
最近 Reddit 的 r/golang 下有人问了一个如何做数据库 schema 变更的问题,不到一天,就有了超过 40 条回复。
数据库 schema 变更一直是让程序员头疼的问题,但又不得不面对,毕竟业务要发展,产品要迭代,添加新的功能往往需要去修改数据库的结构,比如添加一个新的字段来保存新的信息,那么这就涉及到数据库 schema 的变更。
先看提问者的 2 个问题:
问题 1 - 缺少变更的可见度
因为可能就开发者或者 DBA 直接连到数据库,就执行了变更语句,具体执行了什么语句,什么时候执行的这些只有当事人自己知道(或者说当事人回过头来也可能忘记了)。
问题 2 - 保证变更的唯一性和排他性
一个应用通常代码会部署多个副本,但都连着同一个数据库。从提问者的描述看,他们当前是在新的代码版本启动时,去尝试变更数据库的。那么问题来了,当多个新代码版本的副本同时启动时,到底如何保证只有其中一个副本可以对数据库进行变更,而其他副本先等待着呢。
提问者最后也在问有没有推荐的变更最佳实践和工具,可以用于生产环境。从最佳实践角度,主要就 2 点:
- 像对待代码变更一样对待数据库变更
- 把代码变更和数据库变更分离
而 Bytebase 就是结合这套最佳实践的数据库变更工具。
像对待代码变更一样对待数据库变更
我们先来看一下典型的代码变更流程:
- 在 GitLab / GitHub 这样的代码平台提交变更请求,GitLab 里叫 MR (Merge Request),GitHub 上叫 PR (Pull Request)。
- 如果有配的话,MR / PR 会先经过一系列的自动检察,比如最简单的比如代码是否可以编译,是否符合编码规范,以及一系列的自动化测试。
- 会有一个或多个评审人对代码进行审核 (Code Review)。
- 审核通过后,代码就提交到仓库了,提交历史也被记录了一下。
- 经过手动或者自动的流程,代码会被打包成一个新版本,专业的术语叫做制品(Artifact)。
- 代码部署系统会把新版本按照预先配置的流程,逐渐部署出去。通常先部署到测试环境,在测试环境里,会运行一些集成测试,也可能会有 QA 团队进行手工测试。在测试环境通过后,就会部署到预发环境,在预发环境验证后,最终会部署到生产环境,当然在生产环境,往往也会一点点的逐步更新,也就是所谓的灰度发布。
前面介绍的也就是大家现在所熟知的应用 CI/CD 流程,归纳出来不长,但其实也是花了业界 20 多年才摸索出了这套如今约定俗成的方案,解决了代码变更和发布里的协同,可见度,可靠性,效率等一系列问题。
而数据库的变更因为涉及到数据也就是状态(state)的变更,虽然流程上可以借鉴代码变更的思路,但还是更加复杂的。Bytebase 就是这样一套把代码变更的流程引入到数据库变更的工具。
可视化的变更审核界面
