
作者:石臻臻, CSDN博客之星Top5、Kafka Contributor 、nacos Contributor、华为云 MVP ,腾讯云TVP, 滴滴Kafka技术专家 、 KnowStreaming PMC)。
KnowStreaming 是滴滴开源的Kafka运维管控平台, 有兴趣一起参与参与开发的同学,但是怕自己能力不够的同学,可以联系我,带你一起你参与开源! 。
KnowStreaming 体验环境请访问:https://demo.knowstreaming.com/
文章目录
在上一篇文章中,我们分析了JoinGropRequest的流程,详细请看Kafka消费者JoinGroupRequest流程解析
那么我们知道,在执行完了JoinGroupRequest之后, 所有的Member都对消费组协调器发起了SyncGroupRequest请求
那么SyncGroup具体做了哪些事情呢?我们今天来一起分析一下!
1. 请求参数
当我们JoinGroup完成之后, 消费者客户端收到了Response, 然后就会立马发起SyncGroupRequest
相关代码如下
JoinGroupResponseHandler#onJoinLeader
或者
JoinGroupResponseHandler#onJoinFollow
这两个的区别是,如果当前Member是Leder Member则调用的是 onJoinLeader。’
onJoinFollow
和
onJoinLeader
区别在于前者不会带上Assignments数据,onJoinLeader互根据分区分配策略计算一下当前的分配情况然后传入请求。
// 公众号:石臻臻的杂货铺privateRequestFuture<ByteBuffer>onJoinLeader(JoinGroupResponse joinResponse){try{// 根据分区分配策略 计算分配情况Map<String,ByteBuffer> groupAssignment =performAssignment(joinResponse.data().leader(), joinResponse.data().protocolName(),
joinResponse.data().members());List<SyncGroupRequestData.SyncGroupRequestAssignment> groupAssignmentList =newArrayList<>();for(Map.Entry<String,ByteBuffer> assignment : groupAssignment.entrySet()){
groupAssignmentList.add(newSyncGroupRequestData.SyncGroupRequestAssignment().setMemberId(assignment.getKey()).setAssignment(Utils.toArray(assignment.getValue())));}SyncGroupRequest.Builder requestBuilder =newSyncGroupRequest.Builder(newSyncGroupRequestData().setGroupId(rebalanceConfig.groupId).setMemberId(generation.memberId).setProtocolType(protocolType()).setProtocolName(generation.protocolName).setGroupInstanceId(this.rebalanceConfig.groupInstanceId.orElse(null)).setGenerationId(generation.generationId).setAssignments(groupAssignmentList));
log.debug("Sending leader SyncGroup to coordinator {} at generation {}: {}",this.coordinator,this.generation, requestBuilder);returnsendSyncGroupRequest(requestBuilder);}catch(RuntimeException e){returnRequestFuture.failure(e);}}
1.1 请求头RequestHeader
一般来说, 正常的一个请求都包含如下数据
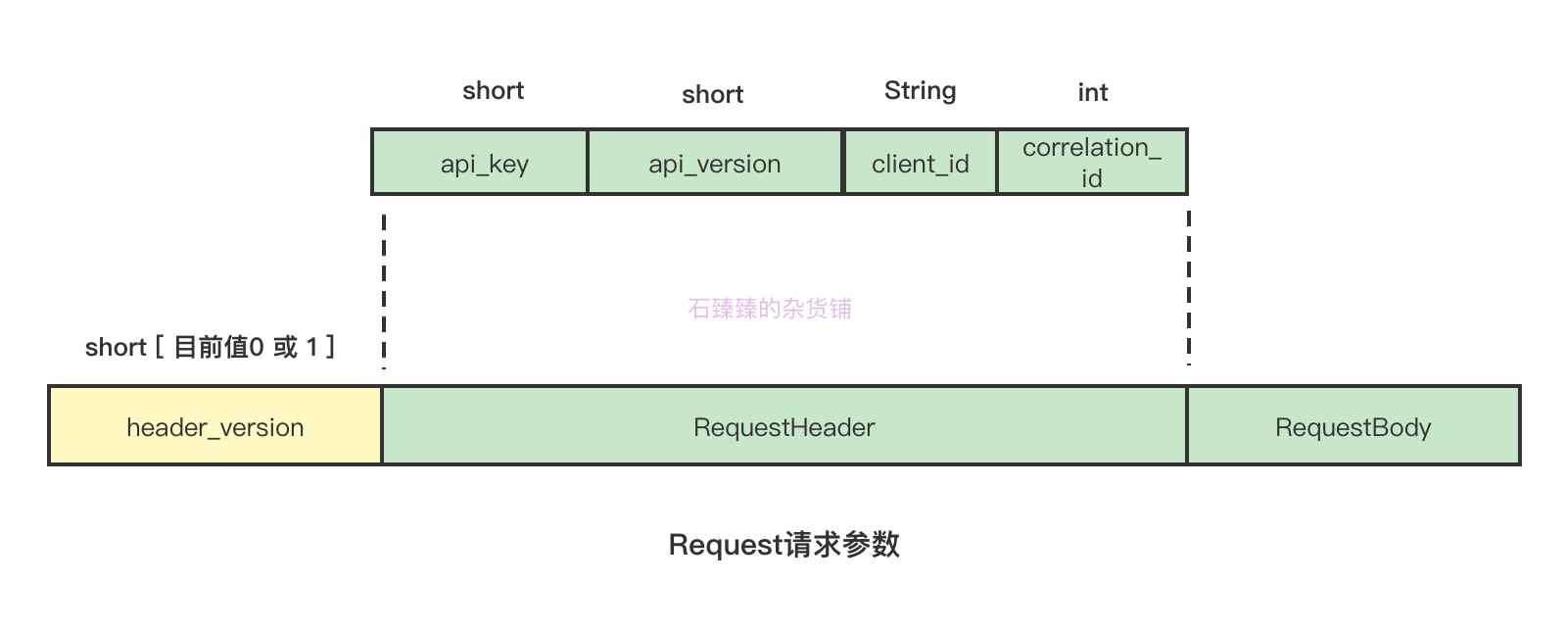
1 .header_version 请求头版本号
请求头版本号, 请求头的版本目前有 0 和 1; 每个请求对应使用哪个headerVersion的映射关系在
ApiMessageType#requestHeaderVersion
