
认识线程
一、概念
什么是线程
一个线程就是一个 “执行流”. 每个线程之间都可以按照顺讯执行自己的代码. 多个线程之间 “同时” 执行着多份代码.
为什么要有进程?
因为我们的系统支持多任务,这个就需要程序员来“并发编程”。(这里的并发编程是 并行 + 并发)。
为什么要有线程
多进程出现的问题
通过多进程,是完全可以实现并发编程的,但是有一点问题。
如果我们频繁的创建/销毁进程,这个事情的成本是比较高的。如果我们需要频繁的调度进程,这个事情成本也是比较高的。
创建进程就得分配资源:内存资源和文件资源。
销毁进程就得释放资源:内存资源和文件资源。
对于资源申请和释放,本身就是一个比较低效的操作。
如何解决这个问题
思路有两个:
- 进程池(比如数据库连接池,字符串常量池)。 进程池虽然能解决上述频繁创建和销毁的问题,但是进程池太消耗系统的资源了,因为在进程池里面有很多闲置的进程。
- 使用线程来实现并发编程。 线程比进程更轻量,每一个进程可以执行一个任务,每一个线程也能执行一个任务,他们都能实现并发编程。 创建线程的成本比创建进程要低很多。 销毁线程的成本比创建进程要低很多。 调度线程的成本比创建进程要低很多。 在Linux系统中,把 线程 称为 轻量级进程 (LWP)。
为什么线程比进程更轻量
进程的重量是重在资源的申请和释放上面。
线程是包含在进程中的,一个进程可以有多个线程,这多个线程公用同一份资源(同一份内存 + 文件),只是在创建进程的第一个线程的时候需要分配资源,之后进入这个进程的线程不需要再申请资源,这个时候创建线程的成本就会变低。
这个就会有一个疑问,多加一些线程,是不是效率就会进一步提升呢?
一般来说是会的,但是也不一定。
如果线程多了,这些线程就会要竞争同一个资源,这个时候,整体的速度就会收到限制(整体的硬件资源是有效的)。
线程和进程的区别和联系
- 进程包含线程。一个进程可以有一个或者多个线程,多个线程公用同一份资源。
- 进程和线程都是为了处理并发编程这样的场景。 但是创建进程和销毁进程的效率低,而线程就比较的轻量,线程少了创建进程和销毁进程这个过程。
- 操作系统创建进程,要给进程分配资源,进程是操作系统分配资源的最小单位。 操作系统创建线程,是在CPU中执行调度,线程是CPU执行调度的基本单位。
- 进程具有独立性,每一个进程都有各自独立的地址空间。一个进程挂了,不会影响其他的进程。 但是在同一个进程中的多个线程,公用同一个内存空间。一个线程挂了,可能影响到其他的线程,甚至导致整个进程崩溃。
二、创建线程
Java中进行多线程编程,在Java标准库中,就提供了一个Thread类,用来操作线程。Thread类也可以视为是Java标准库提供的API。
创建好的Thread实例,其实和操作系统中的线程一一对应的关系。
操作系统提供了一组关于线程的API(C语言实现的),Java对这一组API进一步封装,就成为了Thread类。
方法一 继承 Thread 类
创建子类,继承Thread类,并重写run方法。
classMyThreadextendsThread{//创建一个MyThread子类继承Thread类。@Override//其中run方法中的内容描述了线程内部要执行的代码publicvoidrun(){//要注意的是,并不是写出这个代码,线程就创建出来了。这个是把要执行的代码准备好。System.out.println("hello thread!");}}publicclassTestDome1{publicstaticvoidmain(String[] args){Thread thread1 =newMyThread();//创建MyThread子类的对象。
thread1.start();//当调用这里的start方法,才是真正的在系统中创建了线程。//在这里才是真正的执行上面我们写的run方法中的代码。在调用start之前,系统没有创建出线程的。}}
方法二 实现 Runnable 接口
通过Runnable来描述任务的内容,进一步的再把描述好的任务交给Thread实例
classMyRunnableimplementsRunnable{//继承接口@Overridepublicvoidrun(){//实现接口中的方法System.out.println("Hello Runnable");}}publicclassTestDome2{publicstaticvoidmain(String[] args){// 创建 Thread 类实例, 调用 Thread 的构造方法时将 Runnable 对象作为 target 参数。Thread thread1 =newThread(newMyRunnable());
thread1.start();//创建线程,执行代吗}}
方法三 匿名内部类创建 Thread 子类对象
publicclassTestDome3{publicstaticvoidmain(String[] args){Thread thread =newThread(){//创建出这个匿名内部类的实例@Override//创建了一个匿名内部类,继承自Thread类,重写了run方法,publicvoidrun(){System.out.println("Hello Thread!!");}};
thread.start();//开始执行线程}}
方法四 匿名内部类创建 Runnable 子类对象
publicclassTestDome4{publicstaticvoidmain(String[] args){//new Runnable,是针对这个创建的内部类,同时Runnable实例传给Thread的构造方法Thread thread =newThread(newRunnable(){@Overridepublicvoidrun(){//要执行的代码System.out.println("hello thread");}});
thread.start();//创建线程,执行代码。}}
通常认为 匿名内部类创建 Runnable 子类对象 这中方法更好一点,能够做到让线程和线程执行的任务更好的解耦。(写代码一般希望,高内聚,低耦合)
