
Flink LookupJoin攒批查询
需求背景
使用Lookup Join进行维表关联时,流表数据需要实时与维表数据进行关联。使用Cache会导致数据关联不准确,不使用Cache会造成数据库服务压力。攒批查询是指攒够一定批数量的数据,相同的查询Key只查询一次,从而减少查询次数。对短时间Key重复率比较高的场景有不错的性能提升。
技术实现
如下流程图所示,技术实现主要包含两个部分:
- 解析Flink SQL中的Hints参数,从而来推断是否要开启攒批处理
- 实现攒批查询的处理逻辑,即BatchLookupJoinRunner
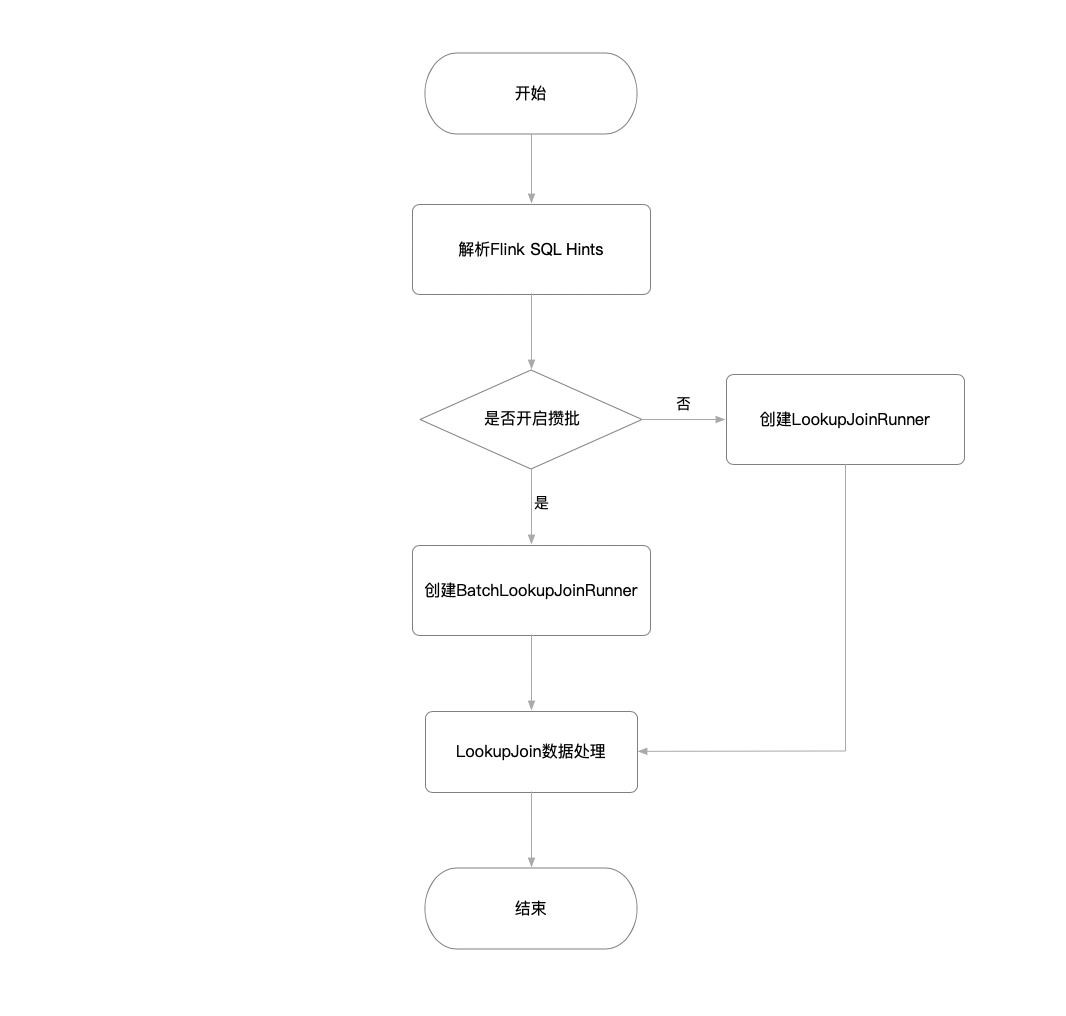
解析Hints参数
Flink官网有对SQL提示的详情描述,具体参考:https://nightlies.apache.org/flink/flink-docs-release-1.19/zh/docs/dev/table/sql/queries/hints/#lookup。
LOOKUP提示允许用户对Flink优化器进行建议配置,如:
- 使用同步或异步的查找函数
- 配置异步查找相关参数
- 启用延迟重试查找策略
利用这个提示机制,我们可以通过提示配置来判断是否需要进行攒批处理,主要涉及到两个参数:
- batch-size: 攒批条数,达到设置条数后执行查询操作,默认值为0,0表示不开启攒批
- batch-interval: 攒批间隔,达到设置间隔后执行查询操作,默认为1 s
最终实现的效果如下:
SELECT /*+ LOOKUP('table'='o','batch-size'='10000','batch-interval'='1s') */ o.order_id, o.total, c.country, c.zip
FROM Orders AS o
JOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id
新增BatchLookupOptions实现
该类用来描述攒批的参数,以及从Hints中提取对应的参数。具体试下如下:
package org.apache.flink.table.planner.plan.utils;
import org.apache.calcite.rel.hint.RelHint;
import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.annotation.JsonCreator;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.annotation.JsonProperty;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.annotation.JsonTypeName;
import javax.annotation.Nullable;
import java.time.Duration;
import java.util.Objects;
import static org.apache.flink.configuration.ConfigOptions.key;
/** BatchLookupOptions includes async related options. */
@JsonIgnoreProperties(ignoreUnknown = true)
@JsonTypeName("BatchOptions")
public class BatchLookupOptions {
public static final String FIELD_NAME_BATCH_SIZE = "batch-size";
public static final String FIELD_NAME_BATCH_INTERVAL = "batch-interval";
public static final ConfigOption<Integer> BATCH_SIZE =
key("batch-size")
.intType()
.defaultValue(0)
.withDescription("The batch size for batch lookup. If the batch size is 0, it means that the batch lookup is disabled.");
public static final ConfigOption<Duration> BATCH_INTERVAL =
key("batch-interval")
.durationType()
.defaultValue(Duration.ofSeconds(1))
.withDescription("The batch interval for batch lookup.");
@JsonProperty(FIELD_NAME_BATCH_SIZE)
public final Integer batchSize;
@JsonProperty(FIELD_NAME_BATCH_INTERVAL)
public final Duration batchInterval;
@JsonCreator
public BatchLookupOptions(
@JsonProperty(FIELD_NAME_BATCH_SIZE) Integer batchSize,
@JsonProperty(FIELD_NAME_BATCH_INTERVAL) Duration batchInterval
) {
this.batchSize = batchSize;
this.batchInterval = batchInterval;
}
public boolean enabled() {
return batchSize > 0;
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
BatchLookupOptions that = (BatchLookupOptions) o;
return Objects.equals(batchSize, that.batchSize) && batchInterval == that.batchInterval;
