
文章目录
一、Spark概述
1、概述
Spark是一种快速、通用、可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache顶级项目。项目是用Scala进行编写。
目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkCore、SparkSQL、Spark Streaming、GraphX、MLib、SparkR等子项目,Spark是基于内存计算的大数据并行计算框架。除了扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。Spark 适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理、迭代算法、交互式查询、流处理。通过在一个统一的框架下支持这些不同的计算,Spark 使我们可以简单而低耗地把各种处理流程整合在一起。而这样的组合,在实际的数据分析 过程中是很有意义的。不仅如此,Spark 的这种特性还大大减轻了原先需要对各种平台分 别管理的负担。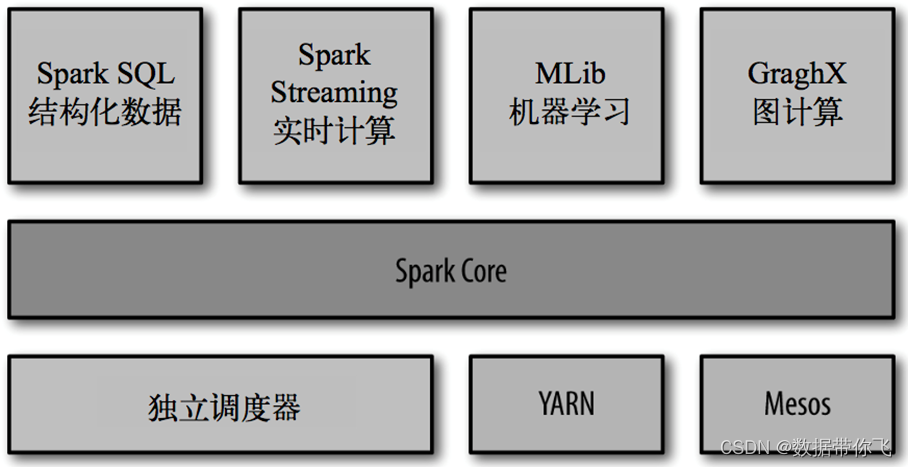
Spark Core:实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core 中还包含了对弹性分布式数据集(resilient distributed dataset,简称RDD)的 API 定义。
Spark SQL:是 Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。Spark SQL 支持多种数据源,比 如 Hive 表、Parquet 以及 JSON 等。
Spark Streaming:是 Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。
Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
GraphX:提供一个分布式图计算框架,能高效进行图计算。
集群管理器:Spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark 支持在各种集群管理器(cluster manager)上运行,包括 Hadoop YARN、Apache Mesos,以及 Spark 自带的一个简易调度 器,叫作独立调度器Standalone。
Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于凤巢、大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群。
2、Spark特点
1)快:与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。计算的中间结果是存在于内存中的。
2)易用:Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。
3)通用:Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
4)兼容性:Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。
二、Spark角色介绍及运行模式
1、集群角色
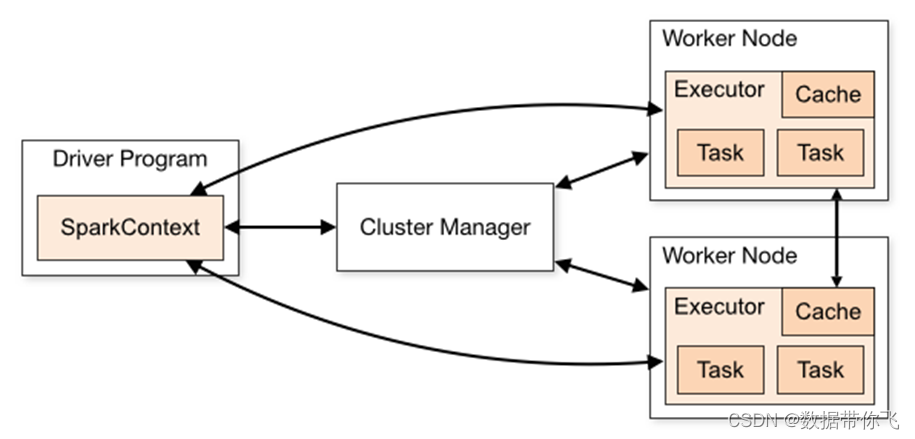
从物理部署层面上来看,Spark主要分为两种类型的节点,Master节点和Worker节点:Master节点主要运行集群管理器的中心化部分,所承载的作用是分配Application到Worker节点,维护Worker节点,Driver,Application的状态。Worker节点负责具体的业务运行。
从Spark程序运行的层面来看,Spark主要分为驱动器节点和执行器节点。
2、运行模式
运行环境模式模式Local本地模式常用于本地开发测试,如在eclipse,idea中写程序测试等。本地还分为local单线程和local-cluster多线程local[]Standalone集群模式Spark自带的一个资源调度框架,支持完全分布式。存在的Master单点故障可由ZooKeeper来实现HAYarn集群模式运行在yarn资源管理器框架之上,由yarn负责资源管理,Spark负责任务调度和计算
1)Local模式: Local模式就是运行在一台计算机上的模式,通常就是用于在本机上练手和测试。它可以通过以下集中方式设置master。
local: 所有计算都运行在一个线程当中,没有任何并行计算,通常我们在本机执行一些测试代码,或者练手,就用这种模式;
local[K]: 指定使用几个线程来运行计算,比如local[4]就是运行4个worker线程。通常我们的cpu有几个core,就指定几个线程,最大化利用cpu的计算能力;
local[]: 这种模式直接帮你按照cpu最多cores来设置线程数了。
2)Standalone模式: 构建一个由Master+Slave构成的Spark集群,Spark运行在集群中。
3)Yarn模式: Spark客户端直接连接Yarn;不需要额外构建Spark集群。有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点。
yarn-client:Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出
yarn-cluster:Driver程序运行在由RM(ResourceManager)启动的AP(APPMaster中,这种模式适用于生产环境
三、Spark集群安装
1.Local模式
1.下载文件
下载地址:
http://spark.apache.org/downloads.html
或者
https://archive.apache.org/dist/spark/
选择合适自己的版本下载。我们这里选择spark-3.1.2-bin-hadoop2.7.tgz版本。
2.解压缩
将我们的压缩包上传到hadoop01服务器的/opt/softwares路径下并解压
cd /opt/softwares/
tar -xvzf spark-3.1.2-bin-hadoop2.7.tgz -C ../servers/
