
1、DolphinScheduler简介
1.1、DolphinScheduler概述
Apache DolphinScheduler是一个新一代分布式、易扩展的可视化大数据工作流任务调度平台,致力于“解决大数据任务之间错综复杂的依赖关系,整个数据处理开箱即用”。它以 DAG(有向无环图) 的方式将任务连接起来,可实时监控任务的运行状态,同时支持重试、从指定节点恢复失败、暂停及 Kill 任务等操作。
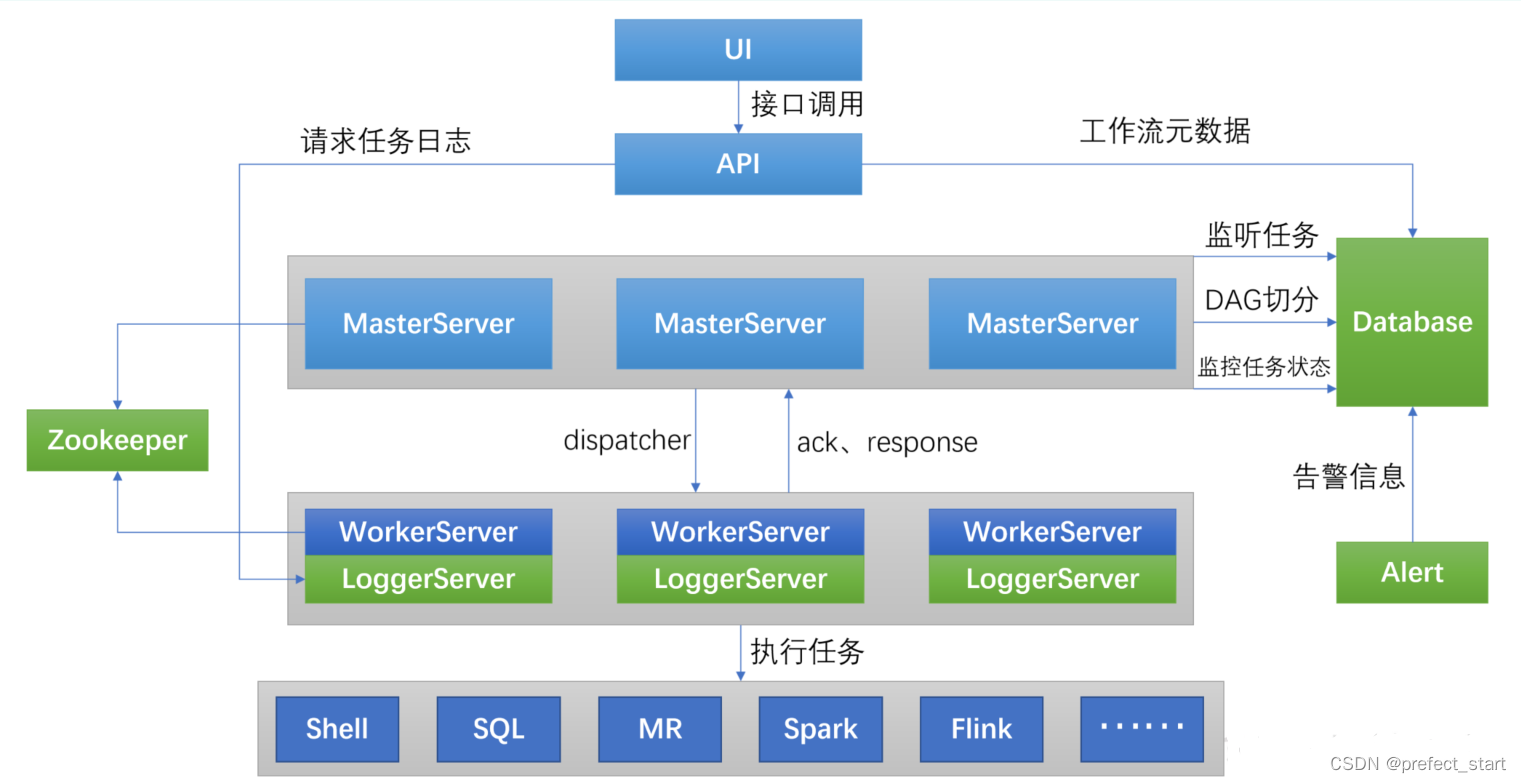
1.2、DolphinScheduler核心架构
DolphinScheduler的主要角色如下:
- MasterServer采用分布式无中心设计理念,MasterServer主要负责 DAG 任务切分、任务提交、任务监控,并同时监听其它MasterServer和WorkerServer的健康状态,MasterServer服务启动时向Zookeeper注册临时节点,通过监听Zookeeper临时节点变化来进行容错处理, MasterServer基于netty提供监听服务。
- WorkerServer也采用分布式无中心设计理念,WorkerServer主要负责任务的执行和提供日志服务,WorkerServer服务启动时向Zookeeper注册临时节点,并维持心跳。 Server基于netty提供监听服务。
- ZooKeeper服务,系统中的MasterServer和WorkerServer节点都通过ZooKeeper来进行集群管理和容错,另外系统还基于ZooKeeper进行事件监听和分布式锁。
- Alert服务,提供告警相关服务。
- API接口层,主要负责处理前端UI层的请求。
- UI,系统的前端页面,提供系统的各种可视化操作界面
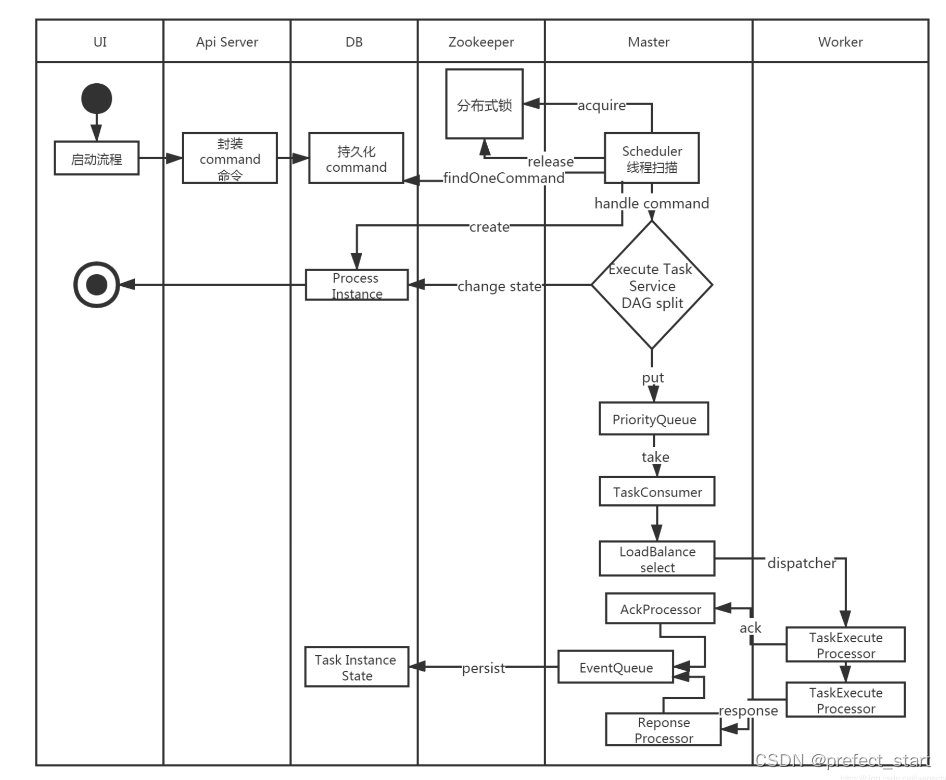
1.3、DolphinScheduler的启动流程活动图
2、DolphinScheduler部署说明
2.1、软硬件环境要求
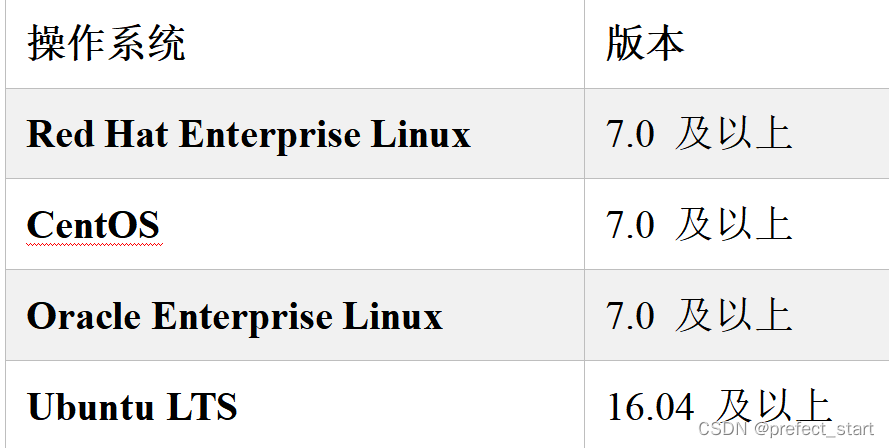
2.1.1、操作系统版本要求
2.1.2、服务器硬件要求

2.2、部署模式
DolphinScheduler支持多种部署模式.
- 单机模式(Standalone)
- 伪集群模式(Pseudo-Cluster)
- 集群模式(Cluster)
2.2.1、单机模式
单机模式(standalone)模式下,所有服务均集中于一个StandaloneServer进程中,并且其中内置了注册中心Zookeeper和数据库H2。
只需配置JDK环境,就可一键启动DolphinScheduler,快速体验其功能,只适合学习使用。
2.2.2、伪集群模式
伪集群模式(Pseudo-Cluster)是在单台机器部署 DolphinScheduler 各项服务,该模式下master、worker、api server、logger server等服务都只在同一台机器上。Zookeeper和数据库需单独安装并进行相应配置,适用于测试环境使用,不可上生产。
2.2.3、集群模式
集群模式(Cluster)与伪集群模式的区别就是在多台机器部署 DolphinScheduler各项服务,并且可以配置多个Master及多个Worker,生产环境使用。
2.3、DolphinScheduler集群模式部署
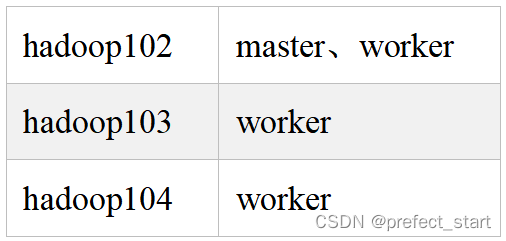
2.3.1、集群规划
集群模式下,可配置多个Master及多个Worker。通常可配置2~3个Master,若干个Worker。由于集群资源有限,此处配置一个Master,三个Worker,集群规划如下。
2.3.2、前置准备工作
- 三台节点均需部署JDK(1.8+),并配置相关环境变量。
- 需部署数据库,支持MySQL(5.7+)或者PostgreSQL(8.2.15+)。如 MySQL 则需要 JDBC Driver 8.0.16。
- 需部署Zookeeper(3.4.6+)。
- 如果启用 HDFS 文件系统,则需要 Hadoop(2.6+)环境。
- 三台节点均需安装进程管理工具包psmisc。
[song@hadoop102 ~]$ sudo yum install -y psmisc
[song@hadoop103 ~]$ sudo yum install -y psmisc
[song@hadoop104 ~]$ sudo yum install -y psmisc
2.3.3、解压DolphinScheduler安装包
- 上传DolphinScheduler安装包到hadoop102节点的/opt/software目录
- 解压安装包到当前目录
注:解压目录并非最终的安装目录
[song@hadoop102 software]$ tar -zxvf apache-dolphinscheduler-2.0.3-bin
解压后的目录结构如下图所示:
├─bin DS命令存放目录
│ ├─dolphinscheduler-daemon.sh 启动/关闭DS服务脚本
│ ├─start-all.sh 根据配置文件启动所有DS服务
│ ├─stop-all.sh 根据配置文件关闭所有DS服务
├─conf 配置文件目录
│ ├─application-api.properties api服务配置文件
│ ├─datasource.properties 数据库配置文件
│ ├─zookeeper.properties zookeeper配置文件
│ ├─master.properties master服务配置文件
│ ├─worker.properties worker服务配置文件
│ ├─quartz.properties quartz服务配置文件
│ ├─common.properties 公共服务[存储]配置文件
│ ├─alert.properties alert服务配置文件
│ ├─config 环境变量配置文件夹
│ ├─install_config.conf DS环境变量配置脚本[用于DS安装/启动]
│ ├─env 运行脚本环境变量配置目录
│ ├─dolphinscheduler_env.sh 运行脚本加载环境变量配置文件[如: JAVA_HOME,HADOOP_HOME, HIVE_HOME ...]
│ ├─org mybatis mapper文件目录
│ ├─i18n i18n配置文件目录
│ ├─logback-api.xml api服务日志配置文件
│ ├─logback-master.xml master服务日志配置文件
│ ├─logback-worker.xml worker服务日志配置文件
│ ├─logback-alert.xml alert服务日志配置文件
├─sql DS的元数据创建升级sql文件
│ ├─create 创建SQL脚本目录
│ ├─upgrade 升级SQL脚本目录
│ ├─dolphinscheduler_postgre.sql postgre数据库初始化脚本
│ ├─dolphinscheduler_mysql.sql mysql数据库初始化脚本
│ ├─soft_version 当前DS版本标识文件
├─script DS服务部署,数据库创建/升级脚本目录
│ ├─create-dolphinscheduler.sh DS数据库初始化脚本
│ ├─upgrade-dolphinscheduler.sh DS数据库升级脚本
│ ├─monitor-server.sh DS服务监控启动脚本
│ ├─scp-hosts.sh 安装文件传输脚本
│ ├─remove-zk-node.sh 清理zookeeper缓存文件脚本
├─ui 前端WEB资源目录
├─lib DS依赖的jar存放目录
├─install.sh 自动安装DS服务脚本
2.4、初始化数据库
DolphinScheduler 元数据存储在关系型数据库中,故需创建相应的数据库和用户,便于权限管理。
- 创建数据库
mysql> CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
- 创建用户
mysql> CREATE USER 'dolphinscheduler'@'%' IDENTIFIED BY 'dolphinscheduler';
注:若出现以下错误信息,表明新建用户的密码过于简单。
ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
可提高密码复杂度或者执行以下命令降低MySQL密码强度级别。
mysql> set global validate_password_length=4;
mysql> set global validate_password_policy=0;
- 赋予用户相应权限
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%';
mysql> flush privileges;
- 拷贝MySQL驱动到DolphinScheduler的解压目录下的lib中
[song@hadoop102 apache-dolphinscheduler-2.0.3-bin]$ cp/opt/software/mysql-connector-java-8.0.16.jar lib/
- 执行数据库初始化脚本,数据库初始化脚本位于DolphinScheduler解压目录下的script目录中,即
/opt/software/ds/apache-dolphinscheduler-2.0.3-bin/script/。
[song@hadoop102 apache-dolphinscheduler-2.0.3-bin]$ script/create-dolphinscheduler.sh
2.5、配置一键部署脚本
修改解压目录下的conf/config目录下的install_config.conf文件
[song@hadoop102 apache-dolphinscheduler-2.0.3-bin]$ vim conf/config/install_config.conf
2.5.1、原来的配置
## Licensed to the Apache Software Foundation (ASF) under one or more# contributor license agreements. See the NOTICE file distributed with# this work for additional information regarding copyright ownership.# The ASF licenses this file to You under the Apache License, Version 2.0# (the "License"); you may not use this file except in compliance with# the License. You may obtain a copy of the License at## http://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License.## 注意: 该配置文件中如果包含特殊字符,如: `.*[]^${}\+?|()@#&`, 请转义,# 示例: `[` 转义为 `\[`# 数据库类型, 目前仅支持 postgresql 或者 mysql
dbtype="mysql"# 数据库 地址 & 端口
dbhost="192.168.xx.xx:3306"# 数据库 名称
dbname="dolphinscheduler"# 数据库 用户名
username="xx"# 数据库 密码
password="xx"# Zookeeper地址
zkQuorum="192.168.xx.xx:2181,192.168.xx.xx:2181,192.168.xx.xx:2181"# 将DS安装到哪个目录,如: /data1_1T/dolphinscheduler,
installPath="/data1_1T/dolphinscheduler"# 使用哪个用户部署# 注意: 部署用户需要sudo 权限, 并且可以操作 hdfs .# 如果使用hdfs的话,根目录必须使用该用户进行创建.否则会有权限相关的问题.
deployUser="dolphinscheduler"# 以下为告警服务配置# 邮件服务器地址
mailServerHost="smtp.exmail.qq.com"# 邮件服务器 端口
mailServerPort="25"# 发送者
mailSender="xxxxxxxxxx"# 发送用户
mailUser="xxxxxxxxxx"# 邮箱密码
mailPassword="xxxxxxxxxx"# TLS协议的邮箱设置为true,否则设置为false
starttlsEnable="true"# 开启SSL协议的邮箱配置为true,否则为false。注意: starttlsEnable和sslEnable不能同时为true
sslEnable="false"# 邮件服务地址值,同 mailServerHost
sslTrust="smtp.exmail.qq.com"#业务用到的比如sql等资源文件上传到哪里,可以设置:HDFS,S3,NONE。如果想上传到HDFS,请配置为HDFS;如果不需要资源上传功能请选择NONE。
resourceStorageType="NONE"# if S3,write S3 address,HA,for example :s3a://dolphinscheduler,# Note,s3 be sure to create the root directory /dolphinscheduler
defaultFS="hdfs://mycluster:8020"# 如果resourceStorageType 为S3 需要配置的参数如下:
s3Endpoint="http://192.168.xx.xx:9010"
s3AccessKey="xxxxxxxxxx"
s3SecretKey="xxxxxxxxxx"# 如果ResourceManager是HA,则配置为ResourceManager节点的主备ip或者hostname,比如"192.168.xx.xx,192.168.xx.xx",否则如果是单ResourceManager或者根本没用到yarn,请配置yarnHaIps=""即可,如果没用到yarn,配置为""
yarnHaIps="192.168.xx.xx,192.168.xx.xx"# 如果是单ResourceManager,则配置为ResourceManager节点ip或主机名,否则保持默认值即可。
singleYarnIp="yarnIp1"# 资源文件在 HDFS/S3 存储路径
resourceUploadPath="/dolphinscheduler"# HDFS/S3 操作用户
hdfsRootUser="hdfs"# 以下为 kerberos 配置# kerberos是否开启
kerberosStartUp="false"# kdc krb5 config file path
krb5ConfPath="$installPath/conf/krb5.conf"# keytab username
keytabUserName="[email protected]"# username keytab path
keytabPath="$installPath/conf/hdfs.headless.keytab"# api 服务端口
apiServerPort="12345"# 部署DS的所有主机hostname
ips="ds1,ds2,ds3,ds4,ds5"# ssh 端口 , 默认 22
sshPort="22"# 部署master服务主机
masters="ds1,ds2"# 部署 worker服务的主机# 注意: 每一个worker都需要设置一个worker 分组的名称,默认值为 "default"
workers="ds1:default,ds2:default,ds3:default,ds4:default,ds5:default"# 部署alert服务主机
alertServer="ds3"# 部署api服务主机
apiServers="ds1"
2.5.2、修改之后的配置
## Licensed to the Apache Software Foundation (ASF) under one or more# contributor license agreements. See the NOTICE file distributed with# this work for additional information regarding copyright ownership.# The ASF licenses this file to You under the Apache License, Version 2.0# (the "License"); you may not use this file except in compliance with# the License. You may obtain a copy of the License at## http://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License.## NOTICE : If the following config has special characters in the variable `.*[]^${}\+?|()@#&`, Please escape, for example, `[` escape to `\[`# postgresql or mysql
dbtype="mysql"# db config# db address and port
dbhost="hadoop102:3306"# db username
username="dolphinscheduler"# database name
dbname="dolphinscheduler"# db passwprd# NOTICE: if there are special characters, please use the \ to escape, for example, `[` escape to `\[`
password="xxx"# zk cluster
zkQuorum="hadoop102:2181,hadoop103:2181,hadoop104:2181"# Note: the target installation path for dolphinscheduler, please not config as the same as the current path (pwd)
installPath="/opt/model/dolphinscheduler"# deployment user# Note: the deployment user needs to have sudo privileges and permissions to operate hdfs. If hdfs is enabled, the root directory needs to be created by itself
deployUser="song"# alert config# mail server host 暂时不需要配 一键部署完毕之后 分别单独配置
mailServerHost="smtp.exmail.qq.com"# mail server port# note: Different protocols and encryption methods correspond to different ports, when SSL/TLS is enabled, make sure the port is correct.
mailServerPort="25"# sender
mailSender="xxxxxxxxxx"# user
mailUser="xxxxxxxxxx"# sender password# note: The mail.passwd is email service authorization code, not the email login password.
mailPassword="xxxxxxxxxx"# TLS mail protocol support
starttlsEnable="true"# SSL mail protocol support# only one of TLS and SSL can be in the true state.