}
@Override
public int hashCode() {
return Objects.hash(batchSize, batchInterval);
}
@Override
public String toString() {
return "BatchLookupOptions{" +
", batchSize=" + batchSize +
", batchInterval=" + batchInterval +
'}';
}
@Nullable
public static BatchLookupOptions fromJoinHint(@Nullable RelHint lookupJoinHint) {
if (null != lookupJoinHint) {
Configuration conf = Configuration.fromMap(lookupJoinHint.kvOptions);
Integer batchSize = conf.get(BATCH_SIZE);
Duration batchInterval = conf.get(BATCH_INTERVAL);
return new BatchLookupOptions(batchSize, batchInterval);
}
return null;
}
}
修改StreamPhysicalLookupJoin
目的是通过解析后的Hints生成Batch参数,并传递给StreamExecLookupJoin。
该类是用Scala编写,需要在对应scala包下开发,org.apache.flink.table.planner.plan.nodes.physical.stream.StreamPhysicalLookupJoin。主要做两个变动:
- 构造代码中新增batchOptions参数
// Support batch lookup
lazy val batchOptions:Option[BatchLookupOptions] = Option.apply(BatchLookupOptions.fromJoinHint(lookupHint.orNull))
- 将batchOptions传入StreamExecLookupJoin构造方法中
override def translateToExecNode(): ExecNode[_] = {
val (projectionOnTemporalTable, filterOnTemporalTable) = calcOnTemporalTable match {
case Some(program) =>
val (projection, filter) = FlinkRexUtil.expandRexProgram(program)
(JavaScalaConversionUtil.toJava(projection), filter.orNull)
case _ =>
(null, null)
}
new StreamExecLookupJoin(
tableConfig,
JoinTypeUtil.getFlinkJoinType(joinType),
remainingCondition.orNull,
new TemporalTableSourceSpec(temporalTable),
allLookupKeys.map(item => (Int.box(item._1), item._2)).asJava,
projectionOnTemporalTable,
filterOnTemporalTable,
lookupKeyContainsPrimaryKey(),
upsertMaterialize,
asyncOptions.orNull,
retryOptions.orNull,
// add options for Batch
batchOptions.orNull,
inputChangelogMode,
InputProperty.DEFAULT,
FlinkTypeFactory.toLogicalRowType(getRowType),
getRelDetailedDescription)
}
修改CommonExecLookupJoin
目的是接受BatchLookupOptions参数,并根据参数创建BatchLookupJoinRunner实例。
类路径:
org.apache.flink.table.planner.plan.nodes.exec.common.CommonExecLookupJoin
- 新增属性
public static final String FIELD_NAME_BATCH_OPTIONS = "batchOptions";
@JsonProperty(FIELD_NAME_BATCH_OPTIONS)
@JsonInclude(JsonInclude.Include.NON_NULL)
private final @Nullable BatchLookupOptions batchOptions;
- 新增构造方法,支持BatchLookupOptions参数的传入
protected CommonExecLookupJoin(
int id,
ExecNodeContext context,
ReadableConfig persistedConfig,
FlinkJoinType joinType,
@Nullable RexNode joinCondition,
// TODO: refactor this into TableSourceTable, once legacy TableSource is removed
TemporalTableSourceSpec temporalTableSourceSpec,
Map<Integer, LookupJoinUtil.LookupKey> lookupKeys,
@Nullable List<RexNode> projectionOnTemporalTable,
@Nullable RexNode filterOnTemporalTable,
@Nullable LookupJoinUtil.AsyncLookupOptions asyncLookupOptions,
