
目录
本文详细记录了函数grouping sets使用时遇到的坑,全文代码基于Hive和Presto实现。
1. 问题讨论
1.1 数据准备
首先建立商品销售表:
CREATETABLEtemp.goods_sale_info(`province` string comment'省份',`city` string comment'城市',`goodsid` string comment'商品编号',`goodsname` string comment'商品名称',`sales_qty`decimal(38,5)comment'销量',`sales_amt`decimal(38,5)comment'销售额')ROW FORMAT DELIMITED FIELDSTERMINATEDBY',';insertintotabletemp.goods_sale_info
values('江西省','南昌市','1000','可口可乐','10','40'),('福建省','福州市','1000','可口可乐','200','1000'),('福建省','厦门市','1000','可口可乐','300','1500'),('福建省','厦门市','1200','百事可乐','200','1000'),('福建省','厦门市','2000','伊利安慕希','300','21000');select*fromtemp.goods_sale_info
再建立一个商品信息表:
CREATETABLEtemp.goods_info(`goodsid` string comment'商品编号',`goodsname` string comment'商品名称',`catgory_id` string comment'商品种类编号',`catgory_name` string comment'商品种类')ROW FORMAT DELIMITED FIELDSTERMINATEDBY',';insertintotabletemp.goods_info
values('1000','可口可乐','11','饮料'),('1200','百事可乐','11','饮料'),('2000','伊利安慕希','12','乳制品')select*fromtemp.goods_info
1.2 问题描述
根据不同字段分组聚合实现各个维度的销量和销售额
1.3 其它方法多维度聚合(union、with cube)
要实现城市’'city’维度聚合求商品销量、销售额以及从省份’province’维度聚合求商品销量、销售额,并放入一个表中,一般可以采用下面两种方法:
-- 方法1:分开聚合select province
,NULLas city
,goodsid
,goodsname
,sum(sales_qty)as sales_qty
,sum(sales_amt)as sales_amt
,'prov_dim' dim_flag
fromtemp.goods_sale_info
groupby province,goodsid,goodsname
unionallselectNULLas province
,city
,goodsid
,goodsname
,sum(sales_qty)as sales_qty
,sum(sales_amt)as sales_amt
,'city_dim' dim_flag
fromtemp.goods_sale_info
groupby city,goodsid,goodsname
运行结果: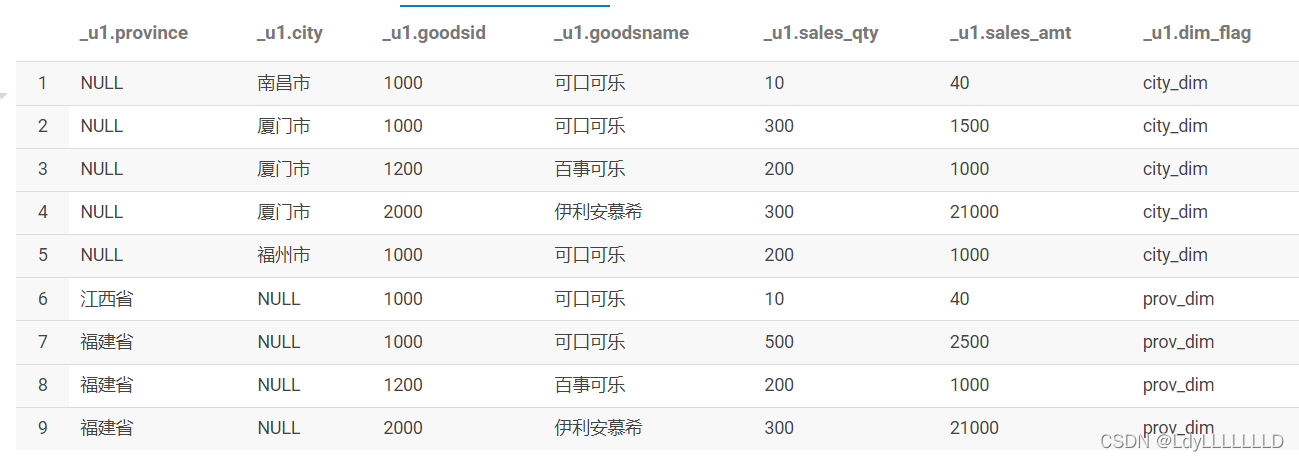
-- 方法2:with cube高级别聚合createtabletemp.goods_sales_info_cube as-- 要生成表才可以进行下一步筛选,起表别名后嵌套筛选不出来select province
,city
,goodsid
,goodsname
,sum(sales_qty)as sales_qty
,sum(sales_amt)as sales_amt
,grouping__id --,可写可不写fromtemp.goods_sale_info
groupby
province
,city
,goodsid
,goodsname with cube
-- rollup 是以最左侧指标为主进行组合聚合,是CUBE的子集,以最左侧的维度为主,从该维度进行层级聚合。更换province和city的前后会出来不同结果-- rollup是cube的一种特殊情况,cube对所有的维度进行聚合,会出现city,province和province,city的结果-- 对生成的结果进行筛选,即可得到与方法1同样的结果select*fromtemp.goods_sales_info_cube
