
Flink总结
一、初步了解什么是Flink?
Flink是一个实时的流式计算引擎,与sparkStreaming不同的是底层是流式引擎,并且有用事件窗口和时间窗口两种窗口,可以进行离线和实时计算,有着完美的容错机制,以及数据延迟机制,在支持高吞吐的同时保证低延迟,并提出了时间语义的概念,将数据分为有界流和无界流,且拥有FlinkSQL方便操作与学习成本。
1、Flink的编程模型
Flink API分层
- 1、Stateful Stream Processing:是Flink最底层的接口,提供了对时间和状态的细粒度控制,虽然灵活度高,但学习成本高,要求编码能力高
- 2、DataStream DataSet API:提供了一些封装好的算子,方便使用计算处理分为两种,流式-DataStream API 和 DataSet API 批处理
- 3、SQL& Table API : 通过构建Table环境,将数据注册成表,直接通过SQL进行编写即可
- 4、扩展库:复杂事件处理CEP,Gelly做图计算的,是一个可扩展的图形处理和分析库。
Flink 组成:数据源+数据转换+数据输出Data Source + Transformations + Data Sink
Flink程序整体的流程可以由多个数据源或者多个输出Slink,中间会经过多个算子进行数据的过滤,形成一个有向无环图DAG
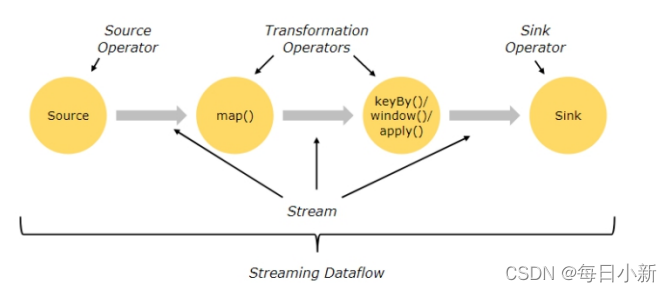
2、Flink的算子Operator
Spark的算子分为:控制算子,行动算子,转换算子。Flink算子划分如下;
- ① 基本转换算子:map()/filter()/flatmap()
- ② 键控流转换算子:keyby()/滚动聚合算子(sum/min/max/minBy)/reduce(x+x)
- ③ 多流转换算子:union():对多条数据合并输出要求数据类型相同不去重。connect():对两条不同的数据流进行合并
- ④ 分布式算子:Random():将上游数据随机分发给下游。Rescale():将上游数据平分到下游。Rebalance():将上游数据依次分发到下游。Global:将上游数据每一份分发到下游第一个分区。Broadcast():将上游数据所有数据复制发送到下游算子的任务中。
3、富函数
富函数:每个函数处理数据之前都需要进行初始化工作,以及数据处理的事后清理,每个DataStream API提供的所有转换算子都由其富函数版本:
常用函数:RichMapFunction、RichFlatMapFunction、RichFilterFunction
富函数主要提供了额外方法:
- open():即初始化方法,通常用来只需要一次的初始化工作
- close():做最后的清理工作
- getRuntimeContext():提供了函数的一些信息,并行度,子任务等以及分区状态的方法
二、Flink集群架构
1、角色分配以及流程
流程:
由App发送任务给分发器Dispatcher,再由分发器对任务进行分发,提交给JobManager,JobManager负责本次任务,JM向ResourceManager资源管理者申请资源,RM会将每个集群的资源情况获取到,并分配给JM资源,再由JM将任务分发给子节点上的TaskManager进行执行,TM开始完成任务。
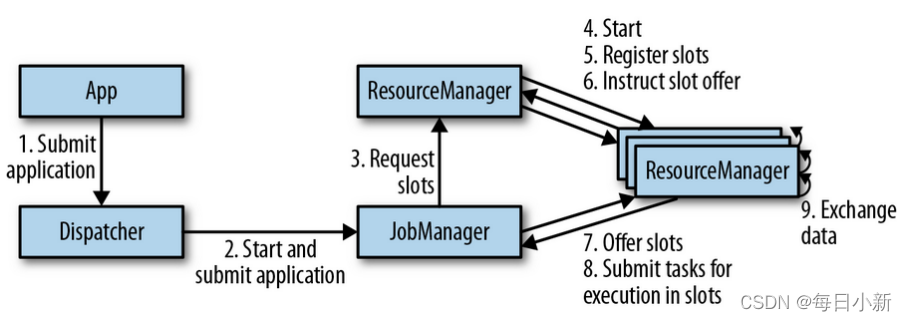
2、TaskSlot与Parallelism
TaskSlot:任务槽,即用于完成任务所用的资源,会根据任务的并行度进行申请资源
Parallelism:并行度,分为算子并行度,环境并行度,客户端并行度,系统并行度
Flink的执行图分层:
- StreamGraph:根据用户的Stream API编写的代码生成拓扑结构图
- Job Graph:将多个符合条件的节点chain在一起作为一个节点减少节点之间的IO传输消耗,以及序列化和反序列化、(形成一个操作链)
- ExecutionGraph:即调度层,最核心的地方由Job Graph的基础上生成
- 物理执行图:通过具体的组件算子进行计算。
3、Flink的并行度
- 算子级别:setParallelism()方法定义并行度
- 执行环境级别:创建环境后.setParallelism()方法
- 客户端级别:即使用客户端提交任务时指定-p参数来设置并行度
- 系统级别:通过修改flink的parallelism.default文件来设置并行度
4、窗口机制
首先窗口概念:通过对数据基于时间或者时间的划分,进行计算,便是窗口。
窗口分类:
- 滑动窗口:滑动窗口在规定时间内进行滑动,会出现重复数据计算
- 滚动窗口:滚动窗口通过规定时间划分窗口,不会出现重复数据计算
- 会话窗口:会话窗口不会重叠,没有固定的开始和结束,当窗口一段时间没有接收到数据,则会关闭窗口
- 全局窗口:将所有相同key的数据分配到单个窗口中计算结果
窗口功能分类:
- 时间窗口:即设置窗口一次处理多长时间数据,后者窗口滑动、滚动的时间,
- 事件窗口:即基于事件,一个窗口处理几条事件作为窗口的划分
窗口函数分类:
- 增量函数:增量指在之前的上个窗口结果的基础上进行当前数据的计算
- 全量函数:全量指不仅将当前的数据进行计算还有加上历史数据整体进行计算
详解水位线原理—>点击跳转
- 水位线注意点:单个线程(单数据源)的时候每次获取当前事务中最大的事务时间减去延迟时间来获取水位线,而并发情况下的水位线会获取到最小的水位线向下游广播同步,也是对齐机制。
5、水位线之后迟到的数据怎么办?
现实中很难有一个很完美的水位线将所有的延迟数据都进行挽回,水位线不仅要考虑效率,还要考虑将数据丢失概率降低,从整体的性价比来考量,故此Flink提供了一些机制进行弥补:
- 直接将延迟数据丢弃
- 将迟到的数据输出到单独的数据流中,即使用sideOutputLateData(new OutputTag<>())实现测输出
- 根据迟到的事件更新并发处结果
三、Flink的状态
数据流被分为有状态和无状态,Flink中的算子与状态关联,所有Flink的计算是有状态的,算子会在计算时将自己的状态注册到TaskManager中。