@Nullable LookupJoinUtil.RetryLookupOptions retryOptions,
// 新增batch参数
@Nullable BatchLookupOptions batchOptions,
ChangelogMode inputChangelogMode,
List<InputProperty> inputProperties,
RowType outputType,
String description) {
super(id, context, persistedConfig, inputProperties, outputType, description);
checkArgument(inputProperties.size() == 1);
this.joinType = checkNotNull(joinType);
this.joinCondition = joinCondition;
this.lookupKeys = Collections.unmodifiableMap(checkNotNull(lookupKeys));
this.temporalTableSourceSpec = checkNotNull(temporalTableSourceSpec);
this.projectionOnTemporalTable = projectionOnTemporalTable;
this.filterOnTemporalTable = filterOnTemporalTable;
this.inputChangelogMode = inputChangelogMode;
this.asyncLookupOptions = asyncLookupOptions;
this.retryOptions = retryOptions;
this.batchOptions = batchOptions;
}
/**
* 兼容之前的构造方法
*/
protected CommonExecLookupJoin(
int id,
ExecNodeContext context,
ReadableConfig persistedConfig,
FlinkJoinType joinType,
@Nullable RexNode joinCondition,
// TODO: refactor this into TableSourceTable, once legacy TableSource is removed
TemporalTableSourceSpec temporalTableSourceSpec,
Map<Integer, LookupJoinUtil.LookupKey> lookupKeys,
@Nullable List<RexNode> projectionOnTemporalTable,
@Nullable RexNode filterOnTemporalTable,
@Nullable LookupJoinUtil.AsyncLookupOptions asyncLookupOptions,
@Nullable LookupJoinUtil.RetryLookupOptions retryOptions,
ChangelogMode inputChangelogMode,
List<InputProperty> inputProperties,
RowType outputType,
String description) {
this(id,
context,
persistedConfig,
joinType,
joinCondition,
temporalTableSourceSpec,
lookupKeys,
projectionOnTemporalTable,
filterOnTemporalTable,
asyncLookupOptions,
retryOptions,
null,
inputChangelogMode,
inputProperties,
outputType,
description);
}
- 修改createSyncLookupJoinFunction,支持根据参数创建不同的LookupRunner
private ProcessFunction<RowData, RowData> createSyncLookupJoinFunction(
RelOptTable temporalTable,
ExecNodeConfig config,
ClassLoader classLoader,
Map<Integer, LookupJoinUtil.LookupKey> allLookupKeys,
TableFunction<?> syncLookupFunction,
RelBuilder relBuilder,
RowType inputRowType,
RowType tableSourceRowType,
RowType resultRowType,
boolean isLeftOuterJoin,
boolean isObjectReuseEnabled) {
DataTypeFactory dataTypeFactory =
ShortcutUtils.unwrapContext(relBuilder).getCatalogManager().getDataTypeFactory();
int[] orderedLookupKeys = LookupJoinUtil.getOrderedLookupKeys(allLookupKeys.keySet());
GeneratedFunction<FlatMapFunction<RowData, RowData>> generatedFetcher =
LookupJoinCodeGenerator.generateSyncLookupFunction(
config,
classLoader,
dataTypeFactory,
inputRowType,
tableSourceRowType,
resultRowType,
allLookupKeys,
orderedLookupKeys,
syncLookupFunction,
StringUtils.join(temporalTable.getQualifiedName(), "."),