sslEnable="false"#note: sslTrust is the same as mailServerHost
sslTrust="smtp.exmail.qq.com"# user data local directory path, please make sure the directory exists and have read write permissions
dataBasedirPath="/tmp/dolphinscheduler"# resource storage type: HDFS, S3, NONE
resourceStorageType="HDFS"# resource store on HDFS/S3 path, resource file will store to this hadoop hdfs path, self configuration, please make sure the directory exists on hdfs and have read write permissions. "/dolphinscheduler" is recommended
resourceUploadPath="/dolphinscheduler"# if resourceStorageType is HDFS,defaultFS write namenode address,HA you need to put core-site.xml and hdfs-site.xml in the conf directory.# if S3,write S3 address,HA,for example :s3a://dolphinscheduler,# Note,s3 be sure to create the root directory /dolphinscheduler
defaultFS="hdfs://hadoop102:8020"# if resourceStorageType is S3, the following three configuration is required, otherwise please ignore
s3Endpoint="http://192.168.xx.xx:9010"
s3AccessKey="xxxxxxxxxx"
s3SecretKey="xxxxxxxxxx"# resourcemanager port, the default value is 8088 if not specified
resourceManagerHttpAddressPort="8088"# if resourcemanager HA is enabled, please set the HA IPs; if resourcemanager is single, keep this value empty
yarnHaIps=
# if resourcemanager HA is enabled or not use resourcemanager, please keep the default value; If resourcemanager is single, you only need to replace ds1 to actual resourcemanager hostname
singleYarnIp="hadoop103"# who have permissions to create directory under HDFS/S3 root path# Note: if kerberos is enabled, please config hdfsRootUser=
hdfsRootUser="song"# kerberos config# whether kerberos starts, if kerberos starts, following four items need to config, otherwise please ignore
kerberosStartUp="false"# kdc krb5 config file path
krb5ConfPath="$installPath/conf/krb5.conf"# keytab username
keytabUserName="[email protected]"# username keytab path
keytabPath="$installPath/conf/hdfs.headless.keytab"# kerberos expire time, the unit is hour
kerberosExpireTime="2"# api server port
apiServerPort="12345"# install hosts# Note: install the scheduled hostname list. If it is pseudo-distributed, just write a pseudo-distributed hostname
ips="hadoop102,hadoop103,hadoop104"# ssh port, default 22# Note: if ssh port is not default, modify here
sshPort="22"# run master machine# Note: list of hosts hostname for deploying master
masters="hadoop102"# run worker machine# note: need to write the worker group name of each worker, the default value is "default"
