

作者:娜米
本文整理于 2024 年云栖大会阿里云智能集团产品专家张凤婷带来的主题演讲《云消息队列 Kafka 版全面升级:经济、弹性、稳定》
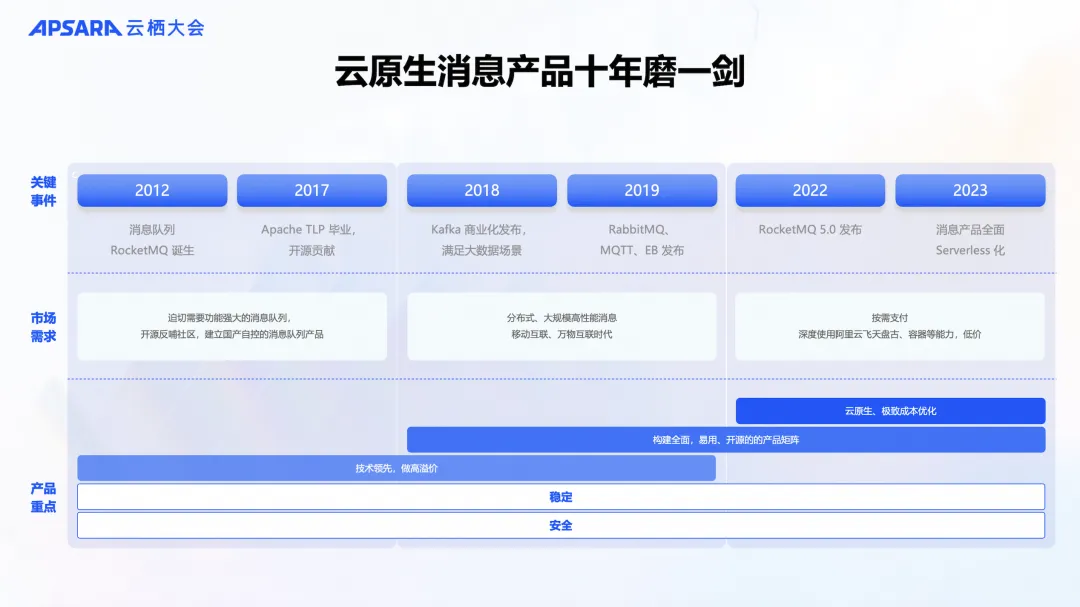
云原生消息产品十年磨一剑
消息产品的演进可以大致分为三个主要阶段:
- 起步阶段: 初期,市场上缺乏能够支撑大规模业务场景的优秀消息产品,无论是商业化还是开源产品。阿里巴巴的消息产品诞生于淘宝核心交易链路,服务于当时世界上最大的交易系统之一,在场景适应性、性能、扩展性等方面都经受了严苛的考验。因此,消息队列团队推出了 RocketMQ 的开源和商业化产品,并迅速在技术领域占据领先地位。
- 大数据阶段: 随着 MapReduce、Hadoop、Spark、Hbase 等开源大数据工具的发布,大数据计算变得更容易和低成本。随之,企业业务架构向数据驱动架构转型。为了适应这一趋势,消息队列团队陆续发布了 Kafka、RabbitMQ、MQTT 等多款产品,基于丰富的开源消息生态,构建了一个完整的商业化消息产品矩阵,以满足多样化的业务场景。
- 云计算阶段: 云计算成为行业共识,云基础设施日益成熟。云服务的核心价值在于成本效益,因此,消息队列团队致力于让客户以更低的成本使用云上的消息产品。通过充分利用云服务,如容器服务、飞天盘古等的产品能力,云消息队列 ApsaraMQ (阿里云消息队列产品品牌)全系列产品均实现了 Serverless 架构,以达到成本极致优化。
降本是持续的技术方向
为了持续优化成本,云消息队列 Kafka 版(阿里云消息队列的 Kafka 商业化产品)不仅是简单地给予让利,而是通过架构层面的深度优化,实现客户使用成本的降低。
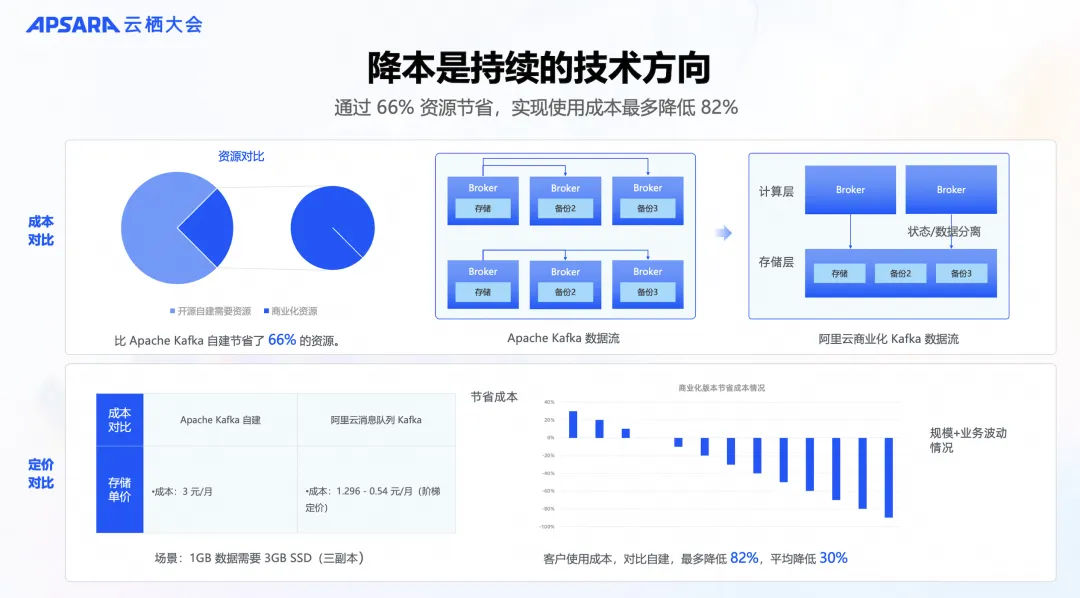