3、修改配置文件
修改spark/conf/spark-env.sh.template,执行如下命令:
cd /opt/servers/spark-3.1.2-bin-hadoop2.7/conf
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
新增如下内容:
export JAVA_HOME=/opt/servers/jdk1.8.0_65
4.配置环境变量
修改/etc/profile文件,新增spark环境变量:
export SPARK_HOME=/opt/servers/spark-3.1.2-bin-hadoop2.7
export PATH=:$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
修改完成后记得执行 source /etc/profile 使其生效
5.启动服务
cd /opt/servers/spark-3.1.2-bin-hadoop2.7
sbin/start-all.sh
6.启动客户端
spark-shell
简单测试
读取spark安装目录下的readme.md文件,并统计词条数量和显示第一行字符。
scala> val textFile = sc.textFile("file:///opt/servers/spark-3.1.2-bin-hadoop2.7/README.md") //读取readme.md文件
textFile: org.apache.spark.rdd.RDD[String] = /opt/servers/spark-3.1.2-bin-hadoop2.7/README.md MapPartitionsRDD[1] at textFile at <console>:24
scala> textFile.count() //词条统计
res0: Long = 108
scala> textFile.first() //打印第一行字符
res1: String = # Apache Spark
2.Standalone模式
Standalone模式可以在Local模式下继续操作。
1.停止服务
cd /opt/servers/spark-3.1.2-bin-hadoop2.7
sbin/stop-all.sh
2.修改配置文件spark-env.sh
修改spark-env.sh文件,执行以下操作
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
添加以下内容:
export JAVA_HOME=/opt/servers/jdk1.8.0_65
SPARK_MASTER_HOST=hadoop01
SPARK_MASTER_PORT=7077
3.修改配置文件workers
mv workers.template workers
vim workers
添加以下内容:
hadoop01
hadoop02
hadoop03
4、将配置好后的spark-3.1.2安装包分发到其他节点
cd /opt/servers/
scp -r spark-3.1.2-bin-hadoop2.7 hadoop02:$PWD
scp -r spark-3.1.2-bin-hadoop2.7 hadoop03:$PWD
5、分发/etc/profile
分发/etc/profile文件
scp /etc/profile hadoop02:/etc
scp /etc/profile hadoop03:/etc
完成后记得执行 source /etc/profile 使其生效
5.启动服务
cd /opt/servers/spark-3.1.2-bin-hadoop2.7
sbin/start-all.sh
6.测试
1.spark-shell
spark-shell \
--master spark://hadoop01:7077 \
--executor-memory 1g \
--total-executor-cores 2
读取spark安装目录下的readme.md文件,并统计词条数量和显示第一行字符。
scala> val textFile = sc.textFile("hdfs://hadoop01:8020/test/input/README.md") //读取readme.md文件
textFile: org.apache.spark.rdd.RDD[String] = /opt/servers/spark-3.1.2-bin-hadoop2.7/README.md MapPartitionsRDD[1] at textFile at <console>:24
scala> textFile.count() //词条统计
res0: Long = 108
scala> textFile.first() //打印第一行字符
res1: String = # Apache Spark
2.spark-submit
该算法是利用蒙特·卡罗算法求PI
cd /opt/servers/spark-3.1.2-bin-hadoop2.7
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop01:7077 \
./examples/jars/spark-examples_2.12-3.1.2.jar \
10
3.Spark on Yarn
yarn模式两种提交任务方式:
Spark可以和Yarn整合,将Application提交到Yarn上运行,Yarn有两种提交任务的方式。
3.1yarn-client提交任务方式
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.12-3.1.2.jar 100
3.1yarn-cluster提交任务方式
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster ./examples/jars/spark-examples_2.12-3.1.2.jar 100
注:如果在yarn集群中运行报错,可能是因为yarn内存检测的原因导致,需要增加如下配置
vi yarn-site.xml
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
四、Spark Core
1、RDD概述
什么是RDD?
RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、弹性、里面的元素可并行计算的集合。在 Spark 中,对数据的所有操作不外乎创建 RDD、转化已有RDD 以及调用 RDD 操作进行求值。每个 RDD 都被分为多个分区,这些分区运行在集群中的不同节点上。RDD 可以包含 Python、Java、Scala 中任意类型的对象, 甚至可以包含用户自定义的对象。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD支持两种操作:转化操作和行动操作。RDD 的转化操作是返回一个新的 RDD的操作,比如 map()和 filter(),而行动操作则是向驱动器程序返回结果或把结果写入外部系统的操作。比如 count() 和 first()。
Spark采用惰性计算模式,RDD只有第一次在一个行动操作中用到时,才会真正计算。Spark可以优化整个计算过程。默认情况下,Spark 的 RDD 会在你每次对它们进行行动操作时重新计算。如果想在多个行动操作中重用同一个 RDD,可以使用 RDD.persist() 让 Spark 把这个 RDD 缓存下来。
2、 RDD的属性
- RDD是一个分片的数据集合,即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
- RDD的函数针对每个分片进行计算;。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
- RDD之间是个依赖的集合;。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
- 可选:key-value型RDD是根据哈希来分区的;当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
- 可选:数据本地性优先计算。一个列表,存储存取每个Partition的对应数据的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
RDD是一个应用层面的逻辑概念。一个RDD多个分片。RDD就是一个元数据记录集,记录了RDD内存所有的关系数据。
3、 RDD的弹性
- 自动进行内存和磁盘数据存储的切换 Spark优先把数据放到内存中,如果内存放不下,就会放到磁盘里面,程序进行自动的存储切换
- 基于血统的高效容错机制 在RDD进行转换和动作的时候,会形成RDD的Lineage依赖链,当某一个RDD失效的时候,可以通过重新计算上游的RDD来重新生成丢失的RDD数据,如果只是某个分区的数据丢失,只计算这个分区的数据。
- Task如果失败会自动进行特定次数的重试 RDD的计算任务如果运行失败,会自动进行任务的重新计算,默认次数是4次。
- Stage如果失败会自动进行特定次数的重试 如果Job的某个Stage阶段计算失败,框架也会自动进行任务的重新计算,默认次数也是4次。 Spark中的Stage其实就是一组并行的任务,任务是一个个的task
- Checkpoint和Persist可主动或被动触发 RDD可以通过Persist持久化将RDD缓存到内存或者磁盘,当再次用到该RDD时直接读取就行。也可以将RDD进行检查点,检查点会将数据存储在HDFS中,该RDD的所有父RDD依赖都会被移除。
- 数据调度弹性 Spark把这个JOB执行模型抽象为通用的有向无环图DAG,可以将多Stage的任务串联或并行执行,调度引擎自动处理Stage的失败以及Task的失败。
4、RDD特点
RDD表示只读的分区的数据集,对RDD进行改动,只能通过RDD的转换操作,由一个RDD得到一个新的RDD,新的RDD包含了从其他RDD衍生所必需的信息。RDDs之间存在依赖,RDD的执行是按照血缘关系延时计算的。如果血缘关系较长,可以通过持久化RDD来切断血缘关系。
(1)分区
RDD逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候会通过一个compute函数得到每个分区的数据。如果RDD是通过已有的文件系统构建,则compute函数是读取指定文件系统中的数据,如果RDD是通过其他RDD转换而来,则compute函数是执行转换逻辑将其他RDD的数据进行转换。
(2)只读