workers="hadoop102:default,hadoop103:default,hadoop104:default"# run alert machine# note: list of machine hostnames for deploying alert server
alertServer="hadoop102"# run api machine# note: list of machine hostnames for deploying api server
apiServers="hadoop102"
2.6、一键部署DolphinScheduler
- 启动Zookeeper集群
[song@hadoop102 apache-dolphinscheduler-2.0.3-bin]$ zk.sh start
- 一键部署并启动DolphinScheduler
[song@hadoop102 apache-dolphinscheduler-2.0.3-bin]$ ./install.sh
- 查看DolphinScheduler进程
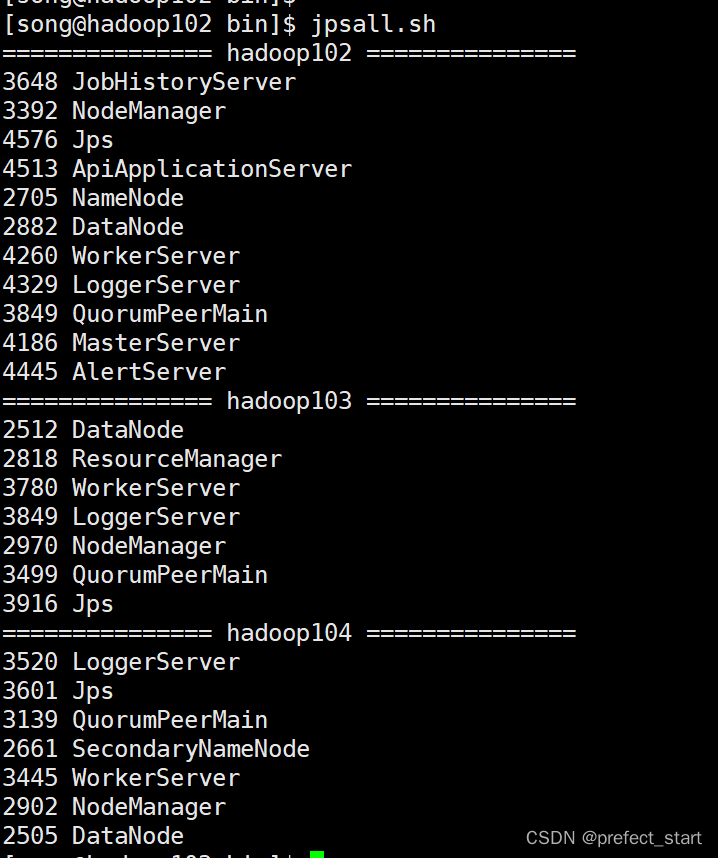
- 访问DolphinScheduler UI DolphinScheduler UI地址为http://hadoop102:12345/dolphinscheduler,初始用户的用户名为:admin,密码为dolphinscheduler123
2.7、DolphinScheduler启停命令
DolphinScheduler的启停脚本均位于其安装目录的bin目录下。
- 一键启停所有服务
./bin/start-all.sh
./bin/stop-all.sh
注意同Hadoop的启停脚本进行区分。
2. 启停 Master
./bin/dolphinscheduler-daemon.sh start master-server
./bin/dolphinscheduler-daemon.sh stop master-server
- 启停 Worker
./bin/dolphinscheduler-daemon.sh start worker-server
./bin/dolphinscheduler-daemon.sh stop worker-server
- 启停 Api
./bin/dolphinscheduler-daemon.sh start api-server
./bin/dolphinscheduler-daemon.sh stop api-server
- 启停 Logger
./bin/dolphinscheduler-daemon.sh start logger-server
./bin/dolphinscheduler-daemon.sh stop logger-server
- 启停 Alert
./bin/dolphinscheduler-daemon.sh start alert-server
./bin/dolphinscheduler-daemon.sh stop alert-server
2.8、dolphinscheduler_env.sh 环境变量配置
通过类似shell方式提交任务的的时候,会加载该配置文件中的环境变量到主机中. 涉及到的任务类型有: Shell任务、Python任务、Spark任务、Flink任务、Datax任务等等
export HADOOP_HOME=/opt/soft/hadoop
export HADOOP_CONF_DIR=/opt/soft/hadoop/etc/hadoop
export SPARK_HOME1=/opt/soft/spark1
export SPARK_HOME2=/opt/soft/spark2
export PYTHON_HOME=/opt/soft/python
export JAVA_HOME=/opt/soft/java
export HIVE_HOME=/opt/soft/hive
export FLINK_HOME=/opt/soft/flink
export DATAX_HOME=/opt/soft/datax/bin/datax.py
export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$PYTHON_HOME:$JAVA_HOME/bin:$HIVE_HOME/bin:$PATH:$FLINK_HOME/bin:$DATAX_HOME:$PATH
各服务日志配置文件: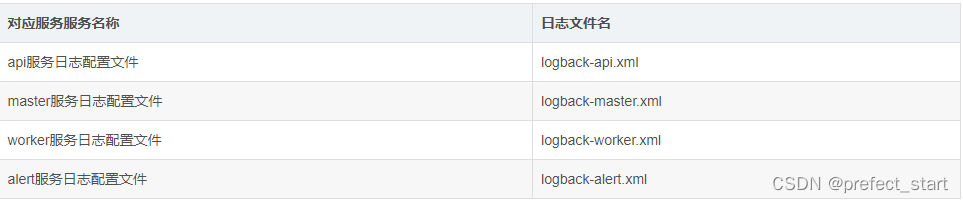
3、DolphinScheduler入门
3.1、安全中心配置
安全中心主要有租户管理、用户管理、告警组管理、告警实例管理、Worker分组管理、Yarn 队列管理、环境管理、令牌管理等功能。安全中心只有管理员账户才有操作权限。
3.1.1、租户管理
租户对应的是Linux的用户,用于worker提交作业所使用的用户。如果linux没有这个用户,则会导致任务运行失败。你可以通过修改 worker.properties 配置文件中参数
worker.tenant.auto.create=true(默认值为 false)
实现当 linux 用户不存在时自动创建该用户。worker.tenant.auto.create=true 参数会要求 worker 可以免密运行 sudo 命令。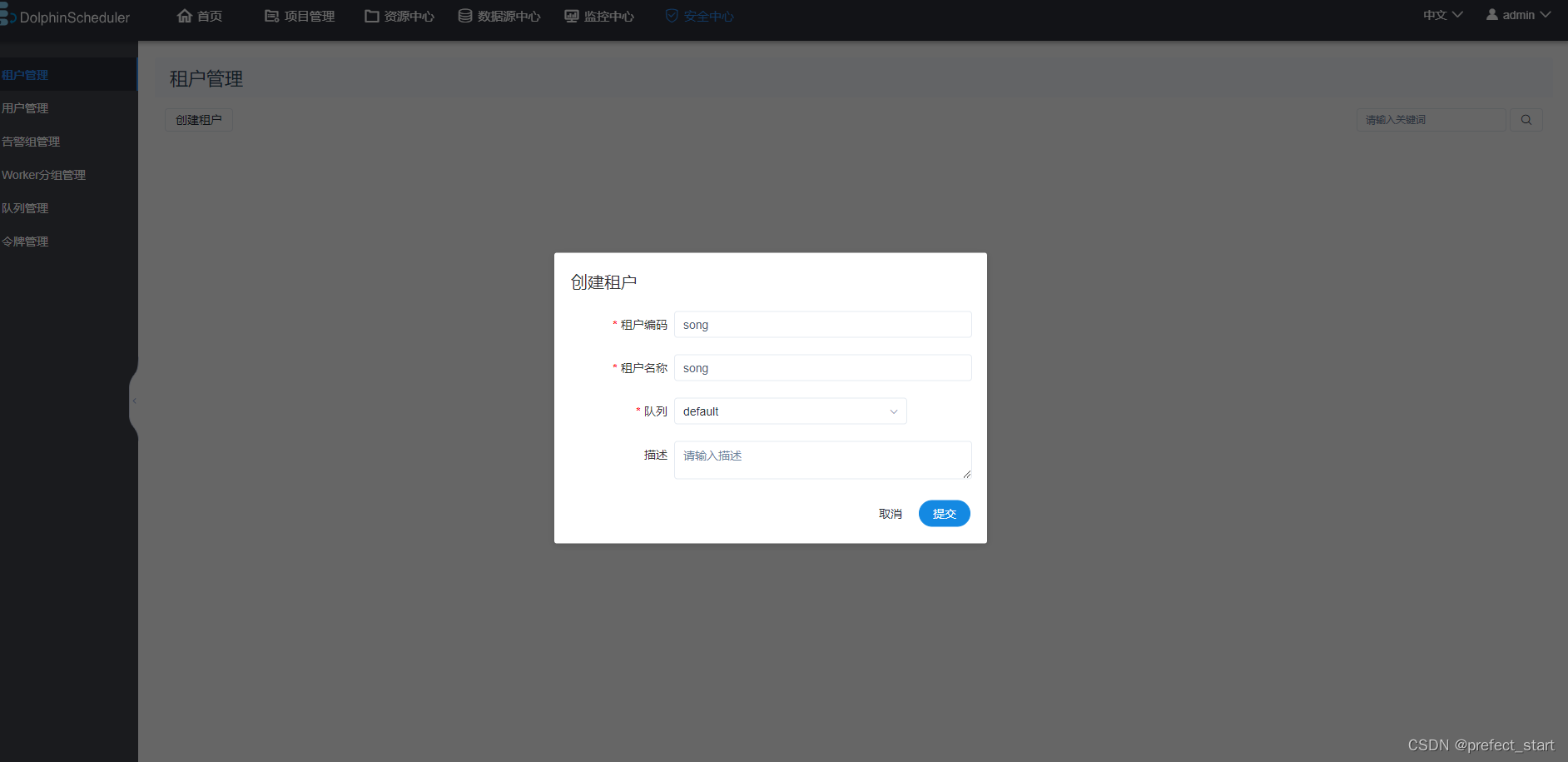
- 租户编码:租户编码是Linux上的用户,唯一,不能重复。
- 租户名称:对应;列显示的名称。
- 队列:该租户提交Yarn任务时的默认队列。
3.1.2、用户管理
用户对应的是DolphinScheduler的用户,用于登录DolphinScheduler。用户分管理员用户和普通用户。
- 管理员有授权和用户管理等权限,没有创建项目和工作流定义的操作的权限。
- 普通用户可以创建项目和对工作流定义的创建,编辑,执行等操作。
注意:如果该用户切换了租户,则该用户所在租户下所有资源将复制到切换的新租户下
