
必背面试题-手写题
前端面试(手写题)_Z_Xshan的博客-CSDN博客
css系列
面试官:说说你对盒子模型的理解
一、是什么
所有元素都可以有像盒子一样的平面空间和外形
一个盒子由四部分组成:context ,padding,margin,border
content:实际内容,显示文本和图像
padding:内边距,清除内容周边的区域,内边距是透明的,不能取负值,受盒子的background属性影响
margin:外边距,在元素外创建额外的空白,空白通常指不能放其他元素的区域
下面来段代码:
<style>
.box {
width: 200px;
height: 100px;
padding: 20px;
}
</style>
<div class="box">
盒子模型
</div>
当我们在浏览器查看元素时,却发现元素的大小变成了
240px
这是因为,在
CSS
中,盒子模型可以分成:
- W3C 标准盒子模型
- IE 怪异盒子模型
默认情况下,盒子模型为
W3C
标准盒子模型
二、标准盒子模型
标准盒子模型,是浏览器默认的盒子模型
- 盒子总宽度 = width + padding + border + margin;
- 盒子总高度 = height + padding + border + margin
也就是,
width/height
只是内容高度,不包含
padding
和
border
值
所以上面问题中,设置
width
为200px,但由于存在
padding
,但实际上盒子的宽度有240px
三、IE 怪异盒子模型
- 盒子总宽度 = width + margin;
- 盒子总高度 = height + margin;
也就是,
width/height
包含了
padding
和
border
值
Box-sizing
CSS 中的 box-sizing 属性定义了引擎应该如何计算一个元素的总宽度和总高度
box-sizing: content-box|border-box|inherit:
- content-box 默认值,元素的 width/height 不包含padding,border,与标准盒子模型表现一致
- border-box 元素的 width/height 包含 padding,border,与怪异盒子模型表现一致
- inherit 指定 box-sizing 属性的值,应该从父元素继承
回到上面的例子里,设置盒子为 border-box 模型
<style>
.box {
width: 200px;
height: 100px;
padding: 20px;
box-sizing: border-box;
}
</style>
<div class="box">
盒子模型
</div>
这时,盒子所占据的宽度为200px
面试官:css选择器有哪些?优先级?哪些属性可以继承?
一、选择器
CSS选择器是CSS规则的第一部分
它是元素和其他部分组合起来告诉浏览器哪个HTML元素应当是被选为应用规则中的CSS属性值的方式
选择器所选择的元素,叫做“选择器的对象”
关于
css
属性选择器常用的有:
- id选择器(#box),选择id为box的元素
- 类选择器(.one),选择类名为one的所有元素
- 标签选择器(div),选择标签为div的所有元素
- 后代选择器(#box div),选择id为box元素内部所有的div元素
- 子选择器(.one>one_1),选择父元素为.one的所有.one_1的元素
- 相邻同胞选择器(.one+.two),选择紧接在.one之后的所有.two元素
- 群组选择器(div,p),选择div、p的所有元素
还有一些使用频率相对没那么多的选择器:
- 伪类选择器
:link :选择未被访问的链接
:visited:选取已被访问的链接
:active:选择活动链接
:hover :鼠标指针浮动在上面的元素
:focus :选择具有焦点的
:first-child:父元素的首个子元素
- 伪元素选择器
:first-letter :用于选取指定选择器的首字母
:first-line :选取指定选择器的首行
:before : 选择器在被选元素的内容前面插入内容
:after : 选择器在被选元素的内容后面插入内容
- 属性选择器
[attribute] 选择带有attribute属性的元素
[attribute=value] 选择所有使用attribute=value的元素
[attribute~=value] 选择attribute属性包含value的元素
[attribute|=value]:选择attribute属性以value开头的元素
在
CSS3
中新增的选择器有如下:
- 层次选择器(p~ul),选择前面有p元素的每个ul元素
- 伪类选择器
:first-of-type 表示一组同级元素中其类型的第一个元素
:last-of-type 表示一组同级元素中其类型的最后一个元素
:only-of-type 表示没有同类型兄弟元素的元素
:only-child 表示没有任何兄弟的元素
:nth-child(n) 根据元素在一组同级中的位置匹配元素
:nth-last-of-type(n) 匹配给定类型的元素,基于它们在一组兄弟元素中的位置,从末尾开始计数
:last-child 表示一组兄弟元素中的最后一个元素
:root 设置HTML文档
:empty 指定空的元素
:enabled 选择可用元素
:disabled 选择被禁用元素
:checked 选择选中的元素
:not(selector) 选择与 <selector> 不匹配的所有元素
- 属性选择器
[attribute*=value]:选择attribute属性值包含value的所有元素
[attribute^=value]:选择attribute属性开头为value的所有元素
[attribute$=value]:选择attribute属性结尾为value的所有元素
二、优先级
!important >内联 > ID选择器 > 类选择器 > 标签选择器
三、继承属性
在
css
中,继承是指的是给父元素设置一些属性,后代元素会自动拥有这些属性
关于继承属性,可以分成:
- 字体系列属性
font:组合字体
font-family:规定元素的字体系列
font-weight:设置字体的粗细
font-size:设置字体的尺寸
font-style:定义字体的风格
font-variant:偏大或偏小的字体
- 文本系列属性
text-indent:文本缩进
text-align:文本水平对刘
line-height:行高
word-spacing:增加或减少单词间的空白
letter-spacing:增加或减少字符间的空白
text-transform:控制文本大小写
direction:规定文本的书写方向
color:文本颜色
- 元素可见性
visibility
- 表格布局属性
caption-side:定位表格标题位置
border-collapse:合并表格边框
border-spacing:设置相邻单元格的边框间的距离
empty-cells:单元格的边框的出现与消失
table-layout:表格的宽度由什么决定
- 列表属性
list-style-type:文字前面的小点点样式
list-style-position:小点点位置
list-style:以上的属性可通过这属性集合
- 引用
quotes:设置嵌套引用的引号类型
- 光标属性
cursor:箭头可以变成需要的形状
继承中比较特殊的几点:
- a 标签的字体颜色不能被继承
- h1-h6标签字体的大下也是不能被继承的
无继承的属性
- display
- 文本属性:vertical-align、text-decoration
- 盒子模型的属性:宽度、高度、内外边距、边框等
- 背景属性:背景图片、颜色、位置等
- 定位属性:浮动、清除浮动、定位position等
- 生成内容属性:content、counter-reset、counter-increment
- 轮廓样式属性:outline-style、outline-width、outline-color、outline
- 页面样式属性:size、page-break-before、page-break-after
面试官:元素水平垂直居中的方法有哪些?如果元素不定宽高呢?
一、背景
在开发中经常遇到这个问题,即让某个元素的内容在水平和垂直方向上都居中,内容不仅限于文字,可能是图片或其他元素
居中是一个非常基础但又是非常重要的应用场景,实现居中的方法存在很多,可以将这些方法分成两个大类:
- 居中元素(子元素)的宽高已知
- 居中元素宽高未知
二、实现方式
实现元素水平垂直居中的方式:
- 利用定位+margin:auto
- 利用定位+margin:负值
- 利用定位+transform
- table布局
- flex布局
- grid布局
利用定位+margin:auto
先上代码:
<style>
.father{
width:500px;
height:300px;
border:1px solid #0a3b98;
position: relative;
}
.son{
width:100px;
height:40px;
background: #f0a238;
position: absolute;
top:0;
left:0;
right:0;
bottom:0;
margin:auto;
}
</style>
<div class="father">
<div class="son"></div>
</div>
父级设置为相对定位,子级绝对定位 ,并且四个定位属性的值都设置了0,那么这时候如果子级没有设置宽高,则会被拉开到和父级一样宽高
这里子元素设置了宽高,所以宽高会按照我们的设置来显示,但是实际上子级的虚拟占位已经撑满了整个父级,这时候再给它一个
margin:auto
它就可以上下左右都居中了
利用定位+margin:负值
绝大多数情况下,设置父元素为相对定位, 子元素移动自身50%实现水平垂直居中
<style>
.father {
position: relative;
width: 200px;
height: 200px;
background: skyblue;
}
.son {
position: absolute;
top: 50%;
left: 50%;
margin-left:-50px;
margin-top:-50px;
width: 100px;
height: 100px;
background: red;
}
</style>
<div class="father">
<div class="son"></div>
</div>

- 初始位置为方块1的位置
- 当设置left、top为50%的时候,内部子元素为方块2的位置
- 设置margin为负数时,使内部子元素到方块3的位置,即中间位置
这种方案不要求父元素的高度,也就是即使父元素的高度变化了,仍然可以保持在父元素的垂直居中位置,水平方向上是一样的操作
但是该方案需要知道子元素自身的宽高,但是我们可以通过下面
transform
属性进行移动
利用定位+transform
实现代码如下:
<style>
.father {
position: relative;
width: 200px;
height: 200px;
background: skyblue;
}
.son {
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%,-50%);
width: 100px;
height: 100px;
background: red;
}
</style>
<div class="father">
<div class="son"></div>
</div>
translate(-50%, -50%)
将会将元素位移自己宽度和高度的-50%
这种方法其实和最上面被否定掉的margin负值用法一样,可以说是
margin
负值的替代方案,并不需要知道自身元素的宽高
table布局
设置父元素为
display:table-cell
,子元素设置
display: inline-block
。利用
vertical
和
text-align
可以让所有的行内块级元素水平垂直居中
<style>
.father {
display: table-cell;
width: 200px;
height: 200px;
background: skyblue;
vertical-align: middle;
text-align: center;
}
.son {
display: inline-block;
width: 100px;
height: 100px;
background: red;
}
</style>
<div class="father">
<div class="son"></div>
</div>
flex弹性布局
还是看看实现的整体代码:
<style>
.father {
display: flex;
justify-content: center;
align-items: center;
width: 200px;
height: 200px;
background: skyblue;
}
.son {
width: 100px;
height: 100px;
background: red;
}
</style>
<div class="father">
<div class="son"></div>
</div>
css3
中了
flex
布局,可以非常简单实现垂直水平居中
这里可以简单看看
flex
布局的关键属性作用:
- display: flex时,表示该容器内部的元素将按照flex进行布局
- align-items: center表示这些元素将相对于本容器水平居中
- justify-content: center也是同样的道理垂直居中
grid网格布局
<style>
.father {
display: grid;
align-items:center;
justify-content: center;
width: 200px;
height: 200px;
background: skyblue;
}
.son {
width: 10px;
height: 10px;
border: 1px solid red
}
</style>
<div class="father">
<div class="son"></div>
</div>
这里看到,
gird
网格布局和
flex
弹性布局都简单粗暴
面试官:怎么理解回流跟重绘?什么场景下会触发?
一、是什么
在
HTML
中,每个元素都可以理解成一个盒子,在浏览器解析过程中,会涉及到回流与重绘:
- 回流:布局引擎会根据各种样式计算每个盒子在页面上的大小与位置
- 重绘:当计算好盒模型的位置、大小及其他属性后,浏览器根据每个盒子特性进行绘制
在页面初始渲染阶段,回流不可避免的触发,可以理解成页面一开始是空白的元素,后面添加了新的元素使页面布局发生改变
当我们对
DOM
的修改引发了
DOM
几何尺寸的变化(比如修改元素的宽、高或隐藏元素等)时,浏览器需要重新计算元素的几何属性,然后再将计算的结果绘制出来
当我们对
DOM
的修改导致了样式的变化(
color
或
background-color
),却并未影响其几何属性时,浏览器不需重新计算元素的几何属性、直接为该元素绘制新的样式,这里就仅仅触发了回流
二、如何触发
回流触发时机
回流这一阶段主要是计算节点的位置和几何信息,那么当页面布局和几何信息发生变化的时候,就需要回流,如下面情况:
- 添加或删除可见的DOM元素
- 元素的位置发生变化
- 元素的尺寸发生变化(包括外边距、内边框、边框大小、高度和宽度等)
- 内容发生变化,比如文本变化或图片被另一个不同尺寸的图片所替代
- 页面一开始渲染的时候(这避免不了)
- 浏览器的窗口尺寸变化(因为回流是根据视口的大小来计算元素的位置和大小的)
还有一些容易被忽略的操作:获取一些特定属性的值
offsetTop、offsetLeft、 offsetWidth、offsetHeight、scrollTop、scrollLeft、scrollWidth、scrollHeight、clientTop、clientLeft、clientWidth、clientHeight
这些属性有一个共性,就是需要通过即时计算得到。因此浏览器为了获取这些值,也会进行回流
除此还包括
getComputedStyle
方法,原理是一样的
重绘触发时机
触发回流一定会触发重绘
可以把页面理解为一个黑板,黑板上有一朵画好的小花。现在我们要把这朵从左边移到了右边,那我们要先确定好右边的具体位置,画好形状(回流),再画上它原有的颜色(重绘)
除此之外还有一些其他引起重绘行为:
- 颜色的修改
- 文本方向的修改
- 阴影的修改
浏览器优化机制
由于每次重排都会造成额外的计算消耗,因此大多数浏览器都会通过队列化修改并批量执行来优化重排过程。浏览器会将修改操作放入到队列里,直到过了一段时间或者操作达到了一个阈值,才清空队列
当你获取布局信息的操作的时候,会强制队列刷新,包括前面讲到的
offsetTop
等方法都会返回最新的数据
因此浏览器不得不清空队列,触发回流重绘来返回正确的值
三、如何减少
我们了解了如何触发回流和重绘的场景,下面给出避免回流的经验:
- 如果想设定元素的样式,通过改变元素的
class类名 (尽可能在 DOM 树的最里层) - 避免设置多项内联样式
- 应用元素的动画,使用
position属性的fixed值或absolute值(如前文示例所提) - 避免使用
table布局,table中每个元素的大小以及内容的改动,都会导致整个table的重新计算 - 对于那些复杂的动画,对其设置
position: fixed/absolute,尽可能地使元素脱离文档流,从而减少对其他元素的影响 - 使用css3硬件加速,可以让
transform、opacity、filters这些动画不会引起回流重绘 - 避免使用 CSS 的
JavaScript表达式
在使用
JavaScript
动态插入多个节点时, 可以使用
DocumentFragment
. 创建后一次插入. 就能避免多次的渲染性能
但有时候,我们会无可避免地进行回流或者重绘,我们可以更好使用它们
例如,多次修改一个把元素布局的时候,我们很可能会如下操作
const el = document.getElementById('el')
for(let i=0;i<10;i++) {
el.style.top = el.offsetTop + 10 + "px";
el.style.left = el.offsetLeft + 10 + "px";
}
每次循环都需要获取多次
offset
属性,比较糟糕,可以使用变量的形式缓存起来,待计算完毕再提交给浏览器发出重计算请求
// 缓存offsetLeft与offsetTop的值
const el = document.getElementById('el')
let offLeft = el.offsetLeft, offTop = el.offsetTop
// 在JS层面进行计算
for(let i=0;i<10;i++) {
offLeft += 10
offTop += 10
}
// 一次性将计算结果应用到DOM上
el.style.left = offLeft + "px"
el.style.top = offTop + "px"
我们还可避免改变样式,使用类名去合并样式
const container = document.getElementById('container')
container.style.width = '100px'
container.style.height = '200px'
container.style.border = '10px solid red'
container.style.color = 'red'
使用类名去合并样式
<style>
.basic_style {
width: 100px;
height: 200px;
border: 10px solid red;
color: red;
}
</style>
<script>
const container = document.getElementById('container')
container.classList.add('basic_style')
</script>
前者每次单独操作,都去触发一次渲染树更改(新浏览器不会),
都去触发一次渲染树更改,从而导致相应的回流与重绘过程
合并之后,等于我们将所有的更改一次性发出
我们还可以通过通过设置元素属性
display: none
,将其从页面上去掉,然后再进行后续操作,这些后续操作也不会触发回流与重绘,这个过程称为离线操作
const container = document.getElementById('container')
container.style.width = '100px'
container.style.height = '200px'
container.style.border = '10px solid red'
container.style.color = 'red'
离线操作后
let container = document.getElementById('container')
container.style.display = 'none'
container.style.width = '100px'
container.style.height = '200px'
container.style.border = '10px solid red'
container.style.color = 'red'
...(省略了许多类似的后续操作)
container.style.display = 'block'
面试官:什么是响应式设计?响应式设计的基本原理是什么?如何做?
一、是什么
响应式网站设计(Responsive Web design)是一种网络页面设计布局,页面的设计与开发应当根据用户行为以及设备环境(系统平台、屏幕尺寸、屏幕定向等)进行相应的响应和调整
描述响应式界面最著名的一句话就是“Content is like water”
大白话便是“如果将屏幕看作容器,那么内容就像水一样”
响应式网站常见特点:
- 同时适配PC + 平板 + 手机等
- 标签导航在接近手持终端设备时改变为经典的抽屉式导航
- 网站的布局会根据视口来调整模块的大小和位置

二、实现方式
响应式设计的基本原理是通过媒体查询检测不同的设备屏幕尺寸做处理,为了处理移动端,页面头部必须有
meta
声明
viewport
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1, user-scalable=no”>
属性对应如下:
- width=device-width: 是自适应手机屏幕的尺寸宽度
- maximum-scale:是缩放比例的最大值
- inital-scale:是缩放的初始化
- user-scalable:是用户的可以缩放的操作
实现响应式布局的方式有如下:
- 媒体查询
- 百分比
- vw/vh
- rem
媒体查询
CSS3
中的增加了更多的媒体查询,就像
if
条件表达式一样,我们可以设置不同类型的媒体条件,并根据对应的条件,给相应符合条件的媒体调用相对应的样式表
使用
@Media
查询,可以针对不同的媒体类型定义不同的样式,如:
@media screen and (max-width: 1920px) { ... }
当视口在375px - 600px之间,设置特定字体大小18px
@media screen (min-width: 375px) and (max-width: 600px) {
body {
font-size: 18px;
}
}
通过媒体查询,可以通过给不同分辨率的设备编写不同的样式来实现响应式的布局,比如我们为不同分辨率的屏幕,设置不同的背景图片
比如给小屏幕手机设置@2x图,为大屏幕手机设置@3x图,通过媒体查询就能很方便的实现
百分比
通过百分比单位 " % " 来实现响应式的效果
比如当浏览器的宽度或者高度发生变化时,通过百分比单位,可以使得浏览器中的组件的宽和高随着浏览器的变化而变化,从而实现响应式的效果
height
、
width
属性的百分比依托于父标签的宽高,但是其他盒子属性则不完全依赖父元素:
- 子元素的top/left和bottom/right如果设置百分比,则相对于直接非static定位(默认定位)的父元素的高度/宽度
- 子元素的padding如果设置百分比,不论是垂直方向或者是水平方向,都相对于直接父亲元素的width,而与父元素的height无关。
- 子元素的margin如果设置成百分比,不论是垂直方向还是水平方向,都相对于直接父元素的width
- border-radius不一样,如果设置border-radius为百分比,则是相对于自身的宽度
可以看到每个属性都使用百分比,会照成布局的复杂度,所以不建议使用百分比来实现响应式
vw/vh
vw
表示相对于视图窗口的宽度,
vh
表示相对于视图窗口高度。 任意层级元素,在使用
vw
单位的情况下,
1vw
都等于视图宽度的百分之一
与百分比布局很相似,在以前文章提过与
%
的区别,这里就不再展开述说
rem
在以前也讲到,
rem
是相对于根元素
html
的
font-size
属性,默认情况下浏览器字体大小为
16px
,此时
1rem = 16px
可以利用前面提到的媒体查询,针对不同设备分辨率改变
font-size
的值,如下:
@media screen and (max-width: 414px) {
html {
font-size: 18px
}
}
@media screen and (max-width: 375px) {
html {
font-size: 16px
}
}
@media screen and (max-width: 320px) {
html {
font-size: 12px
}
}
为了更准确监听设备可视窗口变化,我们可以在
css
之前插入
script
标签,内容如下:
//动态为根元素设置字体大小
function init () {
// 获取屏幕宽度
var width = document.documentElement.clientWidth
// 设置根元素字体大小。此时为宽的10等分
document.documentElement.style.fontSize = width / 10 + 'px'
}
//首次加载应用,设置一次
init()
// 监听手机旋转的事件的时机,重新设置
window.addEventListener('orientationchange', init)
// 监听手机窗口变化,重新设置
window.addEventListener('resize', init)
无论设备可视窗口如何变化,始终设置
rem
为
width
的1/10,实现了百分比布局
除此之外,我们还可以利用主流
UI
框架,如:
element ui
、
antd
提供的栅格布局实现响应式
三、总结
响应式布局优点可以看到:
- 面对不同分辨率设备灵活性强
- 能够快捷解决多设备显示适应问题
缺点:
- 仅适用布局、信息、框架并不复杂的部门类型网站
- 兼容各种设备工作量大,效率低下
- 代码累赘,会出现隐藏无用的元素,加载时间加长
- 其实这是一种折中性质的设计解决方案,多方面因素影响而达不到最佳效果
- 一定程度上改变了网站原有的布局结构,会出现用户混淆的情况
面试官:如果要做优化,CSS提高性能的方法有哪些?
一、前言
css
主要是用来完成页面布局的,像一些细节或者优化,
减少css嵌套,最好不要套三层以上。
不要在ID选择器前面进行嵌套,ID本来就是唯一的而且人家权值那么大,嵌套完全是浪费性能。
建立公共样式类,把相同样式提取出来作为公共类使用,比如我们常用的清除浮动等。
不用css表达式,css表达式对性能的浪费可能是超乎你的想象的
二、实现方式
实现方式有很多种,主要有如下:
- 内联首屏关键CSS
- 异步加载CSS
- 资源压缩
- 合理使用选择器
- 减少使用昂贵的属性
- 不要使用@import
内联首屏关键CSS
在打开一个页面,页面首要内容出现在屏幕的时间影响着用户的体验,而通过内联
css
关键代码能够使浏览器在下载完
html
后就能立刻渲染
而如果外部引用
css
代码,在解析
html
结构过程中遇到外部
css
文件,才会开始下载
css
代码,再渲染
所以,
CSS
内联使用使渲染时间提前
注意:但是较大的
css
代码并不合适内联(初始拥塞窗口、没有缓存),而其余代码则采取外部引用方式
异步加载CSS
在
CSS
文件请求、下载、解析完成之前,
CSS
会阻塞渲染,浏览器将不会渲染任何已处理的内容
前面加载内联代码后,后面的外部引用
css
则没必要阻塞浏览器渲染。这时候就可以采取异步加载的方案,主要有如下:
// 创建link标签
const myCSS = document.createElement( "link" );
myCSS.rel = "stylesheet";
myCSS.href = "mystyles.css";
// 插入到header的最后位置
document.head.insertBefore( myCSS, document.head.childNodes[ document.head.childNodes.length - 1 ].nextSibling );
- 设置link标签media属性为noexis,浏览器会认为当前样式表不适用当前类型,会在不阻塞页面渲染的情况下再进行下载。加载完成后,将
media的值设为screen或all,从而让浏览器开始解析CSS
<link rel="stylesheet" href="mystyles.css" media="noexist" onload="this.media='all'">
- 通过rel属性将link元素标记为alternate可选样式表,也能实现浏览器异步加载。同样别忘了加载完成之后,将rel设回stylesheet
<link rel="alternate stylesheet" href="mystyles.css" onload="this.rel='stylesheet'">
资源压缩
利用
webpack
、
gulp/grunt
、
rollup
等模块化工具,将
css
代码进行压缩,使文件变小,大大降低了浏览器的加载时间
合理使用选择器
css
匹配的规则是从右往左开始匹配,例如
#markdown .content h3
匹配规则如下:
- 先找到h3标签元素
- 然后去除祖先不是.content的元素
- 最后去除祖先不是#markdown的元素
如果嵌套的层级更多,页面中的元素更多,那么匹配所要花费的时间代价自然更高
所以我们在编写选择器的时候,可以遵循以下规则:
- 不要嵌套使用过多复杂选择器,最好不要三层以上
- 使用id选择器就没必要再进行嵌套
- 通配符和属性选择器效率最低,避免使用
减少使用昂贵的属性
在页面发生重绘的时候,昂贵属性如
box-shadow
/
border-radius
/
filter
/透明度/
:nth-child
等,会降低浏览器的渲染性能
不要使用@import
css样式文件有两种引入方式,一种是
link
元素,另一种是
@import
@import
会影响浏览器的并行下载,使得页面在加载时增加额外的延迟,增添了额外的往返耗时
而且多个
@import
可能会导致下载顺序紊乱
比如一个css文件
index.css
包含了以下内容:
@import url("reset.css")
那么浏览器就必须先把
index.css
下载、解析和执行后,才下载、解析和执行第二个文件
reset.css
面试官:说说JavaScript中的数据类型?存储上的差别?
js的数据类型分为两类,一个是基本数据类型,一个是引用数据类型
基本数据类型有undefined
、
null
、
boolean
、
number
、
string
、
symbol
引用数据类型有 object
在js的执行过程中,主要有三种数据类型内存空间,分别是代码空间,栈空间,堆空间,其中的代码空间主要是存储可执行代码的,原始类型的数据值都是直接保存在栈中的,引用数据类型的值是存放在堆空间中的, 原始数据类型存储的是变量的值,而引用数据类型存储的是其在堆空间中的地址
JavaScript系列
面试官:typeof 与 instanceof 区别
一、typeof
typeof 对于原始数据类型来说,除了null都可以正确的显示类型
使用方法如下:
typeof operand
typeof(operand)
operand
表示对象或原始值的表达式,其类型将被返回
举个例子
typeof 1 // 'number'
typeof '1' // 'string'
typeof undefined // 'undefined'
typeof true // 'boolean'
typeof Symbol() // 'symbol'
typeof null // 'object'
typeof [] // 'object'
typeof {} // 'object'
typeof console // 'object'
typeof console.log // 'function'
从上面例子,前6个都是基础数据类型。虽然
typeof null
为
object
,但这只是
JavaScript
存在的一个悠久
Bug
,不代表
null
就是引用数据类型,并且
null
本身也不是对象
所以,
null
在
typeof
之后返回的是有问题的结果,不能作为判断
null
的方法。如果你需要在
if
语句中判断是否为
null
,直接通过
===null
来判断就好
同时,可以发现引用类型数据,用
typeof
来判断的话,除了
function
会被识别出来之外,其余的都输出
object
如果我们想要判断一个变量是否存在,可以使用
typeof
:(不能使用
if(a)
, 若
a
未声明,则报错)
if(typeof a != 'undefined'){
//变量存在
}
二、instanceof
instanceof 可以正确显示数据类型, 因为它是通过对象的原型链来进行判断的,
使用如下:
object instanceof constructor
object
为实例对象,
constructor
为构造函数
构造函数通过
new
可以实例对象,
instanceof
能判断这个对象是否是之前那个构造函数生成的对象
// 定义构建函数
let Car = function() {}
let benz = new Car()
benz instanceof Car // true
let car = new String('xxx')
car instanceof String // true
let str = 'xxx'
str instanceof String // false
关于
instanceof
的实现原理,可以参考下面:
function myInstanceof(left, right) {
// 这里先用typeof来判断基础数据类型,如果是,直接返回false
if(typeof left !== 'object' || left === null) return false;
// getProtypeOf是Object对象自带的API,能够拿到参数的原型对象
let proto = Object.getPrototypeOf(left);
while(true) {
if(proto === null) return false;
if(proto === right.prototype) return true;//找到相同原型对象,返回true
proto = Object.getPrototypeof(proto);
}
}
也就是顺着原型链去找,直到找到相同的原型对象,返回
true
,否则为
false
三、区别
typeof
与
instanceof
都是判断数据类型的方法,区别如下:
typeof会返回一个变量的基本类型,instanceof返回的是一个布尔值instanceof可以准确地判断复杂引用数据类型,但是不能正确判断基础数据类型- 而
typeof也存在弊端,它虽然可以判断基础数据类型(null除外),但是引用数据类型中,除了function类型以外,其他的也无法判断
可以看到,上述两种方法都有弊端,并不能满足所有场景的需求
如果需要通用检测数据类型,可以采用
Object.prototype.toString
,调用该方法,统一返回格式
“[object Xxx]”
的字符串
如下
Object.prototype.toString({}) // "[object Object]"
Object.prototype.toString.call({}) // 同上结果,加上call也ok
Object.prototype.toString.call(1) // "[object Number]"
Object.prototype.toString.call('1') // "[object String]"
Object.prototype.toString.call(true) // "[object Boolean]"
Object.prototype.toString.call(function(){}) // "[object Function]"
Object.prototype.toString.call(null) //"[object Null]"
Object.prototype.toString.call(undefined) //"[object Undefined]"
Object.prototype.toString.call(/123/g) //"[object RegExp]"
Object.prototype.toString.call(new Date()) //"[object Date]"
Object.prototype.toString.call([]) //"[object Array]"
Object.prototype.toString.call(document) //"[object HTMLDocument]"
Object.prototype.toString.call(window) //"[object Window]"
了解了
toString
的基本用法,下面就实现一个全局通用的数据类型判断方法
function getType(obj){
let type = typeof obj;
if (type !== "object") { // 先进行typeof判断,如果是基础数据类型,直接返回
return type;
}
// 对于typeof返回结果是object的,再进行如下的判断,正则返回结果
return Object.prototype.toString.call(obj).replace(/^\[object (\S+)\]$/, '$1');
}
使用如下
getType([]) // "Array" typeof []是object,因此toString返回
getType('123') // "string" typeof 直接返回
getType(window) // "Window" toString返回
getType(null) // "Null"首字母大写,typeof null是object,需toString来判断
getType(undefined) // "undefined" typeof 直接返回
getType() // "undefined" typeof 直接返回
getType(function(){}) // "function" typeof能判断,因此首字母小写
getType(/123/g) //"RegExp" toString返回
面试官:说说你对闭包的理解?闭包使用场景
闭包就是可以访问其他函数内部变量的函数,我们通常用它来定义私有化的变量和方法,创建一个闭包最简单的方法就是在一个函数内创建一个函数,它有三个特性是 函数内可以再嵌套函数,内部函数可以访问外部的方法和变量,方法和变量不会被垃圾回收机制回收,
一、是什么
闭包最简单的方法就是在一个函数内创建一个函数,闭包让你可以在一个内层函数中访问到其外层函数的作用域
二、使用场景
任何闭包的使用场景都离不开这两点:
- 创建私有变量
- 延长变量的生命周期
一般函数的词法环境在函数返回后就被销毁,但是闭包会保存对创建时所在词法环境的引用,即便创建时所在的执行上下文被销毁,但创建时所在词法环境依然存在,以达到延长变量的生命周期的目的
创建私有变量:好比vue里的data 每个data都是一个闭包所以他们互不干扰
三、优缺点
它的优点就是可以实现封装和缓存,缺点就是可能会造成内存泄漏的问题
面试官:bind、call、apply 区别?如何实现一个bind?
关于call、apply、bind函数,它们主要用来改变this指向的
call的用法
fn.call(thisArg, arg1, arg2, arg3, ...)
调用fn.call时会将fn中的this指向修改为传入的第一个参数thisArg;将后面的参数传入给fn,并立即执行函数fn。
let obj = {
name: "xiaoming",
age: 24,
sayHello: function (job, hobby) {
console.log(`我叫${this.name},今年${this.age}岁。我的工作是: ${job},我的爱好是: ${hobby}。`);
}
}
obj.sayHello('程序员', '看美女'); // 我叫xiaoming,今年24岁。我的工作是: 程序员,我的爱好是: 看美女。
let obj1 = {
name: "lihua",
age: 30
}
// obj1.sayHello(); // Uncaught TypeError: obj1.sayHello is not a function
obj.sayHello.call(obj1, '设计师', '画画'); // 我叫lihua,今年30岁。我的工作是: 设计师,我的爱好是: 画画。
apply的用法
apply(thisArg, [argsArr])
fn.apply的作用和call相同:修改this指向,并立即执行fn。区别在于传参形式不同,apply接受两个参数,第一个参数是要指向的this对象,第二个参数是一个数组,数组里面的元素会被展开传入fn,作为fn的参数。
bind的用法
bind(thisArg, arg1, arg2, arg3, ...)
fn.bind的作用是只修改this指向,但不会立即执行fn;会返回一个修改了this指向后的fn。需要调用才会执行**:
bind(thisArg, arg1, arg2, arg3, ...)()
。**bind的传参和call相同。
obj.sayHello.bind(obj1, '设计师', '画画'); // 无输出结果
obj.sayHello.bind(obj1, '设计师', '画画')(); // 我叫lihua,今年30岁。我的工作是: 设计师,我的爱好是: 画画。
bind、call、apply的区别
1、相同点
三个都是用于改变this指向;
接收的第一个参数都是this要指向的对象;
都可以利用后续参数传参。
2、不同点
call和bind传参相同,多个参数依次传入的;
apply只有两个参数,第二个参数为数组;
call和apply都是对函数进行直接调用,而bind方法不会立即调用函数,而是返回一个修改this后的函数。
面试官:说说你对事件循环的理解
一、是什么
JavaScript
是一门单线程的语言,在
JavaScript
中,所有的任务都可以分为
- 同步任务:立即执行的任务,同步任务一般会直接进入到主线程中执行
- 异步任务:异步执行的任务,比如
ajax网络请求,setTimeout定时函数等
同步任务与异步任务的运行流程图如下:

从上面我们可以看到,同步任务进入主线程,即主执行栈,异步任务进入任务队列,主线程内的任务执行完毕为空,会去任务队列读取对应的任务,推入主线程执行。上述过程的不断重复就事件循环
二、宏任务与微任务
微任务
一个需要异步执行的函数,执行时机是在主函数执行结束之后、当前宏任务结束之前
常见的微任务有:
- Promise.then
- MutaionObserver
- Object.observe(已废弃;Proxy 对象替代)
- process.nextTick(Node.js)
宏任务
宏任务的时间粒度比较大,执行的时间间隔是不能精确控制的,对一些高实时性的需求就不太符合
常见的宏任务有:
- script (可以理解为外层同步代码)
- setTimeout/setInterval
- UI rendering/UI事件
- postMessage、MessageChannel
- setImmediate、I/O(Node.js)
这时候,事件循环,宏任务,微任务的关系如图所示

三、async与await
async
async
是异步的意思,
await
则可以理解为
async wait
。所以可以理解
async
就是用来声明一个异步方法,而
await
是用来等待异步方法执行
async
函数返回一个
promise
对象,下面两种方法是等效的
function f() {
return Promise.resolve('TEST');
}
// asyncF is equivalent to f!
async function asyncF() {
return 'TEST';
}
await
正常情况下,
await
命令后面是一个
Promise
对象,返回该对象的结果。如果不是
Promise
对象,就直接返回对应的值
async function f(){
// 等同于
// return 123
return await 123
}
f().then(v => console.log(v)) // 123
不管
await
后面跟着的是什么,
await
都会阻塞后面的代码
async function fn1 (){
console.log(1)
await fn2()
console.log(2) // 阻塞
}
async function fn2 (){
console.log('fn2')
}
fn1()
console.log(3)
上面的例子中,
await
会阻塞下面的代码(即加入微任务队列),先执行
async
外面的同步代码,同步代码执行完,再回到
async
函数中,再执行之前阻塞的代码
所以上述输出结果为:
1
,
fn2
,
3
,
2
面试官:DOM常见的操作有哪些?
一、DOM
任何
HTML
或
XML
文档都可以用
DOM
表示为一个由节点构成的层级结构
<div>
<p title="title">
content
</p >
</div
上述结构中,
div
、
p
就是元素节点,
content
就是文本节点,
title
就是属性节点
二、操作
DOM
操作才能有助于我们理解框架深层的内容
下面就来分析
DOM
常见的操作,主要分为:
- 创建节点
- 查询节点
- 更新节点
- 添加节点
- 删除节点
创建节点
createEleme
创建新元素,接受一个参数,即要创建元素的标签名
const divEl = document.createElement("div");
createTextNode
创建一个文本节点
const textEl = document.createTextNode("content");
获取节点
querySelector
传入任何有效的
css
选择器,即可选中单个
DOM
元素(首个):
document.querySelector('.element')
document.querySelector('#element')
document.querySelector('div')
document.querySelector('[name="username"]')
document.querySelector('div + p > span')
如果页面上没有指定的元素时,返回
null
关于获取
DOM
元素的方法还有如下,就不一一述说
document.getElementById('id属性值');返回拥有指定id的对象的引用
document.getElementsByClassName('class属性值');返回拥有指定class的对象集合
document.getElementsByTagName('标签名');返回拥有指定标签名的对象集合
document.getElementsByName('name属性值'); 返回拥有指定名称的对象结合
document/element.querySelector('CSS选择器'); 仅返回第一个匹配的元素
document/element.querySelectorAll('CSS选择器'); 返回所有匹配的元素
document.documentElement; 获取页面中的HTML标签
document.body; 获取页面中的BODY标签
document.all['']; 获取页面中的所有元素节点的对象集合型
更新节点
innerHTML
不但可以修改一个
DOM
节点的文本内容,还可以直接通过
HTML
片段修改
DOM
节点内部的子树
// 获取<p id="p">...</p >
var p = document.getElementById('p');
// 设置文本为abc:
p.innerHTML = 'ABC'; // <p id="p">ABC</p >
// 设置HTML:
p.innerHTML = 'ABC <span style="color:red">RED</span> XYZ';
// <p>...</p >的内部结构已修改
innerText、textContent
两者的区别在于读取属性时,
innerText
不返回隐藏元素的文本,而
textContent
返回所有文本
添加节点
innerHTML
如果这个DOM节点是空的,例如,
<div></div>
,那么,直接使用
innerHTML = '<span>child</span>'
就可以修改
DOM
节点的内容,相当于添加了新的
DOM
节点
如果这个DOM节点不是空的,那就不能这么做,因为
innerHTML
会直接替换掉原来的所有子节点
appendChild
把一个子节点添加到父节点的最后一个子节点
举个例子
<!-- HTML结构 -->
<p id="js">JavaScript</p>
<div id="list">
<p id="java">Java</p>
<p id="python">Python</p>
<p id="scheme">Scheme</p>
</div>
<!--添加一个p元素-->
<script>
const js = document.getElementById('js')
js.innerHTML = "JavaScript"
const list = document.getElementById('list');
list.appendChild(js);
</script>
现在
HTML
结构变成了下面
<!-- HTML结构 -->
<div id="list">
<p id="java">Java</p >
<p id="python">Python</p >
<p id="scheme">Scheme</p >
<p id="js">JavaScript</p > <!-- 添加元素 -->
</div>
上述代码中,我们是获取
DOM
元素后再进行添加操作,这个
js
节点是已经存在当前文档树中,因此这个节点首先会从原先的位置删除,再插入到新的位置
如果动态添加新的节点,则先创建一个新的节点,然后插入到指定的位置
const list = document.getElementById('list'),
const haskell = document.createElement('p');
haskell.id = 'haskell';
haskell.innerText = 'Haskell';
list.appendChild(haskell);
insertBefore
把子节点插入到指定的位置,使用方法如下:
parentElement.insertBefore(newElement, referenceElement)
子节点会插入到
referenceElement
之前
删除节点
删除一个节点,首先要获得该节点本身以及它的父节点,然后,调用父节点的
removeChild
把自己删掉
// 拿到待删除节点:
const self = document.getElementById('to-be-removed');
// 拿到父节点:
const parent = self.parentElement;
// 删除:
const removed = parent.removeChild(self);
removed === self; // true
删除后的节点虽然不在文档树中了,但其实它还在内存中,可以随时再次被添加到别的位置
面试官:说说你对BOM的理解,常见的BOM对象你了解哪些?
一、是什么
BOM
(Browser Object Model),浏览器对象模型,提供了内容与浏览器窗口进行交互的对象
其作用就是跟浏览器做一些交互效果,比如如何进行页面的后退,前进,刷新
二、window
Bom
的核心对象是
window
,它表示浏览器的一个实例
在浏览器中 即是浏览器窗口的一个接口,又是全局对象
三、location
window对象给我们提供了一个location属性用于获取或设置窗体的URL,并且可以用于解析URL。
四、navigator
navigator
对象主要用来获取浏览器的属性,区分浏览器类型。属性较多,且兼容性比较复杂
五、screen
保存的是浏览器窗口外面的客户端显示器的信息,比如像素宽度和像素高度
六、history
history
对象主要用来操作浏览器
URL
的历史记录,可以通过参数向前,向后,或者向指定
URL
跳转
面试官:Javascript本地存储的方式有哪些?区别及应用场景?
javaScript
本地缓存的方法我们主要讲述以下四种:
- cookie
- sessionStorage
- localStorage
- indexedDB
cookie
Cookie
,用户发送请求时会携带cookie到服务端,服务端会判断cookie来识别用户,cookie存储一般不超过 4KB 的小型文本数据,但是
cookie
在每次请求中都会被发送,如果不使用
HTTPS
并对其加密,其保存的信息很容易被窃取,
localStorage
HTML5
新方法,IE8及以上浏览器都兼容
特点
- 生命周期:持久化的本地存储,除非主动删除数据,否则数据是永远不会过期的
- 存储的信息在同一域中是共享的
- 当本页操作(新增、修改、删除)了
localStorage的时候,本页面不会触发storage事件,但是别的页面会触发storage事件。 - 大小:5M(跟浏览器厂商有关系)
localStorage本质上是对字符串的读取,如果存储内容多的话会消耗内存空间,会导致页面变卡- 受同源策略的限制
sessionStorage
sessionStorage
和
localStorage
使用方法基本一致,唯一不同的是生命周期,一旦页面(会话)关闭,
sessionStorage
将会删除数据
扩展的前端存储方式
indexedDB
是一种低级API,用于客户端存储大量结构化数据(包括, 文件/ blobs)。
面试官:什么是防抖和节流?有什么区别?如何实现?
一、是什么
本质上是优化高频率执行代码的一种手段
为了优化体验,需要对这类事件进行调用次数的限制,对此我们就可以采用 防抖(debounce) 和 节流(throttle) 的方式来减少调用频率
定义
- 节流: n 秒内只运行一次,若在 n 秒内重复触发,只有一次生效
- 防抖: n 秒后在执行该事件,若在 n 秒内被重复触发,则重新计时
一个经典的比喻:
电梯第一个人进来后,15秒后准时运送一次,这是节流
电梯第一个人进来后,等待15秒。如果过程中又有人进来,15秒等待重新计时,直到15秒后开始运送,这是防抖
二、区别
相同点:
- 都可以通过使用
setTimeout实现 - 目的都是,降低回调执行频率。节省计算资源
不同点:
- 函数防抖,在一段连续操作结束后,处理回调,利用
clearTimeout和setTimeout实现。函数节流,在一段连续操作中,每一段时间只执行一次,频率较高的事件中使用来提高性能 - 函数防抖关注一定时间连续触发的事件,只在最后执行一次,而函数节流一段时间内只执行一次
面试官:如何通过js判断一个数组?
1.通过instanceof判断
instanceof运算符用于检验构造函数的prototype属性是否出现在对象的原型链中的任何位置,返回一个布尔值

