
- 💂 个人网站:【海拥】【摸鱼游戏】【神级源码资源网】
- 🤟 前端学习课程:👉【28个案例趣学前端】【400个JS面试题】
- 💅 想寻找共同学习交流、摸鱼划水的小伙伴,请点击【摸鱼学习交流群】
此脚本从给定的网页中检索所有链接,并将其保存为
txt
文件。(文末有完整源码)
这是一个简单的网络爬虫示例,使用了 requests 库来发送 HTTP 请求并获取网页内容,使用 BeautifulSoup 库来解析网页内容。
代码解释如下:
1.导入所需的库
导入 requests 库并将其重命名为 rq,用于发送 HTTP 请求和获取网页内容。
import requests as rq
从 bs4 库导入 BeautifulSoup 类,用于解析 HTML 内容。
from bs4 import BeautifulSoup
2.获取用户输入的链接
提示用户输入一个链接,并将其保存在 url 变量中。
url =input("Enter Link: ")
3.发送 HTTP 请求获取网页内容
- 使用条件语句判断用户输入的链接是否以 “
https” 或 “http” 开头。 - 如果是,则使用
rq.get(url)发送 GET 请求获取网页内容,并将响应保存在 data 变量中。 - 如果不是,则在链接前添加 “https://” 并使用
rq.get()发送请求,将响应保存在 data 变量中。
4.使用 BeautifulSoup 解析网页内容