2. api_version: 请求的标识ID
每个类型的请求都有他对应的唯一ID, 比如这里的JoinGroupRequest对应的ID是 11 ; 映射关系在
ApiMessageType
3. api_version: 该请求的版本号
因为我们可能会对某个请求类型做过改动, 并且改动了请求的Schemas, 那么每次改动都是一个版本, 比如SyncGroupRequest这个请求总共就有6个版本, 那么当前发起的请求的版本号是 :
Schema.length -1 = 6 - 1 = 5
下面的JoinGroupRequest的Schemas, 不同请求类型的Schemas不一样, 可以通过ApiKeys下面的每个请求查看。
publicstaticfinalSchema[]SCHEMAS=newSchema[]{SCHEMA_0,SCHEMA_1,SCHEMA_2,SCHEMA_3,SCHEMA_4,SCHEMA_5};publicstaticfinalSchemaSCHEMA_5=newSchema(newField("group_id",Type.COMPACT_STRING,"The unique group identifier."),newField("generation_id",Type.INT32,"The generation of the group."),newField("member_id",Type.COMPACT_STRING,"The member ID assigned by the group."),newField("group_instance_id",Type.COMPACT_NULLABLE_STRING,"The unique identifier of the consumer instance provided by end user."),newField("protocol_type",Type.COMPACT_NULLABLE_STRING,"The group protocol type."),newField("protocol_name",Type.COMPACT_NULLABLE_STRING,"The group protocol name."),newField("assignments",newCompactArrayOf(SyncGroupRequestAssignment.SCHEMA_4),"Each assignment."),TaggedFieldsSection.of());
4. client_id: 客户端ID
客户端唯一标识
5. correlation_id: 每次发起的请求的唯一标识
发起的每次请求的唯一标识, 该值自增。
1.2 RequestBody
上面的RequestHeader基本上都大差不差,不同Request类型的RequestBody是不一样的.
本次SyncGroupRequest的属性如下

1. group_id 消费组id
属性group.id 配置
2. member_id 消费者成员ID
消费者的成员id, 默认就是空字符串, 客户端不可设置。 该值会在后续的请求中返回并被赋值。
3. group_instance_id
客户端属性:
group.instance.id
默认值 空)
Kafka2.3版本引入的新参数. 用户提供的消费者实例的唯一标识符。 如果设置了,消费者则被视为静态成员, 静态成员配以较大的session超时设置能够避免因成员临时不可用(比如重启)而引发的Rebalance, 如果不设置, 消费者将作为动态成员
4. generation_id 消费组协调器年代ID
每个消费组协调器的年代ID,没经过一次变化 这个id就是自增1, 比如新增Member、Leave Member 等等操作都会引起年代的增长。
5. protocol_type 协议类型
Consumer发起的协议是
comsumer
, 另一个可选项为
connect
6. protocol_name 分配策略
消费组分区分配策略, 比如
range
7. assignments 每个member对应的分配分区
这个参数,只有是Leader Member发起请求的时候才会带上, 这个请求是每个Member分配到的分区信息。
里面包含着 partitions 、userData 等信息。如下
单个assignment的数据结构是
privateList<TopicPartition> partitions;privateByteBuffer userData;
2. 发起请求
2.1 向哪个协调器节点发起请求
既然要发起请求,那么究竟是哪个节点呢?之前客户端向集群发起请求的计算方式一般都是获取最小负载的节点发起请求。
那么这里可不一样, 这里发起请求的Node是有具体要求的, 那就是向协调器 coordinator 发起。
那么问题来了, 谁是协调器, 协调器的节点是哪个?