isObjectReuseEnabled);
RelDataType projectionOutputRelDataType = getProjectionOutputRelDataType(relBuilder);
RowType rightRowType =
getRightOutputRowType(projectionOutputRelDataType, tableSourceRowType);
GeneratedCollector<ListenableCollector<RowData>> generatedCollector =
LookupJoinCodeGenerator.generateCollector(
new CodeGeneratorContext(config, classLoader),
inputRowType,
rightRowType,
resultRowType,
JavaScalaConversionUtil.toScala(Optional.ofNullable(joinCondition)),
JavaScalaConversionUtil.toScala(Optional.empty()),
true);
ProcessFunction<RowData, RowData> processFunc;
// if batch mode is enabled, use BatchLookupJoinRunner
if (batchOptions != null && batchOptions.enabled()) {
processFunc = new BatchLookupJoinRunner(
generatedFetcher,
generatedCollector,
LookupJoinUtil.getOrderedLookupKeys(allLookupKeys.keySet()),
tableSourceRowType,
isLeftOuterJoin,
rightRowType.getFieldCount(),
batchOptions.batchSize,
batchOptions.batchInterval.toMillis()
);
} else if (projectionOnTemporalTable != null) {
// a projection or filter after table source scan
GeneratedFunction<FlatMapFunction<RowData, RowData>> generatedCalc =
LookupJoinCodeGenerator.generateCalcMapFunction(
config,
classLoader,
JavaScalaConversionUtil.toScala(projectionOnTemporalTable),
filterOnTemporalTable,
projectionOutputRelDataType,
tableSourceRowType);
processFunc =
new LookupJoinWithCalcRunner(
generatedFetcher,
generatedCalc,
generatedCollector,
isLeftOuterJoin,
rightRowType.getFieldCount());
} else {
// right type is the same as table source row type, because no calc after temporal table
processFunc =
new LookupJoinRunner(
generatedFetcher,
generatedCollector,
isLeftOuterJoin,
rightRowType.getFieldCount());
}
return processFunc;
}
修改StreamExecLookupJoin
目的是接受BatchLookupOptions参数
类路径:org.apache.flink.table.planner.plan.nodes.exec.stream.StreamExecLookupJoin
- 新增构造函数
public StreamExecLookupJoin(
ReadableConfig tableConfig,
FlinkJoinType joinType,
@Nullable RexNode joinCondition,
TemporalTableSourceSpec temporalTableSourceSpec,
Map<Integer, LookupJoinUtil.LookupKey> lookupKeys,
@Nullable List<RexNode> projectionOnTemporalTable,
@Nullable RexNode filterOnTemporalTable,
boolean lookupKeyContainsPrimaryKey,
boolean upsertMaterialize,
@Nullable LookupJoinUtil.AsyncLookupOptions asyncLookupOptions,
@Nullable LookupJoinUtil.RetryLookupOptions retryOptions,
// 新增batch参数
@Nullable BatchLookupOptions batchOptions,
ChangelogMode inputChangelogMode,
InputProperty inputProperty,
RowType outputType,
String description) {
this(
ExecNodeContext.newNodeId(),
ExecNodeContext.newContext(StreamExecLookupJoin.class),
ExecNodeContext.newPersistedConfig(StreamExecLookupJoin.class, tableConfig),
joinType,
joinCondition,
temporalTableSourceSpec,