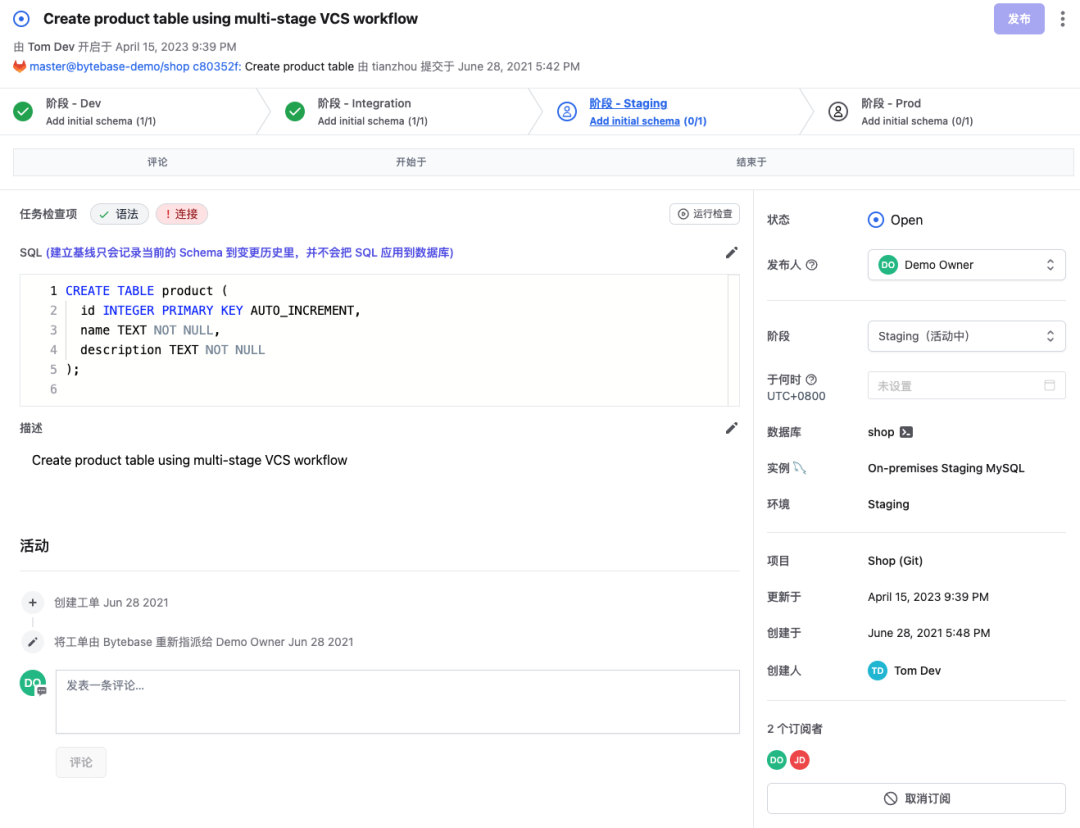
Bytebase 提供了可视化的变更审核界面,开发者和 DBA 可以在同一个界面上对于数据库变更进行协作。
自动 SQL 审核规则
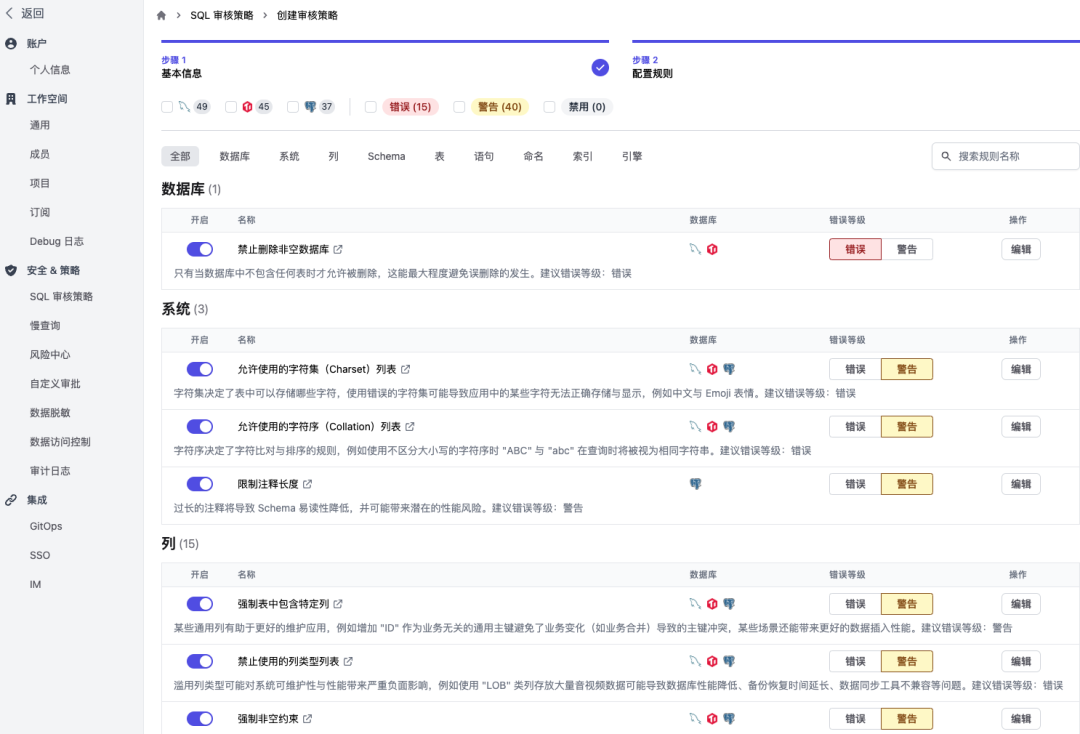
Bytebase 提供了总共 100+ 多条自动 SQL 审核规则,无须 DBA 介入,就能前置地检察开发者提交的语句是否符合规范。这里可以进一步阅读来自用户的案例分享「SQL 审核案例分享回顾|如何搞定 300 个研发」
数据库代码化 Database as Code
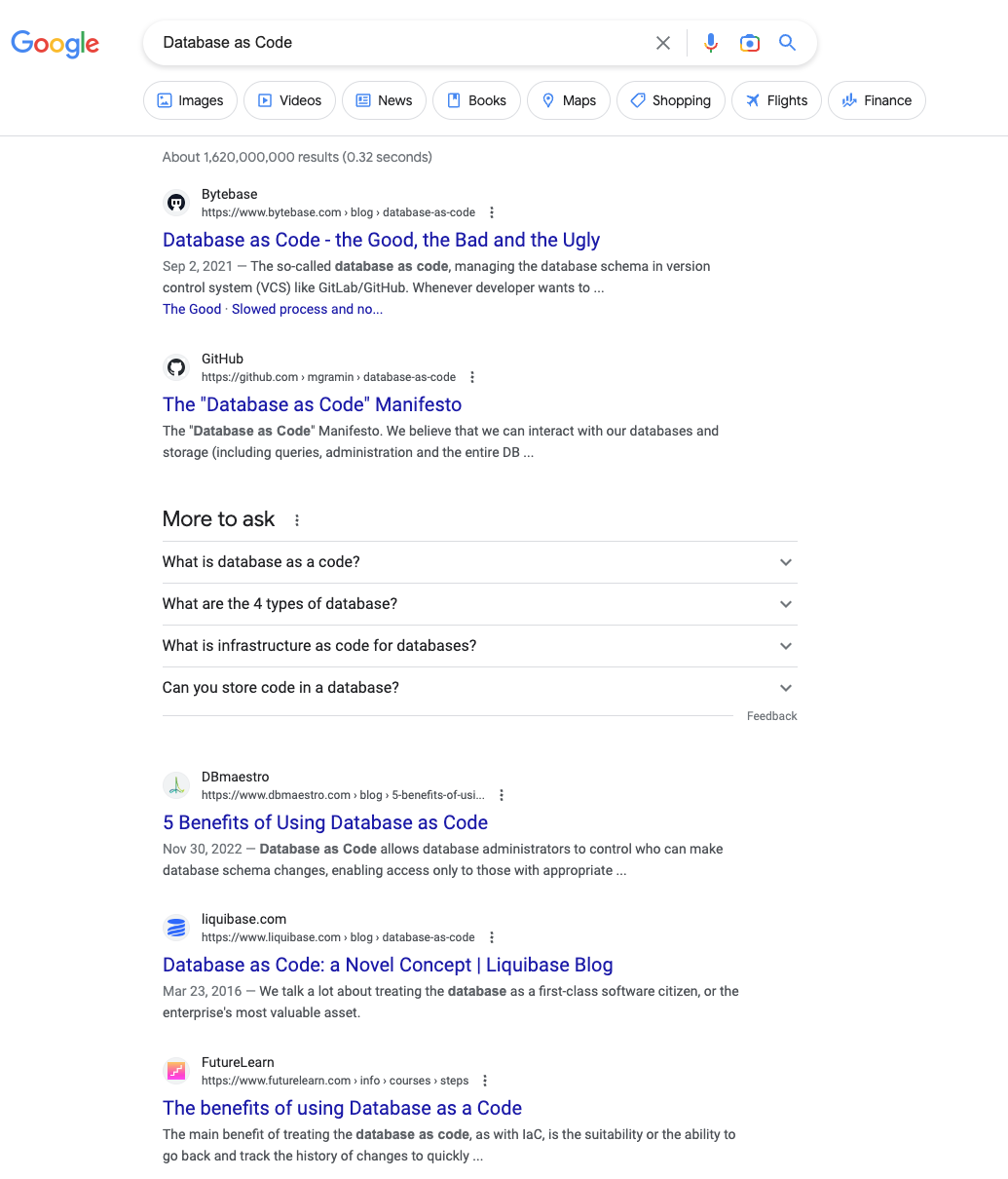
Bytebase 是数据库代码化的布道者和领导者,如果在 Google 上搜索 Database as Code 的话,Bytebase 关于 Database as Code 的阐述也是排名第一的,领先于像 Liquibase,DBmaestro 这样的老牌厂商。
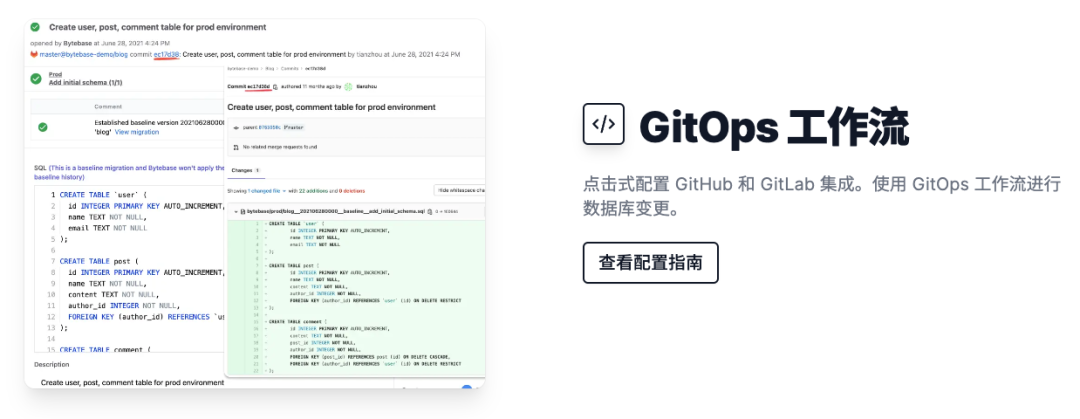
Bytebase 是目前业界唯一提供了点击式的配置交互,类似于 Terraform Cloud / Vercel 这样的体验,就可以配置好 GitOps 工作流。配置完成后,研发还是在他们熟悉的代码仓库中提交数据库的变更文件,在审核完成提交到代码仓库后,会自动触发在 Bytebase 这边的部署流程。
