
基于 Docker 搭建完全分布式 Hadoop 平台
前言
学校课程要求学习Hadoop,老师说要用VM虚拟机,搭建至少3个结点的集群,我寻思使用Docker不是更方便快捷吗,一来不用重复配置了,二来可能趁此机会学习Docker用法,于是就开始折腾了。
作此文,供学习记录。
如果只是希望尽快搭建好环境,可以参见文章 “通过已有镜像极速搭建” 部分,直接使用打包并配置好的镜像。
环境
Dockers20.10.7 + Hadoop3.3
其它工具:VS Code的Dockers插件
遇到的坑
- 一开始使用腾讯云学生机 CentOS 7 的服务器来搭建环境,但是在Dockers中启动Hadoop3.10时可能会导致服务器卡死,只能重新启动服务器。 原因:不明。尝试在本机搭建,暂且解决问题。[更新:可能是ip冲突]
- 找不到hadoop/etc/hadoop/slaves文件,自行创建后配置无效 原因:3.3版本中,slaves文件被workers文件取代,配置workers文件即可
- 运行yum install 报错:Failed to download metadata for repo ‘AppStream’ [CentOS] 原因:centOS Linux8的官方源已经停止服务,需要更换源,我采用的是更换为阿里源(参考链接2) 参考链接1:Failed to download metadata for repo ‘AppStream’ [CentOS] 参考链接2:CentOS 镜像 更新:此解决方案已弃用,CentOS8环境无法执行示例程序,直接换用CentOS7即可
- 巨坑:千万不要用CentOS8作为Hadoop环境!!! 在start-all时完全没问题,但是一旦运行示例程序,就会显示无法连接从机 解决方案:换用CentOS7
- 报错:执行示例程序报错Cannot create directory /usr. Name node is in safe mode. 原因:打开了安全模式 解决方案:关闭安全模式,执行
hdfs dfsadmin -safemode leave
折腾实录
本次折腾参考了这篇19年的文章:使用Docker搭建Hadoop集群(伪分布式与完全分布式)
注意,本文与上述参考文章有所不同(都是趟过的坑)
一、构建镜像
1. 准备JDK和Hadoop
- 创建对应目录并准备好JDK和Hadoop
mkdir centos-hadoopcd centos-hadoop# 上传hadoop和jdk,略参考链接: Java Download 官网(自行选择合适版本) hadoop 官网(自行选择合适版本) jdk-8u321-linux-x64.tar.gz 官网下载链接 hadoop-3.3.1.tar.gz 官网下载链接
2. 构建centos-hadoop镜像
- 编写Dockerfile
sudo yum install vimvim Dockerfile #这里docker build时缺省名为Dockerfile - Dockerfile内容
FROM centos:centos7 # 安装openssh-server和sudo软件包,并且将sshd的UsePAM参数设置成no RUN yum install -y openssh-server sudoRUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config#安装openssh-clientsRUN yum install -y openssh-clients# 添加测试用户root,密码root,并且将此用户添加到sudoers里 RUN echo "root:root" | chpasswdRUN echo "root ALL=(ALL) ALL" >> /etc/sudoersRUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_keyRUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key# 启动sshd服务并且暴露22端口 RUN mkdir /var/run/sshdEXPOSE 22CMD ["/usr/sbin/sshd", "-D"]ADD jdk-8u321-linux-x64.tar.gz /usr/local/RUN mv /usr/local/jdk1.8.0_321 /usr/local/jdk1.8ENV JAVA_HOME /usr/local/jdk1.8ENV PATH $JAVA_HOME/bin:$PATHADD hadoop-3.3.1.tar.gz /usr/localRUN mv /usr/local/hadoop-3.3.1 /usr/local/hadoopENV HADOOP_HOME /usr/local/hadoopENV PATH $HADOOP_HOME/bin:$PATH - 构建镜像
docker build -t centos-hadoop ./ # docker build -t ImageName:TagName dir - 查看镜像
docker image ls
二、启动容器
网络结构分别为:
- hadoop0:192.168.1.2
- hadoop1:192.168.1.3
- hadoop2:192.168.1.4
- 创建子网
docker network create --subnet=192.168.1.0/24 hadoopnet - 启动容器
