
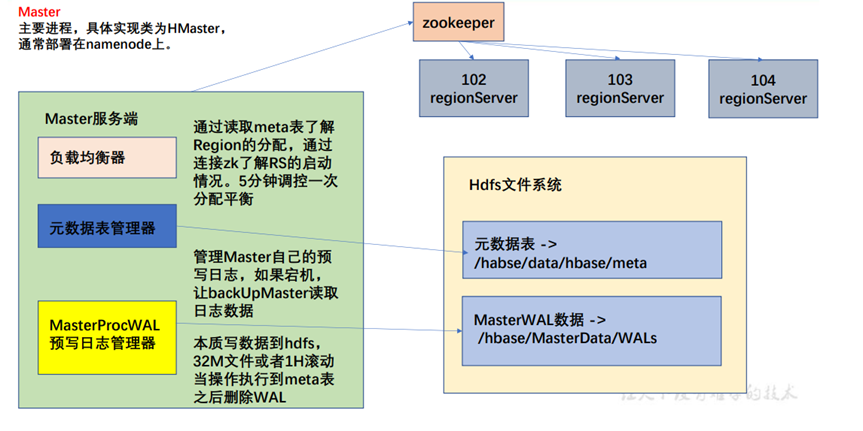
1 Master
1.1 Meta 表
- 全称 hbase:meta,只是在 list 命令中被过滤掉了,本质上和 HBase 的其他表格一样。
- RowKey:([table],[region start key],[region id]) 即 表名,region 起始位置和 regionID。
- 列: • info:regioninfo 为 region 信息,存储一个 HRegionInfo 对象。 • info:server 当前 region 所处的 RegionServer 信息,包含端口号。 • info:serverstartcode 当前 region 被分到 RegionServer 的起始时间。 • 如果一个表处于切分的过程中,即 region 切分,还会多出两列 info:splitA 和 info:splitB, 存储值也是 HRegionInfo 对象,拆分结束后,删除这两列。 注意: 在客户端对元数据进行操作的时候才会连接 master,如果对数据进行读写,直接连接 zookeeper 读取目录/hbase/meta-region-server 节点信息,会记录 meta 表格的位置。直接读 取即可,不需要访问 master,这样可以减轻 master 的压力,相当于 master 专注 meta 表的 写操作,客户端可直接读取 meta 表。 在 HBase 的 2.3 版本更新了一种新模式:Master Registry。客户端可以访问 master 来读取 meta 表信息。加大了 master 的压力,减轻了 zookeeper 的压力。
2 RegionServer
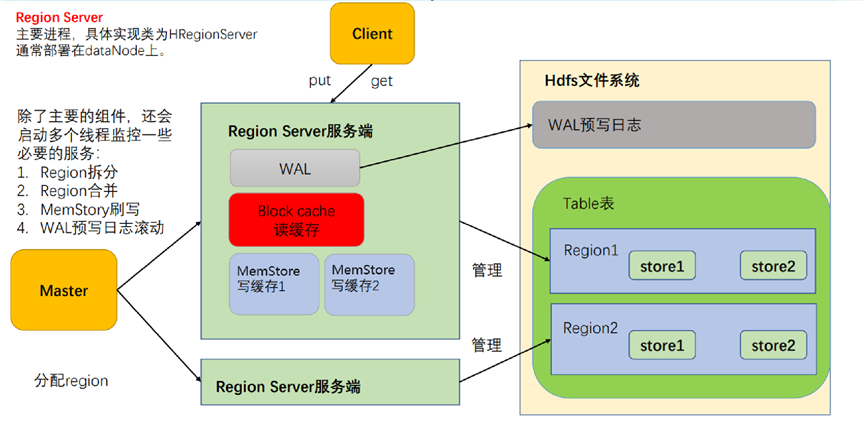
2.1 Memstore
写缓存,由于 HFile 中的数据要求是有序的,所以数据是先存储在 MemStore 中,排好 序后,等到达刷写时机才会刷写到 HFile,每次刷写都会形成一个新的 HFile,写入到对应的 文件夹 store 中。
2.2 WAL
由于数据要经 MemStore 排序后才能刷写到 HFile,但把数据保存在内存中会有很高的 概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做 Write-Ahead logfile 的文件 中,然后再写入 MemStore 中。所以在系统出现故障的时候,数据可以通过这个日志文件重 建。
2.3 BlockCache
读缓存,每次查询出的数据会缓存在 BlockCache 中,方便下次查询。
3 写流程
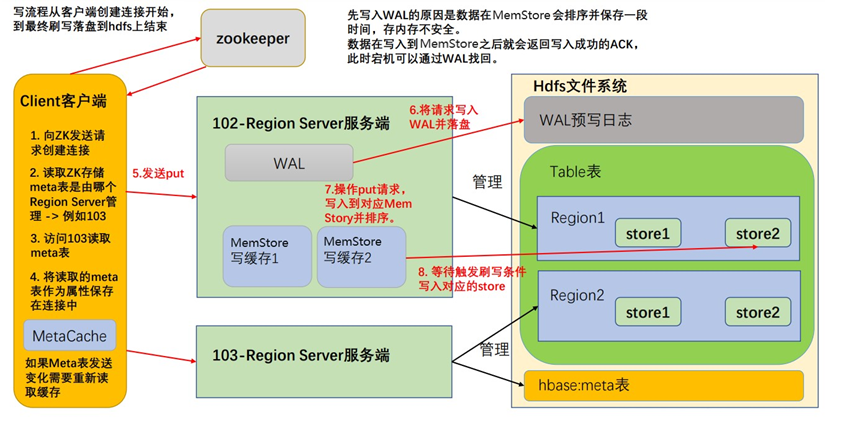
写流程顺序正如 API 编写顺序,首先创建 HBase 的重量级连接
- 首先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server;
- 访问对应的 Region Server,获取 hbase:meta 表,将其缓存到连接中,作为连接属性 MetaCache,由于 Meta 表格具有一定的数据量,导致了创建连接比较慢;之后使用创建的连接获取 Table,这是一个轻量级的连接,只有在第一次创建的时候会检查表格是否存在访问 RegionServer,之后在获取 Table 时不会访问 RegionServer;
- 调用Table的put方法写入数据,此时还需要解析RowKey,对照缓存的MetaCache,查看具体写入的位置有哪个 RegionServer;
- 将数据顺序写入(追加)到 WAL,此处写入是直接落盘的,并设置专门的线程控制 WAL 预写日志的滚动(类似 Flume);
- 根据写入命令的 RowKey 和 ColumnFamily 查看具体写入到哪个 MemStore,并且在 MemStore 中排序;
- 向客户端发送 ack;
- 等达到 MemStore 的刷写时机后,将数据刷写到对应的 store 中。