先说结论:
该客户端的
group.id
的hash值跟
__consumer_offsets
分区数取模得到的分区号, 这个分区号的Leader在哪个Broker,那么这个Node就在哪个Broker上。
一个Broker可能有多个Node, 使用哪个Node取决于客户端发起请求时候使用的是哪个listener。 客户端发起请求对应的listener就对应着相应的Node。
PS: 如果leader不存在或者不在线, 会提示异常:
The coordinator is not available
具体流程请看
寻找协调器FindCoordinatorRequest请求流程
2.2 发起请求时机
我们既然要发起SyncGroup的请求, 那么我们是在什么时候才会触发这个请求呢?
在上一篇文章 Kafka消费者JoinGroupRequest流程解析 我们有知道, 在所有JoinGroupRequest都Join完成并收到回调之后, 这些收到回调的Member都会立马发起SyncGroup请求,来请求协同最终的分配。
我们看一下 JoinGroupRequest 的时序图
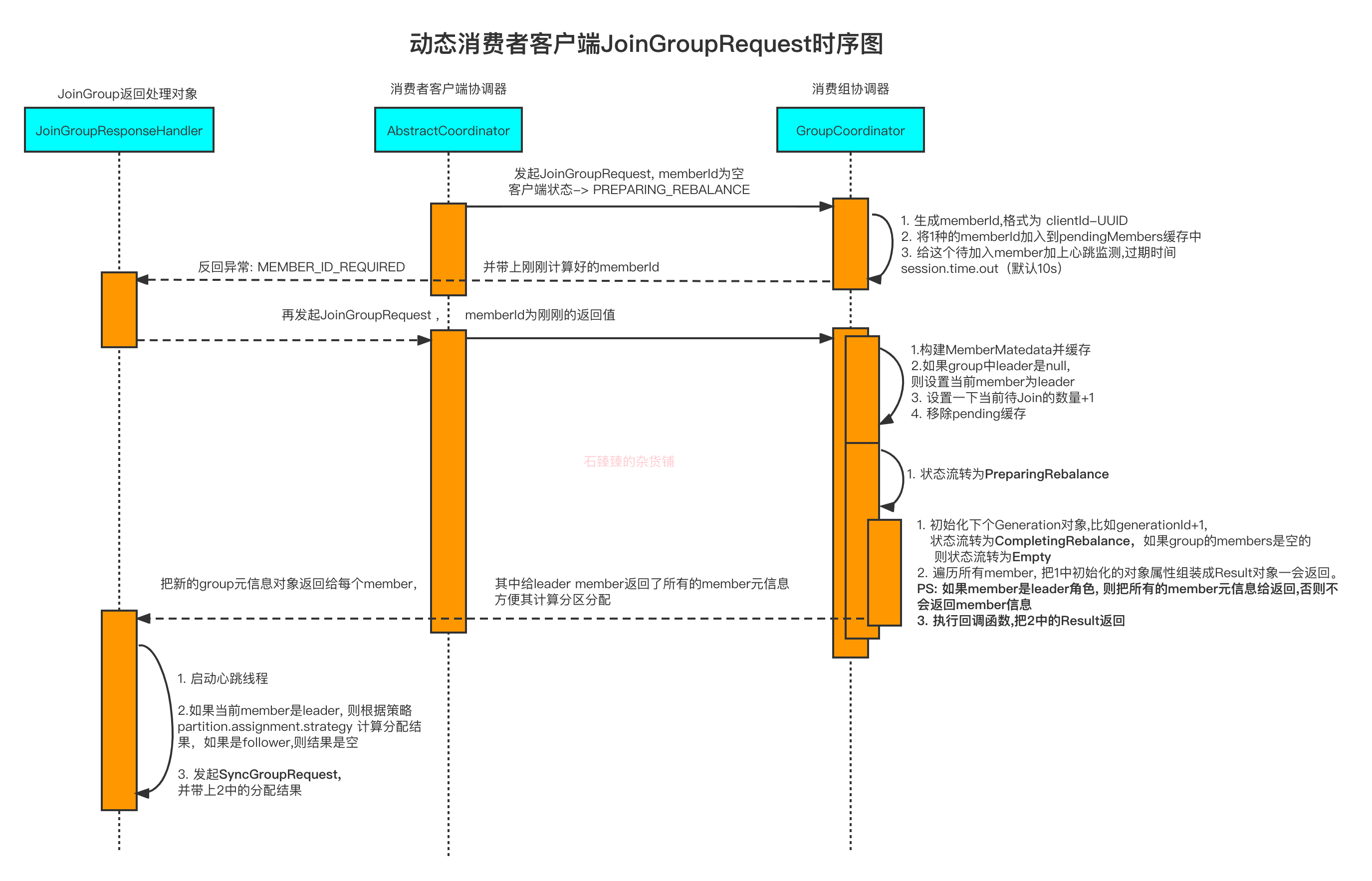
上图的左边 JoinGroupResponseHandler 最后是发起了SyncGroupRequest
但是要注意, Leader Member和Follower Member是有区别的, Leader Member 会接收到所有Member的元信息,然后根据 Kafka消费者客户端分区分配策略 计算每个Member应该分配到的分区信息, 然后把这个信息当做入参, 发送给组协调器( GroupCoordinator )
但是Follow Member没有这个信息的, 你看下面这个就是Follower的请求,Assignments 那一个属性都是空集合。
AbstractCoordinator#onJoinFollower
privateRequestFuture<ByteBuffer>onJoinFollower(){// send follower's sync group with an empty assignmentSyncGroupRequest.Builder requestBuilder =newSyncGroupRequest.Builder(newSyncGroupRequestData().setGroupId(rebalanceConfig.groupId).setMemberId(generation.memberId).setProtocolType(protocolType()).setProtocolName(generation.protocolName).setGroupInstanceId(this.rebalanceConfig.groupInstanceId.orElse(null)).setGenerationId(generation.generationId).setAssignments(Collections.emptyList()));
log.debug("Sending follower SyncGroup to coordinator {} at generation {}: {}",this.coordinator,this.generation, requestBuilder);returnsendSyncGroupRequest(requestBuilder);}
3. 协调器接受请求
协调器接受到客户端发来的SyncGroup请求进行处理
处理入口:KafkaApi#handleSyncGroupRequest
真正处理的地方:GroupCoordinator#handleSyncGroup
