
hdfs 主要角色
namenode:获取所有datanode信息以及元数据信息
datanode:实际存储数据得节点
什么是 hdfs ha部署
1.HA机制的产生背景
高可用(High Availability, HA),为了整个系统的可靠性,通常会在系统中部署两台或多台主节点,多台主节点形成主备的关系,但是某一时刻只有一个主节点能够对外提供服务,当某一时刻检测到对外提供服务的主节点“挂”掉之后,备用主节点能够立刻接替已挂掉的主节点对外提供服务,而用户感觉不到明显的系统中断。这样对用户来说整个系统就更加的可靠和高效。
影响HDFS集群不可用主要包括以下两种情况。● NameNode机器宕机,将导致集群不可用,重启NameNode之后才可使用。
● 计划内的NameNode节点软件或硬件升级,导致集群在短时间内不可用。
在Hadoop1.0的时代,HDFS集群中NameNode存在单点故障(SPOF)时,由于NameNode保存了整个HDFS的元数据信息,对于只有一个NameNode的集群,如果NameNode所在的机器出现意外情况,将导致整个HDFS系统无法使用。同时Hadoop生态系统中依赖于HDFS的各个组件,包括MapReduce、Hive、Pig以及HBase等也都无法正常工作,直到NameNode重新启动。重新启动NameNode和其进行数据恢复的过程也会比较耗时。这些问题在给Hadoop的使用者带来困扰的同时,也极大地限制了Hadoop的使用场景,使得Hadoop在很长的时间内仅能用作离线存储和离线计算,无法应用到对可用性和数据一致性要求很高的在线应用场景中。
为了解决上述问题,在Hadoop2.0中给出了HDFS的高可用(HA)解决方案。
2.HDFS的HA机制
HDFS的HA通常由两个NameNode组成,一个处于Active状态,另一个处于Standby状态。Active状态的NameNode对外提供服务,比如处理来自客户端的RPC请求;而Standby状态的NameNode则不对外提供服务,仅同步Active状态的NameNode的状态,以便能够在它失败时快速进行切换。
hdfs ha模式架构图
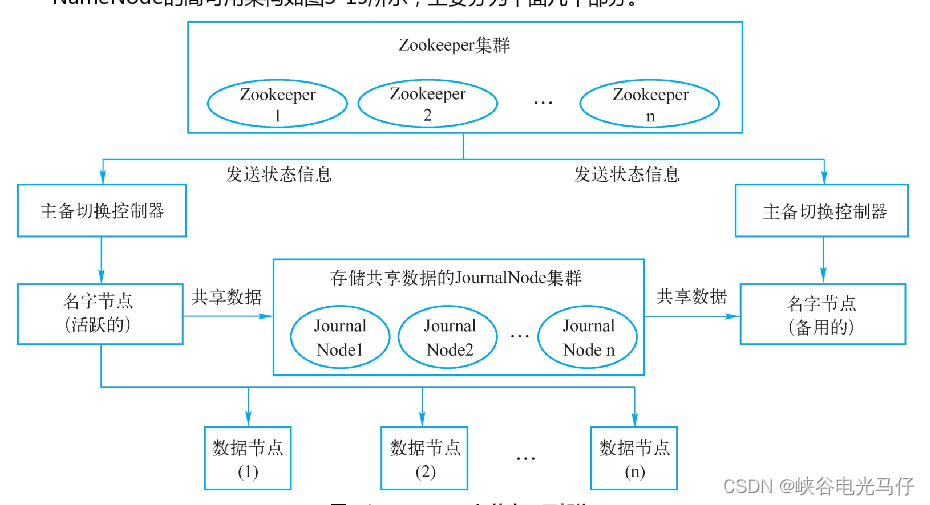
zookeeper 作用
Zookeeper是一个分布式的、开源的协调服务框架,服务于分布式应用。它是Google的Chubby组件的一个开源实现,是Hadoop和HBase的重要组件。
● 它提供了一系列的原语(数据结构)操作服务,因此分布式应用能够基于这些服务,构建出更高级别的服务,比如分布式锁服务、配置管理服务、分布式消息队列、分布式通知与协调服务等。
● Zookeeper设计上易于编码,数据模型构建在树形结构目录风格的文件系统中。
● Zookeeper运行在Java环境上,同时支持Java和C语言。
2.Zookeeper的特点
Zookeeper工作在集群中,对集群提供分布式协调服务,它提供的分布式协调服务具有如下的特点。
● 最终一致性:客户端不论连接到哪个Server,看到的都是同一个视图,这是Zookeeper最重要的特点。
● 可靠性:Zookeeper具有简单、健壮、良好的性能。如果一条消息被一台服务器接收,那么它将被所有的服务器接收。