批量变更(企业版功能)
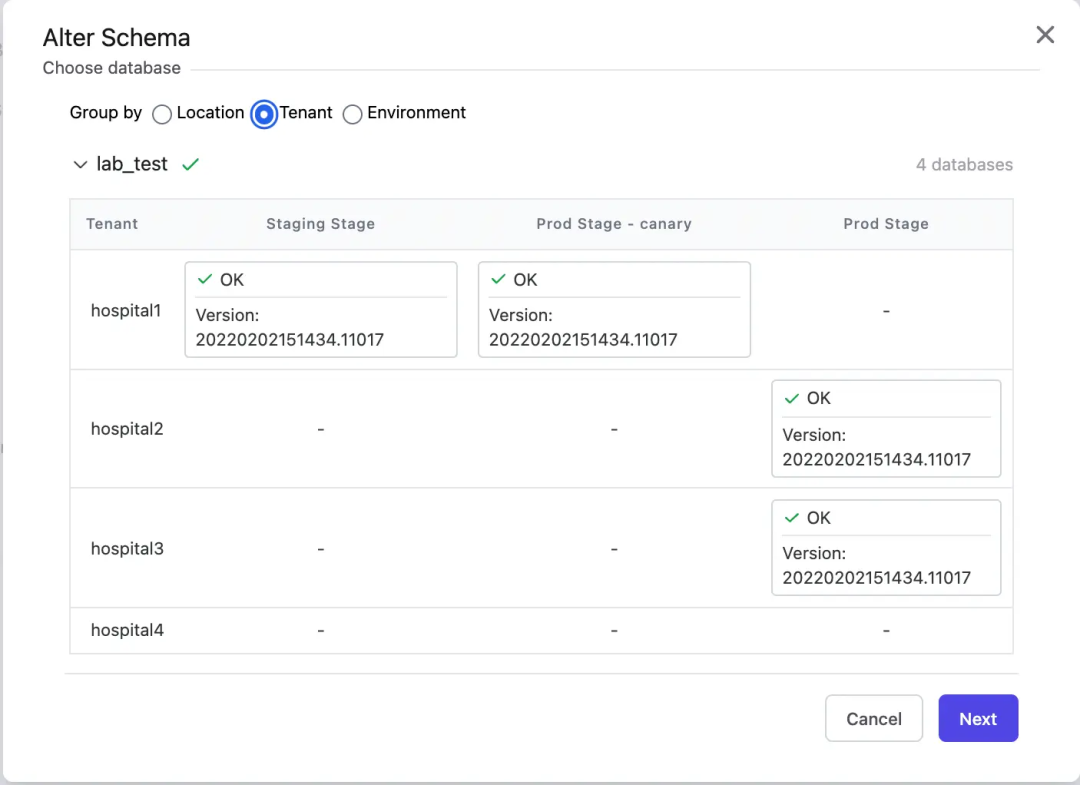
变一个数据库已经不容易了,同时变一堆数据库呢?这个需求其实在企业里很常见,比如不同研发环境就对应着不同的数据库;SaaS 公司,会给每一个租户分配独立的数据库;游戏公司,不同的服务器背后对应的其实也就是不同的数据库;因为容灾或者数据合规的要求,不同地区也会部署各自的数据库;当然也不能忘了互联网常见的分库分表场景。这些数据库的结构都是相同的,所以一旦变更,也要是能保持一致。Bytebase 就专门针对这种场景设计了批量变更的能力,像下图所示,展示了变更一次医院 SaaS 系统的数据库,针对不同的医院租户在不同环境上变更的一个二维进展图。
自定义审批流(企业版功能)
自从 1.16.0 版本,Bytebase 也推出了基于风险模型的自定义审批流。用户首先定义数据库操作的风险等级,然后再根据不同的风险等级来配置相对应的审批流。
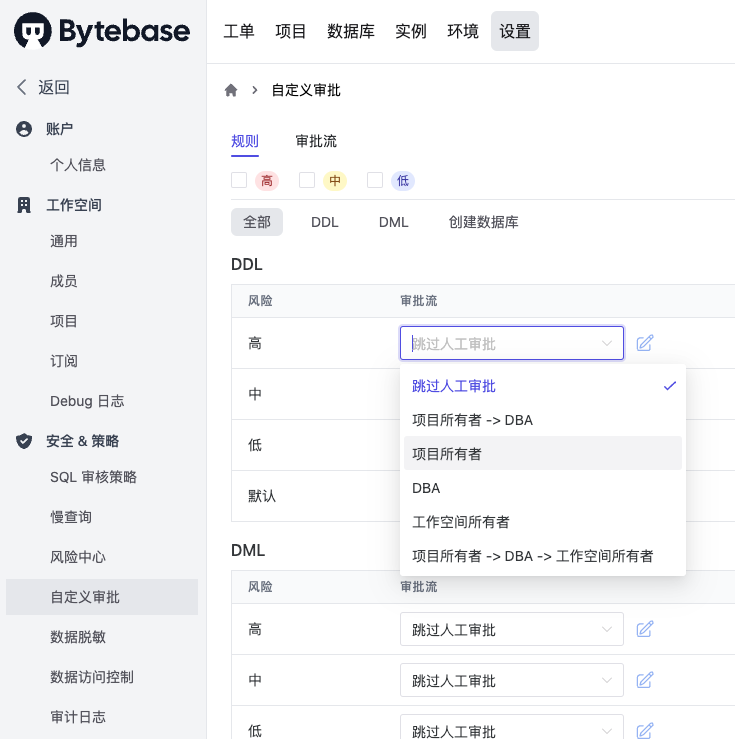
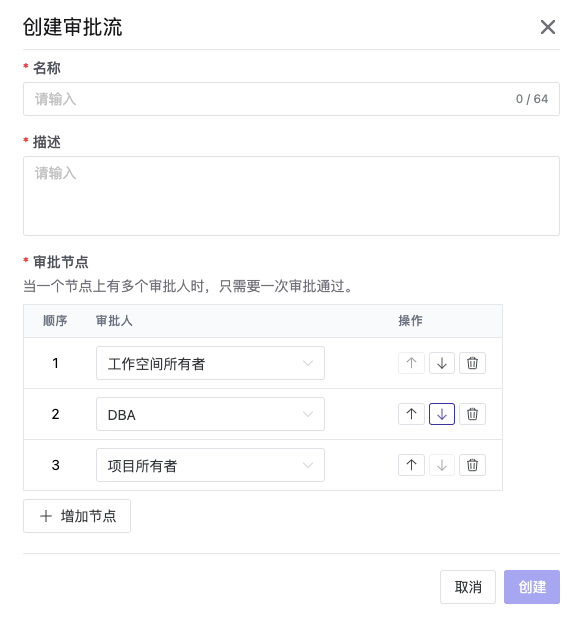
审批节点可以自定义,因为 Bytebase 有独特的项目概念,所以说在审批节点上,还可以指定具体该项目的 DBA,测试负责人这些。
