
前言
工作中需要抓取一下某音频网站的音频,我就用了两个小时学习弄了一下,竟然弄出来,这里分享记录一下。
springboot项目 + Selenium
Java使用Selenium实现自动化测试以及全功能爬虫
1 自动化测试
提到Selenium,便离不开自动化测试。
自动化测试,就是把手工进行的测试过程,转变成机器自动执行的测试过程。
自动化测试有如下优点
- 对程序的回归测试更方便。 这可能是自动化测试最主要的任务,特别是在程序修改比较频繁时,效果是非常明显的。
- 可以运行更多更繁琐的测试。
- 可以执行一些手工测试困难或不可能进行的测试。
- 更好地利用资源。
- 测试具有一致性和可重复性。
- 测试的复用性。
- 增加软件信任度。
2 java中集成Selenium
maven添加依赖
在java中使用Selenium很简单,你只需要添加如下依赖:
<dependency><groupId>org.seleniumhq.selenium</groupId><artifactId>selenium-java</artifactId><version>3.141.59</version></dependency><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>23.0</version></dependency><dependency><groupId>com.google.code.gson</groupId><artifactId>gson</artifactId><version>2.8.2</version></dependency>
3 添加浏览器驱动
我在这里遇到了问题,不知道为什么我访问网上给出的谷歌浏览器的驱动总是跳到0.0.0.0
