
一:初识Flink
Flink 是 Apache 基金会旗下的一个开源大数据处理框架。
1 .1 Flink 的源起和设计理念
⚫ 2014 年 8 月, Flink 第一个版本 0.6 正式发布(至于 0.5 之前的版本,那就是在
Stratosphere 名下的了)。与此同时 Fink 的几位核心开发者创办了 Data Artisans 公司, 主要做 Fink 的商业应用,帮助企业部署大规模数据处理解决方案。
⚫ 2014 年 12 月, Flink 项目完成了孵化,一跃成为 Apache 软件基金会的顶级项目。
⚫ 2015 年 4 月, Flink 发布了里程碑式的重要版本 0.9.0,很多国内外大公司也正是从这 时开始关注、并参与到 Flink 社区建设的。
⚫ 2019 年 1 月,长期对 Flink 投入研发的阿里巴巴,以 9000 万欧元的价格收购了 Data Artisans 公司;之后又将自己的内部版本 Blink 开源,继而与 8 月份发布的 Flink 1.9.0
版本进行了合并。自此之后, Flink 被越来越多的人所熟知,成为当前最火的新一代 大数据处理框架。
具体定位是: Apache Flink 是一个框架和分布式处理引擎,如图 1-2 所示,用于对无界和 有界数据流进行有状态计算。 Flink 被设计在所有常见的集群环境中运行,以内存执行速度和 任意规模来执行计算。
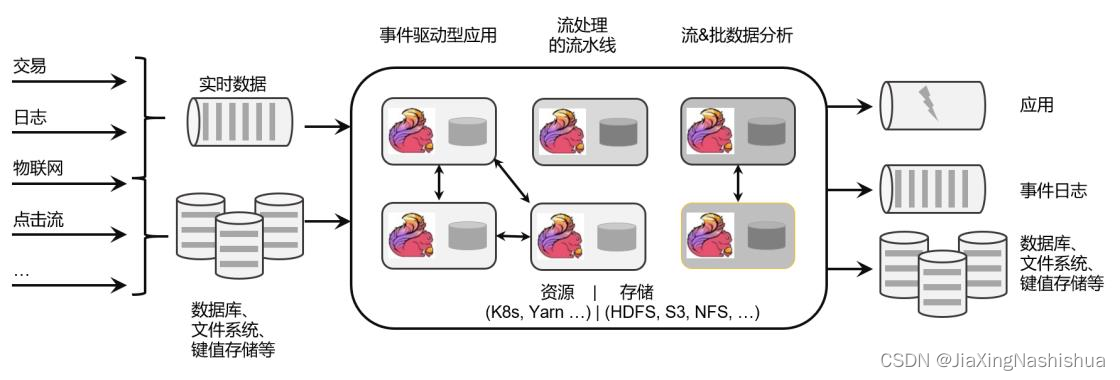
1 .2 Flink 的应用
1 .2.1 Flink 主要的应用场景
它是一个大数据流式处理引擎,处理的是流式数据,也就是“数 据流”(Data Flow)。顾名思义,数据流的含义是,数据并不是收集好的,而是像水流一样, 是一组有序的数据序列,逐个到来、逐个处理。由于数据来到之后就会被即刻处理,所以流处 理的一大特点就是“快速”,也就是良好的实时性。 Flink 适合的场景,其实也就是需要实时处 理数据流的场景。
1 .3 流式数据处理的发展和演变
1.3.1 流处理和批处理
对于具体应用来说,有些场景数据是一个一个来的,是一组有序的数据序列,我们把它叫 作“数据流”;
而有些场景的数据,本身就是一批同时到来,是一个有限的数据集,这就是批量数据(有时也直接叫数据集)。
容易想到,处理数据流,当然应该“来一个就处理一个”,这种数据处理模式就叫作流处理因为这种处理是即时的,所以也叫实时处理。
与之对应,处理批量数据自然就应该一批读 入、一起计算,这种方式就叫作批处理,也叫作离线处理。
1.3.2 传统事务处理
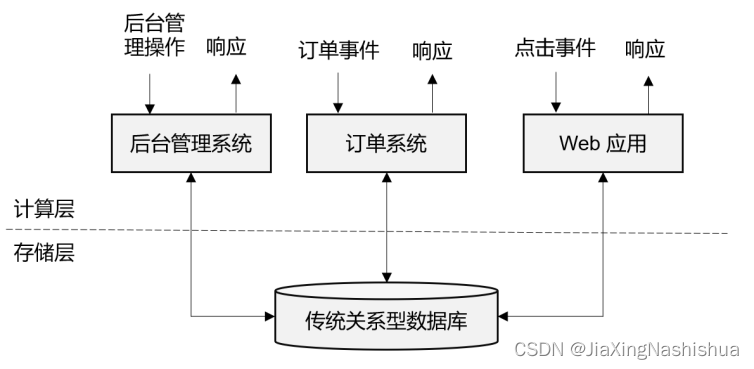
对于各种事件请求,事务处理的方式能够保证实时响应,好处是一目了然的。但是我们知 道,这样的架构对表和数据库的设计要求很高;当数据规模越来越庞大、系统越来越复杂时, 可能需要对表进行重构,而且一次联表查询也会花费大量的时间,甚至不能及时得到返回结果。 于是,作为程序员就只好将更多的精力放在表的设计和重构,以及 SQL 的调优上,而无法专 注于业务逻辑的实现了——我们都知道,这种工作费力费时,却没法直接体现在产品上给老板 看,简直就是噩梦。
那有没有更合理、更高效的处理架构呢?