where grouping__id in('13','14')-- 不想生成grouping__id字段的话可以用下面条件判断-- where (province is null and city is not null and goodsid is not null and goodsname is not null)-- or (province is not null and city is null and goodsid is not null and goodsname is not null)
运行结果:
相较于with rollup 和with cube,grouping sets可以实现分组字段的自由组合,当分组字段变多,想要按需分组时候用grouping sets更方便。
2. Hive中的grouping sets函数
对于多个维度聚合问题,grouping sets不用像cube方式将分组字段排列组合列出全部维度的结果,能够实现更灵活的组合。
2.1 grouping sets方法多维度聚合
select province
,city
,goodsid
,goodsname
,sum(sales_qty)as sales_qty
,sum(sales_amt)as sales_amt
,GROUPING__ID
fromtemp.goods_sale_info
groupby province
,city
,goodsid
,goodsname
grouping sets((),-- 1、全国销量、销售额(goodsid,goodsname),-- 2、各商品的全国销量、销售额(province,goodsid,goodsname),-- 3、各省各商品的销量、销售额(province,goodsid),-- 4、各省各商品的销量、销售额(city)-- 5、各城市销量、销售额)
运行结果: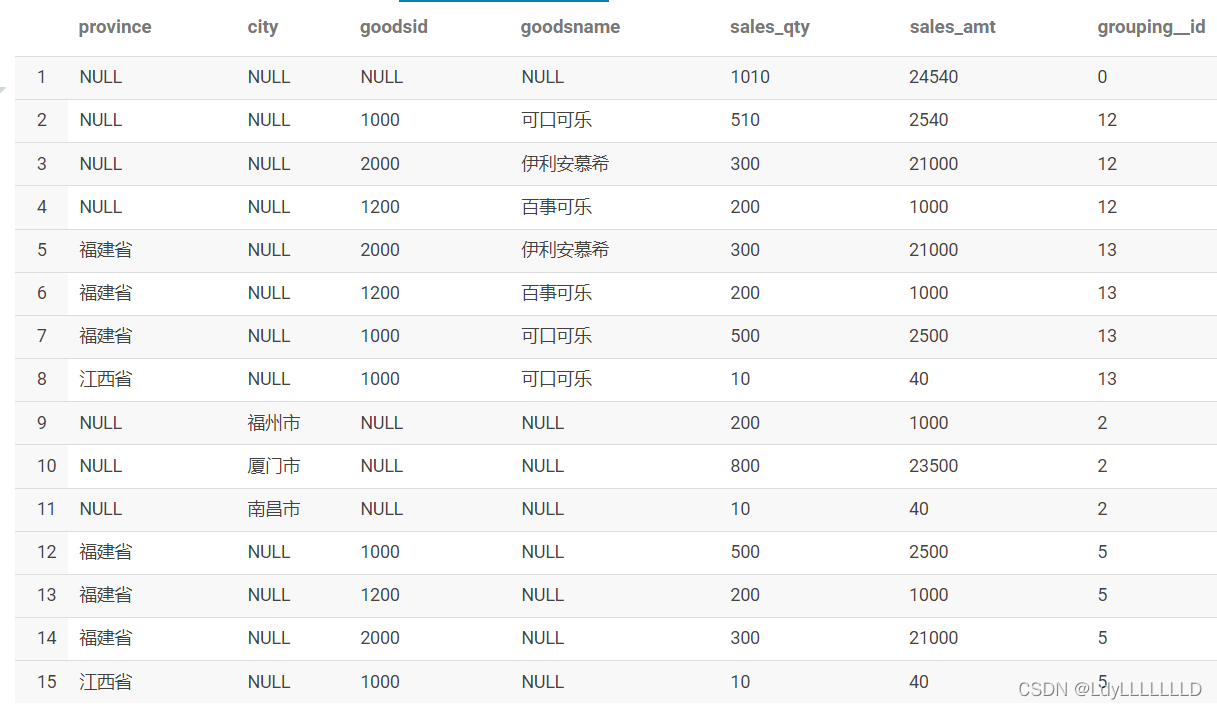
函数及运行结果讲解:
1、group by后面放的字段表示要分组聚合的全部字段
2、grouping sets 后面放的是 group by 后面各种字段的组合,根据实际需求进行组合,组合字段用小括号括起来(上面代码中的第2、3、4组),也可以是单一字段(上面代码中sets里面的第5组)
3、在求取全国的成交量的时候其实是不需要分组聚合的,但是为了使用 grouping sets,所以在求取全国成交量的时候用 group by null(上面代码中sets里面的第1组)
4、sets中第3组和第4组的区别在于有没有写goodsname,没有写goodsname的第4组生成的结果中goodsname列为空值
2.2 grouping sets在联结join中使用的踩坑点
在具有表联结语句中grouping sets函数使用有个踩坑点,初次使用很可能都报错找不到原因。。总结一下就是:
表联结的结果出来之后再用grouping sets,分组字段组合sets里面用表别名会报错。
报错语句见下:
-- 报错语句select t1.province
,t1.city
,t2.catgory_id
,t2.catgory_name
,t1.goodsid
,t1.goodsname
,sum(t1.sales_qty)as sales_qty
,sum(t1.sales_amt)as sales_amt
,GROUPING__ID
fromtemp.goods_sale_info t1
leftjointemp.goods_info t2
on t1.goodsid=t2.goodsid
groupby
t1.province
,t1.city
,t2.catgory_id
,t2.catgory_name
,t1.goodsid
,t1.goodsname
grouping sets((t1.province,t2.catgory_id,t2.catgory_name))
正确语句见下:
-- 正确语句select province
,city
,catgory_id
,catgory_name
,goodsid
,goodsname
,sum(sales_qty)as sales_qty
,sum(sales_amt)as sales_amt
,GROUPING__ID
from(select t1.province
,t1.city
,t2.catgory_id
,t2.catgory_name
,t1.goodsid
,t1.goodsname
,sales_qty
,sales_amt
fromtemp.goods_sale_info t1
leftjointemp.goods_info t2
on t1.goodsid=t2.goodsid
) t --在表t的基础上使用grouping sets函数groupby
province
,city
,catgory_id
,catgory_name
,goodsid
,goodsname
