
导语
在上一篇博客中,我描述了该如何参加自己的第一个竞赛项目《泰坦尼克号》,旨在引领你完成自己的第一次竞赛,并让你了解一些机器学习的入门知识,初步学会该如何处理表格型数据。而这次将领你走进深度学习:图像识别的大门。
赛事描述
这项竞赛使用了MNIST(Modified National Institute of Standards and Technology)美国国家标准与技术研究院收集整理的大型手写数字数据库。你需要从数万张手写测试图像中正确识别数字。
正式开始
一.参加比赛
跟之前操作相同,这是竞赛界面Digit Recognizer | Kaggle
二.数据集概览
在竞赛界面可以找到data界面来查看比赛数据,共有三个数据文件(1) **train.csv**, (2) **test.csv**, (3) **gender_submission.csv。**
你也可以下载这些数据集在本地进行分析。
(1) train.csv
train.csv 和 test.csv 包含从0到9的手绘数字的灰度图像。每张图像的高度为 28 像素,宽度为 28 像素,总共为 784 像素。每个像素都有一个与之关联的像素值,指示该像素的亮度或暗度,数字越大表示越暗。此像素值是介于 0 和 255 之间的整数(包括 0 和 255)。
train.csv 有 785 列。第一列是标签(label),表示用户绘制的数字;其余列是关联图像的像素值。训练集中的每个像素列都有一个类似于 pixelx 的名称,其中 x 是介于 0 和 783 之间的整数(包括 0 和 783)。
(2) test.csv
test.csv文件中的数据表现形式几乎与train.csv文件中一致,但缺少了label列,所以我们需要正确识别手写数字图像。
(3) sample_submission.csv
比赛提供的sample_submission.csv文件是一个示例,显示了应该如何构建预测并提交。它包含了ImageId和Label两列。所以就像这个文件一样,我们的提交应该具有:
"ImageId" 列,表示test.csv中每张图像的id。即第一张图像id为1......
"Label" 列,表示我们预测图像所代表的数字。
三.编写代码
(1)导入包
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import models, transforms
import torch.optim.lr_scheduler as lr_scheduler
from tqdm import tqdm
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
import seaborn as sns
import matplotlib.pyplot as plt
(2)数据集加载和初步分析
1.加载数据
# 加载数据
train_data=pd.read_csv("/kaggle/input/digit-recognizer/train.csv")
test_data=pd.read_csv("/kaggle/input/digit-recognizer/test.csv")
train_data.head()

test_data.head()

2.查看数据简要信息并检查是否有缺失值
train_data.info()

test_data.info()

观察后发现数据集中并没有缺失值,isnull函数用于判断数据中是否有缺失值,describe函数进行统计,从unique可以看出,只存在一个唯一值,且类型为false,所以数据中并不存在缺失值。
train_data.isnull().any().describe()

test_data.isnull().any().describe()

print(f"训练集有{len(train_data)}个样本数据,测试集有{len(test_data)}个样本数据")

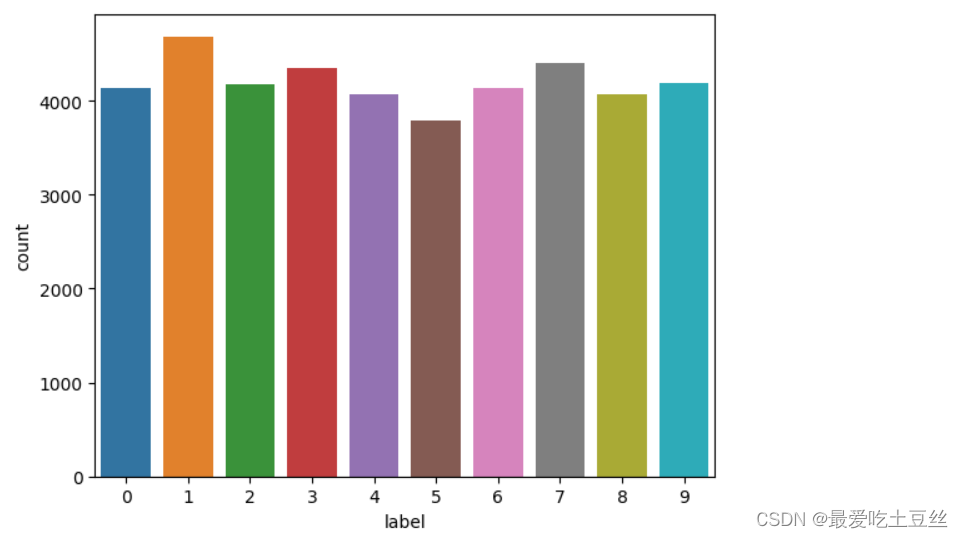
3.训练集数据分布可视化
对训练集中手写数字分布进行可视化,数字从0-9基本均匀分布,因为基本均匀分布,所以在后续划分数据集时并不需要分层抽取,使用train_test_split随机划分。
#统计训练集中数字分布频次
sns.countplot(x=train_data.label)
plt.xlabel("label")
plt.ylabel("count")
plt.show()
(3)数据预处理
1.数据集划分及类型转换
对训练集数据进行处理,再分割以便后续操作,如评价模型等。
train_labels = train_data["label"].values
train_images = train_data.drop(labels=["label"], axis=1)
进行数据的转换,确保能与模型兼容。