4 MemStore Flush
MemStore 刷写由多个线程控制,条件互相独立:
主要的刷写规则是控制刷写文件的大小,在每一个刷写线程中都会进行监控
- 当某个 memstroe 的大小达到了 hbase.hregion.memstore.flush.size(默认值 128M), 其所在 region 的所有 memstore 都会刷写。当 memstore 的大小达到了 hbase.hregion.memstore.flush.size(默认值 128M) * hbase.hregion.memstore.block.multiplier(默认值 4) 时,会刷写同时阻止继续往该 memstore 写数据(由于线程监控是周期性的,所有有可能面 对数据洪峰,尽管可能性比较小)
- 由 HRegionServer 中的属性 MemStoreFlusher 内部线程 FlushHandler 控制。标准为 LOWER_MARK(低水位线)和 HIGH_MARK(高水位线),意义在于避免写缓存使用过多的内存造成 OOM。 • 当 region server 中 memstore 的总大小达到低水位线 java_heapsize *hbase.regionserver.global.memstore.size(默认值 0.4) *hbase.regionserver.global.memstore.size.lower.limit(默认值 0.95), region 会按照其所有 memstore 的大小顺序(由大到小)依次进行刷写。直到 region server 中所有 memstore 的总大小减小到上述值以下。 • 当 region server 中 memstore 的总大小达到高水位线 java_heapsize *hbase.regionserver.global.memstore.size(默认值 0.4) 时,会同时阻止继续往所有的 memstore 写数据。
- 为了避免数据过长时间处于内存之中,到达自动刷写的时间,也会触发 memstore flush。由 HRegionServer 的属性 PeriodicMemStoreFlusher 控制进行,由于重要性比较低,5min才会执行一次。 自动刷新的时间间隔由该属性进行配置 hbase.regionserver.optionalcacheflushinterval(默认 1 小时)。
- 当 WAL 文件的数量超过 hbase.regionserver.max.logs,region 会按照时间顺序依次 进行刷写,直到 WAL 文件数量减小到 hbase.regionserver.max.log 以下(该属性名已经废弃, 现无需手动设置,最大值为 32)。
5 读流程
5.1 HFile结构
在了解读流程之前,需要先知道读取的数据是什么样子的。
HFile 是存储在 HDFS 上面每一个 store 文件夹下实际存储数据的文件。里面存储多种内容。包括数据本身(keyValue 键值对)、元数据记录、文件信息、数据索引、元数据索引和 一个固定长度的尾部信息(记录文件的修改情况)。
键值对按照块大小(默认 64K)保存在文件中,数据索引按照块创建,块越多,索引越 大。每一个 HFile 还会维护一个布隆过滤器(就像是一个很大的地图,文件中每有一种 key, 就在对应的位置标记,读取时可以大致判断要 get 的 key 是否存在 HFile中)。
KeyValue 内容如下:
rowlength -----------→ key 的长度
row -----------------→ key 的值
columnfamilylength --→ 列族长度
columnfamily --------→ 列族
columnqualifier -----→ 列名
timestamp -----------→ 时间戳(默认系统时间)
keytype -------------→ Put
由于 HFile 存储经过序列化,所以无法直接查看。可以通过 HBase 提供的命令来查看存 储在 HDFS 上面的 HFile 元数据内容。