grouping sets((province,catgory_id,catgory_name)--这里仅有3个字段,但select中列有不在sets中的非分组字段city、goodsid、goodsname,hive不报错,presto会报错)
运行结果:
2.3 grouping sets函数使用补充事项
1、select子句中的GROUPING__ID是两个下划线
2、执行语句后GROUPING__ID的结果是数字,如果sets中有5种组合,GROUPING__ID会生成5个不等的数字,具体哪个数字对应哪个维度,需要根据生成的表进行测试判断,或者根据下面2.4节的方法用二进制去计算确定,用于自定义划分维度
3、GROUPING__ID的数字只要不改变表以及查询条件,每次运行都是这些数字
2.4 计算grouping__id值
方法描述:
grouping sets 中的每一种粒度,都对应唯一的 grouping__id 值,其计算公式与 group by 的顺序、当前粒度的字段有关。
具体计算方法如下:
1、字段排序
将字段按照group by后的顺序 进行排序,例如是3个字段
2、字段赋值
根据grouping sets的每个set中的字段,用0或1进行赋值,例如group by后跟了3个字段结果就会给出一个有3个数字的二进制数。
赋值规则为 对于每个字段,如果该字段有值则赋给0,空值则给1。出现在当前粒度中,则给0,没出现则给1
3、转化十进制
上面赋值后就形成了一个二进制数,然后将二进制转为10进制就是grouping__id的值
下面为了不进行数据测试,直接根据grouping__id的值来判断grouping__id对应的是哪个维度,在select语句中可以按照如下方式判断:
4、判断维度
按照group by字段顺序求 数字2 的幂次方,紧挨着group by的字段为最高次方,依次递减,然后对grouping__id和 相应层级的幂次方 用位运算 ”&与“ 来判断维度
举个例子:
select province
,city
,goods_id
,if(grouping__id & cast(pow(2,2)asint)=0,'province','')as dim
,sum(sales_amt)from tmp.table1
groupby
province
,city
,goods_id
grouping sets((province,city),(province))
第一步:按顺序,group by 后面是province,city,goods_id,
第二步:以sets中的province为例,得到的二进制数是 011
第三步:转化为十进制,011 为 120+121+0 =3
第四步:根据province,city,goods_id的顺序,分别为 2的平方、2的1次方、2的0次方
在select中想要判断出province维度,即可用 2的平方 去做位运算, 2的平方对应的二进制为 100
对比
0 1 1
1 0 0
其位运算结果为0
则该grouping__id 对应的是province维度
tips:
跟hive的版本有关,有的版本使用下面的规则:
1、字段排序:将 group by 后面的字段 倒序 排列
2、字段赋值:对于每个字段,如果该字段出现在了当前粒度中,则该字段位置赋值为1,否则为0。
3、转化十进制:将这个二进制数转为十进制,即为当前粒度对应的 grouping__id
3. Presto中的grouping sets函数
3.1 函数grouping sets使用及坑点(5点说明)
用法:
1、函数grouping要与group by、grouping sets配合使用
2、函数grouping()中列出sets中所有分组涉及的字段,运行后grouing()列生成结果为二进制转化来的十进制数字
-- 比如select column1,column2,column3,
grouping(column1,column2,column3)groupby
grouping sets(
(column1),(column2,column3)
)
-- 如果分组中包含相应的列,则将位设置为0,否则将其设置为1-- 第一组 中 三个字段的 为 0 1 1-- 第二组 中 三个字段的 为 1 0 0-- grouping函数的值即为011和100对应的十进制数字
参考链接:presto grouping操作
3、group by后面只跟grouping sets(),不加select中的单一字段,否则函数grouping sets无作用
-- 如果group by写上单一字段select province
,city
,catgory_id
,catgory_name
,goodsid
,goodsname
,sum(sales_qty)as sales_qty
,sum(sales_amt)as sales_amt
,grouping(province,city,catgory_id,catgory_name,goodsid,goodsname)from(select t1.province