docker run -itd --name hadoop0 --net hadoopnet --ip 192.168.1.2 -p 8088:8088 -p 9870:9870 centos-hadoop #hadoop0对外开放端口8088docker run -itd --name hadoop1 --net hadoopnet --ip 192.168.1.3 centos-hadoopdocker run -itd --name hadoop2 --net hadoopnet --ip 192.168.1.4 centos-hadoop``````docker ps # 查看刚刚启动的3个容器
三、集群搭建
ps:以下操作均是对hadoop0主节点配置
1. 进入容器
docker exec -it hadoop0 /bin/bash
2. 配置主机名与IP映射(3个节点)
此时,在启动容器这一步时,docker容器的hadoopnet网络已经添加了主机名与IP映射的映射关系,因此不需要往hosts文件中添加ip和主机名的映射。
可以通过ping命令检查是否已有映射关系:
ping hadoop0
ping hadoop1
ping hadoop2
如果没ping通,可以尝试往hosts文件添加以下内容(hosts文件目录:/etc/hosts)
192.168.1.2 hadoop0
192.168.1.3 hadoop1
192.168.1.4 hadoop2
3. ssh免密登录
ssh-keygen
#剩下的一路回车即可
# 以下3条都不能省,请根据提示输入yes以及主机密码,开头我们设置的是root/root
ssh-copy-id hadoop0
ssh-copy-id hadoop1
ssh-copy-id hadoop2
4. hadoop的相关配置
进入/usr/local/hadoop/etc/hadoop目录,涉及的配置文件有:core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml、workers
- hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8 # 修改JAVA_HOME(往该文件内添加即可) - core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop0:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property></configuration> - hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property></configuration> - yarn-site.xml
<configuration><!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <description>The hostname of the RM.</description> <name>yarn.resourcemanager.hostname</name> <value>hadoop0</value> </property></configuration> - mapred-site.xml
<configuration> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property></configuration>
5. 格式化hadoop
进入进入到/usr/local/hadoop目录下
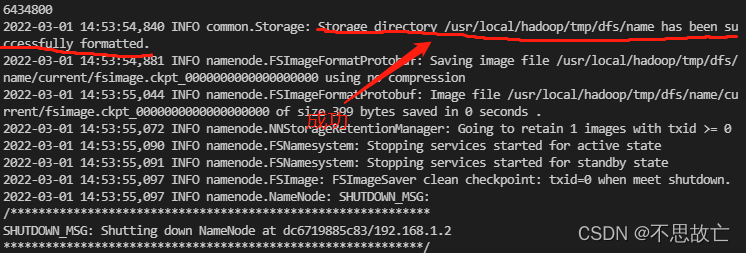
!!!格式化操作不能重复执行
bin/hdfs namenode -format
6. 完全分布式hadoop搭建
进入/usr/local/hadoop
- 修改workers文件 (若为老版本的hadoop,则是slaves文件) 删除原来的所有内容,修改为如下
hadoop1hadoop2 - 拷贝至其他两个节点
scp -rq /usr/local/hadoop/etc hadoop1:/usr/local/hadoopscp -rq /usr/local/hadoop/etc hadoop2:/usr/local/hadoop - 添加变量 进入到目录/usr/local/hadoop/sbin
## 在start-yarn.sh、stop-yarn.sh顶部添加YARN_RESOURCEMANAGER_USER=rootHDFS_DATANODE_SECURE_USER=yarnYARN_NODEMANAGER_USER=root``````## 在start-dfs.sh、stop-dfs.sh顶部添加HDFS_DATANODE_USER=rootHDFS_DATANODE_SECURE_USER=hdfsHDFS_NAMENODE_USER=rootHDFS_SECONDARYNAMENODE_USER=root若不进行变量的添加,会报错找不到变量。 - 启动hadoop分布式集群服务
# 执行sbin/start-all.sh - 若需要中止hadoop分布式集群服务
# 执行sbin/stop-all.sh
7. 验证完全分布式集群是否正常
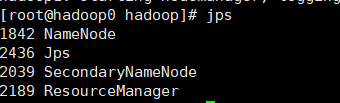
- hadoop0主节点需要有以下进程
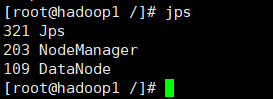
- hadoop1、hadoop2从节点需要有以下进程
- 运示例程序 运行计算PI示例程序,注意不同版本hadoop的路径可能不一样
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 10 10
通过已有镜像极速搭建
待完成…
本文转载自: https://blog.csdn.net/qq_15536617/article/details/123157701
版权归原作者 不思故亡 所有, 如有侵权,请联系我们删除。
版权归原作者 不思故亡 所有, 如有侵权,请联系我们删除。