train_images = train_images.values.astype(np.float32)
test_images = test_data.values.astype(np.float32)
X_train, X_val, Y_train, Y_val = train_test_split(train_images, train_labels, test_size = 0.2, random_state=41)
将数据从一维向量转换为二维矩阵,28*28对应数据集图像尺寸,满足模型输入要求。
X_train = X_train.reshape(-1, 28, 28)
X_val = X_val.reshape(-1, 28, 28)
test_images = test_images.reshape(-1, 28, 28)
2.自定义Dataset 类
自定义MNISTDataset 的类,继承自 PyTorch 的 Dataset 类。用于将 MNIST 数据集封装成 PyTorch 可用的数据格式,并提供数据加载和预处理功能。
class MNISTDataset(Dataset):
def __init__(self, data, labels=None, transform=None):
self.data = data
self.labels = labels
self.transform = transform
self.indices = np.arange(len(data))#原始数据的索引
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
image = self.data[idx]
if self.transform:
image = self.transform(image)
if self.labels is not None:
label = self.labels[idx]
return image, torch.tensor(label).long(), self.indices[idx] #返回索引
else:
return image
3.数据增强
因为手写数字图像很简单,所以不建议进行过度的数据增强,在测试中,我在增加了弹性形变和高斯模糊后,反复调整参数,模型性能并没有得到提升,反而降低了训练速度,当然,也许是我并没有提升训练轮次的原因,你可以在这一方面,进行测试。
# 定义数据增强操作
transform = transforms.Compose([
transforms.ToPILImage(),#将输入数据转换为PIL图像格式
transforms.RandomRotation(degrees=10), # 旋转角度范围
transforms.RandomAffine(degrees=0, translate=(0.1, 0.1), scale=(0.9, 1.1)), # 平移和缩放
transforms.ToTensor(),#将PIL图像格式转换为pytorch张量
transforms.Normalize(mean=[0.5], std=[0.5]) # 标准化
])
4.加载数据
pytorch框架下处理数据方式,使用Dataset 和 DataLoader加载数据,便于训练模型,数据增强等操作。
# 创建 Dataset 和 DataLoader
train_dataset = MNISTDataset(X_train, Y_train, transform=transform)
val_dataset = MNISTDataset(X_val, Y_val,transform=transform)
test_dataset = MNISTDataset(test_images,transform=transform)
train_loader = DataLoader(train_dataset, batch_size=96, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=96, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=96, shuffle=False)
5.增强前后可视化对比
对数据增强前后图像进行对比(只截取了部分)
# 获取一个批次的训练数据
images, labels, indices = next(iter(train_loader)) # 获取索引
# 选择要显示的图像数量
num_images = 4
# 创建图形和子图
fig, axes = plt.subplots(nrows=num_images, ncols=2, figsize=(8, 4 * num_images))
# 循环遍历图像并显示
for i in range(num_images):
