
最近我在知乎受到一个付费问答,虽然开通了付费问答功能,但是我已经很久没有回答过提问者的问题。
由于时间和精力有限,抽不出整块的时间好好回答提问者的问题,又不愿意三言两语糊弄提问的同学,索性就不回答了。
但是,前几天有一个同学付费咨询我”如何用Python把3个PDF文件按交叉顺序合并在一起?“
的确,PDF、Word作为工作和学习中经常会接触到的文档格式,很难避免与其打交道,今天,就来给大家介绍一下如何使用Python完成常用的PDF、Word编辑功能,再也不用为这项简单的事情付费了!
PDF文档
PDF是一种便携式文件格式,它包含文本、图像、图表等。
与纯文本文件不同,它是一种包含".pdf"扩展名的文件,由Adobe公司发明。
这种类型的文件与任何平台如软件、硬件和操作系统无关。
安装工具包
你需要安装一个名为
pypdf2
的软件包,它可以处理扩展名为".pdf "的文件:
pip install pypdf2
安装成功,会看到如下内容:
读取PDF文件并提取数据
我们只能从pdf文件中提取文本内容,因为PyPDF2在提取多媒体内容时有一个限制,logo、图片等无法从中提取。
上面的代码中的
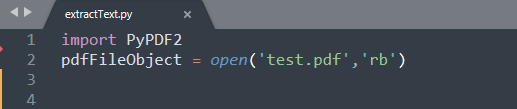
import
语句得到了PyPDF2模块。你需要使用
open('pdfFileName' , 'openMode')
,其中
pdfFilename
是文件名称,
openMode
是
rb
,即只读取二进制格式。

PyPDF2有一个名为 "PdfFileReader"的方法,它接收新创建的对象 "pdfFileObject"。你现在可以从 "pdfFileObject "中访问名为 "numPages"的属性,它能给返回总页数。

你可以使用pdfReaderObject里面的'getPage(0)'方法来获取第1页。然后将结果存储在'firstPageObject'中,通过使用'extractText()'方法可以打印出该特定页面中的所有文本。

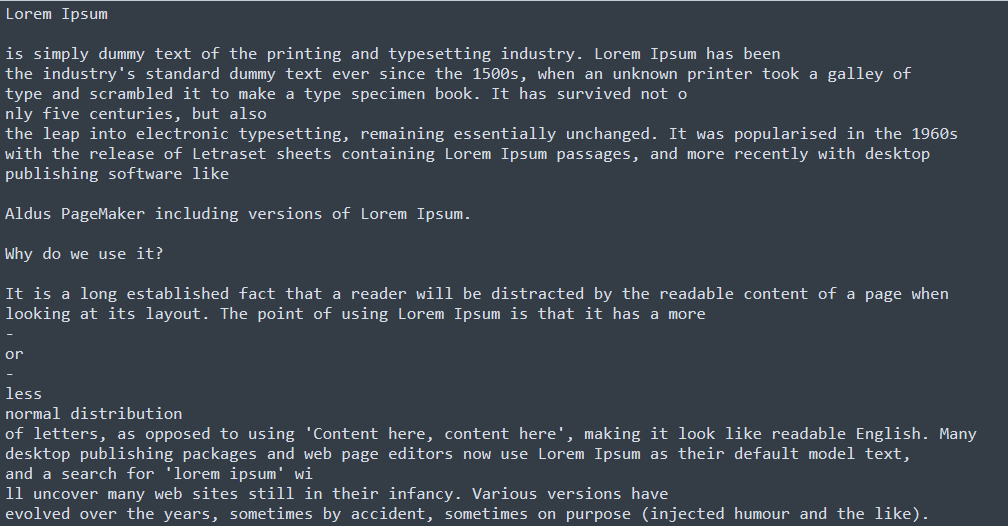
上面的代码给出了pdf文件的所有文本。但是,图像没有显示在终端,这一点用pyPDF2是无法获取到。
合并PDF
你将把两个不同的pdf文件合并成一个pdf文件,首先需要获取2个用于测试的PDF文档。
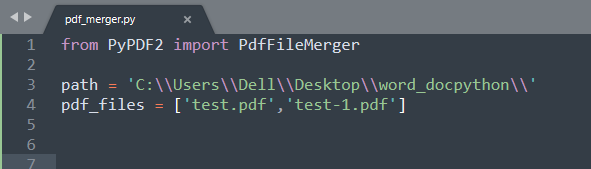
我们需要从PyPDF2包中导入PdfFileMerger模块,它能够用于合并pdf文件。
指定'path',它表示文件所在的文件夹的路径。另外,要合并的pdf文件被包含在'pdf_files'的列表中。
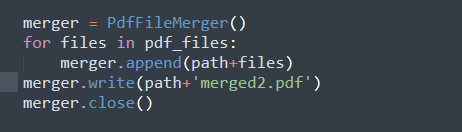
首先,需要通过
PdfFileMerger
创建一个合并对象,然后针对列表中的每个文件进行的遍历,其中合并是通过向'append'方法传递路径和文件来完成的。
最后,通过使用'merger.write()'可以获得最终的输出,在这里可以获得合并后的内容和新的PDF文件名。