与 Apache Kafka 相比,云消息队列 Kafka 版通过节省 66% 的资源,实现客户使用成本比自建最多降低 82%, 这是如何实现的呢?
我们来看 Apache Kafka 的数据流,在传统的三备份复制模式下,无论计算还是存储,都需要三份复制来确保系统的高可用。然而,这种设计最初是为了在 IDC 环境中实现高可靠性和可用性的,在高 SLA 的云环境中,就会导致资源冗余。因此,云消息队列 Kafka 版通过架构升级,实现了计算与存储的完全分离,而不是简单的二级存储。
在计算层面,云消息队列 Kafka 版通过存算分离,将计算与存储剥离,实现了计算节点的无状态和互为主备。在存储层面,与 Apache Kafka 不同的是,云消息队列 Kafka 版的存储层采用了成熟产品化的飞天盘古存储产品,支持百万级客户,并且充分利用了云盘的三份复制功能。
因此,云消息队列 Kafka 版在计算层面只需要使用三分之一的机器资源,在存储层面也只需要三分之一的存储空间,就能实现与 Apache Kafka 相似的功能。
消息队列架构演进
在云消息队列 Kafka 版的产品演进过程中,我们不仅注重成本优化,而是致力于实现经济性、稳定性和弹性的三大核心目标。
- 经济性: 我们持续改进定价策略以适应市场趋势。起初,市场上缺乏优秀的消息产品,为了更好地提供高级功能,我们的定价策略需要覆盖研发成本。随着开源消息生态的发展,我们调整定价模型,以降低使用成本,与自建运维成本相持平。目前,我们通过优化成本结构,将使用成本降至与自建机器成本相当的水平,无需额外的人力投入。通过减少预留资源和增加资源弹性,云消息队列 Kafka 版实现了 Serverless 架构,客户使用成本比自建平均降低 30%,为客户提供了更具成本效益的消息产品。