# 原始图像
original_image = X_train[indices[i]] # 使用索引获取原始图像
# 增强后的图像
augmented_image = images[i].permute(1, 2, 0).numpy()
# 显示图像
for j, img in enumerate([original_image, augmented_image]):
axes[i, j].imshow(img, cmap='gray')
axes[i, j].set_title(f"{'Original' if j == 0 else 'Augmented'} (Label: {labels[i]})")
axes[i, j].axis('off')
plt.tight_layout()
plt.show()

(4)模型及评估预测
1.模型选择构建
模型选择:
在该项目中我选择了自己构建cnn模型、加载resnet18和densenet121预训练模型这3种方式对项目进行拟合预测,以30轮训练轮次为基准,kaggle(GPU:P100),因为并无严格参数对照,且每种模型的结构不同,所以并不具有参考意义,在拟合过程中:
- 准确率:cnn:98.7%左右,resnet18:99%左右,densenet121:99.6%左右
- 训练速度:自构建cnn模型>resnet18模型>densenet121模型(主要与模型复杂度有关)
** 综合:**
虽然densenet121模型具有较高的准确率,但这是牺牲大量训练时间来实现的,且模型结构复杂,调整模型结构效率不高。所以在模型初步搭建时,你可以选择自己构建cnn模型进行拟合预测,观察拟合曲线,训练速度的变化,并调整参数或模型结构,之后再进一步使用更加复杂的模型,在这里我选择了resnet模型和densenet模型。在熟悉了常用各种模型的基本结构后,你就可以根据项目选择适合该项目的预训练模型,再进行调整,这样就可以节省大量模型搭建过程中的时间。
DenseNet121模型:
加载 DenseNet121 预训练模型:
修改第一层卷积层以匹配单通道输入,因为MNIST 数据集是单通道灰度图像,因此需要将输入通道数改为 1,其他参数保持不变。因为MNIST 数据集规模小,且图像尺寸不大,所以移除最后一个 Dense Block (transition3)来降低模型的复杂度,减少参数数量,并加快训练速度。
- 移除 Dense Block 后,需要重新计算全连接层的输入特征数 (num_ftrs)
- 创建一个虚拟输入 x,并将其传递给修改后的 model.features 部分,得到输出 x
- num_ftrs 就是输出 x 的第二个维度的大小 (通道数)
- 将 DenseNet121 的原始分类器替换为一个新的分类器,包含两个全连接层,一个 ReLU 激活函数和一个 Dropout 层
- 第一个全连接层的输入特征数为 num_ftrs,输出特征数为 1000
- 第二个全连接层的输入特征数为 1000,输出特征数为 10 (MNIST 数据集的类别数)
- Dropout 层可以帮助降低过拟合的风险
模型架构 :
Input Image --> Conv1 --> MaxPool --> Dense Block 1 --> Transition Layer --> Dense Block 2 --> Transition Layer --> Dense Block 3 --> Transition Layer --> Dense Block 4 --> Global Average Pooling --> FC Layer --> Output
架构解析:
1. 密集连接 (Dense Connectivity):
- DenseNet 的核心思想是密集连接,即每个层都与其所有后续层直接相连。 这与传统的 CNN 不同,传统的 CNN 中,每层只与其下一层相连。
- 密集连接的优势在于:- 缓解梯度消失问题: 由于梯度可以直接从损失函数传递到前面的层,即使网络很深,梯度也不会消失。- 特征重用: 每一层都可以利用之前所有层的特征信息,从而学习更丰富的特征表示。- 减少参数数量: 由于特征重用,DenseNet 可以使用更少的参数来达到相同的性能。
2. Dense Block:
- DenseNet 由多个 Dense Block 组成,每个 Dense Block 包含多个卷积层。
- 在每个 Dense Block 中,每一层的输入是之前所有层的输出的拼接。
- 每个 Dense Block 的输出是所有层的输出的拼接。
- Dense Block 中的卷积层通常使用 1x1 卷积进行降维,减少计算量。
3. Transition Layer:
- Dense Block 之间通过 Transition Layer 连接,用于降维和控制特征图的尺寸。
- Transition Layer 通常包含一个 1x1 卷积和一个平均池化层。
4. DenseNet121 结构:
DenseNet121 包含 121 层,其中包括 4 个 Dense Block,每个 Dense Block 分别包含 6、12、24 和 16 个卷积层。
每个 Dense Block 之间有一个 Transition Layer。
在最后一个 Dense Block 之后,使用全局平均池化层将特征图转换为一个向量。
最后使用一个全连接层进行分类。
注:该模型调整并不完善,只是一个初步思路,根据对模型架构的解析,你可以根据你的想法作出进一步调整,注意判断模型是否过拟合。
# 加载 DenseNet121 模型 (预训练)
model = models.densenet121(pretrained=True)
# 修改第一层卷积层以匹配单通道输入
model.features.conv0 = nn.Conv2d(1, 64, kernel_size=5, stride=1, padding='same', bias=False)
# 移除最后一个 Dense Block (transition3)
model.features = nn.Sequential(*list(model.features.children())[:-4])
# 重新获取 num_ftrs
x = torch.randn(1, 1, 28, 28) # 创建一个虚拟输入
x = model.features(x)
num_ftrs = x.size(1)
# 修改最后一层分类器
model.classifier = nn.Sequential(
nn.Linear(num_ftrs, 1000),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(1000, 10)
)
简单cnn模型:
模型包含两个卷积层、两个最大池化层、三个 Dropout 层和两个全连接层。 通过这些层的组合,模型可以学习从输入图像中提取特征,并进行分类。
class CNN(nn.Module):
- 定义一个名为 CNN 的类,继承自 PyTorch 的 nn.Module 类。
- nn.Module 是 PyTorch 中所有神经网络模块的基类,它提供了一些基本的功能,例如参数管理、模型保存和加载等。
def init(self):
- 这是类的构造函数,用于初始化模型的各个层。
- super(CNN, self).init(): 调用父类的构造函数,确保 nn.Module 的初始化工作完成。
模型层定义:
- self.conv1 = nn.Conv2d(1, 32, kernel_size=5, padding='same'):- 创建第一个卷积层 (conv1),使用 32 个 5x5 的卷积核。- in_channels=1:输入通道数为 1,因为 MNIST 数据集是灰度图像。- out_channels=32:输出通道数为 32,表示该层会生成 32 个特征图。- padding='same':使用 'SAME' 填充模式,确保卷积操作后输出特征图的大小与输入相同。
- self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2):- 创建第一个最大池化层 (pool1),使用 2x2 的池化窗口和步长为 2。- 这会将特征图的高度和宽度都减半。
- self.dropout1 = nn.Dropout(p=0.25):- 创建第一个 Dropout 层 (dropout1),以 0.25 的概率随机丢弃神经元,用于防止过拟合。
- self.conv2 = nn.Conv2d(32, 64, kernel_size=5, padding='same'):- 创建第二个卷积层 (conv2),使用 64 个 5x5 的卷积核。- in_channels=32:输入通道数为 32,来自 conv1 的输出。- out_channels=64:输出通道数为 64,表示该层会生成 64 个特征图。
- self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2):- 创建第二个最大池化层 (pool2),使用 2x2 的池化窗口和步长为 2。
- self.dropout2 = nn.Dropout(p=0.25):- 创建第二个 Dropout 层 (dropout2),以 0.25 的概率随机丢弃神经元。
- self.flatten = nn.Flatten():- 创建一个 Flatten 层,将多维的特征图展平成一维向量,以便输入到全连接层。
- self.fc1 = nn.Linear(64 * 7 * 7, 1000):- 创建第一个全连接层 (fc1)。- in_features=64 * 7 * 7:输入特征数为 3136,来自 conv2 输出的 64 个 7x7 特征图展平后的结果。- out_features=1000:输出特征数为 1000。
