
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
from selenium.webdriver import ActionChains
import gc
import csv
from matplotlib import rcParams ## run command settings for plotting
config = {
"mathtext.fontset":'stix',
"font.family":'serif',
"font.serif": ['SimHei'],
"font.size": 10, # 字号
'axes.unicode_minus': False # 处理负号,即-号
}
rcParams.update(config) ## 设置画图的一些参数
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 屏蔽保存密码提示框
prefs = {'credentials_enable_service': False, 'profile.password_manager_enabled': False}
options.add_experimental_option('prefs', prefs)
# 反爬虫特征处理
options.add_argument('--disable-blink-features=AutomationControlled')
web = webdriver.Chrome(options=options)
web.get('https://passport.jd.com/new/login.aspx?ReturnUrl=https%3A%2F%2Fwww.jd.com%2F')
web.maximize_window()
web.find_element('id','loginname').send_keys('jd_FVzgxqKJDpIL')
web.find_element('css selector','#nloginpwd').send_keys('pass-word')
web.implicitly_wait(10)
web.find_element('id','loginsubmit').click()
time.sleep(2)
web.implicitly_wait(10)
web.find_element('css selector','#key').send_keys('数据结构与算法:Python语言实现')
web.find_element('css selector','#search > div > div.form > button').click()
comments=web.find_element('css selector','#J_comment_12425597')
#跳转链接
lianjie=comments.get_attribute('href')
print(lianjie)
web.get(lianjie)
data_list=[]
#爬取商品前四十页的评论
for i in range(1,40):
web.implicitly_wait(10)
comments1=web.find_elements('css selector','#comment-0 > div')
i=1
for comment in comments1:
