
scrapy框架介绍

scrapy是由Python语言开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。
scrapy框架的传送门:
https://scrapy.org

scrapy框架运行原理


Scrapy Engine(引擎):负者Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据转递等。
Scheduler(调度器) :它负责接受引擊发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
**Downloader (下载器)**:负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎) ,由引擎交给Spider来处理。
Spider (爬虫) :它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
**Item Pipeline(管道) **:它负责处理Spider 中获取到的Item ,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares (下载中间件) : 你可以当作是一个可以自定义扩 展下载功能的组件。
Spider Middlewares (Spider中间件) : 你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests )
制作 Scrapy 爬虫 一共需要4步:

新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
明确目标 (编写items.py):明确你想要抓取的目标
制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
存储内容 (pipelines.py):设计管道存储爬取内容

今天我们就以B站小姐姐为例,带大家亲自体验一下scrapy的强大之处!

创建spider项目

首先我们来看看scrapy的常用命令:
scrapy startproject 项目名称 # 创建一个爬虫项目或工程
scrapy genspider 爬虫名 域名 # 在项目下创建一个爬虫spider类
scrapy runspider 爬虫文件 #运行一个爬虫spider类
scrapy list # 查看当前项目有多少个爬虫
scrapy crawl 爬虫名称 # 通过名称指定运行爬取信息
scrapy shell url/文件名 # 使用shell进入scrapy交互环境
第一步我们创建一个scrapy工程, 进入到你指定的目录下,使用命令:
scrapy startproject 项目名称 # 创建一个爬虫项目或工程
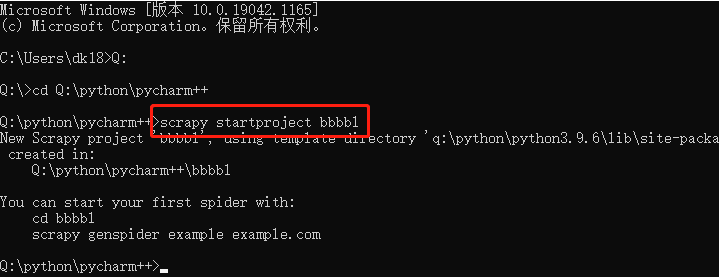
此时可以看到该目录下多了一个叫bbbbl的文件夹

当我们创建完项目之后,它会有提示,那么我们就按照它的提示继续操作。
You can start your first spider with: cd BliBli scrapy genspider example example.com
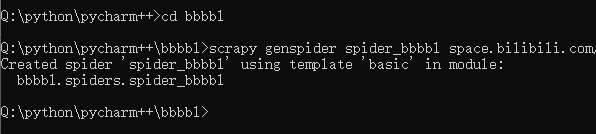
当你按照上面的操作,之后你就会发现,在spiders文件夹下就会出现
spider_bbbl.py
这个文件。这个就是我们的爬虫文件。
后面的 earch.bilibili.com就是我们要爬取的目标网站
BliBli
|—— BliBli
| |—— __init__.py
| |—— __pycache__.
| |—— items.py # Item定义,定义抓取的数据结构
| |—— middlewares.py # 定义Spider和Dowmloader和Middlewares中间件实现
| |—— pipelines.py # 它定义Item Pipeline的实现,即定义数据管道
| |—— settings.py # 它定义项目的全局配置
| |__ spiders # 其中包含一个个Spider的实现,每个Spider都有一个文件
|—— __init__.py
|—— spider_bl.py # 爬虫实现
|—— __pycache__
|—— scrapy.cfg # scrapy部署时的配置文件,定义了配置文件的路径、部署相关的信息内容。