def handleSyncGroup(groupId:String,
generation:Int,
memberId:String,
protocolType: Option[String],
protocolName: Option[String],
groupInstanceId: Option[String],
groupAssignment: Map[String, Array[Byte]],
responseCallback: SyncCallback):Unit={
validateGroupStatus(groupId, ApiKeys.SYNC_GROUP)match{case Some(error)if error == Errors.COORDINATOR_LOAD_IN_PROGRESS =>// 如果协调器还在加载中, 意味着该组需要从JoinGroup重新开始,返回异常:REBALANCE_IN_PROGRESS 给客户端进行处理
responseCallback(SyncGroupResult(Errors.REBALANCE_IN_PROGRESS))case Some(error)=> responseCallback(SyncGroupResult(error))case None =>
groupManager.getGroup(groupId)match{case None => responseCallback(SyncGroupResult(Errors.UNKNOWN_MEMBER_ID))case Some(group)=> doSyncGroup(group, generation, memberId, protocolType, protocolName,
groupInstanceId, groupAssignment, responseCallback)}}}
- 如果发现消费组协调器还在加载中,返回异常REBALANCE_IN_PROGRESS, 让客户端重新从JoinGroup发起请求。
- 如果当前缓存中不存在给定的memberId的menber,说明可能已经异常,则返回异常
- 执行
doSyncGroup
doSyncGroup
代码省略。
- 一些异常检验
- 如果当前Group的State是 Empty, 则直接返回UNKNOWN_MEMBER_ID异常(Group都是空的,还同步个球)
- 如果当前状态是PreparingRebalance,返回异常: REBALANCE_IN_PROGRESS; 这个状态一般还没有JoinGroup完成呢
- 如果状态是Stable,什么也不做,直接返回当前Group的分组情况就行了。
- 如果是CompletingRebalance状态,那么就对了, JoinGroup完成之后就是这么个状态的。这里要判断一下过来的Member是不是Leader Member,不是Leader Member啥也不做。就设置了一下回调参数,一会自己会被回调。如果是Member的话,我们就需要把当前的Group元信息给持久化一下了。相当于是每次重平衡都会把新的数据持久化存储;详情看下面
状态是CompletingRebalance并且请求来源是Leader Member则做下面的逻辑
// 公众号:石臻臻的杂货铺//wx: shiyanzu001
groupManager.storeGroup(group, assignment,(error: Errors)=>{
