
环境准备
1.VMware虚拟机(Linux操作系统)
2.Windows7~11
3.JDK
4.Hadoop
Hadoop安装及集群环境配置-CSDN博客https://blog.csdn.net/2301_81921110/article/details/139362063?spm=1001.2014.3001.55015.Xshell 7(用于连接虚拟机与Windows)
6.Xftp 7(用于虚拟机与Windows之间传输文件)
Xshell 7与Xftp 7使用教程-CSDN博客https://blog.csdn.net/2301_81921110/article/details/139377831?spm=1001.2014.3001.5501
*一、启动虚拟机并在Windows中使用Xshell 7连接虚拟机*

二、****安装Spark
spark下载地址:
Index of /dist/spark/spark-2.1.0 (apache.org)https://archive.apache.org/dist/spark/spark-2.1.0/1、sudo tar -zxvf ~/下载/spark-2.1.0-bin-h27hive.tgz -C /usr/local/
(注:spark-2.1.0-bin-h27hive.tgz需修改为个人所下载的spark压缩包名称)
2、cd /usr/local
3、sudo mv ./spark-2.1.0-bin-h27hive/ ./spark
4、sudo chown -R hadoop:hadoop ./spark # 此处的hadoop为你的用户名
5、vim ~/.bashrc # 配置环境变量
在其中添加以下配置信息****:
export SPARK_HOME=/usr/local/spark

6、source ~/.bashrc
7、cd /usr/local/spark
8、cp ./conf/spark-env.sh.template ./conf/spark-env.sh
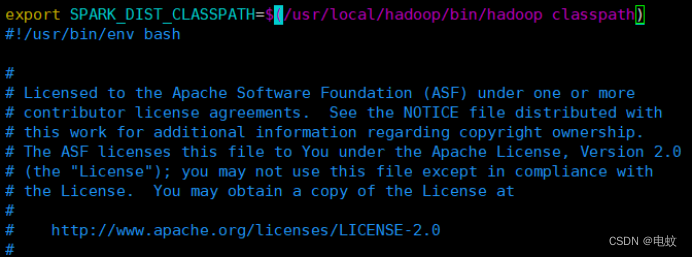
9、vim ./conf/spark-env.sh # 编辑spark-env.sh文件
在第一行添加以下配置信息****:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
配置完成后就可以直接使用,不需要像Hadoop运行启动命令。
10、bin/spark-shell # 启动spark shell
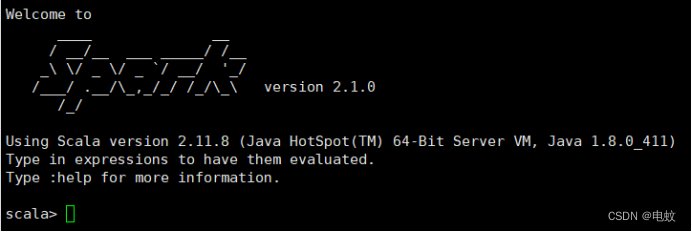
11、:quit # 退出spark shell
二、安装sbt
使用Scala语言编写Spark程序,需要使用sbt进行编译打包。Spark没有自带sbt,需要单独安装。
sbt下载地址: http://www.scala-sbt.orghttp://www.scala-sbt.org/
1、sudo mkdir /usr/local/sbt # 创建安装目录
2、cd ~/下载
3、sudo tar -zxvf ./sbt-1.3.8.tgz -C /usr/local
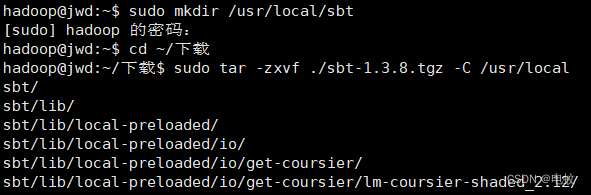
4、cd /usr/local/sbt
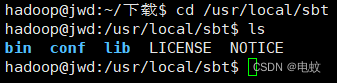
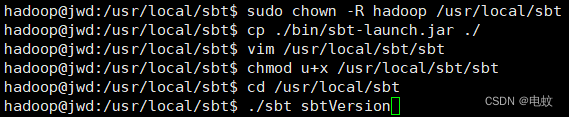
5、sudo chown -R hadoop /usr/local/sbt # 此处的hadoop为系统当前用户名
6、cp ./bin/sbt-launch.jar ./ #把bin目录下的sbt-launch.jar复制到sbt安装目录下
在安装目录中使用下面命令创建一个Shell脚本文件,用于启动sbt:
7、vim /usr/local/sbt/sbt
脚本文件中的代码如下:
#!/bin/bash
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jar `dirname $0`/sbt-launch.jar "$@"
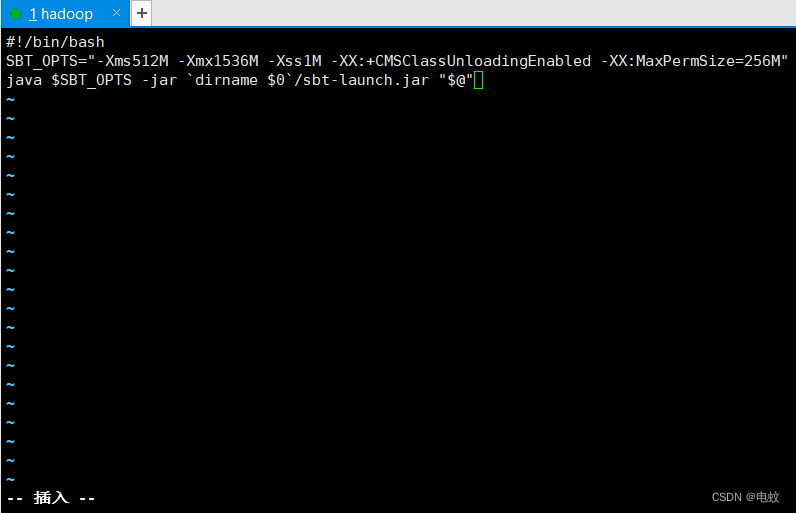
为该Shell脚本文件增加可执行权限:
8、chmod u+x /usr/local/sbt/sbt
查看sbt版本信息:
9、cd /usr/local/sbt
10、./sbt sbtVersion
./sbt sbtVersion过程第1次执行比较漫长。但第2次速度会快很多。

