
SparkStreaming入门案例
一、准备工作
二、任务分析
三、官网案例
四、开发NetWordCount
一、准备工作
- 实验环境:netcat
- 安装nc:yum install -y nc
二、任务分析
将nc作为服务器端,用户产生数据;启动sparkstreaming案例中的客户端程序,监听服务器端发送过来的数据,并对其数据进行词频统计,即为流式的wordcount入门程序
三、官网案例
- 启动nc作为服务器端,执行:nc -l 1234,并输入测试数据,如图所示:

- 启动客户端,执行:bin/run-example streaming.NetworkWordCount localhost1234
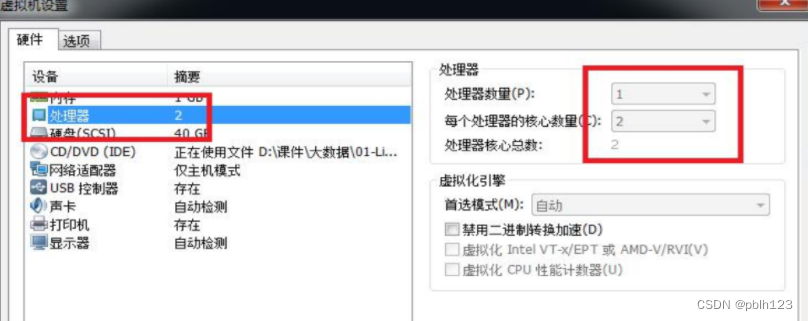
注意):如果要执行本例,必须确保机器 cpu 核数大于 2

四、开发NetWordCount
- 创建maven工程
- 添加maven依赖,即在pom.xml中添加streamming的依赖,如下(如果之前实验已经添加,就不用再添加,如果之前未添加,则需要添加该依赖)
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>2.1.1</version>
</dependency>
3.开发NetWordCount程序
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object StreamingTest {
def main(args: Array[String]): Unit = {
val sparkConf = newSparkConf().setMaster("local[2]").setAppName("StreamingTest")
val streamingContext = new StreamingContext(sparkConf, Seconds(5))
// 创建DStream对象,并链接到nc服务器端
val ris: ReceiverInputDStream[String] = streamingContext.socketTextStream("192.168.245.110", 1234,StorageLevel.MEMORY_AND_DISK)
// 采集数据,并处理数据
val ds: DStream[String] = ris.flatMap(_.split(" "))
println(ris)
// 统计单词
val resultDS: DStream[(String, Int)] = ds.map(x => (x, 1)).reduceByKey(_ + _)
// 打印结果
resultDS.print()
// 启动实时计算
streamingContext.start()
// 等待计算结束
streamingContext.awaitTermination()
}
}
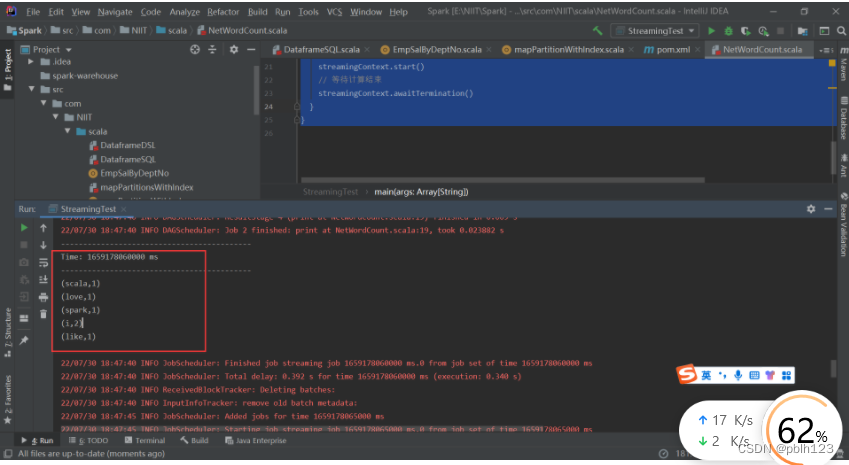
4.先在虚拟机上启动nc服务器:nc -l 1234,并输入测试数据,如图
5.然后运行程序
6.运行结果如下
参考:
本文转载自: https://blog.csdn.net/pblh123/article/details/133856058
版权归原作者 pblh123 所有, 如有侵权,请联系我们删除。
版权归原作者 pblh123 所有, 如有侵权,请联系我们删除。