Image
把代码变更和数据库变更分离
一个应用有两大部分组成,一块是代码,一块是数据,前者专业的术语叫无状态(stateless),后者则对应有状态(statefull)。无状态的代码变相对好解决,因为如果变更有问题,直接回滚就完事了。但有状态的数据变更就难多了,变更的时候要考虑是否会把数据库锁住导致整个服务的不可用,回滚也不是那么好弄的,因为有脏数据的问题。
小团队起步时,通常会把数据库变更和代码变更放在一起,但就像那个 Reddit 提问者遇到的一样,规模上去后就会面临问题:
- 当变更出问题后,可控力很小。应用程序将无法启动,这需要人工干预。
- 一些变更可能需要很长时间才能完成,这意味着在部署新版本发布时需要停机。
- 不适合于有多个服务器实例访问同一数据库的应用。因为任何一个服务器实例都可以执行变更,而且需要额外的锁机制来协调变更(就是 reddit 提问者提到的那个问题)
- 不适合有专门的 DBA 或平台工程团队来中心化管理数据库的团队协作模式。集中的 DBA 或平台工程师不知道什么时候发生了变更,他们只会在收到监控系统告警后,然后花费大量的精力去诊断后,才发现是由一个应用团队鲁莽的变更引起的。
有状态的数据和无状态的代码是两个完全不一样的物种,针对代码的变更发布,有 GitLab / GitHub + Octopus / Jenkins 这样的集中式 CI/CD 平台,而针对数据库的变更发布,Bytebase 起到的就是类似的作用。