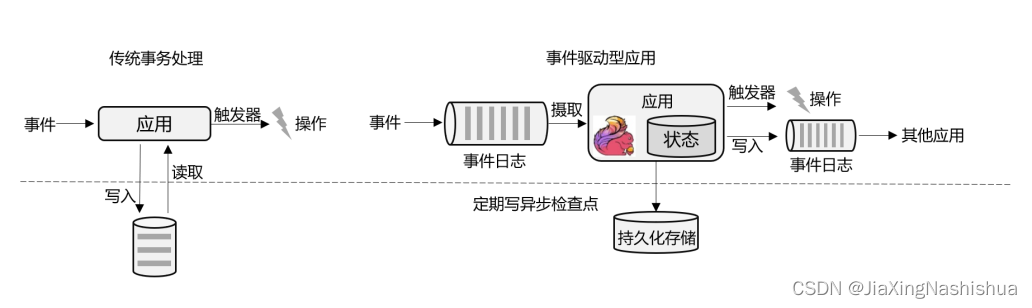
1.3.3 有状态的流处理
为了加快访问速度,我们可以直接将状态保存在本地内存,如图所示。当应用收到一 个新事件时,它可以从状态中读取数据,也可以更新状态。而当状态是从内存中读写的时候, 这就和访问本地变量没什么区别了,实时性可以得到极大的提升。
另外,数据规模增大时,我们也不需要做重构,只需要构建分布式集群,各自在本地计算就可以了,可扩展性也变得更好。
因为采用的是一个分布式系统,所以还需要保护本地状态,防止在故障时数据丢失。我们 可以定期地将应用状态的一致性检查点(checkpoint)存盘,写入远程的持久化存储,遇到故 障时再去读取进行恢复,这样就保证了更好的容错性。

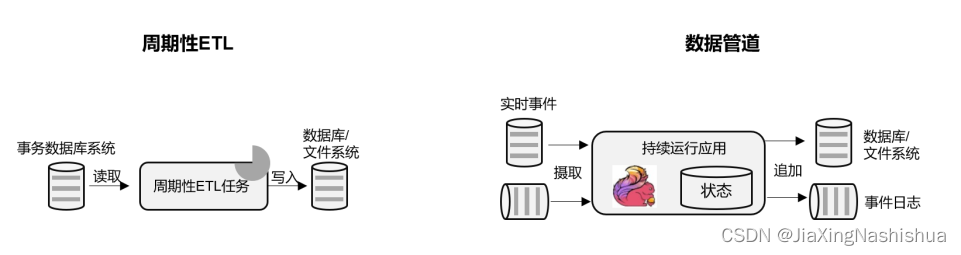
1 . 事件驱动型(Event-Driven)应用
- 数据分析(Data Analysis)型应用

- 数据管道(Data Pipeline)型应用
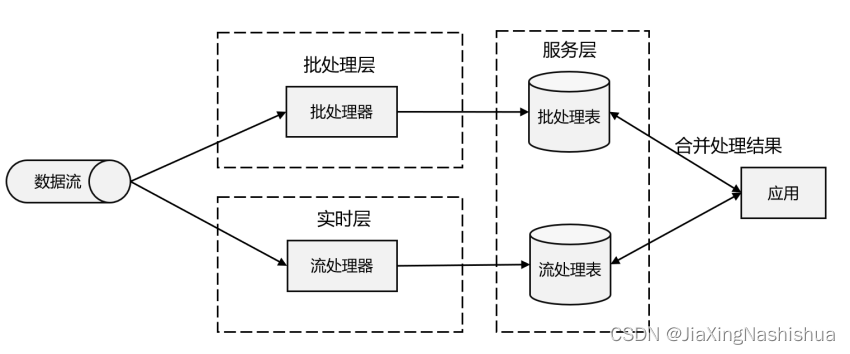
1 .3.4 Lambda 架构
1.3.5 新一代流处理器 (Flink)
之前的分布式流处理架构,都有明显的缺陷,人们也一直没有放弃对流处理器的改进和完 善。终于,在原有流处理器的基础上,新一代分布式开源流处理器诞生了。为了与之前的系统 区分,我们一般称之为第三代流处理器,代表当然就是 Flink。
第三代流处理器通过巧妙的设计,完美解决了乱序数据对结果正确性的影响。这一代系统 还做到了精确一次( exactly-once)的一致性保障,是第一个具有一致性和准确结果的开源流 处理器。另外,先前的流处理器仅能在高吞吐和低延迟中二选一,而新一代系统能够同时提供 这两个特性。所以可以说,这一代流处理器仅凭一套系统就完成了 Lambda 架构两套系统的工 作,它的出现使得 Lambda 架构黯然失色。
除了低延迟、容错和结果准确性之外,新一代流处理器还在不断添加新的功能,例如高可 用的设置,以及与资源管理器(如 YARN 或 Kubernetes)的紧密集成等等。
1.4 Flink 的特性总结
Flink 是第三代分布式流处理器,它的功能丰富而强大。
1.4.1 Flink 的核心特性
Flink 区别与传统数据处理框架的特性如下。
⚫ 高吞吐和低延迟。每秒处理数百万个事件,毫秒级延迟。
⚫ 结果的准确性。 Flink 提供了事件时间(event-time)和处理时间(processing-time) 语义。对于乱序事件流,事件时间语义仍然能提供一致且准确的结果。
⚫ 精确一次(exactly-once)的状态一致性保证。
⚫ 可以连接到最常用的存储系统,如 Apache Kafka、 Apache Cassandra、 Elasticsearch、
JDBC、 Kinesis 和(分布式)文件系统,如 HDFS 和 S3。