if(i>10):
continue
commentor=comment.find_element('css selector','.comment-item .user-info')
information=comment.find_element('tag name','p')
info=comment.find_element('css selector','.comment-item .order-info')
dit={
'评论者':commentor.text,
'评论内容':information.text,
'时间':info.text,
}
print(dit)
#用字典的形式显示出来
data_list.append(dit)
i=i+1
web.find_element('css selector','#comment-0 > div.com-table-footer > div > div > a.ui-pager-next').click()
print('进入下一页')
time.sleep(1)
#用csv文件保存字典内容
csv_file='comments2_csv'
csv_headers=['评论者','评论内容','时间']
with open(csv_file,'w',newline='',encoding='utf-8')as file:
writer=csv.DictWriter(file,fieldnames=csv_headers)
writer.writeheader()
for data in data_list:
writer.writerow(data)
print('csv文件已保存')
#用词云对内容机型可视化分析
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
from collections import Counter
text = ''
with open('comments2_csv', 'r', encoding='utf-8') as file:
reader = csv.reader(file)
next(reader) # 跳过表头
for row in reader:
text += ' '.join(row) + ' ' # 将词云连接在一起
# 生成词云,调整词云尺寸和字体大小
wordcloud = WordCloud(font_path='simsun.ttc', background_color='white', width=800, height=800, max_font_size=100).generate(text)
# 显示词云
plt.figure(figsize=(10, 10)) # 调整画布大小
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
gc.collect()
爬取的数据:
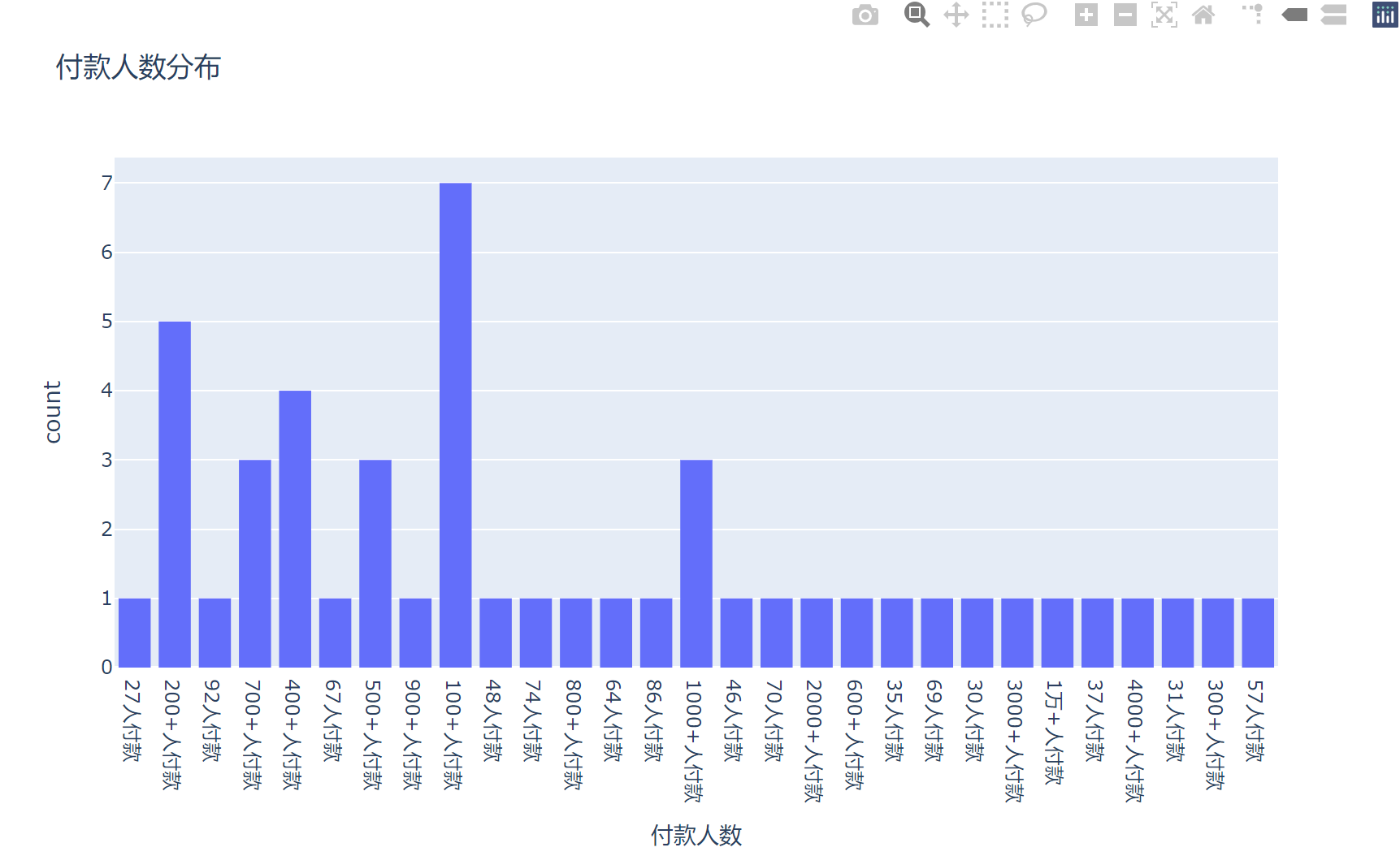
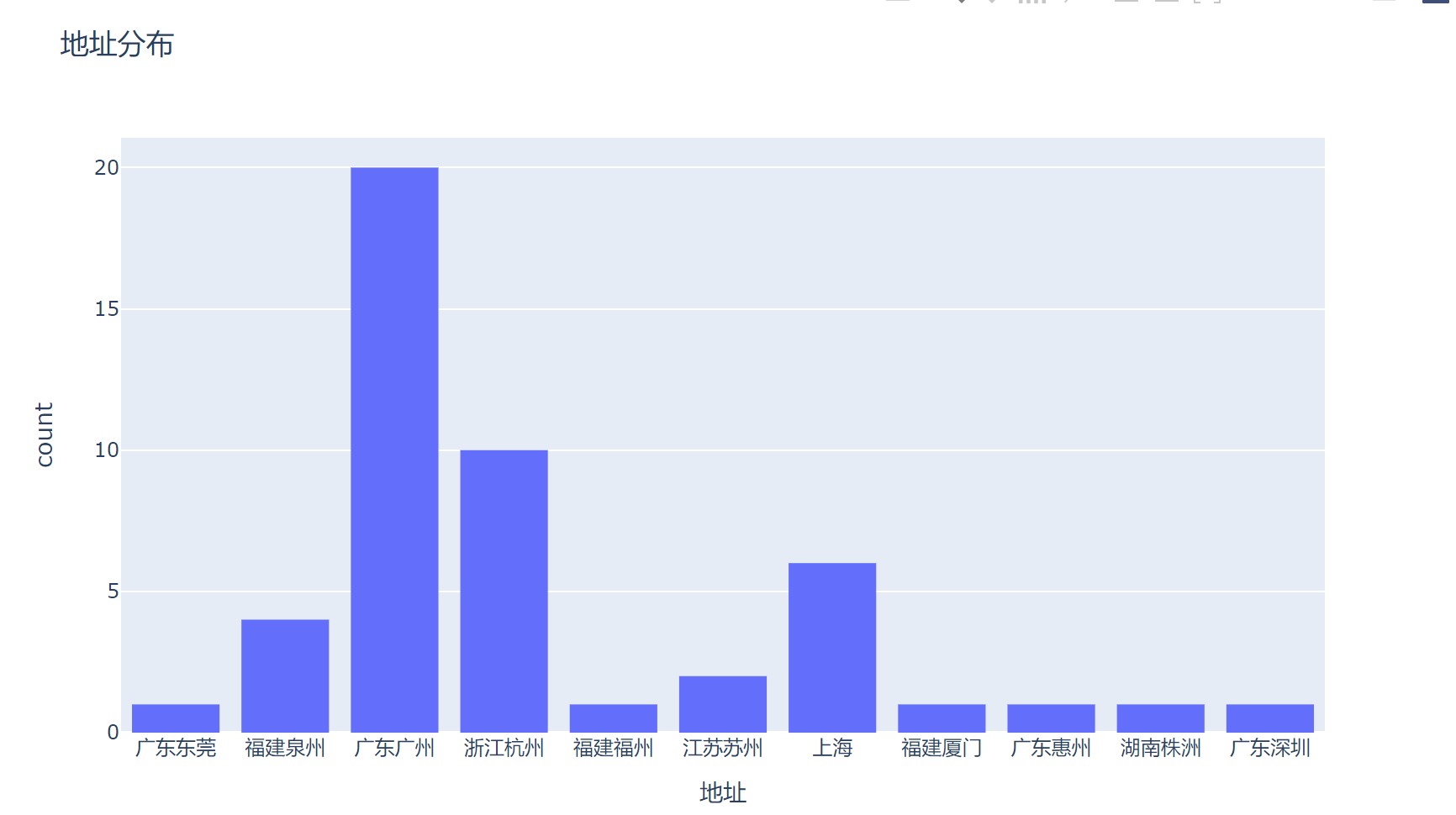

本文转载自: https://blog.csdn.net/m0_73639297/article/details/137999111
版权归原作者 spider文 所有, 如有侵权,请联系我们删除。
版权归原作者 spider文 所有, 如有侵权,请联系我们删除。