
传奇开心果博文系列
- 系列博文目录
- Python的自动化办公库技术点案例示例系列
- 博文目录
- 前言- 一、主要特点和功能介绍- 二、Series 示例代码- 三、DataFrame示例代码- 四、数据导入/导出示例代码- 五、数据清洗示例代码- 六、数据选择和过滤示例代码- 七、数据合并和连接示例代码- 八、数据分组和聚合示例代码- 九、数据转换示例代码- 十、时间序列数据处理示例代码- 十一、高效处理大型数据集示例代码- 十二、支持向量化操作示例代码- 十三、数据分析和可视化示例代码- 十四、社区支持举例说明- 十五、归纳总结
系列博文目录
Python的自动化办公库技术点案例示例系列
博文目录
前言

 Pandas是一个流行的Python数据处理库,提供了易于使用的数据结构和数据分析工具,使得在Python中进行数据清洗、数据分析和数据处理变得更加简单和高效。
Pandas是一个流行的Python数据处理库,提供了易于使用的数据结构和数据分析工具,使得在Python中进行数据清洗、数据分析和数据处理变得更加简单和高效。
一、主要特点和功能介绍

 以下是Pandas的一些主要特点和功能:
以下是Pandas的一些主要特点和功能:
- 数据结构: -Series:类似于一维数组,可以存储不同类型的数据,并带有标签(索引)。 -DataFrame:类似于二维表格,由多个Series组成,每列可以是不同的数据类型。
- 数据操作: -数据导入/导出:Pandas支持从各种数据源中导入数据,如CSV文件、Excel表格、数据库等,并可以将处理后的数据导出。 -数据清洗:处理缺失数据、重复数据、异常值等。 -数据选择和过滤:通过标签或位置选择数据,进行数据筛选和过滤。 -数据合并和连接:合并多个数据集,支持不同类型的连接操作。 -数据分组和聚合:按照指定的条件对数据进行分组,并进行聚合操作,如求和、平均值等。 -数据转换:对数据进行排序、重塑、透视等操作。 -时间序列数据处理:提供了强大的时间序列数据处理功能。
- 性能优势: -Pandas基于NumPy构建,能够高效处理大型数据集。 -支持向量化操作,避免了使用显式循环,提高了数据处理的效率。
- 灵活性: -可以与其他Python库(如NumPy、Matplotlib等)结合使用,实现更复杂的数据分析和可视化任务。
- 社区支持: -Pandas拥有庞大的社区支持和活跃的开发者社区,提供了丰富的文档、教程和示例,便于学习和使用。
总的来说,Pandas是一个功能强大且灵活的数据处理工具,适用于各种数据分析和数据处理任务。如果你需要进行数据清洗、数据分析或数据处理,Pandas通常是一个很好的选择。
二、Series 示例代码

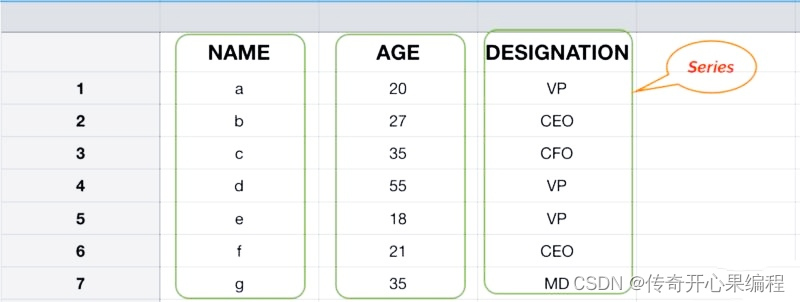 当创建一个Pandas Series 对象时,你可以传入一个包含数据的列表或数组,并可以选择性地指定索引。以下是一个简单的示例代码,演示如何创建一个包含不同类型数据并具有标签索引的 Pandas Series:
当创建一个Pandas Series 对象时,你可以传入一个包含数据的列表或数组,并可以选择性地指定索引。以下是一个简单的示例代码,演示如何创建一个包含不同类型数据并具有标签索引的 Pandas Series:
import pandas as pd
# 创建一个包含不同类型数据的 Pandas Series
data =[10,'Hello',3.5,True]
index =['A','B','C','D']# 使用数据列表和索引列表创建 Series 对象
series = pd.Series(data, index=index)# 打印 Series 对象print(series)
在这个示例中,我们创建了一个包含整数、字符串、浮点数和布尔值的 Pandas Series,每个值都有一个对应的标签索引。运行这段代码后,你将看到类似以下输出:
A 10
B Hello
C 3.5
D True
dtype: object
这个 Series 包含了不同类型的数据,并且每个数据都与一个索引标签相关联。这使得在 Pandas 中处理数据时更加灵活和方便。
三、DataFrame示例代码
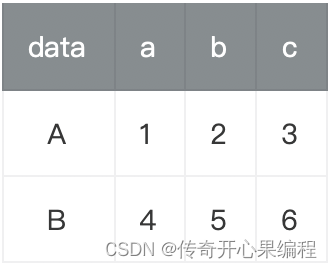 当创建一个 Pandas DataFrame 时,你可以传入一个字典,其中键是列名,值是列数据(可以是列表、数组或 Series)。以下是一个简单的示例代码,演示如何创建一个包含不同数据类型的 Pandas DataFrame,每列可以是不同的数据类型:
当创建一个 Pandas DataFrame 时,你可以传入一个字典,其中键是列名,值是列数据(可以是列表、数组或 Series)。以下是一个简单的示例代码,演示如何创建一个包含不同数据类型的 Pandas DataFrame,每列可以是不同的数据类型:
import pandas as pd
# 创建一个包含不同数据类型的 Pandas DataFrame
data ={'A':[1,2,3,4],'B':['apple','banana','cherry','date'],'C':[2.5,3.7,1.2,4.9],'D':[True,False,True,False]}# 使用字典创建 DataFrame 对象