2.通过constructor判断
实例的构造函数属性constructor指向构造函数,通过constructor属性可以判断是否为一个数组
 3.通过Object.prototype.toString.call()判断
3.通过Object.prototype.toString.call()判断
Object.prototype.toString.call()可以获取到对象的不同类型

4.通过Array.isArray()判断
Array.isArray()用于确定传递的值是否是一个数组,返回一个布尔值

面试官:说说你对作用域链的理解?
一、作用域
我们一般将作用域分成:
- 全局作用域
- 函数作用域
- 块级作用域
二、作用域链
function fn(){
let age=18;
function inner(){
// 函数内访问变量时,优先使用自己内部声明变量
// 如果没有,尝试访问外部函数作用域的变量
// 如果外部函数作用域也没有这个变量,继续往下找
// 知道找到全局,如果全局都没有,就报错
let count=100;
console.log(count);
console.log(age);
console.log(name);
}
inner()
}
fn()
如上图:
- inner函数访问自身的变量时,没有找到。则访问外部中的变量,还是没有找到就往全局找
- 这样一层一层形成的链叫做作用域链
- 当然全局还没有找到最外面一层是null 会报错
面试官:什么是浏览器缓存?
浏览器缓存就是把一个已经请求过的web资源(如html页面,图片,JS,数据)拷贝一份放在浏览器中。缓存会根据进来的请求保存输入内容的副本。当下一个请求到来的时候,如果是相同的URL,浏览器会根据缓存机制决定是直接使用副本响应访问请求还是向源服务器再次发起请求。
使用缓存的原因
(1)减少网络带宽消耗
(2)降低服务器压力
(3)减少网络延迟
浏览器的缓存机制
过期机制:指的是缓存副本的有效期。一个缓存的副本必须满足以下条件,浏览器会认为它是有效的,足够新的:
1.含有完整的过期时间控制头信息(HTTP协议报头),并且仍在有效期内
2.浏览器已经使用过这个缓存的副本,并且会在一个会话中已经检查过新鲜度(即服务器上的资源是否发生改变)
满足以上两种情况的一种,浏览器会直接从缓存中获取副本进行渲染
校验值(验证机制):服务器返回资源的时候有时在控制头信息带上这个资源的实体标签Etag(Entity Tag),它可以用来作为浏览器再次请求过程中的校验标识,如果发现校验标识不匹配,说明资源已经被修改或者过期,浏览器需要重新获取资源内容。
浏览器缓存的控制
(1)使用meta标签
Web开发者可以在HTML页面的节点中加入标签,代码如下:
<meta http-equiv="Pragma" content="no-cache">
<!- Pragma是http1.0版本中给客户端设定缓存方式之一,具体作用会在后面详细介绍 -->
上述代码的作用是告诉浏览器当前页面不被缓存,每次访问都需要去服务器上拉取。但是这种禁用缓存的形式很有限:
1.仅有IE才能识别这段meta标签的含义,其他主流浏览器仅识别”Cache-Control:no-store”的meta标签
2.在IE中识别到该meta标签的含义,并不一定会在请求字段中加上Pragma,但的确会让当前页面每次都发起新请求(仅限页面,页面上的资源则不受影响)
(2)使用缓存有关的HTTP消息报头
在HTTP请求和响应的消息报头中,常见与缓存有关的消息报头有:
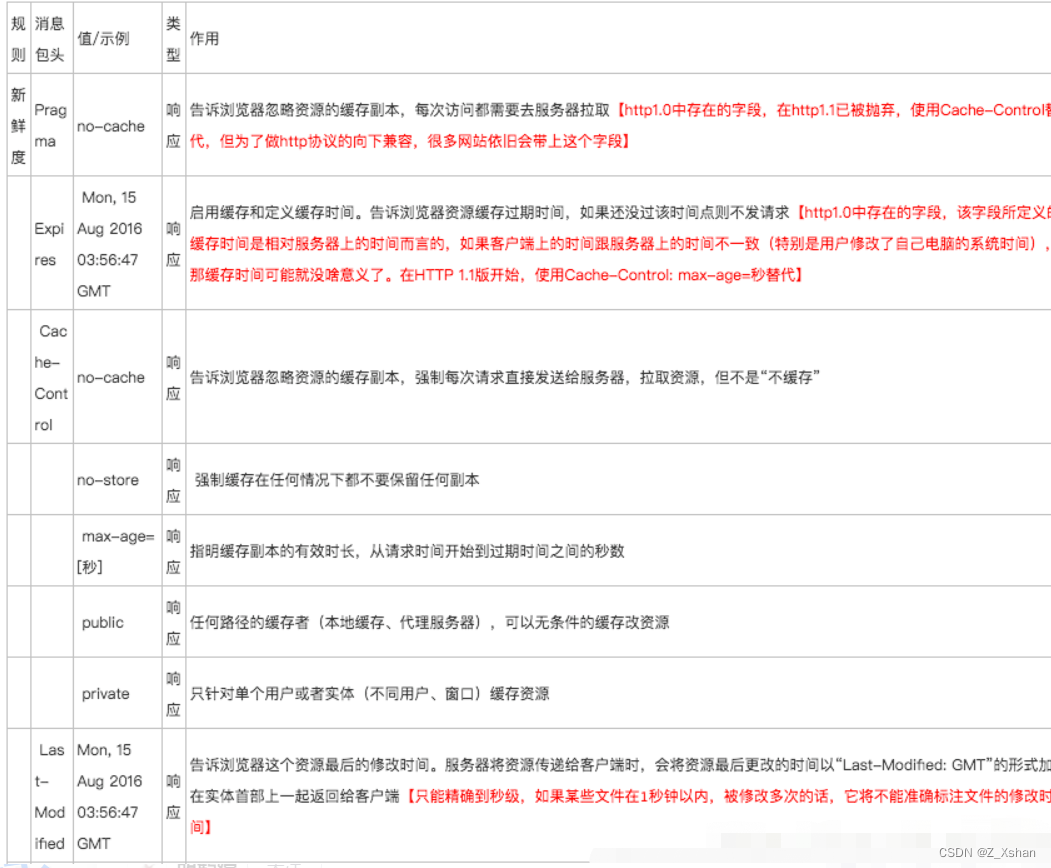

不同字段间的比较:
在配置Last-Modified/Etag的情况下,浏览器再次访问统一的URI资源,还是会发送请求到服务器询问文件是否已经修改,如果没有,服务器只发送一个304给浏览器,告诉浏览器直接从自己的本地缓存取数据,如果修改过,那就将整个数据重新发送给浏览器。
Cache-Control/Expires则不同,如果检测到本地的缓存还在有效的时间范围内,浏览器直接使用本地副本,不会发送任何请求。两者一起使用的时候,Cache-Control/Expires的优先级要高于Last-Modified/Etag。
即当当地副本根据Cache-Control/Expires发现还在有效期内,则不会再次发送请求去服务器询问修改时间(Last-Modified)或者实体标识符(Etag)了。
一般情况下,使用Cache-Control/Expires会配合Last-Modified/Etag一起使用,因为即使浏览器设置缓存时间,当用户点击“刷新”按钮时,浏览器会忽略缓存继续向服务器发送请求,这是Last-Modified/Etag将能够很好的利用304,从而减少响应开销。
浏览器向服务器请求资源的过程

** 关于缓存的两个概念**
强缓存:
用户发送的请求,直接从客户端缓存中获取,不发送请求到服务器,不与服务器发生交互行为。
协商缓存:
用户发送请求,发送到服务器之后,由服务器判定是否从缓存中获取资源。
两者共同点:客户端获取的数据最后都是熊客户端的缓存中取得。
两者区别:从名字就可以看出,强缓存不与服务器发生交互,而协商缓存则需要需服务器发生交互。
面试官:什么是原型和原型链?
一、原型
①所有引用类型都有一个__proto__(隐式原型) 属性,属性值是一个普通对象
②所有函数都有一个prototype(原型),属性值是一个普通对象
③所有引用类型的__proto__属性指向他的构造函数的prototype
var a = [1,2,3];
a.__proto__ === Array.prototype; // true
** 二、原型链**
当访问一个对象的某个属性时,会先在这个对象本身属性上查找,如果没有找到,则会去它的__proto__隐式原型上查找,即它的构造函数的prototype,如果还没有找到就会再在构造函数的prototype的__proto__中查找,这样一层一层向上查找就会形成一个链式结构,我们称为原型链。
举例,有以下代码
function Parent(month){
this.month = month;
}
var child = new Parent('Ann');
console.log(child.month); // Ann
console.log(child.father); // undefined
在child中查找某个属性时,会
执行下面步骤
:
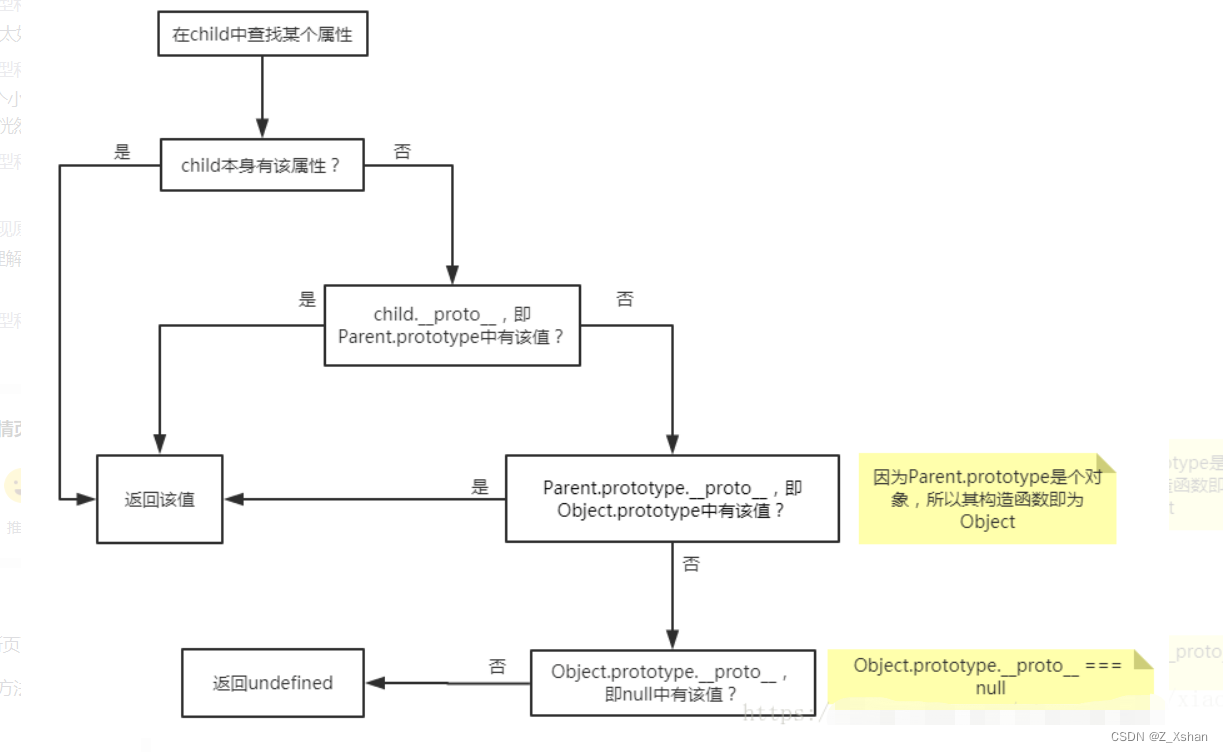
访问链路
为:

①一直往上层查找,直到到null还没有找到,则返回
undefined②
Object.prototype.__proto__ === null③所有从原型或更高级原型中的得到、执行的方法,其中的this在执行时,指向当前这个触发事件执行的对象
面试官:JS中null和undefined的区别
相同点 if 判断语句中,两者都会被转换为false 都是是 JavaScript 基本类型之一
不同点
Number转换的值不同Number(null)输出为0, Number(undefined)输出为NaN
Undefined,当声明的变量还未被初始化时,变量的默认值为undefined。
Null,null用来表示尚未存在的对象,常用来表示函数企图返回一个不存在的对象。
面试官:JS中的“use strict” 严格模式
JavaScript 除了提供正常模式外,还提供了严格模式(strict mode)。ES5 的严格模式是采用具有限制性JavaScript变体的一种方式,即在严格的条件下运行 JS 代码。
严格模式在 IE10 以上版本的浏览器中才会被支持,旧版本浏览器中会被忽略。
严格模式对正常的 JavaScript 语义做了一些更改:
消除了 Javascript 语法的一些不合理、不严谨之处,减少了一些怪异行为。
消除代码运行的一些不安全之处,保证代码运行的安全。
提高编译器效率,增加运行速度。
禁用了在 ECMAScript 的未来版本中可能会定义的一些语法,为未来新版本的 Javascript 做好铺垫。比如一些保留字如:class,enum,export, extends, import, super 不能做变量名
面试官:同步与异步的区别
同步:同步是指一个进程在执行某个请求的时候,如果该请求需要一段时间才能返回信息,那么这个进程会一直等待下去,直到收到返回信息才继续执行下去。
异步:异步是指进程不需要一直等待下去,而是继续执行下面的操作,不管其他进程的状态,当有信息返回的时候会通知进程进行处理,这样就可以提高执行的效率了,即异步是我们发出的一个请求,该请求会在后台自动发出并获取数据,然后对数据进行处理,在此过程中,我们可以继续做其他操作,不管它怎么发出请求,不关心它怎么处理数据。
打个比方:同步的时候,你在写程序,然后你妈妈叫你马上拖地,你就必须停止写程序然后拖地,没法同时进行。而异步则不需要按部就班,可以在等待那个动作的时候同时做别的动作,打个比方:你在写程序,然后你妈妈让你马上拖地,而这时你就贿赂你弟弟帮你拖地,于是结果同样是拖好地,你可以继续敲你的代码而不用管地是怎么拖
面试官:箭头函数与普通函数的区别
一,普通函数可以有匿名函数,也可以有具体名函数,但是箭头函数都是匿名函数。
// 具名函数
function func(){
// code
}
// 匿名函数
let func=function(){
// code
}
// 箭头函数全都是匿名函数
let func=()=>{
// code
}
二、箭头函数不能用于构造函数,不能使用new
普通函数可以用于构造函数,以此创建对象实例。
三、箭头函数中this的指向不同
在普通函数中,this总是指向调用它的对象,如果用作构造函数,this指向创建的对象实例。
箭头函数没有
prototype
(原型),所以箭头函数本身没有
this
箭头函数的
this
指向在定义的时候继承自外层第一个普通函数的this
面试官:JS 对象和数组的遍历方法,以及方式的比较
一、JS 遍历数组
1、for 循环遍历数组
// 1、for循环
let arr = ['d', 'a', 'w', 'n'];
for (let i = 0; i < arr.length; i++){
console.log(arr[i]);
}
这种直接使用for循环的方法是最普遍的遍历数组和对象的方法;
2、使用for ……in 遍历数组
//2、for……in 循环
let arr = ['d', 'a', 'w', 'n'];
for (let key in arr) {
console.log(arr[key]);
}
3、for……of 遍历数组
//3、for……of 遍历数组
let arr = ['d', 'a', 'w', 'n'];
for (let value of arr) {
console.log(value);
}
es6新出的方法,for…of ,值得注意的是,for…of 和 for…in不一样,for…in是直接获取数组的索引,而for…of是直接获取的数组的值
ES6里引入了一种遍历器(Iterator)机制,为不同的数据结构提供统一的访问机制。只要部署了Iterator的数据结构都可以使用 for ··· of ··· 完成遍历操作
它既比传统的for循环简洁,同时弥补了forEach和for-in循环的短板。
循环遍历键值对的value,与for in遍历key相反
4、forEach 遍历数组
//4、forEach遍历数组
let arr = ['d', 'a', 'w', 'n'];
arr.forEach(function (k){
console.log(k);
})
forEach这种方法也有一个小缺陷:你不能使用break语句中断循环,也不能使用return语句返回到外层函数。
5、map遍历数组
// 5、map 遍历数组
let arr = ['d', 'a', 'w', 'n'];
let res = arr.map(function (item) {
return item;
})
console.log(res);
总结:
for…in 遍历(当前对象及其原型上的)每一个key,而 for…of遍历(当前对象上的)每一个value;
for in 以任意顺序遍历对象的可枚举属性,(最好不要用来遍历数组) 因此当迭代那些访问次序重要的 arrays 时用整数索引去进行 for 循环 (或者使用 Array.prototype.forEach() 或 for…of 循环) 。
(ES6)for…of 允许你遍历 Arrays(数组), Strings(字符串), Maps(映射), Sets(集合)等可迭代的数据结构等。不能遍历普通对象
forEach 遍历数组,而且在遍历的过程中不能被终止,必须每一个值遍历一遍后才能停下来
二、JS 遍历对象
1、for……in 循环遍历对象
//1、for……in遍历对象
var obj = {
name: 'dawn',
age: 21,
address:'深圳'
}
for (let key in obj) {
console.log(key+':'+obj[key]);
}
2、Object.keys 遍历对象
//2、for……of遍历对象
var obj = {
name: 'dawn',
age: 21,
address: '深圳'
}
for (let key of Object.keys(obj)) {
console.log(key+':'+obj[key]);
}
【注意】:for…of不能单独来遍历对象,要结合Object.keys一起使用才行
Object.keys()方法会返回一个由一个指定对象的自身可枚举属性组成的数组,数组中属性名的排列顺序和使用for...in循环遍历该对象时返回的顺序一致。
3、Object.getOwnPropertyNames(obj) 遍历对象
//3、Object.getOwnPropertyNames(obj) 遍历对象
var obj = {
name: 'dawn',
age: 21,
address: '深圳'
}
Object.getOwnPropertyNames(obj).forEach(function (key){
console.log(key+':'+obj[key]);
})
返回一个数组,包含对象自身的所有属性(包含不可枚举属性) 遍历可以获取key和value
面试官:如何解决跨域问题
一、什么是跨域?跨域是如何产生的?
- 同源策略:
浏览器内置的规则!是浏览器提供的一种安全机制,限制来自不同源的数据。如果当前页面的URL地址和Ajax的请求地址不同源,浏览器不允许得到服务器的数据;
- 同源:、
协议 http||https、域名和 port端口 都相同则同源,只要有一项不同就是不同源 不同源就跨域
二、如何解决跨域?
1.JSONP
注意:
JSONP和json没有任何关系
JSONP需要前后台配合
1.实现原理:
走获取文件资源script这个方式
JSONP实现跨域请求的原理简单的说,就是动态创建<script>标签,然后利用<script>的src 不受同源策略约束来跨域获取数据。
JSONP 由两部分组成:回调函数和数据。回调函数是当响应到来时应该在页面中调用的函数。回调函数的名字一般是在请求中指定的。而数据就是传入回调函数中的 JSON 数据。
** 2. CORS(跨域资源共享)**
- 一般都是后台设置
CORS是一个W3C标准,全称是"跨域资源共享"(Cross-origin resource sharing)。 它允许浏览器向跨源服务器,发出XMLHttpRequest请求,从而克服了AJAX只能同源使用的限制。
**3.代理服务器 **
在vue.config.js修改配置
# vue.config.js
module.exports = {
devServer: {
host: 'localhost',
port: 8080,
proxy: {
'/api': {
target: 'http://localhost:3000',// 要跨域的域名
changeOrigin: true, // 是否开启跨域
},
'/get': {
target: 'http://localhost:3000',// 要跨域的域名
changeOrigin: true, // 是否开启跨域
}
}
}
}
面试官:JSON和XML的区别
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它完全独立于语言。它基于JavaScript编程语言,易于理解和生成。
XML(可扩展标记语言)旨在传输数据,而不是显示数据。这是W3C的推荐。可扩展标记语言(XML)是一种标记语言,它定义了一组规则,用于以人类可读和机器可读的格式编码文档。XML的设计目标侧重于Internet上的简单性,通用性和可用性。它是一种文本数据格式,通过Unicode为不同的人类语言提供强大的支持。尽管XML的设计侧重于文档,但该语言被广泛用于表示任意数据结构,
JSON和XML之间的区别
1、JSON是JavaScript Object Notation;XML是可扩展标记语言。
2、JSON是基于JavaScript语言;XML源自SGML。
3、JSON是一种表示对象的方式;XML是一种标记语言,使用标记结构来表示数据项。
4、JSON不提供对命名空间的任何支持;XML支持名称空间。
5、JSON支持数组;XML不支持数组。
6、XML的文件相对难以阅读和解释;与XML相比,JSON的文件非常易于阅读。
7、JSON不使用结束标记;XML有开始和结束标签。
8、JSON的安全性较低;XML比JSON更安全。
9、JSON不支持注释;XML支持注释。
10、JSON仅支持UTF-8编码;XML支持各种编码。
面试官:什么是事件代理
基本概念
事件委托,会把一个或者一组元素的事件委托到它的父层或者更外层元素上,真正绑定事件的是外层元素,而不是目标元素
当事件响应到目标元素上时,会通过事件冒泡机制从而触发它的外层元素的绑定事件上,然后在外层元素上去执行函数
事件代理(Event Delegation),又称之为事件委托。是JavaScript中常用绑定事件的常用技巧。顾名思义,“事件代理”即是把原本需要绑定在子元素的响应事件(click、keydown......)委托给父元素,让父元素担当事件监听的职务。事件代理的原理是DOM元素的事件冒泡。
** 事件冒泡**
事件流的都会经过三个阶段: 捕获阶段 -> 目标阶段 -> 冒泡阶段。而事件委托就是在冒泡阶段完成的。
一个事件触发后,会在子元素和父元素之间传播(propagation)。这种传播分成三个阶段
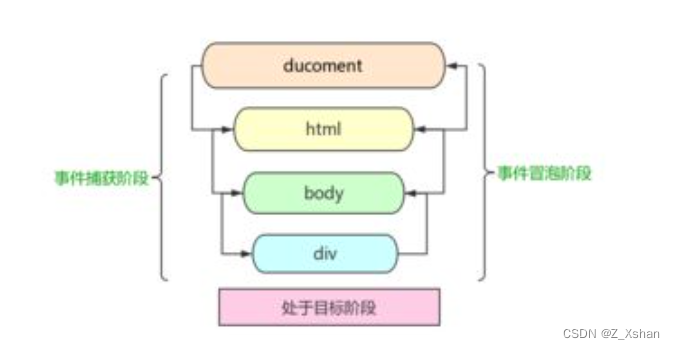
捕获阶段:从window对象传导到目标节点(上层传到底层)称为“捕获阶段”(capture phase),捕获阶段不会响应任何事件;
目标阶段:在目标节点上触发,称为“目标阶段”
冒泡阶段:从目标节点传导回window对象(从底层传回上层),称为“冒泡阶段”(bubbling phase)。事件代理即是利用事件冒泡的机制把里层所需要响应的事件绑定到外层;
事件委托的优点
【1】可以大量节省内存占用,减少事件注册,比如在ul上代理所有li的click事件就非常棒
【2】可以实现当新增子对象时无需再次对其绑定(动态绑定事件)
面试官:谈谈this对象的理解
1,作为一个函数调用(function),直接被调用
在非严格模式下,this指向window
在严格模式下,this指向undefined
2,作为一个方法(method)被调用
当函数作为一个对象的某个属性时,我们更加习惯称呼这个函数为方法
当通过方法被调用时,this指向的是方法的拥有者
let obj={
name:"张三",
show1(){
console.log('show1',this);
},
show2(){
console.log('show2',this);
}
}
let n=obj.show1()
console.log(n);
输出结果:

3.作为一个构造函数(constructor),被实例化
通过构建函数
new
关键字生成一个实例对象,此时
this
指向这个实例对象
function test() {
this.x = 1;
}
var obj = new test();
obj.x // 1
4,通过apply,call,bind方法(上面有)
面试官:new操作符具体干了什么
1,创建了一个空对象


2,将空对象的原型,指向构造函数的原型

返回true
3,将空对象作为构造函数的上下文(改变this指向)


4,对构造函数有返回值的判断
如果构造函数返回一个基本类型的值 则返回结果没有变化
如果返回一个对象 则结果就是你返回的对象
面试官:谈谈你对webpack的理解
1,对webpack的理解
webpack是一个模块化打包JS的工具,在webpack中一切文件都是模块,通过loader转换文件 通过plugin注入钩子,最后输出由多个模块组合而成的文件。
2、什么是bundle?什么是chunk?什么是module?
bundle:是由webpack打包出来的文件
chunk:是一个代码块,一个chunk由多个模块组合而成
module:是开发中的单个模块。
在wenpack中一切都是模块,一个模块对应一个文件,webpack会从配置的entry(入口)中递归开始查找所有模块
3、什么是Loader?什么是Plugin?
Loader:因为webpack本身只理解JavaScript,所以loader用来解析js以外的东西
主要功能:用于告诉webpack如何处理某一类型的文件,并引入到打包出来的文件中
常用Loader:
file-loader:把文件输出到一个文件夹中,在代码中通过相对URL去引用输出的文件
url-loader:和file-loader类似,但是能在文件很小的情况下以base64的方式把文件内容注入到代码中去
source-map-loader:加载额外的Source Map文件,以方便断点调试image-loader:加载并且压缩图片文件
babel-loader:把ES6转换成ES5css-loader:加载CSS,支持模块化、压缩、文件导入等特性
style-loader:把CSS代码注入到JavaScript中,通过DOM操作去加载CSS。
eslint-loader:通过ESLint检查JavaScript代码
Plugin:中文名称 插件,是一个扩展器,丰富webpack本身,增强功能 ,针对的是在loader结束之后,webpack打包的整个过程,他并不直接操作文件,而是基于事件机制工作,监听webpack打包过程中的某些节点,在合适的机会通过webpackt提供的API改变输出结果。常用Plugin:
define-plugin:定义环境变量
commons-chunk-plugin:提取公共代码
uglifyjs-webpack-plugin:通过UglifyES压缩ES6代码
4、webpack的构建流程
Webpack的运行流程是一个串行的过程,从启动到结束会依次执行以下流程:
确定入口:根据配置中的entry找出所有的入口文件;
编译模块:从入口文件开始,调用所有配置的Loader对模块进行编译,再找出该模块的依赖模块,再递归本步骤直到所有的入口文件都经过本步骤的处理;
完成模块编译:在经过Loader翻译完所有模块后,得到了每个模块被翻译后的最终内容以及它们之间的依赖关系;
输出资源:根据入口和模块之间的依赖关系,组装成一个个包含多个模块的Chunk,再把每个Chunk转换成一个单独的文件加入到输出列表,这步是可以修改输出内容的最后机会;
输出完成:在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统。
**5、如何利用webpack来优化前端性能 **
** 其实优化前端性能就是优化webpack的输出结果,让打包之后的最终结果在游览器中快速高效**
1、压缩代码:
** ** 压 缩JS文 件 :可以利用webpack的UglifyJsPlugin和ParallelUglifyPlugin
压缩CSS:利用cssnano(cssloader?minimize)2、利用CDN加速:
** **在构建过程中,将引用的静态资源路径修改为CDN上对应的路径。可以利用webpack对于output参数和各loader的publicPath参数来修改资源路径
3、删除死代码:
** **将代码中永远不会走到的片段删除掉。可以通过在启动webpack时追加参数--optimize-minimize来实现
4、提取公共代码
5、 如何提高webpack的构建速度?
多入口情况下,使用CommonsChunkPlugin来提取公共代码
通过externals配置来提取常用库
利用DllPlugin和DllReferencePlugin预编译资源模块 通过DllPlugin来对那些我们引用但是绝对不会修改的npm包来进行预编译,再通过DllReferencePlugin将预编译的模块加载进来。
使用Happypack实现多线程加速编译
使用webpack-uglify-parallel来 提 升uglifyPlugin的 压 缩 速 度 。原 理 上webpack-uglify-parallel采用了多核并行压缩来提升压缩速度
使用Tree-shaking和Scope Hoisting来剔除多余代码
面试官:说说你对promise的了解
Promise 是异步编程的一种解决方案,其实是一个构造函数,自己身上有all、reject、resolve这几个方法,原型上有then、catch等方法。
Promise
对象有以下两个特点
1)对象的状态不受外界影响。Promise对象代表一个异步操作,有三种状态:pending(进行中)、fulfilled(已成功)和rejected(已失败)。只有异步操作的结果,可以决定当前是哪一种状态,任何其他操作都无法改变这个状态。这也是Promise这个名字的由来,它的英语意思就是“承诺”,表示其他手段无法改变。
(2)一旦状态改变,就不会再变,任何时候都可以得到这个结果。Promise对象的状态改变,只有两种可能:从pending变为fulfilled和从pending变为rejected。只要这两种情况发生,状态就凝固了,不会再变了,会一直保持这个结果,这时就称为 resolved(已定型)。如果改变已经发生了,你再对Promise对象添加回调函数,也会立即得到这个结果。这与事件(Event)完全不同,事件的特点是,如果你错过了它,再去监听,是得不到结果的。
** resolve是什么**
当我们在excutor函数中调用resolve方法时,Promise的状态就变成fulfilled,即操作成功状态,
简单的理解就是调用resolve方法,Promise变为操作成功状态(fulfilled),执行then方法里面onfulfilled里的操作。
reject是什么
就是调用reject方法后,Promise状态变为rejected,即操作失败状态,此时执行then方法里面onrejected操作,上面我们提到了then方法有两个参数,一种是Promise状态为fulfilled时执行(onfullfilled),一种是Promise状态为rejected时执行(onrejected)
catch方法
其实跟then方法中的第二个参数一样,就是在Promise状态为rejected时执行,then方法捕捉到Promise的状态为rejected,就执行catch方法里面的操作
和try ..catch 用发很想是用来捕获错误的
如果抛出异常了(代码出错了),那么并不会报错卡死js,而是会进到这个catch方法中。
all的用法
与then同级的另一个方法,all方法,该方法提供了并行执行异步操作的能力,并且在所有异步操作执行完后并且执行结果都是成功的时候才执行回调。
Promise.all来执行,all接收一个数组参数,这组参数为需要执行异步操作的所有方法,里面的值最终都算返回Promise对象。这样,三个异步操作的并行执行的,等到它们都执行完后才会进到then里面。那么,三个异步操作返回的数据哪里去了呢?都在then里面,all会把所有异步操作的结果放进一个数组中传给then,然后再执行then方法的成功回调将结果接收,
race的用法
all是等所有的异步操作都执行完了再执行then方法,那么race方法就是相反的,谁先执行完成就先执行回调。先执行完的不管是进行了race的成功回调还是失败回调,其余的将不会再进入race的任何回调
Promise.race([p1, p2, p3])里面哪个结果获得的快,就返回哪个结果,不管结果本身是成功状态还是失败状态
面试官:ES6异步操作async函数
async
是异步的意思,
await
则可以理解为
async wait
。所以可以理解
async
就是用来声明一个异步方法,而
await
是用来等待异步方法执行
async
async
函数返回一个
promise
对象
await
正常情况下,
await
命令后面是一个
Promise
对象,返回该对象的结果。如果不是
Promise
对象,就直接返回对应的值 不管
await
后面跟着的是什么,
await
都会阻塞后面的代码
await
会阻塞下面的代码(即加入微任务队列)
面试官:有使用过vue吗?说说你对vue的理解
一、vue是什么
是一个用于创建用户界面的开源JavaScript框架,也是一个创建单页应用的Web应用框架。是一套构建用户界面的 渐进式框架。
二、Vue核心特性
数据驱动(MVVM)
MVVM
表示的是
Model-View-ViewModel
- Model:模型层,负责处理业务逻辑以及和服务器端进行交互
- View:视图层:负责将数据模型转化为UI展示出来,可以简单的理解为HTML页面
- ViewModel:视图模型层,用来连接Model和View,是Model和View之间的通信桥梁
组件化
1.什么是组件化
就是把具有相同功能的功能拿出来,在
Vue
中每一个
.vue
文件都可以视为一个组件
2.组件化的优势
降低整个系统的耦合度,在保持接口不变的情况下,我们可以替换不同的组件快速完成需求,例如输入框,
调试方便,由于整个系统是通过组件组合起来的,在出现问题的时候,可以用排除法直接移除组件,或者根据报错的组件快速定位问题,之所以能够快速定位,是因为每个组件之间低耦合,职责单一,所以逻辑会比分析整个系统要简单
提高可维护性,由于每个组件的职责单一,并且组件在系统中是被复用的,所以对代码进行优化可获得系统的整体升级
面试官:你对SPA单页面的理解,他的缺点是什么,如何实现SPA应用呢
一、什么是SPA
SPA(single-page application),翻译过来就是单页应用。
SPA是一种特殊的web应用。将所有的活动局限于一个Web页面中,仅在该Web页面初始化时加载相应的HTML、JavaScript和CSS。 一旦页面加载完成,SPA不会因为用户的操作而进行页面的重新加载或跳转。取而代之的是利用JavaScript动态的变换HTML的内容, 从而实现UI与用户的交互。
二、SPA和MPA的区别
多页应用MPA(MultiPage-page application),翻译过来就是多页应用在
MPA
中,每个页面都是一个主页面,都是独立的当我们在访问另一个页面的时候,都需要重新加载
html
、
css
、
js
文件,
单页应用优缺点
优点:
- 具有桌面应用的即时性、网站的可移植性和可访问性
- 用户体验好、快,内容的改变不需要重新加载整个页面
- 良好的前后端分离,分工更明确
缺点:
- 不利于搜索引擎的抓取
- 首次渲染速度相对较慢
三、实现一个SPA(vue路由的原理)
原理
- 监听地址栏中
hash变化驱动界面变化 - 用
pushsate记录浏览器的历史,驱动界面发送变化
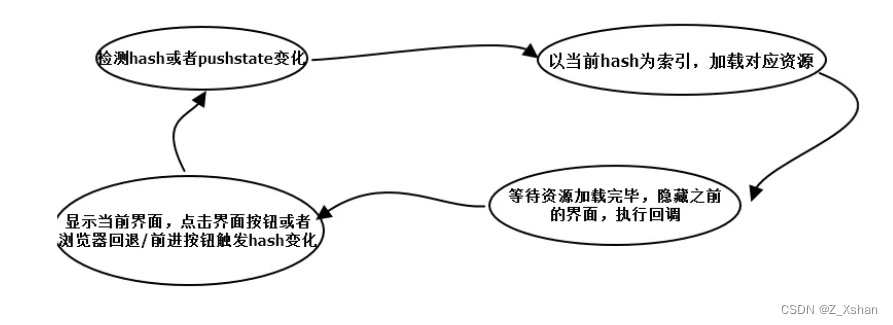
实现
**
hash
模式**
核心通过监听
url
中的
hash
来进行路由跳转
// 定义 Router
class Router {
constructor () {
this.routes = {}; // 存放路由path及callback
this.currentUrl = '';
// 监听路由change调用相对应的路由回调
window.addEventListener('load', this.refresh, false);
window.addEventListener('hashchange', this.refresh, false);
}
route(path, callback){
this.routes[path] = callback;
}
push(path) {
this.routes[path] && this.routes[path]()
}
}
// 使用 router
window.miniRouter = new Router();
miniRouter.route('/', () => console.log('page1'))
miniRouter.route('/page2', () => console.log('page2'))
miniRouter.push('/') // page1
miniRouter.push('/page2') // page2
history模式
history
模式核心借用
HTML5 history api
,
api
提供了丰富的
router
相关属性先了解一个几个相关的api
history.pushState浏览器历史纪录添加记录history.replaceState修改浏览器历史纪录中当前纪录history.popState当history发生变化时触发
// 定义 Router
class Router {
constructor () {
this.routes = {};
this.listerPopState()
}
init(path) {
history.replaceState({path: path}, null, path);
this.routes[path] && this.routes[path]();
}
route(path, callback){
this.routes[path] = callback;
}
push(path) {
history.pushState({path: path}, null, path);
this.routes[path] && this.routes[path]();
}
listerPopState () {
window.addEventListener('popstate' , e => {
const path = e.state && e.state.path;
this.routers[path] && this.routers[path]()
})
}
}
// 使用 Router
window.miniRouter = new Router();
miniRouter.route('/', ()=> console.log('page1'))
miniRouter.route('/page2', ()=> console.log('page2'))
// 跳转
miniRouter.push('/page2') // page2
面试官:Vue 中组件和插件有什么区别?
一、组件是什么?
组件就是把图形、非图形的各种逻辑均抽象为一个统一的概念(组件)来实现开发的模式,在Vue中每一个.vue文件都可以视为一个组件。
组件的优势
降低整个系统的耦合度,在保持接口不变的情况下,我们可以替换不同的组件快速完成需求,例如输入框,可以替换为日历、时间、范围等组件作具体的实现。
调试方便,由于整个系统是通过组件组合起来的,在出现问题的时候,可以用排除法直接移除组件,或者根据报错的组件快速定位问题,之所以能够快速定位,是因为每个组件之间低耦合,职责单一,所以逻辑会比分析整个系统要简单。
提高可维护性,由于每个组件的职责单一,并且组件在系统中是被复用的,所以对代码进行优化可获得系统的整体升级。
二、插件是什么?
插件通常是为了给
Vue
添加全局功能的。插件的功能范围没有严格意义上的限制
这里在总结一下:
组件 (Component) 是用来构成你的App 的业务模块,它的目标是 App.vue
插件(Plugin)是用来增强你的技术栈的功能模块,它的目标是 Vue本身。
简单来说,插件就是指对Vue的功能的增强或补充。
面试官:Real DOM 和 Virtual DOM含义、区别、优缺点
1. Real DOM :(真实的DOM)
在页面渲染出的每个节点都是一个真实的DOM结构,比如:
<div class="root">
<h1>hello Real </h1>
</div>
- Virtual DOM:(虚拟dom,本质是以js对象形式存在的,对DOM的描述)
Virtual DOM 是一个轻量级的js对象,它最初只是real DOM的副本,也是一个节点树,它将元素、它们的属性和内容作为该对象组成部分
Virtual DOM(虚拟dom工作过程有3个步骤):
每当底层数据发生变化时,整个UI都将在虚拟dom中重新渲染;
计算之前虚拟dom与新的虚拟dom之间的差异;
完成计算后,将只用实际更新的内容更新真实的DOM.
区别:
- 虚拟dom不会进行重绘和回流,而真实dom会频繁重排与重绘
- 虚拟dom的总损耗是”虚拟dom的增删改+真实dom的差异增删改+重排“;真实dom的消耗是”真实dom全部增删改+重排“
优缺点
1.真实dom
优点:
1. 直接操作HTML,易用
缺点:
1. 解析速度慢,效率低,内存占用量高
2. 性能差:频繁操作真实DOM,导致重绘、回流
2.虚拟dom
优点:
1. 减少真实dom的频繁更新,减少重绘回流、占用内存少
2. 跨平台:一套react代码可以多端运行
缺点:
1. 页面首次渲染时,由于多一层虚拟dom的计算,速度比正常慢些
面试官:Vue组件之间的通信方式都有哪些?
1,通过 props 传递
- 子组件设置
props属性,定义接收父组件传递过来的参数 - 父组件在使用子组件标签中通过字面量来传递值
2,$emit 触发自定义事件
- 适用场景:子组件传递数据给父组件
- 子组件通过
$emit触发自定义事件,$emit第二个参数为传递的数值 - 父组件绑定监听器获取到子组件传递过来的参数
3,EventBus
- 使用场景:兄弟组件传值
- 创建一个中央事件总线
EventBus - 兄弟组件通过
$emit触发自定义事件,$emit第二个参数为传递的数值 - 另一个兄弟组件通过
$on监听自定义事件
// 创建一个中央时间总线类
class Bus {
constructor() {
this.callbacks = {}; // 存放事件的名字
}
$on(name, fn) {
this.callbacks[name] = this.callbacks[name] || [];
this.callbacks[name].push(fn);
}
$emit(name, args) {
if (this.callbacks[name]) {
this.callbacks[name].forEach((cb) => cb(args));
}
}
}
// main.js
Vue.prototype.$bus = new Bus() // 将$bus挂载到vue实例的原型上
// 另一种方式
Vue.prototype.$bus = new Vue() // Vue已经实现了Bus的功能
Children1.vue
this.$bus.$emit('foo')
Children2.vue
this.$bus.$on('foo', this.handle)
4,provide 与 inject
- 在祖先组件定义
provide属性,返回传递的值 - 在后代组件通过
inject接收组件传递过来的值
父组件中
provide('color',color)
子组件中
let txt = inject("txt");
5,
vuex
- 适用场景: 复杂关系的组件数据传递
Vuex作用相当于一个用来存储共享变量的容器