此处创建一个普通用户song,如下图。
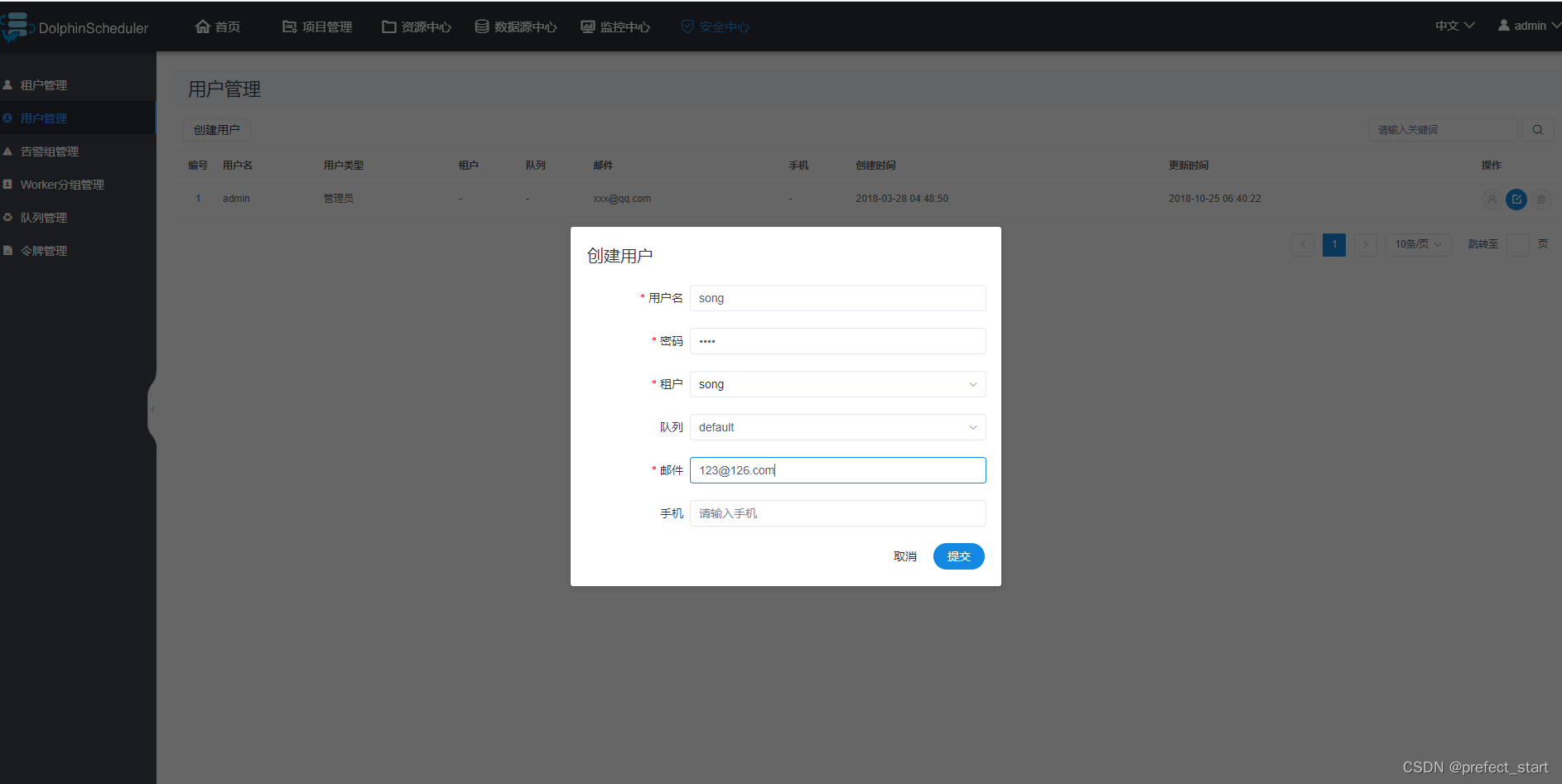
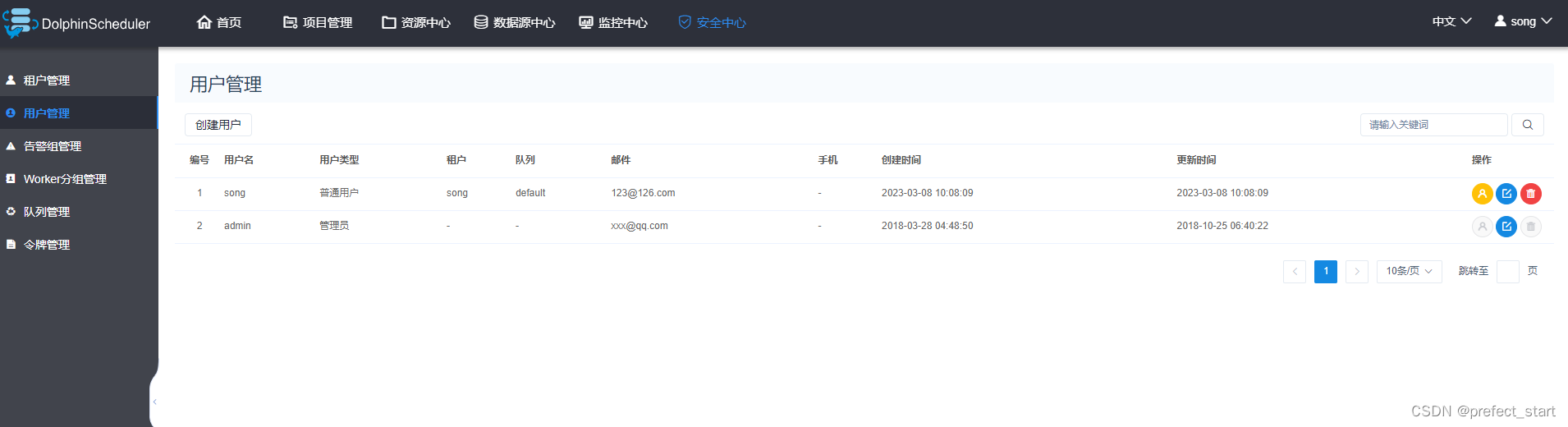
- 用户名:DolphinScheduler登录账户
- 租户:该用户关联的租户
- 队列:默认为租户所关联的队列。
- 邮件、手机号:主要用于告警通知。
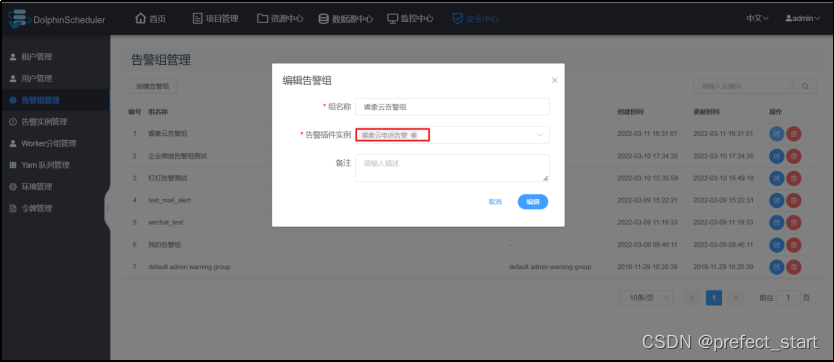
3.1.3、告警组管理
告警组是在启动时设置的参数,在流程结束以后会将流程的状态和其他信息以邮件形式发送给告警组。
管理员进入安全中心->告警组管理页面,点击“创建告警组”按钮,创建告警组。
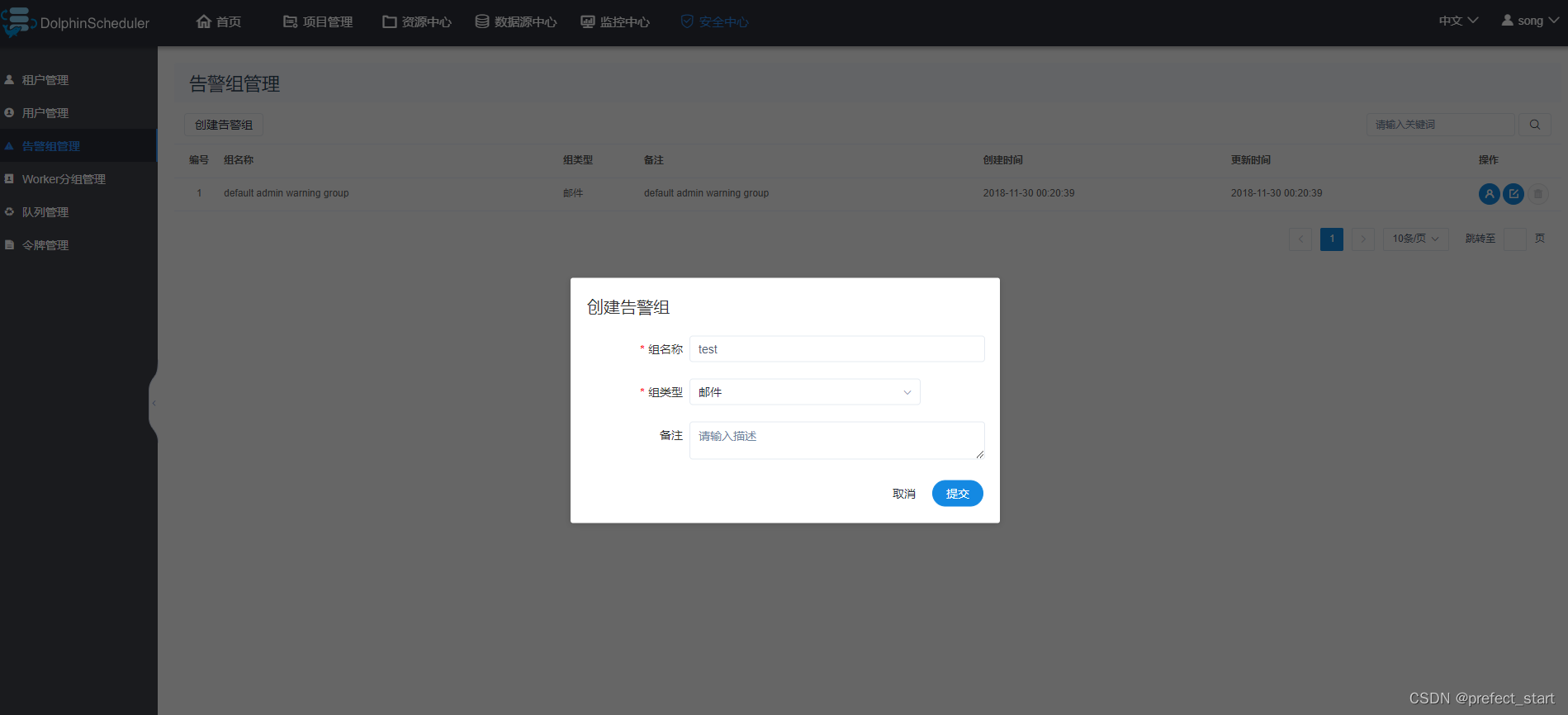
- 组名称:用户自定义的告警组名称。
- 告警插件实例:用户创建的告警实例。
3.1.4、Worker分组管理
在任务执行时,可以将任务分配给指定Worker组,最终由该组中的Worker节点执行该任务。每个worker节点都会归属于自己的Worker分组,默认分组为default。
3.1.4.1、Worker 分组修改方式一
打开要设置分组的worker节点上的"
conf/worker.properties
"配置文件. 修改worker.groups参数。
worker.groups参数后面对应的为该worker节点对应的分组名称,默认为default。
如果该worker节点对应多个分组,则以逗号隔开。
示例:
worker.groups=default,test
3.1.4.2、Worker 分组修改方式二
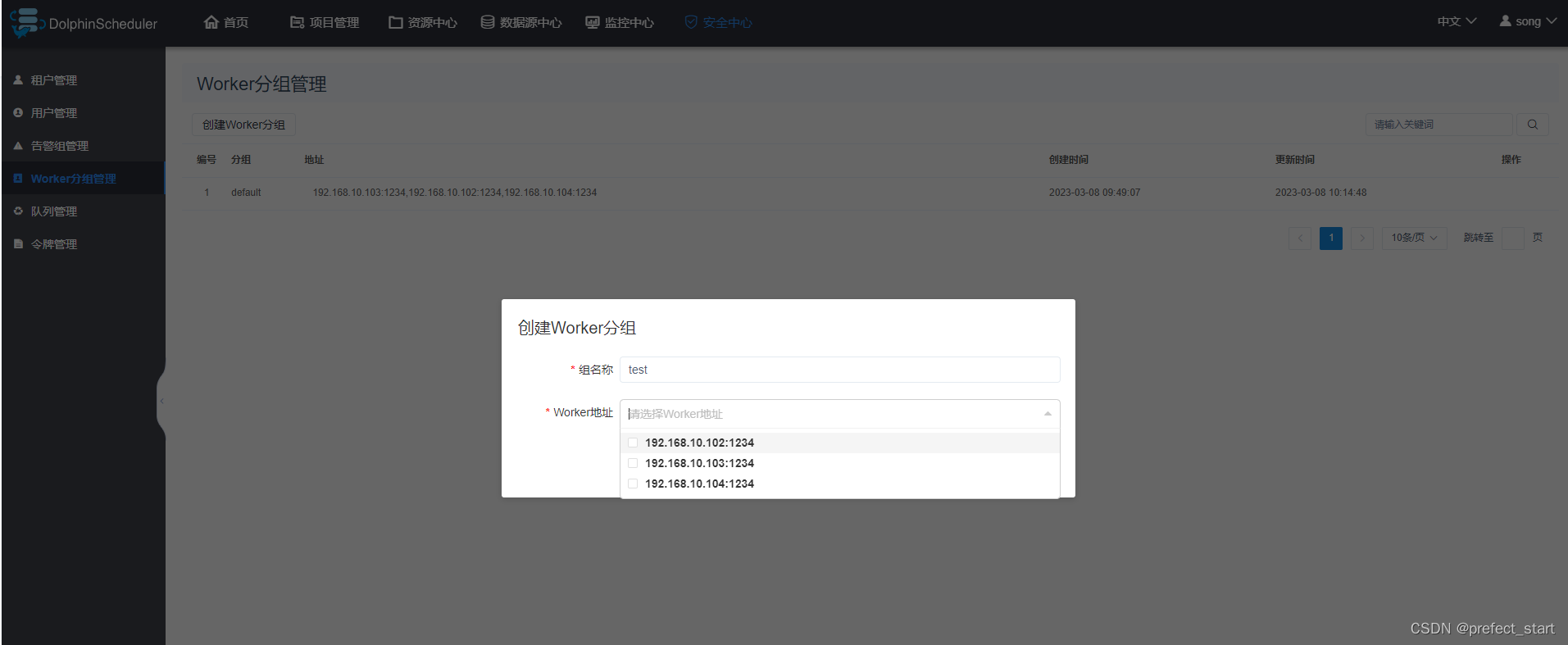
在运行中修改worker所属的worker分组,如果修改成功,worker就会使用这个新建的分组,忽略worker.properties中的配置。即方式二优先级高于方式一。
修改步骤为“安全中心 -> worker分组管理 -> 点击 ‘新建worker分组’ -> 输入’组名称’ -> 选择已有worker -> 点击’提交’”。如下图所示:
3.1.5、队列管理
队列是在执行spark、mapreduce等程序,需要用到“队列”参数时使用的,此处的队列对应的是Yarn调度器的资源队列。
故队列概念只对跑在Yarn上的任务类型有效。此处创建出的队列,可供后续任务进行选择。需要注意的是,在DolphinScheduler中创建队列,并不会影响到Yarn调度器的队列配置,此处可不创建队列。
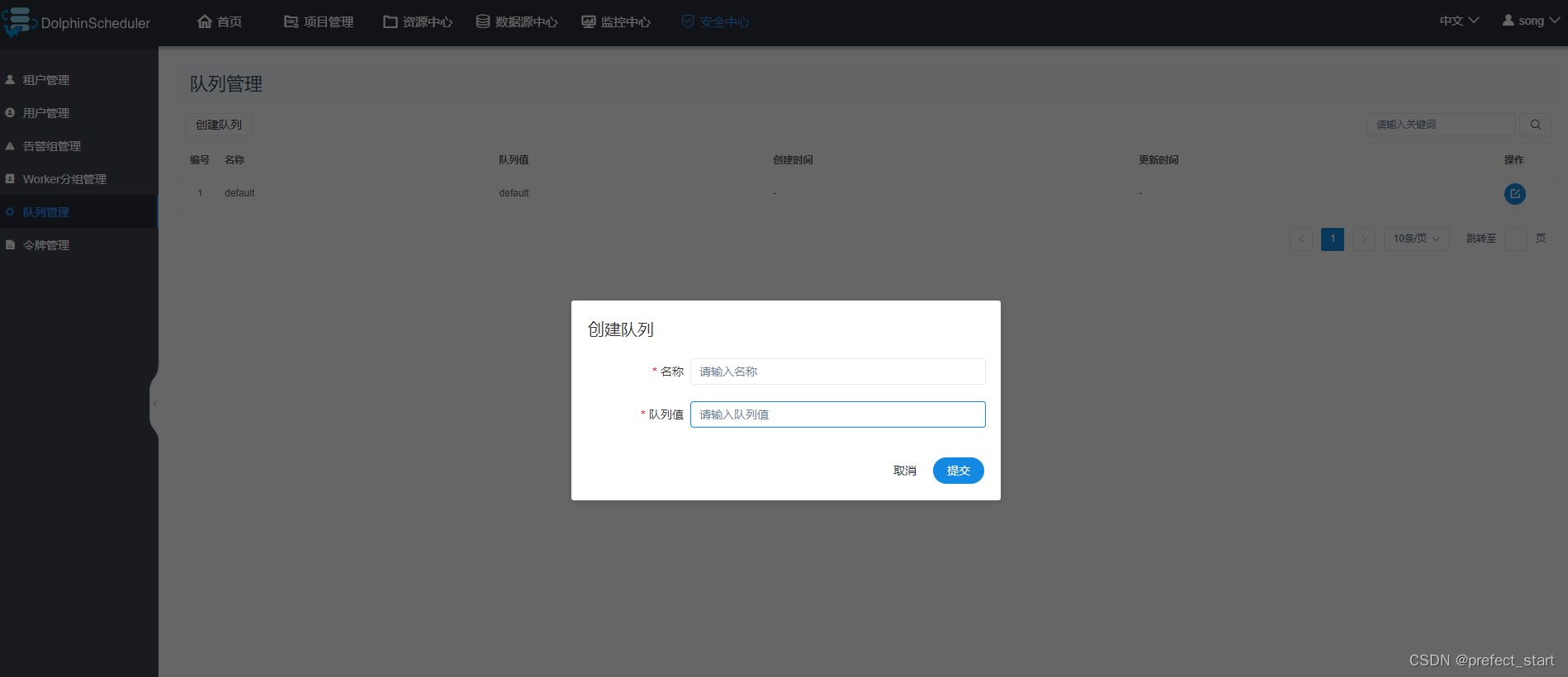
- 名称:DS 执行任务时可以选择的队列名称。
- 队列值:与名称相对应的 Yarn 调度队列的名称。
3.1.6、令牌管理
令牌用于通过接口访问DolphinScheduler各项服务时的用户验证。普通用户通过UI页面访问各项服务时,无需使用令牌。
若需将DolphinScheduler与第三方服务进行集成,则需调用其接口,此时需使用令牌。
3.2、项目管理
默认不使用管理员用户操作项目和工作流等,故需先切换到创建的普通用户song。
3.2.1、创建项目
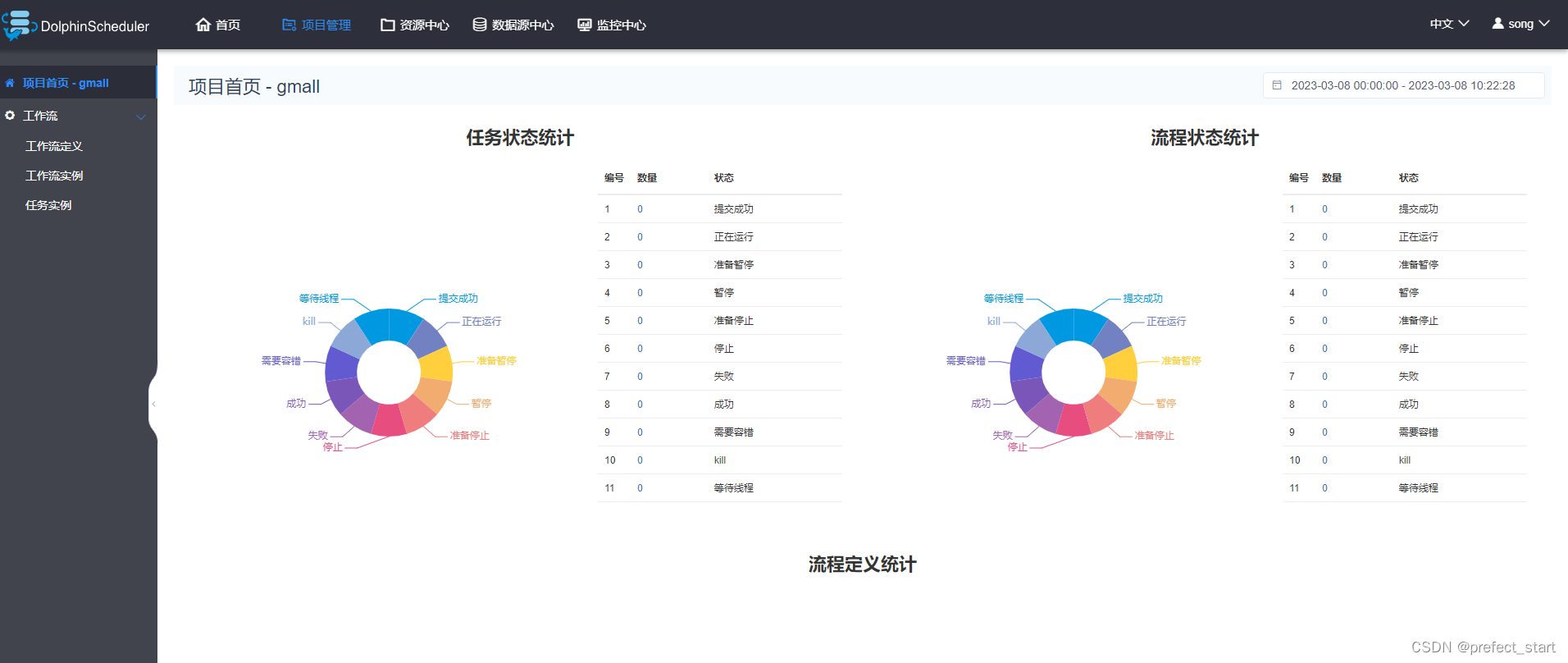
3.2.2、查看项目
3.2.3、工作流基础配置
下图为工作流配置页面,共包含三个模快,分别为工作流定义、工作流实例和任务实例。
- 工作流定义:用于定义工作流,包括工作流各节点任务详情及各节点依赖关系等。
- 工作流实例:工作流每执行一次就会生成一个工作流实例。此处可查看正在运行的工作流以及已经完成的工作流。
- 任务实例:工作流中的一个节点任务,每执行一次就会生成一个任务实例。此处可用于查看正在执行的节点任务以及已经完成的节点任务。
3.2.3.1、工作流定义
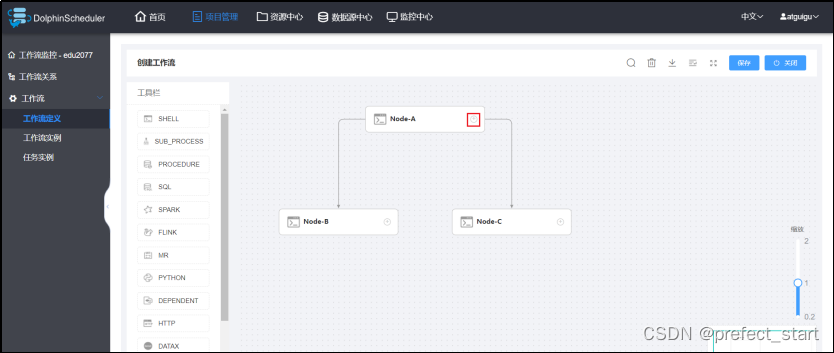
工作流要求:工作流需包含三个Shell类型的任务节点,分别是A,B,C。三个任务的依赖关系如下图所示: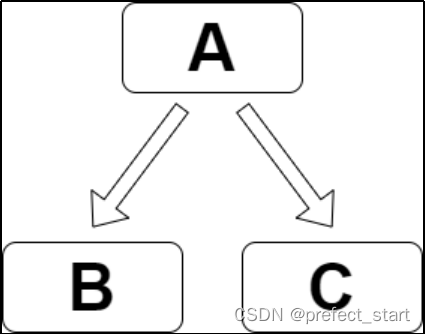
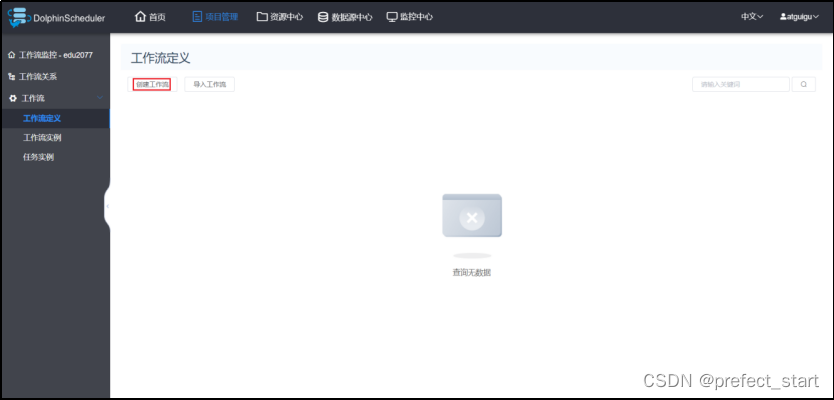
- 创建工作流
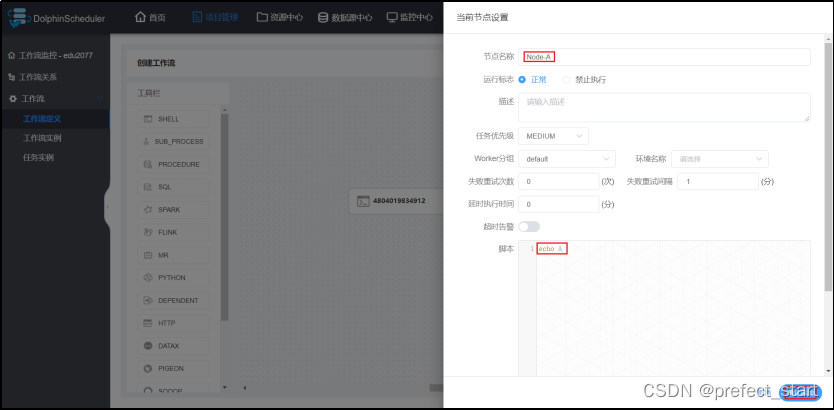
- 配置任务节点- 节点A
 - 节点B
- 节点B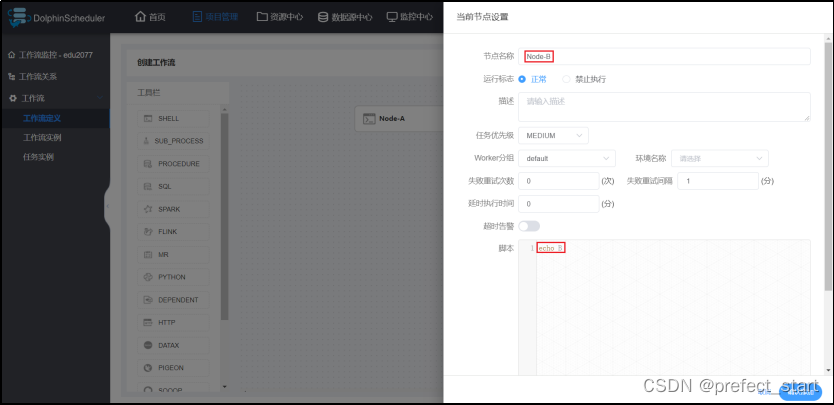 - 节点C
- 节点C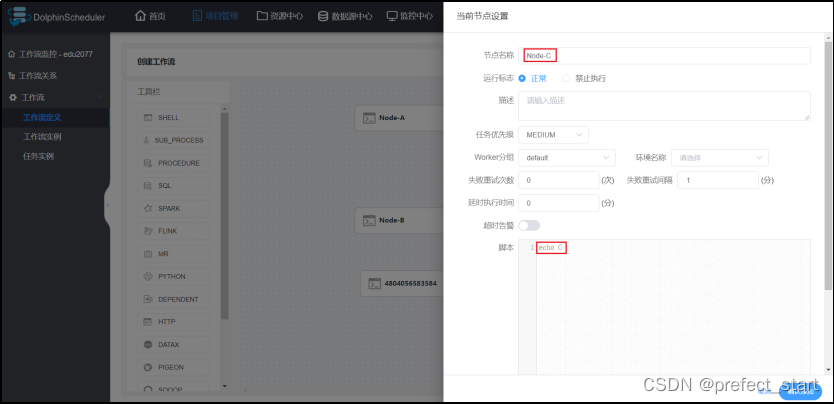
- 配置任务节点的依赖关系- 直接对 DAG 图进行操作
 - 在节点设置中选择 “前置任务”
- 在节点设置中选择 “前置任务”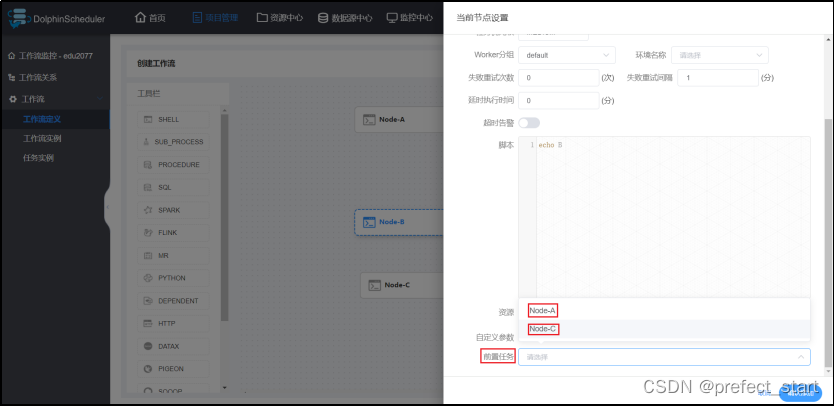
- 保存工作流定义
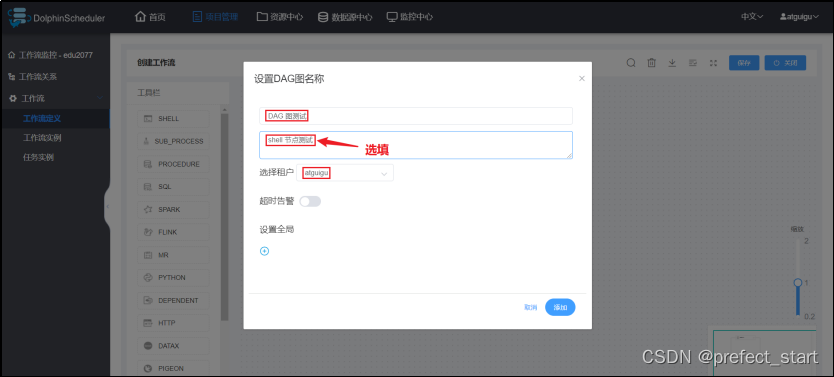
3.2.3.2、提交执行工作流
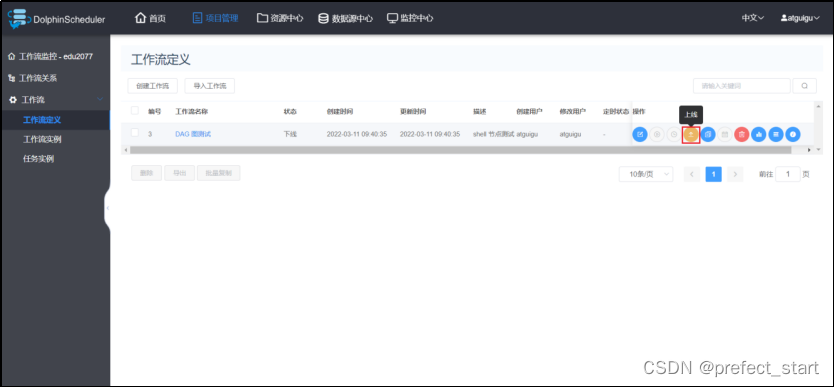
- 上线工作流,工作流须上线之后才能执行。处于上线状态的工作流定义不可修改,如需修改,须先下线。
- 单次运行工作流
- 定时执行工作流- 点击定时
 - 配置定时规则,此处示例为每秒钟执行一次
- 配置定时规则,此处示例为每秒钟执行一次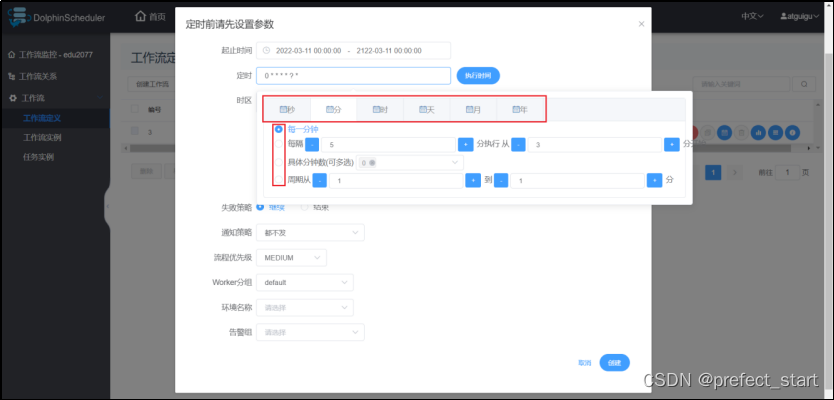 配置定时之后,点击“执行时间”查看任务接下来五次执行时间
配置定时之后,点击“执行时间”查看任务接下来五次执行时间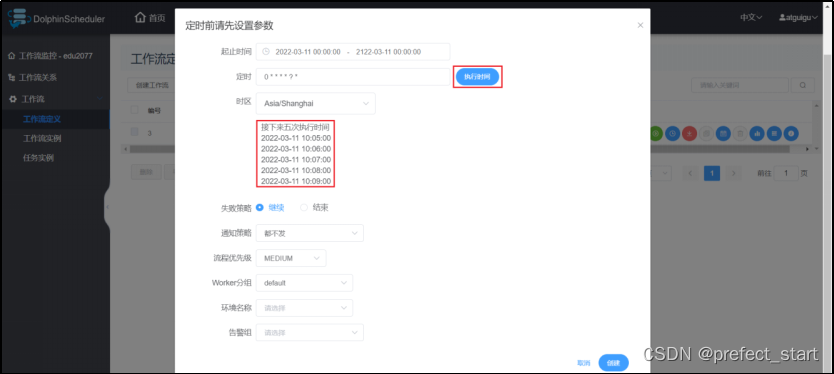 - 定时管理
- 定时管理 - 定时上线
- 定时上线 - 查看工作流实例
- 查看工作流实例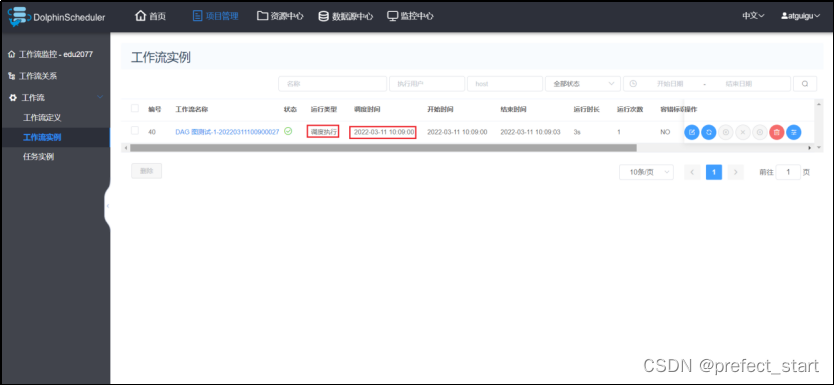
3.2.3.3、查看工作流实例
- 查看所有工作流实例