如下图所示,RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD。
由一个RDD转换到另一个RDD,可以通过丰富的操作算子实现,不再像MapReduce那样只能写map和reduce了,如下图所示。
RDD的操作算子包括两类,一类叫做transformations,它是用来将RDD进行转化,构建RDD的血缘关系;另一类叫做actions,它是用来触发RDD的计算,得到RDD的相关计算结果或者将RDD保存的文件系统中。下图是RDD所支持的操作算子列表。
(3)依赖
RDDs通过操作算子进行转换,转换得到的新RDD包含了从其他RDDs衍生所必需的信息,RDDs之间维护着这种血缘关系,也称之为依赖。如下图所示,依赖包括两种,一种是窄依赖,RDDs之间分区是一一对应的,另一种是宽依赖,下游RDD的每个分区与上游RDD(也称之为父RDD)的每个分区都有关,是多对多的关系,宽依赖会引起shuffle。
通过RDDs之间的这种依赖关系,一个任务流可以描述为DAG(有向无环图),如下图所示,在实际执行过程中宽依赖对应于Shuffle(图中的reduceByKey和join),窄依赖中的所有转换操作可以通过类似于管道的方式一气呵成执行(图中map和union可以一起执行)。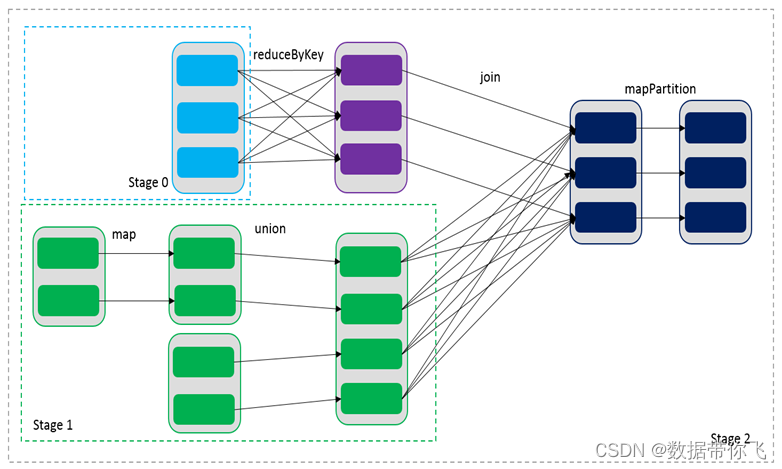
5.代码示例
需求:统计统计词的出现次数
1.创建Maven工程,添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.2</version>
</dependency>
代码实现
publicstaticvoidmain(String[] args){SparkConf sparkConf =newSparkConf().setAppName("JavaWordCount").setMaster("local[*]");JavaSparkContext sc =newJavaSparkContext(sparkConf);JavaRDD lines = sc.textFile("hdfs://hadoop01:8020/test/input/word.txt");JavaRDD words = lines.flatMap(newFlatMapFunction<String,String>(){@OverridepublicIterator<String>call(String line)throwsException{returnArrays.asList(line.split(" ")).iterator();}});JavaPairRDD word = words.mapToPair(newPairFunction<String,String,Integer>(){@OverridepublicTuple2<String,Integer>call(String word)throwsException{returnnewTuple2<>(word,1);}});JavaPairRDD wordcount = word.reduceByKey(newFunction2<Integer,Integer,Integer>(){@OverridepublicIntegercall(Integer i1,Integer i2)throwsException{return i1 + i2;}});
wordcount.foreach(newVoidFunction<Tuple2<String,Integer>>(){publicvoidcall(Tuple2<String,Integer> o)throwsException{System.out.println(o._1 +" : "+ o._2);}});}
五、Spark Streaming
1、 Spark streaming简介
Spark Streaming是Spark API的核心扩展,支持实时数据流的可扩展、高吞吐量和容错流处理。数据可以从Kafka、Kinesis或TCP套接字等多种来源中获取,并且可以使用复杂的算法进行处理,这些算法用高级函数表示,如map、reduce、join和window。最后,处理过的数据可以推送到文件系统、数据库和实时仪表板。事实上,您可以在数据流上应用Spark的机器学习和图形处理算法。
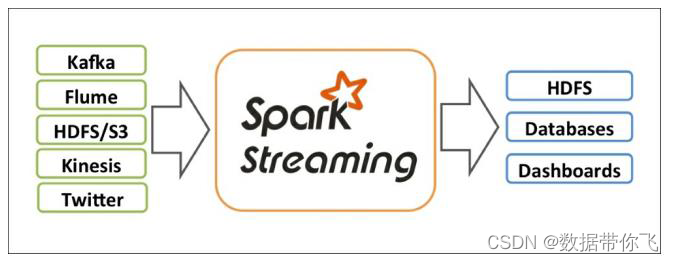