df = pd.DataFrame(data)# 打印 DataFrame 对象print(df)
在这个示例中,我们创建了一个包含整数、字符串、浮点数和布尔值的 Pandas DataFrame。每列的数据类型可以是不同的,这是 Pandas DataFrame 的一个重要特性。运行这段代码后,你将看到类似以下输出:
A B C D
0 1 apple 2.5 True
1 2 banana 3.7 False
2 3 cherry 1.2 True
3 4 date 4.9 False
这个 DataFrame 包含了四列数据,每列可以是不同的数据类型,类似于一个二维表格。Pandas DataFrame 提供了强大的数据操作功能,使得数据分析和处理变得更加简单和高效。
四、数据导入/导出示例代码

 Pandas 提供了丰富的功能来导入和导出数据,包括从 CSV 文件、Excel 表格、数据库等数据源中导入数据,并将处理后的数据导出到各种格式。以下是一些示例代码,演示如何使用 Pandas 进行数据导入和导出:
Pandas 提供了丰富的功能来导入和导出数据,包括从 CSV 文件、Excel 表格、数据库等数据源中导入数据,并将处理后的数据导出到各种格式。以下是一些示例代码,演示如何使用 Pandas 进行数据导入和导出:
- 从 CSV 文件导入数据并将处理后的数据导出到 CSV 文件:
import pandas as pd
# 从 CSV 文件导入数据
df = pd.read_csv('data.csv')# 处理数据...# 将处理后的数据导出到 CSV 文件
df.to_csv('processed_data.csv', index=False)
- 从 Excel 表格导入数据并将处理后的数据导出到 Excel 文件:
import pandas as pd
# 从 Excel 表格导入数据
df = pd.read_excel('data.xlsx')# 处理数据...# 将处理后的数据导出到 Excel 文件
df.to_excel('processed_data.xlsx', index=False)
- 从数据库导入数据并将处理后的数据导出到数据库表:
import pandas as pd
import sqlite3
# 连接到 SQLite 数据库
conn = sqlite3.connect('database.db')# 从数据库表导入数据
query ="SELECT * FROM table"
df = pd.read_sql_query(query, conn)# 处理数据...# 将处理后的数据导出到数据库表
df.to_sql('processed_table', conn, index=False, if_exists='replace')
通过这些示例代码,你可以了解如何使用 Pandas 从不同数据源中导入数据,并在处理后将数据导出到所需的格式中。Pandas 提供了简单而强大的方法来处理各种数据导入和导出任务,使得数据分析工作更加高效和便捷。
五、数据清洗示例代码

 在数据分析中,数据清洗是一个非常重要的步骤,它包括处理缺失数据、重复数据、异常值等问题。Pandas 提供了丰富的功能来进行数据清洗。以下是一些示例代码,演示如何使用 Pandas 进行数据清洗:
在数据分析中,数据清洗是一个非常重要的步骤,它包括处理缺失数据、重复数据、异常值等问题。Pandas 提供了丰富的功能来进行数据清洗。以下是一些示例代码,演示如何使用 Pandas 进行数据清洗:
- 处理缺失数据:
import pandas as pd
# 创建包含缺失数据的示例 DataFrame
data ={'A':[1,2,None,4],'B':['apple','banana','cherry',None],'C':[2.5,None,1.2,4.9]}
df = pd.DataFrame(data)# 检查缺失数据print(df.isnull())# 填充缺失数据
df.fillna(0, inplace=True)
- 处理重复数据:
import pandas as pd
# 创建包含重复数据的示例 DataFrame
data ={'A':[1,2,2,4],'B':['apple','banana','banana','date']}
df = pd.DataFrame(data)# 检查重复数据print(df.duplicated())# 删除重复数据
df.drop_duplicates(inplace=True)
- 处理异常值:
import pandas as pd
# 创建包含异常值的示例 DataFrame
data ={'A':[1,2,3,100],'B':['apple','banana','cherry','date']}
df = pd.DataFrame(data)# 检查异常值print(df[df['A']>10])# 替换异常值
df.loc[df['A']>10,'A']=10