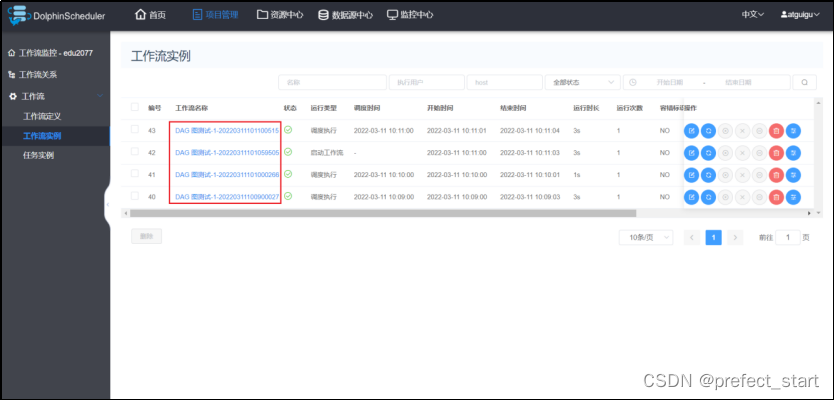
- 查看工作流执行状态
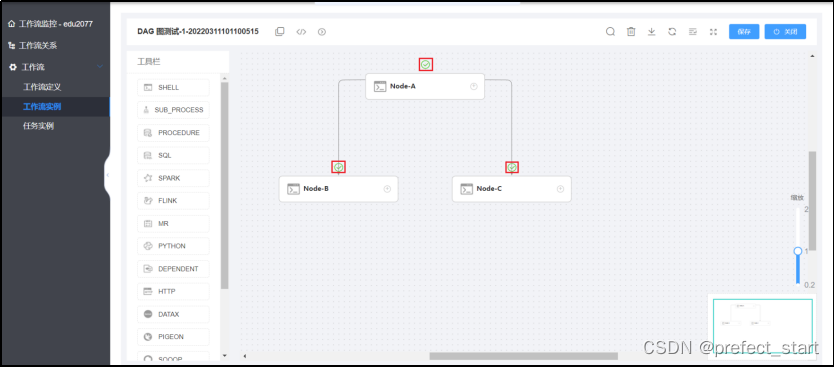
3.2.3.4、查看任务实例
- 查看所有任务实例
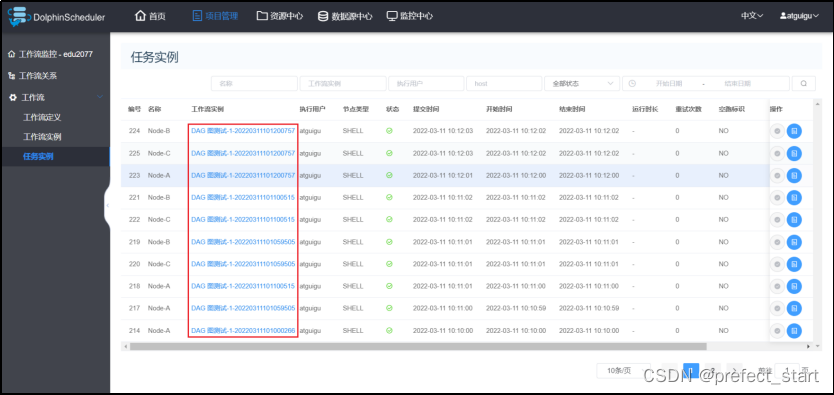
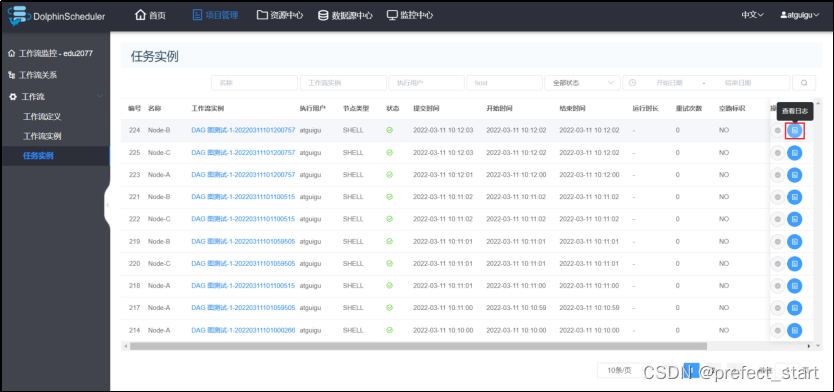
- 查看任务实例日志
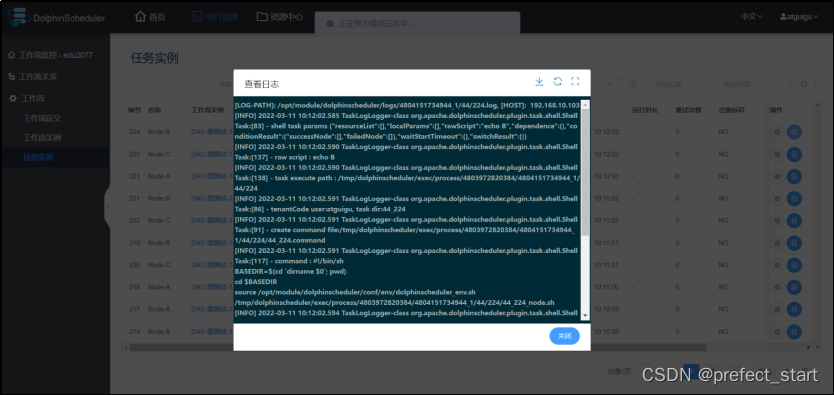
4、DolphinScheduler进阶
4.1、工作流传参
DolphinScheduler支持对任务节点进行灵活的传参,任务节点可通过${参数名}引用参数值。
4.2、内置参数
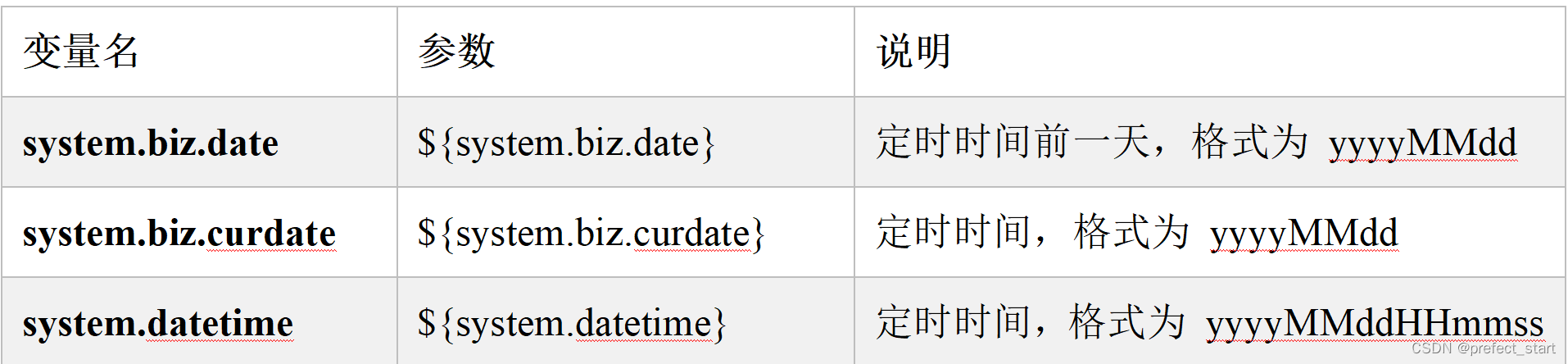
DolphinScheduler提供了一些时间相关的系统参数,方便定时调度使用。
4.2.1、基础内置参数
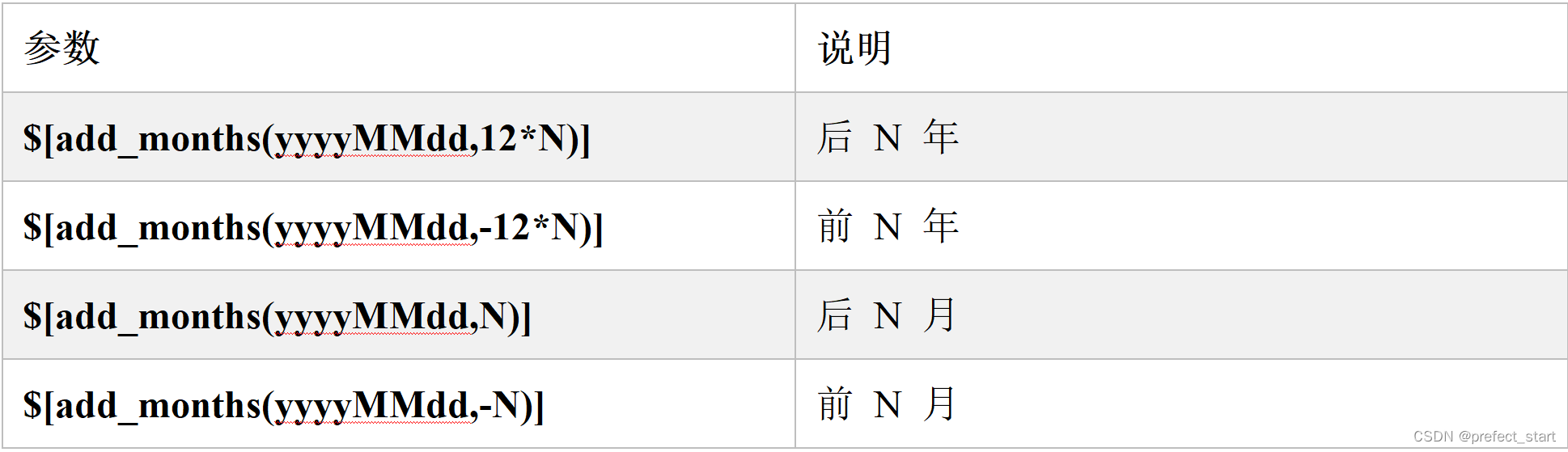
4.2.2、衍生内置参数,可通过衍生内置参数,设置任意格式、任意时间的日期。
- 自定义日期格式,可以对 $[yyyyMMddHHmmss] 任意分解组合,如 $[yyyyMMdd], $[HHmmss], $[yyyy-MM-dd]。
- 使用 add_months() 函数,该函数用于加减月份, 第一个入口参数为[yyyyMMdd],表示返回时间的格式 第二个入口参数为月份偏移量,表示加减多少个月。
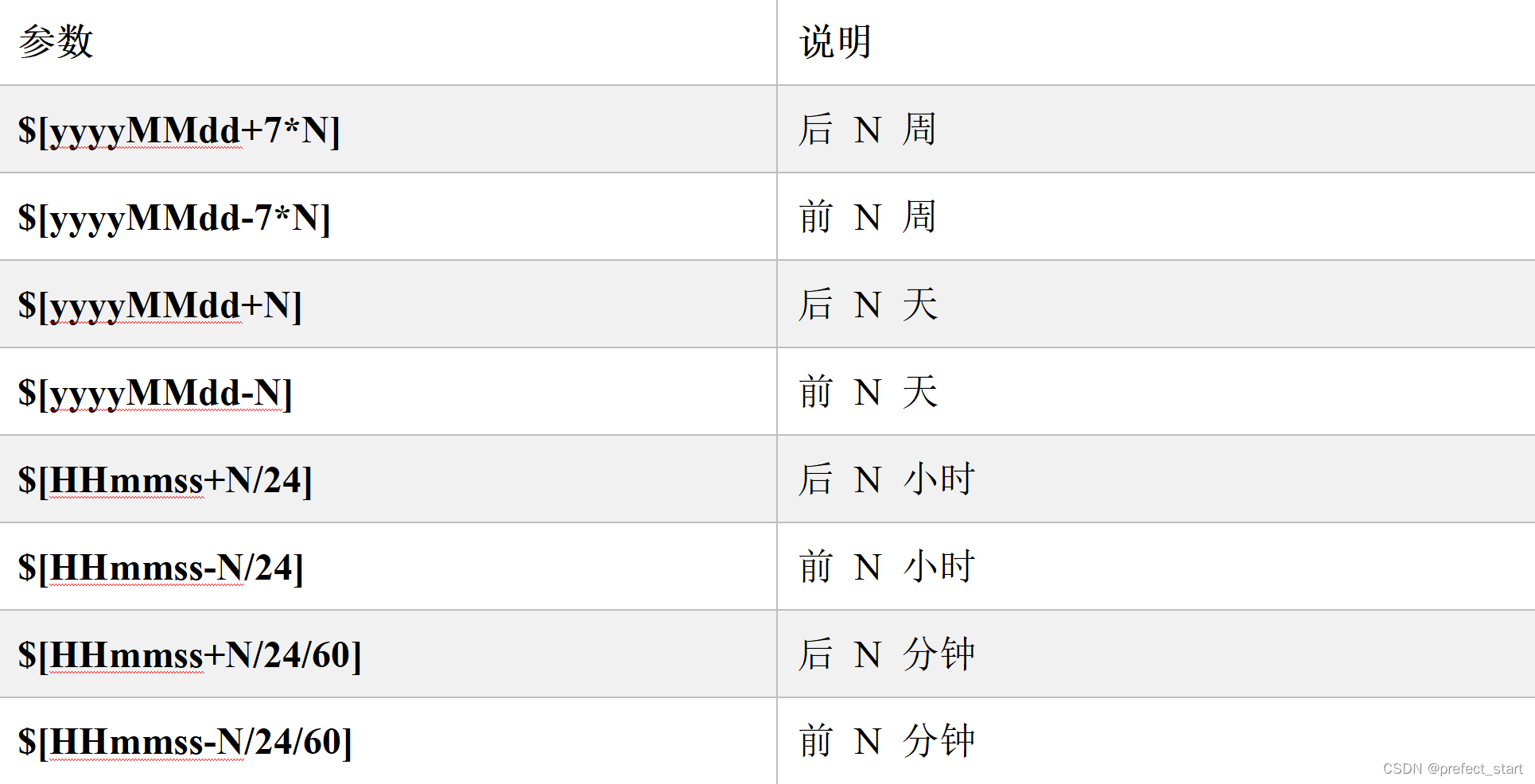
4.2.3、直接加减数字,在自定义格式后直接“+/-”数字,单位为“天”。
4.2.4、配置示例
若执行的脚本需要一个格式为yyyy-MM-dd的前一天日期的参数,进行如下配置即可。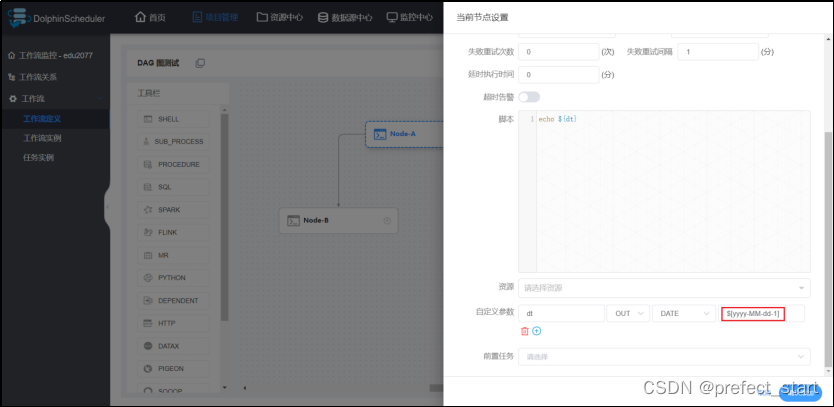
4.3、全局参数
全局参数是指针对整个工作流的所有任务节点都有效的参数,在工作流定义页面配置。
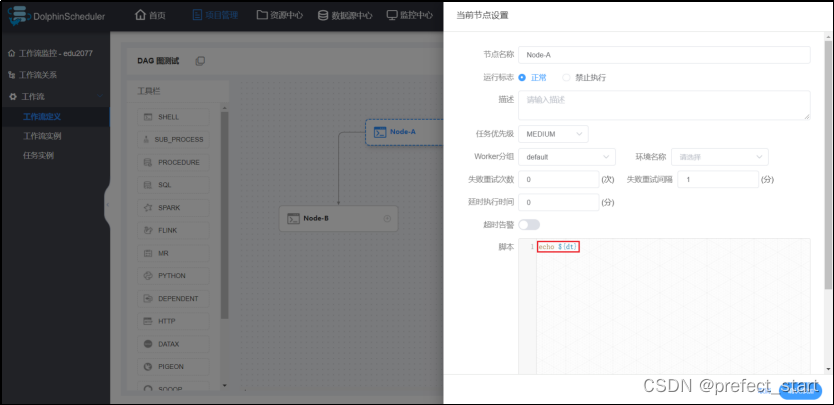
4.3.1、修改helloworld工作流每个任务节点如下
- 节点A配置
- 节点B配置
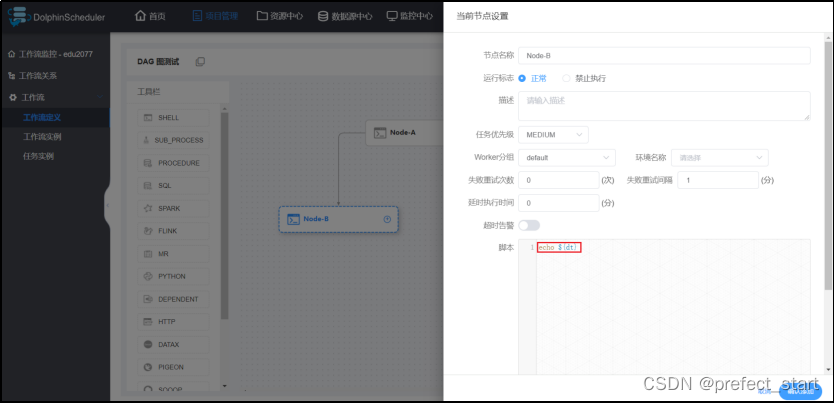
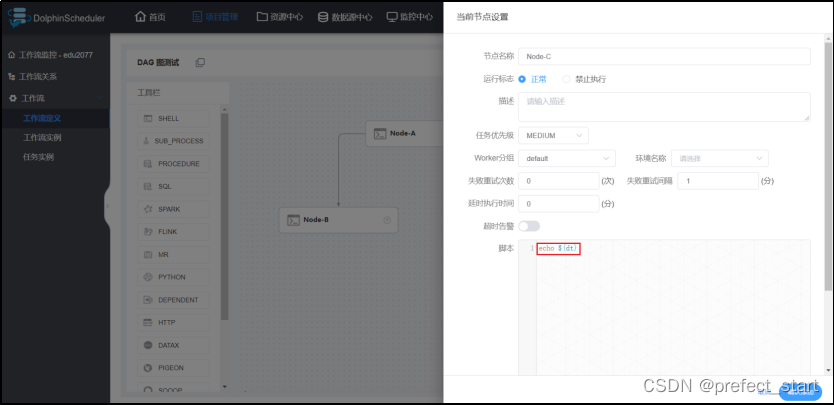
- 节点C配置
4.3.2、保存工作流,并设置全局参数
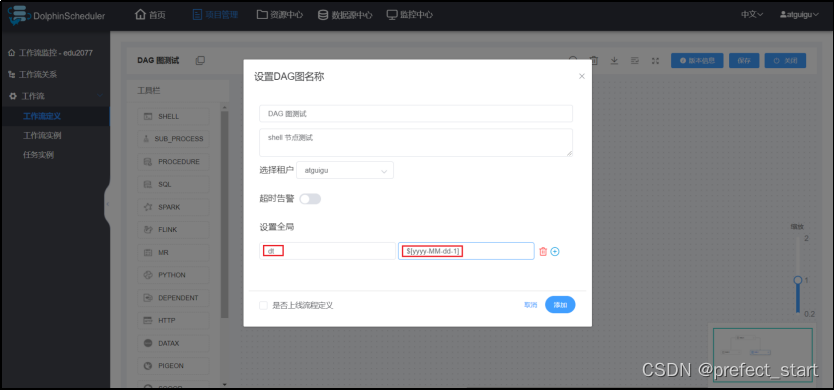
4.3.3、执行工作流,查看三个任务节点输出日志。
4.4、局部参数
局部参数是指只针对单个任务节点有效的参数
4.4.1、修改helloworld工作流Node-A节点如下
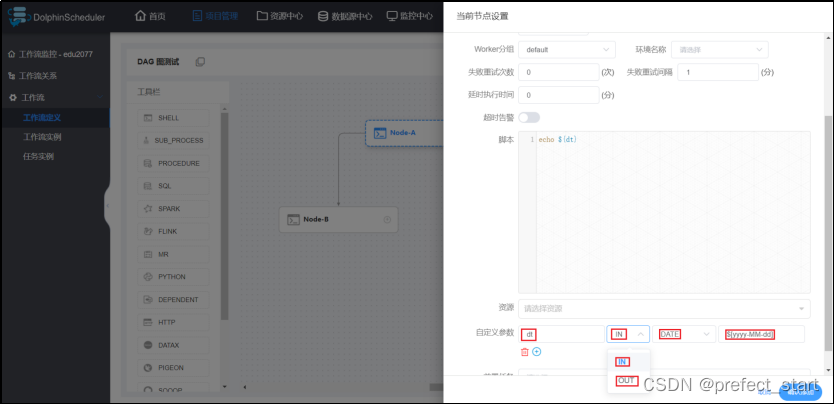
- dt:参数名
- IN:IN 表示局部参数仅能在当前节点使用,OUT 表示局部参数可以向下游传递
- DATE:数据类型,日期
- $[yyyy-MM-dd]:自定义格式的衍生内置参数
4.4.2、保存工作流并运行,查看Node-A输出日志。
4.5、参数传递
4.5.1、本地任务使用全局参数
通过 ${param} 方式引用全局参数。
4.5.2、上游任务传递给下游任务
目前传递方向仅支持上游单向传递给下游。目前支持这个特性的任务类型有:
Shell、SQL、Procedure。
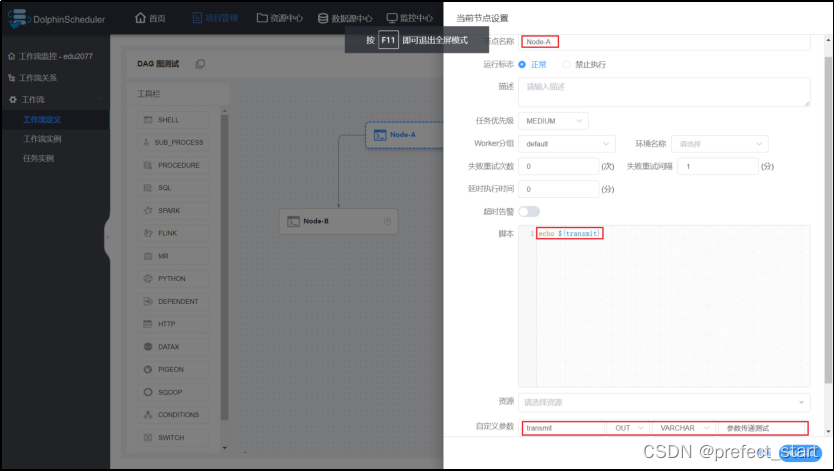
如果要将该节点的结果传递给有依赖关系的下游节点,当定义上游节点时,需要在设置自定义参数时选择方向为 OUT。
4.5.3、实操
- 设置上游节点 A
- 设置下游节点 B
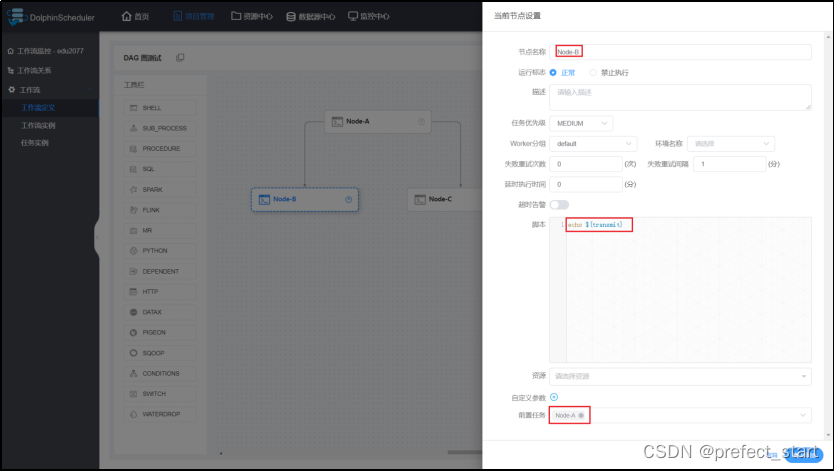 若节点之间没有依赖关系,则局部参数无法传递。
若节点之间没有依赖关系,则局部参数无法传递。 - 查看输出日志,可以看到对应节点日志中输出了其调用参数的值。
4.6、参数优先级
4.6.1、本地参数、全局参数、上有任务传递参数优先级测试
- 设置上游节点本地参数
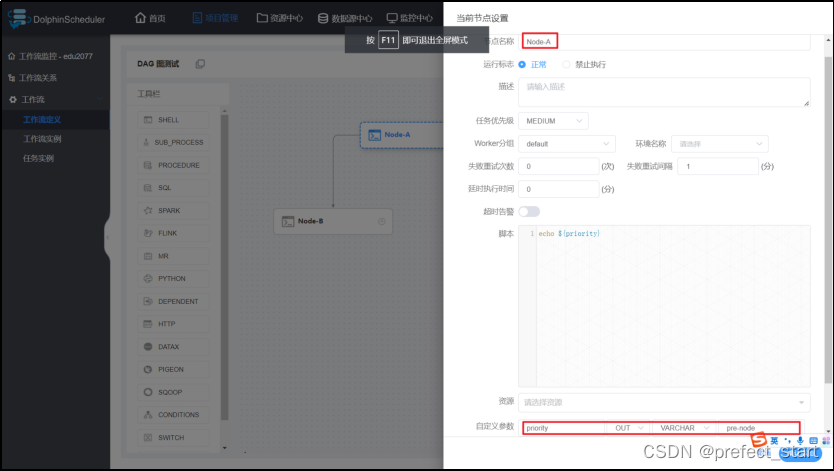
- 设置当前节点本地参数
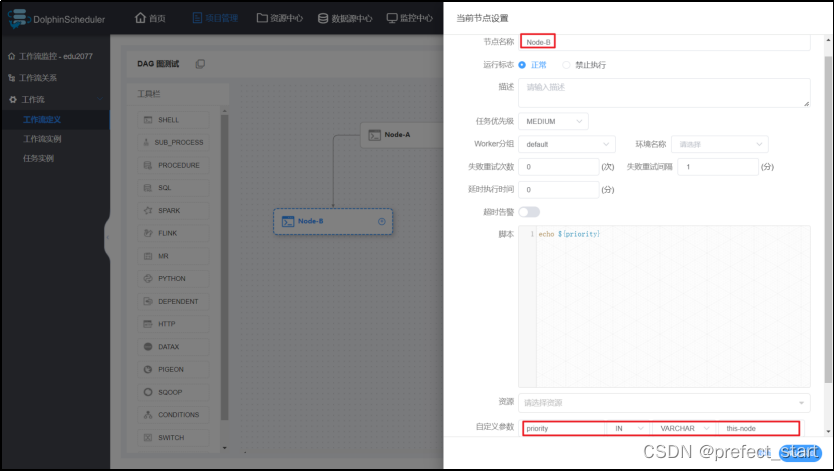
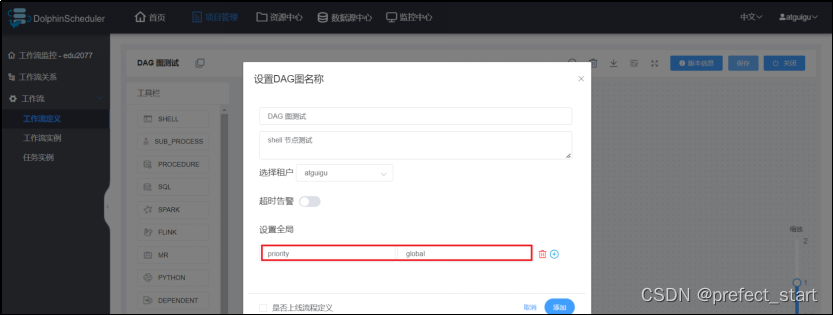
- 设置全局参数
- 上线并运行工作流查看 Node-B 运行结果
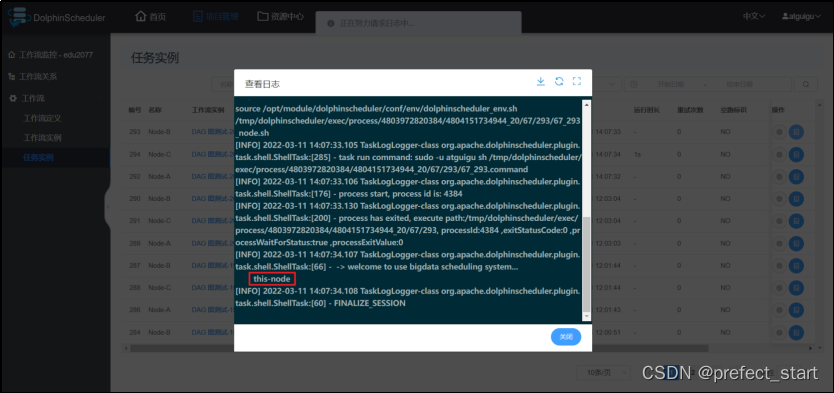 可见,生效的参数为 Node-B 节点定义的本地参数
可见,生效的参数为 Node-B 节点定义的本地参数 - 使 Node-B 节点定义的本地参数 priority 失效,重新运行工作流
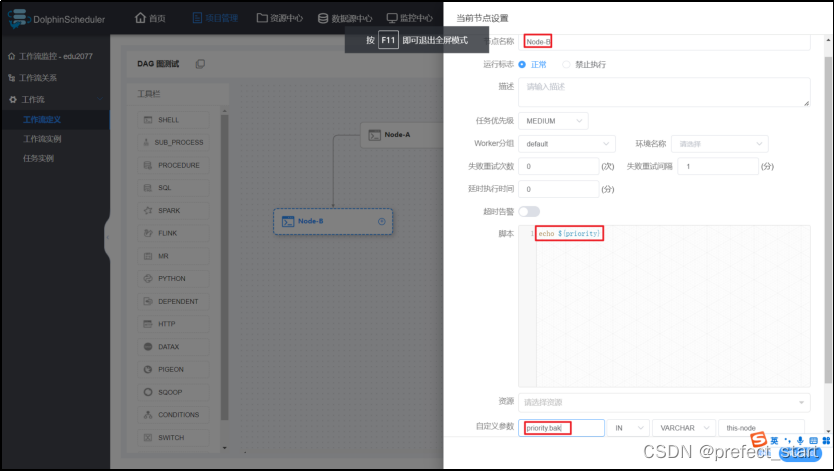
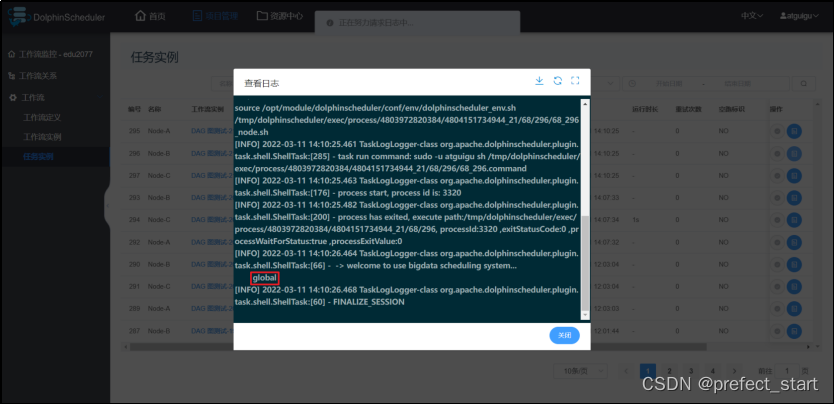 由此可得,优先级由高到低:本地参数 > 全局参数 > 上游任务传递的参数。
由此可得,优先级由高到低:本地参数 > 全局参数 > 上游任务传递的参数。
4.6.2、多个上游任务传递参数场景分析
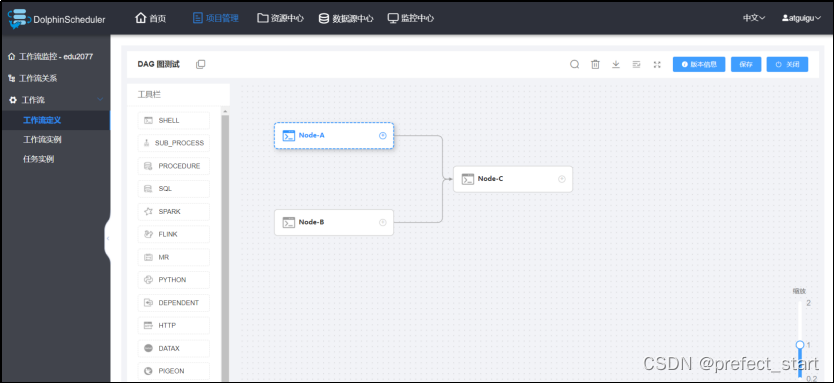
- 节点间依赖关系如下
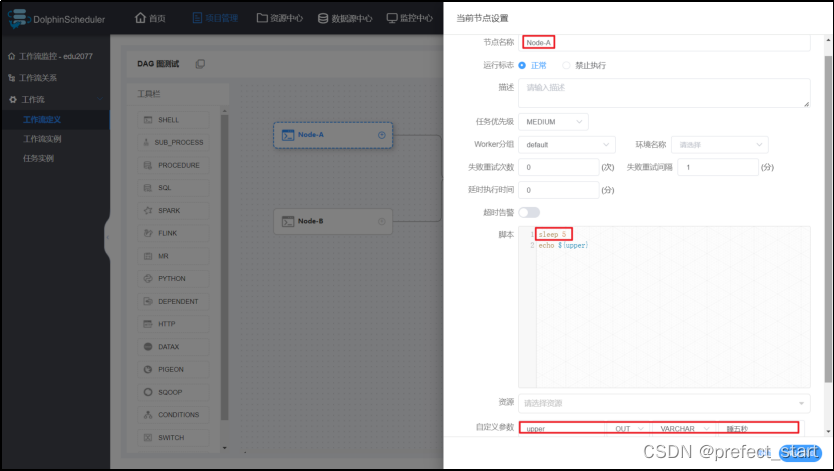
- Node-A 参数设置
- Node-B 参数设置
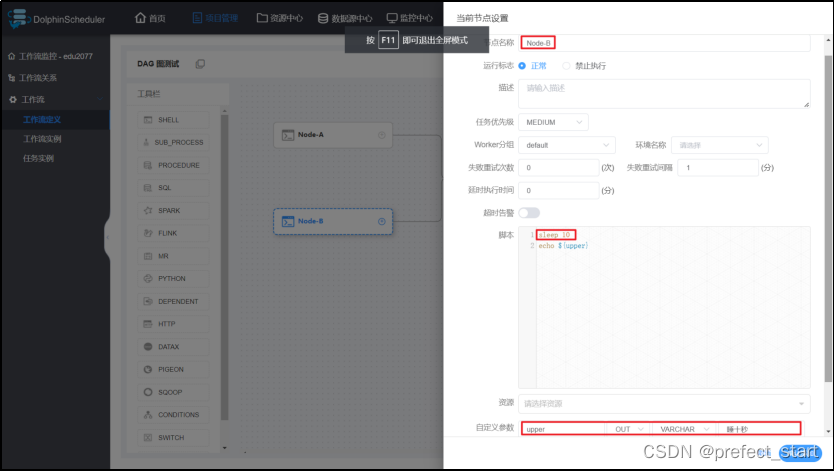
- Node-C 节点设置
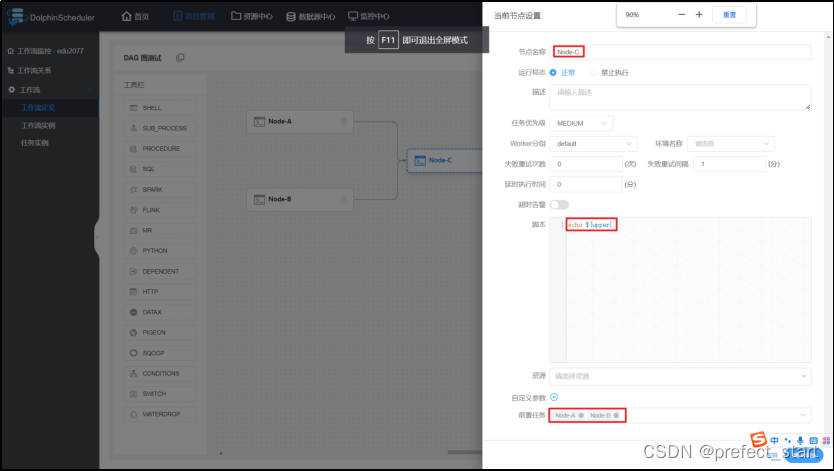
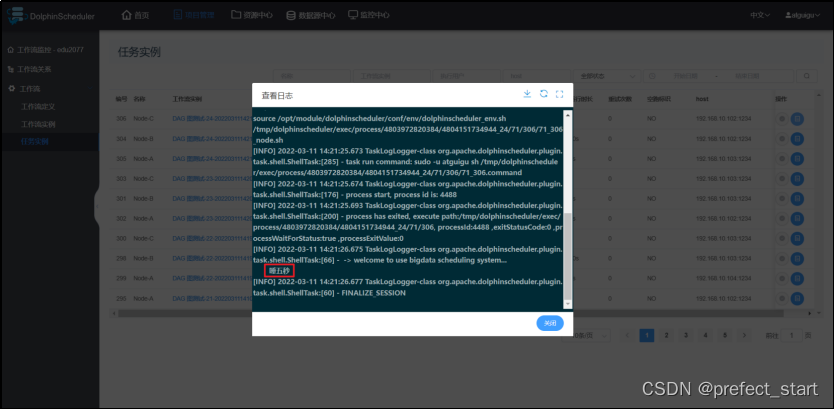
- 上线并运行工作流查看 Node-C 日志
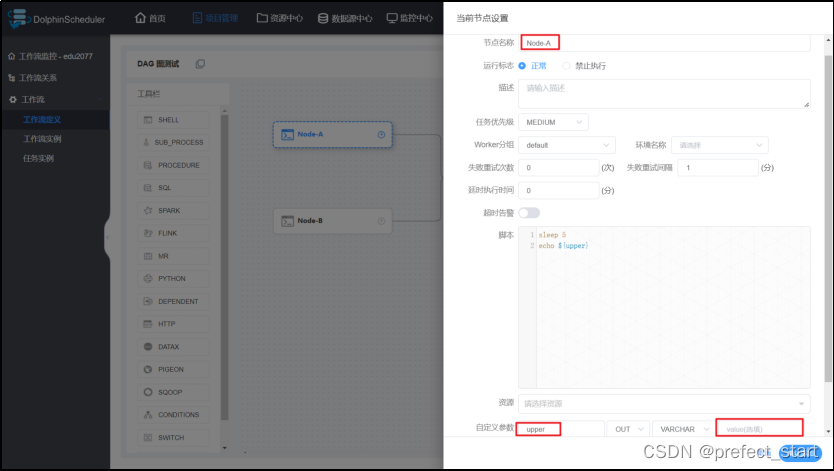