目标确定

接下来我们打开B站搜索 '小姐姐'如下。我们今天的任务很简单,
视频标题、视频链接、视频播放时长、视频播放量、视频发布时间、视频作者还有封面图片和视频链接


网页分析

我们打开网页分析这是一个get请求
分页是由参数page来控制的。所有的数据都存在于一个json格式的数据集里面
我们的目标就是获取result列表中的数据

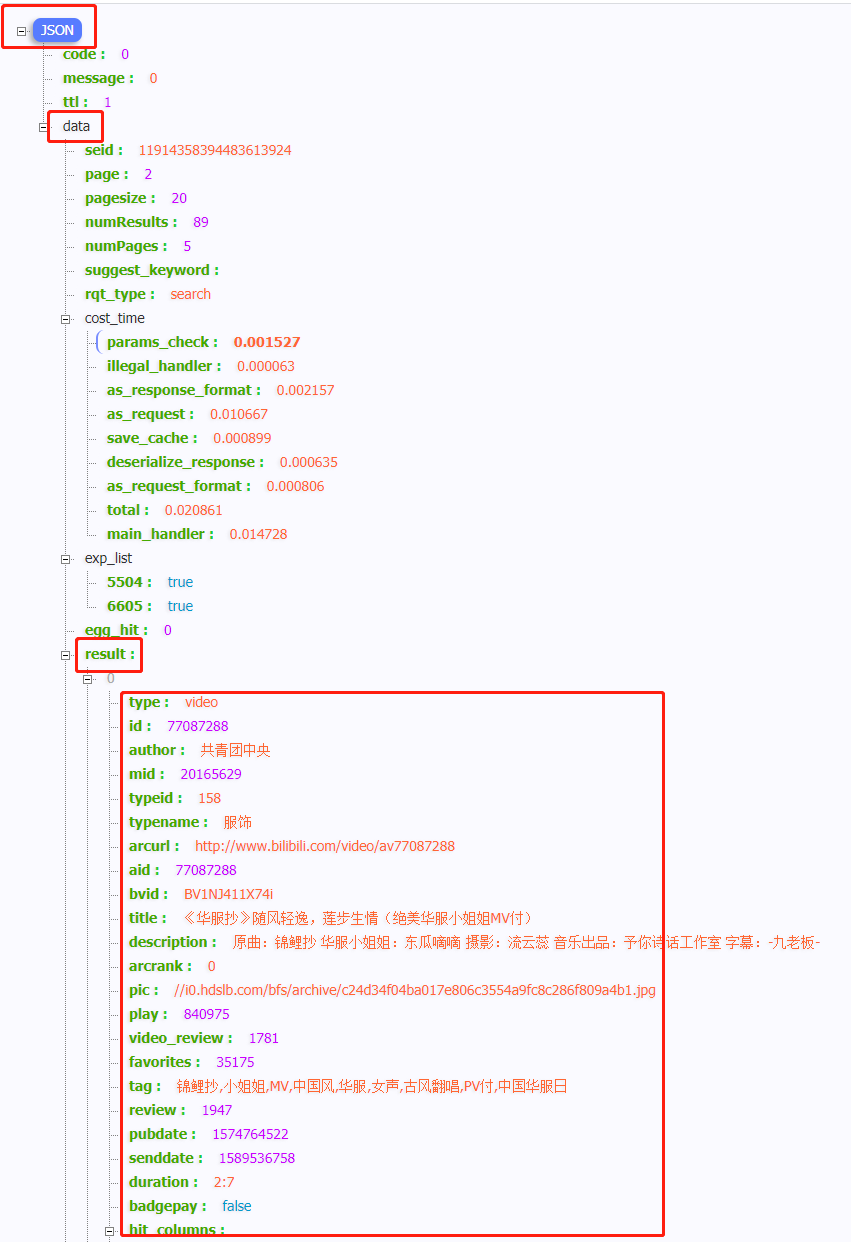

请求发送

设置item模板,定义我们要获取的信息
# 视频标题
title_video = scrapy.Field()
# 视频时长
time_video = scrapy.Field()
# 播放量
num_video = scrapy.Field()
# 发布时间
date_rls = scrapy.Field()
# 作者
author = scrapy.Field()
# 图片链接
link_pic = scrapy.Field()
# 视频地址
link_video = scrapy.Field()
然后我们在我们创建的spider_bl.py文件中写我们爬虫函数的具体实现
bl_list = response.json()['data']['result']
ic(bl_list)
结果如下:

接下来我们提取我们所需的数据:
for bl in bl_list:
# 视频标题
item['title_video'] = bl['title']
# 视频时长
item['time_video'] = bl['duration']
# 视频播放量
item['num_video'] =bl['video_review']
# 发布时间
date_rls = bl['pubdate']
item['date_rls'] = time.strftime('%Y-%m-%d %H:%M', time.localtime(date_rls))
# 视频作者
item['author'] = bl['author']
# 图片链接
link_pic = bl['pic']
item['link_pic'] = 'https:'+link_pic
# 视频链接
item['link_video'] = bl['arcurl']
'''
{'author': '共青团中央',
'date_rls': '2019-11-26 18:35',
'link_pic': 'https://i0.hdslb.com/bfs/archive/c24d34f04ba017e806c3554a9fc8c286f809a4b1.jpg',
'link_video': 'http://www.bilibili.com/video/av77087288',
'num_video': 1781,
'time_video': '2:7',
'title_video': '《华服抄》随风轻逸,莲步生情(绝美华服小姐姐MV付)'}
Excel数据成功保存!
{'author': '祖瑜兄',
'date_rls': '2019-06-22 18:06',
'link_pic': 'https://i0.hdslb.com/bfs/archive/784607de4c3397af15838123a2fde8c1d301fb42.jpg',
'link_video': 'http://www.bilibili.com/video/av56450490',
'num_video': 5307,
'time_video': '9:51',
'title_video': '5分钟戏腔教程!满满干货不废话!京剧系小姐姐教你如何快速入门~赶紧收藏~(内有清唱示范)'}
Excel数据成功保存!
{'author': '皮皮皮皮皮皮皮卡乒',
'date_rls': '2020-09-02 16:36',
'link_pic': 'https://i1.hdslb.com/bfs/archive/39600c112ea656788740838d53df36fc3fe29e1f.jpg',
'link_video': 'http://www.bilibili.com/video/av754474482',
'num_video': 1148,
'time_video': '3:41',
'title_video': '小姐姐:我等会你(温柔声)外卖小哥:我太感动了!'}
Excel数据成功保存!
{'author': '小疼聊音乐',
'date_rls': '2020-06-19 17:47',
'link_pic': 'https://i1.hdslb.com/bfs/archive/d5bc2336899759fc5bc3cd3742f76d2846609fbd.jpg',
'link_video': 'http://www.bilibili.com/video/av668575442',
'num_video': 814,
'time_video': '3:29',
'title_video': '小姐姐随口哼两句,没想到引发整栋楼的合唱!这届毕业生太惨了!'}
Excel数据成功保存!
{'author': '奇视界',
'date_rls': '2019-11-26 10:39',
'link_pic': 'https://i0.hdslb.com/bfs/archive/d0c1937e9dbccf2c639be865763e41df78f0bed5.jpg',
'link_video': 'http://www.bilibili.com/video/av77065062',
'num_video': 1583,
'time_video': '4:58',
'title_video': '两个钢铁直男交流追女孩子方法,让坐在边上的小姐姐笑喷了'}
'''
我们现在pipeline中打印一下,没问题我们再将其保存到本地.
当我们要把数据保存成文件的时候,不需要任何额外的代码,只要执行如下代码即可:
scrapy crawl spider爬虫名 -o xxx.json #保存为JSON文件
scrapy crawl spider爬虫名 -o xxx.jl或jsonlines #每个Item输出一行json
scrapy crawl spider爬虫名 -o xxx.csv #保存为csv文件
scrapy crawl spider爬虫名 -o xxx.xml #保存为xml文件
想要保存为什么格式的文件,只要修改后缀就可以了,在这里我就不一一例举了。
我们在此将其保存为json格式
class BbbblPipeline:
def process_item(self, item, spider):
# 保存文件到本地
with open('./B站小姐姐.json', 'a+', encoding='utf-8') as f:
lines = json.dumps(dict(item), ensure_ascii=False) + '\n'
f.write(lines)
return item
settings.py找到以下字段,取消字段的注释
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
"User-Agent" : str(UserAgent().random),
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'BliBli.pipelines.BbbblPipeline': 300,
}
使用如下命令运行程序:可以看到产生了一个json文件
scrapy crawl spider_bbbbl
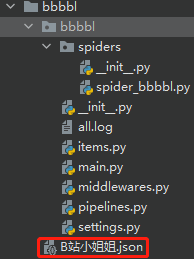
打开文件可以看到已经成功的获取到了我们想要的数据