可能是翻”强“软件的原因,我这里附上我可以使用的一个地址吧,如果你使用其它浏览器,就去找一下相关驱动,或者下载一个谷歌浏览器,再来下载相对应的驱动。
https://chromedriver.chromium.org/downloads
如果在下面这个页面没有找到自己对应的版本驱动,就点击我图片上框起来的部分看看。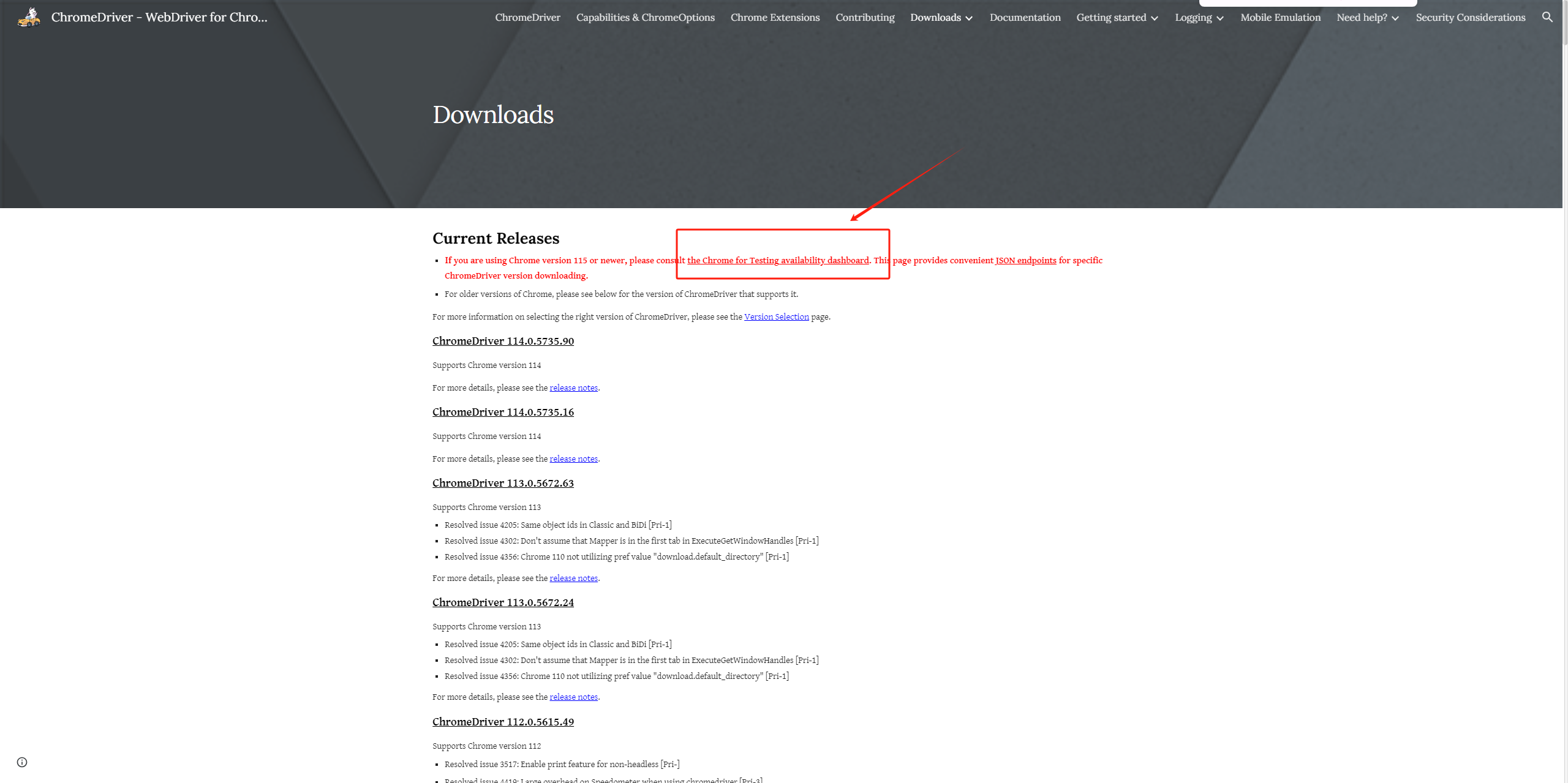
点击之后是这个页面
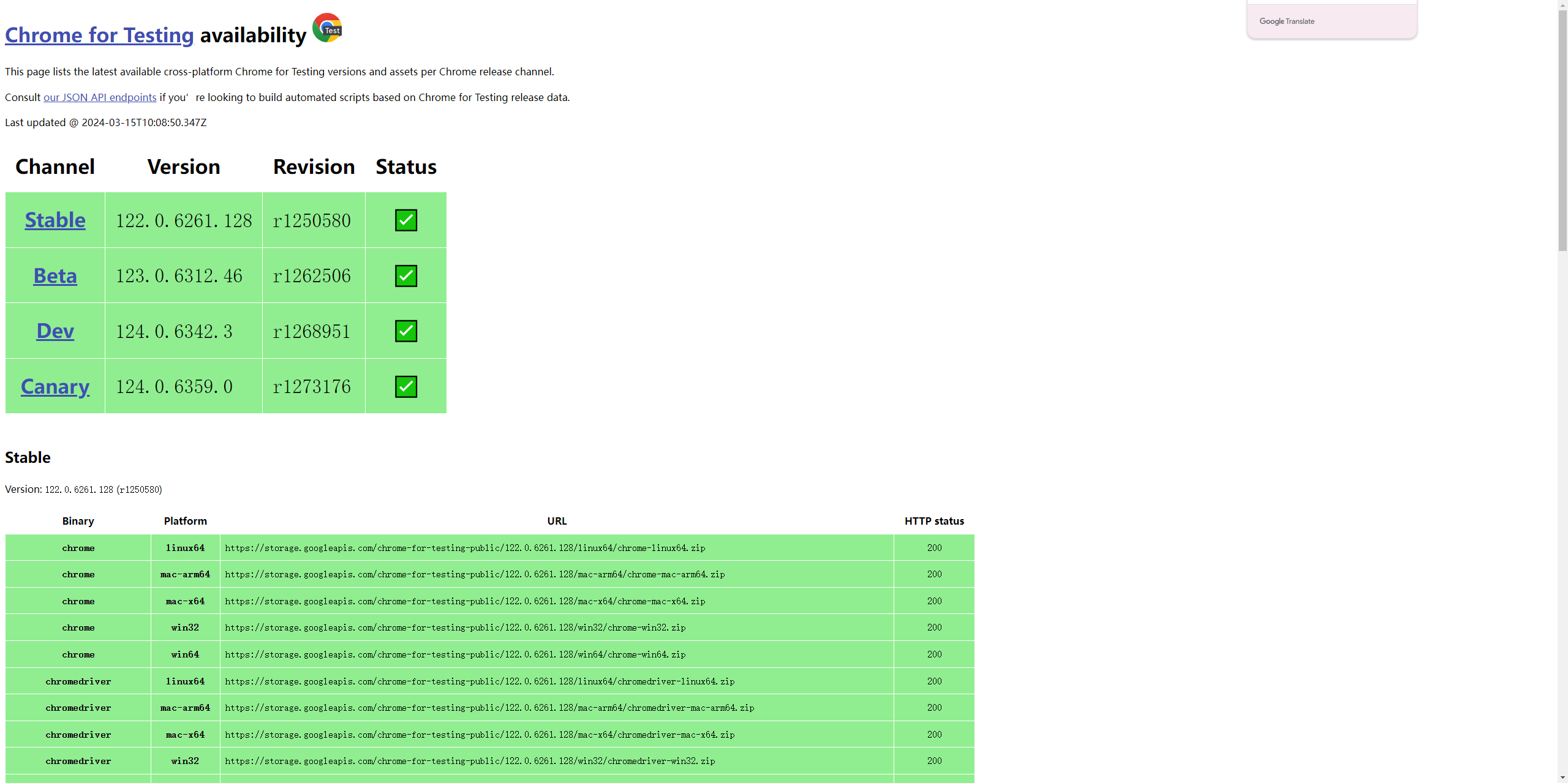
我的版本是122.0.6261.129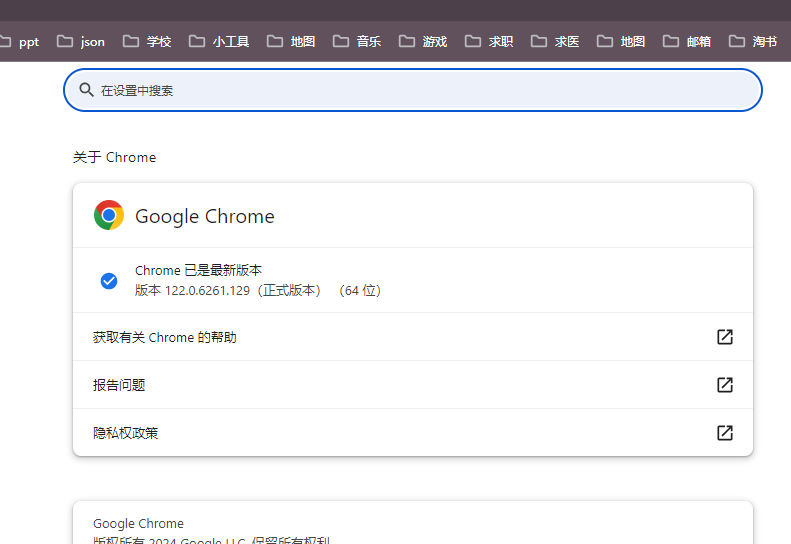
但是我写博客这时只有122.0.6261.128的,所以我就下载了这个 128的。
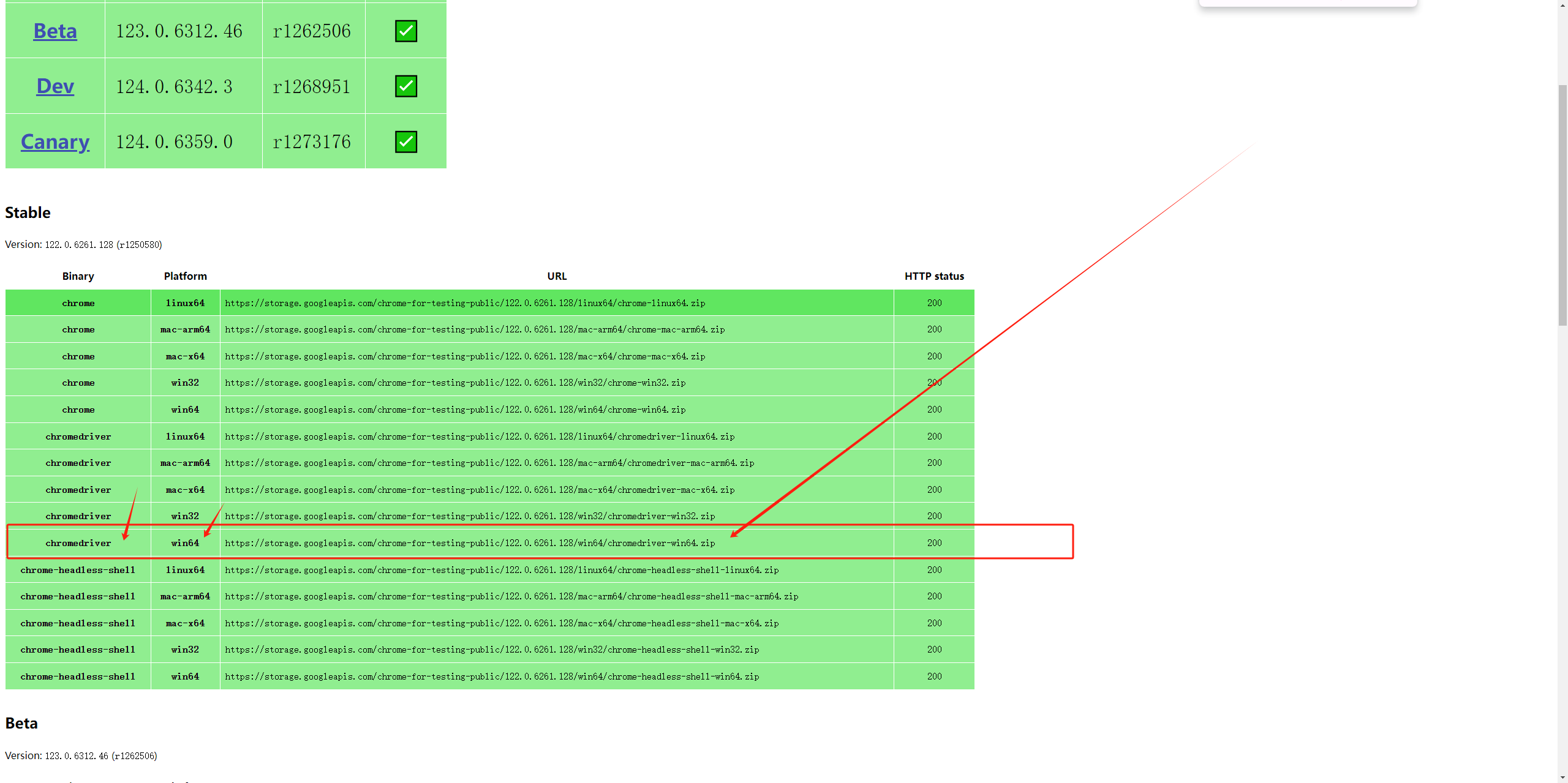
别下载错了 记得看是chromedriver不是chrome(我就下错了。。。)
4 驱动的路径
我们把下载的压缩包解压,找到“chromedriver.exe”,并把它放置到与浏览器“Chrome.exe”相同的文件夹下。
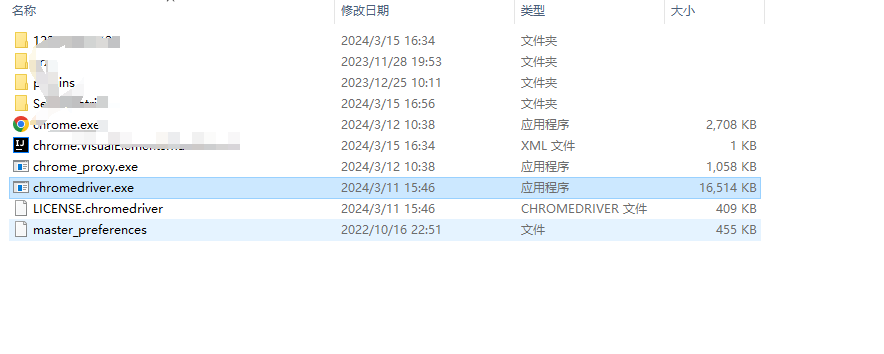
5 使用
项目中新建一个java文件
在java中使用不同浏览器: 首先配置驱动属性,指定驱动文件路径
System.setProperty("webdriver.chrome.driver","Q:\\chromedriver.exe");
获取WebDriver并打开一个新的浏览器窗口
WebDriver driver =newChromeDriver();//Chrome浏览器WebDriver driver =newFirefoxDriver();//Firefox浏览器WebDriver driver =newEdgeDriver();//Edge浏览器WebDriver driver =newInternetExplorerDriver();// Internet Explorer浏览器WebDriver driver =newOperaDriver();//Opera浏览器WebDriver driver =newPhantomJSDriver();//PhantomJS
6 效果图
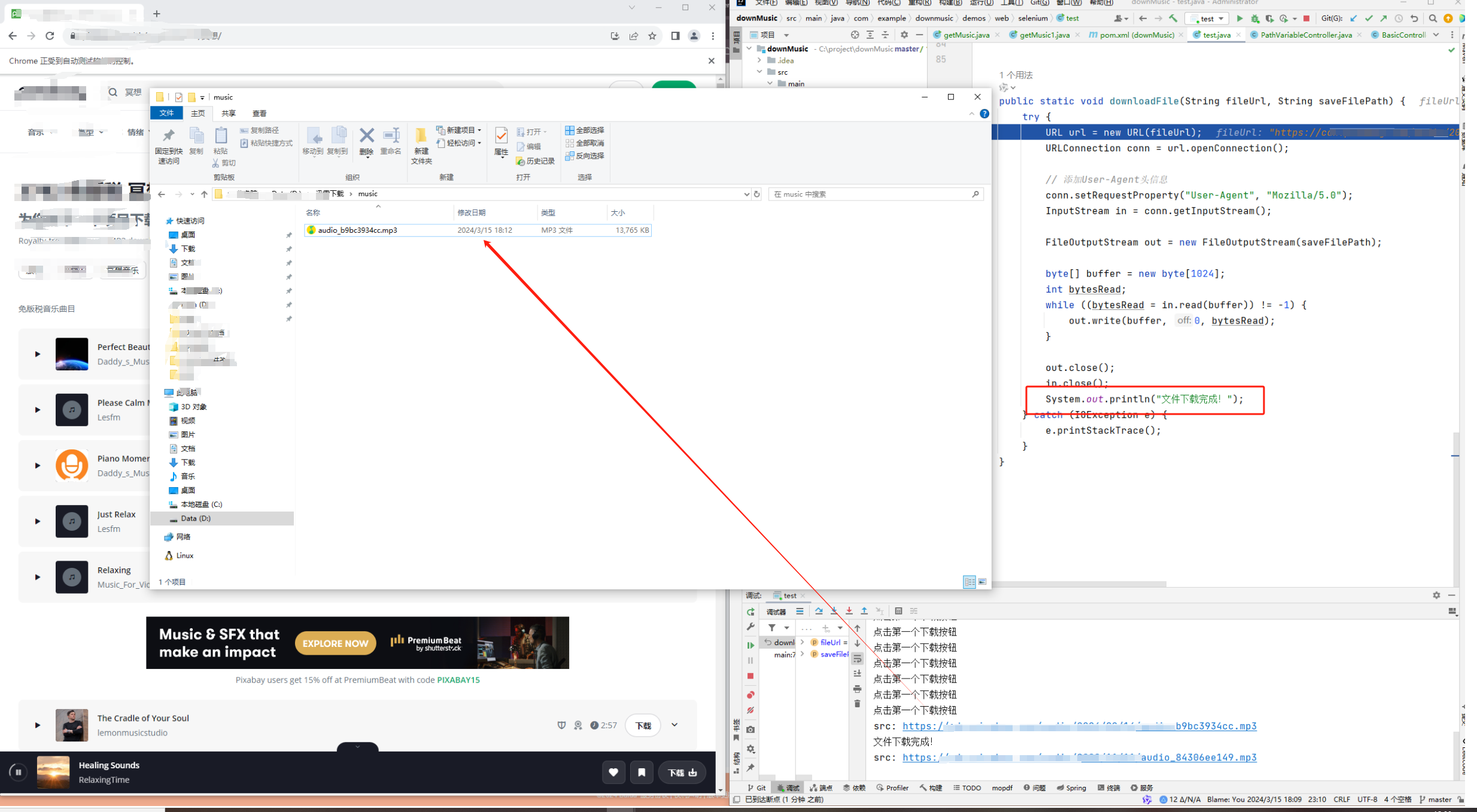
7 完整的项目案例
importorg.openqa.selenium.By;importorg.openqa.selenium.JavascriptExecutor;importorg.openqa.selenium.WebDriver;importorg.openqa.selenium.WebElement;importorg.openqa.selenium.chrome.ChromeDriver;importjava.io.FileOutputStream;importjava.io.IOException;importjava.io.InputStream;importjava.net.URL;importjava.net.URLConnection;importjava.util.List;publicclass downPixabayMusic {publicstaticvoidmain(String[] args){//这里修改一下路径System.setProperty("webdriver.chrome.driver","C:\\Program Files\\Google\\Chrome\\写自己的路径\\chromedriver.exe");WebDriver driver =newChromeDriver();// 打开网页