在内部,它的工作方式如下。Spark Streaming接收实时输入的数据流,并对数据进行分批处理,由Spark引擎进行处理,生成最终的批量结果流。
Spark Streaming提供了一种高级抽象,称为离散流或DStream,它表示连续的数据流。Dstream可以通过来自Kafka和Kinesis等源的输入数据流创建,也可以通过在其他Dstream上应用高级操作来创建。在内部,DStream表示为rdd序列。
2、 Dstream(离散流)
Dstream是Spark Streaming的数据抽象,同DataFrame,其实底层依旧是RDD。
Discretized Stream或DStream是Spark Streaming提供的基本抽象。它表示一个连续的数据流,要么是从源接收的输入数据流,要么是通过转换输入流生成的处理数据流。在内部,DStream由一系列连续的rdd表示,这是Spark对不可变的分布式数据集的抽象。DStream中的每个RDD都包含一定时间间隔的数据,如下图所示:
在DStream上应用的任何操作都转换为在底层rdd上的操作。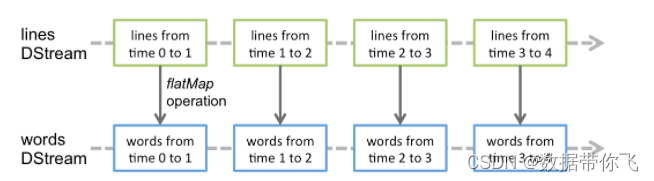
这些底层RDD转换是由Spark引擎计算的。DStream操作隐藏了大部分细节,并为开发人员提供了更高级的API。
3、 数据源
Spark Streaming提供了两类内置流源:
基本源:在StreamingContext API中直接可用的源。例如文件系统和套接字连接。
高级资源:像Kafka, Kinesis等资源可以通过额外的实用程序类获得。
注意,如果希望在流应用程序中并行接收多个数据流,可以创建多个输入Dstream。这将创建多个接收器,这些接收器将同时接收多个数据流。但是请注意,Spark worker/executor是一个长期运行的任务,因此它占用分配给Spark Streaming应用程序的一个核心。因此,Spark Streaming应用程序需要分配足够的内核(或者线程,如果在本地运行的话)来处理接收到的数据,以及运行接收端,记住这一点很重要。
4.代码示例
需求:统计统计词的出现次数
1、linux服务器安装nc服务
yum -y install nc
#使用nc命令发送数据
nc -lk 9999
2、创建Maven工程,添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.1.2</version>
</dependency>
3、代码实现
publicstaticvoidmain(String[] args)throwsException{// Create a local StreamingContext with two working thread and batch interval of 1 secondSparkConf conf =newSparkConf().setMaster("local[2]").setAppName("NetworkWordCount");JavaStreamingContext jssc =newJavaStreamingContext(conf,Durations.seconds(5));// Create a DStream that will connect to hostname:port, like localhost:9999JavaReceiverInputDStream<String> lines = jssc.socketTextStream("hadoop01",9999);
lines.flatMap(x ->Arrays.asList(x.split(" ")).iterator());// Split each line into wordsJavaDStream<String> words = lines.flatMap(x ->Arrays.asList(x.split(" ")).iterator());// Count each word in each batchJavaPairDStream<String,Integer> pairs = words.mapToPair(s ->newTuple2<>(s,1));JavaPairDStream<String,Integer> wordCounts = pairs.reduceByKey((i1, i2)-> i1 + i2);// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print();
