
🏆个人主页:企鹅不叫的博客
🌈专栏
- C语言初阶和进阶
- C项目
- Leetcode刷题
- 初阶数据结构与算法
- C++初阶和进阶
- 《深入理解计算机操作系统》
- 《高质量C/C++编程》
- Linux
⭐️ 博主码云gitee链接:代码仓库地址
⚡若有帮助可以【关注+点赞+收藏】,大家一起进步!
💙系列文章💙
【初阶与进阶C++详解】第一篇:C++入门知识必备
【初阶与进阶C++详解】第二篇:C&&C++互相调用(创建静态库)并保护加密源文件
【初阶与进阶C++详解】第三篇:类和对象上(类和this指针)
【初阶与进阶C++详解】第四篇:类和对象中(类的六个默认成员函数)
【初阶与进阶C++详解】第五篇:类和对象下(构造+static+友元+内部类
【初阶与进阶C++详解】第六篇:C&C++内存管理(动态内存分布+内存管理+new&delete)
【初阶与进阶C++详解】第七篇:模板初阶(泛型编程+函数模板+类模板+模板特化+模板分离编译)
【初阶与进阶C++详解】第八篇:string类(标准库string类+string类模拟实现)
【初阶与进阶C++详解】第九篇:vector(vector接口介绍+vector模拟实现+vector迭代器区间构造/拷贝构造/赋值)
【初阶与进阶C++详解】第十篇:list(list接口介绍和使用+list模拟实现+反向迭代器和迭代器适配)
【初阶与进阶C++详解】第十一篇:stack+queue+priority_queue+deque(仿函数)
【初阶与进阶C++详解】第十二篇:模板进阶(函数模板特化+类模板特化+模板分离编译)
【初阶与进阶C++详解】第十三篇:继承(菱形继承+菱形虚拟继承+组合)
【初阶与进阶C++详解】第十四篇:多态(虚函数+重写(覆盖)+抽象类+单继承和多继承)
【初阶与进阶C++详解】第十五篇:二叉树搜索树(操作+实现+应用KVL+性能+习题)
【初阶与进阶C++详解】第十六篇:AVL树-平衡搜索二叉树(定义+插入+旋转+验证)
【初阶与进阶C++详解】第十七篇:红黑树(插入+验证+查找)
【初阶与进阶C++详解】第十八篇:map_set(map_set使用+multiset_multimap使用+模拟map_set)
文章目录
💎一、哈希概念
不经过任何比较,一次直接从表中得到要搜索的元素。如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素 。哈希方法中用到的转换函数称为哈希函数,构造出来的结构叫哈希表(散列表),对数组中的数据进行快速访问必须要通过数组的下标,时间复杂度为 O(1)。如果只知道数据或者数据中的部分内容,或者全员冲突(所有数据都存放到同一个地址下),想在数组中找到这个数据,还是需要遍历数组,时间复杂度为 O(N),但是平均下来,哈希的插入删除查找时间复杂度都是O(1)。