- self.dropout3 = nn.Dropout(p=0.5):- 创建第三个 Dropout 层 (dropout3),以 0.5 的概率随机丢弃神经元。
- self.fc2 = nn.Linear(1000, 10):- 创建第二个全连接层 (fc2)。- in_features=1000:输入特征数为 1000,来自 fc1 的输出。- out_features=10:输出特征数为 10,对应 MNIST 数据集的 10 个类别。
def forward(self, x):
- 这是模型的前向传播方法,定义了数据在模型中的流动顺序。
- x 是模型的输入,一个形状为 (batch_size, 1, 28, 28) 的张量,表示一个批次的 MNIST 图像。
前向传播过程:
- x = torch.relu(self.conv1(x)):将输入 x 传递给 conv1,然后应用 ReLU 激活函数。
- x = self.pool1(x):将 conv1 的输出传递给 pool1。
- x = self.dropout1(x):将 pool1 的输出传递给 dropout1。
- x = torch.relu(self.conv2(x)):将 dropout1 的输出传递给 conv2,然后应用 ReLU 激活函数。
- x = self.pool2(x):将 conv2 的输出传递给 pool2。
- x = self.dropout2(x):将 pool2 的输出传递给 dropout2。
- x = self.flatten(x):将 dropout2 的输出传递给 flatten,将其展平成一维向量。
- x = torch.relu(self.fc1(x)):将 flatten 的输出传递给 fc1,然后应用 ReLU 激活函数。
- x = self.dropout3(x):将 fc1 的输出传递给 dropout3。
- x = self.fc2(x):将 dropout3 的输出传递给 fc2。
- return x:返回 fc2 的输出,这是一个形状为 (batch_size, 10) 的张量,表示每个样本属于每个类别的概率。
创建模型实例:
- model = CNN(): 创建一个 CNN 类的实例,名为 model。
# 定义CNN 模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=5, padding='same')
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.dropout1 = nn.Dropout(p=0.25)
self.conv2 = nn.Conv2d(32, 64, kernel_size=5, padding='same')
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.dropout2 = nn.Dropout(p=0.25)
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(64 * 7 * 7, 1000) # 7*7 是经过两次池化后的特征图大小
self.dropout3 = nn.Dropout(p=0.5)
self.fc2 = nn.Linear(1000, 10)
def forward(self, x):
x = torch.relu(self.conv1(x))
x = self.pool1(x)
x = self.dropout1(x)
x = torch.relu(self.conv2(x))
x = self.pool2(x)
x = self.dropout2(x)
x = self.flatten(x)
x = torch.relu(self.fc1(x))
x = self.dropout3(x)
x = self.fc2(x)
return x
# 创建模型实例
model = CNN()
注:后面的模型拟合过程使用cnn模型进行,因为我先进行了预训练模型的搭建,再通过cnn模型进行调整,而DenseNet121模型训练时间过长,没有再进行调整。这也算我的一个失误。resnet模型示例代码没有列出的原因是,在初步拟合预测中,发现其预测准确率相较于densenet模型偏低,且训练速度并没有大幅提高,所以将其忽略。但下面我也会列出其架构,你可以根据自己的想法,对模型作出调整预测。
Resnet18模型:
ResNet18 架构及解析:
输入图像 --> 7x7 卷积 (步长 2) --> 最大池化 --> 残差块组 1 (2 个残差块) --> 残差块组 2 (2 个残差块) --> 残差块组 3 (2 个残差块) --> 残差块组 4 (2 个残差块) --> 全局平均池化 --> 全连接层 --> 输出
