
如有错误,敬请谅解!
此文章仅为本人学习笔记,仅供参考,如有冒犯,请联系作者删除!!
我们在学习selenium模块的时候,经常会用到 browser.find_element_by_id命令,但随着selenuim版本更新,我们会发现运行时会报错,非常苦恼。
示例:
from selenium import webdriver
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'https://www.baidu.com'
browser.get(url)
button = browser.find_element_by_id('su')
print(button)
错误如下:
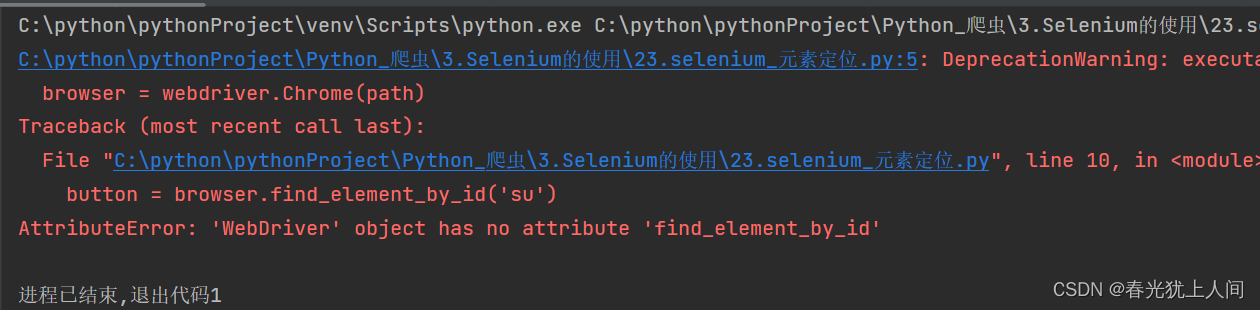
点击运行后报错:AttributeError: 'WebDriver' object has no attribute 'find_element_by_id'
'WebDriver'没有find_element_by_id这个方法
我们发现,finde_element这个方法有,所以可以尝试换一种方法改写上述代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'https://www.baidu.com'
browser.get(url)
button = browser.find_element(By.ID,'su')
print(button)
可以发现只是改变了这两句:
from selenium.webdriver.common.by import By
button = browser.find_element(By.ID,'su')
如果自己的版本是最新的版本,那么很有可能这种方法已经不用了,可以去查看一下官方的文档,或者直接查看配置文件,对自己的代码进行修改。
以下是更新之后常见的的用法(使用前需引用:from selenium.webdriver.common.by import By):
根据xpath选择元素
driver.find_element(By.XPATH, '//*[@id="kw"]')
根据css选择器选择元素
driver.find_element(By.CSS_SELECTOR, '#kw')
根据name属性值选择元素
driver.find_element(By.NAME, 'wd')
根据类名选择元素
driver.find_element(By.CLASS_NAME, 's_ipt')
根据链接文本选择元素
driver.find_element(By.LINK_TEXT, 'hao123')
根据包含文本选择
driver.find_element(By.PARTIAL_LINK_TEXT, 'hao')
根据标签名选择
目标元素在当前html中是唯一标签或众多标签第一个时候使用
driver.find_element(By.TAG_NAME, 'title')
根据id选择
driver.find_element(By.ID, 'su')
如有错误,请联系作者删除
并恳请同行朋友予以斧正,万分感谢!
本文转载自: https://blog.csdn.net/m0_54803732/article/details/130774963
版权归原作者 春光犹上人间 所有, 如有侵权,请联系我们删除。
版权归原作者 春光犹上人间 所有, 如有侵权,请联系我们删除。