- 稳定性: 我们致力于增强系统的稳定性。服务水平协议(SLA)通常确保产品在正常运行时的稳定性。然而,对于云消息队列 Kafka 版,我们的 SLA 不仅确保系统稳定运行,还特别关注在运维、扩缩容和弹性等操作中的稳定性。专业版支持多可用区故障无损切换;同时 Serverless 系列支持在两倍弹性范围内进行无感扩展,目前也支持定时弹性无限(最大到 50GB/s 的规格)弹性,解决秒杀场景的冷启动弹性问题。后面规划可以做到自适应弹性,跟随流量增长,动态扩容,支持数倍的弹性。确保用户体验的流畅性和服务的可靠性。
- 弹性: 我们注重提升效率。Apache Kafka 作为一个有状态的产品,在扩容和缩容过程中可能会耗费较长时间。尤其面对大规模业务,Apache Kafka Broker 有状态的特点导致了扩容缓慢、缩容困难的问题。云消息队列 Kafka 版从设计之初就追求在有状态背景下,实现快速、顺畅地扩容和缩容。目前,则更进一步追求,在保持系统稳定性的同时,实现更快速的弹性。通过存算分离、状态下推、并行升级、预留资源池等技术,云消息队列 Kafka 版实现了秒级弹性,而开源自建扩容要小时甚至天的时间。
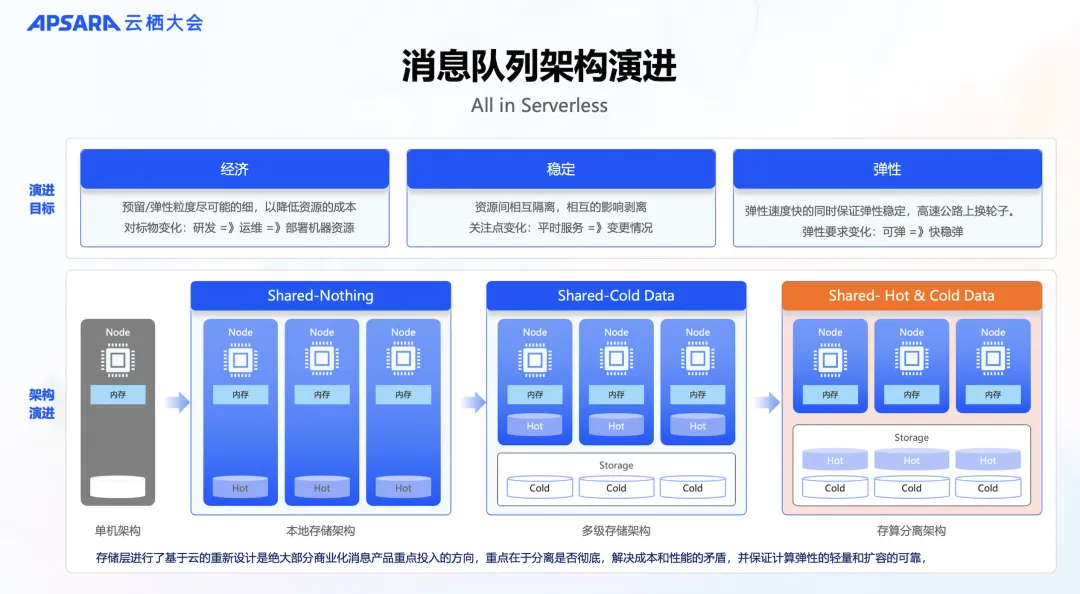
综上所述,云消息队列 Kafka 版架构演进的核心目标,是平衡成本与性能,并确保弹性和可靠性。同样,这也是整个消息生态系统架构发展的趋势。
随着单机架构的淘汰,目前市场上主要采用以下三种架构:
- 本地存储架构: 这是 Apache Kafka 的开源架构。
- 多级存储架构: 尽管 Apache Kafka 也提出了该架构,但目前还不够成熟。许多云厂商也采用这种架构,因为它易于部署,投入较少的资源就能够适配不同云厂商的环境,但并没有专为某个云厂商进行深度优化。而且,这种架构还存在存算分离不彻底、热盘爆盘、数据丢失以及 HA 瓶颈等问题。
- 存算分离架构: 这是目前的最优选择,真正实现了计算层的完全无状态,有助于提高弹性过程中的稳定性、效率和数据可靠性。