⚫ 高可用。本身高可用的设置,加上与 K8s, YARN 和 Mesos 的紧密集成,再加上从故 障中快速恢复和动态扩展任务的能力, Flink 能做到以极少的停机时间 7× 24 全天候 运行。
⚫ 能够更新应用程序代码并将作业(jobs)迁移到不同的 Flink 集群,而不会丢失应用 程序的状态。
1.4.2 分层 API
除了上述这些特性之外, Flink 还是一个非常易于开发的框架,因为它拥有易于使用的分层API
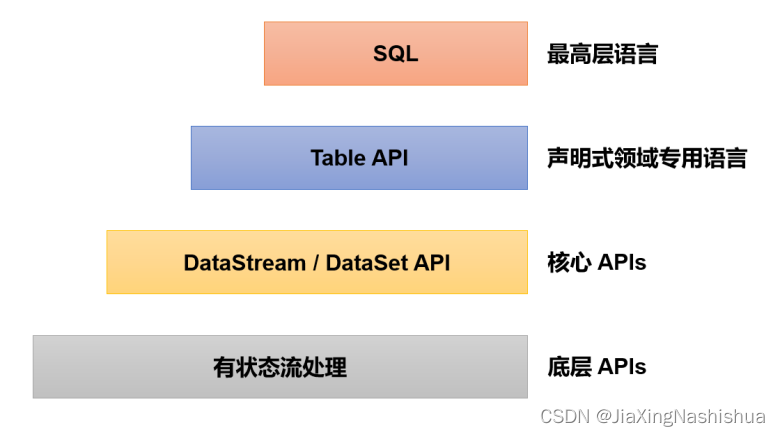
最底层级的抽象仅仅提供了有状态流,它将处理函数( Process Function)嵌入到了
DataStream API 中。底层处理函数(Process Function)与 DataStream API 相集成,可以对某 些操作进行抽象,它允许用户可以使用自定义状态处理来自一个或多个数据流的事件,且状态 具有一致性和容错保证。除此之外,用户可以注册事件时间并处理时间回调,从而使程序可以 处理复杂的计算。
实际上,大多数应用并不需要上述的底层抽象,而是直接针对核心 API(Core APIs) 进 行编程,比如 DataStream API(用于处理有界或无界流数据)以及 DataSet API(用于处理有界 数据集)。这些 API 为数据处理提供了通用的构建模块,比如由用户定义的多种形式的转换 (transformations)、连接(joins)、聚合(aggregations)、窗口(windows)操作等。 DataSet API
14
为有界数据集提供了额外的支持,例如循环与迭代。这些 API 处理的数据类型以类(classes) 的形式由各自的编程语言所表示。 Table API 是以表为中心的声明式编程,其中表在表达流数据时会动态变化。 Table API 遵 循关系模型:表有二维数据结构(schema)(类似于关系数据库中的表),同时 API 提供可比 较的操作,例如 select、 join、 group-by、 aggregate 等。
尽管 Table API 可以通过多种类型的用户自定义函数(UDF)进行扩展,仍不如核心 API
更具表达能力,但是使用起来代码量更少,更加简洁。除此之外, Table API 程序在执行之前 会使用内置优化器进行优化。
我们可以在表与 DataStream/DataSet 之间无缝切换,以允许程序将 Table API 与 DataStream 以及 DataSet 混合使用。 Flink 提供的最高层级的抽象是 SQL。这一层抽象在语法与表达能力上与 Table API 类似, 但是是以 SQL 查询表达式的形式表现程序。 SQL 抽象与 Table API 交互密切,同时 SQL 查询 可以直接在 Table API 定义的表上执行。
目前 Flink SQL 和 Table API 还在开发完善的过程中,很多大厂都会二次开发符合自己需 要的工具包。而 DataSet 作为批处理 API 实际应用较少, 2020 年 12 月 8 日发布的新版本 1.12.0,
