":false,"name":"Lucy","id":"67","type":"INSERT","table":"user","ts":6852139698555588608}>{"schema":"presto","flag":false,"name":"Mars","id":"85","type":"INSERT","table":"info","ts":6852139698555588608}>{"schema":"presto","flag":false,"name":"Lucy","id":"67","type":"INSERT","table":"info","ts":6852139698555588608}>{"schema":"presto","flag":false,"name":"Mars","id":"85","type":"INSERT","table":"user","ts":6852139698555588608}>{"schema":"presto","flag":false,"name":"Mars","id":"85","type":"INSERT","table":"user","ts":6852139698555588608}>{"schema":"presto","flag":false,"name":"Mars","id":"85","type":"UPDATE","table":"user","ts":6852139698555588608}>{"schema":"presto","flag":false,"name":"Mars","id":"85","type":"DELETE","table":"user","ts":6852139698555588608}
topic user-behavior中的数据是 changelog 格式的。
3.3.2 kafka user-behavior consumer
[song@cdh70 ~]$ kafka-console-consumer --topic user-behavior --group test-user --bootstrap-server cdh68:9092,cdh69:9092,cdh70:9092
{"schema":"presto","flag":false,"name":"Mars","id":"85","type":"INSERT","table":"user","ts":6852139698555588608}{"schema":"presto","flag":false,"name":"Lucy","id":"67","type":"INSERT","table":"user","ts":6852139698555588608}{"schema":"presto","flag":false,"name":"Mars","id":"85","type":"INSERT","table":"info","ts":6852139698555588608}{"schema":"presto","flag":false,"name":"Lucy","id":"67","type":"INSERT","table":"info","ts":6852139698555588608}{"schema":"presto","flag":false,"name":"Mars","id":"85","type":"INSERT","table":"user","ts":6852139698555588608}{"schema":"presto","flag":false,"name":"Mars","id":"85","type":"INSERT","table":"user","ts":6852139698555588608}{"schema":"presto","flag":false,"name":"Mars","id":"85","type":"UPDATE","table":"user","ts":6852139698555588608}{"schema":"presto","flag":false,"name":"Mars","id":"85","type":"DELETE","table":"user","ts":6852139698555588608}
3.3.3 kafka after-user-behavior consumer
[song@cdh69 ~]$ kafka-console-consumer --topic after-user-behavior --grouptest --bootstrap-server cdh68:9092,cdh69:9092,cdh70:9092
{"name":"Mars","pv":1}{"name":"Lucy","pv":1}{"name":"Mars","pv":2}{"name":"Lucy","pv":2}{"name":"Mars","pv":3}{"name":"Mars","pv":4}{"name":"Mars","pv":5}{"name":"Mars","pv":6}
3.3.4 FlinkSQL user_behavior
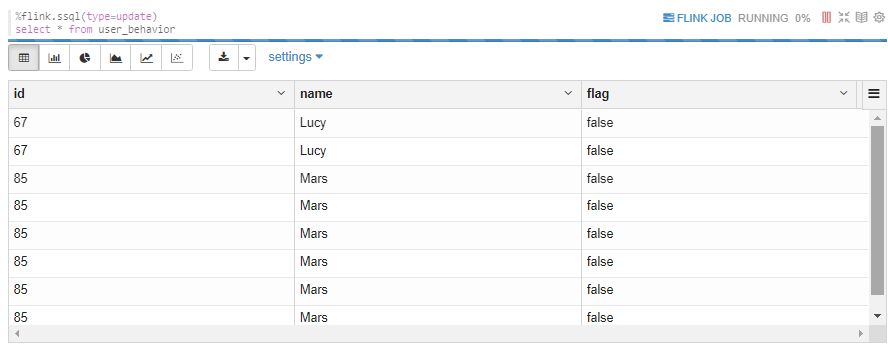
从此结果可以看出 kafka 和 upsert-kafka 的区别:
kafka 的结果则显示所有数据,upsert-kafka则显示更新后的最新数据。
3.3.5 FlinkSQL alfter_user_behavior
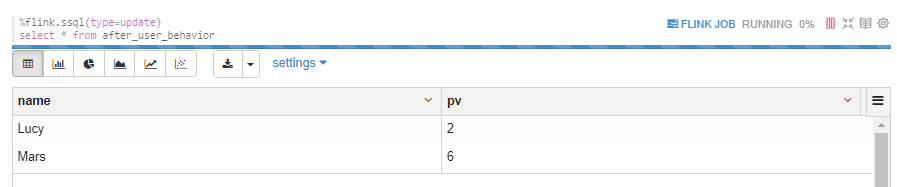
此结果是动态变化的,变化与kafka after-user-behavior consumer相同。
可见,upsert-kafka 表存储了所有变化的数据,但是读取时,只读取最新的数据。
3.2 flink-pageviews-demo
https://github.com/fsk119/flink-pageviews-demo
3.2.1 测试数据准备
在 Mysql 中执行以下命令:
CREATEDATABASE flink;USE flink;CREATETABLE users (
user_id BIGINT,
user_name VARCHAR(1000),
region VARCHAR(1000));INSERTINTO users VALUES(1,'Timo','Berlin'),(2,'Tom','Beijing'),(3,'Apple','Beijing');
现在,我们利用Sql client在Flink中创建相应的表。
CREATETABLE users (
user_id BIGINT,
user_name STRING,
region STRING