存算分离架构是 Serverless 架构的最优选择
在云消息队列 Kafka 版的架构演进的过程中,重点在于重新设计存储层。我们的目标是确保计算层和存储层的状态剥离得足够彻底,并在此基础上解决成本、性能、稳定性和弹性效率之间的矛盾。
为什么说存算分离架构是目前的最优选择?以下是几个关键考量点:
- 冷热数据的运维问题: 在多级存储系统中,冷热数据管理至关重要。资源预留不足可能导致爆盘,影响写入操作,但资源预留实际是与 Serverless 架构理念相悖的。同时,由于多级存储涉及多种产品,增加了运维复杂性,因此,冷热数据运维通常应由成熟产品而非个人负责。
- 热数据灾备切换问题: 在多级存储系统中,需要考虑计算和热盘绑定的问题。热盘是架构中有状态的部分,Broker 并不是独立存在的,因此在进行 HA 切换时,如何保证不丢数据,保证 HA 的效率是一个关键问题。
- 热盘机型切换问题: 尽管存在热盘挂载的技术,但其尚未被大规模应用,成熟度还没有得到保证。同时,支持该技术的机型数量很有限,相关成本也是一个考虑因素。
因此,简单的多级存储可能会掩盖很多潜在问题,在实际落地中隐藏了巨大的风险。所以,多级存储的进一步演进,是真正实现存算分离架构,确保数据不丢失、服务持续可用、快速实现 HA,并通过大规模验证。
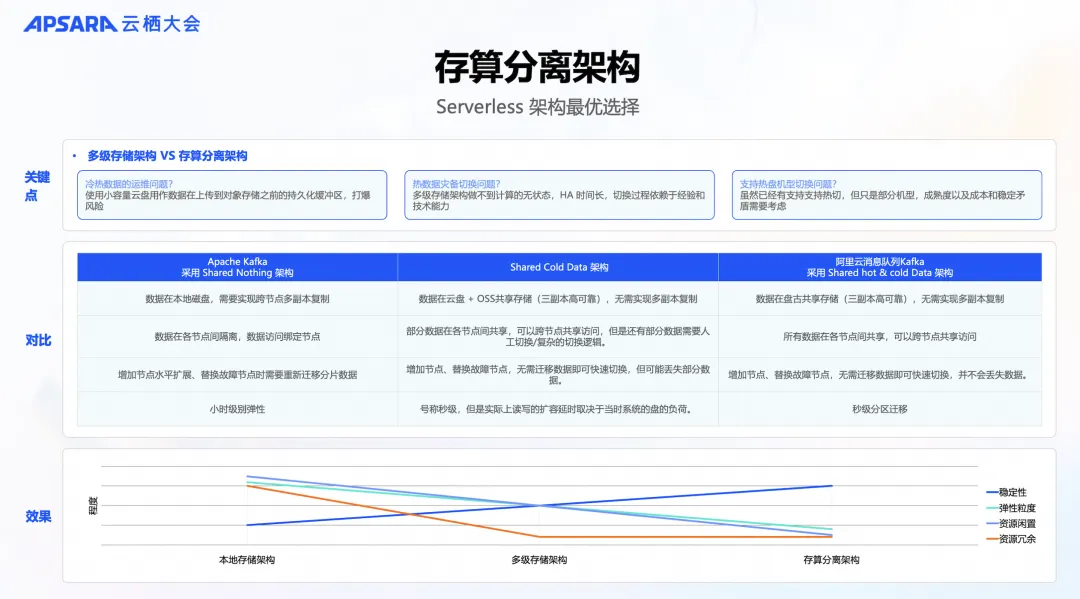
从以上关键点来比较三种架构:
- 本地存储架构: Apache Kafka 最被诟病的运维痛点,包括弹性时间长和资源冗余导致成本高。采用本地存储架构数据不共享,需要在计算层进行备份和复制,成本较高。由于数据并未剥离,扩容时需要数据迁移,导致扩容速度慢至小时甚至天级别,严重影响业务,有时还需要在数据丢失和稳定性之间进行取舍。