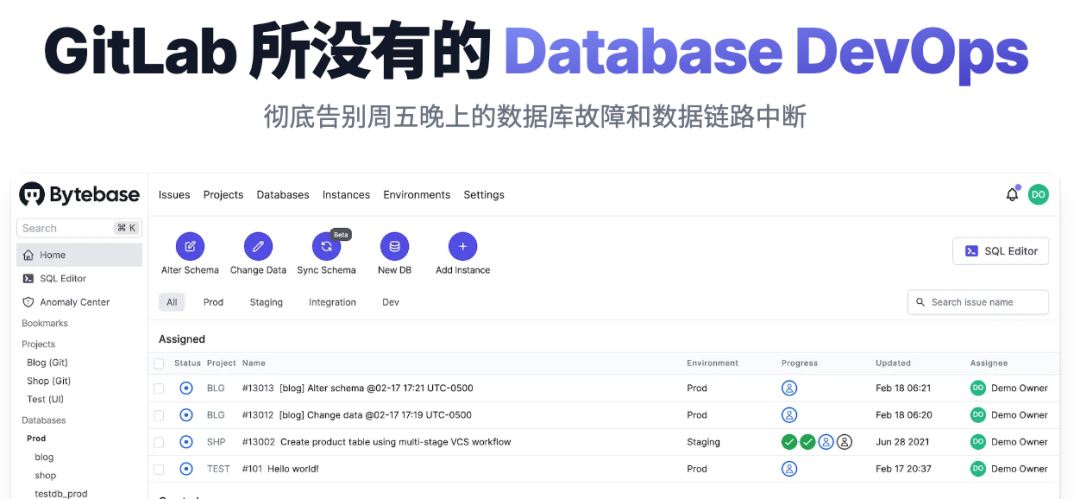
所以 Bytebase 也把自己称为数据库届的 GitLab,承担了 Database DevOps 的职责。我们也像 GitLab 一样,采用了类似的开源策略,也同时既有托管的 SaaS 服务,也支持私有化部署。
Image
升舱的免费版,让更多团队可以进行安全高效的数据库变更
市面上也有像 Yearning, Archery 这样个人维护的社区项目,而 Bytebase 走的则是商业化路线,有完整建制的产研团队。Bytebase 之前也提供免费版,但因为能力上的限制,使得许多团队有所顾忌,还是采用了社区里完全免费的方案。于是在上周,我们进行了 Bytebase 有史以来最大的版本功能调整,主要是针对 Bytebase 免费版的定位进行了调整,从定位于服务个人兴趣项目以及团队产品验证,调整为了可以覆盖大多数研发团队中心化管理数据库生命周期的所有核心场景。具体到功能点上,免费版的功能得到了大大的增强💎
- 本来只存在于付费版的 RBAC 功能移到了免费版。
- 100+ 条的自动 SQL 审核策略全部开放给了免费版。
- 不再有 10 个用户,10 个实例的限制,而是无限用户,20 个实例。