)WITH('connector'='mysql-cdc','hostname'='localhost','database-name'='flink','table-name'='users','username'='root','password'='123456');CREATETABLE pageviews (
user_id BIGINT,
page_id BIGINT,
view_time TIMESTAMP(3),
proctime AS PROCTIME())WITH('connector'='kafka','topic'='pageviews','properties.bootstrap.servers'='localhost:9092','scan.startup.mode'='earliest-offset','format'='json');
并利用Flink 往 Kafka中灌入相应的数据
INSERTINTO pageviews VALUES(1,101, TO_TIMESTAMP('2020-11-23 15:00:00')),(2,104, TO_TIMESTAMP('2020-11-23 15:00:01.00'));
3.2.2 将 left join 结果写入 kafka
我们首先测试是否能将Left join的结果灌入到 Kafka 之中。
首先,我们在 Sql client 中创建相应的表
CREATETABLE enriched_pageviews (
user_id BIGINT,
user_region STRING,
page_id BIGINT,
view_time TIMESTAMP(3),
WATERMARK FOR view_time as view_time -INTERVAL'5'SECOND,PRIMARYKEY(user_id, page_id)NOT ENFORCED
)WITH('connector'='upsert-kafka','topic'='enriched_pageviews','properties.bootstrap.servers'='localhost:9092','key.format'='json','value.format'='json');
并利用以下语句将left join的结果插入到kafka对应的topic之中。
INSERTINTO enriched_pageviews
SELECT pageviews.user_id, region, pageviews.page_id, pageviews.view_time
FROM pageviews
LEFTJOIN users ON pageviews.user_id = users.user_id;
利用以下命令,我们可以打印topic内的数据
kafka-console-consumer.sh --bootstrap-server kafka:9094 --topic "enriched_pageviews" --from-beginning --property print.key=true
#预期结果
{"user_id":1,"page_id":101}{"user_id":1,"user_region":null,"page_id":101,"view_time":"2020-11-23 15:00:00"}{"user_id":2,"page_id":104}{"user_id":2,"user_region":null,"page_id":104,"view_time":"2020-11-23 15:00:01"}{"user_id":1,"page_id":101}null{"user_id":1,"page_id":101}{"user_id":1,"user_region":"Berlin","page_id":101,"view_time":"2020-11-23 15:00:00"}{"user_id":2,"page_id":104}null{"user_id":2,"page_id":104}{"user_id":2,"user_region":"Beijing","page_id":104,"view_time":"2020-11-23 15:00:01"}
Left join中,右流发现左流没有join上但已经发射了,此时会发送
DELETE
消息,而非
UPDATE-BEFORE
消息清理之前发送的消息。详见
org.apache.flink.table.runtime.operators.join.stream.StreamingJoinOperator#processElement
我们可以进一步在mysql中删除或者修改一些数据,来观察进一步的变化。
UPDATE users SET region ='Beijing'WHERE user_id =1;DELETEFROM users WHERE user_id =1;
3.2.3 将聚合结果写入kafka
我们进一步测试将聚合的结果写入到 Kafka 之中。
在Sql client 中构建以下表
CREATETABLE pageviews_per_region (
user_region STRING,
cnt BIGINT,PRIMARYKEY(user_region)NOT ENFORCED
)WITH('connector'='upsert-kafka','topic'='pageviews_per_region','properties.bootstrap.servers'='localhost:9092','key.format'='json','value.format'='json')
我们再用以下命令将数据插入到upsert-kafka之中。
INSERTINTO pageviews_per_region
SELECT
user_region,COUNT(*)FROM enriched_pageviews
WHERE user_region isnotnullGROUPBY user_region;
我们可以通过以下命令查看 Kafka 中对应的数据
./kafka-console-consumer.sh --bootstrap-server kafka:9094--topic "pageviews_per_region"--from-beginning --property print.key=true
# 预期结果
{"user_region":"Berlin"}{"user_region":"Berlin","cnt":1}{"user_region":"Beijing"}{"user_region":"Beijing","cnt":1}{"user_region":"Berlin"}null{"user_region":"Beijing"}{"user_region":"Beijing","cnt":2}{"user_region":"Beijing"}{"user_region":"Beijing","cnt":1}

版权归原作者 大数据AI 所有, 如有侵权,请联系我们删除。