● 实时性:Zookeeper保证客户端将在一个时间间隔范围内,获得服务器更新的信息或服务器失效的信息。
但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新的数据,应该在读数据之前调用sync( )接口
部署部分
找三台机器并设置机器host
机器1 hadoop1
机器2 hadoop2
机器3 hadoop3
部署网络拓扑
hadoop1hadoop2hadoop3zookeeper1zookeeper2zookeeper3namenode1namenode2datanode3
zookeeper集群部署
zookeeper 下载
下载地址 Apache ZooKeeper
我这下载的是 3.5.9,解压 放到自己的应用路径上,记住三台机器尽量放置路径都一致
tar -zxvf zookeeper-3.5.9.tar.gz -C /home/hadoop/
创建文件夹
mkdir /home/hadoop/zookeeper/data
mkdir /home/hadoop/zookeeper/log
进入zookeeper文件夹,然后修改配置文件 conf/zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
dataDir=/home/hadoop/zookeeper/data #数据目录,三个机器都要相同,首先
dataLogDir=/home/hadoop/zookeeper/log #数据目录,三个机器都要相同
server.0=hadoop1:2888:3888
server.1=hadoop2:2888:3888
server.2=hadoop3:2888:3888
在/etc/profile文件末尾添加
export PATH=$PATH:/home/hadoop/zookeeper-3.5.9/bin
启动和关闭zookeeper
进入zookeeper 目录 bin下执行
zkServer.sh start
zkServer.sh stop
查看启动状态
zkServer.sh status

hdfs ha 集群部署
下载
hadoop下载 3.2.2下载地址 解压放到自定义得目录下比如 /usr/local/hadoop
修改配置文件
进入到解压后得hadoop目录
修改 core-site.xml 为如下配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://vmcluster</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/env/hadoop-3.2.2/data</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<vaule>root</vaule>
</property>
<property>
<name>hadoop.proxyuser.bigdata.hosts</name>
<vaule>*</vaule>
</property>
<property>
<name>hadoop.proxyuser.bigdata.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.bigdata.users</name>