jssc.start();// Start the computation
jssc.awaitTermination();// Wait for the computation to terminate}
六 Spark ML
1、 ALS介绍
1.1、ALS算法概括
1、ALS算法用来补全用户评分矩阵。由于用户评分矩阵比较稀疏,将用户评分矩阵进行分解,变成V和U的乘积。通过求得V和U两个小的矩阵来补全用户评分矩阵。
2、ALS算法使用交替最小二乘法来进行求解
3、ALS分为显示反馈和隐式反馈两种。显示反馈是指用户有明确的评分。对于商品推荐来说,大部分是通过用户的行为,获取隐式反馈的评分。隐式反馈评分矩阵需要进行处理,如果有用户评分则置为1,没有则赋值为0。但是对这个处理后的评分矩阵,再有一个置信度来评价这个评分。置信度等于1+a*用户真实评分
4、ALS的代价函数是估计值和现有的评分值误差的平方和,引入了L2正则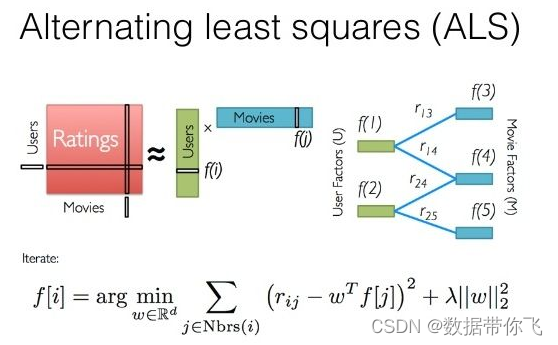
2、ALS算法原理及运用
ALS:交替最小二乘(alternating least squares)的简称。在机器学习中,ALS特指使用交替最小二乘求解的一个协同推荐算法。它通过观察到的所有用户给商品的打分,来推断每个用户的喜好并向用户推荐适合的商品。
在ALS算法出现前,协同过滤算法是最适合做类似的工作的,理解ALS算法工作原理前可以先了解一下协同过滤的工作原理。
(1)、协同过滤
1 什么是协同过滤
协同过滤是利用集体智慧的一个典型方法。要理解什么是协同过滤 (Collaborative Filtering, 简称 CF),首先想一个简单的问题,如果你现在想看个电影,但你不知道具体看哪部,你会怎么做?大部分的人会问问周围的朋友,看看最近有什么好看的电影推荐,而我们一般更倾向于从口味比较类似的朋友那里得到推荐。这就是协同过滤的核心思想。
换句话说,就是借鉴和你相关人群的观点来进行推荐,很好理解。
2 协同过滤的实现
要实现协同过滤的推荐算法,要进行以下三个步骤:
收集数据——找到相似用户和物品——进行推荐
2.1 收集数据
这里的数据指的都是用户的历史行为数据,比如用户的购买历史,关注,收藏行为,或者发表了某些评论,给某个物品打了多少分等等,这些都可以用来作为数据供推荐算法使用,服务于推荐算法。需要特别指出的在于,不同的数据准确性不同,粒度也不同,在使用时需要考虑到噪音所带来的影响。
找到相似用户和物品
2.2 进行推荐
在知道了如何计算相似度后,就可以进行推荐了。
在协同过滤中,有两种主流方法:基于用户的协同过滤,和基于物品的协同过滤。具体怎么来阐述他们的原理呢,看个图大家就明白了
基于用户的 CF 的基本思想相当简单,基于用户对物品的偏好找到相邻邻居用户,然后将邻居用户喜欢的推荐给当前用户。计算上,就是将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,找到 K 邻居后,根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。 下图给出了一个例子,对于用户 A,根据用户的历史偏好,这里只计算得到一个邻居 - 用户 C,然后将用户 C 喜欢的物品 D 推荐给用户 A。
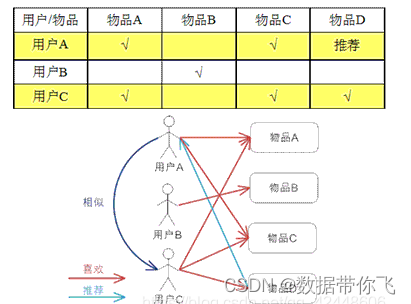
基于物品的 CF 的原理和基于用户的 CF 类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。从计算的角度看,就是将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度,得到物品的相似物品后,根据用户历史的偏好预测当前用户还没有表示偏好的物品,计算得到一个排序的物品列表作为推荐。下图给出了一个例子,对于物品 A,根据所有用户的历史偏好,喜欢物品 A 的用户都喜欢物品 C,得出物品 A 和物品 C 比较相似,而用户 C 喜欢物品 A,那么可以推断出用户 C 可能也喜欢物品 C。
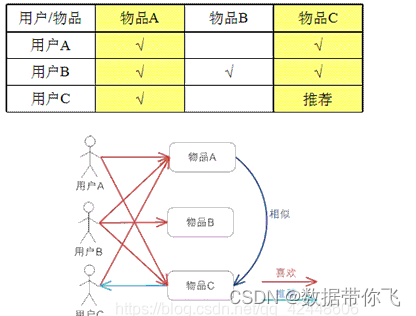
总结