- 将休眠 5 秒的 Node-A 的 upper 参数置空
- 再次运行工作流,查看 Node-C 的日志
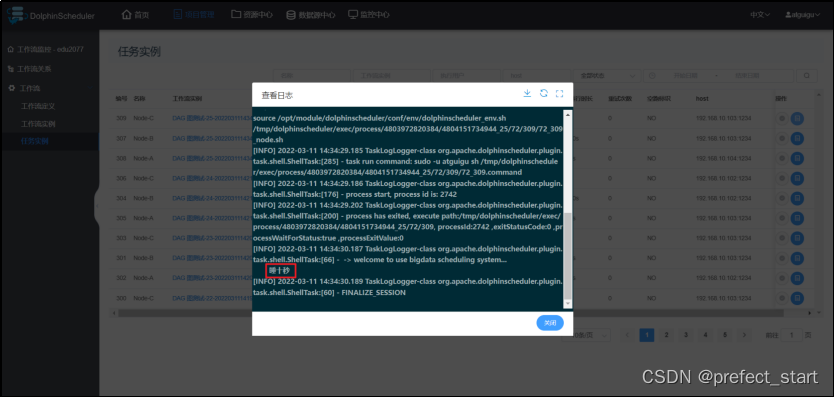
4.6.3、小结
Node-C 依赖于 Node-A 和 Node-B,而 Node-A 节点在执行 echo 之前休眠5秒,Node-B 节点在执行 echo 命令之前休眠 10 秒,Node-A 先于 Node-B 执行完毕,Node-C 最终调用的参数为 Node-A 传递的参数。
交换 Node-A 和 Node-B 的休眠时间使得 Node-B 先执行完毕,发现 Node-C 调用的是 Node-B 传递的参数。多次调整休眠时间,发现 Node-C 调用的参数始终为先执行完毕的上游节点传递的参数。
此外,当先执行完毕的节点参数值为空时,会调用其它上游节点传递的值为非空的参数。
4.6.4、结论
- 本地参数 > 全局参数 > 上游任务传递的参数;
- 多个上游节点均传递同名参数时,下游节点会优先使用值为非空的参数;
- 如果存在多个值为非空的参数,则按照上游任务的完成时间排序,选择完成时间最早的上游任务对应的参数。
4.7、引用依赖资源
有些任务需要引用一些额外的资源,例如MR、Spark等任务须引用jar包,Shell任务需要引用其他脚本等。DolphinScheduler提供了资源中心来对这些资源进行统一管理。
如果需要用到资源上传功能,针对单机可以选择本地文件目录作为上传文件夹(此操作不需要部署 Hadoop),当然也可以选择上传到 Hadoop or MinIO 集群上,此时则需要有Hadoop (2.6+) 或者 MinIO 等相关环境。本文在部署 DS 集群时指定了文件系统为 HDFS。
4.7.1、文件管理
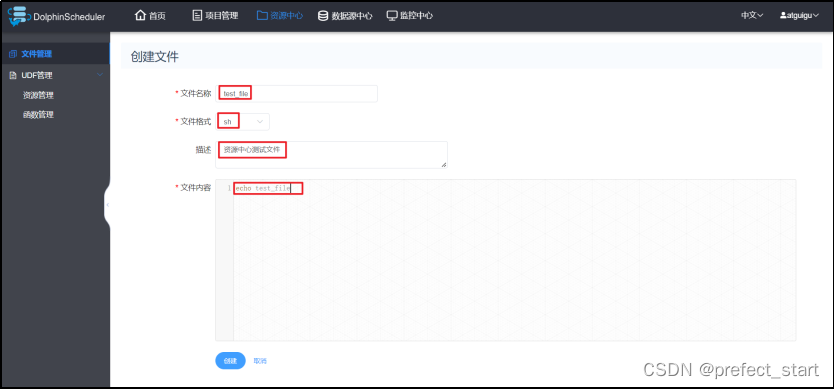
文件管理是对各种资源文件的管理,包括创建基本的txt/log/sh/conf/py/java等文件、上传jar包等各种类型文件,可进行编辑、重命名、下载、删除等操作。
- 创建文件
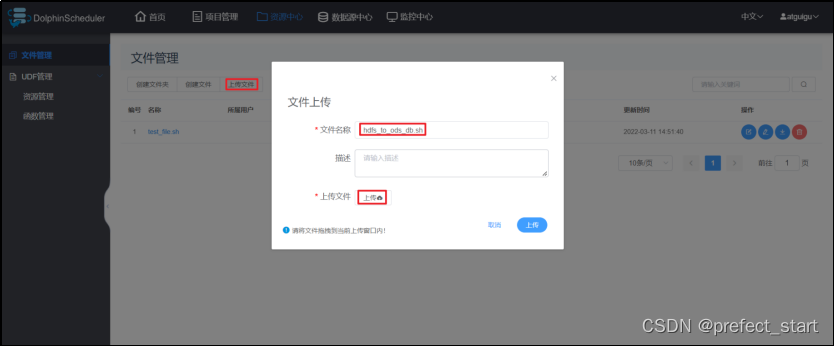
- 上传文件 点击"上传文件"按钮进行上传,将文件拖拽到上传区域,文件名会自动以上传的文件名称补全。
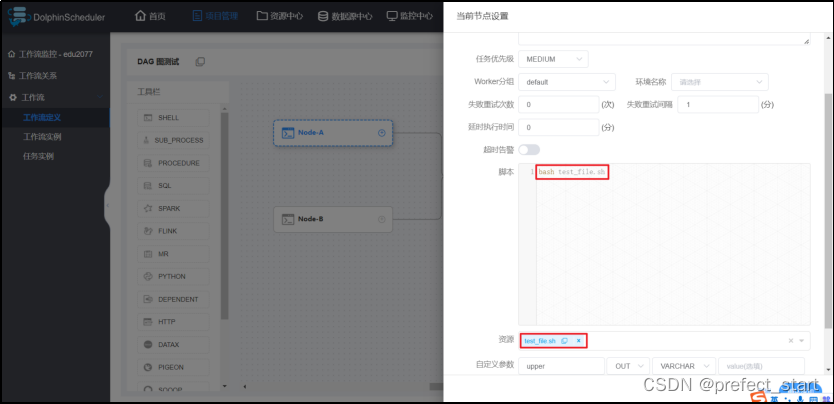
- 引用文件
4.7.1、UDF 管理
- 资源管理:资源管理和文件管理功能类似,不同之处是资源管理是上传的UDF函数,文件管理上传的是用户程序,脚本及配置文件 操作功能:重命名、下载、删除。上传方式同上。
- 函数管理:创建 UDF 函数
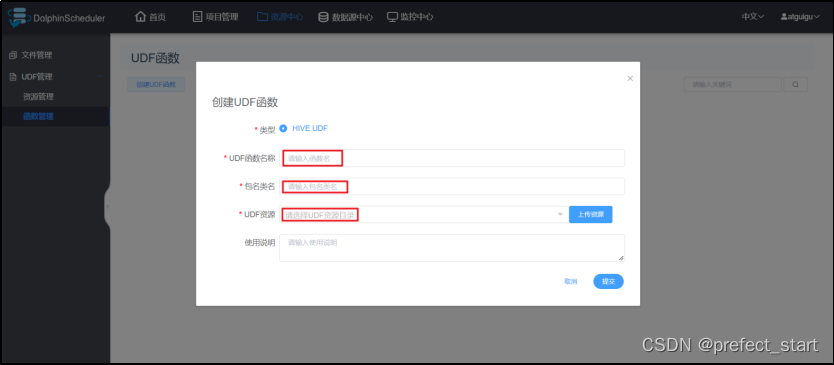 - UDF函数名称:输入UDF函数时的名称- 包名类名:输入UDF函数的全路径- UDF资源:设置创建的UDF对应的资源文件
- UDF函数名称:输入UDF函数时的名称- 包名类名:输入UDF函数的全路径- UDF资源:设置创建的UDF对应的资源文件
4.8、数据源配置
数据源中心支持MySQL、POSTGRESQL、HIVE/IMPALA、SPARK、CLICKHOUSE、ORACLE、SQLSERVER等数据源,此处仅对 HIVE 数据源进行介绍。
4.8.1、配置 Hive 数据源
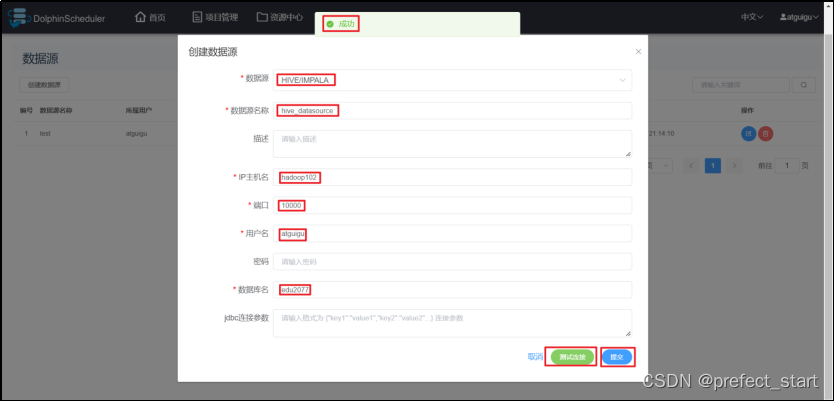
- 数据源:选择HIVE。
- 数据源名称:输入数据源的名称。
- 描述:输入数据源的描述,可置空。
- IP/主机名:输入连接HIVE的IP。
- 端口:输入连接HIVE的端口,默认 10000。
- 用户名:设置连接HIVE的用户名,如果没有配置 HIVE 权限管理,则用户名可以任意,但 HIVE 表数据存储在 HDFS,为了保证对所有表的数据均有操作权限,此处选择 HDFS 超级用户 song(注:HDFS 超级用户名与执行 HDFS 启动命令的 Linux 节点用户名相同)。
- 密码:设置连接HIVE的密码,如果没有配置 HIVE 权限管理,则密码置空即可。
- 数据库名:输入连接HIVE的数据库名称。
- Jdbc连接参数:用于HIVE连接的参数设置,以JSON形式填写,没有参数可置空。
4.8.2、使用 HIVE 数据源
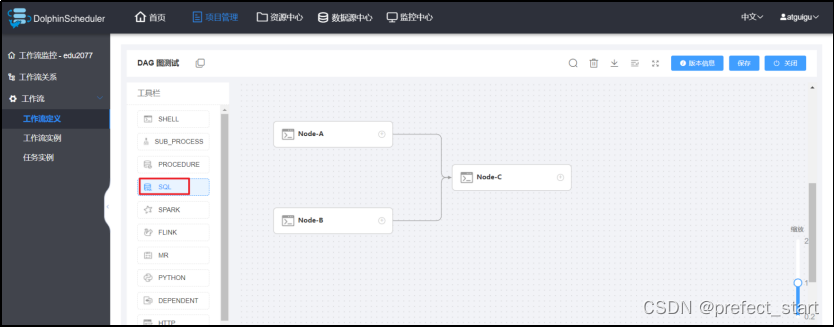
- 新建 SQL 节点
- 配置节点
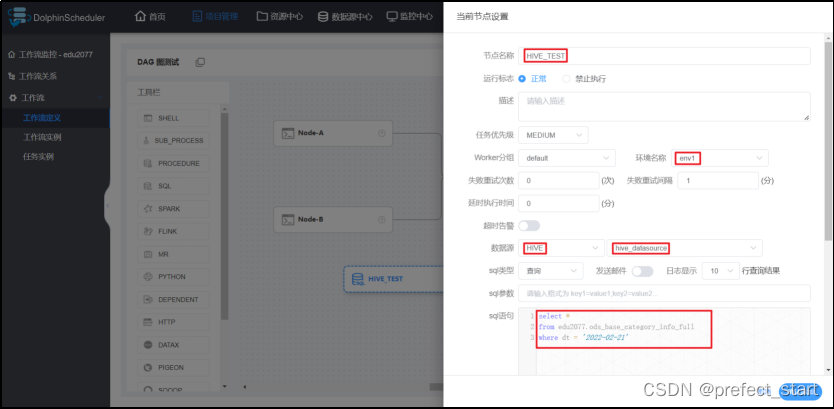 - 节点名称:自定义节点名称。- 环境名称:HIVE 执行所需环境- 数据源:类型选择 HIVE,数据源选择上文配置的 HIVE 数据源。- SQL 类型:根据SQL 语句选择,此处选用默认的“查询”即可。- SQL 语句:要执行的 SQL 语句,末尾不能有分号,否则报错:语法错误。
- 节点名称:自定义节点名称。- 环境名称:HIVE 执行所需环境- 数据源:类型选择 HIVE,数据源选择上文配置的 HIVE 数据源。- SQL 类型:根据SQL 语句选择,此处选用默认的“查询”即可。- SQL 语句:要执行的 SQL 语句,末尾不能有分号,否则报错:语法错误。
4.9、告警实例配置
4.9.1、邮箱告警实例配置
如需使用DolphinScheduler的邮件告警通知功能,需要准备一个电子邮箱账号,并启用SMTP服务。此处以 QQ 邮箱为例。
4.9.1.1、POP3,IMAP,SMTP
4.9.1.1.1、POP3
POP3是Post Office Protocol 3的简称,即邮局协议的第3个版本,它规定怎样将个人计算机连接到Internet的邮件服务器和下载电子邮件的电子协议。
它是因特网电子邮件的第一个离线协议标准,POP3允许用户从服务器上把邮件存储到本地主机(即自己的计算机)上,同时删除保存在邮件服务器上的邮件,而POP3服务器则是遵循POP3协议的接收邮件服务器,用来接收电子邮件的。(与IMAP有什么区别?)