保存数据Excel

我们使用openpyxl将数据保存到excel中便于后面的数据分析,我们先在pipeline.py中定义一个ExcelPipeline的函数,
# 名称
ws.append(['视频标题', '视频时长', '视频播放量', '发布时间', '视频作者', '图片链接', '视频链接'])
# 存储
line = [item['title_video'], item['time_video'], item['num_video'], item['date_rls'], item['author'], item['link_pic'],item['link_video']]
ws.append(line)
wb.save('../B站小姐姐.xlsx')
然后在settings中打开这个通道的开关,资源就会下载下来。
ITEM_PIPELINES = {
'bbbbl.pipelines.BbbblPipeline': 300,
'bbbbl.pipelines.ExcelPipeline': 301,
}
结果如下,我们会在scrapy目录下发现一个我们下载数据的excel
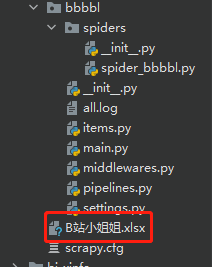
可以看到数据全部已经成功下载到excel中


保存数据Mysql

之前我有分享过最新Mysql8.0的下载安装以及常见问题的处理,尚未安装的小伙伴可以参考一下
Python操作mysql(上)!一文带你看懂!
Python操作mysql(下)!一文带你看懂!
跟保存excel的方式大同小异,区别在于Mysql除了要在setting中配置Pipeline外,还要配置Mysql端口、用户和密码等参数
# 配置Mysql
MYSQL_HOST = 'localhost'
MYSQL_DATABASE = 'BLBL'
MYSQL_USER = 'root'
MYSQL_PASSWORD = '211314'
MYSQL_PORT = 3306
此外我们还需再Pipeline.py中定义一个MysqlPipeline的类
然后在其中写Sql并且执行。
# Sql建表命令
sql = '''
CREATE TABLE bbbbl3
(id int primary key auto_increment
, title_video VARCHAR(200) NOT NULL
, time_video VARCHAR(100)
, num_video INTEGER
, date_rls VARCHAR(100)
, author VARCHAR(100)
, link_pic VARCHAR(1000)
, link_video VARCHAR(1000)
);
'''
# 执行建表Sql
cursor.execute(sql)
# 插入数据
value = (item["title_video"], item["time_video"], item["num_video"], item["date_rls"], item["author"], item["link_pic"], item["link_video"])
# 执行操作
sql = "insert into bbbbl3(title_video,time_video,num_video,date_rls,author,link_pic,link_video) value (%s,%s,%s,%s,%s,%s,%s)"
# 提交数据
self.db.commit()
# 关闭数据库
self.db.close()
我使用的Mysql可视化工具是Sqlyog,
执行完查询语句显示如下:


图片保存

封面小姐姐的链接已经获取到了,接下来我们要做的就是将这些小姐姐下载到我的马克思主义文件夹下
# 保存图片到本地
with open('images/{}.jpg'.format(item['title_video']), 'wb') as f:
req = requests.get(item['link_pic'])
f.write(req.content)
time.sleep(random.random() * 4)
为了防止被网址反爬,加了延时处理
结果如下:

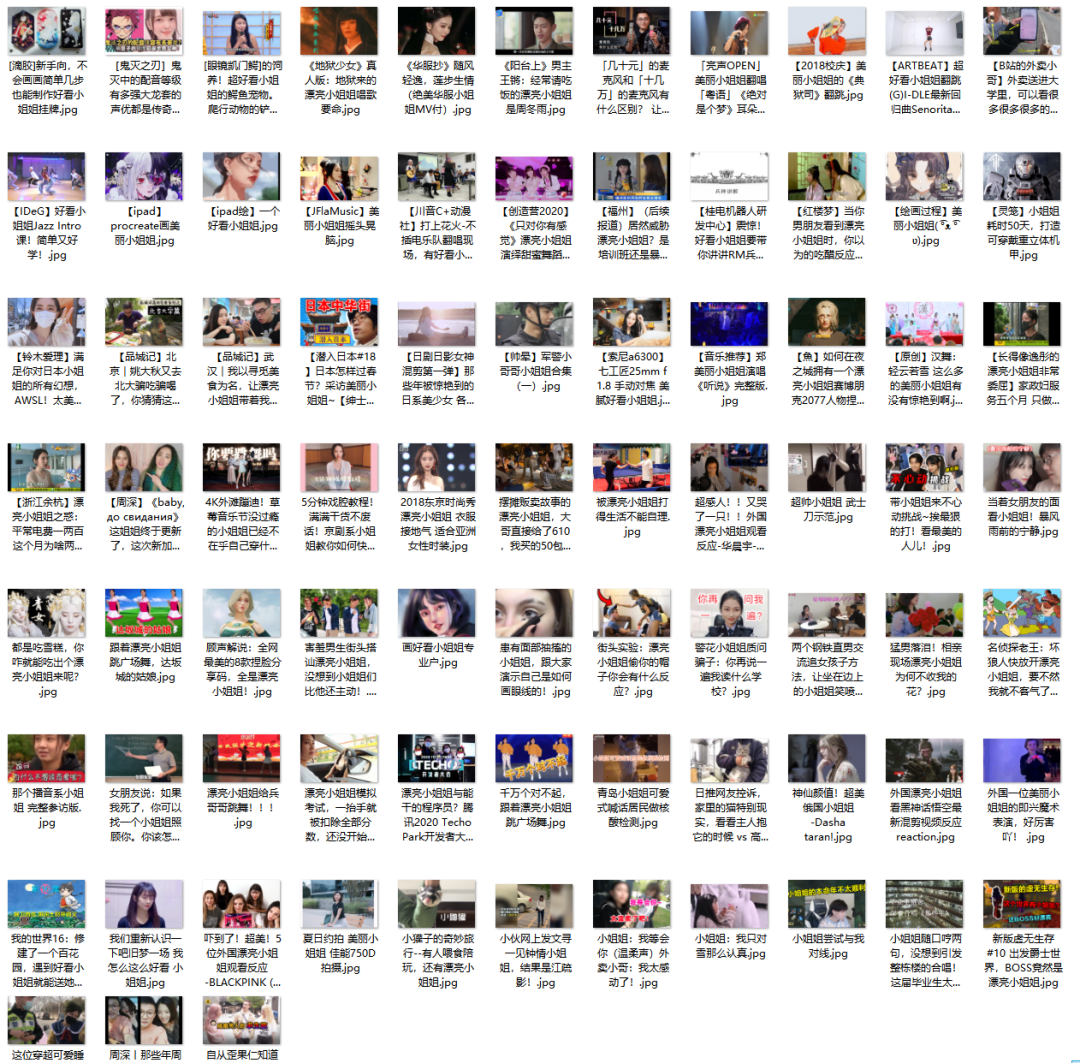
版权归原作者 Python是世界上最好的语言 所有, 如有侵权,请联系我们删除。