通过这些示例代码,你可以了解如何使用 Pandas 处理缺失数据、重复数据和异常值。数据清洗是数据分析过程中的关键步骤,有效的数据清洗可以提高数据分析的准确性和可靠性。
六、数据选择和过滤示例代码
 在 Pandas 中,你可以通过标签或位置选择数据,进行数据筛选和过滤。以下是一些示例代码,演示如何使用 Pandas 进行数据选择和过滤:
在 Pandas 中,你可以通过标签或位置选择数据,进行数据筛选和过滤。以下是一些示例代码,演示如何使用 Pandas 进行数据选择和过滤:
- 通过标签选择数据:
import pandas as pd
# 创建示例 DataFrame
data ={'A':[1,2,3,4,5],'B':['apple','banana','cherry','date','elderberry']}
df = pd.DataFrame(data, index=['X','Y','Z','W','V'])# 通过标签选择单列数据
column_data = df['A']# 通过标签选择多列数据
multiple_columns_data = df[['A','B']]# 通过标签选择单行数据
row_data = df.loc['Z']# 通过标签选择多行数据
multiple_rows_data = df.loc[['X','Y']]
- 通过位置选择数据:
import pandas as pd
# 创建示例 DataFrame
data ={'A':[1,2,3,4,5],'B':['apple','banana','cherry','date','elderberry']}
df = pd.DataFrame(data)# 通过位置选择单列数据
column_data = df.iloc[:,0]# 通过位置选择多列数据
multiple_columns_data = df.iloc[:,[0,1]]# 通过位置选择单行数据
row_data = df.iloc[2]# 通过位置选择多行数据
multiple_rows_data = df.iloc[[0,1]]
通过这些示例代码,你可以了解如何使用 Pandas 通过标签或位置选择数据,进行数据筛选和过滤。Pandas 提供了灵活的方法来选择和操作数据,使得数据分析工作更加高效和便捷。
七、数据合并和连接示例代码
 在 Pandas 中,你可以使用不同类型的连接操作来合并多个数据集。以下是一些示例代码,演示如何使用 Pandas 进行数据合并和连接:
在 Pandas 中,你可以使用不同类型的连接操作来合并多个数据集。以下是一些示例代码,演示如何使用 Pandas 进行数据合并和连接:
- 使用
pd.concat()进行数据合并:
import pandas as pd
# 创建示例 DataFrame
data1 ={'A':[1,2,3],'B':['apple','banana','cherry']}
data2 ={'A':[4,5,6],'B':['date','elderberry','fig']}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)# 沿行方向合并两个 DataFrame
result = pd.concat([df1, df2])
- 使用
pd.merge()进行数据连接:
import pandas as pd
# 创建示例 DataFrame
data1 ={'key':['K0','K1','K2'],'A':[1,2,3]}
data2 ={'key':['K0','K1','K3'],'B':['apple','banana','cherry']}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)# 内连接
result_inner = pd.merge(df1, df2, on='key', how='inner')# 左连接
result_left = pd.merge(df1, df2, on='key', how='left')# 右连接
result_right = pd.merge(df1, df2, on='key', how='right')# 外连接
result_outer = pd.merge(df1, df2, on='key', how='outer')
通过这些示例代码,你可以了解如何使用 Pandas 进行数据合并和连接。Pandas 提供了丰富的功能来支持不同类型的连接操作,使得合并多个数据集变得简单和灵活。
八、数据分组和聚合示例代码

 在 Pandas 中,你可以使用数据分组和聚合功能来按照指定的条件对数据进行分组,并进行聚合操作,如求和、平均值等。以下是一些示例代码,演示如何使用 Pandas 进行数据分组和聚合:
在 Pandas 中,你可以使用数据分组和聚合功能来按照指定的条件对数据进行分组,并进行聚合操作,如求和、平均值等。以下是一些示例代码,演示如何使用 Pandas 进行数据分组和聚合:
import pandas as pd
# 创建示例 DataFrame
data ={'Category':['A','B','A','B','A','B'],'Value':[10,20,30,40,50,60]}