已经完全实现了真正的流批一体, DataSet API 已处于软性弃用(soft deprecated)的状态。用
Data Stream API 写好的一套代码, 即可以处理流数据, 也可以处理批数据,只需要设置不同的 执行模式。这与之前版本处理有界流的方式是不一样的, Flink 已专门对批处理数据做了优化 处理。本书中以介绍 DataStream API 为主,采用的是目前最新版本 Flink 1.13.0。
1 .5.1 数据处理架构
我们已经知道,数据处理的基本方式,可以分为批处理和流处理两种。
批处理针对的是有界数据集,非常适合需要访问海量的全部数据才能完成的计算工作,一 般用于离线统计。
流处理主要针对的是数据流,特点是无界、实时, 对系统传输的每个数据依次执行操作, 一般用于实时统计。
从根本上说, Spark 和 Flink 采用了完全不同的数据处理方式。可以说,两者的世界观是 截然相反的。 Spark 以批处理为根本,并尝试在批处理之上支持流计算;在 Spark 的世界观中,万物皆 批次,离线数据是一个大批次,而实时数据则是由一个一个无限的小批次组成的。所以对于流 处理框架 Spark Streaming 而言,其实并不是真正意义上的“流”处理,而是“微批次” (micro-batching)处理

而 Flink 则认为,流处理才是最基本的操作,批处理也可以统一为流处理。在 Flink 的世 界观中,万物皆流,实时数据是标准的、没有界限的流,而离线数据则是有界限的流。
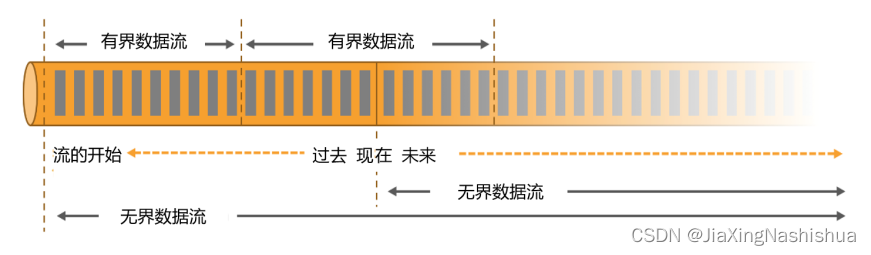
1 . 无界数据流(Unbounded Data Stream)
所谓无界数据流,就是有头没尾,数据的生成和传递会开始但永远不会结束,如图 1-13
所示。我们无法等待所有数据都到达,因为输入是无界的,永无止境,数据没有“都到达”的 时候。所以对于无界数据流,必须连续处理,也就是说必须在获取数据后立即处理。在处理无 界流时,为了保证结果的正确性,我们必须能够做到按照顺序处理数据。
2. 有界数据流(Bounded Data Stream)
对应的,有界数据流有明确定义的开始和结束,如图 1-13 所示,所以我们可以通过获取 所有数据来处理有界流。处理有界流就不需要严格保证数据的顺序了,因为总可以对有界数据 集进行排序。有界流的处理也就是批处理。
正因为这种架构上的不同, Spark 和 Flink 在不同的应用领域上表现会有差别。一般来说, Spark 基于微批处理的方式做同步总有一个“攒批”的过程,所以会有额外开销,因此无法在 流处理的低延迟上做到极致。在低延迟流处理场景, Flink 已经有明显的优势。而在海量数据 的批处理领域, Spark 能够处理的吞吐量更大,加上其完善的生态和成熟易用的 API,目前同 样优势比较明显。
1.5.2 数据模型和运行架构