lookupKeys,
projectionOnTemporalTable,
filterOnTemporalTable,
lookupKeyContainsPrimaryKey,
upsertMaterialize,
asyncLookupOptions,
retryOptions,
batchOptions,
inputChangelogMode,
Collections.singletonList(inputProperty),
outputType,
description);
}
实现攒批查询的处理逻辑
攒批支持按照条数、按照时间段攒批。
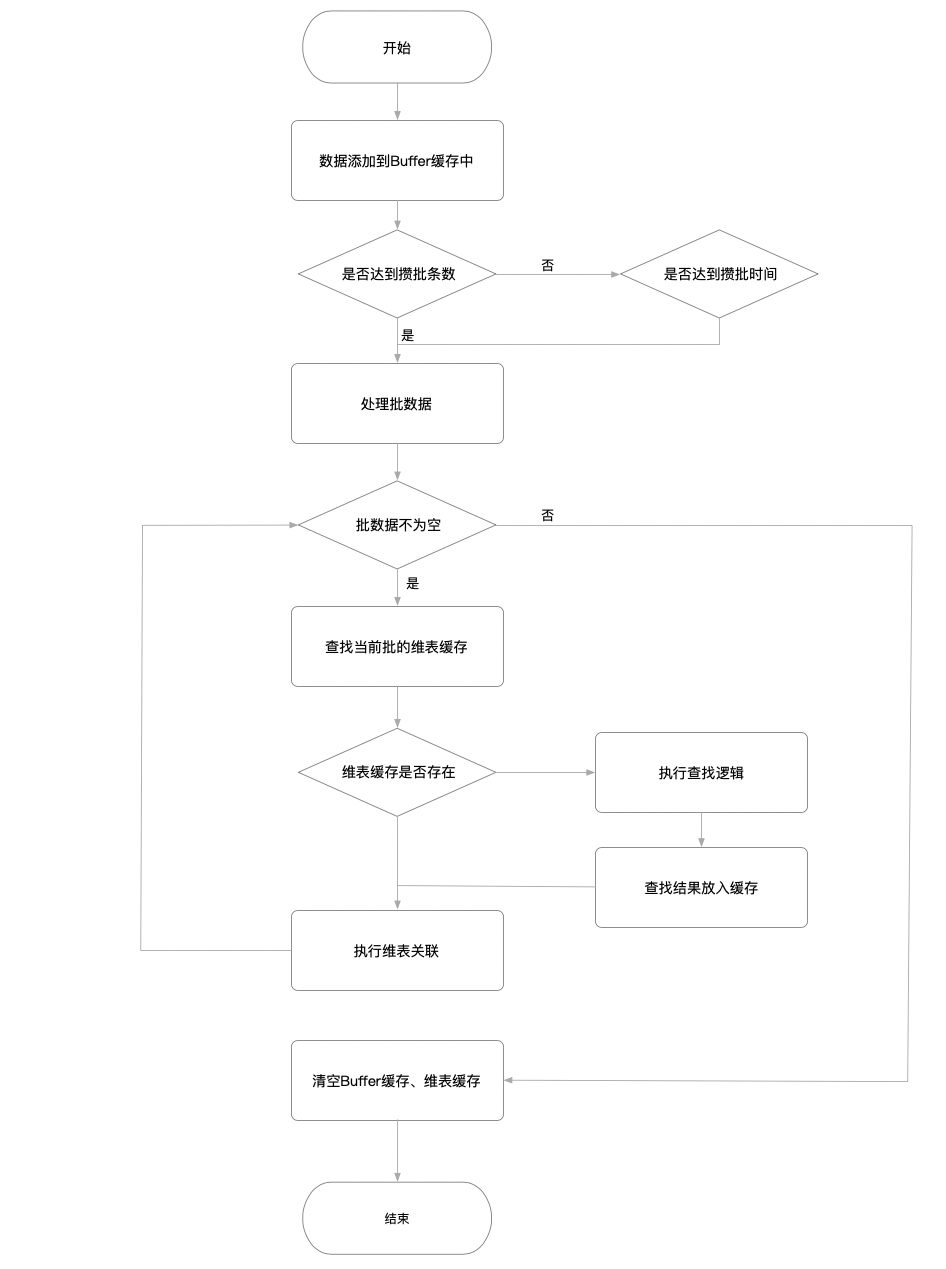
包路径:org.apache.flink.table.runtime.operators.join.lookup.BatchLookupJoinRunner
实现代码:
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.flink.table.runtime.operators.join.lookup;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.IterationRuntimeContext;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.api.common.functions.util.FunctionUtils;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.metrics.Counter;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.table.api.TableException;
import org.apache.flink.table.data.GenericRowData;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.data.utils.JoinedRowData;
import org.apache.flink.table.runtime.collector.ListenableCollector;
import org.apache.flink.table.runtime.generated.GeneratedCollector;
import org.apache.flink.table.runtime.generated.GeneratedFunction;
import org.apache.flink.table.types.logical.RowType;
import org.apache.flink.util.Collector;
import javax.annotation.Nullable;
import java.util.*;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
/** The join runner to lookup the dimension table. */
public class BatchLookupJoinRunner extends ProcessFunction<RowData, RowData> implements CheckpointedFunction {
private static final long serialVersionUID = -4521543015709964734L;
private final GeneratedFunction<FlatMapFunction<RowData, RowData>> generatedFetcher;
private final GeneratedCollector<ListenableCollector<RowData>> generatedCollector;
private final int[] lookupKeyIndicesInOrder;
private final RowType tableRowType;
protected final boolean isLeftOuterJoin;
protected final int tableFieldsCount;
private final List<RowData> recordBuffers;
private transient ListState<RowData> bufferState;
private transient FlatMapFunction<RowData, RowData> fetcher;
protected transient JoinedRowData outRow;
private transient GenericRowData nullRow;
private transient RowData.FieldGetter[] keyFieldGetters;
private transient Map<RowData, Collection<RowData>> cache;
private transient CollectorWrapper collector;
private transient ScheduledExecutorService executorService;
private transient Collector<RowData> collectorHolder;
private final int batchSize;
private final long batchInterval;
private transient Counter bufferCounter;
public BatchLookupJoinRunner(
GeneratedFunction<FlatMapFunction<RowData, RowData>> generatedFetcher,
GeneratedCollector<ListenableCollector<RowData>> generatedCollector,
int[] lookupKeyIndicesInOrder,
