
一.DataFrame 简介
Spark SQL****使用的数据首先并非RDD,而是DataFrame
DataFrame是一种以RDD为基础的分布式数据集,DataFrame可以完成RDD的绝大多数功能。
DataFrame的结构类似于传统数据库的二维表格,并且可以从很多数据源中创建,如结构化文件、外部数据库、Hive表等数据源。
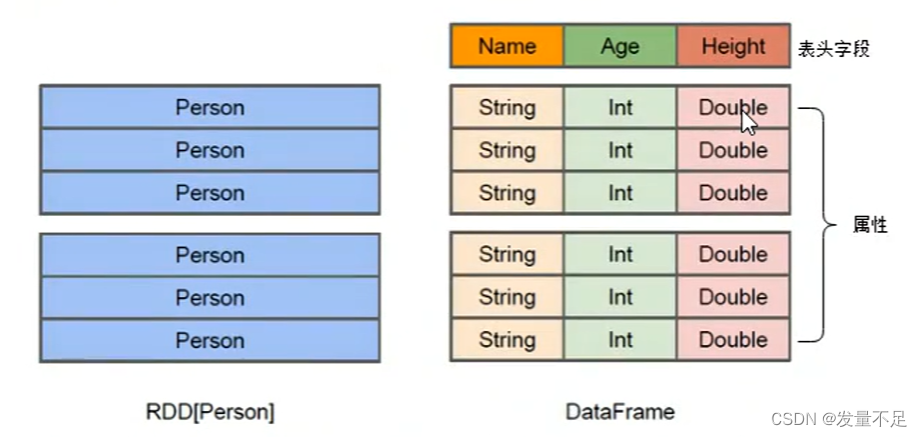
RDD:分布式弹性数据集,分布式Java对象存储。
DataFrame:可以看出分布式Row对象的集合,在二维表数据集的每一列都带有名称和类型,这些就是schema(元数据)
DataFrame与Hive类似支持嵌套数据类型(如Struct、Array、Map)
DataFrame:除了提供比RDD更丰富的算子外,更重要的特点是提升Spark框架执行效率,减少数据的读取时间,和优化执行结果。
二.DataFrame 的创建
先启动集群和Spark
zkServer.sh start(在opt目录下)
start-all.sh(随意目录下)
sbin/start-all.sh(在spark目录下启动)
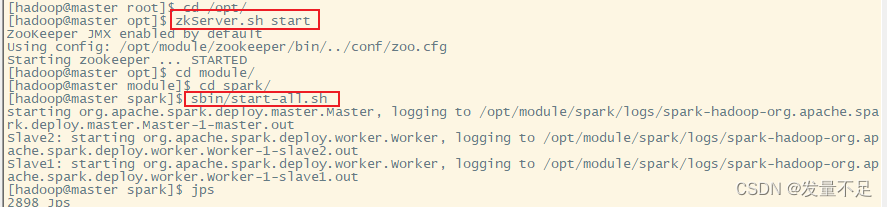 在slave1和slave2下启动zkServer.sh start
在slave1和slave2下启动zkServer.sh start

数据准备
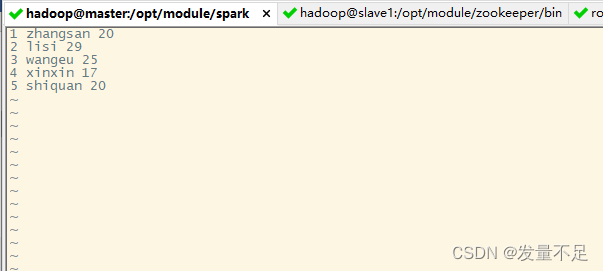
在spark目录下创建文本
vi person.txt
输入如下内容
hadoop fs -put person.txt /spark/
**hadoop fs -ls /spark/ **(查看是否成功)

**#**启动Spark-Shell
#Spark-shell –master local[2]
或者如下
Step 3 启动Spark
bin/spark-shell spark://master:7077,slave1:7077,slave2:7077

直接创建DataFrame
val personDataFrame = spark.read.text("/spark/person.txt")
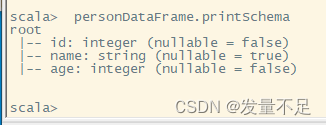
personDataFrame.printSchema()
personDataFrame.show()


RDD转换DataFrame
通过RDD的toDF()方法,可以将RDD转换为DataFrame对象,具体代码如下所示:
//读文件并按空格分割成 数组RDD
val lineRDD = sc.textFile("/spark/person.txt").map(_.split(" "))

//定义样式类
case class Person(id:Int,name:String,age:Int)

//转换成lineRDD
val personRDD = lineRDD.map(x=>Person(x(0).toInt, x(1),x(2).toInt))

//转换DataFrame
val personDataFrame = personRDD.toDF()

//显示DataFrame
personDataFrame.show

三.DataFrame 的常用操作
DataFrame提供了两种语法风格,1 DSL风格语法,2 SQL语法风格
DSL风格语法:
1 show:查看DataFrame中具体类容信息
2 printSchema:查看DataFrame中Schema信息
3 select:查看DataFrame中选取部分列的数据
personDataFrame.show

personDataFrame.printSchema
Select:col:某一列,as:重命名 filter:过滤groupBy() ,对记录进行分组sort排序
personDataFrame.select(personDataFrame.col("name")).show

personDataFrame.filter (personDataFrame.col("age")>=25).show

personDataFrame.sort (personDataFrame.col("age").desc).show

版权归原作者 发量不足 所有, 如有侵权,请联系我们删除。