,t1.city
,t2.catgory_id
,t2.catgory_name
,t1.goodsid
,t1.goodsname
,sales_qty
,sales_amt
fromtemp.goods_sale_info t1
leftjointemp.goods_info t2
on t1.goodsid=t2.goodsid
) t --也是要在表t的基础上使用grouping sets函数groupby
province
,city
,catgory_id
,catgory_name
,goodsid
,goodsname
,grouping sets(--这里记得加上逗号,(province,catgory_id,catgory_name),(province,catgory_id,catgory_name,goodsid,goodsname),(province,city),(province))
运行结果:
表t结果有5条记录,grouping sets中有4种组合。按照上面语句执行,结果记录数为 5×4=20条记录,同理1种组合结果为5×1,2种组合为5×2,3种组合为5×3
4、不用的分组字段不要在select子句中写出
-- 与hive不同,如果不出现在grouping sets中的字段,select子句写上会报错-- 比如sets中不涉及city、goodsid、goodsname,select子句中写出来报错select province
-- ,city,catgory_id
,catgory_name
-- ,goodsid-- ,goodsname,sum(sales_qty)as sales_qty
,sum(sales_amt)as sales_amt
,grouping(province,catgory_id,catgory_name)from(select t1.province
,t1.city
,t2.catgory_id
,t2.catgory_name
,t1.goodsid
,t1.goodsname
,sales_qty
,sales_amt
fromtemp.goods_sale_info t1
leftjointemp.goods_info t2
on t1.goodsid=t2.goodsid
) t
groupby
grouping sets((province,catgory_id,catgory_name))
5、函数grouping中要将grouping sets所有分组组合用到的字段取并集列出
select province
,city
,catgory_id
,catgory_name
,goodsid
,goodsname
,sum(sales_qty)as sales_qty
,sum(sales_amt)as sales_amt
,grouping(province,city,catgory_id,catgory_name,goodsid,goodsname)-- grouping里面一定要把sets中用到的字段写全,不然生成的数字会缺-- 比如下面sets中有3种组合,如果grouping()种缺少字段,数字会不是3个from(select t1.province
,t1.city
,t2.catgory_id
,t2.catgory_name
,t1.goodsid
,t1.goodsname
,sales_qty
,sales_amt
fromtemp.goods_sale_info t1
leftjointemp.goods_info t2
on t1.goodsid=t2.goodsid
) t --也是要在表t的基础上使用grouping sets函数groupby
grouping sets((province,catgory_id,catgory_name),(province,catgory_id,catgory_name,goodsid,goodsname),(province,city))
3.2 函数grouping sets在hive与presto中的区别
综上可见,可以对比出presto与hive在grouping sets函数使用上的区别:
1、Hive中select子句中用GROUPING__ID,GROUPING__ID不是函数;Presto的select子句中grouping是一个函数,要采用grouping(column_1,column_2,…),列出分组涉及到的所有字段。不过两者运行后的结果都是数字,可以用于后面的维度测试
2、Hive的group by子句中要列出单一字段,然后加上grouping sets,并且grouping sets 前面不加逗号“,”;Presto的group by子句中仅有grouping sets
版权归原作者 LdyLLLLLLLD 所有, 如有侵权,请联系我们删除。