上图显示了一个'merged.pdf',它由'test.pdf'和'test-1.pdf'的内容合并而成。
Word文档
Word文件由文件名末尾的".docx "扩展名组成。这些文件并不像纯文本文件那样只包含文本,而是包括富文本文件。富文本文件包含文件的不同结构,这些结构有大小、对齐、颜色、图片、字体等。
如果你有一个用于处理Word文档的应用程序,那将是最好的。适用于Windows和Mac操作系统的流行应用程序是Microsoft Word,但它是一个付费订阅软件。
当然,也有一个免费的替代选择,如 "LibreOffice",它是一个预装在Linux中的应用程序。这些应用程序可以在Windows和Mac操作系统中下载。
本文,将介绍如何通过Python免费操作Word文档。
安装工具包
你需要安装一个名为 "python-docx"的软件包,它可以处理扩展名为".docx "的word文档。

编辑Word文档

你可以看到上面第一行中的 "document"模块是从 "docx "包中导入的。
第二行的代码通过Document对象的帮助生成了一个新的word文档。
使用'document.save()',文件名被保存为'first.docx'。
添加标题
上面的代码包含一个
Document()
打开一个新文件,
document.save('addHeader.docx')
被用来创建一个新编辑的docx文件。
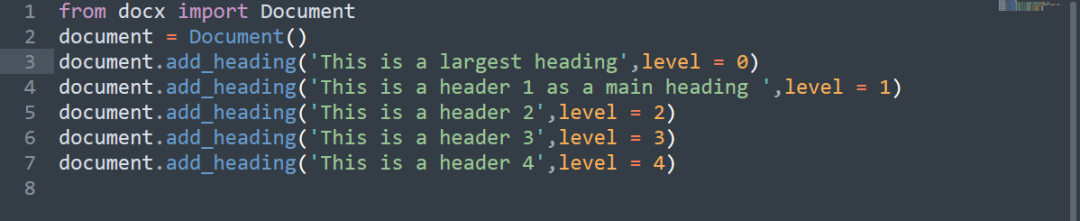
你可以通过
add_heading('text,' level=number)
方法添加标题,该方法将文本作为标题,标题级别从0到4开始。

上述代码给出的输出是一个新创建的'addedHeader.docx'文件,其中0级的标题是文本下面的横线,而1级的标题是主标题。
同样地,其他的标题是副标题,其字体大小依次递减。
添加段落
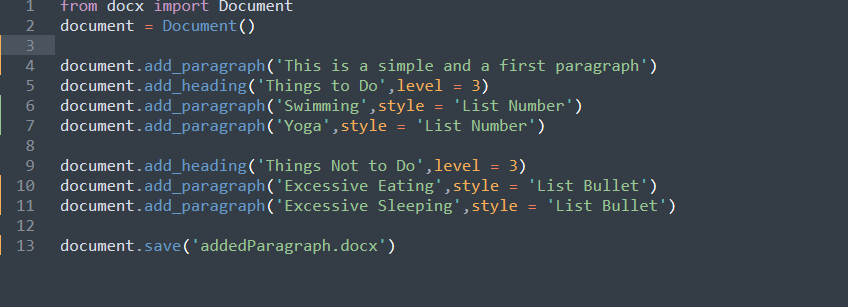
上述代码包含一个
Document()
,它打开了一个新的文档文件,
document.save('addParagraph.docx')
被用来创建一个新编辑的docx文件。你可以通过
add_paragraph('text,' style='required_style')
方法添加标题,该方法接收文本,同时
style
是一个可选的参数,可以使用'List Number'和'List Bullet'。
上述代码给出的输出是一个新创建的
addedParagraph.docx
文件,在第一行有一个简单的段落。
同样,有一个标题,在它下面有一个有序的列表,包含一个编号为1和2的项目。
添加图片