- 多级存储架构: 多级存储本身是个很棒的架构,在数据存储上有广泛的应用,但由消息产品直接实现该架构非最佳实践,可能会存在热盘规划、数据丢失、稳定性、服务持续性、运维投入、HA 速度等很多问题。非常考验代码的细节以及极端且广泛场景的验证。
- 存算分离架构: 从目前云产品和技术发展的进程看,存算分离架构是从根本上解决这些问题的最佳实践。
上面是效果比较的示意图,在稳定性、弹性、资源利用率方面,存算分离架构均表现最佳。因此,我们采取冷热数据共享,通过存算分离架构进行云消息队列 Kafka 版产品重构和演进。
Kafka 不仅仅是 Apache Kafka
接下来将通过一些实际例子,与大家分享存算分离架构带来的优势。
秒级弹性 & 扩容稳定性打磨
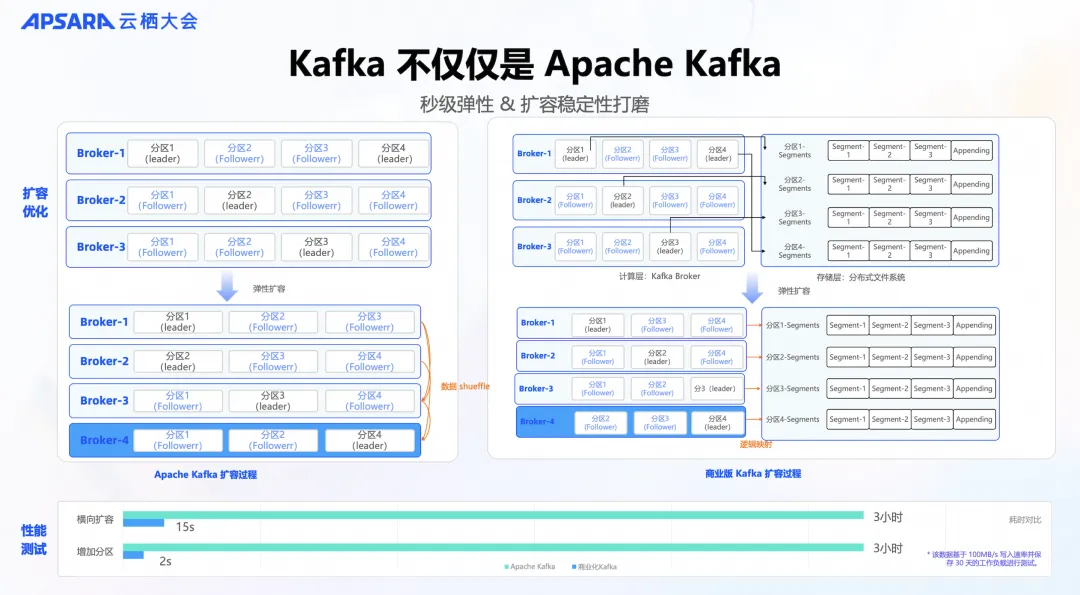
在扩容方面,Apache Kafka 需要进行数据的 shuffle。例如,假设有一个由 broker 1、2、3 组成的集群,当我们再加入一个 broker 4 时,不论是 leader 数据还是 follower 数据,都需要进行 shuffle。
相比之下,云消息队列 Kafka 版的扩容过程则更为简便,只需要添加一个计算的 broker,并进行逻辑映射,就可以开始读写操作,无需进行数据迁移。这种模式将数据迁移所需的线性增长时间转变为定量的扩容时间,从而减少了时间成本并提高了效率。
以下是一个示例,供参考。基于一个数据写入速率 100MB/s 并保存数据 30 天的工作负载进行测试,使用云消息队列 Kafka 版,无论是横向扩容还是增加分区,时间上都有了百倍到千倍的减少。 对于需要持续运行的业务场景来说,这是显著的优势。
故障切换,数据不丢
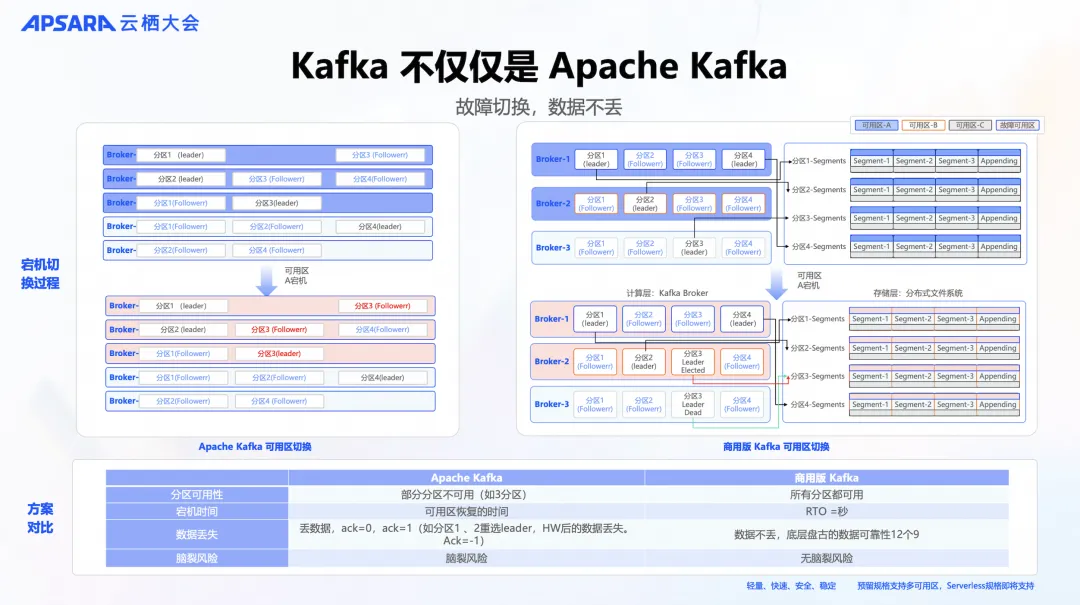
随着规模的增长,单点故障的概率也随之上升。因此,在 HA 场景下,必须考虑到数据快速切换且不丢失的问题,这是 Kafka HA 的关键点。