4.9.1.1.2、SMTP
SMTP 的全称是“Simple Mail Transfer Protocol”,即简单邮件传输协议。它是一组用于从源地址到目的地址传输邮件的规范,通过它来控制邮件的中转方式。
SMTP 协议属于 TCP/IP 协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。SMTP 服务器就是遵循 SMTP 协议的发送邮件服务器。
SMTP 认证,简单地说就是要求必须在提供了账户名和密码之后才可以登录 SMTP 服务器,这就使得那些垃圾邮件的散播者无可乘之机,增加 SMTP 认证的目的是为了使用户避免受到垃圾邮件的侵扰。
4.9.1.1.3、IMAP
IMAP全称是Internet Mail Access Protocol,即交互式邮件存取协议,它是跟POP3类似邮件访问标准协议之一。不同的是,开启了IMAP后,您在电子邮件客户端收取的邮件仍然保留在服务器上,同时在客户端上的操作都会反馈到服务器上,如:删除邮件,标记已读等,服务器上的邮件也会做相应的动作。
所以无论从浏览器登录邮箱或者客户端软件登录邮箱,看到的邮件以及状态都是一致的。
4.9.1.1.4、邮件发送流程
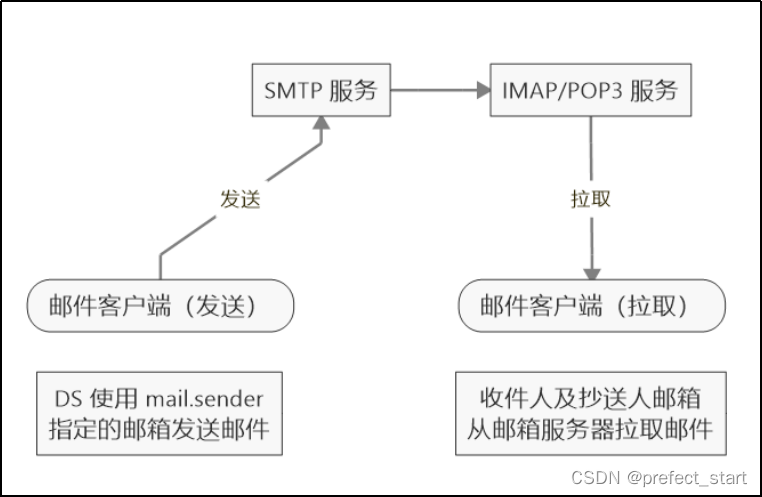
- DS 使用 mail.sender 指定的邮箱发送邮件到 SMTP 服务器,要求此邮箱开启 SMTP 服务;
- SMTP 服务将邮件转交给 POP3 或 IMAP 服务,经测试,通常SMTP 服务和 POP3 或 IMAP 服务处于同一台服务器;
- 收件邮箱客户端从 IMAP/POP3 服务器拉取邮件,某些邮箱可以设置邮件刷新时间,以此来控制客户端从服务端拉取邮件的频率。
- 需要注意:此处的邮件客户端均为第三方右键客户端,登陆邮箱输入的密码为授权码,使用 web 端收发邮件的流程可能有所不同。
4.9.1.2、获取授权码
4.9.1.2.1、开启 SMTP 服务
拖动进度条在页面下方找到下图所示内容,开启 POP3/SMTP | IMAP/SMTP 任一服务即可。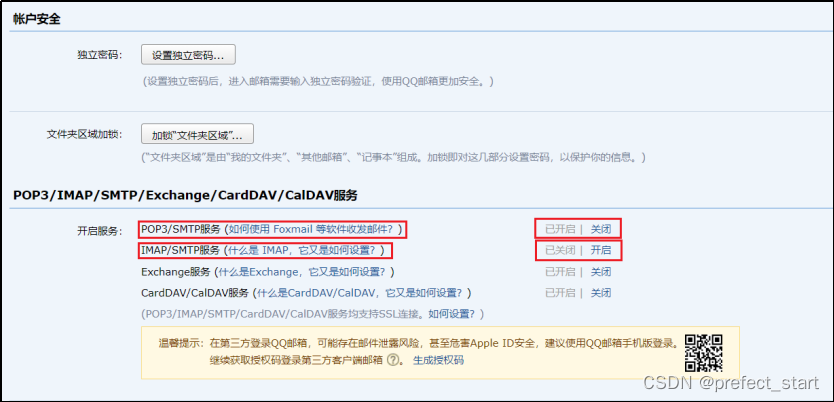
4.9.1.2.2、生成授权码
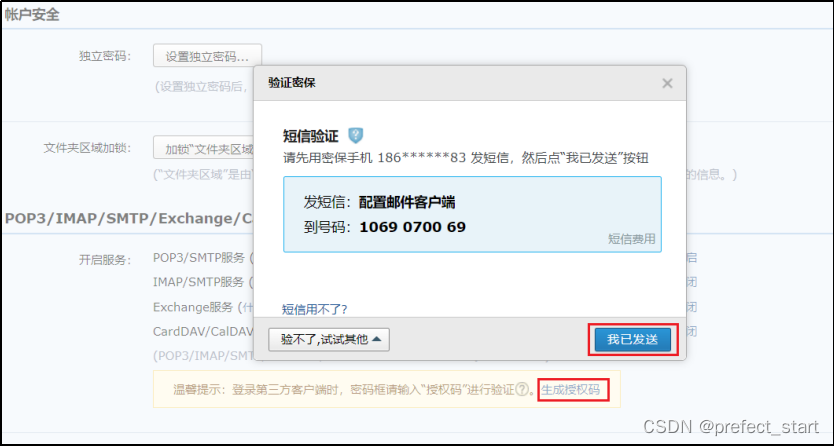
点击“生成授权码”,按照提示信息操作后点击“我已发送”即可生成授权码。授权码可以生成多次,若遗忘重新生成即可。
4.9.1.2.3、DolphinScheduler 配置
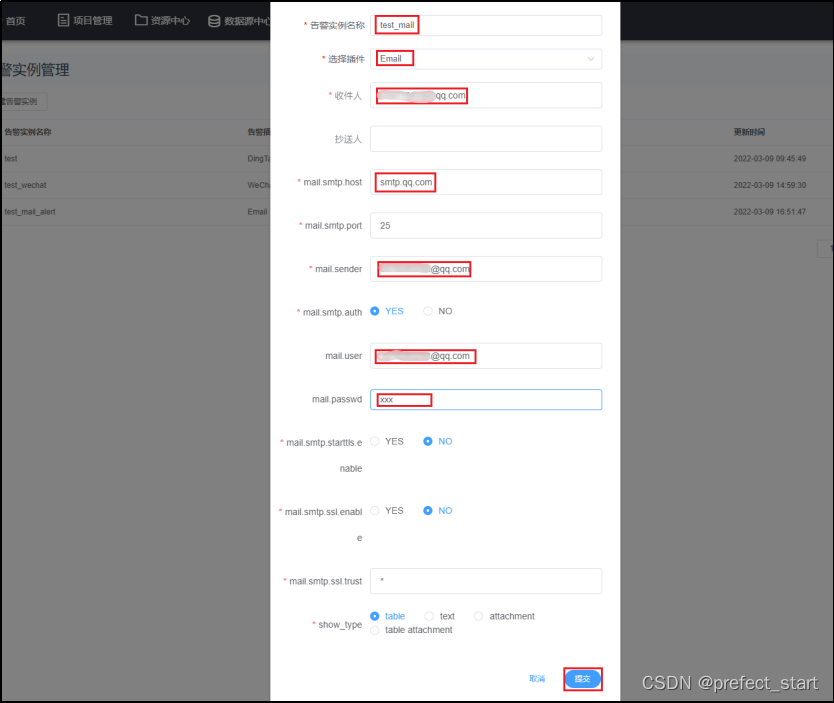
- 告警实例名称: 在告警组配置时可以选择的告警插件实例名称,用户自定义。
- 选择插件: 选择 Email 则为邮箱告警实例
- 收件人: 接收方邮箱地址,收件人不需要开启 SMTP 服务。
- 抄送人: 抄送是指用户给收件人发出邮件的同时把该邮件发送给另外的人,收件人之外的收件方都是抄送人,“收件人”可以获知该邮件的所有抄送人。 抄送人可以为空。
- mail.smtp.host : 邮箱的 SMTP 服务器域名,对于 QQ 邮箱,为 smtp.qq.com。各邮箱的 SMTP 服务器见此链接:
https://blog.csdn.net/wustzjf/article/details/52481309 - mail.smtp.port: 邮箱的 SMTP 服务端口号,主流邮箱均为 25 端口,使用默认值即可。
- mail.sender: 发件方邮箱地址,需要开启 SMTP 服务。
- mail.user: 与 mail.sender 保持一致即可。
- mail.password: 上文获取的邮箱授权码。未列出的选项保留默认值或默认选项即可。
4.9.2、钉钉告警实例配置
4.9.2.1、钉钉 webhook 准备
下载钉钉 PC 客户端。
4.9.2.1.1、点击发起群聊
4.9.2.1.2、在弹出的窗口中选择群聊类型
部分群聊需要选择归属企业,或不支持 PC 端建群,此处选择创建“培训群”
4.9.2.1.3、选择群成员,创建
4.9.2.1.4、点击“群设置”
4.9.2.1.5、选择“智能群助手”
4.9.2.1.6、添加机器人
4.9.2.1.7、选择“自定义”

4.9.2.1.8、添加
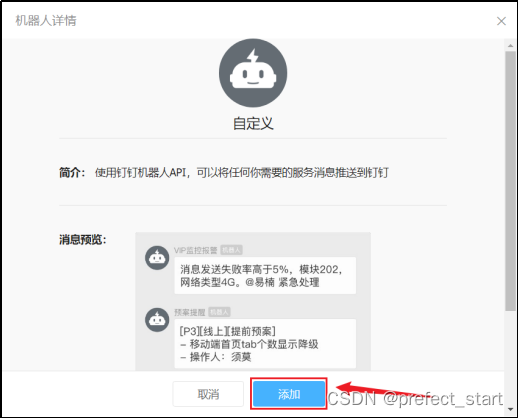
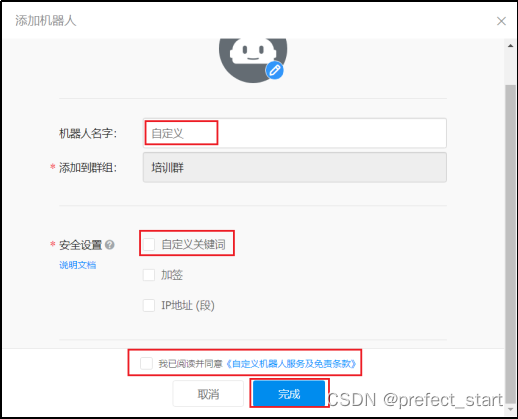
勾选自定义关键词之后可以添加至多10个关键词,发送的消息中至少包含其中 1 个关键词才可以发送成功。
4.9.2.1.9、获得 webhook
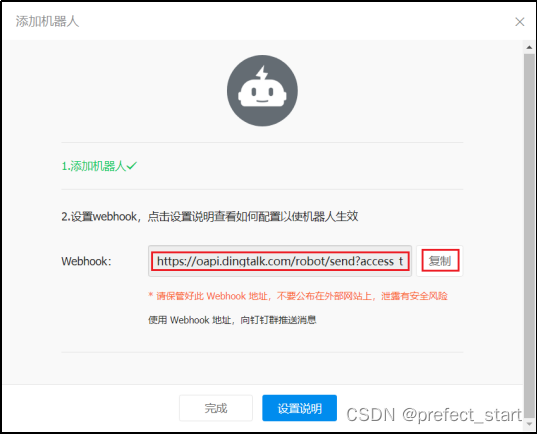
4.9.2.1.10、DS 钉钉告警实例创建
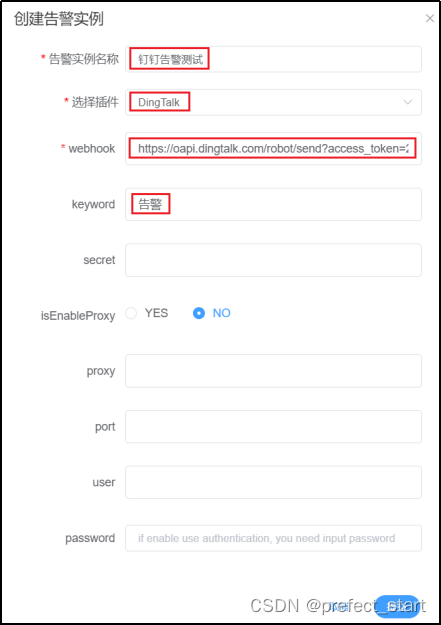
Keyword 必须至少包含一个创建钉钉机器人时指定的关键词。否则不会发送告警信息。
4.9.3、企业微信告警实例配置
4.9.3.1、企业微信配置
- 下载企业微信手机客户端,主界面左滑,选择“全新创建企业”。
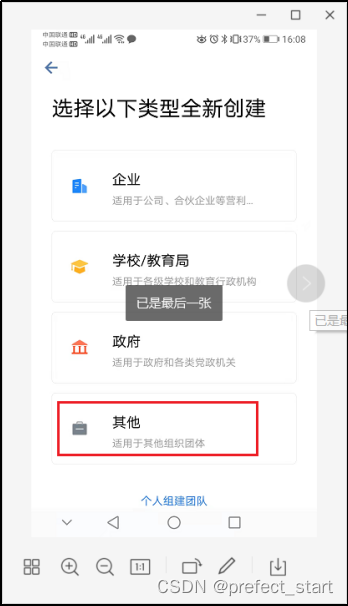
- 选择“其他”
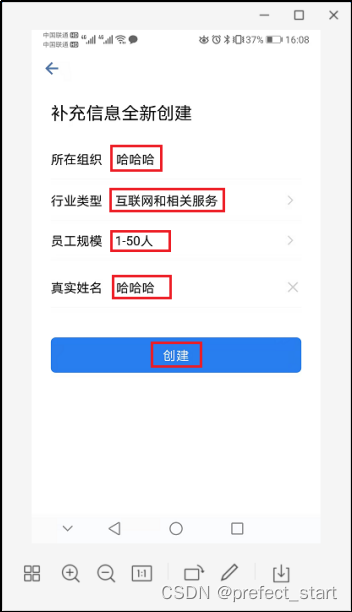
- 补全信息
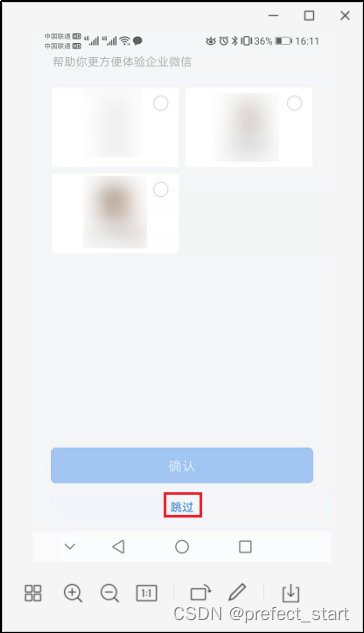
- “跳过”进入组织
4.9.3.2、获取相关参数
登陆企业微信 web 端管理后台
4.9.3.2.1、corp.id 获取
“我的企业”下的“企业 ID”即为 corp.id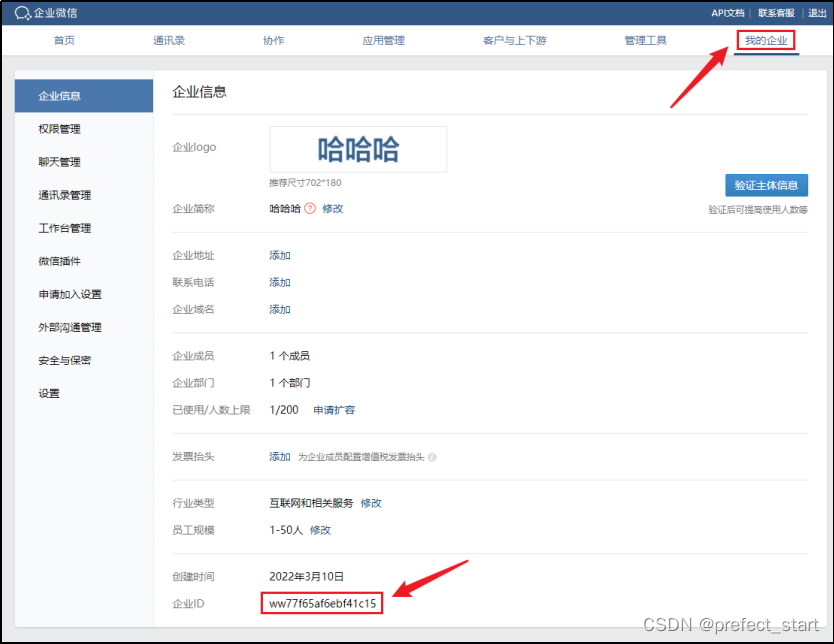
4.9.3.2.2、agent.id 及 secret 获取
4.9.3.2.2.1、创建应用
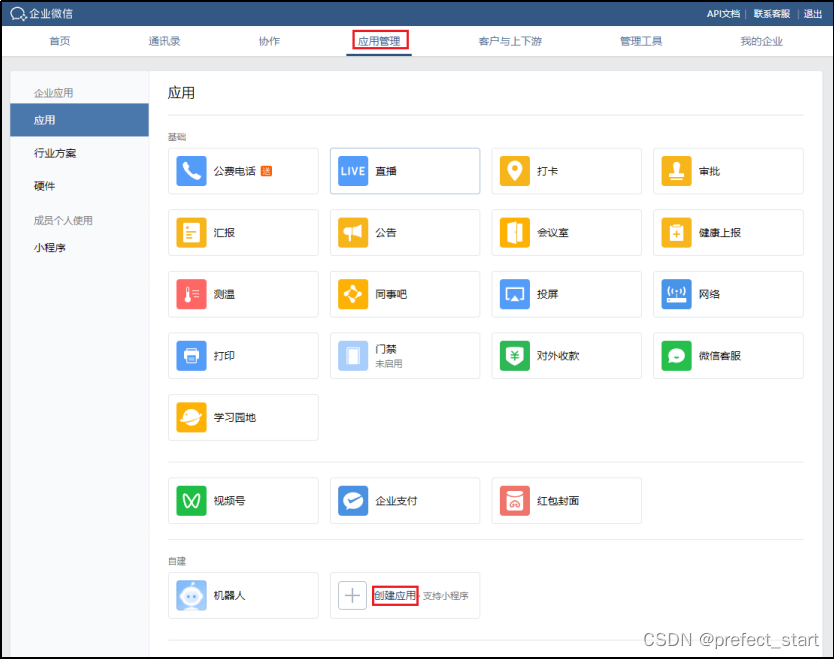
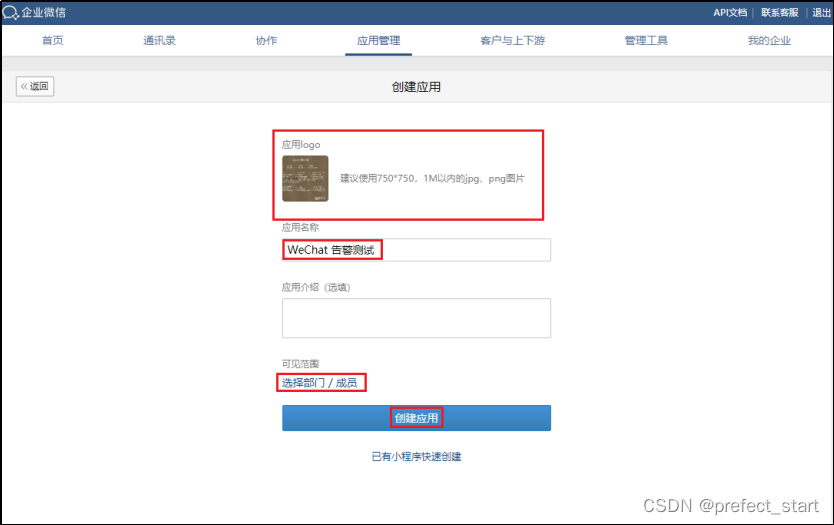 需要上传 logo,且可见范围必须为根部门,此处即“哈哈哈”
需要上传 logo,且可见范围必须为根部门,此处即“哈哈哈”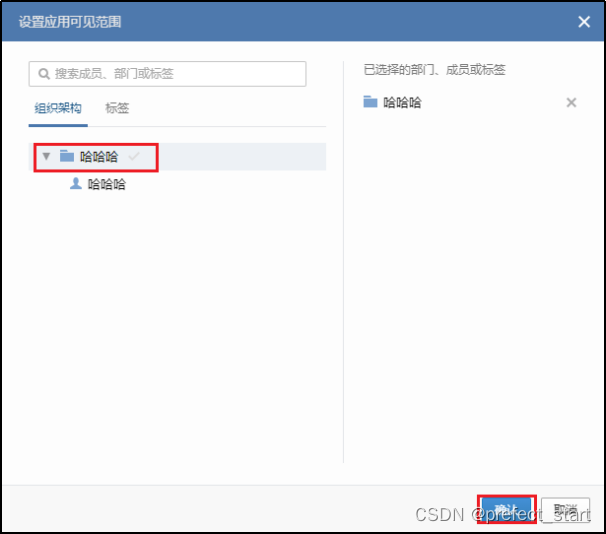
4.9.3.2.2.2、 获取 agent.id 及 secret
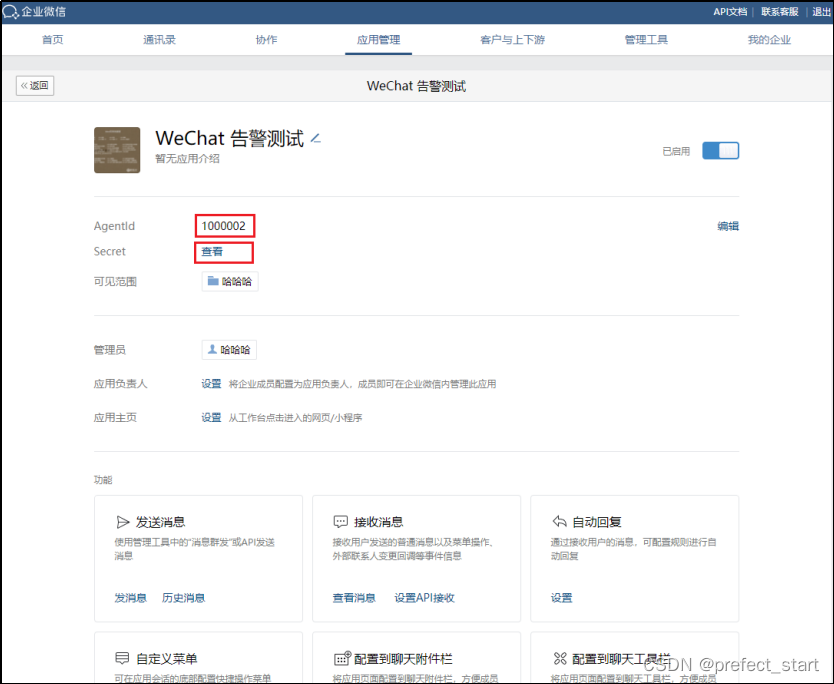
点击 Secret 后面的“查看”发送消息至企业微信客户端即可获取 secret。
4.9.3.2.2.3、user.id 获取
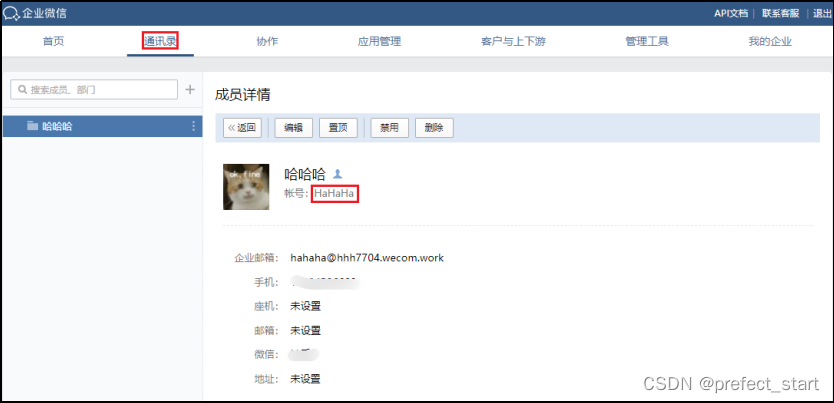