bin/hbase hfile -m -f /hbase/data/命名 空间/表名/regionID/列族/HFile 名
5.2 读流程
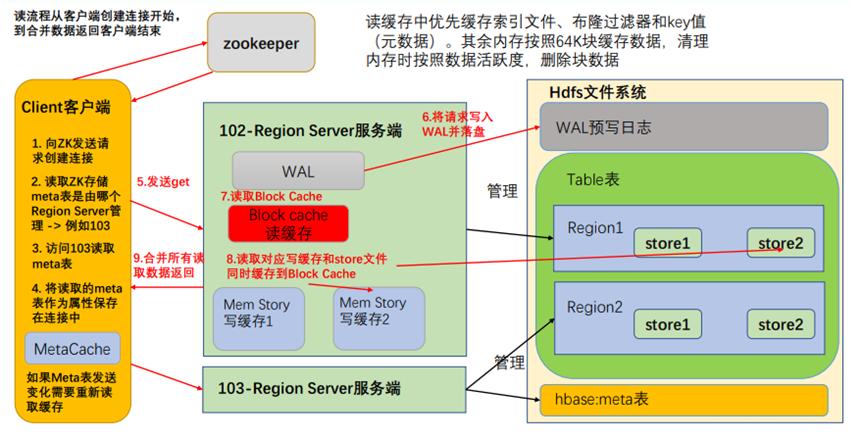
- 首先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server;
- 访问对应的 Region Server,获取 hbase:meta 表,将其缓存到连接中,作为连接属性 MetaCache,由于 Meta 表格具有一定的数据量,导致了创建连接比较慢;之后使用创建的连接获取 Table,这是一个轻量级的连接,只有在第一次创建的时候会检查表格是否存在访问 RegionServer,之后在获取 Table 时不会访问 RegionServer;
- 创建 Table 对象发送 get 请求。
- 优先访问 Block Cache,查找是否之前读取过,并且可以读取 HFile 的索引信息和 布隆过滤器。
- 不管读缓存中是否已经有数据了(可能已经过期了),都需要再次读取写缓存和 store 中的文件。
- 最终将所有读取到的数据合并版本,按照 get 的要求返回即可。
5.3 合并读取数据优化
每次读取数据都需要读取三个位置,最后进行版本的合并。效率会非常低,所有系统需 要对此优化。
- HFile 带有索引文件,读取对应 RowKey 数据会比较快。
- Block Cache 会缓存之前读取的内容和元数据信息,如果 HFile 没有发生变化(记 录在 HFile 尾信息中),则不需要再次读取。
- 使用布隆过滤器能够快速过滤当前 HFile 不存在需要读取的 RowKey,从而避免读 取文件。(布隆过滤器使用 HASH 算法,不是绝对准确的,出错会造成多扫描一个文件,对 读取数据结果没有影响)
5.4 StoreFile Compaction
由于 memstore 每次刷写都会生成一个新的 HFile,文件过多读取不方便,所以会进行文 件的合并,清理掉过期和删除的数据,会进行 StoreFile Compaction。
Compaction 分为两种,分别是 Minor Compaction 和 Major Compaction。Minor Compaction 会将临近的若干个较小的 HFile 合并成一个较大的 HFile,并清理掉部分过期和删除的数据, 有系统使用一组参数自动控制,Major Compaction 会将一个 Store 下的所有的 HFile 合并成 一个大 HFile,并且会清理掉所有过期和删除的数据,由参数 hbase.hregion.majorcompaction 控制,默认 7 天。

Minor Compaction 控制机制: 参与到小合并的文件需要通过参数计算得到,有效的参数有 5 个
- hbase.hstore.compaction.ratio(默认 1.2F)合并文件选择算法中使用的比率。
- hbase.hstore.compaction.min(默认 3) 为 Minor Compaction 的最少文件个数。
- hbase.hstore.compaction.max(默认 10) 为 Minor Compaction 最大文件个数。
- hbase.hstore.compaction.min.size(默认 128M)为单个 Hfile 文件大小最小值,小于这 个数会被合并。
- hbase.hstore.compaction.max.size(默认 Long.MAX_VALUE)为单个 Hfile 文件大小最大 值,高于这个数不会被合并。 小合并机制为拉取整个 store 中的所有文件,做成一个集合。之后按照从旧到新的顺序遍历。 判断条件为:
- 过小合并,过大不合并
- 文件大小/ hbase.hstore.compaction.ratio < (剩余文件大小和) 则参与压缩。所有把比值设 置过大,如 10 会最终合并为 1 个特别大的文件,相反设置为 0.4,会最终产生 4 个 storeFile。 不建议修改默认值