上面的代码包含一个
Document()
,它创建了一个新的文档文件,
document.save('addPicture.docx')
用于创建一个新编辑的docx文件。
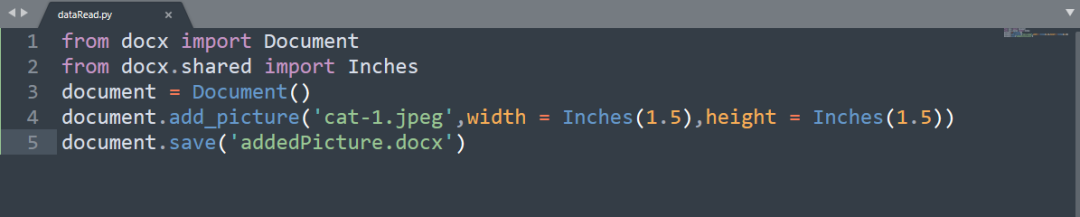
你可以通过使用
add_picture()
来添加图片,它包含的第一个参数是
cat-1.jpeg
是猫的图片的路径。

宽度和高度是可选的参数,默认为
72 dp
,但我们为我们的目的使用了
Inches
。
上述代码给出的输出是一个新创建的
addedPicture.docx
文件,其中包含一张猫的图像,图像的宽度和高度都是1.25英寸。
读取Word文档
接下来,我们使用Python中读取一个word文档。
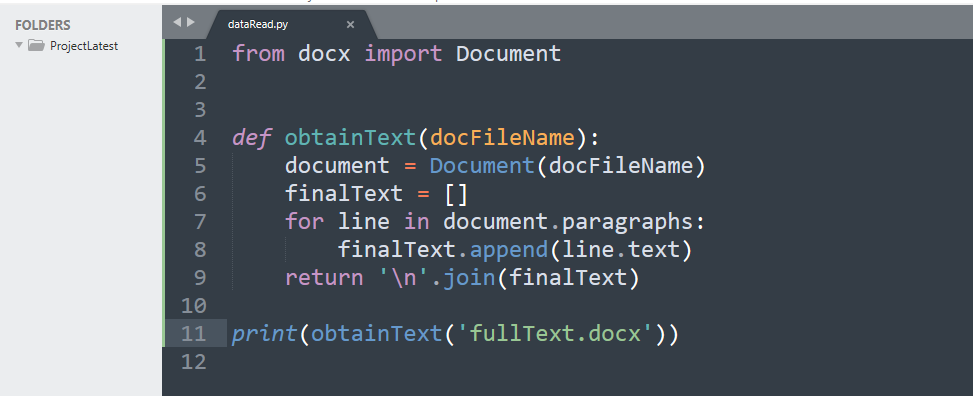
代码的第一行从
docx
模块中导入Document,用来传递所需的文档文件,并创建一个对象。
obtainText
是一个函数,接收文件
fullText.docx
。循环是针对每个段落进行的,这些段落由
document.parages
访问,并使用
append
方法插入到一个空列表中。
最后,该函数返回一个以”另起一行“结束的段落列表。
上面的输出给出了没有任何样式、颜色的纯文本。
接下来,你就可以解放双手,使用Python自动完成PDF、Word文档操作了!
版权归原作者 七步编程 所有, 如有侵权,请联系我们删除。