state用来存放共享变量的地方getter,可以增加一个getter派生状态,(相当于store中的计算属性),用来获得共享变量的值mutations用来存放修改state的方法。actions也是用来存放修改state的方法,不过action是在mutations的基础上进行。常用来做一些异步操作
面试官:vue3的设计目标是什么?做了那些优化
**
Vue3
之前我们或许会面临的问题**
- 随着功能的增长,复杂组件的代码变得越来越难以维护
- 缺少一种在多个组件之间提取和复用逻辑的机制
- 类型推断不够友好
bundle的时间太久了
vue3做出了那些改变
更小
Vue3
移除一些不常用的
API
引入
tree-shaking
,可以将无用模块“剪辑”,仅打包需要的,使打包的整体体积变小了
更快
主要体现在编译方面:
- diff算法优化
- 静态提升
- 事件监听缓存
- SSR优化
更友好
vue3
在兼顾
vue2
的
options API
的同时还推出了
composition API
,大大增加了代码的逻辑组织和代码复用能力
优化方案
vue3
从很多层面都做了优化,可以分成三个方面:
- 源码
- 性能
- 语法 API
源码
源码可以从两个层面展开:
- 源码管理
vue3
整个源码是通过
monorepo
的方式维护的,根据功能将不同的模块拆分到
packages
目录下面不同的子目录中
- TypeScript
Vue3
是基于
typeScript
编写的,提供了更好的类型检查,能支持复杂的类型推导
性能
vue3
是从什么哪些方面对性能进行进一步优化呢?
- 体积优化
- 编译优化
- 数据劫持优化
这里讲述数据劫持:
在
vue2
中,数据劫持是通过
Object.defineProperty
,这个 API 有一些缺陷,并不能检测对象属性的添加和删除
尽管
Vue
为了解决这个问题提供了
set
和
delete
实例方法,但是对于用户来说,还是增加了一定的心智负担
同时在面对嵌套层级比较深的情况下,就存在性能问题
相比之下,
vue3
是通过
proxy
监听整个对象,那么对于删除还是监听当然也能监听到
同时
Proxy
并不能监听到内部深层次的对象变化,而
Vue3
的处理方式是在
getter
中去递归响应式,这样的好处是真正访问到的内部对象才会变成响应式,而不是无脑递归
语法 API (Composition Api 与Options Api 的不同)
这里当然说的就是
composition API
,其两大显著的优化:
- 优化逻辑组织
相同功能的代码编写在一块,而不像
options API
那样,各个功能的代码混成一块
- 优化逻辑复用
在
vue2
中,我们是通过
mixin
实现功能混合,如果多个
mixin
混合,会存在两个非常明显的问题:命名冲突和数据来源不清晰
而通过
composition
这种形式,可以将一些复用的代码抽离出来作为一个函数,只要的使用的地方直接进行调用即可
面试官:说一下数据响应式的原理