group.inLock {// 另一个成员可能在我们等待此回调时加入了该组,// 因此我们必须确保我们仍处于 CompletingRebalance 状态并且在它被调用时处于同一代。// 如果我们已经转换到另一个状态,那么什么都不做if(group.is(CompletingRebalance)&& generationId == group.generationId){if(error != Errors.NONE){// 写入数据的过程出现了异常了; //1.更新本地缓存,将所有的member分配方式设置为empty,//2:遍历所有member, 把孔的分配方案返回给他们。
resetAndPropagateAssignmentError(group, error)
maybePrepareRebalance(group,s"error when storing group assignment during SyncGroup (member: $memberId)")}else{// 传播分配方式;1.先更新本地缓存 2.遍历所有member, 把他们各自的分配方案 返回给他们。
setAndPropagateAssignment(group, assignment)//装换状态为Stable
group.transitionTo(Stable)}}}})
这段代码做的事情如下
3.1 存储Group元信息storeGroup
- 根据
group.id找到对应的__consumer_offset分区,获取magicValue, 就是看下当前日志文件的版本号,关于消息体结构请看图解Kafka的RecordBatch结构 - 组装Group元信息的Key、Value结构,关于Group元信息数据结构请看:消费组偏移量_consumer_offset的数据结构

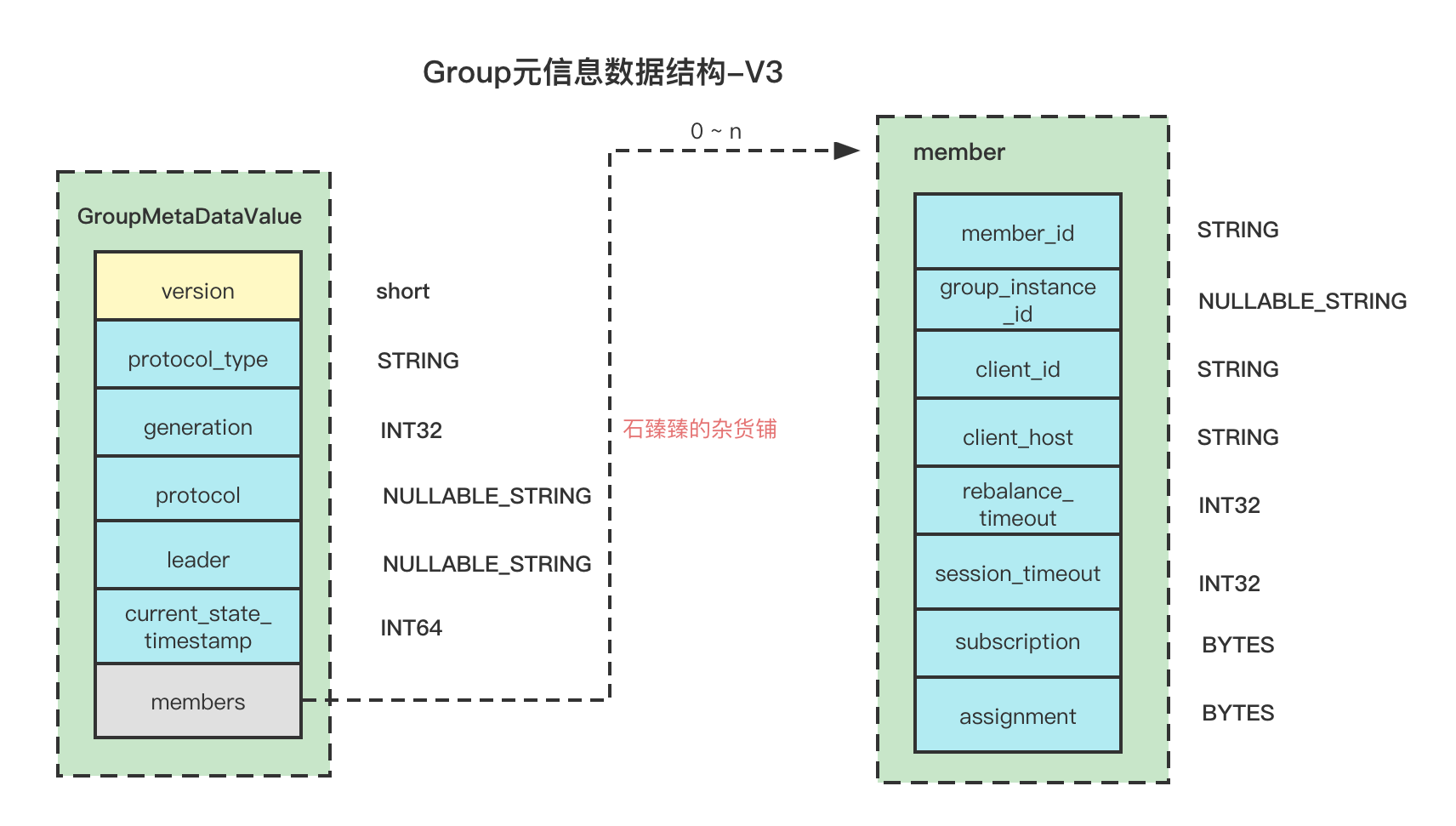
- 消息的 压缩类型是
offsets.topic.compression.codec默认是 0; 对应的压缩k-v映射关系为{ 0:NONE、1:GZIP、2:SNAPPY、3:LZ4、4: ZSTD} - 把消息写入到 对应的TopicPartition中 ,Topic为
__consumer_offset,分区是group.id计算出来的。写入消息的一些基本配置如下:配置默认描述offsets.commit.timeout.ms5000偏移量提交将被延迟,直到偏移量主题的所有副本都收到提交或达到此超时。这类似于生产者请求超时offsets.commit.required.acks-1偏移量提交的Ack设置,可选项 0、1、-1 ,默认-1.一般不建议去修改此值 - 在写入过程如果出现写入失败,异常了,则重置所有Member的分配方案为Empty,并返回数据给各自的消费者客户端(客户端会再次发起JoinGroup请求);完了之后执行
maybePrepareRebalance方法; 这个时候状态会流转为PreparingRebalance,等待Memmber们的再次JoinGroup。然后再加一个有效期为[max.poll.interval.ms,默认值300000(5 分钟)] 的onCompleteJoin任务, 这个任务会在所有的Member都JoinGrop之后,会执行方法:GroupCoordinator#onCompleteJoin, 是不是熟悉的方法又来了, ( 因为我们在 Kafka消费者JoinGroupRequest流程解析 分析过 ) 把结果返回给所有的Member,告知JoinGroup成功了! 那么客户端是不是又得重新再来发起SyncGropuRequest(在这个方法里面呢,如果Group已经是Empty了,那么也是会去在写入一个空的Group元信息的。) - 如果正常写入, 则传播新的分配方案给每个Member,注意,每个Member只会收到自己的分配方案。然后当前Group状态流转为 Stable
4. 返回客户端
上面我们说到了 Sync之后会给Member发起回调,那么拿到回调之后客户端是如何处理的呢?