- 满足压缩条件的文件个数达不到个数要求(3 <= count <= 10)则不压缩。
6 Region Spilt
6.1 预分区
每一个 region 维护着 startRow 与 endRowKey,如果加入的数据符合某个 region 维护的 rowKey 范围,则该数据交给这个 region 维护。那么依照这个原则,我们可以将数据所要投 放的分区提前大致的规划好,以提高 HBase 性能。
- 手动设定预分区 JSON create ‘staff1’,‘info’, SPLITS => [‘1000’,‘2000’,‘3000’,‘4000’]
- 生成 16 进制序列预分区 create ‘staff2’,‘info’,{NUMREGIONS => 15, SPLITALGO => ‘HexStringSplit’}
- 按照文件中设置的规则预分区 ( 创建 splits.txt 文件内容如下:
aaaa
bbbb
cccc
dddd
然后执行
create 'staff3','info',SPLITS_FILE=> 'splits.txt'
6.2 系统分区
Region 的拆分是由 HRegionServer 完成的,在操作之前需要通过 ZK 汇报 master,修改 对应的 Meta 表信息添加两列 info:splitA 和 info:splitB 信息。之后需要操作 HDFS 上面对 应的文件,按照拆分后的 Region 范围进行标记区分,实际操作为创建文件引用,不会挪动数据。刚完成拆分的时候,两个 Region 都由原先的 RegionServer 管理。之后汇报给 Master, 由Master将修改后的信息写入到Meta表中。等待下一次触发负载均衡机制,才会修改Region 的管理服务者,而数据要等到下一次压缩时,才会实际进行移动。
不管是否使用预分区,系统都会默认启动一套 Region 拆分规则。不同版本的拆分规则有差别。系统拆分策略的父类为 RegionSplitPolicy。
- 0.94 版本之前 => ConstantSizeRegionSplitPolicy :当 1 个 region 中 的 某 个 Store 下 所 有 StoreFile 的 总 大 小 超 过 hbase.hregion.max.filesize (10G),该 Region 就会进行拆分。
- 0.94 版本之后,2.0 版本之前 => IncreasingToUpperBoundRegionSplitPolicy :当 1 个 region 中 的 某 个 Store 下 所 有 StoreFile 的 总 大 小 超 过 Min(initialSizeR^3 ,hbase.hregion.max.filesize"),该 Region 就会进行拆分。其中 initialSize 的 默认值为 2hbase.hregion.memstore.flush.size,R 为当前 Region Server 中属于该 Table 的 Region 个数(0.94 版本之后)。 具体的切分策略为: 第一次 split:1^3 * 256 = 256MB 第二次 split:2^3 * 256 = 2048MB 第三次 split:3^3 * 256 = 6912MB 第四次 split:4^3 * 256 = 16384MB > 10GB, 因此取较小的值 10GB 后面每次 split 的 size 都是 10GB 了。
- 2.0 版本之后 => SteppingSplitPolicy :Hbase 2.0 引入了新的 split 策略:如果当前 RegionServer 上该表只有一个 Region, 按照 2 * hbase.hregion.memstore.flush.size 分裂,否则按照 hbase.hregion.max.filesize 分裂。 这叫大道至简,学海抽丝。
版权归原作者 那时的样子_ 所有, 如有侵权,请联系我们删除。