在我们创建vue实例的时候,会传入el和data,将data传到Observer中做数据劫持,利用Object.definproperty将data里数据转化成getter/setter,data里的每个属性都有自己的dep(依赖收集对象)用来保存watcher实例。而el则传入compile,在compile里进行指令的解释,当解析到el中使用到data里的数据会触发我们的getter,从而将我们的watcher添加到依赖当中。当数据发生改变的时候会触发我们的setter发出依赖通知,通知watcher,watcher接受到通知后去向view发出通知,让view去更新
面试官:说说对React的理解?有哪些特性?
一、是什么
React,用于构建用户界面的 JavaScript 库,只提供了 UI 层面的解决方案
遵循组件设计模式、声明式编程范式和函数式编程概念,以使前端应用程序更高效
使用虚拟
DOM
来有效地操作
DOM
,遵循从高阶组件到低阶组件的单向数据流
帮助我们将界面成了各个独立的小块,每一个块就是组件,这些组件之间可以组合、嵌套,构成整体页面
react
类组件使用一个名为
render()
的方法或者函数组件
return
,接收输入的数据并返回需要展示的内容
二、特性
React
特性有很多,如:
- JSX 语法
- 单向数据绑定
- 虚拟 DOM
- 声明式编程
- Component
着重介绍下声明式编程及 Component
声明式编程
声明式编程是一种编程范式,它关注的是你要做什么,而不是如何做
它表达逻辑而不显式地定义步骤。这意味着我们需要根据逻辑的计算来声明要显示的组件
Component
在
React
中,一切皆为组件。通常将应用程序的整个逻辑分解为小的单个部分。 我们将每个单独的部分称为组件
组件可以是一个函数或者是一个类,接受数据输入,处理它并返回在
UI
中呈现的
React
元素
一个组件该有的特点如下:
- 可组合:每个组件易于和其它组件一起使用,或者嵌套在另一个组件内部
- 可重用:每个组件都是具有独立功能的,它可以被使用在多个 UI 场景
- 可维护:每个小的组件仅仅包含自身的逻辑,更容易被理解和维护
三、优势
通过上面的初步了解,可以感受到
React
存在的优势:
- 高效灵活
- 声明式的设计,简单使用
- 组件式开发,提高代码复用率
- 单向响应的数据流会比双向绑定的更安全,速度更快
面试官:说说React什么周期有那些不同阶段?每个阶段对应的方法是?
挂载阶段:
- constructor() 在 React 组件挂载之前,会调用它的构造函数。
- componentWillMount: 在调用 render 方法之前调用,并且在初始挂载及后续更新时都会被调用。
- componentDidMount(): 在组件挂载后(插入 DOM 树中)立即调用
更新运行阶段:
- componentWillReceiveProps: 在接受父组件改变后的props需要重新渲染组件时用到的比较多,外部组件传递频繁的时候会导致效率比较低
- shouldComponentUpdate():用于控制组件重新渲染的生命周期,state发生变化,组件会进入重新渲染的流程,在这里return false可以阻止组件的更新
- render(): render() 方法是 class 组件中唯一必须实现的方法。
- *componentWillUpdate()**: shouldComponentUpdate返回true以后,组件进入重新渲染完成之前进入这个函数。
- componentDidUpdate(): 每次state改变并重新渲染页面后都会进入这个生命周期 卸载或销毁阶段**componentWillUnmount ()**: 在此处完成组件的卸载和数据的销毁。
React旧生命周期有哪些问题?
(1) componentWillMount ,在ssr中 这个方法将会被多次调用, 所以会重复触发多遍,同时在这里如果绑定事件,
将无法解绑,导致内存泄漏 , 变得不够安全高效逐步废弃。
(2) componentWillReceiveProps 外部组件多次频繁更新传入多次不同的 props,会导致不必要的异步请求
(3) componetWillupdate, 更新前记录 DOM 状态, 可能会做一些处理,与componentDidUpdate相隔时间如果过长, 会导致 状态不太信
** React新生命周期有哪些改变?**
- 用 getDerivedStateFromProps替换了 compoentWillMount和compontWillReceiveProps生命周期函数
- 用getSnapshotBeforeUpdate函数替换componetWillUpdate方法,避免和CompoentDidUpdate函数中获取数据不一致的问题
面试官:说说 React中的setState执行机制
一个组件的显示形态可以由数据状态和外部参数所决定,而数据状态就是state, 当需要修改里面的值的状态需要通过调用setState来改变,从而达到更新组件内部数据的作用
setState第一个参数可以是一个对象,或者是一个函数,而第二个参数是一个回调函数,用于可以实时的获取到更新之后的数据
在使用setState更新数据的时候,setState的更新类型分成:同步更新,异步更新
在组件生命周期或React合成事件中,setState是异步
在setTimeout或者原生dom事件中,setState是同步
对同一个值进行多次 setState, setState 的批量更新策略会对其进行覆盖,取最后一次的执行结果
面试官:说说你对Redux的理解?其工作原理?
什么是Redux
在react中每个组件的state是由自身进行管理,包括组件定义自身的state、组件之间的通信通过props传递、使用Context实现数据共享等,如果让每个组件都存储自身相关的状态,理论上来讲不会影响应用的运行,但在开发及后期我们将比较难以维护,所以我们可以把数据进行集中式的管理,redux就是一个实现上述集中管理的容器的工具,
redux并不是只应用在
react中,还与其他界面库一起使用,如
Vue
Redux的三大原则
- state数据必须是单一数据源
- redux中的state数据必须 是只读的,只能通过dispatch调用actions修改
- Reducer必须使用纯函数来执行修改
redux的执行原理
React的组件需要获取或者修改页面的数据,通过dispatch方法调用actions进入到Reducer函数中修改state的数据内容,state更新后,通知组件更新页面即可。
redux的使用步骤
- 创建一个store文件夹,新建一个index.js文件
- 文件中导入redux的createStore方法,用于创建公共数据区域
- 创建一个reducer纯函数,接受两个参数state,actions分别表示分别表示数据和操作state的方法,返回state数据给组件页面
- 把reducer作为createStore的参数抛出
- 在需要使用的页面导入store文件,通过store.getState获取数据,通过store.dispatch触发action修改state数据
- store.subscrible 方法监听 store 的改变,避免数据不更新
面试官:说说对React中类组件和函数组件的理解?有什么区别?
一、类组件
类组件,顾名思义,也就是通过使用
ES6
类的编写形式去编写组件,该类必须继承
React.Component
如果想要访问父组件传递过来的参数,可通过
this.props
的方式去访问
在组件中必须实现
render
方法,在
return
中返回
React
对象
二、函数组件
函数组件,顾名思义,就是通过函数编写的形式去实现一个
React
组件,是
React
中定义组件最简单的方式
函数第一个参数为
props
用于接收父组件传递过来的参数
三、区别
针对两种
React
组件,其区别主要分成以下几大方向:
- 编写形式
函数组件:
function Welcome(props) {
return <h1>Hello, {props.name}</h1>;
}
类组件:
class Welcome extends React.Component {
constructor(props) {
super(props)
}
render() {
return <h1>Hello, {this.props.name}</h1>
}
}
- 状态管理
在
hooks
出来之前,函数组件就是无状态组件,不能保管组件的状态,不像类组件中调用
setState
如果想要管理
state
状态,可以使用
useState
const FunctionalComponent = () => {
const [count, setCount] = React.useState(0);
return (
<div>
<p>count: {count}</p>
<button onClick={() => setCount(count + 1)}>Click</button>
</div>
);
};
在使用
hooks
情况下,一般如果函数组件调用
state
,则需要创建一个类组件或者
state
提升到你的父组件中,然后通过
props
对象传递到子组件
- 生命周期
- 调用方式
- 获取渲染的值
生命周期
在函数组件中,并不存在生命周期,这是因为这些生命周期钩子都来自于继承的
React.Component
所以,如果用到生命周期,就只能使用类组件
但是函数组件使用
useEffect
也能够完成替代生命周期的作用,
调用方式
如果是一个函数组件,调用则是执行函数即可
// 你的代码
function SayHi() {
return <p>Hello, React</p>
}
// React内部
const result = SayHi(props) // » <p>Hello, React</p>
如果是一个类组件,则需要将组件进行实例化,然后调用实例对象的
render
方法:
// 你的代码
class SayHi extends React.Component {
render() {
return <p>Hello, React</p>
}
}
// React内部
const instance = new SayHi(props) // » SayHi {}
const result = instance.render() // » <p>Hello, React</p>
获取渲染的值
函数组件对应如下:
function ProfilePage(props) {
const showMessage = () => {
alert('Followed ' + props.user);
}
const handleClick = () => {
setTimeout(showMessage, 3000);
}
return (
<button onClick={handleClick}>Follow</button>
)
类组件对应如下:
class ProfilePage extends React.Component {
showMessage() {
alert('Followed ' + this.props.user);
}
handleClick() {
setTimeout(this.showMessage.bind(this), 3000);
}
render() {
return <button onClick={this.handleClick.bind(this)}>Follow</button>
}
小结
函数组件语法更短、更简单,这使得它更容易开发、理解和测试
而类组件也会因大量使用
this
而让人感到困惑
面试官:说说对React Hooks的理解?解决了什么问题?
一、是什么
Hook是 React 16.8 的新增特性。它可以让你在不编写
class的情况下使用
state以及其他的
React特性
至于为什么引入
hook,官方给出的动机是解决长时间使用和维护
react过程中常遇到的问题,例如:
- 难以重用和共享组件中的与状态相关的逻辑
- 逻辑复杂的组件难以开发与维护,当我们的组件需要处理多个互不相关的 local state 时,每个生命周期函数中可能会包含着各种互不相关的逻辑在里面
- 类组件中的this增加学习成本,类组件在基于现有工具的优化上存在些许问题
- 由于业务变动,函数组件不得不改为类组件等等
在以前,函数组件也被称为无状态的组件,只负责渲染的一些工作
因此,现在的函数组件也可以是有状态的组件,内部也可以维护自身的状态以及做一些逻辑方面的处理
二、有哪些
最常见的
hooks
有如下:
- useState
import React, { useState } from 'react';
function Example() {
// 声明一个叫 "count" 的 state 变量
const [count, setCount] = useState(0);
return (
<div>
<p>You clicked {count} times</p >
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}
在函数组件中通过
useState
实现函数内部维护
state
,参数为
state
默认的值,返回值是一个数组,第一个值为当前的
state
,第二个值为更新
state
的函数
- useEffect
useEffect
第一个参数接受一个回调函数,默认情况下,
useEffect
会在第一次渲染和更新之后都会执行,相当于在
componentDidMount
和
componentDidUpdate
两个生命周期函数中执行回调
如果某些特定值在两次重渲染之间没有发生变化,你可以跳过对 effect 的调用,这时候只需要传入第二个参数
dom更新之后调用
useEffect(() => {
document.title = `You clicked ${count} times`;
}, [count]); // 仅在 count 更改时更新
其它 hooks
- useReducer
和redux类似用法一样相当于一个仓库 但是不能替代redux
import React, { useReducer } from 'react'
import { useState } from 'react'
const initialState={
num:0
}
let reducer=(state,action)=>{
//通过state对 initialState数据修改 通过action对传来的数据进行接受
switch (action.type){
case 'increment':
return {'one':state.num+action.one}
default:
return state
}
}
const Goods = () => {
//两个参数第一个是接受的值 第二个是要传递的值 useReducer里的两个
//参数第一个是一个函数第二个相当于仓库要存储的信息
let [state,dispatch]=useReducer(reducer,initialState)
return (
<div>
zhi--->
{state.one}
{/* */}
<button onClick={()=>dispatch({type:'increment',one:5})} >num++</button>
</div>
)
}
export default Goods
- useCallback
如果在父组件触发方法的时候没有给子组件修改值但是子组件重新渲染了 我们可以用memo对其子组件进行包裹,但是如果你传的是一个方法给子组件 虽然你没触发这个方法 但是他的memo也会失效 所以我们需要用useCallback代码如下、
import React, { memo, useCallback } from 'react'
import { useState } from 'react'
const Ren=memo(
(props)=>{
console.log('触发子组件')
return(
<div>
{props.name}
<h2 style={{backgroundColor:'red'}}>子组件的内容</h2>
</div>
)
}
)
function Goods() {
let [num,setnum]=useState(0)
let [num1,setnum1]=useState(0)
let [name,setname]=useState('李四')
const one=()=>{
setnum(num+1)
}
const setval=useCallback(
()=>{
console.log('123')
// setname('李思路是')
},[name]
)
return (
<div>
num--->{num}
<button onClick={one.bind(this)}>num++</button>
<button onClick={setval.bind(this)}>修改命子</button>
<Ren num1={setval}></Ren>
</div>
)
}
export default Goods
- useMemo
useMemo是在渲染前执行 相当于计算属性 需要returen 返回数据 第二个参数用来监听数据的变话
- useRef
useRef 跟 createRef 类似,都可以用来生成对 DOM 对象的引用,
import React from 'react'
import { useRef } from 'react';
const Goods = () => {
let nameRef=useRef();
const btn=()=>{
console.log(nameRef.current.value,'in[p')
}
return (
<div>
<input ref={nameRef} type="text" />
<button onClick={btn.bind(this)}></button>
</div>
)
}
export default Goods
- useContext
就是可是实现跨组件传值较少层级嵌套 代码如下:
import React, { memo, useCallback } from 'react'
import { useContext } from 'react';
//引入createContext
const colorContext = React.createContext();
function Bar() {
const color = useContext(colorContext);
return <div>bar-->{color}</div>;
}
function Foo() {
//在子组件内通过 useContext 进行接受父组件传的值
const color = useContext(colorContext);
return (
<div>
{color}
<Bar/>
</div>
)
}
function Goods() {
return (
//用colorContext.Provider 包裹住子组件 value进行传值
<colorContext.Provider value={"red"}>
<Foo />
</colorContext.Provider>
);
}
export default Goods
三、解决什么
- 每调用useHook一次都会生成一份独立的状态
- 通过自定义hook能够更好的封装我们的功能
编写
hooks
为函数式编程,每个功能都包裹在函数中,整体风格更清爽,更优雅
hooks
的出现,使函数组件的功能得到了扩充,拥有了类组件相似的功能,在我们日常使用中,使用
hooks
能够解决大多数问题,并且还拥有代码复用机制,因此优先考虑
hooks
面试官:说说 React 性能优化的手段有哪些?
React
凭借
virtual DOM
和
diff
算法拥有高效的性能,但是某些情况下,性能明显可以进一步提高
在前面文章中,我们了解到类组件通过调用
setState
方法, 就会导致
render
,父组件一旦发生
render
渲染,子组件一定也会执行
render
渲染
当我们想要更新一个子组件的时候 理想状态只调用该路径下的组件
render
:但是
react
的默认做法是调用所有组件的
render
,再对生成的虚拟
DOM
进行对比如不变则不进行更新
如何做
避免使用内联函数
如果我们使用内联函数,则每次调用
render
函数时都会创建一个新的函数实例
import React from "react";
export default class InlineFunctionComponent extends React.Component {
render() {
return (
<div>
<h1>Welcome Guest</h1>
<input type="button" onClick={(e) => { this.setState({inputValue: e.target.value}) }} value="Click For Inline Function" />
</div>
)
}
我们应该在组件内部创建一个函数,并将事件绑定到该函数本身。这样每次调用
render
时就不会创建单独的函数实例
import React from "react";
export default class InlineFunctionComponent extends React.Component {
setNewStateData = (event) => {
this.setState({
inputValue: e.target.value
})
}
render() {
return (
<div>
<h1>Welcome Guest</h1>
<input type="button" onClick={this.setNewStateData} value="Click For Inline Function" />
</div>
)
}
}
使用 React Fragments 避免额外标记
用户创建新组件时,每个组件应具有单个父标签。父级不能有两个标签,所以顶部要有一个公共标签,所以我们经常在组件顶部添加额外标签
div
这个额外标签除了充当父标签之外,并没有其他作用,这时候则可以使用
fragement
其不会向组件引入任何额外标记,但它可以作为父级标签的作用
export default class NestedRoutingComponent extends React.Component {
render() {
return (
<>
<h1>This is the Header Component</h1>
<h2>Welcome To Demo Page</h2>
</>
)
}
}
React.Fragment 组件能够在不额外创建 DOM 元素的情况下,让 render() 方法中返回多个元素。
<React.Fragment> 与 <>区别
<></>(简写语法) 语法不能接受键值或属性,<React.Fragment>可以。
注意:简写形式<></>,但目前有些前端工具支持的还不太好,用 create-react-app 创建的项目可能就不能通过编译。所以遇到这种情况很正常。
**事件绑定方式 **
从性能方面考虑,在
render
方法中使用
bind
和
render
方法中使用箭头函数这两种形式在每次组件
render
的时候都会生成新的方法实例,性能欠缺
而
constructor
中
bind
事件与定义阶段使用箭头函数绑定这两种形式只会生成一个方法实例,性能方面会有所改善
懒加载组件
从工程方面考虑,
webpack
存在代码拆分能力,可以为应用创建多个包,并在运行时动态加载,减少初始包的大小
而在
react
中使用到了
Suspense
和
lazy
组件实现代码拆分功能
服务端渲染
采用服务端渲染端方式,可以使用户更快的看到渲染完成的页面
服务端渲染,需要起一个
node
服务,可以使用
express
、
koa
等,调用
react
的
renderToString
方法,将根组件渲染成字符串,再输出到响应中
其他
除此之外,还存在的优化手段有组件拆分、合理使用
hooks
等性能优化手段...
总结
通过上面初步学习,我们了解到
react
常见的性能优化可以分成三个层面:
- 代码层面
- 工程层面
- 框架机制层面
通过这三个层面的优化结合,能够使基于
react
项目的性能更上一层楼
面试官: Vue\React\Angular的区别
1. 基本概念
Angular 是一个应用设计框架与开发平台,用于创建高效、复杂、精致的单页面应用。
React 是一个用于构建用户界面的 JavaScript 库
Vue是一套用于构建用户界面的渐进式框架。其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用。Vue 的核心库只关注视图层,不仅易于上手,还便于与第三方库或既有项目整合
2. 三者比较
相同点
都是基于javascript/typescript的前端开发库,为前端开发提供高效、复用性高的开发方式
都有组件和模板的开发思想
各自的组件都有生命周期,不用的组件可以卸载,不占用资源
都支持指令,如样式、事件等的指令
不同点
1. 创始和发行不同:
** Angular是由googl提供支持的,初始发行于 2016年9月;React由Facebook维护,初始发行于 2013年3月;Vue**是由前google人员创建,初始发行于2014年2月
2. 应用类型不同:
Angular支持开发native应用程序、SPA单页应用程序、混合应用程序和web应用程序;React支持开发SPA和移动应用程序;Vue支持开发高级SPA,开始支持native应用程序
3. 模型不同
angular基于MVC(模型-视图-控制器)架构;react和vue是基于Virtual DOM(虚拟的文档对象模型)
4. 数据流流向不同
Angular使用的是双向数据绑定,React用的是单数据流的,而Vue则支持两者。
5. 组件之间传值方式不同
Angular 中直接的父子组件,父组件可以直接访问子组件的 public 属性和方法,也可以借助于@Input 和 @Output 进行通讯。没有直接关系的,借助于 Service 单例进行通讯;React 组件之间通过通过prop或者state来通信,不同组件之间还有Rex状态管理功能;Vue组件之间通信通过props ,以及Vuex状态管理来传值
面试官:说说你对 TypeScript 的理解?与 JavaScript 的区别?
一、是什么
**
TypeScript
是
JavaScript
的类型的超集,支持
ES6
语法,支持面向对象编程的概念,其是一种静态类型检查的语言,提供了类型注解,在代码编译阶段就可以检查出数据类型的错误,TypeScript在编译阶段需要编译成JavaScript来运行**
二、特性
- 类型批注和编译时类型检查 :在编译时批注变量类型
- 类型推断:ts 中没有批注变量类型会自动推断变量的类型
- 类型擦除:在编译过程中批注的内容和接口会在运行时利用工具擦除
- 接口:ts 中用接口来定义对象类型
- 枚举:用于取值被限定在一定范围内的场景
- Mixin:可以接受任意类型的值
- 泛型编程:写代码时使用一些以后才指定的类型
- 名字空间:名字只在该区域内有效,其他区域可重复使用该名字而不冲突
- 元组:元组合并了不同类型的对象,相当于一个可以装不同类型数据的数组
**类型批注 **
通过类型批注提供在编译时启动类型检查的静态类型
类型推断
当类型没有给出时,TypeScript 编译器利用类型推断来推断类型
接口
接口简单来说就是用来描述对象的类型 数据的类型有
number
、
null
、
string
等数据格式,对象的类型就是用接口来描述的
面试官:说说你对 TypeScript 中泛型的理解?应用场景?
一、是什么
泛型程序设计(generic programming)是程序设计语言的一种风格或范式
泛型允许我们在强类型程序设计语言中编写代码时使用一些以后才指定的类型,在实例化时作为参数指明这些类型 在
typescript
中,定义函数,接口或者类的时候,不预先定义好具体的类型,而在使用的时候在指定类型的一种特性
虽然可以使用
any
类型去替代,但这也并不是很好的方案,因为我们的目的是接收什么类型的参数返回什么类型的参数,即在运行时传入参数我们才能确定类型
这种情况就可以使用泛型
function returnItem<T>(para: T): T {
return para
}
泛型给予开发者创造灵活、可重用代码的能力
使用方式
- 函数
- 接口
- 类
函数声明
函数
function returnItem<T>(para: T): T {
return para
}
定义泛型的时候,可以一次定义多个类型参数,比如我们可以同时定义泛型
T
和 泛型
U
:
function swap<T, U>(tuple: [T, U]): [U, T] {
return [tuple[1], tuple[0]];
}
swap([7, 'seven']); // ['seven', 7]
接口声明
声明接口的形式如下
interface ReturnItemFn<T> {
(para: T): T
}
那么当我们想传入一个number作为参数的时候,就可以这样声明函数:
const returnItem: ReturnItemFn<number> = para => para
** 类声明**
使用泛型声明类的时候,既可以作用于类本身,也可以作用与类的成员函数
下面简单实现一个元素同类型的栈结构,如下所示:
class Stack<T> {
private arr: T[] = []
public push(item: T) {
this.arr.push(item)
}
public pop() {
this.arr.pop()
}
}
使用方式如下:
const stack = new Stacn<number>()
1如果上述只能传递
string
和
number
类型,这时候就可以使用
<T extends xx>
的方式猜实现约束泛型,如下所示:
除了上述的形式,泛型更高级的使用如下:
例如要设计一个函数,这个函数接受两个参数,一个参数为对象,另一个参数为对象上的属性,我们通过这两个参数返回这个属性的值
这时候就设计到泛型的索引类型和约束类型共同实现
索引类型、约束类型
索引类型
keyof T
把传入的对象的属性类型取出生成一个联合类型,这里的泛型 U 被约束在这个联合类型中,如下所示:
function getValue<T extends object, U extends keyof T>(obj: T, key: U) {
return obj[key] // ok
}
上述为什么需要使用泛型约束,而不是直接定义第一个参数为
object
类型,是因为默认情况
object
指的是
{}
,而我们接收的对象是各种各样的,一个泛型来表示传入的对象类型,比如
T extends object
使用如下图所示:
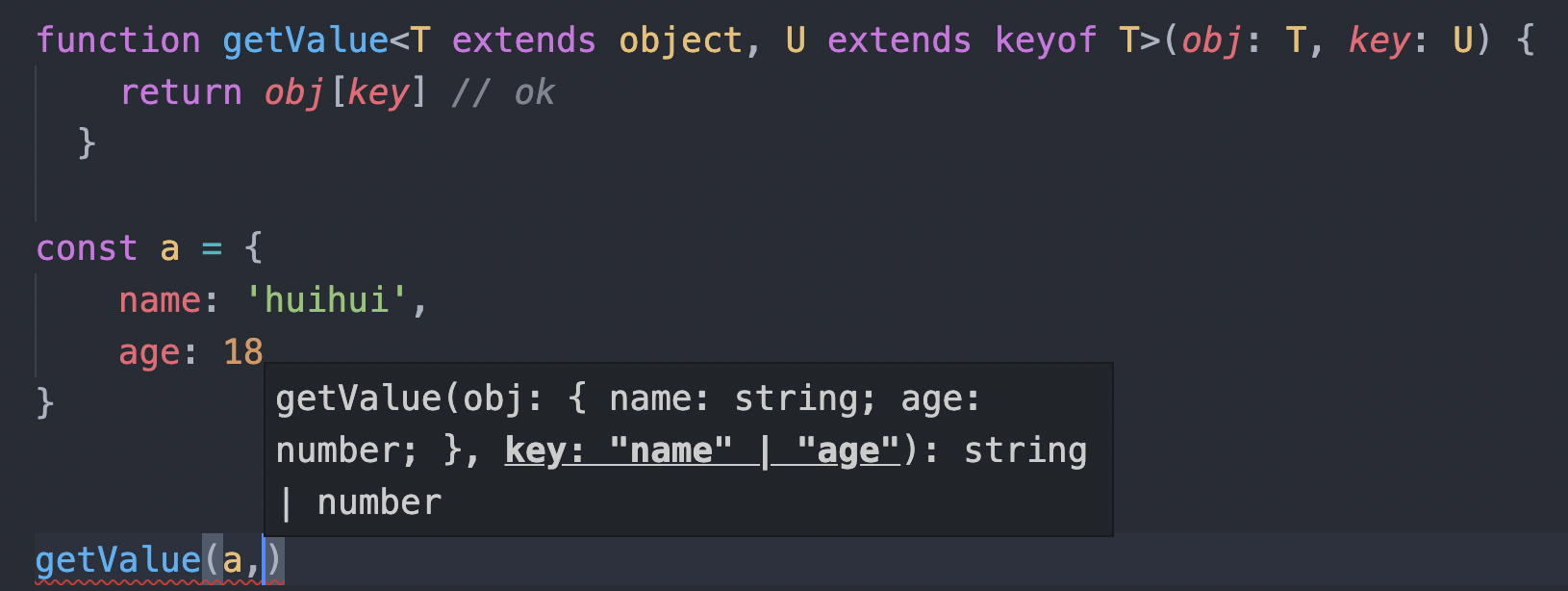
#多类型约束
例如如下需要实现两个接口的类型约束:
interface FirstInterface {
doSomething(): number
}
interface SecondInterface {
doSomethingElse(): string
}
可以创建一个接口继承上述两个接口,如下:
interface ChildInterface extends FirstInterface, SecondInterface {
}
正确使用如下:
class Demo<T extends ChildInterface> {
private genericProperty: T
constructor(genericProperty: T) {
this.genericProperty = genericProperty
}
useT() {
this.genericProperty.doSomething()
this.genericProperty.doSomethingElse()
}
}
通过泛型约束就可以达到多类型约束的目的
面试官:说说你对微信小程序的理解?优缺点?
一、是什么
截至目前,小程序已经成为国内前端的一个重要业务,**跟
Web
和手机
App
有着同等的重要性**
小程序是一种不需要下载安装即可使用的应用,它实现了应用“触手可及”的梦想,用户扫一扫或者搜一下即可打开应用
也体现了“用完即走”的理念,用户不用关心是否安装太多应用的问题。应用将无处不在,随时可用,但又无需安装卸载
二、背景
⼩程序并⾮凭空冒出来的⼀个概念,当微信中的
WebView
逐渐成为移动
Web
的⼀个重要⼊⼝时,微信就有相关的
JS-SDK
JS-SDK
解决了移动⽹⻚能⼒不⾜的问题,通过暴露微信的接⼝使得
Web
开发者能够拥有更多的能⼒,然⽽在更多的能⼒之外,
JS-SDK
的模式并没有解决使⽤移动⽹⻚遇到的体验不良的问题
因此需要设计⼀个⽐较好的系统,使得所有开发者在微信中都能获得⽐较好的体验:
- 快速的加载
- 更强⼤的能⼒
- 原⽣的体验
- 易⽤且安全的微信数据开放
- ⾼效和简单的开发
这些是
JS-SDK
做不到的,需要设计一个全新的小程序系统
对于小程序的开发,提供一个简单、高效的应用开发框架和丰富的组件及
API
,帮助开发者开发出具有原生体验的服务
其中相比
H5
,小程序与其的区别有如下:
- 运⾏环境:⼩程序基于浏览器内核重构的内置解析器
- 系统权限:⼩程序能获得更多的系统权限,如⽹络通信状态、数据缓存能⼒等
- 渲染机制:⼩程序的逻辑层和渲染层是分开的
小程序可以视为只能用微信打开和浏览的
H5
,小程序和网页的技术模型是一样的,用到的
JavaScript
语言和
CSS
样式也是一样的,只是网页的
HTML
标签被稍微修改成了
WXML
标签
因此可以说,小程序页面本质上就是网页
三、优缺点
优点:
- 随搜随用,用完即走:使得小程序可以代替许多APP,或是做APP的整体嫁接,或是作为阉割版功能的承载体
- 流量大,易接受:小程序借助自身平台更加容易引入更多的流量
- 安全
- 开发门槛低
- 降低兼容性限制
缺点:
- 用户留存:及相关数据显示,小程序的平均次日留存在13%左右,但是双周留存骤降到仅有1%
- 体积限制:微信小程序只有2M的大小,这样导致无法开发大型一些的小程序
- 受控微信:比起APP,尤其是安卓版的高自由度,小程序要面对很多来自微信的限制,从功能接口,甚至到类别内容,都要接受微信的管控
面试官:SPA首屏加载速度慢的怎么解决?
常见的几种SPA首屏优化方式
- 减小入口文件积
- 静态资源本地缓存
- UI框架按需加载
- 图片资源的压缩
- 组件重复打包
- 开启GZip压缩
- 使用SSR
面试官:为什么虚拟 dom 会提高性能?
虚拟 dom 相当于在 js 和真实 dom 中间加了一个缓存,利用 dom diff 算法避免了没有必要的 dom 操作,从而提高性能。
用Js对象表示真实的DOM结构,当状态变化的时候在重新创建一个虚拟DOM树结构,然后用新的树和旧的树进行比较,记录两棵树差异,把所记录的差异应用到所构建的真正的 DOM 树上,视图就更新了。
面试官:什么是JSX?
jsx是JavaScript的一种语法扩展,它跟模板语言很接近,但是它充分具备JavaScript的能力
JSX就是用来声明React当中的元素,React使用JSX来描述用户界面
JSX语法糖允许前端开发者使用我们最熟悉的类HTML标签语法来创建虚拟DOM在降低学习成本
面试官:React创建元素的方法?
React.createElement()
面试官:** React 事件绑定的方式**
React 事件绑定属性的命名采用驼峰式写法, 采用 JSX 的语法传入一个函数作为事件处理函数
事件绑定函数的方式
1. 直接写函数名字{callback},
2. 可以使用bind方法绑定调用 {callback.bind(this)}
面试官:事件处理方法this指向改变
当我们把事件函数写成普通函数的形式时 , 调用函数使用state变量会报错,提示state变量不存在,
是因为
- 事件处理程序的函数式函数调用模式,在严格模式下,this指向
undefined - render函数是被组件实例调用的,因此render函数中的this指向当前组件
解决方法: 1. 把普通函数改成箭头函数 2. 调用函数的时候使用bind方法改变this指向
面试官:React事件处理方法传值
- 调用的时候定义一个箭头函数 函数中调用方法传递参数据
<button onClick={()=> this.del(index) }>
点击
</button>
2,第二种方法 bind方法传递参数
<button onClick={this.del.bind(this,index) }>
点击
</button>
面试官:React如何获取表单数据
- 给文本框绑定value属性,value属性绑定state中定义的变量
- 给表单绑定onChange事件,调用定义的方法
- 在方法中我们获取e.target.value属性,赋给value属性绑定的变量
面试官:React条件渲染方法有哪些
- if-else的条件渲染方法
- 三元运算符进行条件渲染,可以缩短代码量
- switch的多条件渲染效果
- HOC条件渲染
面试官:** React怎么实现列表渲染**
react中可以使用map方法渲染列表,return对应的页面结构即可, React 在渲染列表时,会要求开发者为每一个列表元素指定唯一的
key
,我们尽量不要使用index索引值作为key,如果对数据进行:逆序添加、逆序删除等破坏顺序操作:可能会引起页面更新错误问题。
面试官:** React中key的作用是什么?**
key是虚拟DOM对象的唯一标识,在更新显示时key起到极其重要的作用 ,简单的来说就是为了提高diff的同级比较的效率,避免原地复用带来的副作用
react采用的是自顶而下的更新策略,每次小的改动都会生成一个全新的的vdom,从而进行diff,如果不写key,就会发生本来应该更新却没有更新
面试官:** React组件样式的定义方式**
- 外联样式定义css文件,在组件中通过import导入css样式,import "App.css"
- 内联样式React推崇的是内联的方式定义样式。这样做的目的就在于让你的组件更加的容易复用定义一个style属性,属性中定义对应的css样式即可,比如style={{fontSize:'15px'}}外层花括号是语法,内层花括号是对象边界符
面试官:** Props校验数据类型**
array(数组)、bool(布尔值)、func(函数number(数字)、object(对象)、string(字符串)
面试官:** 受控组件和非受控组件**
受控组件
由React控制的输入表单元素而改变其值的方式,称为受控组件。
比如,给表单元素input绑定一个onChange事件,当input状态发生变化时就会触发onChange事件,从而更新组件的state。
非受控组件
非受控组件指的是,表单数据由DOM本身处理。即不受setState()的控制,与传统的HTML表单输入相似,input输入值即显示最新值。
在非受控组件中,可以使用一个ref来从DOM获得表单值。
面试官:** 组件传值的方式?**
父传子组件通信, 子传父组件通信 兄弟组件通信
面试官:** 父传子通信流程**
- 在父组件中的子组件标签上绑定自定义属性,挂载传递的数据
- 子组件中props接受传递的数据,直接使用即可
面试官:** 子传父通信的流程**
- 父组件中子组件标签上绑定一个属性,传递一个方法给子组件
- 子组件中通过props接受这个方法,直接调用,传递相应的参数即可
面试官:** 非父子组件通信**
- 状态提升(中间人模式) React中的状态提升概括来说,就是将多个组件需要共享的状态提升到它们最近的父组件,在父组件上改变这个状态然后通过props分发给子组件
- context状态树传参
面试官:** context状态树是怎么运行的?**
- 在父组件中我们通过createContext() 创建一个空对象,在父组件的最外层我们使用Provider包裹数据,通过value绑定要传递的对象数据。
- 在嵌套的子组件中,我们有两种方式获取数据: (1) 我们可以使用Customer标签,在标签中绑定一个箭头函数,函数的形参context就是value传递的数据 (2). class组件中我们可以定义static contextType=context对象,组件中直接使用this.context获取数据。
面试官:** react的路由几种模式,是什么?**
两种路由模式:
一种是Hash路由模式,用的是HashRouter组件
一种是历史路由模式,用的是BrowserRouter组件绑定
面试官:** react路由常用的组件有哪些?**
HashRouter或BrowserRouter配置路由模式
Route 定义路由组件映射关系
Redirect 设置路由重定向
NavLink 或者Link 页面路由跳转
Switch 路由匹配,当path匹配到一个component之后,将不会再想下继续匹配,提高了程序效率
面试官:** react路由传参的方式有哪些?**
//隐士参数传递
(1) this.props.history.push({ pathname : '/user' ,query : {id:100}})
this.props.location.query.id 获取query传递的参数据,刷新数据不在
(2) this.props.history.push({ pathname:'/user',state:{id: 1000 } }) this.props.location.state.id 获取state的数据,刷新数据还在
- url传参方式 (<Link to="/user?id=100"></Link>) history.location.search获取数据比较麻烦,得自己解析
- 动态路由定义
/detail/:id=>/detail/100=> location.match.params中接受的参数是 {id:100}
面试官:** react路由跳转的方式有哪些?**
声明式导航:
使用NavLink或者Link跳转, to属性后面跟字符串或者跟对象
编程式导航跳转:
props.history.push(url) 跳转页面可以返回上一页,保留历史记录
props.history.replace(url) 跳转页面,清空历史记录
props.history.go(num) 返回第几个页面
面试官:** react路由嵌套如何配置?**
- 配置父组件的路由地址,在父组件中配置子组件的路由映射关系
- 关闭父组件路由配置exact属性,避免精准匹配
- 父组件路由地址作为子组件路由地址的开始的一部分。比如父组件是/index 子组件应该是/index/子组件地址
面试官:** withRouter是干什么的?**
不是所有组件都直接与路由相连(比如拆分的子组件)的,当这些组件需要路由参数时,使用withRouter就可以给此组件传入路由参数,将react-router的history、location、match三个对象传入props对象上,此时就可以使用this.props.history跳转页面了或者接受参数了
面试官:** **state和props有什么区别
相同点:
两者都是 JavaScript 对象
两者都是用于保存信息
props 和 state 都能触发渲染更新
区别:
props 是外部传递给组件的,而 state 是在组件内被组件自己管理的,一般在 constructor 中初始化
props 在组件内部是不可修改的,但 state 在组件内部可以进行修改
state 是多变的、可以修改
面试官:** **super() 和super(props)有什么区别?
在 React 中,类组件基于 ES6,所以在 constructor 中必须使用 super
在调用 super 过程,无论是否传入 props,React 内部都会将 porps 赋值给组件实例 porps 属性中
如果只调用了 super(),那么 this.props 在 super() 和构造函数结束之间仍是 undefined
面试官:React的事件机制总结
React事件机制总结如下:
- React 上注册的事件最终会绑定在document这个 DOM 上,而不是 React 组件对应的 DOM(减少内存开销就是因为所有的事件都绑定在 document 上,其他节点没有绑定事件)
- React 自身实现了一套事件冒泡机制,所以这也就是为什么我们 event.stopPropagation()无效的原因。
- React 通过队列的形式,从触发的组件向父组件回溯,然后调用他们 JSX 中定义的 callback
- React 有一套自己的合成事件 SyntheticEvent
- 说说对React refs 的理解?应用场景?
创建ref的形式有三种:
- 传入字符串,使用时通过 this.refs.传入的字符串的格式获取对应的元素
- 传入对象,对象是通过 React.createRef() 方式创建出来,使用时获取到创建的对象中存在 current 属性就是对应的元素
- 传入hook,hook是通过 useRef() 方式创建,使用时通过生成hook对象的 current 属性就是对应的元素
在某些情况下,我们会通过使用refs来更新组件,但这种方式并不推荐,更多情况我们是通过props与state的方式进行去重新渲染子元素
但下面的场景使用refs非常有用:
- 对Dom元素的焦点控制、内容选择、控制
- 对Dom元素的内容设置及媒体播放
- 对Dom元素的操作和对组件实例的操作
- 集成第三方 DOM 库
面试官:说说你对发布订阅、观察者模式的理解?区别
一、观察者模式
观察者模式定义了对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都将得到通知,并自动更新
观察者模式属于行为型模式,行为型模式关注的是对象之间的通讯,观察者模式就是观察者和被观察者之间的通讯
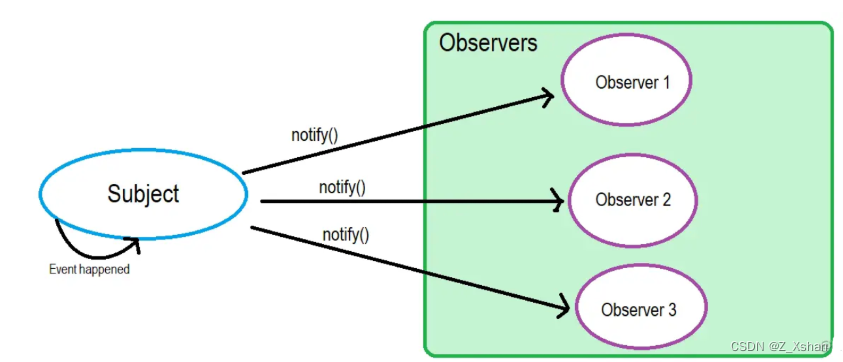
例如生活中,我们可以用报纸期刊的订阅来形象的说明,当你订阅了一份报纸,每天都会有一份最新的报纸送到你手上,有多少人订阅报纸,报社就会发多少份报纸
二、发布订阅模式
发布-订阅是一种消息范式,消息的发送者(称为发布者)不会将消息直接发送给特定的接收者(称为订阅者)。而是将发布的消息分为不同的类别,无需了解哪些订阅者(如果有的话)可能存在
同样的,订阅者可以表达对一个或多个类别的兴趣,只接收感兴趣的消息,无需了解哪些发布者存在
发布者和订阅者需要通过发布订阅中心进行关联,发布者的发布动作和订阅者的订阅动作相互独立,无需关注对方,消息派发由发布订阅中心负责
三、区别
两种设计模式思路是一样的,举个生活例子:
- 观察者模式:某公司给自己员工发月饼发粽子,是由公司的行政部门发送的,这件事不适合交给第三方,原因是“公司”和“员工”是一个整体
- 发布-订阅模式:某公司要给其他人发各种快递,因为“公司”和“其他人”是独立的,其唯一的桥梁是“快递”,所以这件事适合交给第三方快递公司解决
上述过程中,如果公司自己去管理快递的配送,那公司就会变成一个快递公司,业务繁杂难以管理,影响公司自身的主营业务,因此使用何种模式需要考虑什么情况两者是需要耦合的
两者区别如下图:
- 在观察者模式中,观察者是知道Subject的,Subject一直保持对观察者进行记录。然而,在发布订阅模式中,发布者和订阅者不知道对方的存在。它们只有通过消息代理进行通信。
- 在发布订阅模式中,组件是松散耦合的,正好和观察者模式相反。
- 观察者模式大多数时候是同步的,比如当事件触发,Subject就会去调用观察者的方法。而发布-订阅模式大多数时候是异步的(使用消息队列)
面试官:浏览器的渲染过程,DOM 树和渲染树的区别
HTML 经过解析生成 DOM树; CSS经过解析生成 Style Rules。 二者一结合生成了Render Tree。 通过layout计算出DOM要显示的宽高、位置、颜色。 最后渲染在界面上,用户就看到了
浏览器的渲染过程:
解析 HTML 构建 DOM(DOM 树),并行请求 css/image/js
CSS 文件下载完成,开始构建 CSSOM(CSS 树)
CSSOM 构建结束后,和 DOM 一起生成 Render Tree(渲染树)
布局(Layout):计算出每个节点在屏幕中的位置
显示(Painting):通过显卡把页面画到屏幕上
DOM 树 和 渲染树 的区别:
DOM 树与 HTML 标签一一对应,包括 head 和隐藏元素
渲染树不包括 head 和隐藏元素,大段文本的每一个行都是独立节点,每一个节点都有对应的 css 属性
CSS会阻塞DOM解析吗?
对于一个HTML文档来说,不管是内联还是外链的css,都会阻碍后续的dom渲染,但是不会阻碍后续dom的解析。
当css文件放在中时,虽然css解析也会阻塞后续dom的渲染,但是在解析css的同时也在解析dom,所以等到css解析完毕就会逐步的渲染页面了。
面试官:你认为什么 样的前端代码是好的
代码质量的评价有很强的主观性,描述代码质量的词汇也有很多,比如可读性、可维护性、灵活、优雅、简洁等,这些词汇是从不同的维度去评价代码质量的。它们之间有互相作用,并不是独立的,比如,代码的可读性好、可扩展性好就意味着代码的可维护性好。代码质量高低是一个综合各种因素得到的结论。我们并不能通过单一的维度去评价一段代码的好坏。
2.最常用的评价标准有哪几个?
最常用到几个评判代码质量的标准是:可维护性、可读性、可扩展性、灵活性、简洁性、可复用性、可测试性。其中,可维护性、可读性、可扩展性又是提到最多的、最重要的三个评价标准。
面试官:从浏览器地址输入url到显示页面的步骤
- 浏览器根据请求的 url 交给 dns 域名解析,找到真实的 ip, 向服务器发送请求;
- 服务器交给后台处理完成后返回数据,浏览器接收文件( html, js, css,图像等);
- 浏览器对加载到的资源( HTML, JS, CSS等)进行语法解析,建立对应的内部数据结构(如 HTML 的DOM );
- 载入解析到的资源文件,渲染页面,完成
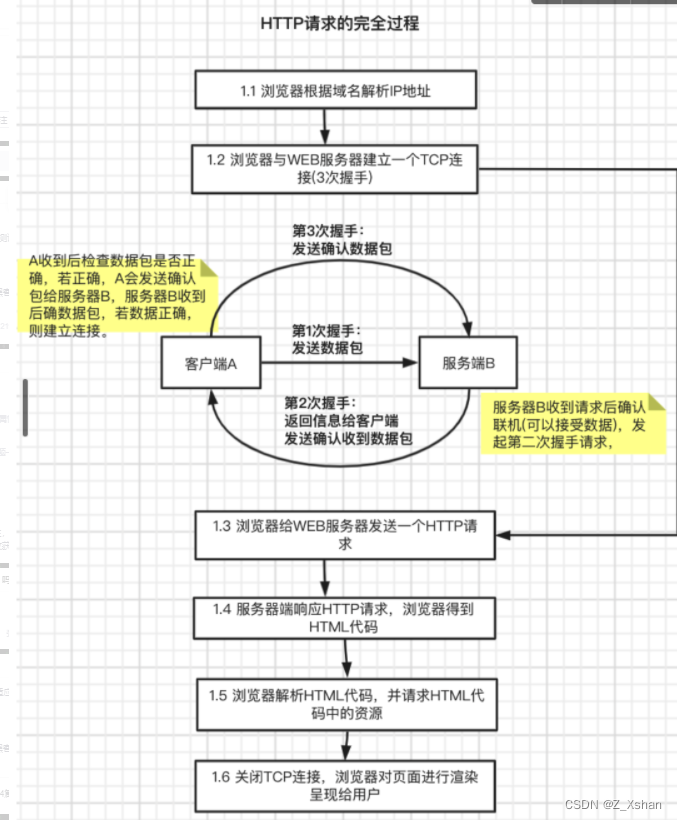
更重要的事情-HTTP缓存
http缓存是客户端缓存, 我们常认为浏览器有一个缓存数据库,用来存放静态文件,
下面我们分为以下几个方面来简单介绍HTTP缓存
- 缓存的规则
- 缓存的方案
- 缓存的优点
- 不同刷新的请求执行过程
1: 缓存规则:
缓存规则分为: 强缓存 和 协商缓存
** 强缓存:**
当 缓存数据库 中有 客户端需要的数据 时,客户端会从直接从缓存数据库中取数据使用【如果数据未失效】 ,当缓存数据库中没有 客户端需要的数据时,才会向服务端发送请求。
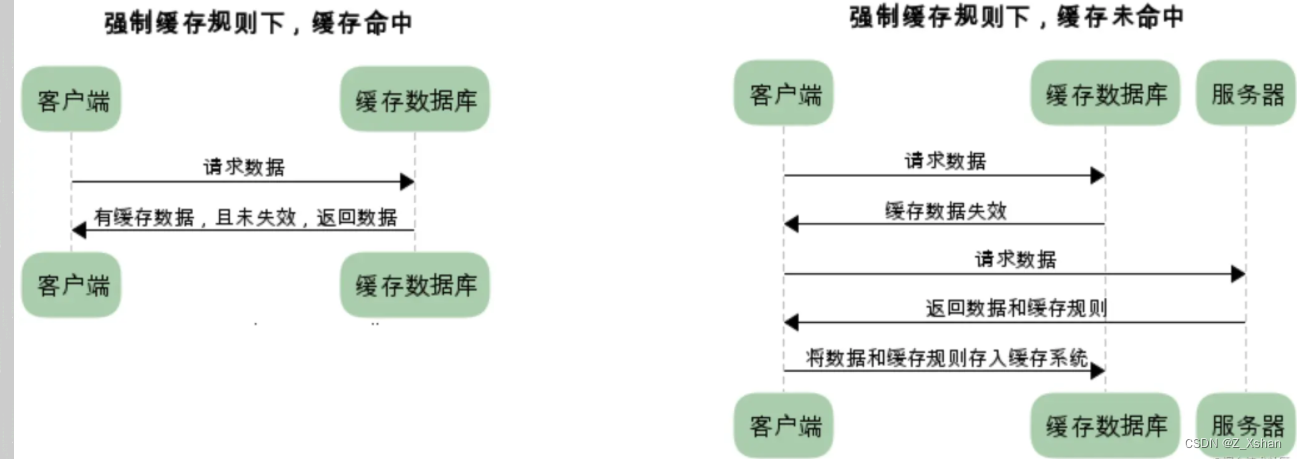
协商缓存:
客户端会先从缓存数据库拿一个缓存的标识,然后向服务端验证标识是否失效,如果没有失效,服务端会返回304,客户端会从直接去缓存数据库拿出数据, 如果标识失效,服务端会返回新的数据,
需要对比判断是否可使用缓存,浏览器第一次请求数据时,服务端就将 缓存标识 和数据一起返回给客户端,客户端将他们备份至缓存中,再次请求时,客户端会将缓存中的标识发送给服务端,服务端根据此标识判断,若未失效,返回304状态码,浏览器拿到此状态码可直接使用缓存数据
**强制缓存 ****的优先级高于 **协商缓存,若两种缓存皆存在,且强制缓存命中目标,则协商缓存不再验证标识。
2: 缓存的方案
服务器是如何判断缓存是否失效呢???
彻底理解浏览器的缓存机制 和 服务端到底是咋 判断缓存是否失效的呢???
我们知道浏览器和服务器进行交互时,会发送一些请求数据和响应数据,我们称为HTTP报文.
报文中包含 首部 header 【存放与缓存相关的规则信息】和 主体部分 body【存放http请求真正要传输的部分】 。
我们分别以。强缓存 和 协商缓存 来分析
强缓存:当浏览器向服务器发起请求时,服务器会将缓存规则放入 HTTP响应报文的HTTP头(response中) 中和请求结果一起返回给浏览器,
如何开启强缓存:设置强制缓存的字段分别是: Expires 和 Cache-Control,它俩可以在 服务端配置(且可同时启用),同时启用的时候 Cache-Control 优先级高于 Expires
Expires:是HTTP/1.0控制网页缓存的字段,其值为服务器返回该请求结果缓存的到期时间,即再次发起该请求时,如果客户端的时间小于Expires的值时,直接使用缓存结果。
Expires是HTTP/1.0的字段,但是现在浏览器默认使用的是HTTP/1.1,那么在HTTP/1.1中网页缓存还是否由Expires控制?
到了HTTP/1.1,Expire已经被Cache-Control替代,原因在于Expires控制缓存的原理是使用客户端的时间与服务端返回的时间做对比,那么如果客户端与服务端的时间因为某些原因(例如时区不同;客户端和服务端有一方的时间不准确)发生误差,那么强制缓存则会直接失效,这样的话强制缓存的存在则毫无意义,那么Cache-Control又是如何控制的呢?
Cache-Control
在HTTP/1.1中,Cache-Control是最重要的规则,主要用于控制网页缓存,主要取值为:
public:所有内容都将被缓存(客户端和代理服务器都可缓存)
private:所有内容只有客户端可以缓存,Cache-Control的默认取值
no-cache:客户端缓存内容,但是是否使用缓存则需要经过协商缓存来验证决定
no-store:所有内容都不会被缓存,即不使用强制缓存,也不使用协商缓存
max-age=xxx (xxx is numeric):缓存内容将在xxx秒后失效
由上面的例子我们可以知道:
HTTP响应报文中expires的时间值,是一个绝对值
HTTP响应报文中Cache-Control为max-age=600,是相对值
由于Cache-Control的优先级比expires,那么直接根据Cache-Control的值进行缓存,意思就是说在600秒内再次发起该请求,则会直接使用缓存结果,强制缓存生效。
注:在无法确定客户端的时间是否与服务端的时间同步的情况下,Cache-Control相比于expires是更好的选择,所以同时存在时,只有Cache-Control生效。
浏览器的缓存存放在哪里,如何在浏览器中判断 强制缓存是否生效?
2个概念 内存缓存(from memory cache) 和 硬盘缓存(from disk cache)
from memory cache代表使用内存中的缓存, from disk cache则代表使用的是硬盘中的缓存, 浏览器读取缓存的顺序为memory –> disk内存缓存(from memory cache):内存缓存具有两个特点,分别是快速读取和时效性:
1: 快速读取:内存缓存会将编译解析后的文件,直接存入该进程的内存中,占据该进程一定的内存资源,以方便下次运行使用时的快速读取。 2: 时效性:一旦该进程关闭,则该进程的内存则会清空。硬盘缓存(from disk cache):硬盘缓存则是直接将缓存写入硬盘文件中,读取缓存需要对该缓存存放的硬盘文件进行I/O操作,然后重新解析该缓存内容,读取复杂,速度比内存缓存慢。
总结:
在浏览器中,浏览器会在 js 和 图片 等文件解析执行后直接存入内存缓存中,那么当刷新页面时只需直接从内存缓存中读取(from memory cache);而css文件则会存入硬盘文件中,所以每次渲染页面都需要从硬盘读取缓存(from disk cache)。
协商缓存:
同样,协商缓存的标识也是在 响应报文的HTTP头 (response) 中 和 请求结果一起返回给浏览器的,控制协商缓存的字段分别有:Last-Modified / If-Modified-Since 和 Etag / If-None-Match,其中Etag / If-None-Match的优先级比Last-Modified / If-Modified-Since高。
Etag:是服务器响应请求时,返回当前请求的资源文件的一个唯一标识(由服务器生成)
Last-Modified:是服务器响应请求时,返回该资源文件在服务最后被修改的时间,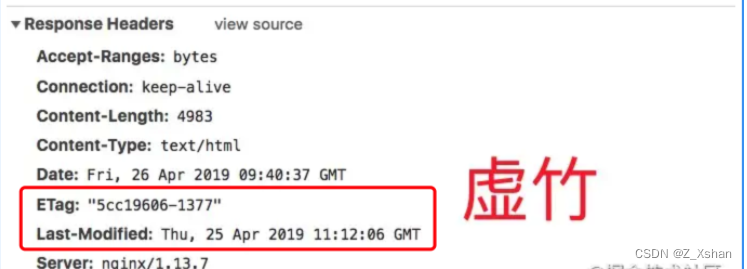
服务端如何判断协商缓存失效,分析如下 ?
If-Modified-Since则是客户端再次发起该请求时,携带上次请求返回的Last-Modified值,通过此字段值告诉服务器该资源上次请求返回的最后被修改时间。服务器收到该请求,发现请求头含有If-Modified-Since字段,则会根据If-Modified-Since的字段值与该资源在服务器的最后被修改时间做对比,若服务器的资源最后被修改时间大于If-Modified-Since的字段值,则重新返回资源,状态码为200;否则则返回304,代表资源无更新,可继续使用缓存文件。 If-None-Match是客户端再次发起该请求时,携带上次请求返回的唯一标识Etag值,通过此字段值告诉服务器该资源上次请求返回的唯一标识值。服务器收到该请求后,发现该请求头中含有If-None-Match,则会根据If-None-Match的字段值与该资源在服务器的Etag值做对比,一致则返回304,代表资源无更新,继续使用缓存文件;不一致则重新返回资源文件,状态码为200
3: 缓存的优点:
- 减少了冗余的数据传输,节省宽带流量
- 减少了服务端的负担,大大提高了网站性能
- 加快了客户端加载网页的速度,这也正是http缓存属于客户端缓存的原因
面试官:Http请求报文格式和响应报文格式
前言
http协议是一个应用层协议,其报文分为请求报文和响应报文
当客户端请求一个网页时,会先通过http协议将请求的内容封装在http请求报文之中,服务器收到该请求报文后根据协议规范进行报文解析,然后向客户端返回响应报文。
http报文结构为:
- 起始行 对报文进行描述
- 头部 向报文中添加了一些附加信息,是一个名/只的列表,头部和协议配合工作,共同决定了客户端和服务器能做什么事情 例如:Content-Length(主体长度),Content-Type(主体类型)等。
- 主体 包含数据的主体部分
请求报文
起始行
在请求报文中,起始行包括了3个部分:
- 请求的方法(POST)
- 请求的URL(/cgi-bin/qqshow_user_props_info)
- 协议类型及版本(HTTP/1.1)
响答报文
起始行
应答报文的起始行也包含了3个部分
- 协议类型及版本号
- 状态码
- 状态码的文字描述
状态码
在http协议中,状态码被分为了5大类
- 100~199(信息性状态码)
- 200~299(成功状态码)
- 300~399(重定向状态码)
- 400~499(客户端错误状态码)
- 500~599(服务器端错误状态码)
面试官:Session和Cookie和Token到底有什么区别
1.Cookie
cookie 是一个非常具体的东西,指的就是浏览器里面能永久存储的一种数据,仅仅是浏览器实现的一种数据存储功能。
cookie由服务器生成,发送给浏览器,浏览器把cookie以kv形式保存到某个目录下的文本文件内,下一次请求同一网站时会把该cookie发送给服务器。由于cookie是存在客户端上的,所以浏览器加入了一些限制确保cookie不会被恶意使用,同时不会占据太多磁盘空间,所以每个域的cookie数量是有限的。
2.Session
session 也是类似的道理,服务器要知道当前发请求给自己的是谁。为了做这种区分,服务器就要给每个客户端分配不同的“身份标识”,然后客户端每次向服务器发请求的时候,都带上这个“身份标识”,服务器就知道这个请求来自于谁了。至于客户端怎么保存这个“身份标识”,可以有很多种方式,对于浏览器客户端,大家都默认采用 cookie 的方式。
3.Token
Token的定义:Token是服务端生成的一串字符串,以作客户端进行请求的一个令牌,当第一次登录后,服务器生成一个Token便将此Token返回给客户端,以后客户端只需带上这个Token前来请求数据即可,无需再次带上用户名和密码。最简单的token组成:uid(用户唯一的身份标识)、time(当前时间的时间戳)、sign(签名,由token的前几位+盐以哈希算法压缩成一定长的十六进制字符串,可以防止恶意第三方拼接token请求服务器)。
使用Token的目的:Token的目的是为了减轻服务器的压力,减少频繁的查询数据库,使服务器更加健壮
区别在哪里
cookie与session的区别
1、cookie数据存放在客户端上,session数据放在服务器上。
2、cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗
考虑到安全应当使用session。
3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能
考虑到减轻服务器性能方面,应当使用COOKIE。
4、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
5、所以个人建议:
将登陆信息等重要信息存放为SESSION
其他信息如果需要保留,可以放在COOKIE中
session与token的区别
session 和 oauth token并不矛盾,作为身份认证 token安全性比session好,因为每个请求都有签名还能防止监听以及重放攻击,而session就必须靠链路层来保障通讯安全了。如上所说,如果你需要实现有状态的会话,仍然可以增加session来在服务器端保存一些状态
App通常用restful api跟server打交道。Rest是stateless的,也就是app不需要像browser那样用cookie来保存session,因此用session token来标示自己就够了,session/state由api server的逻辑处理。 如果你的后端不是stateless的rest api, 那么你可能需要在app里保存session.可以在app里嵌入webkit,用一个隐藏的browser来管理cookie session.
Session 是一种HTTP存储机制,目的是为无状态的HTTP提供的持久机制。所谓Session 认证只是简单的把User 信息存储到Session 里,因为SID 的不可预测性,暂且认为是安全的。这是一种认证手段。 而Token ,如果指的是OAuth Token 或类似的机制的话,提供的是 认证 和 授权 ,认证是针对用户,授权是针对App 。其目的是让 某App有权利访问 某用户 的信息。这里的 Token是唯一的。不可以转移到其它 App上,也不可以转到其它 用户 上。 转过来说Session 。Session只提供一种简单的认证,即有此 SID,即认为有此 User的全部权利。是需要严格保密的,这个数据应该只保存在站方,不应该共享给其它网站或者第三方App。 所以简单来说,如果你的用户数据可能需要和第三方共享,或者允许第三方调用 API 接口,用 Token 。如果永远只是自己的网站,自己的 App,用什么就无所谓了。
面试官:CORS 跨域原理
CORS
是跨源
AJAX
请求的根本解决方法。
JSONP
只能发
GET
请求,但是
CORS
允许任何类型的请求。
整个
CORS
通信过程都是浏览器自动完成的,不需要用户参与。对于开发者来说,
CORS
通信与同源的
AJAX
通信没有差别,代码完全一样。浏览器一旦发现AJAX请求跨源,就会自动添加一些附加的头信息,有时还会多一次附加的请求,但用户不会有感觉。因此,实现
CORS
通信的关键是服务器。只要服务器实现了
CORS
接口,就可以跨源通信。
面试官:MVVM简介
MVVM(Model-View-ViewModel)是一种软件架构设计模式,它是一种简化用户界面的事件驱动编程方式
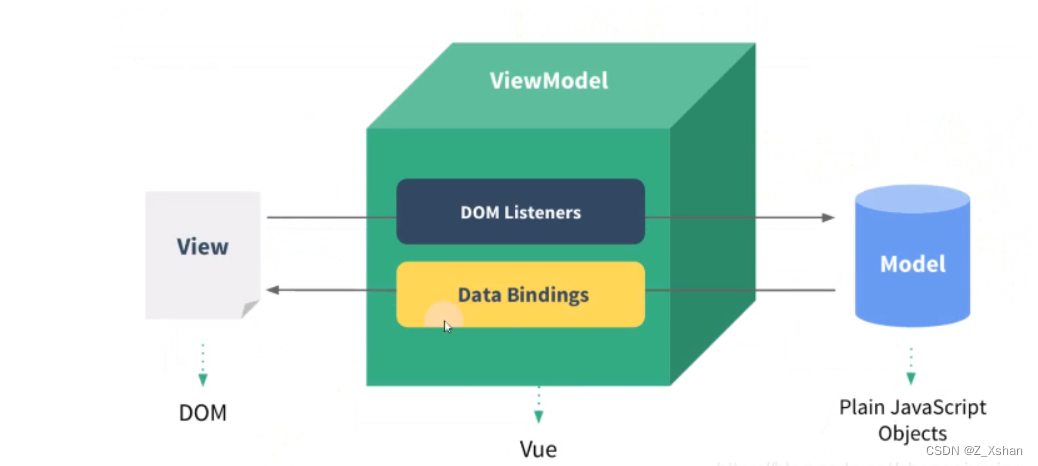
在MVVM架构中,是不允许数据和视图直接通信的,只能通过ViewModel来通信,而ViewModel就是定义了一个Observer观察者。ViewModel是连接View和Model的中间件。
ViewModel能够观察到数据的变化,并对视图对应的内容进行更新。
ViewModel能够监听到视图的变化,并能够通知数据发生变化。
到此,我们就明白了,Vue.js就是一个MVVM的实现者,它的核心就是实现了DOM监听与数据绑定。
2、MVVM优点
MVVM模式和MVC模式一样,主要目的是分离视图(View)和模型(Model),有下面四个优点:
低耦合性: 视图(View)可以独立于Model变化和修改,一个ViewModel可以绑定到不同的"View"上,当View变化的时候Model可以不变,当Model变化的时候View也可以不变
重复使用性:你可以把一些视图逻辑放在一个ViewModel里面,让很多view重用这段视图逻辑
独立开发性: 开发人员可以专注于业务逻辑和数据的开发(ViewModel),设计人员可以专注于页面设计,使用Expression Blend可以很容易设计界面并生成xml代码
可测试性: 界面素来是比较难于测试的,而现在测试可以针对ViewModel来写
面试官:说说你对版本管理的理解?常用的版本管理工具有哪些?
版本控制(Version control),是维护工程蓝图的标准作法,能追踪工程蓝图从诞生一直到定案的过程。
此外,版本控制也是一种软件工程技巧,借此能在软件开发的过程中,确保由不同人所编辑的同一程序文件都得到同步。
透过文档控制,能记录任何工程项目内各个模块的改动历程,并为每次改动编上序号。
简言之,你的修改只要提到到版本控制系统,基本都可以找回,版本控制系统就像一台时光机器,可以让你回到任何一个时间点
版本控制系统在当今的软件开发中,被认为是理所当然的配备工具之一,根据类别可以分成:
本地版本控制系统
集中式版本控制系统
分布式版本控制系统
1.本地版本控制系统:
优点:
简单,很多系统中都有内置
适合管理文本,如系统配置
缺点:
其不支持远程操作,因此并不适合多人版本开发
2.集中式版本控制系统:
优点:
适合多人团队协作开发
代码集中化管理
缺点:
单点故障(单点故障即会整体故障。)
必须联网,无法单机工作
代表工具有SVN、CVS:
3.分布式版本控制系统
优点:
适合多人团队协作开发
代码集中化管理
可以离线工作
每个计算机都是一个完整仓库
分布式版本管理系统每个计算机都有一个完整的仓库,可本地提交,可以做到离线工作,则不用像集中管理那样因为断网情况而无法工作
代表工具为Git、HG:
版本控制系统的优点如下:
记录文件所有历史变化,这是版本控制系统的基本能力
随时恢复到任意时间点,历史记录功能使我们不怕改错代码了
支持多功能并行开发,通常版本控制系统都支持分支,保证了并行开发的可行
多人协作并行开发,对于多人协作项目,支持多人协作开发的版本管理将事半功倍
三、总结
版本控制系统的优点如下:
记录文件所有历史变化,这是版本控制系统的基本能力
随时恢复到任意时间点,历史记录功能使我们不怕改错代码了
支持多功能并行开发,通常版本控制系统都支持分支,保证了并行开发的可行
多人协作并行开发,对于多人协作项目,支持多人协作开发的版本管理将事半功倍
面试官:git常用的命令有哪些