初始卷积层: 一个 7x7 卷积层,步长为 2,后接一个最大池化层。
残差块组: 4 组残差块,每组包含 2 个残差块。 每个残差块的结构相同,但输入和输出通道数可能不同。
全局平均池化层: 将最后一个残差块的输出进行全局平均池化。
全连接层: 将全局平均池化层的输出映射到最终的类别数。
残差块结构: +-----> 3x3 卷积 --> ReLU --> 3x3 卷积 --> + | |
输入 -----> ----> ReLU --> 输出
| |
+------------------------> 恒等映射 ---------+
- 残差块 (Residual Block): ResNet 的核心是残差块,它包含两个 3x3 卷积层和一个恒等映射 (identity mapping)。 恒等映射是指将输入直接传递到输出,与卷积层的输出相加。 残差连接允许梯度更容易地流向较早的层,从而缓解梯度消失问题。
- 跳跃连接 (Skip Connection): 残差块中的恒等映射被称为跳跃连接,它允许网络学习输入的残差表示,而不是直接学习完整的输入特征。
- 模块化设计: ResNet 由多个重复的残差块组成,可以根据需要堆叠不同数量的残差块,形成不同深度的网络。
** ResNet18 的优点:**
- 解决梯度消失问题: 残差连接可以使梯度更容易地流向较早的层,从而缓解梯度消失问题,使得训练非常深的网络成为可能。
- 提高模型精度: 残差连接可以提高模型的学习能力,从而提高模型的精度。
- 模块化设计: ResNet 的模块化设计使得它可以很容易地扩展到更深的网络,例如 ResNet34、ResNet50、ResNet101 和 ResNet152。
2.优化策略
定义损失函数和优化器:
- nn.CrossEntropyLoss() 是多类别分类任务常用的损失函数
- optim.Adam() 是一个常用的优化算法,用于更新模型的权重
- lr=0.001 是学习率,控制每次参数更新的步长
- weight_decay=1e-5 是 L2 正则化系数,用于降低过拟合的风险
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001,weight_decay=1e-5)
定义学习率调度器:
- lr_scheduler.ReduceLROnPlateau 是一个学习率调度器,当验证集损失不再下降时,自动降低学习率
- 'min' 表示当监控指标 (这里是验证集损失) 停止下降时,降低学习率
- patience=2 表示允许验证集损失连续 2 个 epochs 不下降,才降低学习率
- factor=0.5 表示每次降低学习率的倍数为 0.5
# 定义学习率调度器
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=2, factor=0.5)
3.自定义训练和评估函数
def train_epoch(model, dataloader, criterion, optimizer):
model.train() # 设置模型为训练模式
running_loss = 0.0
correct = 0
total = 0
for i, data in enumerate(dataloader, 0):
inputs, labels, _ = data # 获取输入数据、标签和索引
optimizer.zero_grad() # 梯度清零
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新模型参数
running_loss += loss.item() # 累加损失
_, predicted = torch.max(outputs.data, 1) # 获取预测结果
total += labels.size(0) # 累加样本数量
correct += (predicted == labels[:labels.size(0)]).sum().item() # 累加正确预测数量
return running_loss / len(dataloader), 100 * correct / total # 返回平均损失和准确率
def evaluate(model, dataloader, criterion):
model.eval() # 设置模型为评估模式
val_loss = 0.0
correct = 0
total = 0
with torch.no_grad(): # 禁用梯度计算
for data in dataloader:
images, labels, _ = data # 获取输入数据、标签和索引
outputs = model(images) # 前向传播
loss = criterion(outputs, labels) # 计算损失
val_loss += loss.item() # 累加损失