以 Apache Kafka 为例,当一个机房断网或不可用时,由于分区及其副本可能位于同一个可用区,这就可能直接导致不可用,例如下图的分区 3;如果设定高可用模式,Follower 数据可能尚未完成同步,导致部分分区数据丢失,例如下图的分区 1、2;在集群减少机器资源的情况下,选主后会尽快补齐 Follower,进一步加剧集群流量负担,甚至可能导致全集群的稳定性问题,例如下图的分区 1、2、3、4。因此,虽然理论上 Apache Kafka 可以跨越多个可用区部署,但在实际故障需要主备切换时,仍可能会出现部分分区完全不可用、宕机时间不可控的情况,还有数据丢失和脑裂的风险。
云消息队列 Kafka 版跨多个可用区部署计算和存储资源,当一个可用区不可用,不会对其他可用区产生任何影响。由于计算层面无状态且相互独立,存储层是多可用区容灾的,因此多可用区能够正常提供服务。同时,得益于阿里云飞天盘古存储系统的强大支持,经过大规模商业化验证,提供了 12个9 的数据可靠性和 5个9 的可用性。并且,通过优化选主算法,有效避免了 HA 场景中最令人担心的脑裂风险。
RT 性能量级提升
我们都知道,绝大多数时候,优化架构是远远不够的。实现落地的细节、各种场景的磨练以及商业化规模的打磨,都会影响整个产品的平稳与性能。
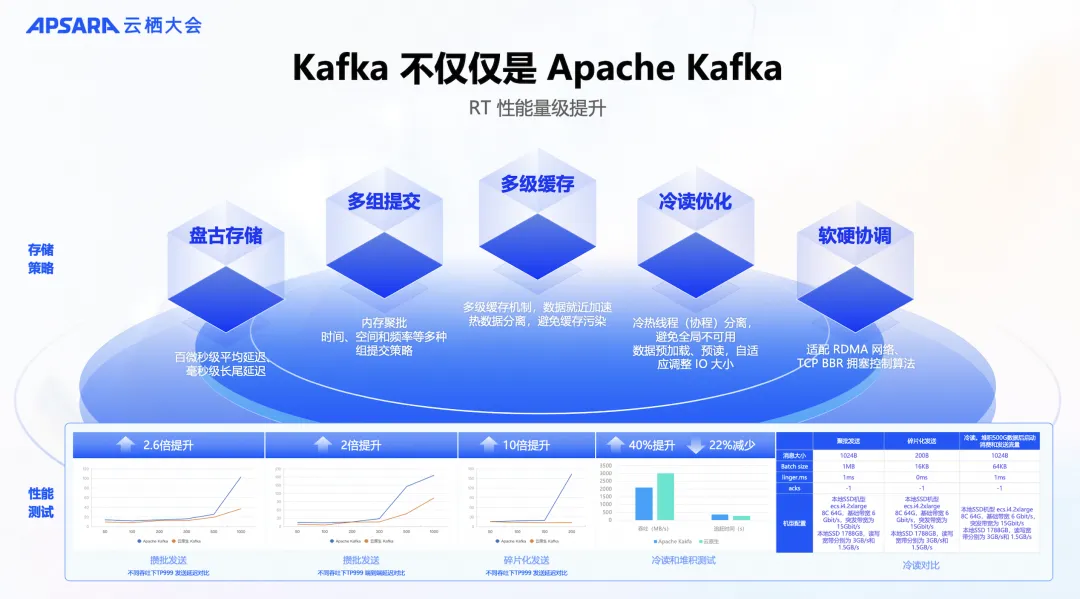
云消息队列 Kafka 版不仅优化了架构,在许多细节上也做了提升。接下来将重点介绍存储层的五个优化策略:
- 利用强大的云服务: 采用了飞天盘古存储系统,其性能非常高,能达到百微秒级平均延迟、毫秒级长尾延迟,同时提供了 12个9 的数据可靠性和 5个9 的可用性。
- 多组提交优化: 采取了多种内存聚批策略,包括时间、空间和频率等,优化多组提交。