- 插入元素: 根据待插入元素的关键码,通过哈希函数计算出该元素的存储位置,并按此位置进行存放
- 查找元素: 对要查找的元素的关键码用样的计算方法得出该元素的存储位置,然后与该位置的元素进行比较,相同就表示查找成功
- 以上两者时间复杂度基本是O(1),哈希冲突有一定影响
例如:哈希函数设置为:hash(key) = key % capacity; capacity为存储元素底层空间总的大小 。用该方法进行搜索不必进行多次关键码的比较,因此搜索的速度比较快 。
💎二、哈希函数
原则
- 哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间
- 哈希函数计算出来的地址能均匀分布在整个空间中,每个函数值概率是同等的
- 哈希函数应该比较简单
常用:
- 直接定制法: 取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B,其中A和B为常数优点: 简单,均匀缺点: 需要事先知道关键字的分布情况,如果关键字分布很散(范围很大),就需要浪费很多的空间,不能处理浮点数,字符串等数据使用范围: 关键字分布范围小且最好连续的情况
- 除留余数法: 取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即 H(key) = key % p,p<=m(p的选择很重要,一般取素数或m)优点: 可以将范围很大的关键字都模到一个范围内缺点: 不同的值映射到同一个位置会冲突使用范围: 关键字分布不均匀
💎三、哈希冲突及其解决
🏆1.哈希冲突概念
例如:哈希函数设置为:hash(key) = key % size; size为存储元素空间总的大小,Key为通过哈希函数对元素的关键码进行计算得到的位置,hash(Key)为冲突元素通过线性探测后得到的存放位置 。用该方法进行搜索不必进行多次关键码的比较,因此搜索的速度比较快 ,有一组元素{0,1,3,9,15}存放到capacity为10的空间,如果此时再插入一个元素5,此时元素5存放的位置有15了。
总结: 不同关键字通过相同的哈希函数计算出相同的哈希地址, 这里的这种现象称为哈希冲突或哈希碰撞,冲突越多,查找时比较的次数就越多,对平均查找长度影响比较大。
🏆2.哈希冲突解决
2.1.闭散列
闭散列: 也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。
2.1.1线性探测