除了三观不合, Spark 和 Flink 在底层实现最主要的差别就在于数据模型不同。 Spark 底层数据模型是弹性分布式数据集(RDD), Spark Streaming 进行微批处理的底层 接口 DStream,实际上处理的也是一组组小批数据 RDD 的集合。可以看出, Spark 在设计上本 身就是以批量的数据集作为基准的,更加适合批处理的场景。
而 Flink 的基本数据模型是数据流(DataFlow),以及事件(Event)序列。 Flink 基本上是 完全按照 Google 的 DataFlow 模型实现的,所以从底层数据模型上看, Flink 是以处理流式数 据作为设计目标的,更加适合流处理的场景。
数据模型不同,对应在运行处理的流程上,自然也会有不同的架构。 Spark 做批计算,需 要将任务对应的 DAG 划分阶段( Stage),一个完成后经过 shuffle 再进行下一阶段的计算。而
Flink 是标准的流式执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理。
1.5.3 Spark 还是 Flink?
通过前文的分析,我们已经可以看出, Spark 和 Flink 可以说目前是各擅胜场,批处理领 域 Spark 称王,而在流处理方面 Flink 当仁不让。具体到项目应用中,不仅要看是流处理还是 批处理,还需要在延迟、吞吐量、可靠性,以及开发容易度等多个方面进行权衡。
如果在工作中需要从 Spark 和 Flink这两个主流框架中选择一个来进行实时流处理,我们 更加推荐使用 Flink,主要的原因有:
⚫ Flink 的延迟是毫秒级别,而Spark Streaming 的延迟是秒级延迟。
⚫ Flink 提供了严格的精确一次性语义保证。
⚫ Flink 的窗口 API 更加灵活、语义更丰富。
⚫ Flink 提供事件时间语义,可以正确处理延迟数据。
⚫ Flink 提供了更加灵活的对状态编程的 API。
基于以上特点,使用 Flink 可以解放程序员, 加快编程效率, 把本来需要程序员花大力气 手动完成的工作交给框架完成。
当然,在海量数据的批处理方面, Spark 还是具有明显的优势。而且 Spark 的生态更加成
熟,也会使其在应用中更为方便。相信随着 Flink 的快速发展和完善,这方面的差距会越来越 小。
另外, Spark 2.0 之后新增的 Structured Streaming 流处理引擎借鉴 DataFlow 进行了大量优 化,同样做到了低延迟、时间正确性以及精确一次性语义保证; Spark 2.3 以后引入的连续处 理(Continuous Processing)模式,更是可以在至少一次语义保证下做到 1 毫秒的延迟。而 Flink
自 1.9 版本合并 Blink 以来,在 SQL 的表达和批处理的能力上同样有了长足的进步。
版权归原作者 JiaXingNashishua 所有, 如有侵权,请联系我们删除。