以上两个方法都能很好的给出推荐,并可以达到不错的效果。但是他们之间还是有不同之处的,而且适用性也有区别。下面进行一下对比
适用场景
在非社交网络的网站中,内容内在的联系是很重要的推荐原则,它比基于相似用户的推荐原则更加有效。比如在购书网站上,当你看一本书的时候,推荐引擎会给你推荐相关的书籍,这个推荐的重要性远远超过了网站首页对该用户的综合推荐。可以看到,在这种情况下,Item CF 的推荐成为了引导用户浏览的重要手段。同时 Item CF 便于为推荐做出解释,在一个非社交网络的网站中,给某个用户推荐一本书,同时给出的解释是某某和你有相似兴趣的人也看了这本书,这很难让用户信服,因为用户可能根本不认识那个人;但如果解释说是因为这本书和你以前看的某本书相似,用户可能就觉得合理而采纳了此推荐。
相反的,在现今很流行的社交网络站点中,User CF 是一个更不错的选择,User CF 加上社会网络信息,可以增加用户对推荐解释的信服程度。
(2)、ALS算法工作原理
ALS算法是2008年以来,用的比较多的协同过滤算法。它已经集成到Spark的Mllib库中,使用起来比较方便。
从协同过滤的分类来说,ALS算法属于User-Item CF,也叫做混合CF。它同时考虑了User和Item两个方面。
用户和商品的关系,可以抽象为如下的三元组:<User,Item,Rating>。其中,Rating是用户对商品的评分,表征用户对该商品的喜好程度。
假设我们有一批用户数据,其中包含m个User和n个Item,则我们定义Rating矩阵,其中的元素表示第u个User对第i个Item的评分。
在实际使用中,由于n和m的数量都十分巨大,因此R矩阵的规模很容易就会突破1亿项。这时候,传统的矩阵分解方法对于这么大的数据量已经是很难处理了。
另一方面,一个用户也不可能给所有商品评分,因此,R矩阵注定是个稀疏矩阵。矩阵中所缺失的评分,又叫做missing item。
为了更好的实现推荐系统,我们需要对这个稀疏的矩阵建模。一般可以采用矩阵分解(或矩阵补全)的方式。
具体就是找出两个低维度的矩阵,使得它们的乘积是原始的矩阵。因此这也是一种降维技术。假设我们的用户和物品数目分别是U和I,那对应的“用户-物品”矩阵的维度为U×I,如下图所示: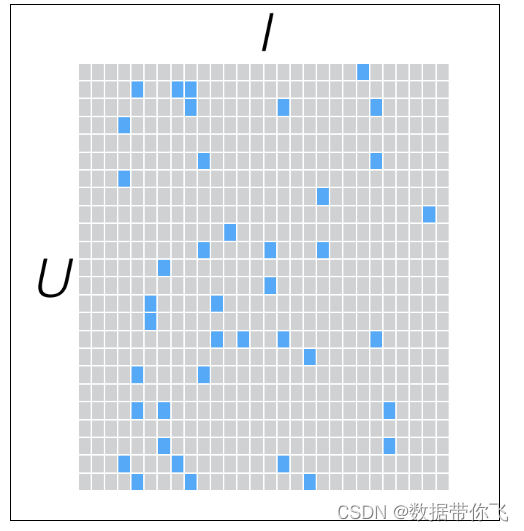
要找到和“用户-物品”矩阵近似的k维(低阶)矩阵,最终要求出如下两个矩阵:一个用于表示用户的U×k维矩阵,以及一个表征物品的k×I维矩阵。这两个矩阵也称作因子矩阵。它们的乘积便是原始评级矩阵的一个近似。值得注意的是,原始评级矩阵通常很稀疏,但因子矩阵却是稠密的(满秩的),如下图所示: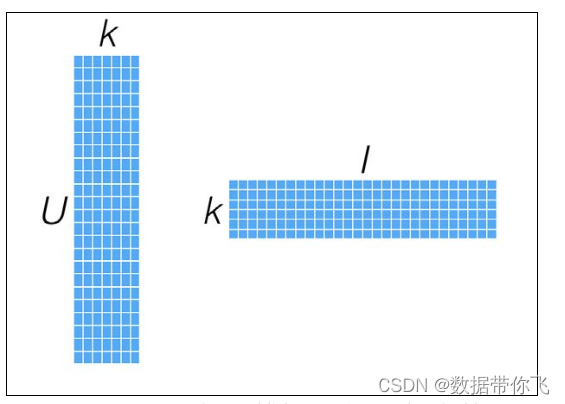
这类模型试图发现对应“用户-物品”矩阵内在行为结构的隐含特征(这里表示为因子矩阵),所以也把它们称为隐特征模型。隐含特征或因子不能直接解释,但它可能表示了某些含义,比如对电影的某个导演、种类、风格或某些演员的偏好。
k隐藏因子的取值有一定的约束:
1.k一般是低阶,小于u和I
2.生产环境中,k的取值范围一般是10~50,不宜过小或是过大,如果k过大,会导致计算代价增大
由于是对“用户-物品”矩阵直接建模,用这些模型进行预测也相对直接:要计算给定用户对某个物品的预计评级,就从用户因子矩阵和物品因子矩阵分别选取相应的行(用户因子向量)与列(物品因子向量),然后计算两者的点积即可。如下图所示: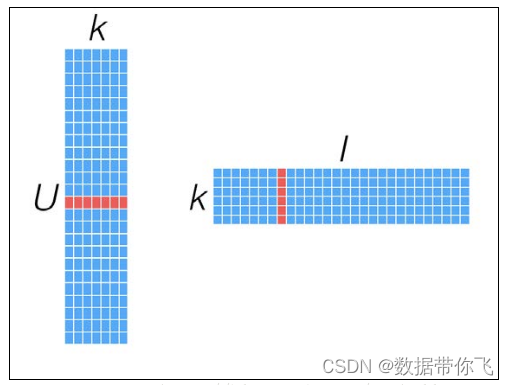
而对于物品之间相似度的计算,可以用最近邻模型中用到的相似度衡量方法。不同的是,这里可以直接利用物品因子向量,将相似度计算转换为对两物品因子向量之间相似度的计算,如下图所示: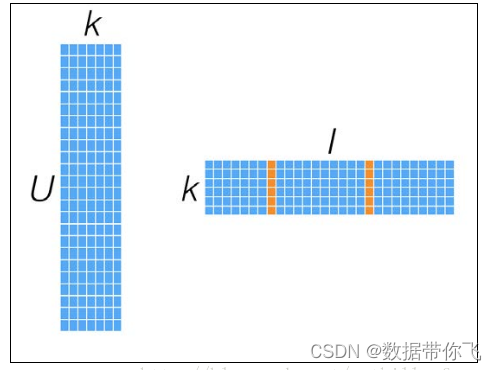
因子分解类模型的好处在于,一旦建立了模型,对推荐的求解便相对容易。所以这类模型的表现通常都很出色。但弊端可能在于因子数量的选择有一定困难,往往要结合具体业务和数据量来决定。一般来说,因子的取值范围在10~200之间。注意:k越大,其计算复杂度越高
(3)、ALS算法输入的参数
参数一: 训练集(rating)
用户对我们这件商品的评分,用户点击了这件商品,我们就给一个评分,然后点击了这个商品的下一步又是多少评分,订单又是多少分,还有访问步长也有加权分,访问时常也有加权分,到最后付款,一共1分.