配置
Git
自带一个
git config
的工具来帮助设置控制
Git
外观和行为的配置变量,在我们安装完
git
之后,第一件事就是设置你的用户名和邮件地址
后续每一个提交都会使用这些信息,它们会写入到你的每一次提交中,不可更改
设置提交代码时的用户信息命令如下:
git config [--global] user.name "[name]" git config [--global] user.email "[email address]"
#启动
一个
git
项目的初始有两个途径,分别是:
#日常基本操作
在日常工作中,代码常用的基本操作如下:
关于提交信息的格式,可以遵循以下的规则:
#分支操作
#远程同步
远程操作常见的命令:
#撤销
reset:真实硬性回滚,目标版本后面的提交记录全部丢失了
revert:同样回滚,这个回滚操作相当于一个提价,目标版本后面的提交记录也全部都有
#存储操作
你正在进行项目中某一部分的工作,里面的东西处于一个比较杂乱的状态,而你想转到其他分支上进行一些工作,但又不想提交这些杂乱的代码,这时候可以将代码进行存储
- git init [project-name]:创建或在当前目录初始化一个git代码库
- git clone url:下载一个项目和它的整个代码历史
- git init 初始化仓库,默认为 master 分支
- git add . 提交全部文件修改到缓存区
- git add <具体某个文件路径+全名> 提交某些文件到缓存区
- git diff 查看当前代码 add后,会 add 哪些内容
- git diff --staged查看现在 commit 提交后,会提交哪些内容
- git status 查看当前分支状态
- git pull <远程仓库名> <远程分支名> 拉取远程仓库的分支与本地当前分支合并
- git pull <远程仓库名> <远程分支名>:<本地分支名> 拉取远程仓库的分支与本地某个分支合并
- git commit -m "<注释>" 提交代码到本地仓库,并写提交注释
- git commit -v 提交时显示所有diff信息
- git commit --amend [file1] [file2] 重做上一次commit,并包括指定文件的新变化
- feat: 新特性,添加功能
- fix: 修改 bug
- refactor: 代码重构
- docs: 文档修改
- style: 代码格式修改, 注意不是 css 修改
- test: 测试用例修改
- chore: 其他修改, 比如构建流程, 依赖管理
- git branch 查看本地所有分支
- git branch -r 查看远程所有分支
- git branch -a 查看本地和远程所有分支
- git merge <分支名> 合并分支
- git merge --abort 合并分支出现冲突时,取消合并,一切回到合并前的状态
- git branch <新分支名> 基于当前分支,新建一个分支
- git checkout --orphan <新分支名> 新建一个空分支(会保留之前分支的所有文件)
- git branch -D <分支名> 删除本地某个分支
- git push <远程库名> :<分支名> 删除远程某个分支
- git branch <新分支名称> <提交ID> 从提交历史恢复某个删掉的某个分支
- git branch -m <原分支名> <新分支名> 分支更名
- git checkout <分支名> 切换到本地某个分支
- git checkout <远程库名>/<分支名> 切换到线上某个分支
- git checkout -b <新分支名> 把基于当前分支新建分支,并切换为这个分支
- git fetch [remote] 下载远程仓库的所有变动
- git remote -v 显示所有远程仓库
- git pull [remote] [branch] 拉取远程仓库的分支与本地当前分支合并
- git fetch 获取线上最新版信息记录,不合并
- git push [remote] [branch] 上传本地指定分支到远程仓库
- git push [remote] --force 强行推送当前分支到远程仓库,即使有冲突
- git push [remote] --all 推送所有分支到远程仓库
- git checkout [file] 恢复暂存区的指定文件到工作区
- git checkout [commit] [file] 恢复某个commit的指定文件到暂存区和工作区
- git checkout . 恢复暂存区的所有文件到工作区
- git reset [commit] 重置当前分支的指针为指定commit,同时重置暂存区,但工作区不变
- git reset --hard 重置暂存区与工作区,与上一次commit保持一致
- git reset [file] 重置暂存区的指定文件,与上一次commit保持一致,但工作区不变
- git revert [commit] 后者的所有变化都将被前者抵消,并且应用到当前分支
- git stash 暂时将未提交的变化移除
- git stash pop 取出储藏中最后存入的工作状态进行恢复,会删除储藏
- git stash list 查看所有储藏中的工作
- git stash apply <储藏的名称> 取出储藏中对应的工作状态进行恢复,不会删除储藏
- git stash clear 清空所有储藏中的工作
- git stash drop <储藏的名称> 删除对应的某个储藏
面试官:说说你对Git的理解?
git,是一个分布式版本控制软件,最初目的是为更好地管理
Linux
内核开发而设计
分布式版本控制系统的客户端并不只提取最新版本的文件快照,而是把代码仓库完整地镜像下来。这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复
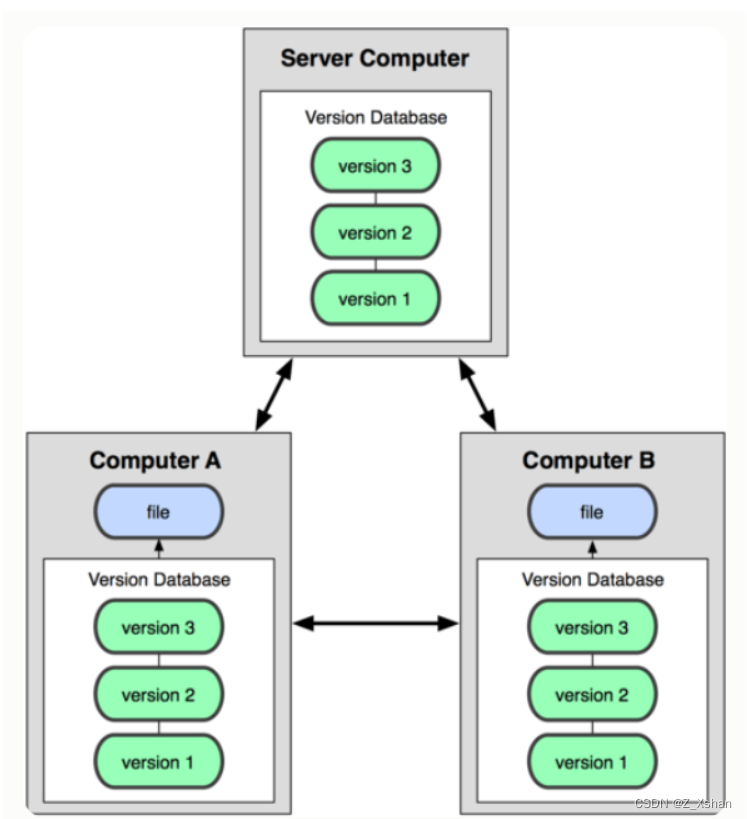
项目开始,只有一个原始版仓库,别的机器可以
clone
这个原始版本库,那么所有
clone
的机器,它们的版本库其实都是一样的,并没有主次之分
所以在实现团队协作的时候,只要有一台电脑充当服务器的角色,其他每个人都从这个“服务器”仓库
clone
一份到自己的电脑上,并且各自把各自的提交推送到服务器仓库里,也从服务器仓库中拉取别人的提交
github
实际就可以充当这个服务器角色,其是一个开源协作社区,提供
Git
仓库托管服务,既可以让别人参与你的开源项目,也可以参与别人的开源项目
面试官:说说 git 发生冲突的场景?如何解决?
在本地主分值
master
创建一个
a.txt
文件,文件起始位置写上
master commit
然后提交到仓库:创建一个新的分支
featurel1
分支,并进行切换 然后修改
a.txt
文件首行文字为
featurel commit
,然后添加到暂存区,并开始进行提交到仓库 然后通过
git checkout master
切换到主分支,通过
git merge
进行合并,发现不会冲突
如果此时切换到
featurel
分支,将文件的内容修改成
featrue second commit
,然后提交到本地仓库
然后切换到主分支,如果此时在
a.txt
文件再次修改,修改成
mastet second commit
,然后再次提交到本地仓库此时,
master
分支和
feature1
分支各自都分别有新的提交
这种情况下,无法执行快速合并,只能试图把各自的修改合并起来,但这种合并就可能会有冲突
现在通过
git merge featurel
进行分支合并,如下所示:

从冲突信息可以看到,
a.txt
发生冲突,必须手动解决冲突之后再提交
而
git status
同样可以告知我们冲突的文件:
打开
a.txt
文件,可以看到如下内容:
三、总结
当
Git
无法自动合并分支时,就必须首先解决冲突,解决冲突后,再提交,合并完成
解决冲突就是把
Git
合并失败的文件手动编辑为我们希望的内容,再提交
面试官:什么是反向代理
正向代理:客户端想要访问一个服务器,但是它可能无法直接访问这台服务器,这时候这可找一台可以访问目标服务器的另外一台服务器,而这台服务器就被当做是代理人的角色 ,称之为代理服务器,于是客户端把请求发给代理服务器,由代理服务器获得目标服务器的数据并返回给客户端。客户端是清楚目标服务器的地址的,而目标服务器是不清楚来自客户端,它只知道来自哪个代理服务器,所以正向代理可以屏蔽或隐藏客户端的信息。
反向代理:从上面的正向代理,你会大概知道代理服务器是为客户端作代理人,它是站在客户端这边的。其实反向代理就是代理服务器为服务器作代理人,站在服务器这边,它就是对外屏蔽了服务器的信息,常用的场景就是多台服务器分布式部署,像一些大的网站,由于访问人数很多,就需要多台服务器来解决人数多的问题,这时这些服务器就由一个反向代理服务器来代理,客户端发来请求,先由反向代理服务器,然后按一定的规则分发到明确的服务器,而客户端不知道是哪台服务器。常常用nginx来作反向代理。
面试官:vue中的diff算法
diff的过程就是调用名为patch的函数,比较新旧节点,一边比较一边给真实的DOM打补丁
其有两个特点:
- 比较只会在同层级进行, 不会跨层级比较
- 在diff比较的过程中,循环从两边向中间比较
Diff算法的步骤:
用 JavaScript 对象结构表示 DOM 树的结构;然后用这个树构建一个真正的 DOM 树,插到文 档当中
当状态变更的时候,重新构造一棵新的对象树。然后用新的树和旧的树进行比较(diff),记录两棵树差异
把第二棵树所记录的差异应用到第一棵树所构建的真正的DOM树上(patch),视图就更新了
面式官:vue中事件修饰符
stop:阻止事件冒
<!-- 阻止单击事件继续传播 -->
<a v-on:click.stop="doThis"></a>
prevent:提交事件不重载页面,
<!-- 提交事件不再重载页面 -->
<form v-on:submit.prevent="onSubmit"></form>
captrue:先执行父在执行子
<!-- 即内部元素触发的事件先在此处理,然后才交由内部元素进行处理 -->
<div v-on:click.capture="doThis">...</div>
once:只执行一次
面试官: 说说对高阶组件的理解?应用场景?
高阶函数(Higher-order function),至少满足下列一个条件的函数
接受一个或多个函数作为输入,输出一个函数
在React中,高阶组件即接受一个或多个组件作为参数并且返回一个组件,本质也就是一个函数,并不是一个组件
高阶组件的主要功能是封装并分离组件的通用逻辑,让通用逻辑在组件间更好地被复用
高阶组件可以传递所有的props,但是不能传递ref
高阶组件能够提高代码的复用性和灵活性,在实际应用中,常常用于与核心业务无关但又在多个模块使用的功能,如权限控制、日志记录、数据校验、异常处理、统计上报等
例:
import React from 'react'
const Gaojie = (Son: any) => {
return function () {
const arr = {
one: '马等待',
two: '小黑'
}
return <Son {...arr} />
}
}
const Gao = (props: any) => {
// console.log(props,'props');
return (
<div>{props.one}安定</div>
)
}
const L=(props:any)=>{
return(
<div>
{props.two}
有阿里了
</div>
)
}
const Fourther=()=>{
return(
<>
老子
<One/>
<T></T>
</>
)
}
const One = Gaojie(Gao)
const T = Gaojie(L)
export default Fourther
面试官:react最新fiber架构原理和流程
react16以后做了很大的改变,对diff算法进行了重写,从总体看,主要是把一次计算,改变为多次计算,在浏览器有高级任务时,暂停计算。
原理:从Stack Reconciler到Fiber Reconciler,源码层面其实就是干了一件递归改循环的事情
fiber设计目的:解决由于大量计算导致浏览器掉帧现象。
由于js是单线程的,解决主线程被长时间计算占用的问题,就是将计算分为多个步骤,分批完成,每完成一次计算就将主线程交还给浏览器,让页面有时间渲染
react更新前后:
旧版:旧版 React 通过递归的方式进行渲染,使用的是 JS 引擎自身的函数调用栈,它会一直执行到栈空为止
新版:Fiber实现了自己的组件调用栈,它以链表的形式遍历组件树,可以灵活的暂停、继续和丢弃执行的任务。实现方式是使用了浏览器的requestIdleCallback这一 API。
React从框架层面有三个层级
Virtual DOM 层,描述页面长什么样。
Reconciler 层 负责调用组件生命周期方法,进行 Diff 运算等。
Renderer 层 根据不同的平台,渲染出相应的页面,比较常见的是 ReactDOM 和 ReactNative。
为了加以区分,以前的 Reconciler 被命名为Stack Reconciler。Stack Reconciler 运作的过程是不能被打断的,必须一条道走到黑。
为了达到这种效果,就需要有一个调度器 (Scheduler) 来进行任务分配。任务的优先级有六种:
synchronous,与之前的Stack Reconciler操作一样,同步执行
task,在next tick之前执行
animation,下一帧之前执行
high,在不久的将来立即执行
low,稍微延迟执行也没关系
offscreen,下一次render时或scroll时才执行
Fiber 树
fiber reconciler在第一阶段diff时,会生成一棵树,这棵树是在virtual dom的基础上增加额外信息生成的,本质上是一个链表。
fiber tree首次渲染:一次生成
后续diff:根据virtual dom和已有tree生成新的tree,这棵树每生成一个节点,都会把控制权交给浏览器,去检查有没有优先级更高的任务需要执行。如果没有,则继续构建树的过程,如果过程中有优先级更高的任务需要进行,则 Fiber Reconciler 会丢弃正在生成的树。
总结:从Stack Reconciler到Fiber Reconciler,源码层面其实就是干了一件递归改循环的事情
面试官:Vue3新特性 组合式Api
setup - 组件内使用 Composition API 的入口点
setup 作为组合式 API 的入口点,也就是说,组合式 API 都必须只能在 setup 中使用
创建组件实例,然后初始化 props ,紧接着就调用setup 函数。从生命周期钩子的视角来看,它会在 beforeCreate 钩子之前被调用
reactive, ref - 数据响应式
reactive - 对象数据响应式
接收一个普通对象然后返回该普通对象的响应式代理。
ref - 单值数据响应式
接受一个参数值并返回一个响应式且可改变的 ref 对象。
computed - 计算属性
只传 getter
返回一个默认不可手动修改的 ref 对象。同时传 getter、setter
创建一个可手动修改的计算状态。
watchEffect、watch - 侦听器
watchEffect
立即执行传入的一个函数,并响应式追踪其依赖,并在其依赖变更时重新运行该函数。watch
对比watchEffect,watch允许我们:
• 懒执行副作用,也就是说仅在侦听的源变更时才执行回调;
• 更明确哪些状态的改变会触发侦听器重新运行副作用;
• 访问侦听状态变化前后的值。
toRefs - 解构响应式对象数据
把一个响应式对象转换成普通对象,该普通对象的每个 property 都是一个 ref ,和响应式对象 property 一一对应。
1.垃圾回收
对于在JavaScript中的字符串,对象,数组是没有固定大小的,只有当对他们进行动态分配存储时,解释器就会分配内存来存储这些数据,当JavaScript的解释器消耗完系统中所有可用的内存时,就会造成系统崩溃。
内存泄漏,在某些情况下,不再使用到的变量所占用内存没有及时释放,导致程序运行中,内存越占越大,极端情况下可以导致系统崩溃,服务器宕机。
JavaScript有自己的一套垃圾回收机制,JavaScript的解释器可以检测到什么时候程序不再使用这个对象了(数据),就会把它所占用的内存释放掉。
针对JavaScript的来及回收机制有以下两种方法(常用):标记清除,引用计数
标记清除
垃圾回收器会给在内存中的变量都做上标记,然后它会去除在环境中的变量和被环境中变量引用的变量(闭包)的标记,在这之后的被标记的变量就是需要清除的变量了。之后垃圾回收器将会回收这些变量所占的内存了
引用计数
引用计数就是追踪每个值被引用的次数,当引用计数为0时,就会回收他所占用的内存。
原理:
- 首先检查 From 空间的存活对象,如果对象存活则判断对象是否满足晋升到老生代的条件,如果满足条件则晋升到老生代。如果不满足条件则移动 To 空间。
- 如果对象不存活,则释放对象的空间。
- 最后将 From 空间和 To 空间角色进行交换。
补充:
1.新创建的对象或者只经历过一次的垃圾回收的对象被称为新生代。经历过多次垃圾回收的对象被称为老生代。
2.新生代被分为 From 和 To 两个空间,To 一般是闲置的。当 From 空间满了的时候会执行 Scavenge 算法进行垃圾回收。当我们执行垃圾回收算法的时候应用逻辑将会停止,等垃圾回收结束后再继续执行。
新生代对象晋升到老生代有两个条件:
- 第一个是判断是对象否已经经过一次 Scavenge 回收。若经历过,则将对象从 From 空间复制到老生代中;若没有经历,则复制到 To 空间。
- 第二个是 To 空间的内存使用占比是否超过限制。当对象从 From 空间复制到 To 空间时,若 To 空间使用超过 25%,则对象直接晋升到老生代中。设置 25% 的原因主要是因为算法结束后,两个空间结束后会交换位置,如果 To 空间的内存太小,会影响后续的内存分配。
内存泄露
- 意外的全局变量: 使用未声明的变量,而意外的创建了一个全局变量,无法被回收
- 定时器: 未被正确关闭,导致所引用的外部变量无法被释放
- 事件监听: 没有正确销毁 (低版本浏览器可能出现)
- 闭包- 第一种情况是我们由于使用未声明的变量,而意外的创建了一个全局变量,而使这个变量一直留在内存中无法被回收。- 第二种情况是我们设置了setInterval定时器,而忘记取消它,如果循环函数有对外部变量的引用的话,那么这个变量会被一直留在内存中,而无法被回收。- 第三种情况是我们获取一个DOM元素的引用,而后面这个元素被删除,由于我们一直保留了对这个元素的引用,所以它也无法被回收。- 第四种情况是不合理的使用闭包,从而导致某些变量一直被留在内存当中。
dom引用:dom元素被删除时,内存中的引用未被正确清空- 控制台
console.log打印的东西
执行上下文
为什么出现上下文
js引擎是一段一段代码来执行的,但不一定是按代码顺序来执行代码的。另外js引擎可执行的代码有全局代码、函数代码、eval代码。当执行一个函数时,会做一些准备工作,就叫做执行上下文。
执行上下文EC
理解:代码执行的环境
时机:代码执行之前会进入到执行环境
工作:
1,创建变量对象: 1)变量 2)函数及函数的参数 3)全局window 4) 局部抽象的但是确实存在 2,确认this指向 1)全局:this--->window 2)局部:this--->调用其对象 3,创建作用域链 父级作用域链+当前作用域链 4,扩展 ECObj={ 变量对象:{变量,函数,函数的参数}, scopChain:父级作用域链+当前的变量对象 this:{window||其调用的对象} }
执行上下文可以简单理解为一个对象:
当执行 JS 代码时,会产生三种执行上下文
- 全局执行上下文
- 函数执行上下文
eval执行上下文
每个执行上下文中都有三个重要的属性
- 变量对象(
VO),包含变量、函数声明和函数的形参,该属性只能在全局上下文中访问 - 作用域链(
JS采用词法作用域,也就是说变量的作用域是在定义时就决定了) this
代码执行过程:
- 创建 全局上下文 (
global EC) - 全局执行上下文 (
caller) 逐行 自上而下 执行。遇到函数时,函数执行上下文 (callee) 被push到执行栈顶层 - 函数执行上下文被激活,成为
active EC, 开始执行函数中的代码,caller被挂起 - 函数执行完后,
callee被pop移除出执行栈,控制权交还全局上下文 (caller),继续执行
例子:
var a = 10 function foo(i) { var b = 20 } foo()
1.变量对象VO
对于上述代码,执行栈中有两个上下文:全局上下文和函数 foo 上下文。
stack = [ globalContext, fooContext ]
对于全局上下文的VO:
globalContext.VO === globe
globalContext.VO = {
a: undefined,
foo: <Function>,
}
对于函数
foo
来说,
VO
不能访问,只能访问到活动对象(
AO
)
fooContext.VO === foo.AO
fooContext.AO {
i: undefined,
b: undefined,
arguments: <>
}
2.作用域链
对于作用域链,可以把它理解成包含自身变量对象和上级变量对象的列表,通过
[[Scope]]
属性查找上级变量
fooContext.[[Scope]] = [
globalContext.VO
]
fooContext.Scope = fooContext.[[Scope]] + fooContext.VO
fooContext.Scope = [
fooContext.VO,
globalContext.VO
]
例子2:(函数和变量提升的原因。通常提升的解释是说将声明的代码移动到了顶部)
b() // call b
console.log(a) // undefinedvar a = 'Hello world'
function b() {
console.log('call b')
}
解释:在生成执行上下文时,会有两个阶段。第一个阶段是创建的阶段(具体步骤是创建
VO
),
JS
解释器会找出需要提升的变量和函数,并且给他们提前在内存中开辟好空间,函数的话会将整个函数存入内存中,变量只声明并且赋值为
undefined
,所以在第二个阶段,也就是代码执行阶段,我们可以直接提前使用。
let
不会提升,
let
提升了声明但没有赋值,因为暂时性死区导致了并不能在声明前使用。
注意:在提升的过程中,相同的函数会覆盖上一个函数,并且函数优先于变量提升
b() // call b second
function b() {
console.log('call b fist')
}
function b() {
console.log('call b second')
}
var b = 'Hello world'
例子3:对于非匿名的立即执行函数需要注意以下一点
var foo = 1
(function foo() {
foo = 10
console.log(foo)
}()) // -> ƒ foo() { foo = 10 ; console.log(foo) }
因为当
JS
解释器在遇到非匿名的立即执行函数时,会创建一个辅助的特定对象,然后将函数名称作为这个对象的属性,因此函数内部才可以访问到
foo
,但是这个值又是只读的,所以对它的赋值并不生效,所以打印的结果还是这个函数,并且外部的值也没有发生更改。
原理↓
specialObject = {};
Scope = specialObject + Scope;
foo = new FunctionExpression;
foo.[[Scope]] = Scope;
specialObject.foo = foo; // {DontDelete}, {ReadOnly}delete Scope[0]; // remove specialObject from the front of scope chain
面试官:在vue3中,新的组合式API中没有this,那我们如果需要用到
this
怎么办?
解决方法:
getCurrentInstance 方法获取当前组件的实例,然后通过
ctx
或
proxy
属性获得当前上下文,这样我们就能在setup中使用router和vuex了
import { getCurrentInstance } from "vue";
export default {
setup() {
let { proxy } = getCurrentInstance();
proxy.$axios(...)
proxy.$router(...)
}
}
但是
但是,不建议使用,如果要使用router和vuex,推荐这样用:
import { computed } from 'vue'
import { useStore } from 'vuex'
import { useRoute, useRouter } from 'vue-router'
export default {
setup () {
const store = useStore()
const route = useRoute()
const router = useRouter()
return {
// 在 computed 函数中访问 state
count: computed(() => store.state.count),
// 在 computed 函数中访问 getter
double: computed(() => store.getters.double)
// 使用 mutation
increment: () => store.commit('increment'),
// 使用 action
asyncIncrement: () => store.dispatch('asyncIncrement')
}
}
}
大家不要依赖 getCurrentInstance 方法去获取组件实例来完成一些主要功能,否则在项目打包后,一定会报错的。
面试官:children以及childNodes的区别
children和只获取该节点下的所有element节点
childNodes不仅仅获取element节点还会获取元素标签中的空白节点
firstElementChild只获取该节点下的第一个element节点
firstChild会获取空白节点
面试官: 请详细说下你对vue生命周期的理解
答:总共分为8个阶段创建前/后,载入前/后,更新前/后,销毁前/后
生命周期是什么
Vue 实例有一个完整的生命周期,也就是从开始创建、初始化数据、编译模版、挂载Dom -> 渲染、更新 -> 渲染、卸载等一系列过程,我们称这是Vue的生命周期
各个生命周期的作用
生命周期描述beforeCreate组件实例被创建之初,组件的属性生效之前created组件实例已经完全创建,属性也绑定,但真实dom还没有生成,$el还不可用beforeMount在挂载开始之前被调用:相关的 render 函数首次被调用mountedel 被新创建的 vm.$el 替换,并挂载到实例上去之后调用该钩子beforeUpdate组件数据更新之前调用,发生在虚拟 DOM 打补丁之前update组件数据更新之后activatedkeep-alive专属,组件被激活时调用deactivatedkeep-alive专属,组件被销毁时调用beforeDestroy组件销毁前调用destroyed组件销毁后调用
1、beforeCreate(创建前):在此生命周期函数执行的时候,data和methods中的数据都还没有初始化。
2、created(创建后):在此生命周期函数中,data和methods都已经被初始化好了,如果要调用 methods中的方法,或者操作data中的数 据,最早只能在created中操作。
3、beforeMount(载入前):在此生命周期函数执行的时候,模板已经在内存中编译好了,但是尚未挂载到页面中去,此时页面还是旧的。
4、mounted(载入后):此时页面和内存中都是最新的数据,这个钩子函数是最早可以操作dom节点的方法。
5、beforeUpdate(更新前):此时页面中显示的数据还是旧的,但是data中的数据是最新的,且页面并未和最新的数据同步。
6、Updated(更新后):此时页面显示数据和最新的data数据同步。
7、beforeDestroy(销毁前):当执行该生命周期函数的时候,实例身上所有的data,所有的methods以及过滤器…等都处于可用状态,并没有真正执行销毁。
8、destroyed(销毁后):此时组件以及被完全销毁,实例中的所有的数据、方法、属性、过滤器…等都已经不可用了。
(三)生命周期(其他三个钩子函数)
下面两个钩子函数一般配合使用
9、activated(组件激活时):和上面的beforeDestroy和destroyed用法差不多,但是如果我们需要一个实例,在销毁后再次出现的话,用 beforeDestroy和destroyed的话,就太浪费性能了。实例被激活时使用,用于重复激活一个实例的时候
10、deactivated(组件未激活时):实例没有被激活时。
11、errorCaptured(错误调用):当捕获一个来自后代组件的错误时被调用
什么是vue生命周期?
- 答: Vue 实例从创建到销毁的过程,就是生命周期。从开始创建、初始化数据、编译模板、挂载Dom→渲染、更新→渲染、销毁等一系列过程,称之为 Vue 的生命周期。
面试官:vue生命周期的作用是什么?
- 答:它的生命周期中有多个事件钩子,让我们在控制整个Vue实例的过程时更容易形成好的逻辑。
面试官:vue生命周期总共有几个阶段?
- 答:它可以总共分为
8个阶段:创建前/后、载入前/后、更新前/后、销毁前/销毁后。
面试官:第一次页面加载会触发哪几个钩子?
- 答:会触发下面这几个
beforeCreate、created、beforeMount、mounted。
面试官:DOM 渲染在哪个周期中就已经完成?
- 答:
DOM渲染在mounted中就已经完成了
面试官:vue路由的钩子函数
首页可以控制导航跳转,
beforeEach,
afterEach等,一般用于页面
title的修改。一些需要登录才能调整页面的重定向功能。
beforeEach主要有3个参数to,from,next。to:route即将进入的目标路由对象。from:route当前导航正要离开的路由。next:function一定要调用该方法resolve这个钩子。执行效果依赖next方法的调用参数。可以控制网页的跳转
面试官:
$route
和
$router
的区别
$route是“路由信息对象”,包括path,params,hash,query,fullPath,matched,name等路由信息参数。- 而
$router是“路由实例”对象包括了路由的跳转方法,钩子函数等
面试官:
<keep-alive></keep-alive>
的作用是什么?
keep-alive可以实现组件缓存,当组件切换时不会对当前组件进行卸载
<keep-alive></keep-alive>包裹动态组件时,会缓存不活动的组件实例,主要用于保留组件状态或避免重新渲染
比如有一个列表和一个详情,那么用户就会经常执行打开详情=>返回列表=>打开详情…这样的话列表和详情都是一个频率很高的页面,那么就可以对列表组件使用
<keep-alive></keep-alive>进行缓存,这样用户每次返回列表的时候,都能从缓存中快速渲染,而不是重新渲染
- 常用的两个属性
include/exclude,允许组件有条件的进行缓存 - 两个生命周期
activated/deactivated,用来得知当前组件是否处于活跃状态
面试官: 指令v-el的作用是什么?
提供一个在页面上已存在的
DOM元素作为
Vue实例的挂载目标.可以是 CSS 选择器,也可以是一个
HTMLElement实例,
面试官: 在Vue中使用插件的步骤
- 采用
ES6的import ... from ...语法或CommonJS的require()方法引入插件 - 使用全局方法
Vue.use( plugin )使用插件,可以传入一个选项对象Vue.use(MyPlugin, { someOption: true })
面试官: 请列举出3个Vue中常用的生命周期钩子函数?
created: 实例已经创建完成之后调用,在这一步,实例已经完成数据观测, 属性和方法的运算,watch/event事件回调. 然而, 挂载阶段还没有开始,$el属性目前还不可见mounted:el被新创建的vm.$el替换,并挂载到实例上去之后调用该钩子。如果root实例挂载了一个文档内元素,当mounted被调用时vm.$el也在文档内。activated:keep-alive组件激活时调用
面试官:CSS3哪些新特性
**1.**新增选择器
p:nth-child(n){color: rgba(255, 0, 0, 0.75)}
2.新增伪元素
::before 和 ::after
3.弹性盒模型
display: flex;
4.多列布局
column-count: 5;
5.媒体查询
@media (max-width: 480px) {.box: {column-count: 1;}}
6.个性化字体
@font-face{font-family: BorderWeb; src:url(BORDERW0.eot);}
7.颜色透明度
color: rgba(255, 0, 0, 0.75);
8.圆角
border-radius: 5px;
9.渐变
background:linear-gradient(red, green, blue);
10.阴影
box-shadow:3px 3px 3px rgba(0, 64, 128, 0.3);
11.倒影
box-reflect: below 2px;
12.文字装饰
text-stroke-color: red;
13.文字溢出
text-overflow:ellipsis;
14.背景效果
background-size: 100px 100px;
15.边框效果
border-image:url(bt_blue.png) 0 10;
16.旋转
transform: rotate(20deg);
17.倾斜
transform: skew(150deg, -10deg);
18.位移
transform: translate(20px, 20px);
19.缩放
transform: scale(.5);
20.平滑过渡
transition: all .3s ease-in .1s;
21.动画
@keyframes anim-1 {50% {border-radius: 50%;}} animation: anim-1 1s;
面试官:ajax原理是什么?如何实现?
`AJAX`全称(Async Javascript and XML),它是一种异步通信的方法,通过直接由 js 脚本向服务器发起 http 通信,然后根据服务器返回的数据,更新网页的相应部分,而不用刷新整个页面的一种方法。
`Ajax`的原理简单来说通过`XmlHttpRequest`对象来向服务器发异步请求,从服务器获得数据,然后用`JavaScript`来操作`DOM`而更新页面
实现过程
实现 `Ajax`异步交互需要服务器逻辑进行配合,需要完成以下步骤:
- 创建 `Ajax`的核心对象 `XMLHttpRequest`对象
- 通过 `XMLHttpRequest` 对象的 `open()` 方法与服务端建立连接
- 构建请求所需的数据内容,并通过`XMLHttpRequest` 对象的 `send()` 方法发送给服务器端
- 通过 `XMLHttpRequest` 对象提供的 `onreadystatechange` 事件监听服务器端你的通信状态
- 接受并处理服务端向客户端响应的数据结果
- 将处理结果更新到 `HTML`页面中
```js
//1:创建Ajax对象
var xhr = window.XMLHttpRequest?new XMLHttpRequest():new ActiveXObject('Microsoft.XMLHTTP');// 兼容IE6及以下版本
//2:配置 Ajax请求地址
xhr.open('get','index.xml',true);
//3:发送请求
xhr.send(null); // 严谨写法
//4:监听请求,接受响应
xhr.onreadystatechange = function() {
if (xhr.readyState == 4) {
if (xhr.status == 200) {
console.log(xhr.responseText)
} else {
console.log("错误信息" + xhr.status)
}
}
}
xhr.open中的参数:
xhr.open(method, url, [async][, user][, password])
method:表示当前的请求方式,常见的有GET、POSTurl:服务端地址async:布尔值,表示是否异步执行操作,默认为trueuser: 可选的用户名用于认证用途;默认为`nullpassword: 可选的密码用于认证用途,默认为`null
xhr.send,将客户端页面的数据发送给服务端
xhr.send([body])
body: 在 XHR 请求中要发送的数据体,如果不传递数据则为 null
如果使用GET请求发送数据的时候,需要注意如下:
- 将请求数据添加到
open()方法中的url地址中 - 发送请求数据中的
send()方法中参数设置为null
onreadystatechange 事件用于监听服务器端的通信状态,主要监听的属性为XMLHttpRequest.readyState ,
关于XMLHttpRequest.readyState属性有五个状态,如下图显示
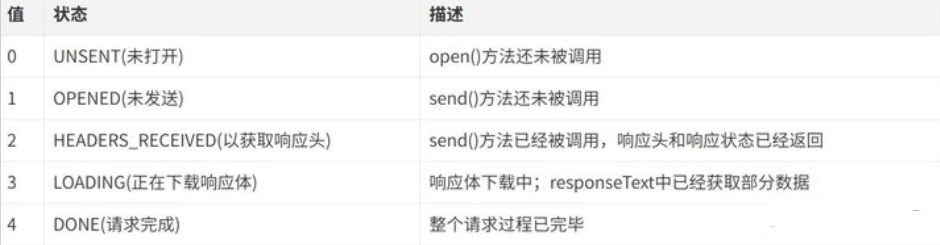
只要 readyState属性值一变化,就会触发一次 readystatechange 事件
XMLHttpRequest.responseText属性用于接收服务器端的响应结果
jQuery写法
$.ajax({
type:'post',
url:'',
async:ture,//async 异步 sync 同步
data:data,//针对post请求
dataType:'jsonp',
success:function (msg) {
},
error:function (error) {
}
})
promise 封装实现:
// promise 封装实现:
functi
面试官:es6新增的拓展
### 1.扩展运算符
//ES6通过扩展元素符`...`,好比 `rest` 参数的逆运算,将一个数组转为用逗号分隔的参数序列
console.log(...[1,2,3])
console.log(0,...[1,2,3],4,5)
//函数调用时,将一个数组变为参数序列
function addAll(a,b,c){
console.log(a,b,c)
}
addAll(...[1,2,3])
addAll(...[4,5,6])
//可以将某些数据结构转为数组
<body>
<div>123</div>
<div>223</div>
<div>323</div>
<div>423</div>
<div>523</div>
</body>
<script>
console.log([...document.querySelectorAll('div')])
</script>
//数组的拷贝/合并
let aa = [1,2,3,4,5]
let bb = [...aa]
bb[1] = 999
console.log(bb)
let aa = [1,2,3,4,5]
let bb = [9,9,9]
console.log([...aa,...bb])
注意:
const arr1 = ['a', 'b',[1,2]]; //这里数组中的数组是浅拷贝,即拷贝的地址值
const arr2 = ['c'];
const arr3 = [...arr1,...arr2]
arr1[2][0] = 9999 // 修改arr1里面数组成员值
console.log(arr3) // 影响到arr3,['a','b',[9999,2],'c']
//扩展运算符可以与解构赋值结合起来,用于生成数组
//注:如果将扩展运算符用于数组赋值,只能放在参数的最后一位,否则会报错
const [first, ...rest] = [1, 2, 3, 4, 5];
first // 1
rest // [2, 3, 4, 5]
const [first, ...rest] = [];
first // undefined
rest // []
const [first, ...rest] = ["foo"];
first // "foo"
rest // []
//可以将字符串转化为真正的数组
console.log([..."hello"])
//定义了遍历器(Iterator)接口的对象,都可以用扩展运算符转为真正的数组
let aa = new Map([
["name","貂蝉"],
["age",12],
["like","跳舞"]
])
console.log([...aa.keys()])
//如果对没有 Iterator 接口的对象,使用扩展运算符,将会报错
const obj = {a: 1, b: 2};
let arr = [...obj]; // TypeError: Cannot spread non-iterable object
//补充:原生具备 Iterator 接口的数据结构如下。
- Array
- Map
- Set
- String
- TypedArray
- 函数的 arguments 对象
- NodeList 对象
### 2.构造函数新增的方法
1.Array.from()
将两类对象转为真正的数组:类似数组的对象和可遍历`(iterable)`的对象(包括 `ES6` 新增的数据结构 `Set` 和 `Map`)(对象也可以)
let aaa = new Map([
['name','貂蝉'],
["age",12],
["like","跳舞"]
])
console.log(Array.from(aaa))
2.Array.of()
//用于将一组值,转换为数组。
//注:
//没有参数的时候,返回一个空数组
//当参数只有一个的时候,实际上是指定数组的长度
//参数个数不少于 2 个时,`Array()`才会返回由参数组成的新数组
面试官:谈谈你对ES6的理解
- 新增模板字符串(为
JavaScript提供了简单的字符串插值功能) - 箭头函数
for-of(用来遍历数据—例如数组中的值。)arguments对象可被不定参数和默认参数完美代替。ES6将promise对象纳入规范,提供了原生的Promise对象。- 增加了
let和const命令,用来声明变量。 - 增加了块级作用域。
let命令实际上就增加了块级作用域。- 还有就是引入
module模块的概念
面试官:模块化
使用一个技术肯定是有原因的,那么使用模块化可以给我们带来以下好处
- 解决命名冲突
- 提供复用性
- 提高代码可维护性
立即执行函数
在早期,使用立即执行函数实现模块化是常见的手段,通过函数作用域解决了命名冲突、污染全局作用域的问题
(function(globalVariable){
globalVariable.test = function() {}
// ... 声明各种变量、函数都不会污染全局作用域
})(globalVariable)
AMD 和 CMD
鉴于目前这两种实现方式已经很少见到,所以不再对具体特性细聊
**CommonJS **
exports
和
module.exports
用法相似,但是不能对
exports
直接赋值。因为
var exports = module.exports
这句代码表明了
exports
和
module.exports
享有相同地址,通过改变对象的属性值会对两者都起效,但是如果直接对
exports
赋值就会导致两者不再指向同一个内存地址,修改并不会对
module.exports
起效
// a.js
module.exports = {
a: 1
}
// or
exports.a = 1
// b.js
var module = require('./a.js')
module.a // -> log 1
ES Module
ES Module是原生实现的模块化方案,与
CommonJS有以下几个区别
CommonJS支持动态导入,也就是require(${path}/xx.js),后者目前不支持,但是已有提案CommonJS是同步导入,因为用于服务端,文件都在本地,同步导入即使卡住主线程影响也不大。而后者是异步导入,因为用于浏览器,需要下载文件,如果也采用同步导入会对渲染有很大影响CommonJS在导出时都是值拷贝,就算导出的值变了,导入的值也不会改变,所以如果想更新值,必须重新导入一次。但是ES Module采用实时绑定的方式,导入导出的值都指向同一个内存地址,所以导入值会跟随导出值变化ES Module会编译成require/exports来执行的
// 引入模块 API
import XXX from './a.js'
import { XXX } from './a.js'
// 导出模块 API
export function a() {}
export default function() {}
扩展:vue3跳转路由实现动画效果
在router-view套上<transition>标签
<transition>
<router-view/>
</transition>
.v-enter, v-leave-to中的css一般相同,一个是进入时过渡(动画)的初始样式,一个是离开过渡(动画)结束时的样式。
.v-enter-active ,v-leave-active 中的css一般相同,一般都是用于定义过渡(动画)的过程时间,延迟和曲线函数。当然离开的过渡(动画)的过程时间,延迟和曲线函数和进入的可以是不同的。
<style>
//
.v-leave-to,.v-enter-from{
opacity: 0;
transform: translateX(-100%);
}
.v-leave-from,.v-enter-to{
opacity: 1;
}
.v-enter-active{
transition: all 1s linear;
}
.v-leave-active{
transition: all 1.5s linear;
}
</style>
面试官:Vue2和vue3的区别?
- 在vue3中新增了
composition-api,入口就是setup函数,在组件创建之前,props被解析之后执行 - 在vue3中不在支持过滤器
filters - 在vue3中移除了
$on、$off、$once、$destroy方法 - 自定以指令的命名必须
v自定以指令名 - 自定义指令的钩子函数新增了
created、beforeUpdate、beforeUnmount,移除了update; bind---->beforeMount inseted--->mounted componentUpdated--->updated unbind---->unmounted - 全局属性的挂载和使用- vue2可以直接在vue的原型上挂载- vue3是
app.config.globalProperites上挂载自定以属性- 通过引入getCurrentInstance函数中proxy来获取 - vue-router路由的使用- 编程式导航的路由跳转:引入了
useRouter函数,通过函数的返回值调用push- 获取路由参数的时候引入了useRoute函数,通过useRoute函数获取 - vuex的使用- 创建store对象时,vue2是
new Vue.Store(),vue3createStore()- 在组件中使用vuex中的state中的数据时,vue3中引入useStore函数
面试官:Symbol是什么,有什么作用?
Symbol
是
ES6
引入的第七种原始数据类型(说法不准确,应该是第七种数据类型,Object不是原始数据类型之一,已更正),所有Symbol()生成的值都是独一无二的,可以从根本上解决对象属性太多导致属性名冲突覆盖的问
// symbol第一种使用方法
const level=Symbol('level')
const student={
name:'小明',
age:2,
[level]:'优秀'
}
for (let i in student){
console.log(i); // name,age
}
// symbol第二种使用方法
const students={
name:'小黑',
age:3,
[Symbol('level')]:'游戏',
[Symbol('level')]:'有钱',
}
// 如何获取symbol的值
let symList=Object.getOwnPropertySymbols(students)
console.log(symList,'ss');//[Symbol(level), Symbol(level)]
for (let i of symList){
console.log(students[i]);//有钱,游戏
}
let list=[1,2,3,4,5,6]
console.log(students[Symbol.iterator]); //undefined
console.log(list[Symbol.iterator]);//ƒ values() { [native code] }
// 如果对象有Symbol.iterator这个属性
//这个对象就可以使用for...of遍历
题。对象中
Symbol()
属性不能被
for...in
遍历,但是也不是私有属性
面试官:Iterator迭代器
Iterator(迭代器)是一种接口,也可以说是一种规范。为各种不同的数据结构提供统一的访问机制。任何数据结构只要部署
Iterator接口,就可以完成遍历操作(即依次处理该数据结构的所有成员)。
Iterator语法:
const obj = {
[Symbol.iterator]:function(){}
}
[Symbol.iterator] 属性名是固定的写法,只要拥有了该属性的对象,就能够用迭代器的方式进行遍历。
- 迭代器的遍历方法是首先获得一个迭代器的指针,初始时该指针指向第一条数据之前,接着通过调用 next 方法,改变指针的指向,让其指向下一条数据
- 每一次的
next都会返回一个对象,该对象有两个属性 -value代表想要获取的数据-done布尔值,false表示当前指针指向的数据有值,true表示遍历已经结束
Iterator 的作用有三个:
- 创建一个指针对象,指向当前数据结构的起始位置。也就是说,遍历器对象本质上,就是一个指针对象。
- 第一次调用指针对象的next方法,可以将指针指向数据结构的第一个成员。
- 第二次调用指针对象的next方法,指针就指向数据结构的第二个成员。
- 不断调用指针对象的next方法,直到它指向数据结构的结束位置。
每一次调用next方法,都会返回数据结构的当前成员的信息。具体来说,就是返回一个包含value和done两个属性的对象。其中,value属性是当前成员的值,done属性是一个布尔值,表示遍历是否结束。
对象没有布局Iterator接口,无法使用
for of遍历。下面使得对象具备Iterator接口
- 一个数据结构只要有Symbol.iterator属性,就可以认为是“可遍历的”
- 原型部署了Iterator接口的数据结构有三种,具体包含四种,分别是数组,类似数组的对象,Set和Map结构
为什么对象(Object)没有部署Iterator接口呢?
- 一是因为对象的哪个属性先遍历,哪个属性后遍历是不确定的,需要开发者手动指定。然而遍历遍历器是一种线性处理,对于非线性的数据结构,部署遍历器接口,就等于要部署一种线性转换
- 对对象部署
Iterator接口并不是很必要,因为Map弥补了它的缺陷,又正好有Iteraotr接口
面试题:Generator
Generator是
ES6中新增的语法,和
Promise一样,都可以用来异步编程。Generator函数可以说是Iterator接口的具体实现方式。Generator 最大的特点就是可以控制函数的执行。
function*用来声明一个函数是生成器函数,它比普通的函数声明多了一个*,*的位置比较随意可以挨着function关键字,也可以挨着函数名yield产出的意思,这个关键字只能出现在生成器函数体内,但是生成器中也可以没有yield关键字,函数遇到yield的时候会暂停,并把yield后面的表达式结果抛出去next作用是将代码的控制权交还给生成器函数
function *foo(x) {
let y = 2 * (yield (x + 1))
let z = yield (y / 3)
return (x + y + z)
}
let it = foo(5)
console.log(it.next()) // => {value: 6, done: false}
console.log(it.next(12)) // => {value: 8, done: false}
console.log(it.next(13)) // => {value: 42, done: true}
上面这个示例就是一个Generator函数,我们来分析其执行过程:
- 首先 Generator 函数调用时它会返回一个迭代器
- 当执行第一次 next 时,传参会被忽略,并且函数暂停在 yield (x + 1) 处,所以返回 5 + 1 = 6
- 当执行第二次 next 时,传入的参数等于上一个 yield 的返回值,如果你不传参,yield 永远返回 undefined。此时 let y = 2 * 12,所以第二个 yield 等于 2 * 12 / 3 = 8
- 当执行第三次 next 时,传入的参数会传递给 z,所以 z = 13, x = 5, y = 24,相加等于 42
yield
实际就是暂缓执行的标示,每执行一次
next()
,相当于指针移动到下一个
yield
位置
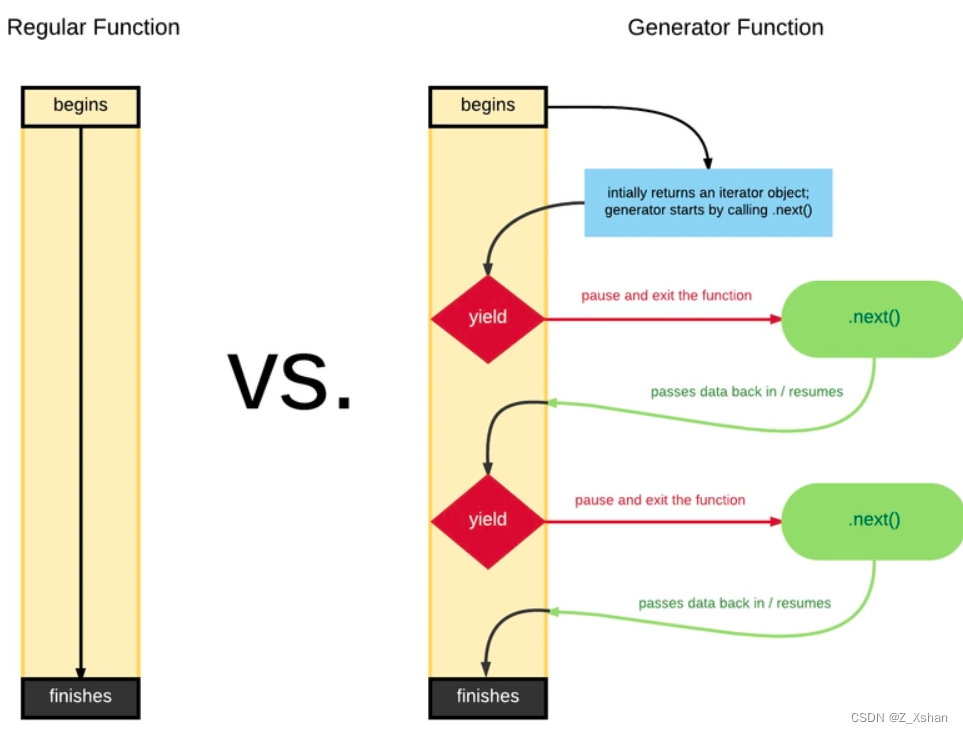
总结一下,
Generator函数是
ES6提供的一种异步编程解决方案。通过
yield标识位和
next()方法调用,实现函数的分段执行
遍历器对象生成函数,最大的特点是可以交出函数的执行权
function关键字与函数名之间有一个星号;- 函数体内部使用
yield表达式,定义不同的内部状态; next指针移向下一个状态
这里你可以说说
Generator的异步编程,以及它的语法糖
async和
awiat,传统的异步编程。
ES6之前,异步编程大致如下
- 回调函数
- 事件监听
- 发布/订阅
传统异步编程方案之一:协程,多个线程互相协作,完成异步任务。
// 使用 * 表示这是一个 Generator 函数
// 内部可以通过 yield 暂停代码
// 通过调用 next 恢复执行
function* test() {
let a = 1 + 2;
yield 2;
yield 3;
}
let b = test();
console.log(b.next()); // > { value: 2, done: false }
console.log(b.next()); // > { value: 3, done: false }
console.log(b.next()); // > { value: undefined, done: true }
从以上代码可以发现,加上
*
的函数执行后拥有了
next
函数,也就是说函数执行后返回了一个对象。每次调用
next
函数可以继续执行被暂停的代码。以下是
Generator
函数的简单实现
// cb 也就是编译过的 test 函数
function generator(cb) {
return (function() {
var object = {
next: 0,
stop: function() {}
};
return {
next: function() {
var ret = cb(object);
if (ret === undefined) return { value: undefined, done: true };
return {
value: ret,
done: false
};
}
};
})();
}
// 如果你使用 babel 编译后可以发现 test 函数变成了这样
function test() {
var a;
return generator(function(_context) {
while (1) {
switch ((_context.prev = _context.next)) {
// 可以发现通过 yield 将代码分割成几块
// 每次执行 next 函数就执行一块代码
// 并且表明下次需要执行哪块代码
case 0:
a = 1 + 2;
_context.next = 4;
return 2;
case 4:
_context.next = 6;
return 3;
// 执行完毕
case 6:
case "end":
return _context.stop();
}
}
});
}
面试官:H5新增了哪些特性
1.语义化标签
HTML5新增的语义化标签主要有:
、 、
面试官: 介绍一下grid网格布局
Grid 布局即网格布局,是一个二维的布局方式,由纵横相交的两组网格线形成的框架性布局结构,能够同时处理行与列,如一些常见的 CSS 布局,如居中,两列布局,三列布局等等是很容易实现的。
擅长将一个页面划分为几个主要区域,以及定义这些区域的大小、位置、层次等关系。
总体兼容性还不错。
同样,Grid 布局属性可以分为两大类:
容器属性,
项目属性
关于容器属性有如下:
1.display:文章开头讲到,在元素上设置display:grid 或 display:inline-grid 来创建一个网格容器
display:grid 则该容器是一个块级元素
display: inline-grid 则容器元素为行内元素
2.grid-template-columns 属性,grid-template-rows 属性
grid-template-columns 属性设置列宽,grid-template-rows 属性设置行高
3.grid-row-gap 属性, grid-column-gap 属性, grid-gap 属性
grid-row-gap 属性、grid-column-gap 属性分别设置行间距和列间距。grid-gap 属性是两者的简写形式
grid-row-gap: 10px 表示行间距是 10px
grid-column-gap: 20px 表示列间距是 20px
grid-gap: 10px 20px 等同上述两个属性
4.grid-template-areas 属性
用于定义区域,一个区域由一个或者多个单元格组成
grid-template-areas: 'a a a'
'b b b'
'c c c';
5.grid-auto-flow 属性
划分网格以后,容器的子元素会按照顺序,自动放置在每一个网格。
6.justify-items 属性, align-items 属性, place-items 属性
justify-items 属性设置单元格内容的水平位置(左中右),align-items 属性设置单元格的垂直位置(上中下)
.container {
justify-items: start | end | center | stretch;
align-items: start | end | center | stretch;
}
7.justify-content 属性, align-content 属性, place-content 属性
justify-content属性是整个内容区域在容器里面的水平位置(左中右),align-content属性是整个内容区域的垂直位置(上中下)
.container {
justify-content: start | end | center | stretch | space-around | space-between | space-evenly;
align-content: start | end | center | stretch | space-around | space-between | space-evenly;
}
8.grid-auto-columns 属性和 grid-auto-rows 属性
有时候,一些项目的指定位置,在现有网格的外部,就会产生显示网格和隐式网格
比如网格只有3列,但是某一个项目指定在第5行。这时,浏览器会自动生成多余的网格,以便放置项目。超出的部分就是隐式网格
而grid-auto-rows与grid-auto-columns就是专门用于指定隐式网格的宽高
关于项目属性,有如下:
1.grid-column-start 属性、grid-column-end 属性、grid-row-start 属性以及grid-row-end 属性
grid-column-start 属性:左边框所在的垂直网格线
grid-column-end 属性:右边框所在的垂直网格线
grid-row-start 属性:上边框所在的水平网格线
grid-row-end 属性:下边框所在的水平网格线
例子:
<style>
#container{
display: grid;
grid-template-columns: 100px 100px 100px;
grid-template-rows: 100px 100px 100px;
}
.item-1 {
grid-column-start: 2;
grid-column-end: 4;
}
</style>
1
2
3
2.grid-area 属性
grid-area 属性指定项目放在哪一个区域,与上述讲到的grid-template-areas搭配使用。
3.justify-self 属性、align-self 属性以及 place-self 属性
justify-self属性设置单元格内容的水平位置(左中右),跟justify-items属性的用法完全一致,但只作用于单个项目。
align-self属性设置单元格内容的垂直位置(上中下),跟align-items属性的用法完全一致,也是只作用于单个项目
.item {
justify-self: start | end | center | stretch;
align-self: start | end | center | stretch;
}这两个属性都可以取下面四个值。
start:对齐单元格的起始边缘。
end:对齐单元格的结束边缘。
center:单元格内部居中。
stretch:拉伸,占满单元格的整个宽度(默认值)
面试官: 说说React Jsx转换成真实DOM过程?
一、是什么
react
通过将组件编写的
JSX
映射到屏幕,以及组件中的状态发生了变化之后
React
会将这些「变化」更新到屏幕上
在前面文章了解中,
JSX
通过
babel
最终转化成
React.createElement
这种形式,例如:
<div>
<img src="avatar.png" className="profile" />
<Hello />
</div>
会被
bebel
转化成如下:
React.createElement(
"div",
null,
React.createElement("img", {
src: "avatar.png",
className: "profile"
}),
React.createElement(Hello, null)
);
在转化过程中,babel在编译时会判断 JSX 中组件的首字母:
当首字母为小写时,其被认定为原生 DOM 标签,createElement 的第一个变量被编译为字符串
当首字母为大写时,其被认定为自定义组件,createElement 的第一个变量被编译为对象
最终都会通过RenderDOM.render(...)方法进行挂载,如下:
ReactDOM.render(<App />, document.getElementById("root"));
**1.使用React.createElement或JSX编写React组件,实际上所有的 JSX 代码最后都会转换成React.createElement(...) ,Babel帮助我们完成了这个转换的过程。 **
2.createElement函数对key和ref等特殊的props进行处理,并获取defaultProps对默认props进行赋值,并且对传入的孩子节点进行处理,最终构造成一个虚拟DOM对象 3.ReactDOM.render将生成好的虚拟DOM渲染到指定容器上,其中采用了批处理、事务等机制并且对特定浏览器进行了性能优化,最终转换为真实DOM
面试官:css中,有哪些方式可以隐藏页面元素?区别?
通过
css
实现隐藏元素方法有如下:
- display:none
特点:元素不可见,不占据空间,无法响应点击事件
- visibility:hidden
特点:元素不可见,占据页面空间,无法响应点击事件
- opacity:0
