
一、安装 Spark On Yarn
在公司中,通常采用Yarn进行资源调度,故此处采用Yarn模式的集群部署。
采用Yarn部署模式时,需要保证集群中已经安装好Hadoop集群,在此基础上才能实现Yarn模式的部署。
在Yarn模式中,Spark应用程序有两种运行模式:
yarn-client:Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出;
yarn-cluster:Driver程序运行在由RM启动的 AppMaster中,适用于生产环境
二者的主要区别:Driver在哪里!
1. Yarn配置
修改Hadoop中的 yarn-site.xml 配置
在
$HADOOP_HOME/etc/hadoop/yarn-site.xml
中增加如下配置,然后分发到集群其他节点,重启yarn 服务。(以下配置保证在运行spark job时不会抛内存不足等的异常)
<property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>
2. Spark配置
# 进入spark配置目录
$ cd /opt/bigdata/hadoop/server/spark-3.2.0-bin-hadoop3.2/conf
# copy 一个模板配置
$ cp spark-env.sh.template spark-env.sh
在spark-env.sh下加入如下配置,并分发到各节点
# Hadoop 的配置文件目录exportHADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# YARN 的配置文件目录exportYARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
# SPARK 的目录exportSPARK_HOME=/opt/bigdata/hadoop/server/spark-3.2.0-bin-hadoop3.2
# SPARK 执行文件目录exportPATH=$SPARK_HOME/bin:$PATH
3. 测试验证
spark资源调度依托yarn集群,因此只需保证hdfs、yarn集群正常运行,即可进行spark job的测试,不需要启动Spark集群;
client运行模式
$ spark-submit --masteryarn\> --deploy-mode client \>--class org.apache.spark.examples.SparkPi \>$SPARK_HOME/examples/jars/spark-examples_2.12-3.2.3.jar 20
可以在控制台输出Pi计算完成的结果:
cluster运行模式
$ spark-submit --masteryarn\> --deploy-mode cluster \>--class org.apache.spark.examples.SparkPi \>$SPARK_HOME/examples/jars/spark-examples_2.12-3.2.3.jar 20
二、HiBench性能测试
使用hibench进行测试前需要保证系统中存在如下程序
maven:用于编译hibench
scala:用于编译hibench
1. 下载解压build
1. 下载GitHub上的release
$ wget https://github.com/Intel-bigdata/HiBench/archive/refs/tags/v7.1.1.tar.gz
2. 解压到指定目录
$ tar-zxvf v7.1.1.tar.gz
3. build all也可指定版本编译,详细可参考hibench官方文档
$ mvn -Dspark=2.4-Dscala=2.11 clean package
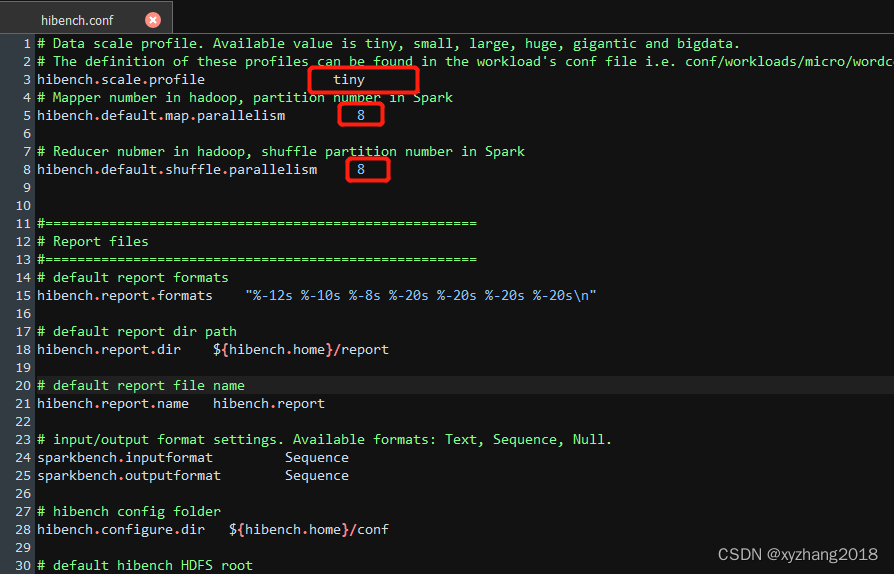
2. hibench.conf
“/opt/module/HiBench-7.1.1/conf/hibench.conf”
- hibench.scale.profile:主要配置HiBench测试的数据规模,有tiny, small, large, huge, gigantic 和- bigdata六个级别;
- hibench.default.map.parallelism:测试MapReduce时是Mapper数量,测试Spark时是分区数;
- hibench.default.shuffle.parallelism:测试MapReduce时是Reduce数量测试Spark时是shuffle分区数。
3. hibench中针对测试spark的配置文件
3.1 hadoop.conf
主要修改hibench.hadoop.home、hibench.hdfs.master和hibench.hadoop.release三个参数,过HDFS启用HA模式,则hibench.hdfs.master设置为HA对应的访问方式。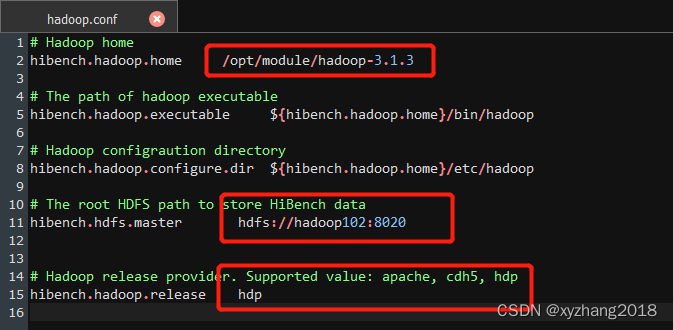
3.2 spark.conf
“/opt/module/HiBench-7.1.1/conf/spark.conf”
根据实际情况设置hibench.spark.home,hibench.spark.master为根据spark是standalone模式还是Yarn模式进行设置。当hibench.spark.master为yarn-client时,通过Yarn的ResourceManager的UI界面查看资源信息,然后设置hibench.yarn.executor.num、hibench.yarn.executor.cores、spark.executor.memory、spark.driver.memory进行性能调优。
4. 运行测试
运行过程中可能存在hdfs写入失败,权限验证失败Permission denied的问题,可以通过hdfs的命令对根目录下的文件赋予权限,使得测试数据得以正常写入:
hadoop fs -chmod 777 /
1. 准备数据:
$ /opt/module/HiBench-7.1.1/bin/workloads/micro/wordcount/prepare/prepare.sh
2. 运行测试:
$ /opt/module/HiBench-7.1.1/bin/workloads/micro/wordcount/spark/run.sh
测试后的结果位于report目录下:
此处以Hadoop测试结果为例:
参考文献:
安装部分:
https://www.cnblogs.com/yanshw/p/11614988.html
https://juejin.cn/post/7114246197988032525#heading-14
HiBench安装测试部分:
官方文档
版权归原作者 xyzhang2018 所有, 如有侵权,请联系我们删除。