df = pd.DataFrame(data)# 按照 'Category' 列进行分组,并计算每组的平均值
grouped = df.groupby('Category').mean()# 按照多列进行分组,并计算每组的总和
grouped_multiple = df.groupby(['Category']).sum()# 对多列进行分组,并同时计算多个聚合函数
grouped_multiple_functions = df.groupby('Category').agg({'Value':['sum','mean']})# 对每个分组应用自定义的聚合函数defcustom_aggregation(x):return x.max()- x.min()
custom_aggregated = df.groupby('Category').agg({'Value': custom_aggregation})# 对每个分组应用多个自定义的聚合函数
custom_aggregated_multiple = df.groupby('Category').agg({'Value':[custom_aggregation,'mean']})
通过这些示例代码,你可以了解如何使用 Pandas 进行数据分组和聚合操作。Pandas 提供了强大的功能来轻松地对数据进行分组和应用各种聚合函数,帮助你更好地理解数据并进行数据分析。
九、数据转换示例代码
 在 Pandas 中,你可以对数据进行各种转换操作,包括排序、重塑、透视等。以下是一些示例代码,演示如何使用 Pandas 进行数据转换:
在 Pandas 中,你可以对数据进行各种转换操作,包括排序、重塑、透视等。以下是一些示例代码,演示如何使用 Pandas 进行数据转换:
- 数据排序:
import pandas as pd
# 创建示例 DataFrame
data ={'A':[3,2,1,4],'B':['apple','banana','cherry','date']}
df = pd.DataFrame(data)# 按照 'A' 列进行升序排序
sorted_df = df.sort_values(by='A')
- 数据重塑(Pivot):
import pandas as pd
# 创建示例 DataFrame
data ={'A':['foo','foo','foo','bar','bar','bar'],'B':['one','one','two','two','one','one'],'C':[1,2,3,4,5,6]}
df = pd.DataFrame(data)# Pivot 操作
pivot_df = df.pivot(index='A', columns='B', values='C')
- 数据透视:
import pandas as pd
# 创建示例 DataFrame
data ={'A':['foo','foo','foo','bar','bar','bar'],'B':['one','one','two','two','one','one'],'C':[1,2,3,4,5,6]}
df = pd.DataFrame(data)# 数据透视表
pivot_table = df.pivot_table(index='A', columns='B', values='C', aggfunc='sum')
通过这些示例代码,你可以了解如何使用 Pandas 进行数据转换操作,包括排序、重塑和透视等。Pandas 提供了丰富的功能来帮助你对数据进行灵活的转换和分析。
十、时间序列数据处理示例代码
 Pandas 提供了强大的时间序列数据处理功能,可以帮助你轻松处理时间序列数据。以下是一些示例代码,演示如何使用 Pandas 处理时间序列数据:
Pandas 提供了强大的时间序列数据处理功能,可以帮助你轻松处理时间序列数据。以下是一些示例代码,演示如何使用 Pandas 处理时间序列数据:
- 创建时间序列数据:
import pandas as pd
import numpy as np
# 创建一个时间范围为一周的时间序列数据
dates = pd.date_range('2024-02-26', periods=7)# 创建一个 DataFrame,使用时间序列作为索引
df = pd.DataFrame(np.random.randn(7,3), index=dates, columns=['A','B','C'])
- 时间序列重采样:
# 将时间序列数据按照每月重新采样,并计算每月的平均值
monthly_resampled = df.resample('M').mean()
- 移动窗口统计:
# 计算时间序列数据的滚动平均值
rolling_mean = df['A'].rolling(window=3).mean()
- 时间序列数据的时区转换:
# 创建一个带有时区信息的时间戳
ts = pd.Timestamp('2024-02-26 08:00', tz='Europe/London')# 将时区转换为美国纽约时区
ts_ny = ts.tz_convert('America/New_York')