SyncGroupResponseHandler#handle
/**
* 公众号:石臻臻的杂货铺
* VX : shiyanzu001
**/privateclass SyncGroupResponseHandler extends CoordinatorResponseHandler<SyncGroupResponse,ByteBuffer>{private SyncGroupResponseHandler(final Generation generation){super(generation);}@Override
public void handle(SyncGroupResponse syncResponse,
RequestFuture<ByteBuffer> future){
Errors error = syncResponse.error();if(error == Errors.NONE){if(isProtocolTypeInconsistent(syncResponse.data.protocolType())){//省略...}else{
synchronized (AbstractCoordinator.this){// 因为在JoinGroup完成的时候状态已经变更为了COMPLETING_REBALANCE, //想要流转为STABLE只能是这个状态的if(!generation.equals(Generation.NO_GENERATION)&& state == MemberState.COMPLETING_REBALANCE){if(protocolNameInconsistent){//省略...}else{// 一切正常,将状态变更为稳定状态
state = MemberState.STABLE;
rejoinNeeded =false;// record rebalance latency
lastRebalanceEndMs = time.milliseconds();
lastRebalanceStartMs =-1L;// 把获取到的assigment 分配数据往上抛出返回给消费者客户端处理
future.complete(ByteBuffer.wrap(syncResponse.data.assignment()));}}else{//省略...}}else{//异常情况 ,需要重新发起 JoinGroup的请求哦
requestRejoin();if(error == Errors.GROUP_AUTHORIZATION_FAILED){// 省略很多异常情况代码...}}}}
- 检验一些异常, 如果异常会重新Join;requestRejoin
- 如果无异常,则将客户端状态更新为STABLE状态, 一定是从COMPLETING_REBALANCE 流转到 STABLE; 关于客户端状态流转图请看
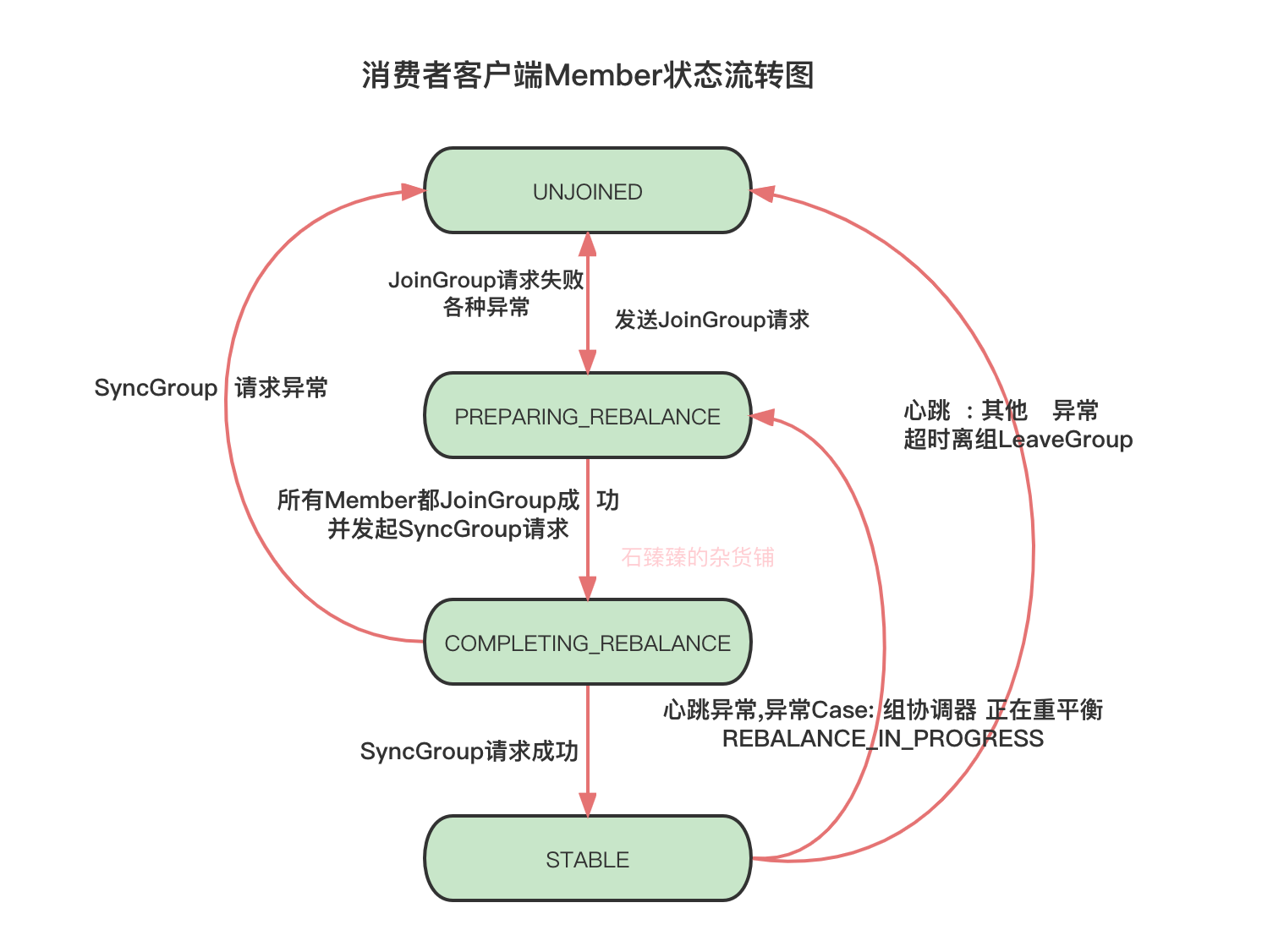
- 把接收到的分配信息