特点:改变元素透明度,元素不可见,占据页面空间,可以响应点击事件
- 设置height、width模型属性为0
特点:元素不可见,不占据页面空间,无法响应点击事件
- position:absolute(将元素移出可视区域)
特点:元素不可见,不影响页面布局
- clip-path:通过裁剪的形式
.hide { clip-path: polygon(0px 0px,0px 0px,0px 0px,0px 0px);}
特点:元素不可见,占据页面空间,无法响应点击事件
区别:
关于
display: none
、
visibility: hidden
、
opacity: 0
的区别,如下表所示:
display: nonevisibility: hiddenopacity: 0页面中不存在存在存在重排会不会不会重绘会会不一定自身绑定事件不触发不触发可触发transition不支持支持支持子元素可复原不能能不能被遮挡的元素可触发事件能能不能
面试官:说说你对http的了解:
超文本传输协议(Hypertext Transfer Protocol,HTTP),是一个基于请求与响应,无状态的,应用层的协议,常基于TCP/IP协议传输数据,互联网上应用最为广泛的一种网络协议
它可以拆成三个部分:
1.超文本:HTTP 传输的内容是「超⽂本」。它就是超越了普通⽂本的⽂本,它是⽂字、图⽚、视频等的混合体,最关键有超链接,能从⼀个超⽂本跳转到另外⼀个超⽂本。(如HTML) 2.传输:HTTP 协议是⼀个双向协议。 我们在上⽹冲浪时,浏览器是请求⽅ A ,百度⽹站就是应答⽅ B。双⽅约定⽤ HTTP 协议来通信,于是浏览器把请求数据发送给⽹站,⽹站再把⼀些数据返回给浏览器,最后由浏览器渲染在屏幕,就可以看到图⽚、视频了。 3.协议:HTTP 是⼀个⽤在计算机世界⾥的协议。它使⽤计算机能够理解的语⾔确⽴了⼀种计算机之间交流通信的规范(两个以上的参与者),以及相关的各种控制和错误处理⽅式(⾏为约定和规范)。
优点:
HTTP 最凸出的优点是「简单、灵活和易于扩展、应⽤⼴泛和跨平台」。
**缺点: **
⽆状态 明⽂传输 不安全 HTTP ⽐较严重的缺点就是不安全
面试官:Vue 组件 data 为什么必须是函数
每个组件都是 Vue 的实例。 组件共享 data 属性,当 data 的值是同一个引用类型的值时,改变其中一个会影响其他
面试官:web常见的攻击方式有哪些?如何防御?
1.XSS,跨站脚本攻击,允许攻击者将恶意代码植入到提供给其它用户使用的页面中 XSS涉及到三方,即攻击者、客户端与Web应用,根据攻击的来源,XSS攻击可以分成: 存储型 反射型 DOM 型
XSS的预防: (1)输入过滤,避免 XSS 的方法之一主要是将用户输入的内容进行过滤。对所有用户提交内容进行可靠的输入验证,包括对 URL、查询关键字、POST数据等,仅接受指定长度范围内、采用适当格式、采用所预期的字符的内容提交,对其他的一律过滤。(客户端和服务器都要) (2)输出转义 例如: 往 HTML 标签之间插入不可信数据的时候,首先要做的就是对不可信数据进行 HTML Entity 编码 HTML 字符实体 (3)使用 HttpOnly Cookie 将重要的cookie标记为httponly,这样的话当浏览器向Web服务器发起请求的时就会带上cookie字段,但是在js脚本中却不能访问这个cookie,这样就避免了XSS攻击利用JavaScript的document.cookie获取cookie。
2.CSRF(Cross-site request forgery)跨站请求伪造:攻击者诱导受害者进入第三方网站,在第三方网站中,向被攻击网站发送跨站请求 利用受害者在被攻击网站已经获取的注册凭证,绕过后台的用户验证,达到冒充用户对被攻击的网站执行某项操作的目
CSRF的预防: CSRF通常从第三方网站发起,被攻击的网站无法防止攻击发生,只能通过增强自己网站针对CSRF的防护能力来提升安全性 防止csrf常用方案如下: 阻止不明外域的访问 同源检测 Samesite Cookie 提交时要求附加本域才能获取的信息 CSRF Token 双重Cookie验证
3.SQL注入 Sql 注入攻击,是通过将恶意的 Sql查询或添加语句插入到应用的输入参数中,再在后台 Sql服务器上解析执行进行的攻击
预防方式如下: 严格检查输入变量的类型和格式 过滤和转义特殊字符 对访问数据库的Web应用程序采用Web应用防火墙
面试官:为什么 0.1 + 0.2 != 0.3
原因,因为
JS采用
IEEE 754双精度版本(
64位),并且只要采用
IEEE 754的语言都有该问题
我们都知道计算机是通过二进制来存储东西的,那么
0.1
在二进制中会表示为
// (0011) 表示循环
0.1 = 2^-4 * 1.10011(0011)
我们可以发现,
0.1在二进制中是无限循环的一些数字,其实不只是
0.1,其实很多十进制小数用二进制表示都是无限循环的。这样其实没什么问题,但是
JS采用的浮点数标准却会裁剪掉我们的数字。
IEEE 754 双精度版本(64位)将 64 位分为了三段
- 第一位用来表示符号
- 接下去的
11位用来表示指数 - 其他的位数用来表示有效位,也就是用二进制表示
0.1中的10011(0011)
那么这些循环的数字被裁剪了,就会出现精度丢失的问题,也就造成了
0.1不再是
0.1了,而是变成了
0.100000000000000002
0.100000000000000002 === 0.1 // true
那么同样的,
0.2在二进制也是无限循环的,被裁剪后也失去了精度变成了
0.200000000000000002
0.200000000000000002 === 0.2 // true
所以这两者相加不等于
0.3而是
0.300000000000000004
0.1 + 0.2 === 0.30000000000000004 // true
那么可能你又会有一个疑问,既然
0.1不是
0.1,那为什么
console.log(0.1)却是正确的呢?
因为在输入内容的时候,二进制被转换为了十进制,十进制又被转换为了字符串,在这个转换的过程中发生了取近似值的过程,所以打印出来的其实是一个近似值,你也可以通过以下代码来验证
console.log(0.100000000000000002) // 0.1
解决方法
parseFloat((0.1 + 0.2).toFixed(10)) === 0.3 // true
面试官: 注册事件
通常我们使用
addEventListener注册事件,该函数的第三个参数可以是布尔值,也可以是对象。对于布尔值
useCapture参数来说,该参数默认值为
false,
useCapture决定了注册的事件是捕获事件还是冒泡事件。对于对象参数来说,可以使用以下几个属性
capture:布尔值,和useCapture作用一样once:布尔值,值为true表示该回调只会调用一次,调用后会移除监听passive:布尔值,表示永远不会调用preventDefault
一般来说,如果我们只希望事件只触发在目标上,这时候可以使用
stopPropagation来阻止事件的进一步传播。通常我们认为
stopPropagation是用来阻止事件冒泡的,其实该函数也可以阻止捕获事件
。stopImmediatePropagation同样也能实现阻止事件,但是还能阻止该事件目标执行别的注册事件。
node.addEventListener(
'click',
event => {
event.stopImmediatePropagation()
console.log('冒泡')
},
false
)
// 点击 node 只会执行上面的函数,该函数不会执行
node.addEventListener(
'click',
event => {
console.log('捕获 ')
},
true
)
面试官:什么是
MVVM
?比之
MVC
有什么区别?
首先先来说下 View 和 Model
View很简单,就是用户看到的视图Model同样很简单,一般就是本地数据和数据库中的数据
基本上,我们写的产品就是通过接口从数据库中读取数据,然后将数据经过处理展现到用户看到的视图上。当然我们还可以从视图上读取用户的输入,然后又将用户的输入通过接口写入到数据库中。但是,如何将数据展示到视图上,然后又如何将用户的输入写入到数据中,不同的人就产生了不同的看法,从此出现了很多种架构设计。
传统的
MVC架构通常是使用控制器更新模型,视图从模型中获取数据去渲染。当用户有输入时,会通过控制器去更新模型,并且通知视图进行更新
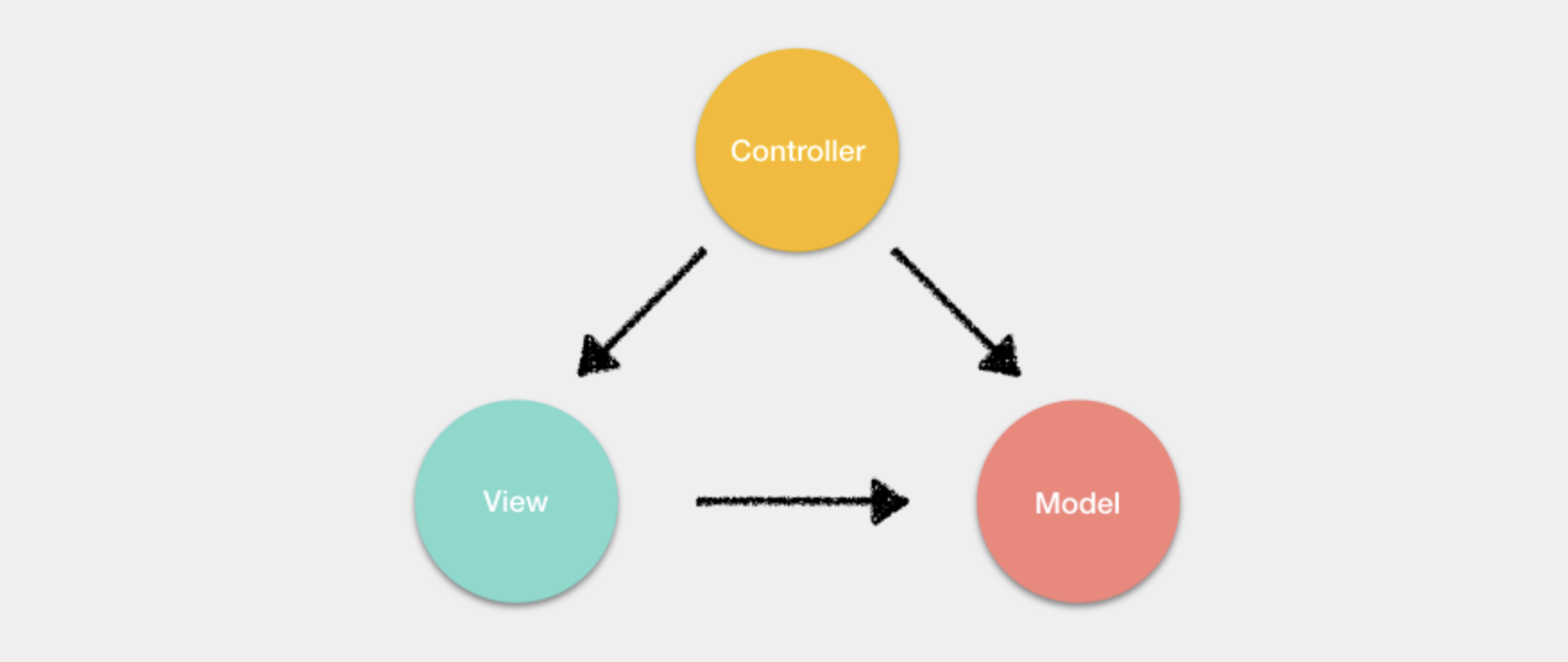
- 但是
MVC有一个巨大的缺陷就是控制器承担的责任太大了,随着项目愈加复杂,控制器中的代码会越来越臃肿,导致出现不利于维护的情况。 - 在
MVVM架构中,引入了ViewModel的概念。ViewModel只关心数据和业务的处理,不关心View如何处理数据,在这种情况下,View和Model都可以独立出来,任何一方改变了也不一定需要改变另一方,并且可以将一些可复用的逻辑放在一个ViewModel中,让多个View复用这个ViewModel。
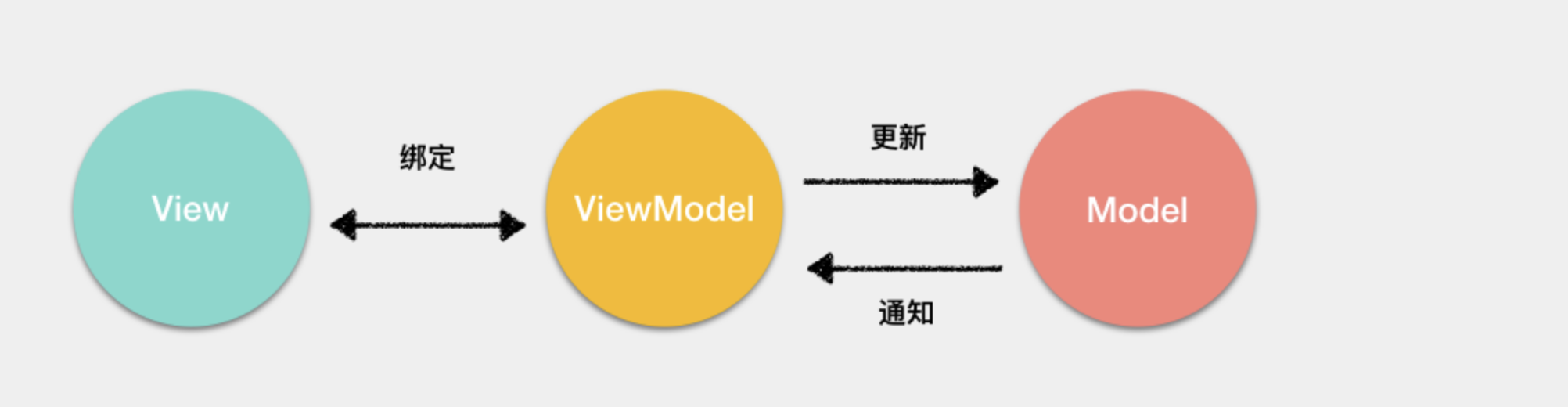
- 以
Vue框架来举例,ViewModel就是组件的实例。View就是模板,Model的话在引入Vuex的情况下是完全可以和组件分离的。 - 除了以上三个部分,其实在
MVVM中还引入了一个隐式的Binder层,实现了View和ViewModel的绑定

- 同样以
Vue框架来举例,这个隐式的Binder层就是Vue通过解析模板中的插值和指令从而实现View与ViewModel的绑定。 - 对于
MVVM来说,其实最重要的并不是通过双向绑定或者其他的方式将View与ViewModel绑定起来,而是通过ViewModel将视图中的状态和用户的行为分离出一个抽象,这才是MVVM的精髓
面试官:mixin 和 mixins 区别
mixin用于全局混入,会影响到每个组件实例,通常插件都是这样做初始化的
Vue.mixin({
beforeCreate() {
// ...逻辑
// 这种方式会影响到每个组件的 beforeCreate 钩子函数
}
})
- 虽然文档不建议我们在应用中直接使用
mixin,但是如果不滥用的话也是很有帮助的,比如可以全局混入封装好的ajax或者一些工具函数等等。 mixins应该是我们最常使用的扩展组件的方式了。如果多个组件中有相同的业务逻辑,就可以将这些逻辑剥离出来,通过mixins混入代码,比如上拉下拉加载数据这种逻辑等等。- 另外需要注意的是
mixins混入的钩子函数会先于组件内的钩子函数执行,并且在遇到同名选项的时候也会有选择性的进行合并,具体可以阅读 文档
面试官: computed 和 watch 区别
computed是计算属性,依赖其他属性计算值,并且computed的值有缓存,只有当计算值变化才会返回内容。watch监听到值的变化就会执行回调,在回调中可以进行一些逻辑操作。- 所以一般来说需要依赖别的属性来动态获得值的时候可以使用
computed,对于监听到值的变化需要做一些复杂业务逻辑的情况可以使用watch。 - 另外
computer和watch还都支持对象的写法,这种方式知道的人并不多。
vm.$watch('obj', {
// 深度遍历
deep: true,
// 立即触发
immediate: true,
// 执行的函数
handler: function(val, oldVal) {}
})
var vm = new Vue({
data: { a: 1 },
computed: {
aPlus: {
// this.aPlus 时触发
get: function () {
return this.a + 1
},
// this.aPlus = 1 时触发
set: function (v) {
this.a = v - 1
}
}
}
})
面试官:Ajax
它是一种异步通信的方法,通过直接由 js 脚本向服务器发起 http 通信,然后根据服务器返回的数据,更新网页的相应部分,而不用刷新整个页面的一种方法。

//1:创建Ajax对象
var xhr = window.XMLHttpRequest?new XMLHttpRequest():new ActiveXObject('Microsoft.XMLHTTP');// 兼容IE6及以下版本
//2:配置 Ajax请求地址
xhr.open('get','index.xml',true);
//3:发送请求
xhr.send(null); // 严谨写法
//4:监听请求,接受响应
xhr.onreadysatechange=function(){
if(xhr.readySate==4&&xhr.status==200 || xhr.status==304 )
console.log(xhr.responsetXML)
}
实现过程
实现 Ajax异步交互需要服务器逻辑进行配合,需要完成以下步骤:
- 创建
Ajax的核心对象XMLHttpRequest对象 - 通过
XMLHttpRequest对象的open()方法与服务端建立连接 - 构建请求所需的数据内容,并通过
XMLHttpRequest对象的send()方法发送给服务器端 - 通过
XMLHttpRequest对象提供的onreadystatechange事件监听服务器端你的通信状态 - 接受并处理服务端向客户端响应的数据结果
- 将处理结果更新到
HTML页面中
promise 封装实现:
// promise 封装实现:
function getJSON(url) {
// 创建一个 promise 对象
let promise = new Promise(function(resolve, reject) {
let xhr = new XMLHttpRequest();
// 新建一个 http 请求
xhr.open("GET", url, true);
// 设置状态的监听函数
xhr.onreadystatechange = function() {
if (this.readyState !== 4) return;
// 当请求成功或失败时,改变 promise 的状态
if (this.status === 200) {
resolve(this.response);
} else {
reject(new Error(this.statusText));
}
};
// 设置错误监听函数
xhr.onerror = function() {
reject(new Error(this.statusText));
};
// 设置响应的数据类型
xhr.responseType = "json";
// 设置请求头信息
xhr.setRequestHeader("Accept", "application/json");
// 发送 http 请求
xhr.send(null);
});
return promise;
}
面试官:深入数组
一、梳理数组 API
Array() 和 Array.of() 的区别
Array()
在JavaScript中,数组构造函数是new Array() 或 Array()
let arr = Array(1, 2, 3, 4)
console.log(arr) // 1, 2, 3, 4
console.log(arr.length) // 4
咋一看,好像什么毛病,我们改一下代码,将构造函数的参数设为只有一个数字时:
let arr = Array(4)
console.log(arr) // [empty × 4]
console.log(arr.length) // 4
这时就会发现,我们或许只是想构造一个只有一个数字4的数组,但却构造了一个数组长度为4的数组,怎么解决这个问题呢?
Array.of()来帮你解决这个问题吧!Array.of()和new Array()功能相同,但当只放入一个数字时,Array.of()会构造一个包含该数字的数组
Array.of()
Array.of ()方法创建一个具有可变数量参数的新数组实例,而不考虑参数的数量或类型。
let arr = Array.of(1, 2, 3, 4)
console.log(arr) // [1, 2, 3, 4]
console.log(arr.length) // 4
这个方法的主要目的,是弥补数组构造函数 Array() 的不足。因为参数个数的不同,会导致 Array() 的行为有差异
let arr = Array.of(4)
console.log(arr) // [4]
console.log(arr.length) // 1
Array.from ()方法详解
1、将类数组对象转换为真正数组:
let arrayLike = {
0: 'tom',
1: '65',
2: '男',
3: ['jane','john','Mary'],
'length': 4
}
let arr = Array.from(arrayLike)
console.log(arr) // ['tom','65','男',['jane','john','Mary']]
如果把length去掉 他就成了一个长度为0的数组
就是具有length属性,但是对象的属性名不再是数字类型的,而是其他字符串型的 会出现以下情况
let arrayLike = {
'name': 'tom',
'age': '65',
'sex': '男',
'friends': ['jane','john','Mary'],
length: 4
}
let arr = Array.from(arrayLike)
console.log(arr) // [ undefined, undefined, undefined, undefined ]
会发现结果是长度为4,元素均为undefined的数组
要将一个类数组对象转换为一个真正的数组,必须具备以下条件:
1、该类数组对象必须具有length属性,用于指定数组的长度。如果没有length属性,那么转换后的数组是一个空数组。
2、该类数组对象的属性名必须为数值型或字符串型的数字
ps: 该类数组对象的属性名可以加引号,也可以不加引号
2、将Set结构的数据转换为真正的数组:
let arr = [12,45,97,9797,564,134,45642]
let set = new Set(arr)
console.log(Array.from(set)) // [ 12, 45, 97, 9797, 564, 134, 45642 ]
Array.from还可以接受第二个参数,作用类似于数组的map方法,用来对每个元素进行处理,将处理后的值放入返回的数组。如下:
let arr = [12,45,97,9797,564,134,45642]
let set = new Set(arr)
console.log(Array.from(set, item => item + 1)) // [ 13, 46, 98, 9798, 565, 135, 45643 ]
3、将字符串转换为数组:
let str = 'hello world!';
console.log(Array.from(str)) // ["h", "e", "l", "l", "o", " ", "w", "o", "r", "l", "d", "!"]
4、Array.from参数是一个真正的数组:
console.log(Array.from([12,45,47,56,213,4654,154]))
** 改变自身的方法**
基于 ES6,会改变自身值的方法一共有
9个,分别为
pop、push、reverse、shift、sort、splice、unshift,以及两个 ES6 新增的方法 copyWithin 和 fill
// pop方法
var array = ["cat", "dog", "cow", "chicken", "mouse"];
var item = array.pop();
console.log(array); // ["cat", "dog", "cow", "chicken"]
console.log(item); // mouse
// push方法
var array = ["football", "basketball", "badminton"];
var i = array.push("golfball");
console.log(array);
// ["football", "basketball", "badminton", "golfball"]
console.log(i); // 4
// reverse方法
var array = [1,2,3,4,5];
var array2 = array.reverse();
console.log(array); // [5,4,3,2,1]
console.log(array2===array); // true
// shift方法
var array = [1,2,3,4,5];
var item = array.shift();
console.log(array); // [2,3,4,5]
console.log(item); // 1
// unshift方法
var array = ["red", "green", "blue"];
var length = array.unshift("yellow");
console.log(array); // ["yellow", "red", "green", "blue"]
console.log(length); // 4
// sort方法
var array = ["apple","Boy","Cat","dog"];
var array2 = array.sort();
console.log(array); // ["Boy", "Cat", "apple", "dog"]
console.log(array2 == array); // true
// splice方法
var array = ["apple","boy"];
var splices = array.splice(1,1);
console.log(array); // ["apple"]
console.log(splices); // ["boy"]
// copyWithin方法
var array = [1,2,3,4,5];
var array2 = array.copyWithin(0,3);
console.log(array===array2,array2); // true [4, 5, 3, 4, 5]
// fill方法
var array = [1,2,3,4,5];
var array2 = array.fill(10,0,3);
console.log(array===array2,array2);
// true [10, 10, 10, 4, 5], 可见数组区间[0,3]的元素全部替换为10
不改变自身的方法
基于 ES7,不会改变自身的方法也有
9个,分别为
concat、join、slice、toString、toLocaleString、indexOf、lastIndexOf、未形成标准的 toSource,以及 ES7 新增的方法 includes。
// concat方法
var array = [1, 2, 3];
var array2 = array.concat(4,[5,6],[7,8,9]);
console.log(array2); // [1, 2, 3, 4, 5, 6, 7, 8, 9]
console.log(array); // [1, 2, 3], 可见原数组并未被修改
// join方法
var array = ['We', 'are', 'Chinese'];
console.log(array.join()); // "We,are,Chinese"
console.log(array.join('+')); // "We+are+Chinese"
// slice方法
var array = ["one", "two", "three","four", "five"];
console.log(array.slice()); // ["one", "two", "three","four", "five"]
console.log(array.slice(2,3)); // ["three"]
// toString方法
var array = ['Jan', 'Feb', 'Mar', 'Apr'];
var str = array.toString();
console.log(str); // Jan,Feb,Mar,Apr
// tolocalString方法
var array= [{name:'zz'}, 123, "abc", new Date()];
var str = array.toLocaleString();
console.log(str); // [object Object],123,abc,2016/1/5 下午1:06:23
// indexOf方法
var array = ['abc', 'def', 'ghi','123'];
console.log(array.indexOf('def')); // 1
// includes方法
var array = [-0, 1, 2];
console.log(array.includes(+0)); // true
console.log(array.includes(1)); // true
var array = [NaN];
console.log(array.includes(NaN)); // true
6. 数组遍历的方法
基于 ES6,不会改变自身的遍历方法一共有 12 个,分别为
forEach、every、some、filter、map、reduce、reduceRight,以及 ES6 新增的方法 entries、find、findIndex、keys、values
// forEach方法
var array = [1, 3, 5];
var obj = {name:'cc'};
var sReturn = array.forEach(function(value, index, array){
array[index] = value;
console.log(this.name); // cc被打印了三次, this指向obj
},obj);
console.log(array); // [1, 3, 5]
console.log(sReturn); // undefined, 可见返回值为undefined
// every方法
var o = {0:10, 1:8, 2:25, length:3};
var bool = Array.prototype.every.call(o,function(value, index, obj){
return value >= 8;
},o);
console.log(bool); // true
// some方法
var array = [18, 9, 10, 35, 80];
var isExist = array.some(function(value, index, array){
return value > 20;
});
console.log(isExist); // true
// map 方法
var array = [18, 9, 10, 35, 80];
array.map(item => item + 1);
console.log(array); // [19, 10, 11, 36, 81]
// filter 方法
var array = [18, 9, 10, 35, 80];
var array2 = array.filter(function(value, index, array){
return value > 20;
});
console.log(array2); // [35, 80]
// reduce方法
var array = [1, 2, 3, 4];
var s = array.reduce(function(previousValue, value, index, array){
return previousValue * value;
},1);
console.log(s); // 24
// ES6写法更加简洁
array.reduce((p, v) => p * v); // 24
// reduceRight方法 (和reduce的区别就是从后往前累计)
var array = [1, 2, 3, 4];
array.reduceRight((p, v) => p * v); // 24
// entries方法
var array = ["a", "b", "c"];
var iterator = array.entries();
console.log(iterator.next().value); // [0, "a"]
console.log(iterator.next().value); // [1, "b"]
console.log(iterator.next().value); // [2, "c"]
console.log(iterator.next().value); // undefined, 迭代器处于数组末尾时, 再迭代就会返回undefined
// find & findIndex方法
var array = [1, 3, 5, 7, 8, 9, 10];
function f(value, index, array){
return value%2==0; // 返回偶数
}
function f2(value, index, array){
return value > 20; // 返回大于20的数
}
console.log(array.find(f)); // 8
console.log(array.find(f2)); // undefined
console.log(array.findIndex(f)); // 4
console.log(array.findIndex(f2)); // -1
// keys方法
[...Array(10).keys()]; // [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[...new Array(10).keys()]; // [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
// values方法
var array = ["abc", "xyz"];
var iterator = array.values();
console.log(iterator.next().value);//abc
console.log(iterator.next().value);//xyz
总结

数组和字符串方法


面试官:在生命周期中的哪一步你应该发起 AJAX 请求
我们应当将AJAX 请求放到
componentDidMount函数中执行,主要原因有下
React下一代调和算法Fiber会通过开始或停止渲染的方式优化应用性能,其会影响到componentWillMount的触发次数。对于componentWillMount这个生命周期函数的调用次数会变得不确定,React可能会多次频繁调用componentWillMount。如果我们将AJAX请求放到componentWillMount函数中,那么显而易见其会被触发多次,自然也就不是好的选择。- 如果我们将
AJAX请求放置在生命周期的其他函数中,我们并不能保证请求仅在组件挂载完毕后才会要求响应。如果我们的数据请求在组件挂载之前就完成,并且调用了setState函数将数据添加到组件状态中,对于未挂载的组件则会报错。而在componentDidMount函数中进行AJAX请求则能有效避免这个问题
面试官:如何告诉 React 它应该编译生产环境版
通常情况下我们会使用
Webpack
的
DefinePlugin
方法来将
NODE_ENV
变量值设置为
production
。编译版本中
React
会忽略
propType
验证以及其他的告警信息,同时还会降低代码库的大小,
React
使用了
Uglify
插件来移除生产环境下不必要的注释等信息
面试官:概述下 React 中的事件处理逻辑
为了解决跨浏览器兼容性问题,
React
会将浏览器原生事件(
Browser Native Event
)封装为合成事件(
SyntheticEvent
)传入设置的事件处理器中。这里的合成事件提供了与原生事件相同的接口,不过它们屏蔽了底层浏览器的细节差异,保证了行为的一致性。另外有意思的是,
React
并没有直接将事件附着到子元素上,而是以单一事件监听器的方式将所有的事件发送到顶层进行处理。这样
React
在更新
DOM
的时候就不需要考虑如何去处理附着在
DOM
上的事件监听器,最终达到优化性能的目的
面试官:createElement 与 cloneElement 的区别是什么
**
传入的第一个参数不同**
**
React.createElement():JSX 语法就是用 React.createElement()来构建 React 元素的。**
**
它接受三个参数,第一个参数可以是一个标签名。如 div、span,或者 React 组件。第二个参数为传入的属性。第三个以及之后的参数,皆作为组件的子组件。**
React.createElement(type, [props], [...children]);React.cloneElement()与 React.createElement()相似,不同的是它传入的第一个参数是一个 React 元素,而不是标签名或组件。新添加的属性会并入原有的属性,传入到返回的新元素中,而旧的子元素将被替换。将保留原始元素的键和引用。
React.cloneElement(element, [props], [...children]);
面试官: redux中间件
中间件提供第三方插件的模式,自定义拦截
action->
reducer的过程。变为
action->
middlewares->
reducer。这种机制可以让我们改变数据流,实现如异步
action,
action过滤,日志输出,异常报告等功能
redux-logger:提供日志输出redux-thunk:处理异步操作redux-promise:处理异步操作,actionCreator的返回值是promise
面试官:redux有什么缺点
Redux 使状态可预测
在 Redux 中,状态始终是可预测的。如果将相同的状态和动作传递给减速器,则总是会产生相同的结果,因为减速器是纯函数。状态也是不可变的,永远不会改变。这使得执行诸如无限撤消和重做之类的艰巨任务成为可能。还可以在之前的状态之间来回移动并实时查看结果。Redux 是可维护的
Redux 对代码的组织方式很严格,这使得具有 Redux 知识的人更容易理解任何 Redux 应用程序的结构。这通常使维护更容易。这也有助于用户将业务逻辑与组件树分离。对于大型应用程序,保持应用程序更具可预测性和可维护性至关重要。Redux 调试简单
Redux 使调试应用程序变得容易。通过记录操作和状态,很容易理解编码错误、网络错误和生产过程中可能出现的其他形式的错误。除了日志记录,它还有很棒的 DevTools,允许时间旅行操作、页面刷新时的持久操作等。对于中型和大型应用程序,调试比实际开发功能花费更多的时间。Redux DevTools 使您可以轻松利用 Redux 提供的所有功能。
4.性能优势
我们可能会假设保持应用程序的状态全局会导致一些性能下降。在很大程度上,情况并非如此,因为 React Redux 在内部实现了许多性能优化,因此我们自己的连接组件仅在实际需要时才重新渲染。5.易于测试
由于函数用于更改纯函数的状态,因此测试 Redux 应用程序很容易。6.状态持久化
我们可以将应用程序的一些状态持久化到本地存储并在刷新后恢复它。这真的很漂亮。7.服务端渲染
Redux 也可用于服务器端渲染。有了它,我们可以通过将应用程序的状态连同它对服务器请求的响应发送到服务器来处理应用程序的初始呈现。然后所需的组件以 HTML 格式呈现并发送到客户端。何时不选择 Redux
主要由简单的用户界面更改组成的应用程序通常不需要像 Redux 这样的复杂模式。有时,不同组件之间的老式状态共享也有效,并提高了代码的可维护性。此外,如果用户的数据来自每个视图的单个数据源,则他们可以避免使用 Redux。换句话说,如果我们不需要多源数据,就没有必要引入Redux。每个视图访问单个数据源时,我们不会遇到数据不一致的问题。
因此,在介绍其复杂性之前,请务必检查我们是否需要 Redux。尽管这是一种促进纯函数的相当有效的模式,但对于仅涉及几个 UI 更改的简单应用程序来说,这可能是一种开销。最重要的是,我们不应该忘记 Redux 是一个内存状态存储。换句话说,如果我们的应用程序崩溃,我们将丢失整个应用程序状态。这意味着我们必须使用缓存解决方案来创建应用程序状态的备份,这又会产生额外的开销。
结论
我们已经讨论了 Redux 的主要特性以及为什么 Redux 对我们的应用程序有益。
虽然 Redux 有它的好处,但这并不意味着我们应该将 Redux 添加到我们所有的应用程序中。如果没有 Redux,我们的应用程序可能仍能正常运行。
Redux 的一个主要好处是增加了方向,将“发生的事情”与“事情如何变化”分开。
如果我们确定我们的项目需要状态管理工具,我们应该只实施 Redux。
面试官:react组件的划分业务组件技术组件?
- 根据组件的职责通常把组件分为UI组件和容器组件。
- UI 组件负责 UI 的呈现,容器组件负责管理数据和逻辑。
- 两者通过
React-Redux提供connect方法联系起来
面试官:预加载
- 在开发中,可能会遇到这样的情况。有些资源不需要马上用到,但是希望尽早获取,这时候就可以使用预加载
- 预加载其实是声明式的
fetch,强制浏览器请求资源,并且不会阻塞onload事件,可以使用以下代码开启预加载
<link rel="preload" href="http://example.com">
预加载可以一定程度上降低首屏的加载时间,因为可以将一些不影响首屏但重要的文件延后加载,唯一缺点就是兼容性不好
面试官: 如何解决a标点击后hover事件失效的问题?
改变a标签css属性的排列顺序
只需要记住
LoVe HAte
原则就可以了(爱恨原则):
link→visited→hover→active
比如下面错误的代码顺序:
a:hover{
color: green;
text-decoration: none;
}
a:visited{ /* visited在hover后面,这样的话hover事件就失效了 */
color: red;
text-decoration: none;
}
正确的做法是将两个事件的位置调整一下。
注意⚠️各个阶段的含义:
a:link:未访问时的样式,一般省略成aa:visited:已经访问后的样式a:hover:鼠标移上去时的样式a:active:鼠标按下时的样式
面试官:Vue实例挂载过程发生了什么

面试官:Js有哪些数据类型
JS中有两种数据类型
1.简单数据类型(也称基本数据类型):Undefined;Null;Boolean;Number和String。
2.引用数据类型(也称复杂数据类型),其中包括Object;Array;Function等等。
面试官:谈谈变量提升?
当执行
JS代码时,会生成执行环境,只要代码不是写在函数中的,就是在全局执行环境中,函数中的代码会产生函数执行环境,只此两种执行环境
- 接下来让我们看一个老生常谈的例子,
var
b() // call b
console.log(a) // undefined
var a = 'Hello world'
function b() {
console.log('call b')
}
变量提升
这是因为函数和变量提升的原因。通常提升的解释是说将声明的代码移动到了顶部,这其实没有什么错误,便于大家理解。但是更准确的解释应该是:在生成执行环境时,会有两个阶段。第一个阶段是创建的阶段,JS
解释器会找出需要提升的变量和函数,并且给他们提前在内存中开辟好空间,函数的话会将整个函数存入内存中,变量只声明并且赋值为
undefined,所以在第二个阶段,也就是代码执行阶段,我们可以直接提前使用
- 在提升的过程中,相同的函数会覆盖上一个函数,并且函数优先于变量提升
b() // call b second
function b() {
console.log('call b fist')
}
function b() {
console.log('call b second')
}
var b = 'Hello world'
复制代码
var会产生很多错误,所以在
ES6中引入了
let。
let不能在声明前使用,但是这并不是常说的
let不会提升,
let提升了,在第一阶段内存也已经为他开辟好了空间,但是因为这个声明的特性导致了并不能在声明前使用
面试官:实现一个trim方法
trim()是一个很适用的方法,作用是去除字符串两边的空白,但是js本身并未提供这个方法,下面介绍js使用trim()的方法
1.通过原型创建字符串的trim()
/去除字符串两边的空白
String.prototype.trim=function(){
return this.replace(/(^\s*)|(\s*$)/g, "");
}
//只去除字符串左边空白
String.prototype.ltrim=function(){
return this.replace(/(^\s*)/g,"");
}
//只去除字符串右边空白
String.prototype.rtrim=function(){
return this.replace(/(\s*$)/g,"");
}
** 2.通过函数实现**
例如:
function trim(str){
return str.replace(/(^\s*)|(\s*$)/g, "");
}
面试官:简述flux思想
1.什么是flux
Flux的提出主要是针对现有前端MVC框架的局限总结出来的一套基于dispatcher的前端应用架构模式。按照MVC的命名习惯,他应该叫ADSV(Action Dispatcher Store View)。
在Flux应用中,数据从action到dispatcher,再到store,最终到view的路线是不可逆的,各个角色之间不会像前段MVC模式那样存在交错的连线
1.用户访问view
2.view发出用户的Action
3.dispatcher收到Action,要求Store进行响应的更新
4.Store更新后,发出一个"change"事件
5.view收到"change"事件后,更新页面
Flux将一个应用分成四个部分;
1.view视图层
2.action(动作);视图层发出的消息(比如mouseClick)
3.Dispatcher(派发器):用来接收Actions,执行回调函数
4.Store(数据层):用来存放应用的状态,一旦发生改变,就提醒Views更新页面
Flux的最大特点:就是数据的"单向流动",数据总是"单项流动",任何相邻的部分都不会发生数据的"双向流动"。

面试官:什么是BFC
【透过现象看本质】:BFC就是符合一些特征的HTML标签
【BFC 是什么?】
BFC(Bloce Formatting Context)格式化上下文 指一个独立的渲染区域,或者说是一个隔离的独立容器 可以理解为一个独立的封闭空间。无论如何不会影响到他的外面
【形成BFC的条件】:
1、浮动元素,float除none以外的值
2、绝对定位元素,position(absolute,fixed)
3、diisplay 为一下其中之一的值 inline-block table-cell table-caption,flex
4、overflow除了visible以外的值(hidden,auto,scroll)
5、body 根元素
【BFC的特性】
1、内部的Box会在垂直方向上一个接一个的放置
2、垂直方向上的距离margin决定
3、bfc的区域不会与float的元素区域重叠
4、计算bfc的高度时,浮动元素区域也参与计算
5、bfc就是页面上的一个独立的容器,容器里面的子元素不会影响外面的元素
前端工程化的特点
前端工程化可以分成四个方面来说,分别为模块化、组件化、规范化和自动化。
模块化
模块化是指将一个文件拆分成多个相互依赖的文件,最后进行统一的打包和加载,这样能够很好的保证高效的多人协作。其中包含JS 模块化:CommonJS、AMD、CMD 以及 ES6 Module。
CSS 模块化:Sass、Less、Stylus、BEM、CSS Modules 等。其中预处理器和 BEM 都会有的一个问题就是样式覆盖。而 CSS Modules 则是通过 JS 来管理依赖,最大化的结合了 JS 模块化和 CSS 生态,比如 Vue 中的 style scoped。
资源模块化:任何资源都能以模块的形式进行加载,目前大部分项目中的文件、CSS、图片等都能直接通过 JS 做统一的依赖关系处理。
组件化
不同于模块化,模块化是对文件、对代码和资源拆分,而组件化则是对 UI 层面的拆分。通常,我们会需要对页面进行拆分,将其拆分成一个一个的零件,然后分别去实现这一个个零件,最后再进行组装。 在我们的实际业务开发中,对于组件的拆分我们需要做不同程度的考量,其中主要包括细粒度和通用性这两块的考虑。 对于业务组件,你更多需要考量的是针对你负责业务线的一个适用度,即你设计的业务组件是否成为你当前业务的 “通用” 组件。
规范化
正所谓无规矩不成方圆,一些好的规范则能很好的帮助我们对项目进行良好的开发管理。规范化指的是我们在工程开发初期以及开发期间制定的系列规范,其中又包含了项目目录结构
编码规范:对于编码这块的约束,一般我们都会采用一些强制措施,比如 ESLint、StyleLint 等。
联调规范
文件命名规范
样式管理规范:目前流行的样式管理有 BEM、Sass、Less、Stylus、CSS Modules 等方式。
git flow 工作流:其中包含分支命名规范、代码合并规范等。
定期 code review … 等等
自动化
从最早先的 grunt、gulp 等,再到目前的 webpack、parcel。这些自动化工具在自动化合并、构建、打包都能为我们节省很多工作。而这些只是前端自动化其中的一部分,前端自动化还包含了持续集成、自动化测试等方方面面。以上就是我所了解的前端工程化,以工程的角度去理解我们的web前端。工程是工程,而不是某项技术。
面试官:CSS清除浮动的方法(多种)
清除浮动的含义是什么?
清除浮动带来的影响
影响:如果子元素浮动了,此时子元素不能撑开父元素
➢ 清除浮动的目的是什么?
需要父元素有高度,从而不影响其他网页元素的布局
注意:父子级标签, 子级浮动, 父级没有高度, 后面的标准流盒子会受影响, 显示到上面的位置
方法:
1、直接设置父元素高度
优点:简单粗暴,方便
缺点:有些布局中不能固定父元素高度。如:新闻列表、京东推荐模块
2、额外标签法
操作: 1. 在父元素内容的最后添加一个块级元素 2. 给添加的块级元素设置 clear:both
缺点:会在页面中添加额外的标签,会让页面的HTML结构变得复杂** **
3、单伪元素清除法
操作:用伪元素替代了额外标签
基本写法
.clearfix::after{
content:'';
display:block;
clear:both;
}
补充写法
/* 伪元素添加的标签是行内, 要求块 */
.clearfix::after{
content:'';
/* 伪元素添加的标签是行内, 要求块 */
display:block;
clear:both;
/* 补充代码:在网页中看不到伪元素 *//* 为了兼容性 */
height:0;
visibility:hidden;
}
优点:项目中使用,直接给标签加类即可清除浮动
4、双伪元素清除法
操作:
/* .clearfix::before 作用: 解决外边距塌陷问题
外边距塌陷: 父子标签, 都是块级, 子级加margin会影响父级的位置
*/
/* 清除浮动 */
.clearfix::bofore,
.clearfix::after{
content:'';
display:table;
}
/* 真正清除浮动的标签 */
.clearfix::after{
clear:both;
}
优点:项目中使用,直接给标签加类即可清除浮动
5、给父元素设置overflow : hidden
操作: 直接给父元素设置 overflow : hidden
优点:方便
面试官:keep-alive的属性
include
include:字符串或正则表达,只有匹配的组件会被缓存
<keep-alive include="组件的name">
……
</keep-alive>
如:
<keep-alive include="home,other">
<router-view></router-view>
</keep-alive>
表示home、other组件可以被缓存
exclude
exclude:字符串或正则表达式,任何匹配的组件都不会被缓存
<keep-alive exclude="组件的name">
……
</keep-alive>
如:
<keep-alive exclude="home,other">
<router-view></router-view>
</keep-alive>
表示home、other组件不能被缓存
也可以在router里meta设置true或者或false然后在keep-alive去做判来实现是否进行缓存
面试官:webpack中的代码分割
代码分割的方法
官网给出了三种常用的代码分割的方法
- Entry Points:入口文件设置的时候可以配置
- CommonsChunkPlugin:上篇文章讲了一下应用,更详细的信息可以查看官网
- Dynamic Imports:动态导入。通过模块的内联函数调用来分割,这篇文章主要会结合 vue-router 分析一下这种方
Entry Points
这种是最简单也是最直观的代码分割方式,但是会存在一些问题。方法就是在 webpack 配置文件中的 entry 字段添加新的入口:
const path = require('path');
module.exports = {
entry: {
index: './src/index.js',
another: './src/another-module.js'
},
output: {
filename: '[name].bundle.js',
path: path.resolve(__dirname, 'dist')
}
};
将生成下面的构建结果:

看上去是分割出来了一个新的 bundle。但是会有两个问题:
- 如果入口 chunks 之间包含重复的模块,那些重复模块都会被引入到各个 bundle 中
- 这种方法不够灵活,并且不能将核心应用程序逻辑进行动态拆分代码
举个例子,index 和 another 这两个入口文件都包含了 lodash 这个模块,那分割出来的两个 bundle 都会包含 lodash 这个模块,冗余了。解决这个问题就需要 CommonsChunkPlugin 插件
**CommonsChunkPlugin **
这个插件可以抽取所有入口文件都依赖了的模块,把这些模块抽取成一个新的bundle。具体用法如下:
const path = require('path');
module.exports = {
entry: {
index: './src/index.js',
another: './src/another-module.js'
},
plugins: [
new webpack.optimize.CommonsChunkPlugin({
name: 'common' // bundle 名称
})
],
output: {
filename: '[name].bundle.js',
path: path.resolve(__dirname, 'dist')
}
};
构建结果如下:

可以看到,原来的 index 和 another 两个bundle的体积大大的减小了。并且多了一个574k的 common bundle。这个文件就是抽离出来的 lodash 模块。这样就可以把业务代码,和第三方模块代码分割开了。
Dynamic Imports
Webpack 的动态分割主要方式是使用符合 ECMAScript 提案的 import() 语法。语法如下
import('path/to/module') -> Promise
传入模块的路径,import() 会返回一个Promise。这个模块就会被当作分割点。意味着这个模块和它的子模块都会被分割成一个单独的 chunk。并且,在 webpack 配置文件的 output 字段,需要添加一个 chunkFileName 属性。它决定非入口 chunk 的名称。
// vue-cli 生成的webpack.prod.conf.js
// 注意 output 的 chunkFilename 属性
// 这种写法分割出来的 bundle 会以 id + hash 的命名方式
// 比如 1.32326e28f3acec4b3a9a.js
output: {
path: config.build.assetsRoot,
filename: utils.assetsPath('js/[name].[chunkhash].js'),
chunkFilename: utils.assetsPath('js/[id].[chunkhash].js')
},
这个动态代码分割功能是我们实现按需加载的前提。在 vue 的项目里,我们最终想要达到这样一个效果:
- 把每个路由所包含的组件,都分割成一个单独的 bundle
- 当路由被访问的时候才加载该路由对应的 bundle
第一个点通过上面的
import()
就已经可以实现了。要实现第二点,需要用到 vue 里面的异步组件特性。
Vue 允许将组件定义为一个工厂函数,异步地解析组件的定义。只在组件需要渲染时触发工厂函数,并且把结果缓存起来,用于后面的再次渲染。工厂函数的写法:
Vue.component('async-webpack-example',
// 该 `import` 函数返回一个 `Promise` 对象。
() => import('./my-async-component')
)
最后在
vue-router
的路由配置中,我们只需要这么写:
const router = new VueRouter({
routes: [
{ path: '/login', component: () => import('@/views/login'), },
{ path: '/home', component: () => import('@/views/home'), }
]
})
结合 Vue 的异步组件和 Webpack 的代码分割功能,在 vue-router 中,我们轻松实现了路由组件的按需加载加载。所以,文章开头的问题在这里就可以解答了。以0-7数字开头的 js 文件,就是每个路由对应的组件构建出来的 bundle。只有用户访问对应的路由时,才会加载相应的 bundle,提高页面加载效率。
面试官:Vue数据更新但页面没有更新的多种情况
**1、Vue 无法检测实例被创建时不存在于 **
data
** 中的 变量******
原因:由于 Vue 会在初始化实例时对 data中的数据执行
getter/setter
转化,所以 变量必须在
data
对象上存在才能让 Vue 将它转换为响应式的。
例如:
new Vue({
data:{},
template: '<div>{{message}}</div>'
})
this.message = 'Hello world !' // `message` 不是响应式的页面不会发生变化
解决方法:
new Vue({
data: {
message: '',
},
template: '<div>{{ message }}</div>'
})
this.message = 'Hello world!'
2、vue也不能检测到data中对象的动态添加和删除
例如:
new Vue({
data:{
obj: {
id: 1
}
},
template: '<div>{{ obj.message }}</div>'
})
this.obj.message = 'hello' // 不是响应式的
delete this.obj.id // 不是响应式的
解决:
// 动态添加 - Vue.set
Vue.set(this.obj, 'id', 002)
// 动态添加 - this.$set
this.$set(this.obj, 'id', 002)
// 动态添加多个
// 代替 Object.assign(this.obj, { a: 1, b: 2 })
this.obj = Object.assign({}, this.obj, { a: 1, b: 2 })
// 动态移除 - Vue.delete
Vue.delete(this.obj, 'name')
// 动态移除 - this.$delete
this.$delete(this.obj, 'name')
3、数组的时候,不能通过索引直接修改或者赋值,也不能修改数组的长度
例如
new Vue({
data: {
items: ['a', 'b', 'c']
}
})
this.items[1] = 'x' // 不是响应性的
this.items[3] = 'd' // 不是响应性的
this.items.length = 2 // 不是响应性的
解决:
// Vue.set
Vue.set(this.items, 4, 'd')
// this.$set
this.$set(this.items, 4, 'd)
// Array.prototype.splice