通过这些示例代码,你可以了解如何使用 Pandas 处理时间序列数据,包括创建时间序列数据、重采样、移动窗口统计以及时区转换等操作。Pandas 提供了丰富的功能来支持时间序列数据的处理和分析,让你能够更轻松地处理时间相关的数据。
十一、高效处理大型数据集示例代码

 Pandas 基于 NumPy 构建,能够高效处理大型数据集。以下是一些示例代码,演示如何使用 Pandas 处理大型数据集:
Pandas 基于 NumPy 构建,能够高效处理大型数据集。以下是一些示例代码,演示如何使用 Pandas 处理大型数据集:
- 创建一个大型数据集:
import pandas as pd
import numpy as np
# 创建一个包含100万行和3列的随机数据集
n =1000000
data ={'A': np.random.rand(n),'B': np.random.rand(n),'C': np.random.rand(n)}
df = pd.DataFrame(data)
- 对大型数据集进行聚合操作:
# 计算每列的平均值
mean_values = df.mean()
- 对大型数据集进行筛选操作:
# 筛选出满足条件的行
filtered_data = df[df['A']>0.5]
- 对大型数据集进行分组和汇总操作:
# 按照 'B' 列进行分组,并计算每组的平均值
grouped_data = df.groupby('B').mean()
通过这些示例代码,你可以看到 Pandas 在处理大型数据集时的高效性。Pandas 提供了优化的数据结构和操作,使得处理大型数据集变得更加简单和高效。无论是数据聚合、筛选、分组还是其他操作,Pandas 都能够快速地处理大规模的数据,为数据分析和处理提供了强大的工具支持。
十二、支持向量化操作示例代码

 Pandas 支持向量化操作,这意味着你可以避免使用显式循环,而是直接对整个数据集执行操作,从而提高数据处理的效率。以下是一些示例代码,演示如何使用 Pandas 进行向量化操作:
Pandas 支持向量化操作,这意味着你可以避免使用显式循环,而是直接对整个数据集执行操作,从而提高数据处理的效率。以下是一些示例代码,演示如何使用 Pandas 进行向量化操作:
- 向量化算术操作:
import pandas as pd
import numpy as np
# 创建一个包含随机数据的 DataFrame
df = pd.DataFrame(np.random.randint(0,10, size=(5,3)), columns=['A','B','C'])# 对整个 DataFrame 执行向量化算术操作
result = df['A']+ df['B']* df['C']
- 向量化函数应用:
# 使用 apply 函数对整列数据应用自定义函数
df['D']= df['A'].apply(lambda x: x**2)
- 向量化条件操作:
# 根据条件对 DataFrame 进行填充
df['E']= np.where(df['C']>5,'High','Low')
通过这些示例代码,你可以看到 Pandas 如何支持向量化操作,从而避免显式循环,提高数据处理的效率。向量化操作利用了底层的 NumPy 数组实现,能够高效地处理大型数据集,使得数据处理变得更加简洁和快速。在实际数据处理过程中,推荐尽可能使用向量化操作,以提高代码的执行效率。
十三、数据分析和可视化示例代码
 当与其他 Python 库(如 NumPy、Matplotlib 等)结合使用时,Pandas 可以实现更复杂的数据分析和可视化任务。以下是一些示例代码,展示了 Pandas 与 NumPy 和 Matplotlib 结合使用的情况:
当与其他 Python 库(如 NumPy、Matplotlib 等)结合使用时,Pandas 可以实现更复杂的数据分析和可视化任务。以下是一些示例代码,展示了 Pandas 与 NumPy 和 Matplotlib 结合使用的情况:
- 结合 NumPy 进行数据处理:
import pandas as pd
import numpy as np
# 创建一个包含随机数据的 DataFrame
df = pd.DataFrame(np.random.randint(0,10, size=(5,3)), columns=['A','B','C'])# 使用 NumPy 函数对 DataFrame 进行操作
df['D']= np.sqrt(df['A']**2+ df['B']**2)
- 结合 Matplotlib 进行数据可视化:
import matplotlib.pyplot as plt
# 创建一个包含随机数据的 DataFrame
df = pd.DataFrame(np.random.rand(50,2), columns=['X','Y'])# 绘制散点图
plt.scatter(df['X'], df['Y'])
plt.xlabel('X')
plt.ylabel('Y')
plt.title('Scatter Plot')
plt.show()