4.9.3.2.2.4、chatid 获取
- 获取 token,在 Linux 命令行中执行如下命令
[song@hadoop102 ~]$ curl -XGET https://qyapi.weixin.qq.com/cgi-bin/gettoken\?corpid\=ww77f65af6ebf41c15\&corpsecret\=nV_G3IcidnKglwfJPydArHLQUuQmQxp7XhGIRatWK7w
注:
①?,=,& 在 Linux 中均有特殊含义,需要转义。
②url 中 corpid 和 corpsecret 后的值应分别用前文获取的 corp.id 和 secret 替换。
返回的结果如下
{"errcode":0,"errmsg":"ok","access_token":"EDpWQWZoj3IJ24gkiXlpRltBwqTkzVa0gbBlUxwrDPSPujOYBf2Cqz54k1LQLSuQqDf1fNbQwwC7Tn4PuDOnhkR4Nuecc3F3xhRR6UAhkULcE-0_gfJhnMeeptL52tw0wGB5JOEc0rgi8JEZuEleVuC8PpZawrRMmerfe0RClkIH8yKKAO0Wi-ZuBRrNs0fdsoVpHxcvIYaEEPoIJLVVtw","expires_in":7200}
其中 “access_token” 字段的值即我们需要的 token。
- 创建群聊并获取 chatid
[song@hadoop102 ~]$ curl -XPOST https://qyapi.weixin.qq.com/cgi-bin/appchat/create\?access_token\=EDpWQWZoj3IJ24gkiXlpRltBwqTkzVa0gbBlUxwrDPSPujOYBf2Cqz54k1LQLSuQqDf1fNbQwwC7Tn4PuDOnhkR4Nuecc3F3xhRR6UAhkULcE-0_gfJhnMeeptL52tw0wGB5JOEc0rgi8JEZuEleVuC8PpZawrRMmerfe0RClkIH8yKKAO0Wi-ZuBRrNs0fdsoVpHxcvIYaEEPoIJLVVtw -d '{"name":"告警通知小组","owner":"HaHaHa","userlist":["HaHaHa","TieDun"]}
“owner” 和 “userlist” 中的用户id 获取方式与前文一致。
返回结果如下:
{"errcode":0,"errmsg":"ok","chatid":"wrNP1gIQAA2X7nX-g4addQOa-UB6Cudw"}
其中 “chatid” 字段的值即我们需要的 “chatid”。
注意,“userlist” 至少需要两个 “userid”,否则报错:无效的群聊成员列表规模,如下
{"errcode":86006,"errmsg":"invalid chat member list size, hint: [1646903632450091307995180], from ip: 115.171.202.120, more info at https://open.work.weixin.qq.com/devtool/query?e=86006"}
- DS 告警实例配置
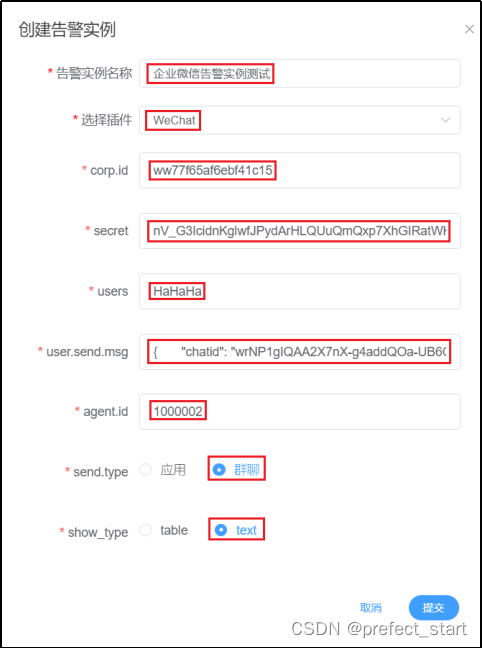 依次填入前文获取的参数即可,其中,user.send.msg为JSON字符串,如下
依次填入前文获取的参数即可,其中,user.send.msg为JSON字符串,如下
{"chatid": "wrNP1gIQAA2X7nX-g4addQOa-UB6Cudw","msgtype":"text","text":{"content" : "告警信息: \n{msg}"},"safe":0
}
上述为固定格式,替换 chatid 和 content 字段的值即可。chatid 的值为上文获取的群聊id,content 的值为发送到群聊的告警信息,可以自定义。
msg 为 DolphinScheduler 规定的告警信息变量名,{msg} 表示取 msg 变量的值。
4.9.4、电话告警实例配置
电话告警需要通过第三方平台实现,此处选用睿象云。睿象云官网:https://www.aiops.com/
4.9.4.1、注册账号
4.9.4.2、选择监控工具
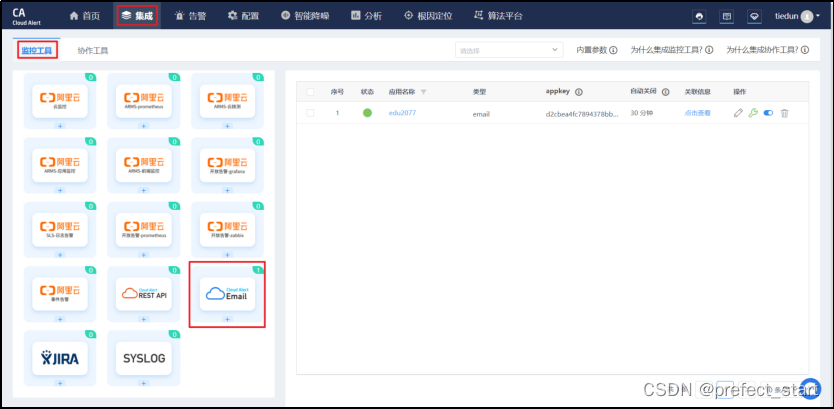
Email 为通用集成,将告警信息以邮件的形式发送到睿象云提供的邮箱,后者会根据用户在睿象云平台配置的告警策略进行各种形式的告警。
4.9.4.3、Email 集成配置
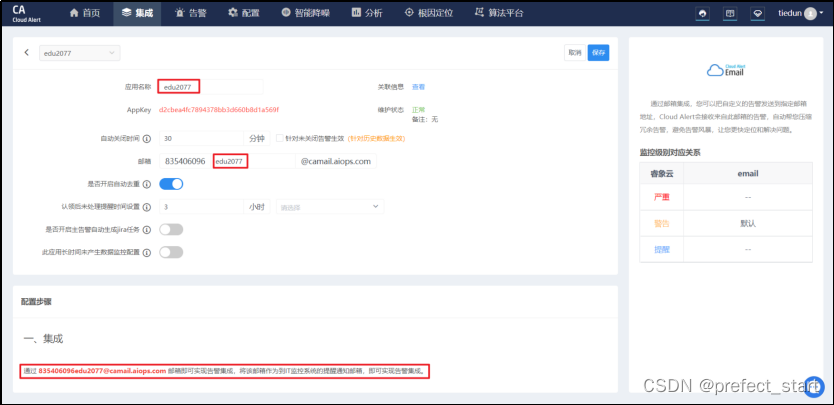
4.9.4.4、配置分派策略
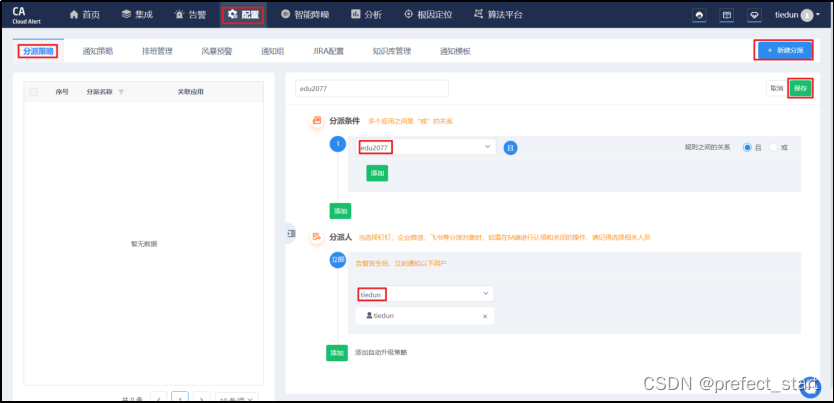
4.9.4.5、配置通知策略
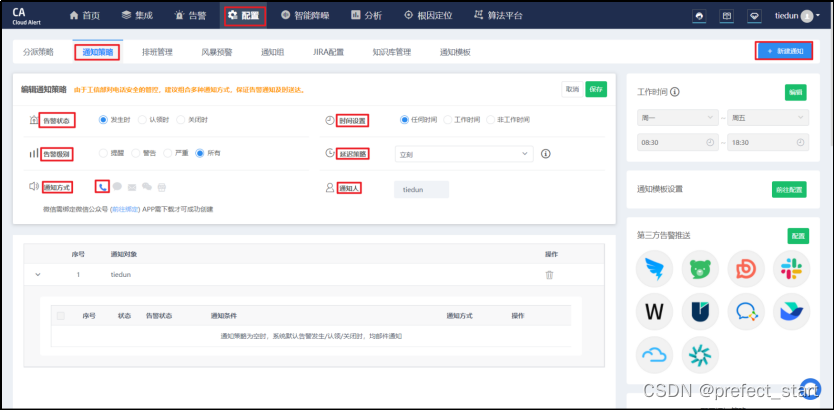
4.9.4.6、配置告警实例
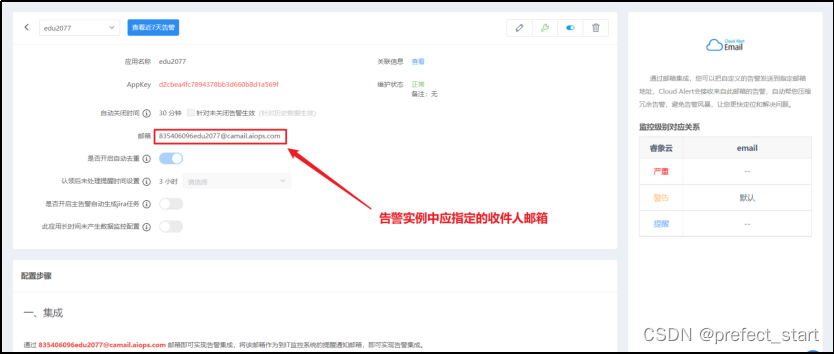
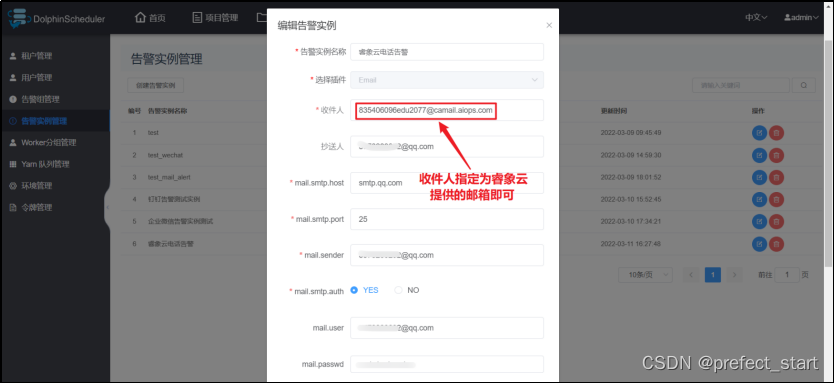
收件人指定为睿象云提供的邮箱即可。
4.9.4.7、配置告警组
4.9.4.8、重新执行任务,设置告警策略
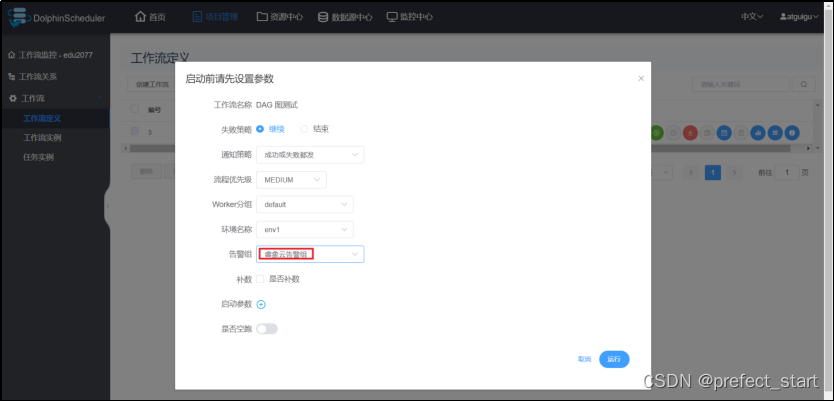
任务执行完毕即可接到告警电话。
4.9.5、告警效果展示
4.9.5.1、邮件告警
4.9.5.2、钉钉告警
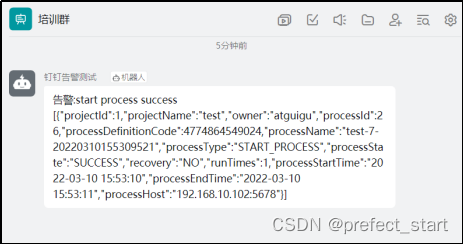
4.9.5.3、企业微信告警
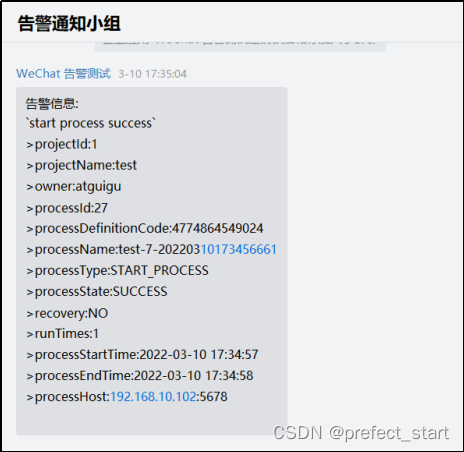
4.9.5.4、企业微信告警
4.10、工作流失败重跑
若工作流执行到一半失败了,需要重新启动工作流。重新启动时可选择从起点开始执行,也可选择从断点开始执行。
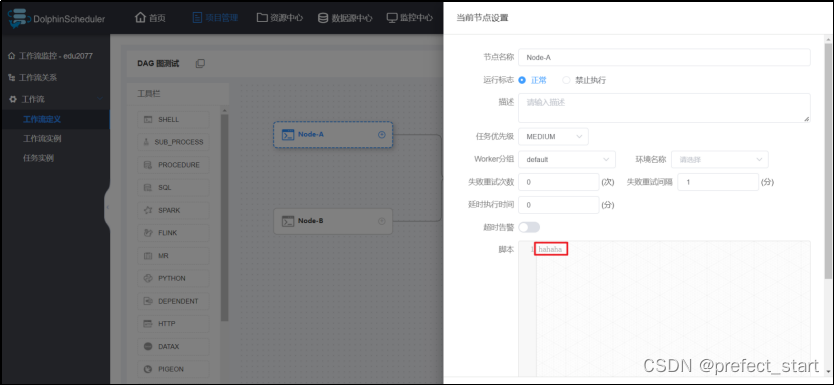
4.10.1、模拟失败场景
- 修改Node-A配置如下
- 运行工作流,查看工作流实例
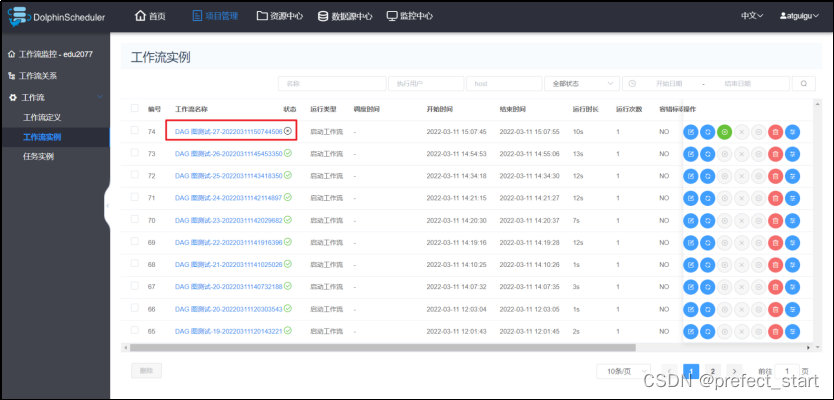
4.10.2、工作流失败重跑
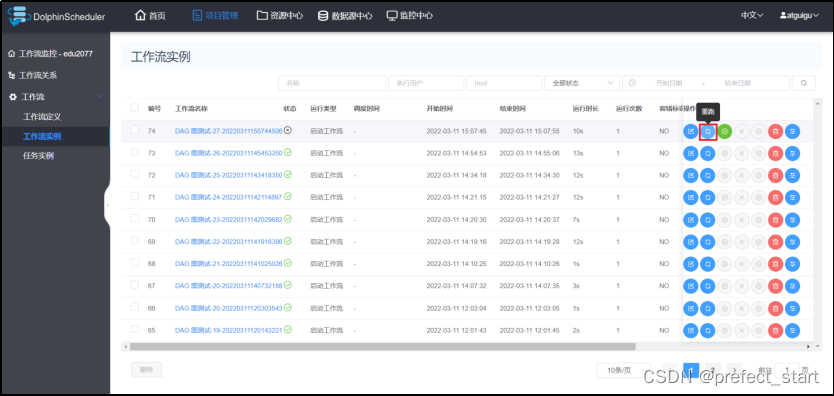
- 从起点开始
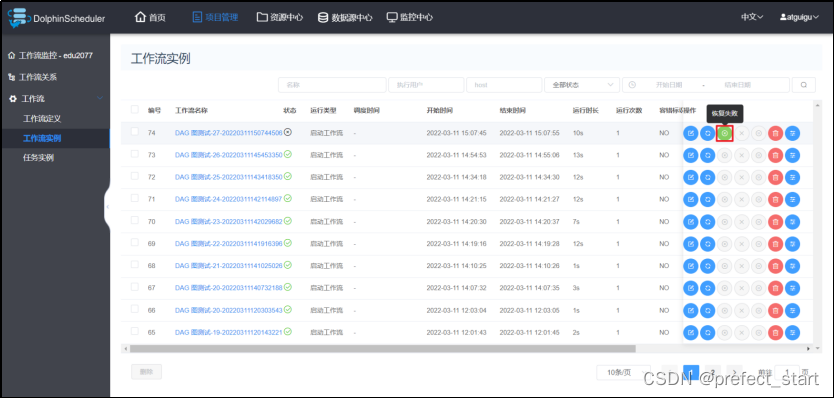
- 从断点开始
版权归原作者 后端技术那点事 所有, 如有侵权,请联系我们删除。