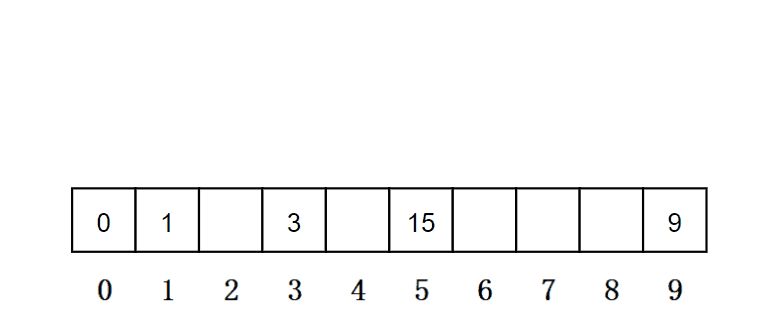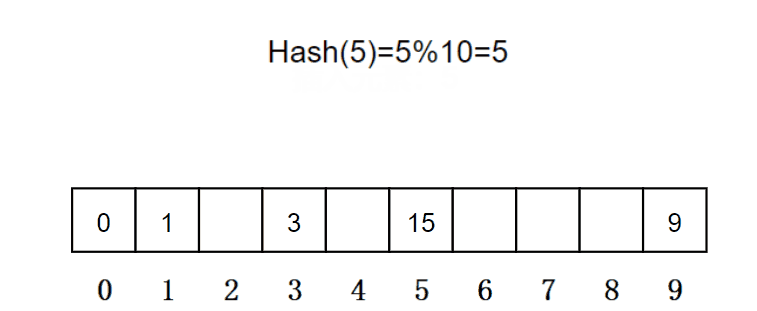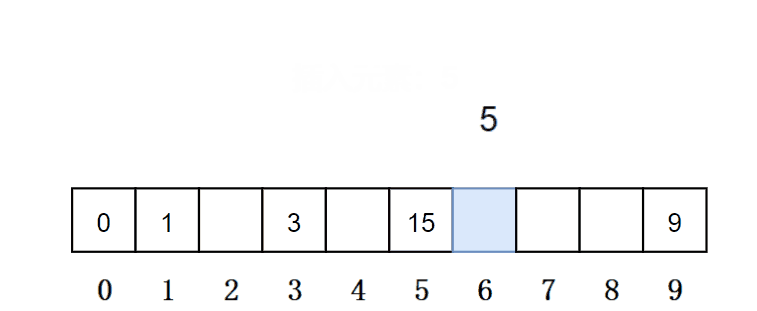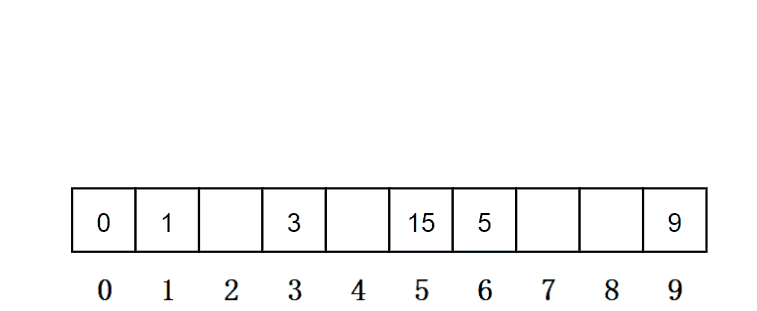
从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。在上面哈希冲突的场景中,插入元素5时,因为此时的位置被占了,所以元素5选择下一个空位置,就是下标为6的位置。
框架
框架:这里采用线性探测(Hash(key)=key%len+i(i=0,1,2…))的方式构建哈希表,哈希表底层我们借用vector容器来实现。
#include<vector>//标识每个位置的状态enumState{ EMPTY,//空 EXITS,//存在数据 DELETE//数据被删除};//哈希表中的每个位置的存储结构包括状态和数据template<classK,classV>structHashData{ pair<K, V> _kv;//初始化为空 State _state = EMPTY;};//仿函数template<classK>structDefaultHash{ size_t operator()(const K& key){return(size_t)key;}};//仿函数特化为字符串template<>structDefaultHash<string>{ size_t operator()(const string& key){// 将所有字符加起来 size_t hash =0;for(auto ch : key){//如果遇到字符串存储,把字符串的所有字母加起来,防止苹果,果苹的缺陷 hash = hash *131+ ch;}//返回所有字符相加的整数return hash;}};//模板参数第一个是key关键字,第二个参数不同容器V的类型不同,可以是K,也可以是pair<K,V>类型//第三个参数就是一个仿函数,为了获取V中K的值然后取模template<classK,classV,classHashFunc= DefaultHash<K>>classHashTable{typedef HashData<K, V> Data;public://释放vector中的自定义类型数据数据//同理如果发生拷贝,vector可以自动调用拷贝构造深拷贝,vector中元素只会浅拷贝~HashTable(){for(size_t i =0; i < _tables.size();++i){ Node* cur = _tables[i];while(cur){ Node* next = cur->_next;delete cur; cur = next;} _tables[i]=nullptr;}}private: vector<HashData> _tables; size_t _n =0;// 存储关键字个数};