相应的,也是因为免费版也具备了足够服务团队的产品能力。所以本来付费的团队版名字就不那么贴切了,所以我们也把本来的团队版名字改成了专业版(Pro)。
这次调整的底气,也是因为经过 2 年多的开发, 我们也构建了足够的产品功能梯度,可以在提供覆盖核心场景的免费版基础上,还能进一步提供差异化的功能点,提供给我们的企业级用户。比如单点登录,DBA 工作流,自定义审批,批量变更,环境分级,数据脱敏,访问控制,水印,审计日志,读写分离等都是专门提供给我们企业级用户的能力。
Bytebase 作为一款 infra 层的开源工具,从第一天起的定位就是做一款全球化的产品。事实上,目前 Bytebase 海外的整体营收也高于国内。只要开发应用,就需要和数据库打交道,不限行业,不限地域。而 Bytebase 就是要帮助全球各地,来自不同行业的研发团队一站式管理云上云下,不同云之间,不同数据库的变更,查询,安全,治理四大问题。
就像提到代码托管,大家会想到 GitLab / GitHub,提到监控仪表盘,就是 Prometheus / Grafana,提到多云管理,就是 Terraform。而我们将要变成的现实,就是当大家提到数据库的开发管理时,想到的就是 Bytebase😇。
💡 你可以访问官网,免费注册云账号,立即体验 Bytebase。
版权归原作者 Bytebase 所有, 如有侵权,请联系我们删除。