driver.get("https://pixabay.com/zh/music/search/%e5%86%a5%e6%83%b3/");// 等待页面加载完成try{Thread.sleep(5000);// 等待5秒,可根据实际情况调整}catch(InterruptedException e){
e.printStackTrace();}// 定位并点击下载按钮// WebElement downloadButton = driver.findElement(By.xpath("//a[@class='item small button download']"));/*
*
* driver.findElement(By.xpath()): 这是 Selenium WebDriver 提供的方法之一,用于查找页面上符合指定条件的元素。By.xpath() 是一种通过 XPath 表达式来定位元素的方式。XPath 是一种用于在 XML 文档中定位节点的语言,也可用于 HTML 文档。
"//a[@class='item small button download']": 这是 XPath 表达式,用于描述要查找的元素的位置。具体解释如下:
//: 表示从文档根节点开始搜索匹配的元素。
a: 表示要匹配的元素是 <a> 标签。
[@class='item small button download']: 这部分是属性条件,指定了要匹配的 <a> 元素必须具有 class 属性为 'item small button download'。这是下载按钮的特定 class 名称。
所以,整个代码行的作用就是在页面中查找一个 <a> 标签,并且该标签具有指定的 class 属性,其值为 'item small button download',然后将找到的元素存储在 WebElement 对象 downloadButton 中,以便后续操作。