插入元素
插入元素:通过哈希函数确定插入位置,如果插入位置为空,则直接插入,否则通过线性探测寻找下一个插入位置,既然要插入元素就要注意扩容。
- 需要注意的是,哈希表不能满了再扩容,这样会导致哈希冲突概率增加,所以哈希表中有一个负载因子来衡量哈希表中装满程度,负载因子 = 填入哈希表数据个数/哈希表长度,负载因子越大,说明填入哈希表中的数据越多,发生函数冲突的概率也就越大,这里定义负载因子最多不超过0.7,达到0.7时开始增容。
- 增容之后,利用现代写法,将旧空间和新空间重现交换,利用临时对象的析构函数清理旧空间的资源
typedef HashData<K, V> Data;public:boolInsert(const pair<K, V>& kv){//如果不为空,说明有值了,返回flaseif(Find(kv.first)){returnfalse;}// 负载因子到0.7及以上,就扩容,防止死循环//_n/_tables.size()>=0.7if(_tables.size()==0|| _n *10/ _tables.size()>=7){//扩容之前要判断是否有数据 size_t newSize = _tables.size()==0?10: _tables.size()*2;// 扩容以后,需要重新映射 HashTable<K, V> newHT; newHT._tables.resize(newSize);// 遍历旧表,插入newHTfor(auto& e : _tables){if(e._state == EXITS){ newHT.Insert(e._kv);}}//把临时空间和旧空间进行交换 newHT._tables.swap(_tables);}//利用仿函数 HashFunc hf;//初始化下标starti size_t starti =hf(kv.first);//不能用capacity,因为,数据插入位置不能超过size//同理vector中,reserve开辟空间,不能用[]访问下标 starti %= _tables.size(); size_t hashi = starti; size_t i =1;// 只有存在就继续//线性探测/二次探测while(_tables[hashi]._state == EXITS){//二次探测//hashi = starti + i*i; hashi = starti + i;++i;//防止越界 hashi %= _tables.size();} _tables[hashi]._kv = kv; _tables[hashi]._state = EXITS; _n++;returntrue;}