- 多级缓存: 内存数据中采用了多级缓存机制,实现数据就近加速和热数据分离,避免缓存污染,从而提升整体性能。
- 冷读优化: 冷读是影响 Apache Kafka 稳定性的关键点,云消息队列 Kafka 版几年前就实现了冷热线程(协程)分离,近期又增强了数据预加载、预读和自适应调整 IO 大小等能力。
- 硬件优化: 云消息队列 Kafka 版还进行了一些硬件优化协调,去提升性能。
云消息队列 Kafka 版通过以上存储策略优化,无论是在攒批发送的端到端延迟、发送延迟、碎片化发送、冷读或者堆积的测试上,性能都得到显著提升。 下图是我们的实验数据和结果。
总的来说,云消息队列 Kafka 版并不仅仅是 Apache Kafka 的全托管产品,我们在整体架构和细节上不断打磨,在性能和稳定性方面持续深度优化,以满足客户对高性能、高稳定性的需求。
云消息队列 Kafka 版:追求极致,接近极致
云消息队列 Kafka 版不仅兼容开源协议,保留了开源产品的核心功能,更致力于为客户提供更加稳定可靠、高效灵活、成本效益更高的消息队列服务。
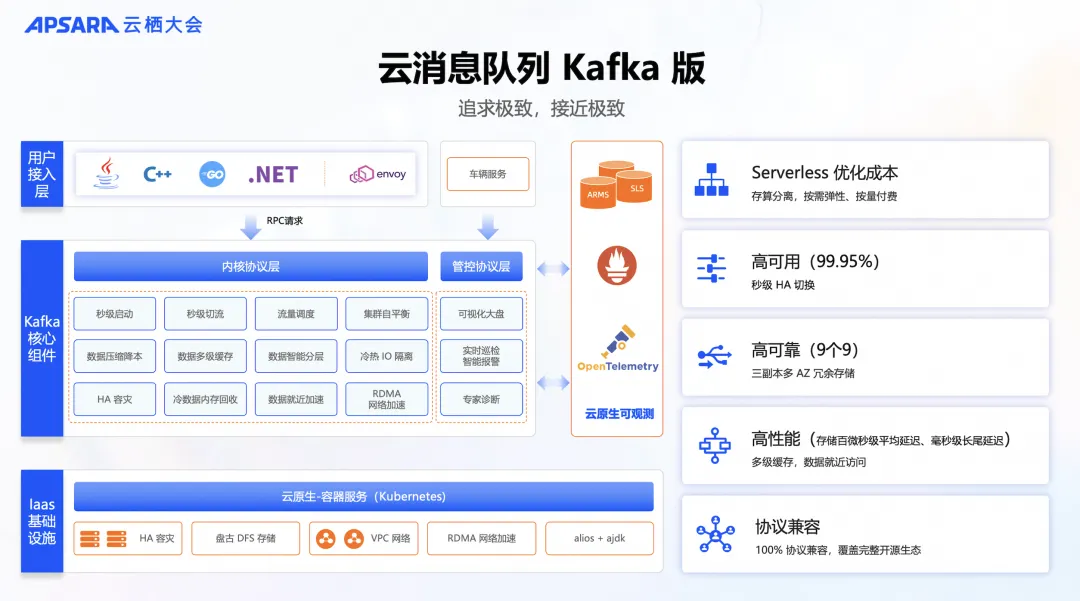
- 云消息队列 Kafka 版依托于阿里云成熟、强大的基础设施,如容器服务、飞天盘古存储系统、云服务器等经过大规模验证的产品,为整体性能和稳定性提供了坚实的基础。
- 内核层面,云消息队列 Kafka 版进行了彻底的重构,包括快速启动、数据自平衡和就近加速等,以确保系统的稳定性和数据传输的可靠性。
- 性能方面,云消息队列 Kafka 专注于提升数据处理速度,使用户能够更迅速地传输和处理数据。
- 云消息队列 Kafka 版在客户体验和功能可视化方面也进行了深度优化。提供完善的可视化大盘、实时监控和专家诊断等,使客户能够更直观地掌握系统的运行状况。
阿里云是 Confluent 中国大陆地区唯一的合作商