_, predicted = torch.max(outputs.data, 1) # 获取预测结果
total += labels.size(0) # 累加样本数量
correct += (predicted == labels[:labels.size(0)]).sum().item() # 累加正确预测数量
return val_loss / len(dataloader), 100 * correct / total # 返回平均损失和准确率
4.训练过程
# 训练模型
epochs = 45
best_val_acc = 0.0
best_epoch = 0 # 记录最佳 epoch
# 记录训练过程中的损失值和准确率
train_losses = []
val_losses = []
train_accuracies = []
val_accuracies = []
for epoch in tqdm(range(epochs), desc="Training"):
# 训练
train_loss, train_acc = train_epoch(model, train_loader, criterion, optimizer)
train_losses.append(train_loss)
train_accuracies.append(train_acc)
# 验证
val_loss, val_acc = evaluate(model, val_loader, criterion)
val_losses.append(val_loss)
val_accuracies.append(val_acc)
# 保存最佳模型
if val_acc > best_val_acc:
best_val_acc = val_acc
best_epoch = epoch + 1 # 记录最佳 epoch
torch.save(model.state_dict(), 'best_model.pth') # 保存最佳模型
# 更新学习率
scheduler.step(val_loss)
# 打印损失值和准确率
print(f'Epoch {epoch + 1}: Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.4f}%, Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.4f}%')
print(f'Finished Training. Best Epoch: {best_epoch}')

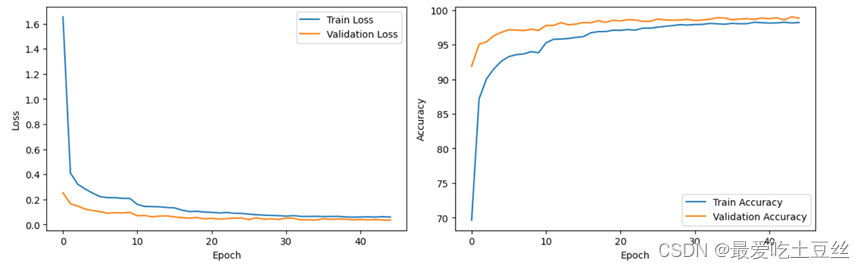
5.绘制训练曲线
你可以通过观察拟合曲线的变化来判断你的模型是否过拟合,以及调整模型结构和参数。
- 训练集和验证集的损失值变化趋势:- 如果训练集损失持续下降,但验证集损失开始上升,则表明模型可能过拟合。
- 训练曲线: 绘制训练集和验证集的损失值和准确率曲线,观察它们之间的差距。- 如果差距较大,则表明模型可能过拟合。
# 绘制训练曲线
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='Train Loss')
plt.plot(val_losses, label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(train_accuracies, label='Train Accuracy')
plt.plot(val_accuracies, label='Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.tight_layout()
plt.show()
6.最佳模型在验证集上准确率
model.load_state_dict(torch.load('best_model.pth'))
model.eval()
# 计算验证集准确率
all_predictions = []
all_labels = []
with torch.no_grad():
for images, labels, _ in val_loader:
outputs = model(images)
_, predictions = torch.max(outputs, 1)
all_predictions.extend(predictions.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
accuracy = accuracy_score(all_labels, all_predictions)
print(f"Validation Accuracy: {accuracy * 100:.4f}%")

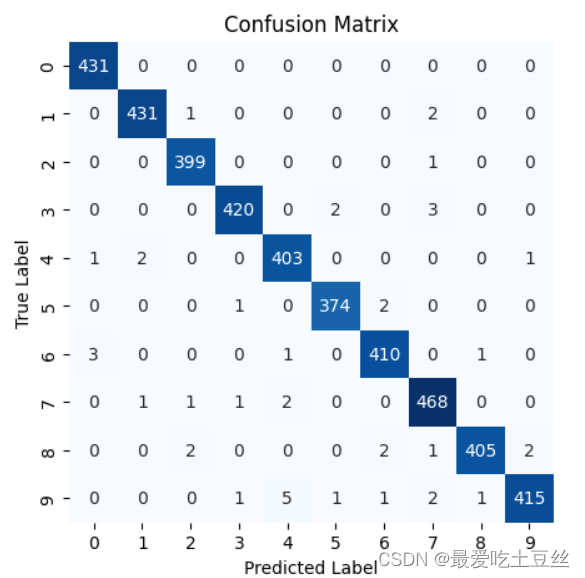