查找
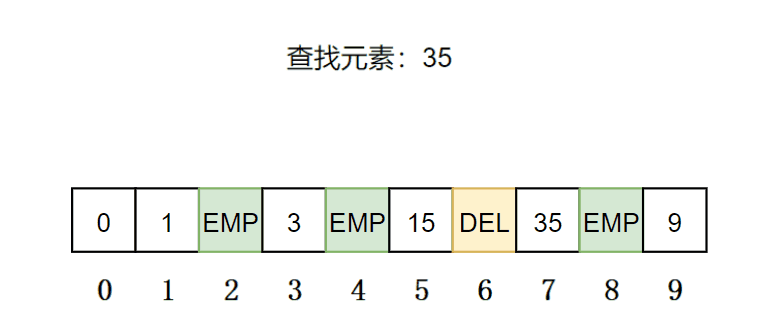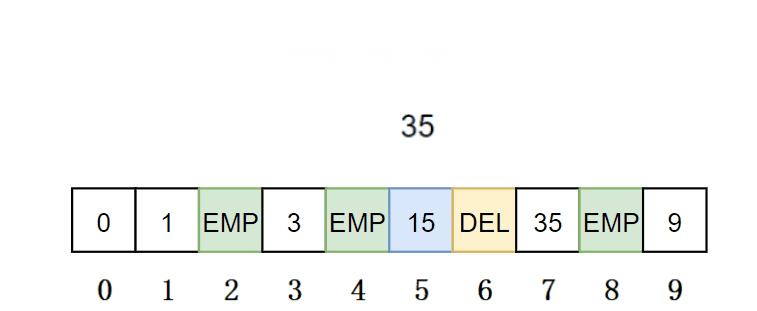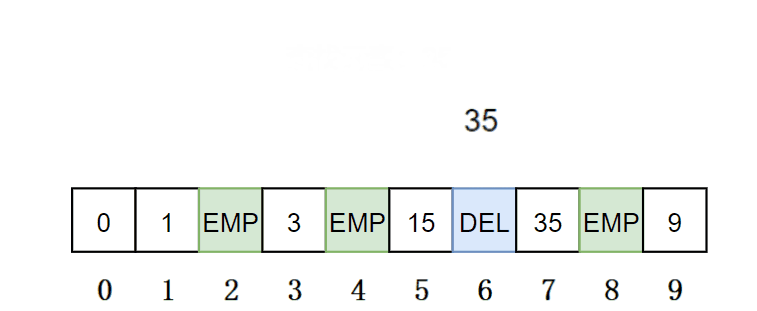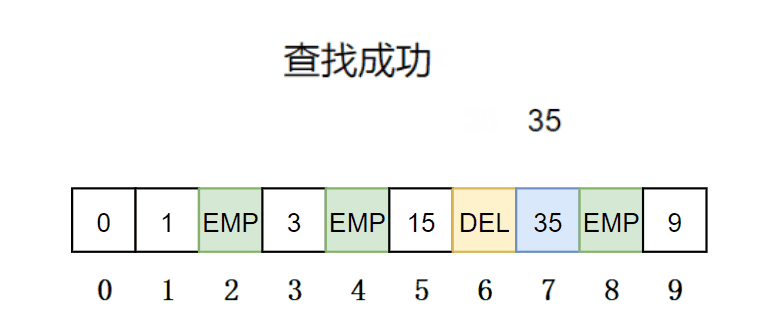
查找:先通过哈希函数确定待查找元素的起始位置,然后线性探测往后找,如果当前位置不为DELETE 就继续往后找,直到当前位置为EMPTY,就停止查找表示该元素不存在;当前位置为EXIT 就进行比较,一样就查找成功,否则去下一个位置;如果当前位置为DELETE,就继续往下探测。
//使用&,如果是空无法处理 Data*Find(const K& key){//表为空返回falseif(_tables.size()==0){returnnullptr;}//利用仿函数 HashFunc hf;//初始化下标starti size_t starti =hf(key);//不能用capacity,因为,数据插入位置不能超过size//同理vector中,reserve开辟空间,不能用[]访问下标//计算出映射的地址 starti %= _tables.size(); size_t hashi = starti; size_t i =1;// 只有存在就继续//线性探测/二次探测while(_tables[hashi]._state != EMPTY){if(_tables[hashi]._state != DELETE && _tables[hashi]._kv.first == key){return&_tables[hashi];}//二次探测//hashi = starti + i*i; hashi = starti + i;++i;//防止越界 hashi %= _tables.size();}returnnullptr;}
删除
删除:先通过查找确定待删除元素的起始位置,然后线性探测往后找到要删除元素,此时不可以直接把这个元素删除,否则会影响到其它元素的搜索。所以这里对每个位置状态进行了标记,EMPTY(空) 、EXITS(存在) 和 DELETE(删除) 三种状态,用DELETE标记删除的位置
boolErase(const K& key){ Data* ret =Find(key);if(ret){ ret->_state = DELETE;--_n;returntrue;}else{returnfalse;}}