- 结合 NumPy 和 Matplotlib 进行数据分析和可视化:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 创建一个包含随机数据的 DataFrame
df = pd.DataFrame(np.random.randn(100,2), columns=['A','B'])# 计算移动平均值
df['MA']= df['A'].rolling(window=10).mean()# 绘制折线图
plt.plot(df['A'], label='A')
plt.plot(df['MA'], label='Moving Average')
plt.legend()
plt.xlabel('Index')
plt.ylabel('Value')
plt.title('Moving Average Plot')
plt.show()
通过这些示例代码,你可以看到 Pandas 如何与 NumPy 和 Matplotlib 结合使用,实现更复杂的数据处理和可视化任务。这种结合可以让你充分利用各个库的优势,完成更多样化和复杂度更高的数据分析工作。无论是数据处理、分析还是可视化,这种结合都能为你提供强大的工具支持。
十四、社区支持举例说明
 Pandas拥有庞大的社区支持和活跃的开发者社区,提供了丰富的文档、教程和示例,让用户更容易学习和使用。以下是一些示例代码,展示了如何利用Pandas的文档、教程和示例资源:
Pandas拥有庞大的社区支持和活跃的开发者社区,提供了丰富的文档、教程和示例,让用户更容易学习和使用。以下是一些示例代码,展示了如何利用Pandas的文档、教程和示例资源:
- 查看Pandas官方文档:
import webbrowser
# 打开Pandas官方文档网站
webbrowser.open('https://pandas.pydata.org/docs/')
- 查看Pandas官方教程:
import webbrowser
# 打开Pandas官方教程网站
webbrowser.open('https://pandas.pydata.org/docs/getting_started/index.html')
- 查看Pandas官方示例库:
import webbrowser
# 打开Pandas官方示例库网站
webbrowser.open('https://pandas.pydata.org/docs/getting_started/index.html#tutorials')
通过这些示例代码,你可以方便地访问Pandas的官方文档、教程和示例资源,这些资源对于学习和使用Pandas都非常有帮助。官方文档提供了详细的API参考和用例说明,官方教程则提供了入门指导和实用技巧,而官方示例库则包含了丰富的示例代码,帮助你更好地理解和应用Pandas库。利用这些资源,你可以更高效地学习和使用Pandas,从而更好地处理和分析数据。
十五、归纳总结
 Pandas 是一个强大的数据处理库,主要用于数据清洗、数据转换和数据分析。以下是一些关键的 Pandas 知识点的归纳总结:
Pandas 是一个强大的数据处理库,主要用于数据清洗、数据转换和数据分析。以下是一些关键的 Pandas 知识点的归纳总结:
- 数据结构: -Series:一维数据结构,类似于数组或列表。 -DataFrame:二维数据结构,类似于表格,由多个 Series 组成。
- 数据导入与导出: -从 CSV、Excel、SQL 数据库等不同数据源导入数据。 -将处理后的数据导出为 CSV、Excel 等格式。
- 数据查看与处理: -查看数据:head()、tail()、info()、describe() 等方法。 -选择数据:使用 loc、iloc、[] 运算符。 -缺失值处理:dropna()、fillna()。 -重复值处理:drop_duplicates()。
- 数据筛选与排序: -条件筛选:使用布尔索引、query() 方法。 -排序:sort_values()、sort_index()。
- 数据分组与聚合: -groupby():按照指定条件对数据进行分组。 -聚合函数:sum()、mean()、count() 等。 -多重索引:实现多层次的分组和聚合。
- 数据合并与连接: -concat():沿着指定轴合并多个 DataFrame。 -merge():根据一个或多个键将不同 DataFrame 连接起来。
- 数据透视表与重塑: -pivot_table():创建数据透视表。 -stack()、unstack():数据重塑操作。
- 时间序列数据处理: -时间索引:将时间列设置为索引。 -日期范围:生成日期范围序列。 -时序数据分析:时间重采样、移动窗口统计等操作。
- 大数据集处理: -分块处理:使用 chunksize 处理大型数据集。 -内存优化:选择合适的数据类型、减少内存占用。
- 数据可视化: -与 Matplotlib、Seaborn 等库结合进行数据可视化。 -绘制折线图、柱状图、散点图等图表。

以上是 Pandas 中一些常用的知识点,掌握这些知识可以帮助你更好地处理和分析数据。通过实践和不断学习,你可以更深入地了解 Pandas,并利用其强大功能解决实际数据处理问题。
版权归原作者 传奇开心果编程 所有, 如有侵权,请联系我们删除。