7.绘制混淆矩阵
混淆矩阵解析:
- 横轴: 表示模型预测的类别标签 (Predicted Label)。
- 纵轴: 表示样本的真实类别标签 (True Label)。
- 每个单元格中的数值: 表示该真实类别被预测为该预测类别的样本数量。
- 对角线上的数值: 表示模型正确预测的样本数量。 数值越大,说明模型在该类别上的表现越好。
- 非对角线上的数值: 表示模型错误预测的样本数量。 数值越大,说明模型在该类别上的表现越差。
例:
- 单元格 (4, 4) 的数值为 403: 表示真实类别为 4 的样本中,有 403 个被正确地预测为类别 4。
- 单元格 (9, 4) 的数值为 5: 表示真实类别为 9 的样本中,有 5 个被错误地预测为类别 4。
# 计算混淆矩阵
cm = confusion_matrix(all_labels, all_predictions)
# 绘制混淆矩阵
plt.figure(figsize=(5, 5))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", cbar=False,
xticklabels=range(10), yticklabels=range(10))
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("Confusion Matrix")
plt.show()
8.预测错误图像对比
通过对预测错误图像的对比,可以更直观的看出模型预测是否准确,及哪里需要改进。
如在这次预测过程中,我觉得真实标签为9的手写数字图像并不应该被预测错误,那我就需要判断是什么导致了预测错误,并进行改进。
# 查找预测错误的样本
incorrect_images = []
incorrect_labels = []
predicted_labels = []
with torch.no_grad():
for images, labels, indices in val_loader:
outputs = model(images)
_, preds = torch.max(outputs, 1)
for i in range(len(preds)):
if preds[i] != labels[i]:
incorrect_images.append(images[i])
incorrect_labels.append(labels[i])
predicted_labels.append(preds[i])
# 展示部分预测错误的样本
num_samples = 6 # 展示的样本数量
fig, axes = plt.subplots(nrows=2, ncols=num_samples // 2, figsize=(12, 6))
axes = axes.flatten()
for i in range(num_samples):
ax = axes[i]
img = incorrect_images[i].cpu().numpy().transpose(1, 2, 0) * 0.5 + 0.5
ax.imshow(img, cmap='gray')
ax.set_title(f"True: {incorrect_labels[i]}, Pred: {predicted_labels[i]}")
ax.axis('off')
plt.tight_layout()
plt.show()

9.正式验证提交
# 预测测试集
predictions = []
with torch.no_grad():
for data in test_loader:
images = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
predictions.extend(predicted.numpy())
# 保存预测结果
submission = pd.DataFrame({'ImageId': range(1, len(test_images) + 1), 'Label': predictions})
submission.to_csv('submission.csv', index=False)
总结:
最终的得分在99.6%(前6%)左右,在该项目中,因为MNIST 数据集图像并不复杂,数据量也并不算很多,所以推荐先使用简单的cnn模型进行训练,直到达到瓶颈再根据你的诉求进行进一步调整。本篇文章参考了很多kaggle中前辈的经验,在这里列出一些文章,还有一些没有找到,你可以根据原文进行学习。
Introduction to CNN Keras - 0.997 (top 6%) (kaggle.com)
Pytorch Tutorial for Deep Learning Lovers (kaggle.com)
版权归原作者 最爱吃土豆丝 所有, 如有侵权,请联系我们删除。