
selenium在处理需要登陆的时候,需要修改浏览器请求头参数cookie或token,在请求需要登陆的页面时,添加参数,跳过登陆,直接获取登陆后的内容。
直接在driver对象内添加cookie参数绕开登陆
处理思路
- 浏览器先登陆,请求同一个域名下的网页,抓包,提取浏览器内的cookie字符串,如:
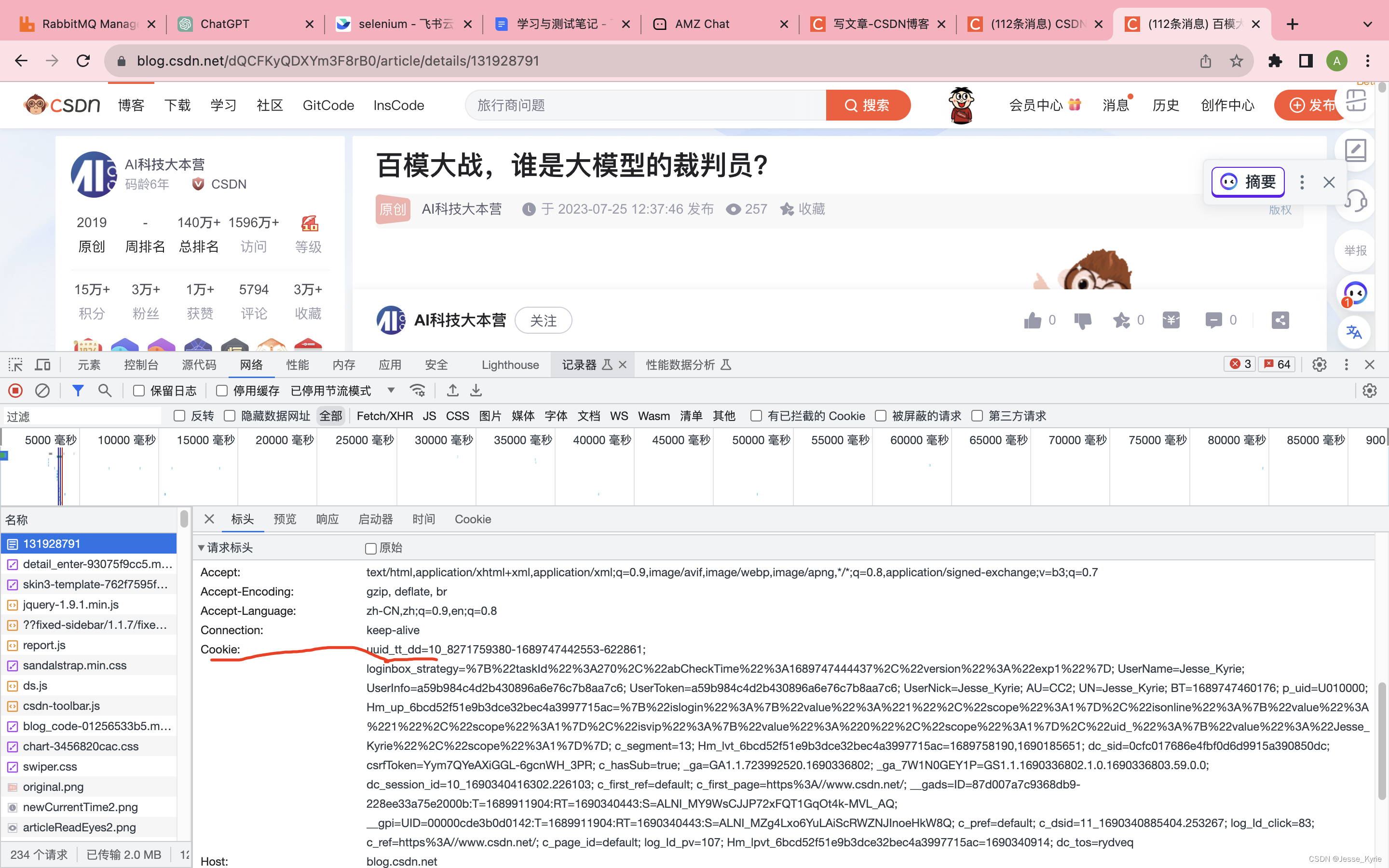 标红的字符串直接复制,并解析为python字典格式【将数据按照“;“划分,name为=之前内容,value为=后的值,domain 为接口的域名,组成以下格式。
标红的字符串直接复制,并解析为python字典格式【将数据按照“;“划分,name为=之前内容,value为=后的值,domain 为接口的域名,组成以下格式。
cookie_string = 'uuid_tt_dd=xxxxxxxxxxx;' # 你的cookie字符串
cookies = [] # 用于添加到driver内的cookies列表
for cookie in cookie_string.split(';'):
name = cookie.split('=')[0].strip()
value = cookie.split('=')[1].strip()
domain = '.csdn.net'
cookies.append({
"name":name,
"value":value,
"domain":domain
})
- 新建driver,并添加cookie,请求数据
from selenium import webdriver
driver = webdriver.Chrome()
# 未添加cookie登录
driver.get("https://blog.csdn.net/yuan2019035055/article/details/131513357")
# 添加cookie
for cookie in cookies:
driver.add_cookie(cookie)
# 重新登录
driver.get("https://blog.csdn.net/yuan2019035055/article/details/131513357")
driver.implicitly_wait(10)
访问登陆页面登陆
登陆地址:https://login2.scrape.center/
处理思路
- 访问登陆页
- 输入用户名密码(都为admin),点击登陆
- 截取详情页
本文转载自: https://blog.csdn.net/Jesse_Kyrie/article/details/131934865
版权归原作者 Jesse_Kyrie 所有, 如有侵权,请联系我们删除。
版权归原作者 Jesse_Kyrie 所有, 如有侵权,请联系我们删除。