memberAssignment更新一下消费者客户端,这个更新的逻辑在AbstractCoordinator#onJoinComplete
4.1 onJoinComplete 同步成功
这个是只有当Member的状态为 MemberState.STABLE的时候才会被执行到的。
Member的状态稳定了之后, 并且也拿到了新的分配方案了
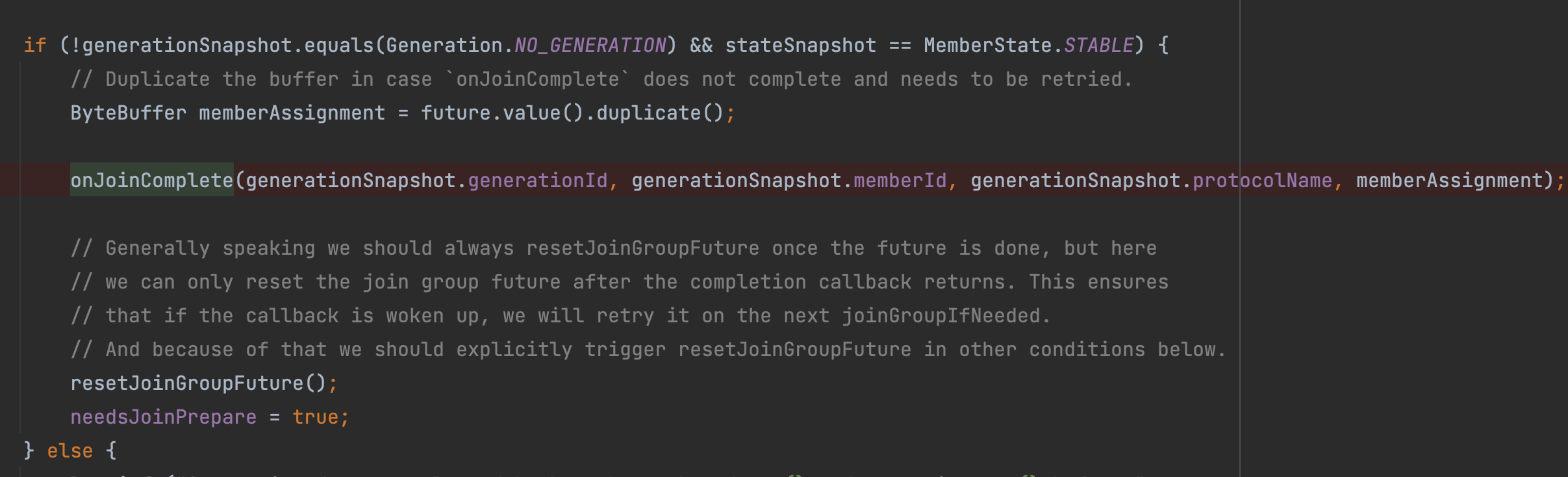
AbstractCoordinator#onJoinComplete
/**
* 公众号:石臻臻的杂货铺
* wx: shiyanzu001
**/@OverrideprotectedvoidonJoinComplete(int generation,String memberId,String assignmentStrategy,ByteBuffer assignmentBuffer){//省略..}
这里代码太长,总结一下
- 更新客户端元数据
- 做一些简单校验
- 如果是以正则表达式规则订阅的 Topic,尝试去更新一下是否有命中新的Topic
- 回调
assignor.onAssignment - 把新的分配方式更新到自己的缓存里面。
总结

附录: 消费者客户端状态流转图和消费组协调器状态流转图
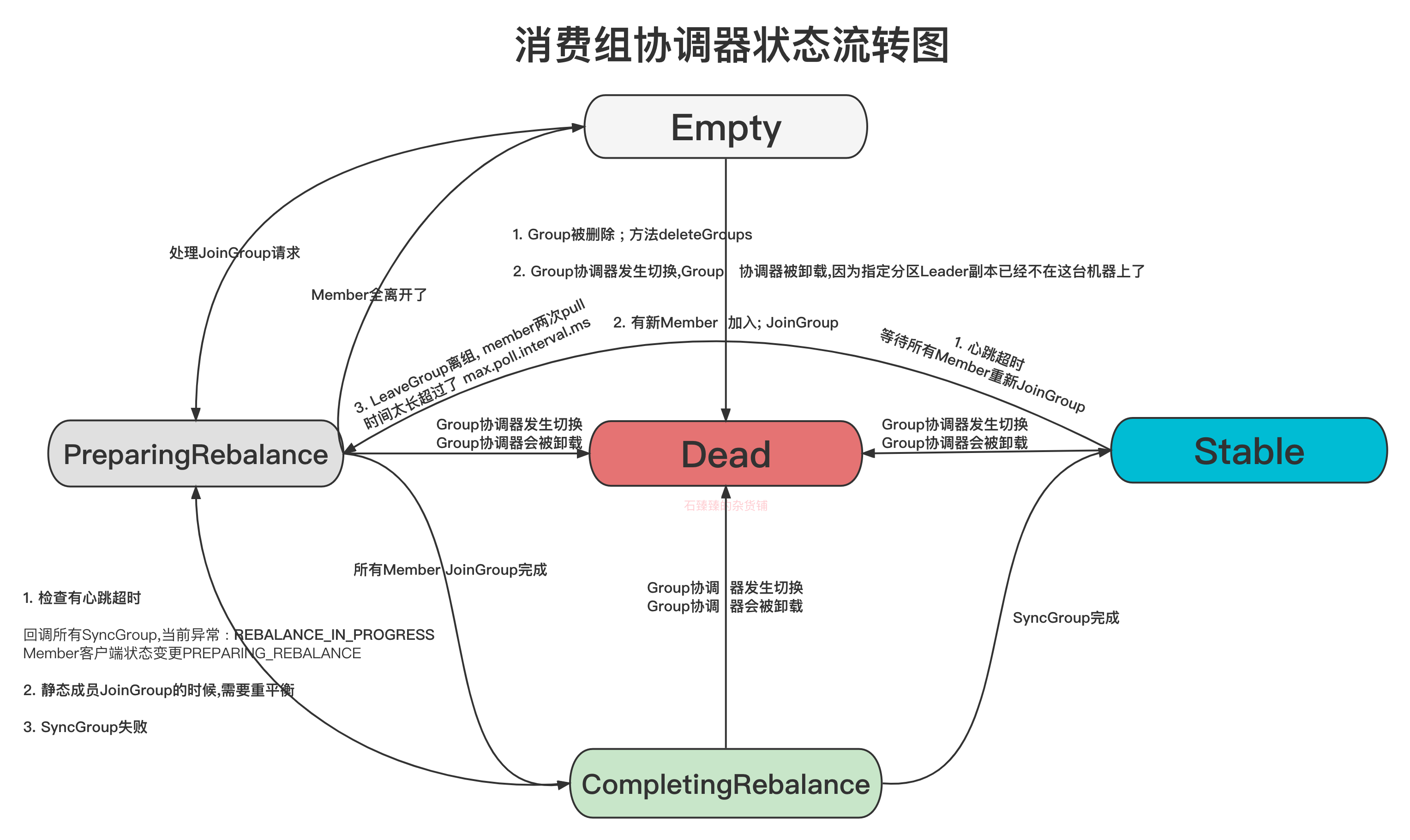
版权归原作者 石臻臻的杂货铺 所有, 如有侵权,请联系我们删除。