云消息队列 Kafka 版不仅提供开源 Apache Kafka 全托管的版本,还提供 Confluent 版。
Confluent 是 Kafka 商业化的领先企业,它提供了基于 Kafka 的消息平台 Confluent Platform,使得用户可以更轻松地构建、管理和监控实时数据流。
Confluent 可以理解为是一个搭积木的产品,Apache Kafka 只是内核。它的核心产品特性包括 Kafka Connector、KSQL 和 Schema Registry 等。Kafka Connector 允许用户轻松地集成 Confluent 平台与各种数据存储系统和应用程序,而 Kafka Cycle Management 则提供了一套工具和服务,让用户能够更轻松地管理和操作 Kafka 集群。此外,Schema Registry 允许用户注册和管理 Avro 模式,而 KSQL 则提供了一种 SQL 接口,使得用户可以使用 SQL 语句对实时数据进行处理和分析。
总之,Confluent 的商业化版本为客户提供了一站式的消息平台解决方案,帮助他们更轻松地构建和管理实时数据流。无论是连接、管理、数据格式还是数据分析,Confluent 都能满足需求,是构建实时数据架构的理想选择。
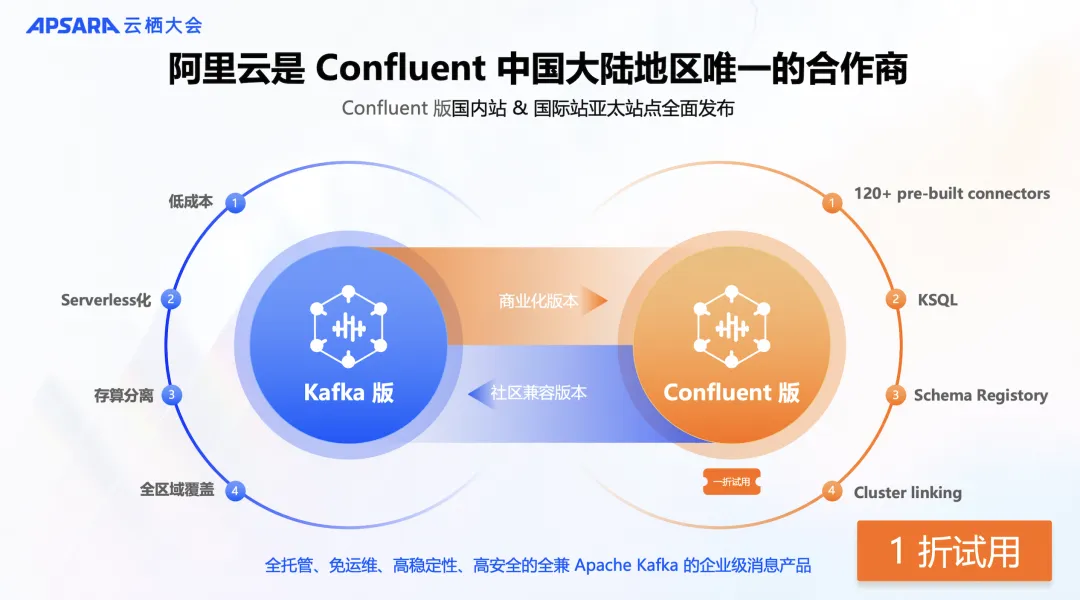
目前,阿里云是中国大陆地区唯一的一个合作商,已经在中国大陆地区核心区域,中国香港、新加坡、马来西亚等区域发布了云消息队列 Confluent 版,并提供新用户首月 1 折试用的优惠活动,欢迎大家体验。
云消息队列 Confluent 版官网:https://www.aliyun.com/product/aliware/alikafka/confluent
点击此处,观看本场直播回放。
版权归原作者 阿里云云原生 所有, 如有侵权,请联系我们删除。