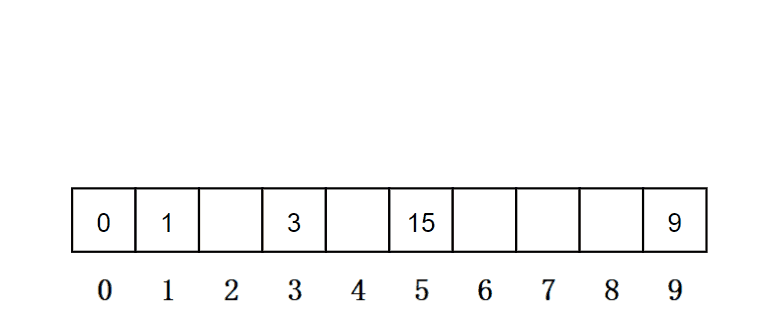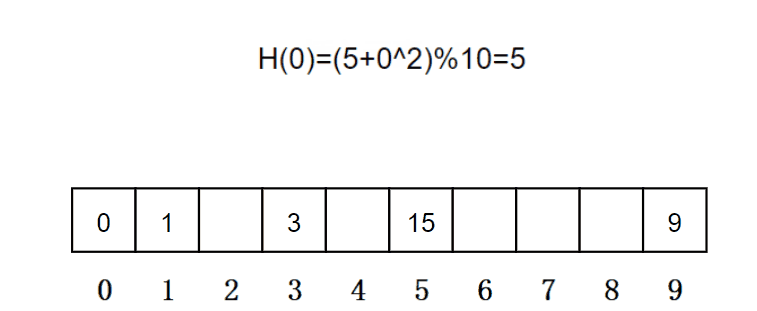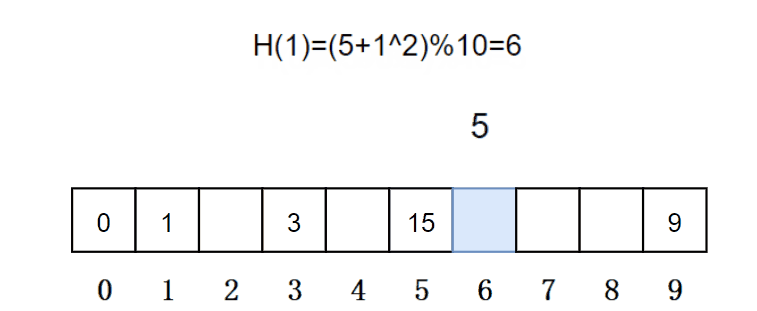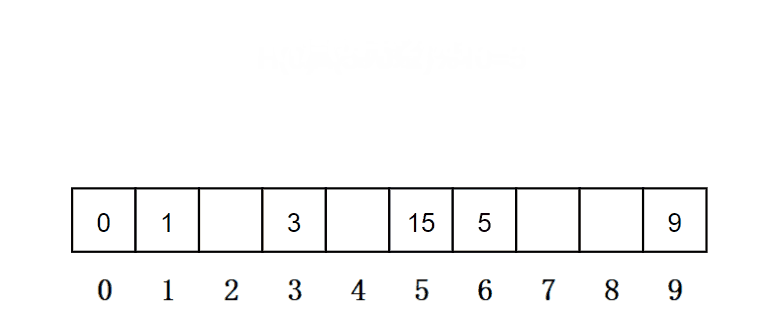
2.1.2.二次探测
找下一个空位置的方法为:H(i) = H(0) + i^2。其中:i = 1,2,3…, 是通过散列函数Hash(x)对元素的关键码 key 进行计算得到的位置,m是表的大小。
注意表装载因子a不超过0.5,表中有一半的空位置,就不会存在表满的问题。在搜索时可以不考虑表装满的情况,但在插入时必须确保表的装载因子a不超过0.5,如果超出必须考虑增容
总结
总结:线性探测缺点是数据堆积,二次探测可以减轻这种情况,闭散列最大的缺陷就是
空间利用率不高
2.2开散列
哈希桶:首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,每个桶放的都是哈希冲突的元素,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中
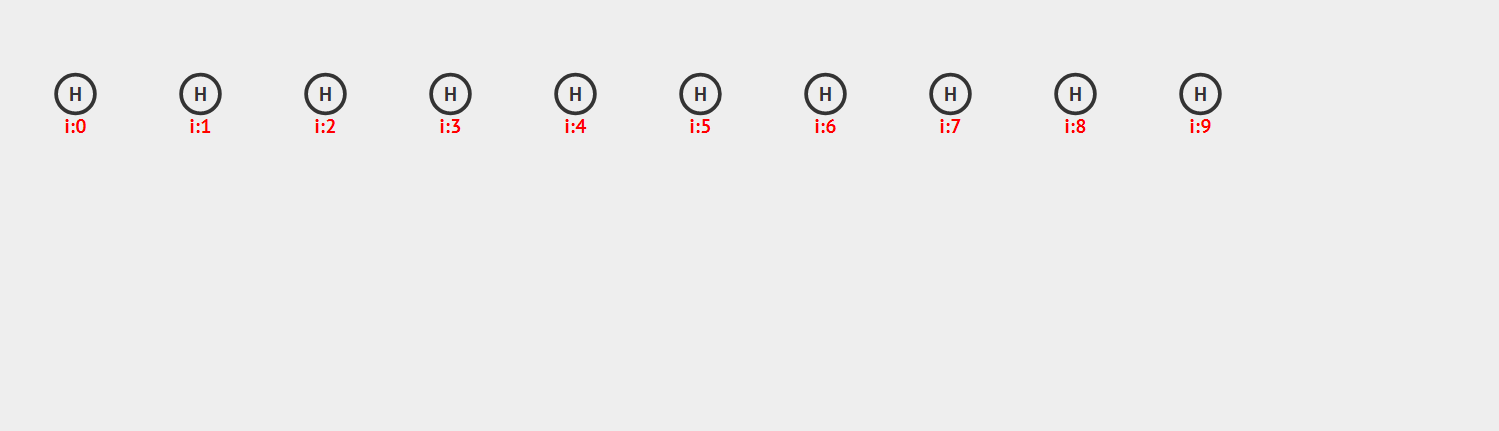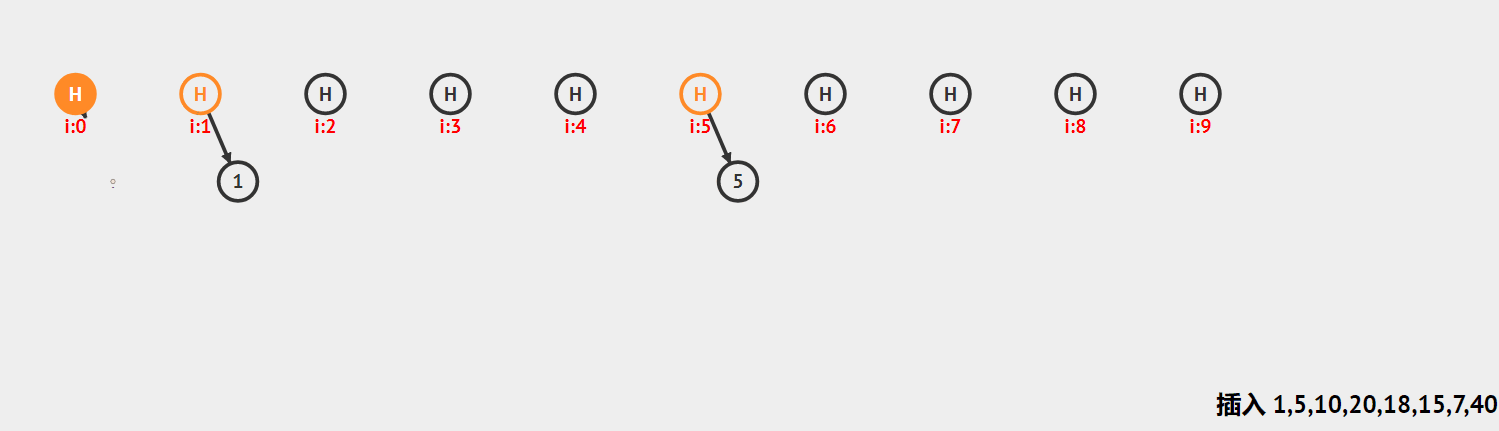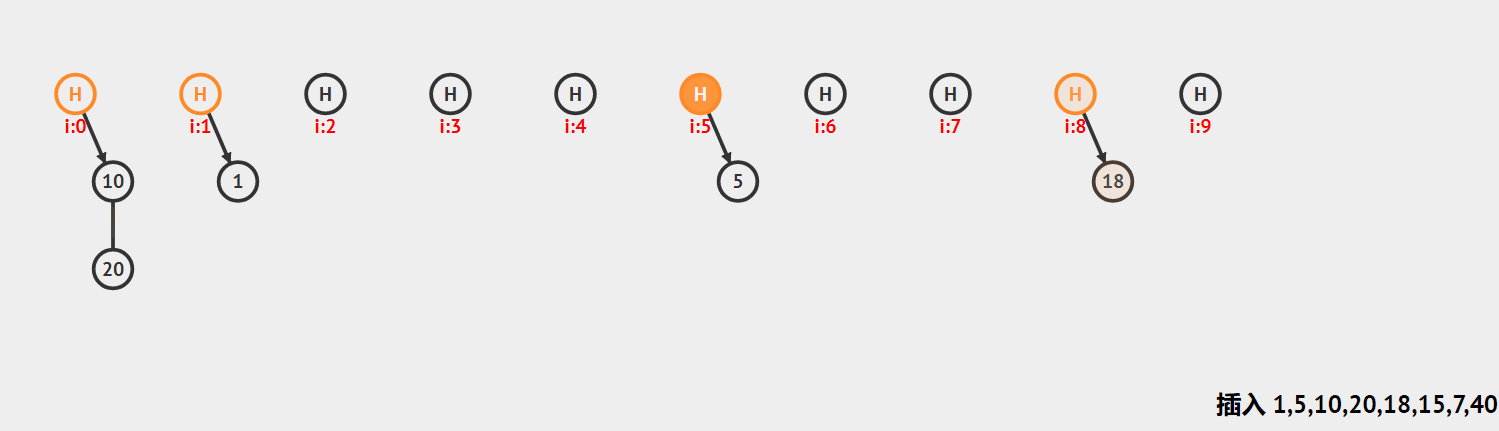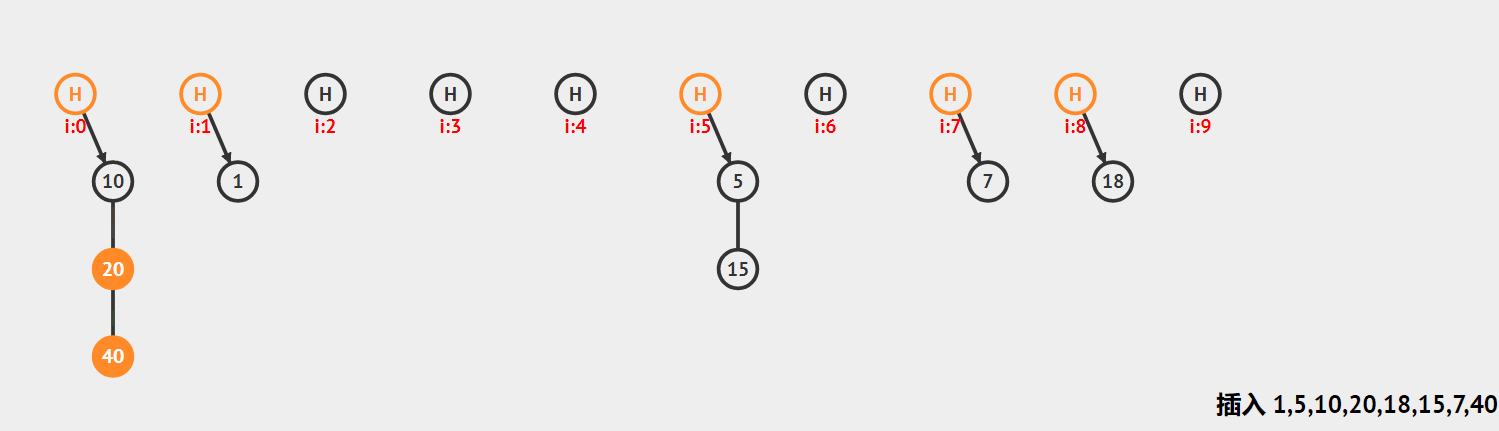
框架
框架:用vector来存放元素,存放的是每个链表的头节点
//仿函数template<classK>structDefaultHash{ size_t operator()(const K& key){return(size_t)key;}};//仿函数特化字符串template<>structDefaultHash<string>{ size_t operator()(const string& key){// 将所有字符加起来 size_t hash =0;for(auto ch : key){//减少类似苹果,果苹缺陷 hash = hash *131+ ch;}//返回所有字符相加的整数return hash;}};//节点template<classT>structHashNode{ T _data; HashNode<T>* _next;HashNode(const