每一步的评分其实就是一个权重.也可以理解为用户对商品合适程度,喜好程度.用户和商品就组成了一个矩阵,只要用户点击了商品,就对这个商品有个评分了,而有的却没有点击,它是空白的,我们要做的就是填充这些空白,在空白处根据之前的权重预测一个评分.然后推荐.
假如预测分和真是分不匹配,我们就优化参数,线上观察效果,再优化权重分,参数.
训练集是用户,物品,评分.,是一个double类型
参数二: 特征值
给一个特征值,也是double类型的,可以很多参数,可以很少,这个是模型了,看你的模型设计了,如0.1,然后矩阵与特征相乘,所有的特征值与矩阵相乘的分相加,就得到了一个预测分.
假如预测分与实际分不同的话, 那就是特征值给的有问题了,可以修改特征值参数,直到和预测分类似即可.这就是那些算法工程师一直线上看效果,然后调参数了
参数三: 迭代参数(numIterations)
这个参数是让模型趋近于平稳,也是一个double值,也就是它的标准差越来越平稳,迭代之后会产生一个预测分,((预测分-真实分)的平方+预测分) / n 在发个方,这就是标准差,只要标准差越来越平稳,也就是收敛,就这OK了,.迭代参数就好了
参数四: 防过拟合参数
这个参数也是一个和double值,过拟合比如给机器看一个红色的苹果,突然给一张青色的苹果让它识别, 它就不认识这是一个苹果了,就是为了满足尽可能复杂的任务,我们给它的一个参数. 不妨参数的话,他就像一个单调函数,无法涵盖所有的点,而我们的目的就是为了涵盖大多数的点,如下图所示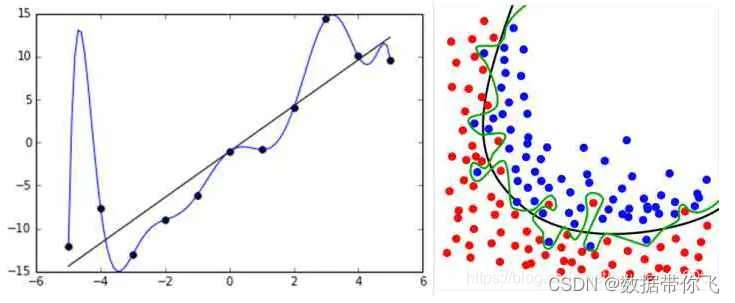
2、创建Maven工程,添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.12</artifactId>
<version>3.1.2</version>
</dependency>
3、代码实现
publicstaticvoidmain(String[] args){SparkConf sparkConf =newSparkConf().setAppName("JavaWordCount").setMaster("local[*]");JavaSparkContext sc =newJavaSparkContext(sparkConf);
sc.setLogLevel("WARN");JavaRDD<String> stringJavaRDD = sc.textFile("spark_demo/flies/ratings.dat");JavaRDD<Rating> ratingJavaRDD = stringJavaRDD.map(x ->{String[] attrs = x.split("::");returnnewRating(Integer.parseInt(attrs[0]),Integer.parseInt(attrs[1]),Double.parseDouble(attrs[2]));});//设置训练集、测试集JavaRDD<Rating>[] splitsRDD = ratingJavaRDD.randomSplit(newdouble[]{0.8,0.2});//设置隐含因子、迭代次数、和lamda因子,防止过拟合MatrixFactorizationModel model = org.apache.spark.mllib.recommendation.ALS.train(splitsRDD[0].rdd(),10,5,0.01);//预测System.out.println(model.predict(1,100));//推荐5个产品Rating[] ratings = model.recommendProducts(1,5);for(Rating rate : ratings){System.out.println(rate);}}
版权归原作者 数据带你飞 所有, 如有侵权,请联系我们删除。