三、****Scala应用程序代码
在终端中执行如下命令创建一个文件夹sparkapp作为应用程序根目录:
1、cd ~ # 进入用户主文件夹
2、mkdir ./sparkapp # 创建应用程序根目录
3、mkdir -p ./sparkapp/src/main/scala # 创建所需的文件夹

在./sparkapp/src/main/scala下建立一个名为SimpleApp.scala的文件
4、vim ./sparkapp/src/main/scala/SimpleApp.scala
添加代码如下:
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "file:///usr/local/spark/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
该程序计算/usr/local/spark/README文件中包含"a"的行数和包含"b"的行数。
代码第8行的/usr/local/spark为Spark的安装目录,如果不是该目录请自行修改。
该程序依赖Spark API,需要通过sbt进行编译打包。
在~/sparkapp这个目录中新建文件simple.sbt,命令如下:
5、cd ~/sparkapp
6、vim simple.sbt
在simple.sbt中添加如下内容,声明该独立应用程序的信息以及与Spark的依赖关系:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"
(注:scalaVersion和spark-core版本号,根据自己的软件配置。)
四、使用 sbt 打包 Scala 程序
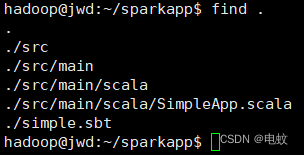
先执行如下命令检查整个应用程序的文件结构:
1、cd ~/sparkapp
2、find .
通过如下代码将整个应用程序打包成 JAR:
3、/usr/local/sbt/sbt package
打包成功会输出如下内容:

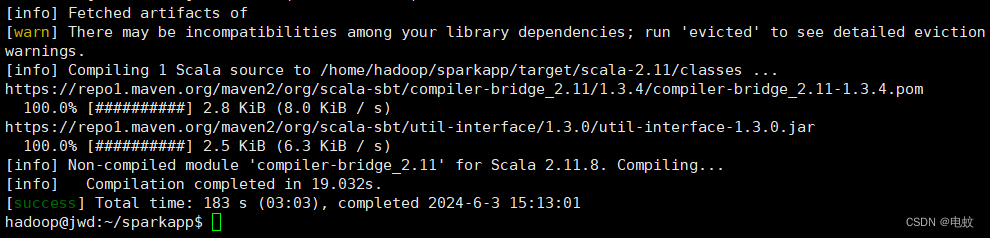
生成的jar包的位置为 ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar。
通过spark-submit运行程序,命令如下:
/usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar
上面命令执行后会输出信息比较多,可以使用下面命令查看想要结果;
/usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar 2>&1 | grep "Lines with a:"
最终结果如下:
Lines with a: 62, Lines with b: 30

版权归原作者 电蚊 所有, 如有侵权,请联系我们删除。