状态分类:算子状态、键控状态
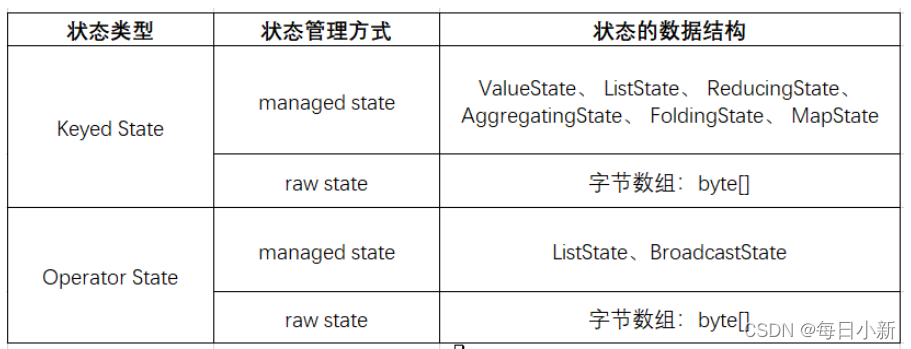
1、Flink容错机制
容错机制详解—>跳转
2、State Backends & SavePoint
Flink在保存状态时,支持三种存储方式,如下:
- MemoryStateBackend (基于内存存储)
- FsStateBackend (基于文件系统存储)
- RocksDBStateBackend (基于RocksDB数据库存储)
Savepoint:保存点与CheckPoint类似,一个时系统提供的,一个是用户自己定义,一般由用户进行手动的备份和恢复。
3、Flink流处理的三种语义
at most once : 至多一次,表示一条消息不管后续处理成功与否只会被消费处理一次,那么就存在数据丢失可能。
exactly once : 精确一次,表示一条消息从其消费到后续的处理成功,只会发生一次。
at least once :至少一次,表示一条消息从消费到后续的处理成功,可能会发生多次。
4、Flink之CEP概念
CEP 由一个或者多个规则组成,主要目的就是从有序简单的数据中获取到高阶特征,简单说就是通过数据的表面看数据本质,CEP可以理解为一个数据模型,数据经过CEP模型来获取一定的指标或者数据。(Pattern API )
CEP模式分类:
- 单个模式:单个模式就是只接受一个事件
- 循环模式:可以接受多个事件
- 组合模式:① 严格连续 ② 松散连续 ③ 不确定的松散连续
- 匹配后跳过策略:对于一个给定的模式,防止同一个事件可能会分配到多个成功的匹配上。
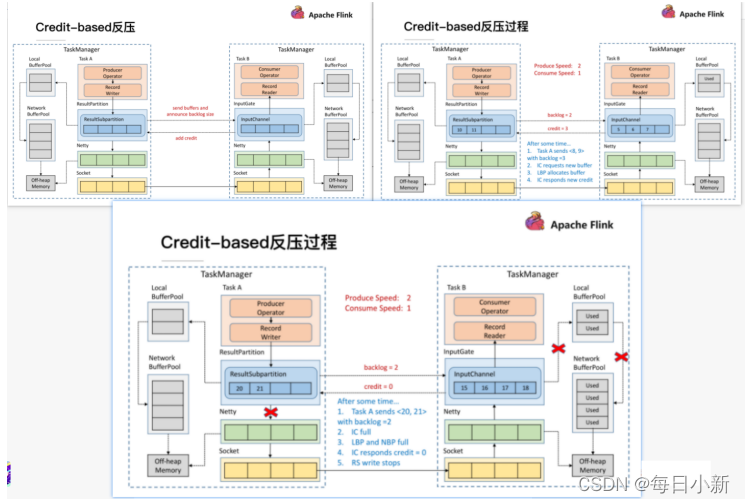
5、Flink 数据反压
Flink1.5版本之前的反压机制
首先由TaskA 发送数据至TaskB,在TaskA的速率远远大于TaskB时,一定会出现反压情况,首先是TaskB的InputChannel会被填满,此时会向LocalBuffer申请空间,当LocalBuffer也填满后,再向NetworkBuffer申请空间,最后NetworkBuffer没空间后,堆积到Socket,Socket堆满会给发送端发送一个状态,此时发送端停止给Socket发送,TaskA这边的Netty发现Socket满了之后会使用Buffer,最后全部全部缓存用尽,TaskA也停止发数据,实现反压。缺点:
- 过于依赖TCP传输,并且反压延迟过高
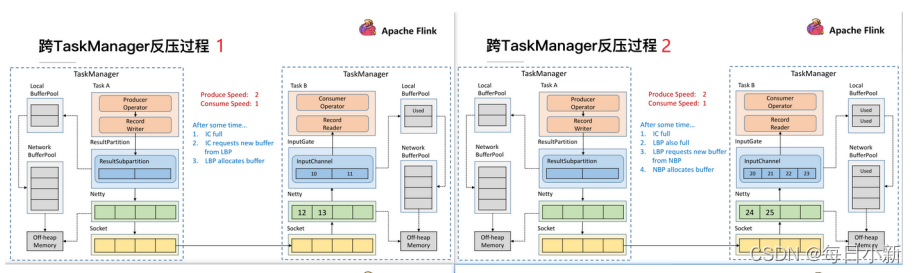
1.5版本之后
如图TaskA正常向TaskB发送数据,单每次ResultSubPartition向InputChannel发送消息的时候都会发送一个Backlog size告诉下游准备发送多少数据,下游会告诉上游是否还有足够空间Buffer,当没有足够的空间时则不进行发送。主要降低了反压生效的延迟性,同时Socket不会阻塞。
版权归原作者 每日小新 所有, 如有侵权,请联系我们删除。