Runnable单纯的只是描述了一个任务,至于这个任务是要通过一个进程来执行,还是线程来执行,还是协程来执行,Runnable本身不关心。
方法五 使用lambda 表达式
publicclassTestDome6{publicstaticvoidmain(String[] args){Thread thread1 =newThread(()->{//使用lambda表达式来代替了Runnable。System.out.println("hello thread1");});
thread1.start();}}
上面的五种写法都很常见,希望大家都能够熟悉
三、线程之间并发执行
publicclassTestDome5{publicstaticvoidmain(String[] args){Thread thread1 =newThread(newRunnable(){//使用匿名内部类创建 Runnable 子类对象@Overridepublicvoidrun(){while(true){//如果一个循环中不加任何限制,这个循环转的速度是非常快的,我们一般看不过来//我们就可以再循环中加一个sleep操作,来强制让这个线程休眠一段时间。System.out.println("hello thread");try{//这个是让线程强行进入堵塞状态,单位是msThread.sleep(1000);//1000ms表示1s中之内这个线程不会到CPU中执行。}catch(InterruptedException e){
e.printStackTrace();//抛出异常,线程被强制中断的异常。}}}});
thread1.start();//在进程中至少有一个线程,在一个Java进程中,会有一个调用main方法的线程//这个线程不是人为调动的,是系统自带的。while(true){System.out.println("hello main");try{Thread.sleep(1000);//休眠一秒,线程堵塞一秒}catch(InterruptedException e){
e.printStackTrace();}}}}
上面这个程序是:自己创建T线程和自动创建的main线程并发执行(在宏观上看起来同时执行)。

两个线程,都是打印一条就休眠1s,由代码运行结果图可知,当1s时间到了之后,系统先唤醒谁是不确定的(随机的)。
对于操作系统来说,内部对于线程之间的调度顺序,在宏观上可以认为是随机的(线程之间是抢占式执行),这个随机性会给多线程编程带来很多的麻烦。
四、多线程的优势-增加运行速度
可以观察多线程在一些场合下是可以提高程序的整体运行效率的。
publicclassTestDome7{//在写一个比较长的整数常量的时候就可以通过_来进行分隔privatestaticfinallong COUNT =10_0000_0000;//定义一个常量COUNT=10_0000_0000publicstaticvoidmain(String[] args)throwsInterruptedException{//使用串行serial();//使用并行concurrency();}//实现两个数自增10亿次privatestaticvoidserial(){//System.currentTimeMillis() Java自带的记录当前系统的时间戳。long begin =System.currentTimeMillis();long a =0;for(long i=0; i<COUNT; i++){//循环10亿次
a++;}long b =0;for(long i=0; i<COUNT; i++){//循环10亿次
b++;}long end =System.currentTimeMillis();//记录系统时间System.out.println("串行: "+(end - begin)+"ms");}//使用线程来实现两个数自增10亿次privatestaticvoidconcurrency()throwsInterruptedException{long begin =System.currentTimeMillis();//记录系统时间Thread thread1 =newThread(()->{//第一个线程long a =0;for(long i=0; i<COUNT; i++){
a++;}});
thread1.start();//使用start函数,才创建了线程Thread thread2 =newThread(()->{//第二个线程long b =0;for(long i=0; i<COUNT; i++){
b++;}});
thread2.start();//在这里不能直接使用记录系统结束的时间。不要忘记了本身就有一个系统自带的mian线程//因为在这里是thread1,thread2,mian线程三个线程同时抢占式执行。//正确的应该是让main线程等待thread1和thread2线程结束,在记录结束时间//要使用join这个函数,这个函数就是要main函数等待线程结束。
thread1.join();
thread2.join();long end =System.currentTimeMillis();//记录系统结束时间System.out.println("并行:"+(end - begin)+"ms");}}
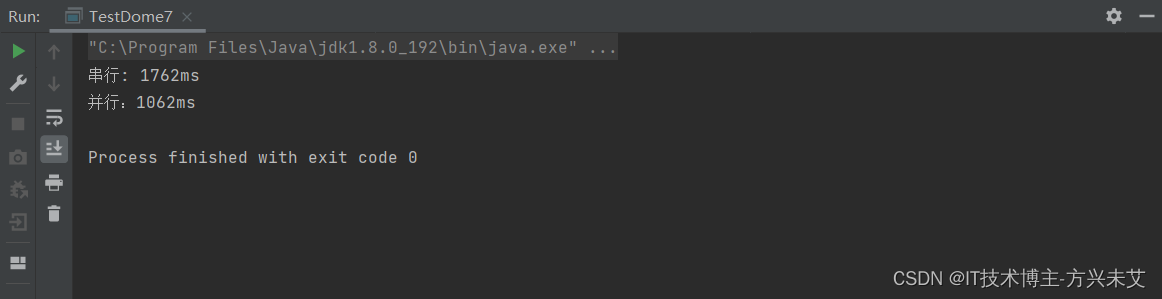
从上面的代码运行结果图可以看出来。串行执行的时候,时间大概是1700多ms。两个线程并发执行,时间大概是1000多ms,提升了接近50%。
但是并不是说,一个线程2000多ms,两个线程就是1000多ms。
这个要根据底层到底是并行执行,还是并发执行,只有在并行执行的时候,效率才会显著提高,但是我们并不确定到底是并发,还是并行,而且还有创建线程的开销。所以并不会完完全全的提升了一半。
版权归原作者 IT技术博主-方兴未艾 所有, 如有侵权,请联系我们删除。