this.items.splice(indexOfItem, 4, 'd')
//修改长度
this.items.splice(3)
4、异步获取接口数据,DOM数据不发现变化
原因:Vue 在更新 DOM 时是异步执行的。只要侦听到数据变化,Vue 将开启一个队列,并缓冲在同一事件循环中发生的所有数据变更。如果同一个 watcher 被多次触发,只会被推入到队列中一次。这种在缓冲时去除重复数据对于避免不必要的计算和 DOM 操作是非常重要的。然后,在下一个的事件循环“tick”中,Vue 刷新队列并执行实际 (已去重的) 工作。Vue 在内部对异步队列尝试使用原生的 Promise.then、MutationObserver 和 setImmediate,如果执行环境不支持,则会采用 setTimeout(fn, 0) 代替。
<div id="example">{{message}}</div>
var vm = new Vue({
el: '#example',
data: {
message: '123'
}
})
vm.message = 'new message' // 更改数据
vm.$el.textContent === 'new message' // false
vm.$el.style.color = 'red' // 页面没有变化
解决办法:
var vm = new Vue({
el: '#example',
data: {
message: '123'
}
})
vm.message = 'new message' // 更改数据
//使用 Vue.nextTick(callback) callback 将在 DOM 更新完成后被调用
Vue.nextTick(function () {
vm.$el.textContent === 'new message' // true
vm.$el.style.color = 'red' // 文字颜色变成红色
})
5、循环嵌套层级太深,视图不更新
当嵌套太深时,页面也可以不更新,此时可以让页面强制刷新
this.$forceUpdate() (不建议用)
6、 路由参数变化时,页面不更新(数据不更新)
拓展一个因为路由参数变化,而导致页面不更新的问题,页面不更新本质上就是数据没有更新。
原因:路由视图组件引用了相同组件时,当路由参会变化时,会导致该组件无法更新,也就是我们常说中的页面无法更新的问题。
场景:
<div id="app">
<ul>
<li><router-link to="/home/foo">To Foo</router-link></li>
<li><router-link to="/home/baz">To Baz</router-link></li>
<li><router-link to="/home/bar">To Bar</router-link></li>
</ul>
<router-view></router-view>
</div>
const Home = {
template: `<div>{{message}}</div>`,
data() {
return {
message: this.$route.params.name
}
}
}
const router = new VueRouter({
mode:'history',
routes: [
{path: '/home', component: Home },
{path: '/home/:name', component: Home }
]
})
new Vue({
el: '#app',
router
})
上段代码中,我们在路由构建选项 routes 中配置了一个动态路由 '/home/:name',它们共用一个路由组件 Home,这代表他们复用 RouterView 。
当进行路由切换时,页面只会渲染第一次路由匹配到的参数,之后再进行路由切换时,message 是没有变化的。
解决办法:
解决的办法有很多种,这里只列举我常用到几种方法。
通过 watch 监听 $route 的变化。
const Home = {
template: `<div>{{message}}</div>`,
data() {
return {
message: this.$route.params.name
}
},
watch: {
'$route': function() {
this.message = this.$route.params.name
}
}
}
new Vue({
el: '#app',
router
})
- 给
<router-view>绑定key属性,这样 Vue 就会认为这是不同的<router-view>。
弊端:如果从
/home
跳转到
/user
等其他路由下,我们是不用担心组件更新问题的,所以这个时候
key
属性是多余的。
<div id="app"><router-view :key="key"></router-view></div>
面试官:vuex是什么?
Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式,可以实现数据之间的共享,它由五部分组成:
分别是:
state (用来存放数据)
actions (可以包含异步操作)
mutations (唯一可以修改state数据的场所)
getters (类似于vue组件中的计算属性,对state数据进行计算(会被缓存))
modules (模块化管理store(仓库),每个模块拥有自己的 state、mutation、action、getter)
**二. vuex的使用步骤 **
代码如下(示例):
在根目录下新建一个store文件夹,里面创建一个index.js文件,
最后在main.js中引入,并挂载到实例上,之后那个组件中需要用到vuex就调用就行
import Vue from 'vue'
import Vuex from 'vuex'
Vue.use(Vuex)
export default new Vuex.Store({
//存放数据 this.$store.state.xxx
state: {},
// 唯一修改state的地方 this.$store.commit('事件名',参数)
mutations: {},
// 执行异步操作 this.$store.dispatch('事件名')
actions: {},
// 模块,每个模块拥有自己的state,mutations,actions,getters
modules: {},
// 计算state
getters:{} this.$store.getters.xxx
})
面试官:Vue Router的路由模式hash和history的实现原理
一、Vue-router 中hash模式和history模式的关系
最直观的区别就是在url中 hash 带了一个很丑的 # 而history是没有#的。
二、hash模式实现原理
早期前端路由的实现就是基于
location.hash来实现的,其实实现原理很简单,
location.hash的值就是URL中
#后面的内容
hash路由模式的实现主要特性:
URL中的hash值只是客户端的一种状态,也就是说当向服务器发送请求时,hash部分不会被发送;
hash值的改变,都会在浏览器的访问历史中增加一个记录,因此在开发时,也可以通过浏览器的回退和前进按钮来控制hash的切换;
也可以通过href属性来改变URL的hash值,或者使用location.hash进行赋值,改变URL的hash值;
可以使用hashchange事件来监听hash值的变化,从而对页面进行跳转。
三、history模式的实现原理
HTML5提供了History API来实现URL的变化,其中最主要的两个API有以下两个
history.pushState()和history.replaceState()。这两个API可以在不进行刷新的情况下,操作浏览器的历史记录。唯一不同的是,前者是新增一个历史记录,后者是直接替换当前的历史记录。
window.history.pushState(null,null,path)
window.history.replaceState(null,null,path)
面试官:Vue的路由钩子函数有哪些?
1、全局的路由钩子函数
** ** 1.1、beforeEach(全局前置钩子),意思是在每次每一个路由改变的时候都要执行 一遍
它有三个参数: to: route:即将要进入的目标 路由对象 from:route:当前导航正要离开的路由 next:function:一定要调用该方法来resolve这个钩子。执行效果依赖next方法 应用场景: 1、进行一些页面跳转前的处理,例如跳转到的页面需要进行登录才可以访问时, 就会做登录的跳转 2、进入页面登录判断、管理员权限判断、浏览器判断 **1.2、afterEach**(全局后置钩子) beforeEach是在页面加载之前的,而afterEach是在页面加载之后的,所以这些钩子是 不会接受next函数,也不会改变导航本身2、单个路由内的钩子函数
** 2.1、beforeEnter** 可以直接在路由配置上直接定义beforeEnter,这些守卫与全局前置守卫的方法参数是 一样的3、组件内的路由钩子函数
**beforeRouteEnter、beforeRouteUpdate、beforeRouteLeave** 应用场景 1、清除组件中的定时器 2、当页面有未关闭的窗口,或未保存的内容时,组织页面跳转 3、保存相关内容到Vuex和Session中
面试官:为什么Vue中data一定要是一个函数?
data必须是一个函数, 函数的好处就是每一次组件复用之后都会产生一个全新的data. 组件与组件之间各自维护自己的数据, 互不干扰
面试官:Proxy 相比较于 defineProperty 的优势
Object.defineProperty
是监听对象的字段而非对象本身,因此对于动态插入对象的字段,它无能为了,只能手动为其设置设置监听属性。
同时,
Object.defineProperty
无法监听对象中数组的变化
Proxy 叫做代理器,它可以为一个对象设置代理,即监听对象本身,任何访问当前被监听的对象的操作,无论是对象本身亦或是对象的字段,都会被 Proxy 拦截,因此可以使用它来做一些双向绑定的操作。
鉴于兼容性的问题,目前仍然主要是使用 Object.defineProperty 更多,但是随着 Vue/3 的发布,Proxy 应该会逐渐淘汰 Object.defineProperty。
面试官:ES5、ES6和ES2015有什么区别?
ES2015特指在2015年发布的新一代JS语言标准,ES6泛指下一代JS语言标准,包含ES2015、ES2016、ES2017、ES2018等。现阶段在绝大部分场景下,ES2015默认等同ES6。ES5泛指上一代语言标准。ES2015可以理解为ES5和ES6的时间分界线。
面试官:babel是什么,有什么作用?
babel是一个 ES6 转码器,可以将 ES6 代码转为 ES5 代码,以便兼容那些还没支持ES6的平台。
面试官:let有什么用,有了var为什么还要用let?
在ES6之前,声明变量只能用var,var方式声明变量其实是很不合理的,准确的说,是因为ES5里面没有块级作用域是很不合理的,
没有块级作用域回来带很多难以理解的问题,比如for循环var变量泄露,变量覆盖等问题。let 声明的变量拥有自己的块级作用域,且修复了var声明变量带来的变量提升问题
面试官:举一些ES6对String字符串类型做的常用升级优化?
1、优化部分:
ES6新增了字符串模板,在拼接大段字符串时,用反斜杠(`)取代以往的字符串相加的形式,能保留所有空格和换行,使得字符串拼接看起来更加直观,更加优雅。2、升级部分:
ES6在String原型上新增了includes()方法,用于取代传统的只能用indexOf查找包含字符的方法(indexOf返回-1表示没查到不如includes方法返回false更明确,语义更清晰), 此外还新增了startsWith(), endsWith(),padStart(),padEnd(),repeat()等方法,可方便的用于查找,补全字符串。
面试官:举一些ES6对Array数组类型做的常用升级优化?
1、优化部分:
a. 数组解构赋值。ES6可以直接以let [a,b,c] = [1,2,3]形式进行变量赋值,在声明较多变量时,不用再写很多let(var),且映射关系清晰,且支持赋默认值。b. 扩展运算符。ES6新增的扩展运算符(...)(重要),可以轻松的实现数组和松散序列的相互转化,可以取代arguments对象和apply方法,轻松获取未知参数个数情况下的参数集合。
(尤其是在ES5中,arguments并不是一个真正的数组,而是一个类数组的对象,但是扩展运算符的逆运算却可以返回一个真正的数组)。扩展运算符还可以轻松方便的实现数组的复制和解构赋值(let a = [2,3,4]; let b = [...a])。
2、升级部分:
ES6在Array原型上新增了find()方法,用于取代传统的只能用indexOf查找包含数组项目的方法,且修复了indexOf查找不到NaN的bug([NaN].indexOf(NaN) === -1).此外还新增了copyWithin(), includes(), fill(),flat()等方法,可方便的用于字符串的查找,补全,转换等。
面试官:举一些ES6对Number数字类型做的常用升级优化?
1、优化部分:
ES6在Number原型上新增了isFinite(), isNaN()方法,用来取代传统的全局isFinite(), isNaN()方法检测数值是否有限、是否是NaN。ES5的isFinite(), isNaN()方法都会先将非数值类型的参数转化为Number类型再做判断,这其实是不合理的,最造成isNaN('NaN') === true的奇怪行为--'NaN'是一个字符串,但是isNaN却说这就是NaN。而Number.isFinite()和Number.isNaN()则不会有此类问题(Number.isNaN('NaN') === false)。(isFinite()同上)2、升级部分:
ES6在Math对象上新增了Math.cbrt(),trunc(),hypot()等等较多的科学计数法运算方法,可以更加全面的进行立方根、求和立方根等等科学计算。
面试官:举一些ES6对Object类型做的常用升级优化?(重要)
1、优化部分:
a. 对象属性变量式声明。ES6可以直接以变量形式声明对象属性或者方法,。比传统的键值对形式声明更加简洁,更加方便,语义更加清晰。let [apple, orange] = ['red appe', 'yellow orange']; let myFruits = {apple, orange}; // let myFruits = {apple: 'red appe', orange: 'yellow orange'};尤其在对象解构赋值(见优化部分b.)或者模块输出变量时,这种写法的好处体现的最为明显:
let {keys, values, entries} = Object; let MyOwnMethods = {keys, values, entries}; // let MyOwnMethods = {keys: keys, values: values, entries: entries}可以看到属性变量式声明属性看起来更加简洁明了。方法也可以采用简洁写法:
let es5Fun = { method: function(){} }; let es6Fun = { method(){} }b. 对象的解构赋值。ES6对象也可以像数组解构赋值那样,进行变量的解构赋值:
let {apple, orange} = {apple: 'red appe', orange: 'yellow orange'};c. 对象的扩展运算符(...)。ES6对象的扩展运算符和数组扩展运算符用法本质上差别不大,毕竟数组也就是特殊的对象。对象的扩展运算符一个最常用也最好用的用处就在于可以轻松的取出一个目标对象内部全部或者部分的可遍历属性,从而进行对象的合并和分解。
let {apple, orange, ...otherFruits} = {apple: 'red apple', orange: 'yellow orange', grape: 'purple grape', peach: 'sweet peach'}; // otherFruits {grape: 'purple grape', peach: 'sweet peach'} // 注意: 对象的扩展运算符用在解构赋值时,扩展运算符只能用在最有一个参数(otherFruits后面不能再跟其他参数) let moreFruits = {watermelon: 'nice watermelon'}; let allFruits = {apple, orange, ...otherFruits, ...moreFruits};d. super 关键字。ES6在Class类里新增了类似this的关键字super。同this总是指向当前函数所在的对象不同,super关键字总是指向当前函数所在对象的原型对象。
2、升级部分:
a. ES6在Object原型上新增了is()方法,做两个目标对象的相等比较,用来完善'==='方法。'==='方法中NaN === NaN //false其实是不合理的,Object.is修复了这个小bug。(Object.is(NaN, NaN) // true)b. ES6在Object原型上新增了assign()方法,用于对象新增属性或者多个对象合并。
const target = { a: 1 }; const source1 = { b: 2 }; const source2 = { c: 3 }; Object.assign(target, source1, source2); target // {a:1, b:2, c:3}注意:assign合并的对象target只能合并source1、source2中的自身属性,并不会合并source1、source2中的继承属性,也不会合并不可枚举的属性,且无法正确复制get和set属性(会直接执行get/set函数,取return的值)。
c. ES6在Object原型上新增了getOwnPropertyDescriptors()方法,此方法增强了ES5中getOwnPropertyDescriptor()方法,可以获取指定对象所有自身属性的描述对象。结合defineProperties()方法,可以完美复制对象,包括复制get和set属性。
d. ES6在Object原型上新增了getPrototypeOf()和setPrototypeOf()方法,用来获取或设置当前对象的prototype对象。这个方法存在的意义在于,ES5中获取设置prototype对象是通过__proto__属性来实现的,然而__proto__属性并不是ES规范中的明文规定的属性,只是浏览器各大厂商“私自”加上去的属性,只不过因为适用范围广而被默认使用了,再非浏览器环境中并不一定就可以使用,所以为了稳妥起见,获取或设置当前对象的prototype对象时,都应该采用ES6新增的标准用法。
d. ES6在Object原型上还新增了**Object.keys(),Object.values(),Object.entries()**方法,用来获取对象的所有键、所有值和所有键值对数组。
面试官:举一些ES6对Function函数类型做的常用升级优化?(重要)
** 1、优化部分:**
a. 箭头函数(核心)。箭头函数是ES6核心的升级项之一,箭头函数里没有自己的this,这改变了以往JS函数中最让人难以理解的this运行机制。主要优化点:
Ⅰ. 箭头函数内的this指向的是函数定义时所在的对象,而不是函数执行时所在的对象。ES5函数里的this总是指向函数执行时所在的对象,这使得在很多情况下this的指向变得很难理解,尤其是非严格模式情况下,this有时候会指向全局对象,这甚至也可以归结为语言层面的bug之一。ES6的箭头函数优化了这一点,它的内部没有自己的this,这也就导致了this总是指向上一层的this,如果上一层还是箭头函数,则继续向上指,直到指向到有自己this的函数为止,并作为自己的this。
Ⅱ. 箭头函数不能用作构造函数,因为它没有自己的this,无法实例化。
Ⅲ. 也是因为箭头函数没有自己的this,所以箭头函数 内也不存在arguments对象。(可以用扩展运算符代替)
b. 函数默认赋值。ES6之前,函数的形参是无法给默认值的,只能在函数内部通过变通方法实现。ES6以更简洁更明确的方式进行函数默认赋值。
function es6Fuc (x, y = 'default') {
console.log(x, y);
}
es6Fuc(4) // 4, default
2、升级部分:
ES6新增了双冒号运算符,用来取代以往的bind,call,和apply。(浏览器暂不支持,Babel已经支持转码)
foo::bar;
// 等同于
bar.bind(foo);
foo::bar(...arguments);
// 等同于
bar.apply(foo, arguments);
面试官:CSS预编译
一、什么是CSS预编译?
CSS 预编译,就是预先编译处理CSS。它扩展了 CSS 语言,增加了变量、Mixin、函数等编程的特性,使 CSS 更易维护和扩展。CSS预编译的工作原理是提供便捷的语法和特性供开发者编写源代码,随后经过专门的编译工具将源码转化为CSS语法。
二、为什么要使用CSS预编译?
- CSS缺点:
- 语法不够强大,比如无法嵌套书写,导致模块化开发中需要书写很多重复的选择器;
- 没有变量和合理的样式复用机制,使得逻辑上相关的属性值必须以字面量的形式重复输出,导致难以维护。
- CSS预编译优点:
- 可以提供 CSS 缺失的样式层复用机制、减少冗余代码,提高样式代码的可维护性。大大提高了开发效率。
- 增强编程能力;增强可复用性;增强可维护性;更便于解决浏览器兼容性
- CSS预编译缺点:
- CSS的好处在于简便、随时随地被使用和调试。预编译CSS步骤的加入,让我们开发工作流中多了一个环节,调试也变得更麻烦了。更大的问题在于,预编译很容易造成后代选择器的滥用。所以我们在实际项目中衡量预编译方案时,还是得想想,比起带来的额外维护开销,CSS预处理器有没有解决更大的麻烦
- 不同的预编译器特性虽然有所差异,但核心功能均围绕这些目标打造,比如:
- 嵌套(所有预编译器都支持的语法特性,也是原生CSS最让开发者头疼的问题之一)
- 变量(增强了源码的可编程能力)
- 运算(增强了源码的可编程能力)
- mixin/继承(为了解决hack和代码复用)
- 模块化(不仅更利于代码复用,同时也提高了源码的可维护性)
四、CSS预处理器的选择
1、Sass
**优点**
1) 用户多,更容易找到会用scss的开发,更容易找到scss的学习资源;
2) 可编程能力比较强,支持函数,列表,对象,判断,循环等;
3) 相比less有更多的功能;
4) Bootstrap/Foundation等使用scss;
5) 丰富的sass库:Compass/Bourbon;
**缺点**
安装node-sass会经常失败或者报错,需要使用cnpm或者手工安装
2、Less
**优点**
可以在浏览器中运行,实现主题定制功能;
**缺点**
编程能力弱,不直接支持对象,循环,判断等;
@variable 变量命名和css的@import/media/keyframes等含义容易混淆;
mixin/extend的语法比较奇怪;
mixin的参数如果遇到多参数和列表参数值的时候容易混淆;
3、Stylus
**优点**
来自NodeJS社区,所以和NodeJS走得很近,与JavaScript联系非常紧密。还有专门JavaScript API:
http://learnboost.github.io/stylus/docs/js.html
支持Ruby之类等等框架3.更多更强大的支持和功能
**缺点**
人气不高和教程较少
总结:
Sass看起来在提供的特性上占有优势,但是LESS能够让开发者平滑地从现存CSS文件过渡到LESS,而不需要像Sass那样需要将CSS文件转换成Sass格式。Stylus功能上更为强壮,和js联系更加紧密。
面试官:DNS的解析过程
什么是 DNS
DNS 即域名系统,全称是 Domain Name System。当我们在浏览器输入一个 URL 地址时,浏览器要向这个 URL 的主机名对应的服务器发送请求,就得知道服务器的 IP,对于浏览器来说,DNS 的作用就是将主机名转换成 IP 地址。
DNS 是:
- 一个由分层的 DNS 服务器实现的分布式数据库
- 一个使得主机能够查询分布式数据库的应用层协议
也就是,DNS 是一个应用层协议,我们发送一个请求,其中包含我们要查询的主机名,它就会给我们返回这个主机名对应的 IP;
其次,DNS 是一个分布式数据库,整个 DNS 系统由分散在世界各地的很多台 DNS 服务器组成,每台 DNS 服务器上都保存了一些数据,这些数据可以让我们最终查到主机名对应的 IP。
所以 DNS 的查询过程,说白了,就是去向这些 DNS 服务器询问,你知道这个主机名的 IP 是多少吗,不知道?那你知道去哪台 DNS 服务器上可以查到吗?直到查到我想要的 IP 为止。
**分布式、层次数据库 **
什么是分布式?
这个世界上没有一台 DNS 服务器拥有因特网上所有主机的映射,每台 DNS 只负责部分映射。
什么是层次?
DNS 服务器有 3 种类型:根 DNS 服务器、顶级域(Top-Level Domain, TLD)DNS 服务器和权威 DNS 服务器。它们的层次结构如下图所示:
- 根 DNS 服务器
首先我们要明确根域名是什么,比如
www.baidu.com,有些同学可能会误以为
com就是根域名,其实
com是顶级域名,
www.baidu.com的完整写法是
www.baidu.com.,最后的这个
.就是根域名。
根 DNS 服务器的作用是什么呢?就是管理它的下一级,也就是顶级域 DNS 服务器。通过询问根 DNS 服务器,我们可以知道一个主机名对应的顶级域 DNS 服务器的 IP 是多少,从而继续向顶级域 DNS 服务器发起查询请求。
- 顶级域 DNS 服务器
除了前面提到的
com是顶级域名,常见的顶级域名还有
cn、
org、
edu等。顶级域 DNS 服务器,也就是 TLD,提供了它的下一级,也就是权威 DNS 服务器的 IP 地址。
- 权威 DNS 服务器
权威 DNS 服务器可以返回主机 - IP 的最终映射。
关于这几个层次的服务器之间是怎么交互的,接下来我们会讲到 DNS 具体的查询过程,结合查询过程,大家就不难理解它们之间的关系了。
**本地 DNS 服务器 **
之前对 DNS 有过了解的同学可能会发现,上一节的 DNS 层次结构,为什么没有提到本地 DNS 服务器?因为严格来说,本地 DNS 服务器并不属于 DNS 的层次结构,但它对 DNS 层次结构是至关重要的。那什么是本地 DNS 服务器呢?
每个 ISP 都有一台本地 DNS 服务器,比如一个居民区的 ISP、一个大学的 ISP、一个机构的 ISP,都有一台或多台本地 DNS 服务器。当主机发出 DNS 请求时,该请求被发往本地 DNS 服务器,本地 DNS 服务器起着代理的作用,并负责将该请求转发到 DNS 服务器层次结构中。
接下来就让我们通过一个简单的例子,看看 DNS 的查询过程是怎样的,看看客户端、本地 DNS 服务器、DNS 服务器层次结构之间是如何交互的。
** 递归查询、迭代查询**
如下图,假设主机
m.n.com想要获取主机
a.b.com的 IP 地址,会经过以下几个步骤:
- 首先,主机
m.n.com向它的本地 DNS 服务器发送一个 DNS 查询报文,其中包含期待被转换的主机名a.b.com;- 本地 DNS 服务器将该报文转发到根 DNS 服务器;
- 该根 DNS 服务器注意到
com前缀,便向本地 DNS 服务器返回com对应的顶级域 DNS 服务器(TLD)的 IP 地址列表。意思就是,我不知道a.b.com的 IP,不过这些 TLD 服务器可能知道,你去问他们吧;- 本地 DNS 服务器则向其中一台 TLD 服务器发送查询报文;
- 该 TLD 服务器注意到
b.com前缀,便向本地 DNS 服务器返回权威 DNS 服务器的 IP 地址。意思就是,我不知道a.b.com的 IP,不过这些权威服务器可能知道,你去问他们吧;- 本地 DNS 服务器又向其中一台权威服务器发送查询报文;
- 终于,该权威服务器返回了
a.b.com的 IP 地址;- 本地 DNS 服务器将
a.b.com跟 IP 地址的映射返回给主机m.n.com,m.n.com就可以用该 IP 向a.b.com发送请求啦。
“你说了这么多,递归呢?迭代呢?”
这位同学不要捉急,其实递归和迭代已经包含在上述过程里了。
主机
m.n.com向本地 DNS 服务器
dns.n.com发出的查询就是递归查询,这个查询是主机
m.n.com以自己的名义向本地 DNS 服务器请求想要的 IP 映射,并且本地 DNS 服务器直接返回映射结果给到主机。
而后继的三个查询是迭代查询,包括本地 DNS 服务器向根 DNS 服务器发送查询请求、本地 DNS 服务器向 TLD 服务器发送查询请求、本地 DNS 服务器向权威 DNS 服务器发送查询请求,所有的请求都是由本地 DNS 服务器发出,所有的响应都是直接返回给本地 DNS 服务器。
那么问题来了,所有的 DNS 查询都必须遵循这种递归 + 迭代的模式吗?
当然不是。
从理论上讲,任何 DNS 查询既可以是递归的,也可以是迭代的。下图的所有查询就都是递归的,不包含迭代。
看到这里,大家可能会有个疑问,TLD 一定知道权威 DNS 服务器的 IP 地址吗?
还真不一定,有时 TLD 只是知道中间的某个 DNS 服务器,再由这个中间 DNS 服务器去找到权威 DNS 服务器。这种时候,整个查询过程就需要更多的 DNS 报文。
** DNS 缓存**
为了让我们更快的拿到想要的 IP,DNS 广泛使用了缓存技术。DNS 缓存的原理非常简单,在一个 DNS 查询的过程中,当某一台 DNS 服务器接收到一个 DNS 应答(例如,包含某主机名到 IP 地址的映射)时,它就能够将映射缓存到本地,下次查询就可以直接用缓存里的内容。当然,缓存并不是永久的,每一条映射记录都有一个对应的生存时间,一旦过了生存时间,这条记录就应该从缓存移出。
事实上,有了缓存,大多数 DNS 查询都绕过了根 DNS 服务器,需要向根 DNS 服务器发起查询的请求很少。
面试官:为什么Vue中的v-if和v-for不建议一起用?
v-for 优先级是比 v-if 高
这时候我们可以看到,v-for 与 v-if 作用再不同标签时候,是先进性判断,再进行列表的渲染
注意事项
- 永远不要把 v-if 和 v-for 同时用在一个元素上,带来性能方面的浪费(每次渲染都会先循环再进行条件判断)
- 如果避免出现这种情况,则在外层嵌套 template (页面渲染不生成dom节点),再这一层进行 v-if 判断,然后再内部进行 v-for 循环
- 如果条件出现再循环内部,可通过计算属性 computed 提前过滤掉那些不需要显示的项
面试官:vue插槽(slot)的使用
vue的slot分为三种::匿名插槽,具名插槽, 作用域插槽
作用:让父组件可以向子组件指定位置插入 html 结构,也是一种组件间通信的方式,适用于父组 件=>子组件
一.**匿名插槽 **
1)带有插槽 的组件 TipsText.vue(子组件)
<slot>作为我们想要插入内容的占位符——就这么简单!
//子组件 <template> <div> <div>hello world</div> <slot></slot> </div> </template> //父组件 <template> <div> <tips-text> <template v-slot> <div>我是匿名插槽</div> </template> </tips-text> </div> </template> <script> import TipsText from './TipsText.vue' export default { components:{ TipsText } } </script>二.具名插槽 (给插槽加入name属性就是具名插槽)
//子组件 <template> <div> <div>hello world</div> <slot name="one"></slot> <slot name="two"></slot> </div> </template> //父组件 <template> <div> <tips-text> <template v-slot:one> <div>我是具名插槽one</div> </template> <template v-slot:two> <div>我是具名插槽two</div> </template> </tips-text> </div> </template> <script> import TipsText from './TipsText.vue' export default { components:{ TipsText } } </script>三.作用域插槽
//子组件 <template> <div> <div>hello world</div> <!-- ⼦组件中告诉⽗组件,要实现obj⾥的信息 --> <slot :info="info.title"></slot> <slot :info="info.msg"></slot> <slot :info="info.text"></slot> </div> </template> <script> import { reactive } from "vue"; export default { setup() { const info = reactive({ title:'作用域插槽', msg:'lalalalalala', text:'how are you' }) return { info } } } </script> //父组件 <template> <div> <tips-text> <template v-slot:default="slotProps" > <div>{{slotProps.info}}</div> </template> <template v-slot:other="slotProps" > <div>{{slotProps.info}}</div> <div>{{slotProps.text}}</div> </template> </tips-text> </div> </template> <script> import TipsText from './TipsText.vue' export default { components:{ TipsText } } </script>
面试官:如何创建插件
1、新建一个plugins.js的文件(文件名可以不是plugins)
2、plugins.js内容:
必须有install()函数,第一参数是Vue的构造函数,剩余参数可自己传入
// plugins.js
export default {
install(Vue) {
console.log('使用插件了')
// 自定义全局获取焦点指令
Vue.directive('focus',{
inserted: function(el){
// el代表绑定的元素
el.focus();
}
})
// 定义一个全局过滤器 ---- 字母转大写
Vue.filter('toUpperCase', function(val){
return val.toUpperCase();
});
// 添加一个混入
Vue.mixin({
data() {
return {
mixData: '这是mixin中数据',
x: 100,
}
},
created () {
console.log(this.y)
},
methods: {
handleClick() {
console.log(this.name)
}
},
computed: {
showNumber() {
return this.x + this.y
}
}
})
// 给Vue原型上添加一个方法
Vue.prototype.hello = () => {
alert("你好啊")
}
}
}
面试官:HTTP 和 HTTPS
HTTP请求的格式
HTTP的请求分成四个部分:
1、请求行;
HTTP方法:大概,描述了这个请求想要干什么,例如get意思就是想从服务器获取到什么
URL:描述了要访问的网络上的资源具体是在哪
版本号:表示当前使用的HTTP的版本是什么,目前常用的版本是1.1
2、请求报头;
这一部分一般有很多行,每一行都是一个键值对,键和值之间通过 :空格 来分割。
3、空行;
请求头的结束标志
4、请求正文
这一部分可有可无,有时候会存在有时候没有。
** HTTP响应的格式**
**1,状态行 **
版本号:代表当前HTTP协议的版本
状态码:描述了这个响应是表示成功还是失败的,以及不同的状态码也描述了失败的原因,常见的如404
状态码的描述:通过一个或是一组简短的单词描述了当前状态码的含义
2,响应头
也是键值对结构,每个键值对占一行,每个键和值之间通过 :空格 进行分割。响应头中的键值对个数是不确定的,不同的键值对也代表了不同的关系。
3, 空行
响应头的结束标志
4 ,响应正文
是服务器返回客户端的具体数据,可能会有各种不同的格式,其中最常见的格式就是HTNL。
** HTTP方法**
HTTP协议的方法有很多,其中常用的是GET和POST。
** 1、GET方法**
GET方法用于使用给定的URI从给定服务器中检索信息,即从指定资源中请求数据。使用GET方法的请求应该只是检索数据,并且不应对数据产生其他影响。2、POST方法
POST方法用于将数据发送到服务器以创建或更新资源,它要求服务器确认请求中包含的内容作为由URI区分的Web资源的另一个下属。POST请求永远不会被缓存,且对数据长度没有限制;我们无法从浏览器历史记录中查找到POST请求。
3、HEAD方法
HEAD方法与GET方法相同,但没有响应体,仅传输状态行和标题部分。这对于恢复相应头部编写的元数据非常有用,而无需传输整个内容。
4、PUT方法
从客户端向服务器传送的数据取代指定的文档的内容。
PUT方法用于将数据发送到服务器以创建或更新资源,它可以用上传的内容替换目标资源中的所有当前内容。它会将包含的元素放在所提供的URI下,如果URI指示的是当前资源,则会被改变。如果URI未指示当前资源,则服务器可以使用该URI创建资源。
5、DELETE方法
DELETE方法用来删除指定的资源,它会删除URI给出的目标资源的所有当前内容。
6、CONNECT方法
HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。
CONNECT方法用来建立到给定URI标识的服务器的隧道;它通过简单的TCP / IP隧道更改请求连接,通常实使用解码的HTTP代理来进行SSL编码的通信(HTTPS)。7、OPTIONS方法
OPTIONS方法用来描述了目标资源的通信选项,会返回服务器支持预定义URL的HTTP策略。
8、TRACE方法
TRACE方法用于沿着目标资源的路径执行消息环回测试;它回应收到的请求,以便客户可以看到中间服务器进行了哪些(假设任何)进度或增量。
HTTP特点:
1.无状态:协议对客户端没有状态存储,对事物处理没有“记忆”能力,比如访问一个网站需要反复进行登录操作
2.无连接:HTTP/1.1之前,由于无状态特点,每次请求需要通过TCP三次握手四次挥手,和服务器重新建立连接。比如某个客户机在短时间多次请求同一个资源,服务器并不能区别是否已经响应过用户的请求,所以每次需要重新响应请求,需要耗费不必要的时间和流量。
3.基于请求和响应:基本的特性,由客户端发起请求,服务端响应
4.简单快速、灵活
5.通信使用明文、请求和响应不会对通信方进行确认、无法保护数据的完整性
HTTPS特点:
- 内容加密:采用混合加密技术,中间者无法直接查看明文内容
- 验证身份:通过证书认证客户端访问的是自己的服务器
- 保护数据完整性:防止传输的内容被中间人冒充或者篡改
** 常见状态码**
1xx:信息提示
2xx:成功
3xx:重定向
4xx:客户端错误
5xx:服务器错误
1xx: 接受,继续处理200: 成功,并返回数据201: 已创建202: 已接受203: 成为,但未授权204: 成功,无内容205: 成功,重置内容206: 成功,部分内容301: 永久移动,重定向302: 临时移动,可使用原有URI304: 资源未修改,可使用缓存305: 需代理访问400: 请求语法错误401: 要求身份认证403: 拒绝请求404: 资源不存在500: 服务器错误
面试官:你们项目RESTful API设计规范是什么?
动词+宾语
RESTful的核心思想就是,客户端发出的数据+操作指令都是“动词+宾语”的结构,比如GET /articles这个命令,GET是动词,/articles是宾语,动词通常就有5种HTTP请求方法,对应CRUD操作,根据 HTTP 规范,动词一律大写。
GET:读取(Read)
POST:新建(Create)
PUT:更新(Update)
PATCH:更新(Update),通常是部分更新
DELETE:删除(Delete)
动词的覆盖
有些客户端只能使用GET和POST这两种方法。服务器必须接受POST模拟其他三个方法(PUT、PATCH、DELETE)。这时,客户端发出的 HTTP 请求,要加上X-HTTP-Method-Override属性,告诉服务器应该使用哪一个动词,覆盖POST方法。
宾语必须是名词
宾语就是 API 的 URL,是 HTTP 动词作用的对象。它应该是名词,不能是动词。比如,/articles这个 URL 就是正确的,而下面的 URL 不是名词,所以都是错误的。
复数 URL
既然 URL 是名词,那么应该使用复数,还是单数?这没有统一的规定,但是常见的操作是读取一个集合,比如GET /articles(读取所有文章),这里明显应该是复数。
避免多级 URL
常见的情况是,资源需要多级分类,因此很容易写出多级的 URL,比如获取卖手游账号平台某个作者的某一类文章。
# GET /authors/12/categories/2
这种 URL 不利于扩展,语义也不明确,往往要想一会,才能明白含义。
总 结:Restful API的接口架构风格中制定了一些规范,极大的简化了前后端对接的时间,以及增加了开发效率,在实际开发中,比如在获取列表分页的时候,对于查询参数过多的接口,会导致uri的长度过长、请求失败,在这种情况下的接口就不能完全按照Restful API的请求规范来。Restful API也就只是一种接口架构的风格,接口API永远不会强约束于此,因按照实际需求做出相应的接口需改。
面试官:git代码回滚
git回退历史,有以下步骤:
1.已push后回退:
(1) 使用git log命令,查看分支提交历史,确认需要回退版本的<commit_id>
(2) 使用git reset --hard <commit_id>命令或者git revert <commit_id>,进行版本回退(此时本地已回退)
(3) 在git commit后,再次使用git push origin <分支名> --force命令,推送至远程分支(此时线上版本已回退)
快捷命令:git reset --hard HEAD^
注:HEAD是指向当前版本的指针,HEAD^表示上个版本,HEAD^^表示上上个版本
revert和reset的区别:
(1) 在实际生产环境中,代码是基于master分支发布到线上的,会有多人进行提交。可能会碰到自己或团队其他成员开发的某个功能在上线之后有Bug,需要及时做代码回滚的操作。
在确认要回滚的版本之后,如果别人没有最新提交,那么就可以直接用reset命令进行版本回退,否则,就可以考虑使用revert命令进行还原修改,不能影响到别人的提交。
(2) reset命令会把要回退版本之后提交的修改都删除。要从第三次修改回退到第一次修改,那么会删除第二、三次的修改。【注:这里并不是真正的物理删除】
如果发现第二次修改有错误,想要恢复第二次修改,却要保留第三次修改,使用revert命令,其产生了新的commit_id。
**2.提交到暂存区后(执行
git add后)回退:**
git reset HEAD <file_name>命令撤销提交到暂存区的内容,再使用
git checkout -- <file_name>命令,来清空工作区的修改
**3.工作区(执行
git add前)回退:**
git checkout -- <file_name>命令,来清空工作区的修改
面试官:react的Component和PureComponent
介绍
React.PureComponent 与 React.Component 几乎完全相同,但 React.PureComponent 通过props和state的浅对比来实现 shouldComponentUpate()。
在PureComponent中,如果包含比较复杂的数据结构,可能会因深层的数据不一致而产生错误的否定判断,导致界面得不到更新。
如果定义了 shouldComponentUpdate(),无论组件是否是 PureComponent,它都会执行shouldComponentUpdate结果来判断是否 update。如果组件未实现 shouldComponentUpdate() ,则会判断该组件是否是 PureComponent,如果是的话,会对新旧 props、state 进行 shallowEqual 比较,一旦新旧不一致,会触发 update。
浅对比:通过遍历对象上的键执行相等性,并在任何键具有参数之间不严格相等的值时返回false。 当所有键的值严格相等时返回true。shallowEqual
不同:
PureComponent自带通过props和state的浅对比来实现 shouldComponentUpate(),而Component没有。
PureComponent缺点
可能会因深层的数据不一致而产生错误的否定判断,从而shouldComponentUpdate结果返回false,界面得不到更新。PureComponent优势
不需要开发者自己实现shouldComponentUpdate,就可以进行简单的判断来提升性能。
面试官: CSS3新增伪类有那些
:root选择文档的根元素,等同于 html 元素:empty选择没有子元素的元素:target选取当前活动的目标元素:not(selector)选择除selector元素意外的元素:enabled选择可用的表单元素:disabled选择禁用的表单元素:checked选择被选中的表单元素:after在元素内部最前添加内容:before在元素内部最后添加内容:nth-child(n)匹配父元素下指定子元素,在所有子元素中排序第n:nth-last-child(n)匹配父元素下指定子元素,在所有子元素中排序第n,从后向前数:nth-child(odd):nth-child(even):nth-child(3n+1):first-child:last-child:only-child:nth-of-type(n)匹配父元素下指定子元素,在同类子元素中排序第n:nth-last-of-type(n)匹配父元素下指定子元素,在同类子元素中排序第n,从后向前数:nth-of-type(odd):nth-of-type(even):nth-of-type(3n+1):first-of-type:last-of-type:only-of-type::selection选择被用户选取的元素部分:first-line选择元素中的第一行:first-letter选择元素中的第一个字符
面试官:useMemo和useCallback的区别及使用场景
useMemo和useCallback都是reactHook提供的两个API,用于缓存数据,优化性能;两者接收的参数都是一样的,第一个参数表示一个回调函数,第二个表示依赖的数据。
共同作用
在依赖数据发生变化的时候,才会调用传进去的回调函数去重新计算结果,起到一个缓存的作用
两者的区别
useMemo 缓存的结果是回调函数中return回来的值,主要用于缓存计算结果的值,应用场景如需要计算的状态
useCallback 缓存的结果是函数,主要用于缓存函数,应用场景如需要缓存的函数,因为函数式组件每次任何一个state发生变化,会触发整个组件更新,一些函数是没有必要更新的,此时就应该缓存起来,提高性能,减少对资源的浪费;另外还需要注意的是,useCallback应该和React.memo配套使用,缺了一个都可能导致性能不升反而下降。
面试官:路由跳转方式name 、 path 和传参方式params 、query的区别
**
path 和 Name路由跳转方式,都可以用query传参params传参,push里面只能是 name:'xxx',不能是path:'/xxx',因为params只能用name来引入路由,如果这里写成了path,接收参数页面会是undefined!!!**
面试官:数组的原理
带着疑问,本文将从以下几个方面分享一下数组原理及应用
1.什么是线性表
2.什么是数组
3.数组下标为什么从0开始
4.数组的常规操作
线性表
首先在讲解数组前先理解线性表和非线性表,因为数组属于线性结构的一种
什么是线性表
线性表:(linear list)线性表就是数据排成像一条线一样的结构。每个线性表上的数据最多只有前和后两个方向,是一个有序数据元素的集合。

线性表包含:数组、链表、队列、栈等都是线性表结构。
图例如下:
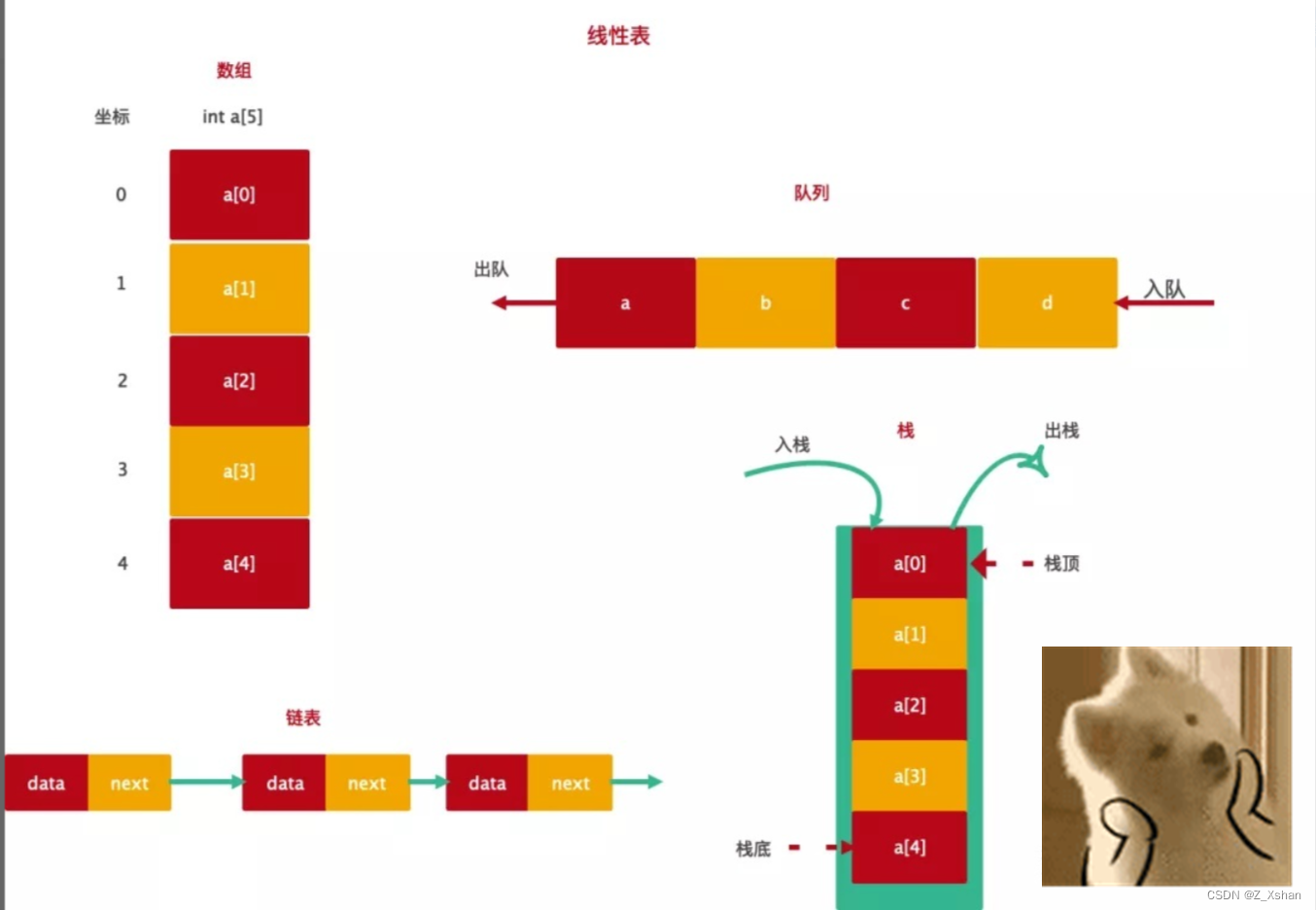
什么是非线性表
非线性表:与线性表相对立的概念是非线性表。之所以叫非线性,是因为,在非线性表中,数据之间并不是简单的前后关系。
非线性表:二叉树、堆、图等,图例如下:
数组
什么是数组
数组:数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。

数组原理
先来说一下数组的存储原理:数组用一组连续的内存空间来存储一组具有相同类型的数据。

数组可以根据下标随机访问数据
比如一个整型数据 int[] 长度为5
- 假设首地址是:1000
- int是4字节(32位),实际内存存储是位
- 随机元素寻址
//上图详细公试:
a[i]_address=a[0]_address+i*4
//通用公式:
//base_address首地址相当于a[0],data_type_size 表示数组中每个元素的大小 案例4个字节
a[i]_address = base_address + i * data_type_size
base_address首地址相当于a[0]。
data_type_size 表示数组中每个元素的大小,假设4个字节。
该公式解释了三个方面
- 连续性分配
- 相同的类型
- 下标从0开始
数组操作
读取元素
根据下标读取元素的方式叫作随机读取
案例:int n=nums[3]
/**
* 获取元素
* @param index
* @return
*/
public int get(int index){
return nums[index];
}
更新元素
案例:nums[3]= 8;
/**
* 通过数组下标更新数组元素
* @param index
* @param n
*/
public void update(int index,int n){
nums[index] = n;
}
注意不要数组越界
读取和更新都可以随机访问,时间复杂度为O(1)
插入元素 有三种情况:
尾部插入
在数据的实际元素数量小于数组长度的情况下:
直接把插入的元素放在数组尾部的空闲位置即可,等同于更新元素的操作
尾部插入的时间复杂度为O(1)
中间插入
在数据的实际元素数量小于数组长度的情况下:
由于数组的每一个元素都有其固定下标,所以首先把插入位置及后面的元素向后移动,腾出地方,再把要插入的元素放到对应的数组位置上。
中间插入或头部插入的时间复杂度为O(n)
范围插入
假如现在有一个数组,已经装满了元素,这时还想插入一个新元素,或者插入位置是越界的,这时就要对原数组进行扩容:可以创建一个新数组,长度是旧数组的2倍,再把旧数组中的元素统统复制过去,这样就实现了数组的扩容。
删除元素
数组的删除操作和插入操作的过程相反,如果删除的元素位于数组中间,其后的元素都需要向前挪
动1位。
尾部删除最好的时候复杂度O(1)
头部删除或中间删除都需要移动元素时间复杂度O(n)
数组如何实现的随机访问?
数组连续的内存空间和相同类型的数据。正是因为这两个特性,从而才使得数组有随机访问的能力;
缺点:这两个特性也让数组的很多操作变得非常低效,比如要想在数组中删除、插入一个数据,为了保证连续性,就需要做大量的数据搬移工作。
面试官: 介绍下资源预加载 prefetch/preload
都是告知浏览器提前加载文件(图片、视频、js、css等),但执行上是有区别的。
prefetch:其利用浏览器空闲时间来下载或预取用户在不久的将来可能访问的文档。<link href="/js/xx.js" rel="prefetch">preload: 可以指明哪些资源是在页面加载完成后即刻需要的,浏览器在主渲染机制介入前就进行预加载,这一机制使得资源可以更早的得到加载并可用,且更不易阻塞页面的初步渲染,进而提升性能。<link href="/js/xxx.js" rel="preload" as="script">需要as指定资源类型目前可用的属性类型有如下:audio: 音频文件。 document: 一个将要被嵌入到<frame>或<iframe>内部的HTML文档。 embed: 一个将要被嵌入到<embed>元素内部的资源。 fetch: 那些将要通过fetch和XHR请求来获取的资源,比如一个ArrayBuffer或JSON文件。 font: 字体文件。 image: 图片文件。 object: 一个将会被嵌入到<embed>元素内的文件。 script: JavaScript文件。 style: 样式表。 track: WebVTT文件。 worker: 一个JavaScript的web worker或shared worker。 video: 视频文件。
面试官:有写过原生的自定义事件吗
创建自定义事件
原生自定义事件有三种写法:
- 使用
Event
let myEvent = new Event('event_name');
2.使用
customEvent
(可以传参数)
let myEvent = new CustomEvent('event_name', {
detail: {
// 将需要传递的参数放到这里
// 可以在监听的回调函数中获取到:event.detail
}
})
3.使用
document.createEvent('CustomEvent')和initCustomEvent()
let myEvent = document.createEvent('CustomEvent');// 注意这里是为'CustomEvent'
myEvent.initEvent(
// 1. event_name: 事件名称
// 2. canBubble: 是否冒泡
// 3. cancelable: 是否可以取消默认行为
)
createEvent:创建一个事件initEvent:初始化一个事件
可以看到,
initEvent
可以指定3个参数。
(有些文章中会说还有第四个参数
detail
,但是我查看了
W3C
上并没有这个参数,而且实践了一下也没有效果)
事件的监听
自定义事件的监听其实和普通事件的一样,使用
addEventListener
来监听:
button.addEventListener('event_name', function (e) {})
事件的触发
触发自定义事件使用
dispatchEvent(myEvent)
。
注意⚠️,这里的参数是要自定义事件的对象(也就是
myEvent
),而不是自定义事件的名称(
'myEvent'
)
案例
来看个案例吧:
// 1.
// let myEvent = new Event('myEvent');
// 2.
// let myEvent = new CustomEvent('myEvent', {
// detail: {
// name: 'lindaidai'
// }
// })
// 3.
let myEvent = document.createEvent('CustomEvent');
myEvent.initEvent('myEvent', true, true)
let btn = document.getElementsByTagName('button')[0]
btn.addEventListener('myEvent', function (e) {
console.log(e)
console.log(e.detail)
})
setTimeout(() => {
btn.dispatchEvent(myEvent)
}, 2000)
面试官:target="_blank"有哪些问题?
存在问题:
- 安全隐患:新打开的窗口可以通过
window.opener获取到来源页面的window对象即使跨域也可以。某些属性的访问被拦截,是因为跨域安全策略的限制。 但是,比如修改window.opener.location的值,指向另外一个地址,这样新窗口有可能会把原来的网页地址改了并进行页面伪装来欺骗用户。 - 新打开的窗口与原页面窗口共用一个进程,若是新页面有性能不好的代码也会影响原页面
解决方案:
- 尽量不用
target="_blank" - 如果一定要用,需要加上
rel="noopener"或者rel="noreferrer"。这样新窗口的window.openner就是null了,而且会让新窗口运行在独立的进程里,不会拖累原来页面的进程。(不过,有些浏览器对性能做了优化,即使不加这个属性,新窗口也会在独立进程打开。不过为了安全考虑,还是加上吧。)
版权归原作者 Z_Xshan 所有, 如有侵权,请联系我们删除。