* */List<WebElement> downloadButton = driver.findElements(By.xpath("//button[@aria-label=\"播放\"]"));// 循环点击每个下载按钮for(WebElement button : downloadButton){System.out.println("点击第一个下载按钮");JavascriptExecutor executor =(JavascriptExecutor)driver;
executor.executeScript("arguments[0].click();", button);// button.click();// 等待一段时间,以确保下载操作完成或者页面跳转try{Thread.sleep(2000);// 等待2秒,可根据实际情况调整}catch(InterruptedException e){
e.printStackTrace();}}// 定位所有 <audio> 标签元素List<WebElement> audioElements = driver.findElements(By.tagName("audio"));// 输出每个 <audio> 标签中的 src 属性值for(WebElement audioElement : audioElements){String src = audioElement.getAttribute("src");System.out.println("src: "+ src);// 找到最后一个斜杠的索引int lastIndex = src.lastIndexOf("/");// 截取最后一个斜杠后的子串String fileName = src.substring(lastIndex +1);// 下载文件downloadFile(src,"D:\\迅雷下载\\music\\"+fileName);}// 关闭浏览器// driver.quit();}publicstaticvoiddownloadFile(String fileUrl,String saveFilePath){try{URL url =newURL(fileUrl);URLConnection conn = url.openConnection();// 添加User-Agent头信息
conn.setRequestProperty("User-Agent","Mozilla/5.0");InputStream in = conn.getInputStream();FileOutputStream out =newFileOutputStream(saveFilePath);byte[] buffer =newbyte[1024];int bytesRead;while((bytesRead = in.read(buffer))!=-1){
out.write(buffer,0, bytesRead);}
out.close();
in.close();System.out.println("文件下载完成!");}catch(IOException e){
e.printStackTrace();}}}
```
本文转载自: https://blog.csdn.net/qq_44850489/article/details/136747016
版权归原作者 黑白极客 所有, 如有侵权,请联系我们删除。
版权归原作者 黑白极客 所有, 如有侵权,请联系我们删除。