
前言:
本专栏在保证内容完整性的基础上,力求简洁,旨在让初学者能够更快地、高效地入门TensorFlow2 深度学习框架。如果觉得本专栏对您有帮助的话,可以给一个小小的三连,各位的支持将是我创作的最大动力!
系列文章汇总:TensorFlow2 入门指南
Github项目地址:https://github.com/Keyird/TensorFlow2-for-beginner
经过前面的两篇文章:
- TensorFlow2 入门指南 | 12 tf.keras.Sequential 搭建简单网络模型
- TensorFlow2 入门指南 | 13 Keras Functional API 搭建复杂网络模型
我们学会了如何去搭建简单和复杂的网络模型,网络搭建好意味着成功了一半,下面就是模型的装配、训练和评估环节!
文章目录
一、模型的装配
通过模型装配可以指定模型训练时的损失函数、评价指标和优化器,TensorFLow 提供了内部函数 compile() 进行模型的装配。
compile函数定义如下:
compile(
optimizer='rmsprop', loss=None, metrics=None, loss_weights=None,
weighted_metrics=None, run_eagerly=None, steps_per_execution=None,**kwargs
)
函数重要参数解释如下:
参数解释optimizer优化器loss损失函数metrics评价指标……
其中,metrics 参数为列表,你的模型可以具有任意数量的指标。
下面给出一个简单的例子:
model.compile(
optimizer=keras.optimizers.RMSprop(learning_rate=1e-3),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=[keras.metrics.SparseCategoricalAccuracy()],)
注:如果你的模型具有多个输出,则可以为每个输出指定不同的损失和指标,并且可以调整每个输出对模型总损失的贡献,后面的文章将会带你具体了解。
TensorFLow 提供许多内置优化器、损失函数和评价指标。对于初学者来说,你不必从头开始创建自己的损失、指标或优化器,可以选择直接调用: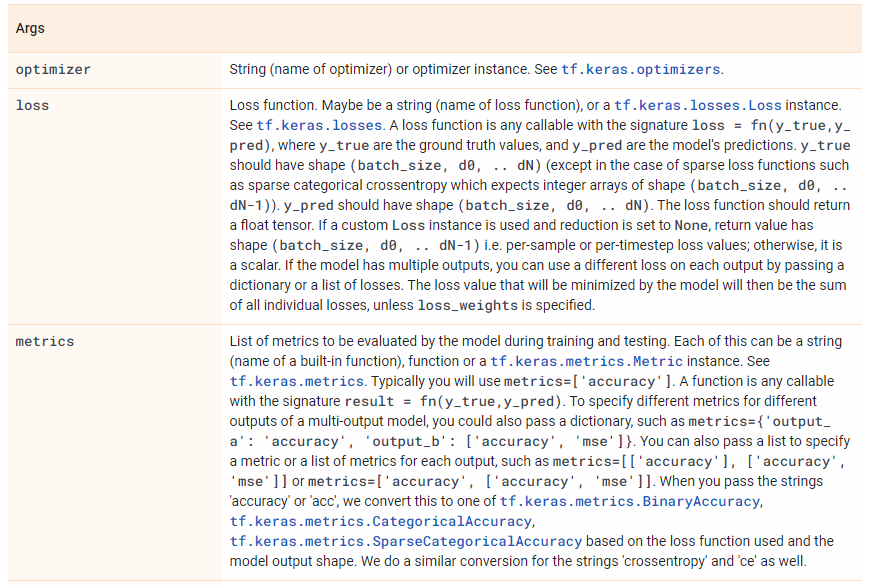
当然,对于进阶者而言,需要进一步掌握如何自定义损失函数、评价指标,这也是我在后面文章中将要带大家学习的内容。
二、模型的训练
当模型搭建、装配完毕,就可以进行模型的训练了。TensorFlow 提供了内置函数 fit() 来进行模型训练。函数定义如下:
fit(
x=None, y=None, batch_size=None, epochs=1, verbose='auto',
callbacks=None, validation_split=0.0, validation_data=None, shuffle=True,
class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None,
validation_hsteps=None, validation_batch_size=None, validation_freq=1,
max_queue_size=10, workers=1, use_multiprocessing=False)
函数重要参数解释如下:
参数解释x训练输入样本y训练输入标签batch_size一次迭代的样本数epochs训练轮数validation_data验证集……
具体可参考:https://tensorflow.google.cn/api_docs/python/tf/keras/Model
下面给出一个简单的例子:
history = model.fit(
x_train,
y_train,
batch_size=64,
epochs=10,
validation_data=(x_val, y_val),)
三、模型的评估
模型进行训练时,想要知道模型泛化性能如何,就需要同步对测试机进行评估,从而作为评估模型训练好坏的标准之一。
在TensorFlow中,提供了evaluate()函数方便开发者使用,其定义如下:
evaluate(
x=None, y=None, batch_size=None, verbose=1, sample_weight=None, steps=None,
callbacks=None, max_queue_size=10, workers=1, use_multiprocessing=False,
return_dict=False,**kwargs
)
函数重要参数解释如下:
参数解释x测试输入样本y测试输入标签batch_size一次测试输入的样本数……
下面给出一个简单的例子:
results = model.evaluate(x_test, y_test, batch_size=128)
四、小试牛刀
根据以上学习内容,针对MNIST数据集,实现手写数字识别。下面分别进行:数据集加载、模型搭建、模型装配、模型训练、评估测试集。完整代码如下:
"""
note: compile/fit/evaluate
author: AI JUN
date: 2022/1/5
"""from tensorflow import keras
from tensorflow.keras import layers
# 数据集准备(x_train, y_train),(x_test, y_test)= keras.datasets.mnist.load_data()
x_train = x_train.reshape(60000,784).astype("float32")/255.
x_test = x_test.reshape(10000,784).astype("float32")/255.
y_train = y_train.astype("float32")
y_test = y_test.astype("float32")# 训练集
x_train = x_train[:-10000]
y_train = y_train[:-10000]# 验证集
x_val = x_train[-10000:]
y_val = y_train[-10000:]# 网络搭建
model = keras.Sequential([
layers.Dense(64, activation="relu", name="layer1"),
layers.Dense(64, activation="relu", name="layer2"),
layers.Dense(10, activation="softmax", name="predictions"),])
model.build(input_shape=[None,28*28])# 模型的装配
model.compile(
optimizer=keras.optimizers.RMSprop(),# Optimizer
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=[keras.metrics.SparseCategoricalAccuracy()],)# 模型的训练
history = model.fit(
x_train,
y_train,
batch_size=64,
epochs=10,
validation_data=(x_val, y_val),# at the end of each epoch)# 评估测试集print("Evaluate on test data")
results = model.evaluate(x_test, y_test, batch_size=128)print("test loss, test acc:", results)
代码运行结果:

本教程所有代码会逐渐上传github仓库:https://github.com/Keyird/TensorFlow2-for-beginner
如果对你有帮助的话,欢迎star收藏~
最好的关系是互相成就,各位的「三连」就是【AI 菌】创作的最大动力,我们下期见!
版权归原作者 AI 菌 所有, 如有侵权,请联系我们删除。