T& data):_data(data),_next(nullptr){}};//模板参数第一个是key关键字,第二个参数不同容器V的类型不同,可以是K,也可以是pair<K,V>类型//第三个参数因为T的类型不同,通过value取key的方式就不同,第四个参数就是一个仿函数,为了获取V中K的值然后取模template<classK,classT,classKeyOfT,classHashFunc>classHashTable{typedef HashNode<T> Node;public:private:// 指针数组 vector<Node*> _tables; size_t _n =0;// 记录表中的数据个数};
插入
插入:
- 防止出现数据冗余,所以先查找Key,存在返回false,根据元素个数考虑增容,通过哈希函数确定关键字的位置,然后把节点挂头插
- 处理增容,创建新的哈希表,大小是原来旧表的2倍,遍历旧表,算出在新表中的位置,在将结点头插到新表中,旧表位置的指针置空,交换两张哈希表
pair<iterator,bool>Insert(const T& data){ HashFunc hf; KeyOfT kot;//如果表中已经有该元素返回false,不能出现数据冗余//插入成功则返回迭代器 iterator pos =Find(kot(data));if(pos !=end()){returnmake_pair(pos,false);}// 负载因子为1就增容if(_tables.size()== _n){//新表的大小等于旧表的2倍 size_t newSize = _tables.size()==0?10: _tables.size()*2;//进行增容,创建一个新的哈希表 vector<Node*> newTable;//把newsize给新表,并将表的位置初始化 newTable.resize(newSize,nullptr);for(size_t i =0; i < _tables.size();++i){//将原链表节点取出来插入 Node* cur = _tables[i];while(cur){//记录下一个节点位置 Node* next = cur->_next;//先用kot将key取出来,利用仿函数将取出来的key转换成整形然后取模 size_t hashi =hf(kot(cur->_data))% newSize;//将cur连接到新节点上 cur->_next = newTable[hashi]; newTable[hashi]= cur;//变化cur之前提前记录 cur = next;}//旧桶置空 _tables[i]=nullptr;}//交换2个哈希表 newTable.swap(_tables);}//计算出映射的位置 size_t hashi =hf(kot(data)); hashi %= _tables.size();// 头插到对应的桶即可 Node* newnode =newNode(data); newnode->_next = _tables[hashi]; _tables[hashi]= newnode;++_n;returnmake_pair(iterator(newnode,this),false);}