RowType tableRowType,
boolean isLeftOuterJoin,
int tableFieldsCount,
int batchSize,
long batchInterval
) {
this.generatedFetcher = generatedFetcher;
this.generatedCollector = generatedCollector;
this.isLeftOuterJoin = isLeftOuterJoin;
this.tableFieldsCount = tableFieldsCount;
this.lookupKeyIndicesInOrder = lookupKeyIndicesInOrder;
this.tableRowType = tableRowType;
this.batchSize = batchSize;
this.batchInterval = batchInterval;
this.recordBuffers = new ArrayList<>(batchSize);
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
this.fetcher = generatedFetcher.newInstance(getRuntimeContext().getUserCodeClassLoader());
FunctionUtils.setFunctionRuntimeContext(fetcher, getRuntimeContext());
FunctionUtils.setFunctionRuntimeContext(collector, getRuntimeContext());
FunctionUtils.openFunction(fetcher, parameters);
FunctionUtils.openFunction(collector, parameters);
this.nullRow = new GenericRowData(tableFieldsCount);
this.outRow = new JoinedRowData();
this.keyFieldGetters = Arrays.stream(lookupKeyIndicesInOrder)
.mapToObj(i -> RowData.createFieldGetter(tableRowType.getTypeAt(i), i))
.toArray(RowData.FieldGetter[]::new);
this.cache = new HashMap<>(batchSize);
this.collector = new CollectorWrapper(generatedCollector.newInstance(getRuntimeContext().getUserCodeClassLoader()));
// Start a timer to emit the buffered records
this.executorService = Executors.newScheduledThreadPool(1);
this.executorService.scheduleAtFixedRate(() -> {
try {
synchronized (recordBuffers) {
if (collectorHolder != null && !recordBuffers.isEmpty()) {
emit(collectorHolder);
}
}
} catch (Exception e) {
throw new TableException("Failed to emit the buffered records.", e);
}
}, 0, batchInterval, TimeUnit.MILLISECONDS);
bufferCounter = getRuntimeContext().getMetricGroup().counter("batchBuffers");
}
@Override
public void processElement(RowData in, Context ctx, Collector<RowData> out) throws Exception {
synchronized (recordBuffers) {
bufferCounter.inc();
recordBuffers.add(in);
if (recordBuffers.size() >= batchSize) {
emit(out);
} else {
this.collectorHolder = out;
}
}
}
public void emit(Collector<RowData> out) throws Exception {
for (RowData input : recordBuffers) {
GenericRowData key = new GenericRowData(lookupKeyIndicesInOrder.length);
for (int i = 0; i < lookupKeyIndicesInOrder.length; i++) {
key.setField(i, keyFieldGetters[i].getFieldOrNull(input));
}
prepareCollector(input, out);
Collection<RowData> value = cache.get(key);
if (value != null) {
value.forEach(collector::collect);
} else {
doFetch(input);
if (collector.isCollected()) {
cache.put(key, new ArrayList<>(collector.records));
}
}
padNullForLeftJoin(input, out);
}
bufferCounter.dec(recordBuffers.size());
recordBuffers.clear();
}
public void prepareCollector(RowData in, Collector<RowData> out) {