将 data.text(网页内容)传递给 BeautifulSoup 类的构造函数,指定解析器为 “html.parser”,创建一个 BeautifulSoup 对象 soup。
soup = BeautifulSoup(data.text,"html.parser")
5.提取链接
- 创建一个空列表 links 用于存储提取的链接。
- 使用 soup.find_all(“a”) 查找网页中所有的
<a>标签,并返回一个包含这些标签的列表。 - 遍历列表中的每个标签,使用 link.get(“href”) 获取每个标签中的 “href” 属性值,并将其添加到 links 列表中。
6.将提取的链接写入文件
- 使用
with open("myLinks.txt", 'a') as saved: 打开一个文件 “myLinks.txt”,以追加模式。 - 使用
print(links[:100], file=saved)将 links 列表中的前 100 个链接写入文件中,每个链接占一行。 - 如果需要每次覆盖文件内容而不是追加,可以将文件打开模式由 ‘a’ 改为 ‘w’。
这段代码的功能是获取用户输入的链接对应网页中的前 100 个链接,并将这些链接写入到名为 “myLinks.txt” 的文件中。
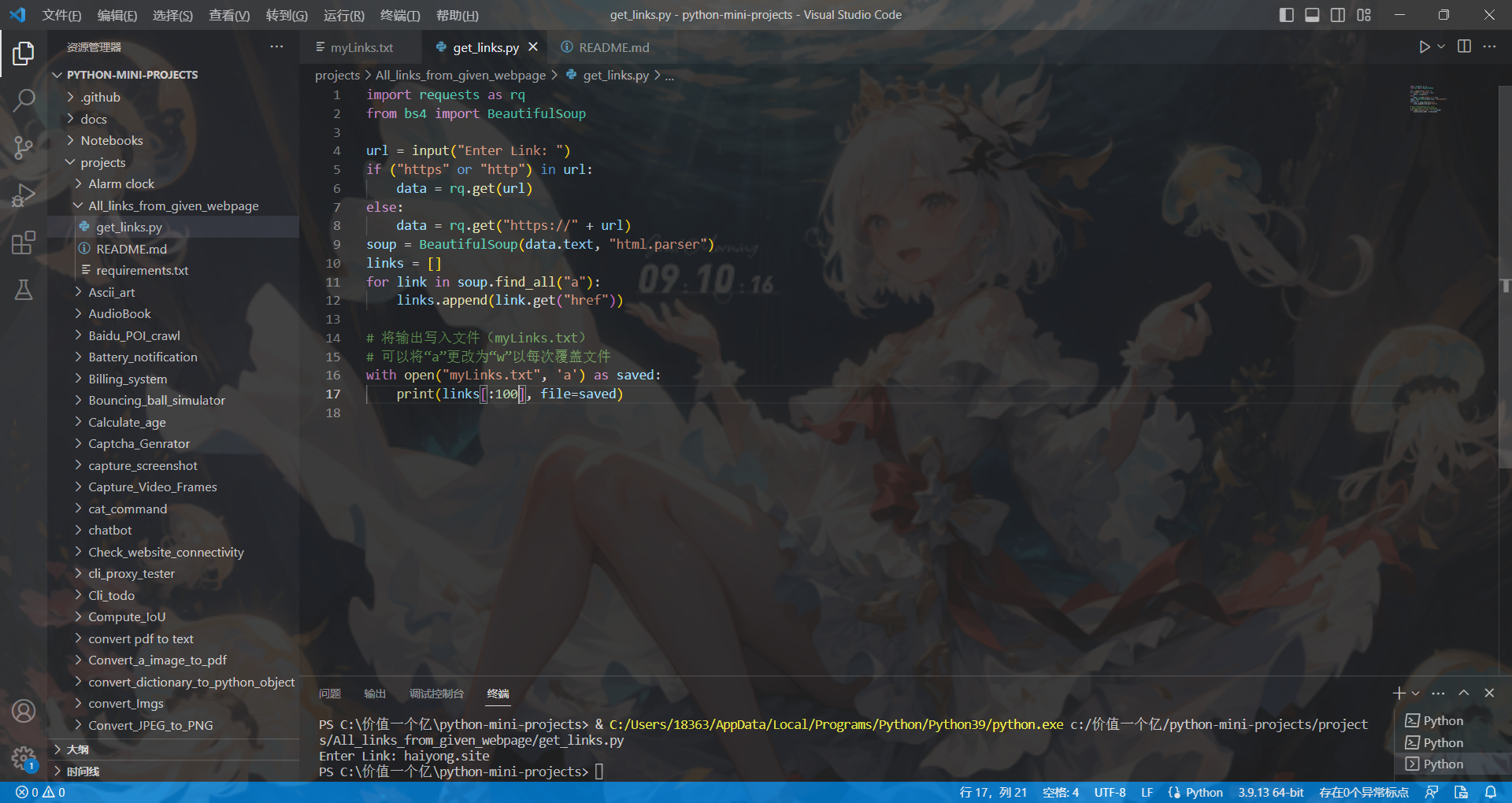
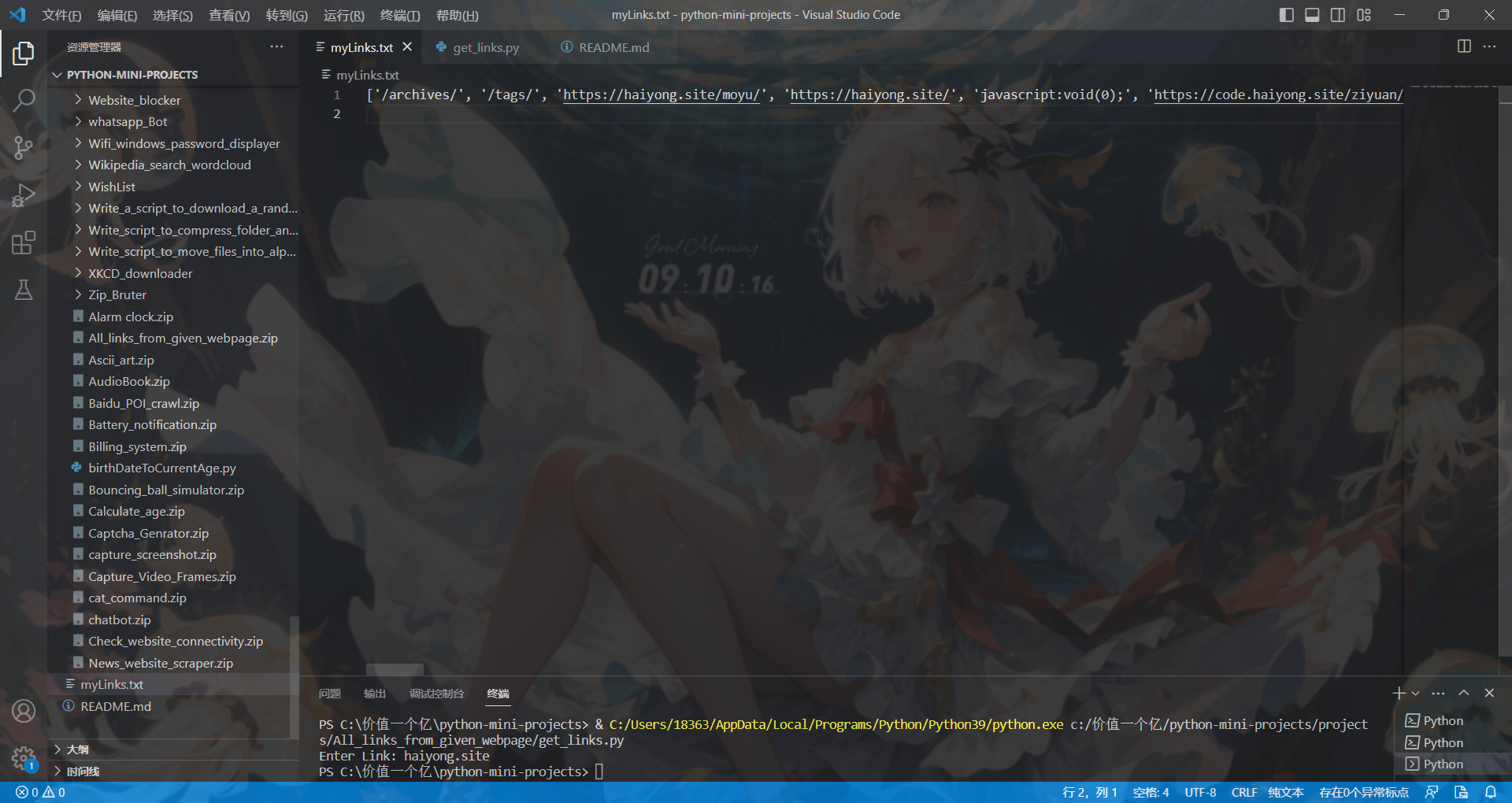
运行截图
好书推荐
《速学Python:程序设计从入门到进阶》

《速学Python:程序设计从入门到进阶》面向没有任何编程基础的初学者。全书共9章,第1、2章以尽可能少的篇幅,完成了对编程环境的搭建、编程的基本概念、Python语法、数据结构、面向对象编程技巧的讲述,这一部分内容虽然简单,但它对初学者非常重要,只有完成这一部分内容的学习,才能够继续深入。
📚 京东自营购买链接:《速学Python:程序设计从入门到进阶》
附完整代码
import requests as rq
from bs4 import BeautifulSoup
url =input("Enter Link: ")if("https"or"http")in url:
data = rq.get(url)else:
data = rq.get("https://"+ url)
soup = BeautifulSoup(data.text,"html.parser")
links =[]for link in soup.find_all("a"):
links.append(link.get("href"))# 将输出写入文件(myLinks.txt)# 可以将“a”更改为“w”以每次覆盖文件withopen("myLinks.txt",'a')as saved:print(links[:10],file=saved)
本文转载自: https://blog.csdn.net/qq_44273429/article/details/130725692
版权归原作者 海拥✘ 所有, 如有侵权,请联系我们删除。
版权归原作者 海拥✘ 所有, 如有侵权,请联系我们删除。