查找
查找:
- 计算出在哈希表中的映射位置
- 在该桶下遍历结点在链表的位置,必须找到位置状态为 EXIST 且 key 值匹配才算成功,若 key 值匹配但该位置状态为 DELETE,则需继续进行查找,因为该位置的元素已经被删除了
iterator Find(const K& key){//不能进行除0操作if(_tables.size()==0){//返回迭代器returniterator(nullptr,this);} KeyOfT kot; HashFunc hf; size_t hashi =hf(key);//下面是另外一种写法//size_t hashi = HashFunc()(key);//先计算出映射的位置 hashi %= _tables.size();//遍历链表的位置 Node* cur = _tables[hashi];while(cur){//找到返回结点if(kot(cur->_data)== key){returniterator(cur,this);} cur = cur->_next;}returniterator(nullptr,this);}
删除
删除:
- 先算出在哈希表中的映射位置
- 然后对元素节点进行删除,将待删除位置置为 DELETE 即可,没找到就删除失败
boolErase(const K& key){//不能进行除0操作if(_tables.size()==0){returnfalse;} HashFunc hf; KeyOfT kot; size_t hashi =hf(key);//先计算出映射的位置 hashi %= _tables.size();//保存cur的前1个结点 Node* prev =nullptr;//开始删除 Node* cur = _tables[hashi];while(cur){//找到了开始删除if(kot(cur->_data)== key){//删除第一个节点if(prev ==nullptr){//指向cur的下一个结点 _tables[hashi]= cur->_next;}else{ prev->_next = cur->_next;} _n--;delete cur;returntrue;} prev = cur; cur = cur->_next;}returnfalse;}
版权归原作者 企鹅不叫 所有, 如有侵权,请联系我们删除。