<value>*</value>
</property>
</configuration>
hadoop-env.sh
export JAVA_HOME=${JAVA_HOME}
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservices</name>
<value>vmcluster</value>
</property>
<property>
<name>dfs.ha.namenodes.vmcluster</name>
<value>nn1,nn2,nn3</value>
</property>
<property>
<name>dfs.namenode.rpc-address.vmcluster.nn1</name>
<value>hadoop1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.vmcluster.nn2</name>
<value>hadoop2:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.vmcluster.nn3</name>
<value>hadoop3:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.vmcluster.nn1</name>
<value>hadoop1:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.vmcluster.nn2</name>
<value>hadoop2:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.vmcluster.nn3</name>
<value>hadoop3:9870</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/vmcluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.vmcluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/bigdata/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.safemode.threshold.pct</name>
<value>1</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/env/hadoop-3.2.2/data/jn</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/dn</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>67108864</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop3:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop3:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/env/hadoop-3.2.2</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/env/hadoop-3.2.2</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/env/hadoop-3.2.2</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*,$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop3:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop3:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/env/hadoop-3.2.2</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/env/hadoop-3.2.2</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/env/hadoop-3.2.2</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*,$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
启动hdfs
进入hadoop目录下,执行
sbin/start-all.sh #启动
sbin/start-all.sh #停止
验证
执行jps,由于我hadoop1 ,hadoop2机器是namenode,hadoop3是datanode,所以执行结果如下
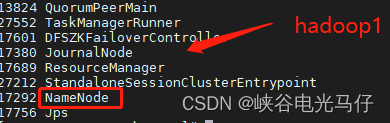
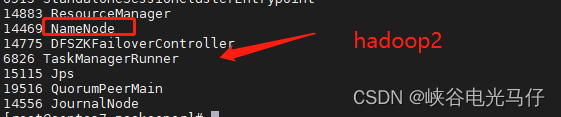
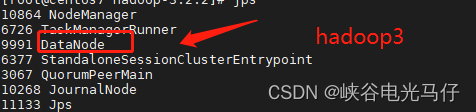
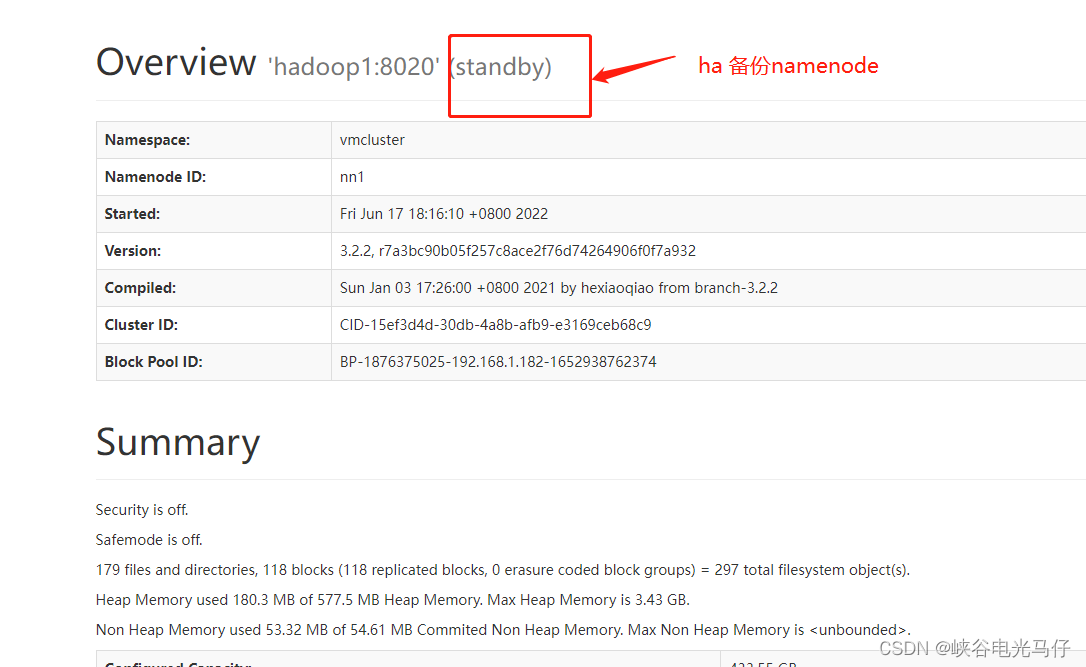
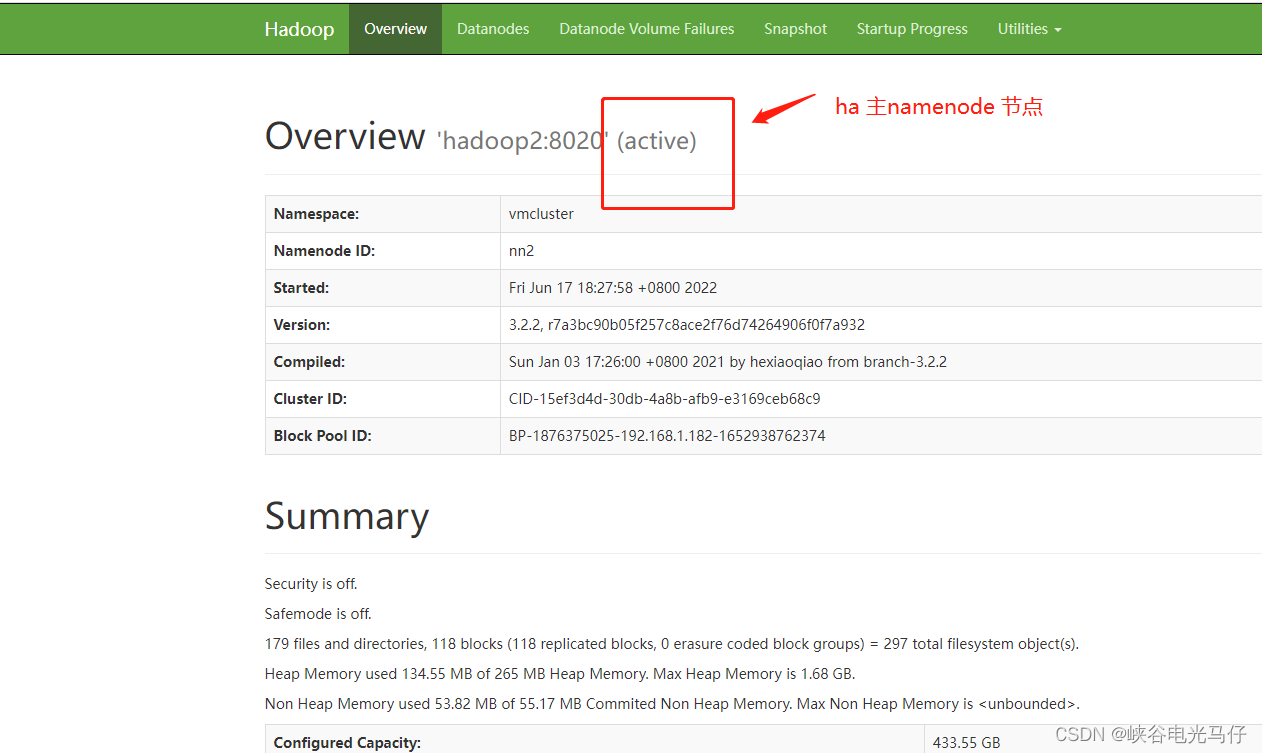
查看页面ha 状态
我配置得hdfs web 端口是 9870,所以浏览器里输入ip:9870 即可
hdfs 文件上传下载
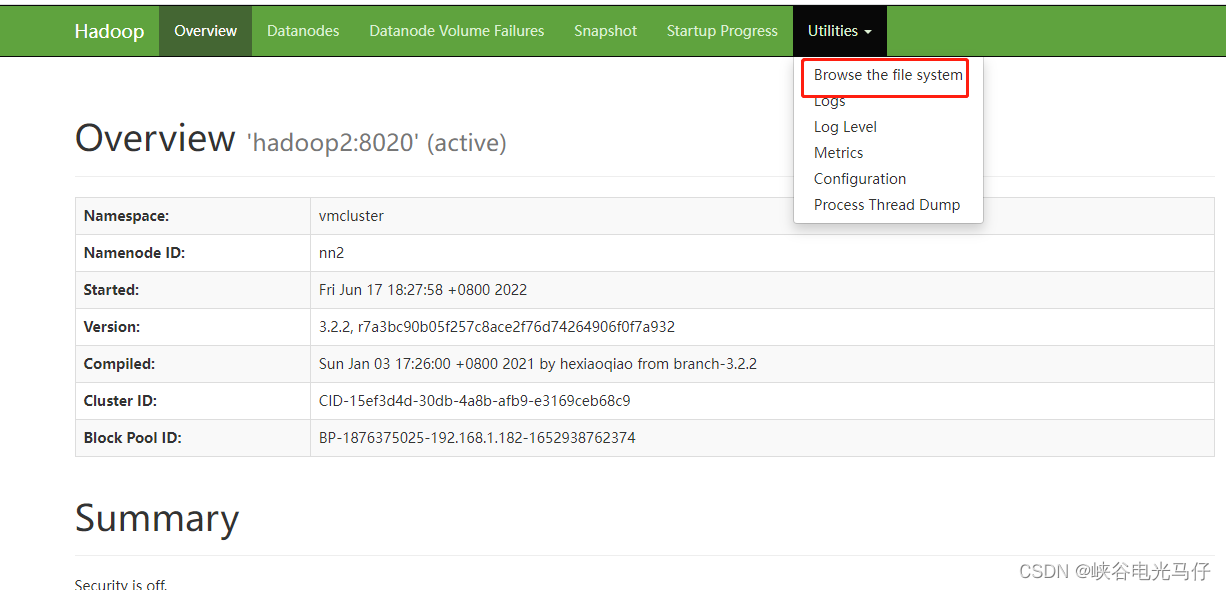
点击browse the file system

java 操作hdfs ha上传下载
也可以通过java代码上传下载,后续将单独发布一篇关于java hdfs ha集群上传下载的文字
本文转载自: https://blog.csdn.net/madness1010/article/details/125333393
版权归原作者 峡谷电光马仔 所有, 如有侵权,请联系我们删除。
版权归原作者 峡谷电光马仔 所有, 如有侵权,请联系我们删除。