collector.setCollector(out);
collector.setInput(in);
collector.reset();
}
public void doFetch(RowData in) throws Exception {
// fetcher has copied the input field when object reuse is enabled
fetcher.flatMap(in, getFetcherCollector());
}
public void padNullForLeftJoin(RowData in, Collector<RowData> out) {
if (isLeftOuterJoin && !collector.isCollected()) {
outRow.replace(in, nullRow);
outRow.setRowKind(in.getRowKind());
out.collect(outRow);
}
}
public Collector<RowData> getFetcherCollector() {
return collector;
}
@Override
public void close() throws Exception {
if (fetcher != null) {
FunctionUtils.closeFunction(fetcher);
}
if (collector != null) {
FunctionUtils.closeFunction(collector);
}
if (executorService != null) {
executorService.shutdown();
}
super.close();
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
bufferState.clear();
bufferState.addAll(recordBuffers);
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
this.bufferState = context
.getOperatorStateStore()
.getListState(
new ListStateDescriptor<>(
"batch-lookup-buffers-state"
, RowData.class)
);
this.recordBuffers.addAll((List<RowData>) bufferState.get());
}
public static class CollectorWrapper extends ListenableCollector<RowData> {
private final ListenableCollector<RowData> delegate;
private final List<RowData> records;
public CollectorWrapper(ListenableCollector<RowData> delegate) {
this.delegate = delegate;
this.records = new ArrayList<>();
}
@Override
public void setCollectListener(@Nullable CollectListener<RowData> collectListener) {
this.delegate.setCollectListener(collectListener);
}
@Override
public void setInput(Object input) {
this.delegate.setInput(input);
}
@Override
public Object getInput() {
return this.delegate.getInput();
}
@Override
public void setCollector(Collector<?> collector) {
this.delegate.setCollector(collector);
}
@Override
public void outputResult(Object result) {
this.delegate.outputResult(result);
}
@Override
public boolean isCollected() {
return this.delegate.isCollected();
}
@Override
public void close() {
this.delegate.close();
}
@Override
public void setRuntimeContext(RuntimeContext t) {
this.delegate.setRuntimeContext(t);
}
@Override
public RuntimeContext getRuntimeContext() {
return this.delegate.getRuntimeContext();
}
@Override
public IterationRuntimeContext getIterationRuntimeContext() {
return this.delegate.getIterationRuntimeContext();
}
@Override
public void open(Configuration parameters) throws Exception {
this.delegate.open(parameters);
}
@Override
public void reset() {
super.reset();
this.records.clear();
}
@Override
public void collect(RowData record) {
this.records.add(record);
delegate.collect(record);
}
}
}
版权归原作者 shirukai 所有, 如有侵权,请联系我们删除。