

在今天的文章中,我们应该学习如何管理我们的集群。 备份和分片分配是我们应该能够执行的基本任务。
分片分配过滤
Elasticsearch 将索引配到一个或多个分片中,我们可以将这些分片保存在特定的集群节点中。 例如,假设你有多个数据集群节点,其中两个具有 SSD 存储。 如果我们正在寻找对我们的一个索引的快速响应,我们可以将它们的分片配置为仅进入 SSD 数据节点。 这个概念称为分片分配过滤。 我们可以根据一组给定的要求将索引的分片分配给特定的节点。更多的细节可以阅读之前的文章 “Elasticsearch:运用 shard 过滤器来控制索引分配给哪个节点”。
为了执行分片分配,我们需要为每个节点指定属性。 每次启动节点时我们都会这样做:
./bin/elasticsearch -Enode.attr.size=medium -Enode.attr.disk=ssd
或者在 elasticsearch.yml 配置文件中指定这些属性:
node.attr.size: medium
node.attr.disk: ssd
然后我们可以指定我们选择的索引 twitter 保存在具有 SSD 属性和大小中等的数据节点上:
PUT twitter/_settings
{
"index.routing.allocation.require.size": "medium",
"index.routing.allocation.require.disk": "ssd"
}
分片分配感知
此外,执行这些操作的另一种可能性是使用分片分配感知。 我们可以让 Elasticsearch 将我们的物理硬件配置考虑在内。更多阅读,请参考文章 “Elasticsearch:shard 分配感知”。
例如,我们可以指定集群的每个节点运行的机架:
./bin/elasticsearch -Enode.attr.rack_id=rack_one
或者使用 elasticsearch.yml:
node.attr.rack_id: rack_one
然后我们需要在主节点中指定我们将使用 rack_id 作为属性:
cluster.routing.allocation.awareness.attributes: rack_id
稍后,如果我们添加新节点并指定不同的 rack_id,例如 rack_two,因为它们位于不同的机架中。 Elasticsearch 会将分片移动到新节点,确保(如果可能)两个副本不会存储在同一个机架中。 这样我们就可以防止在同一位置分配特定分片的多个副本。一旦有一个机架发生故障,那么我们的数据至少还是完整的。
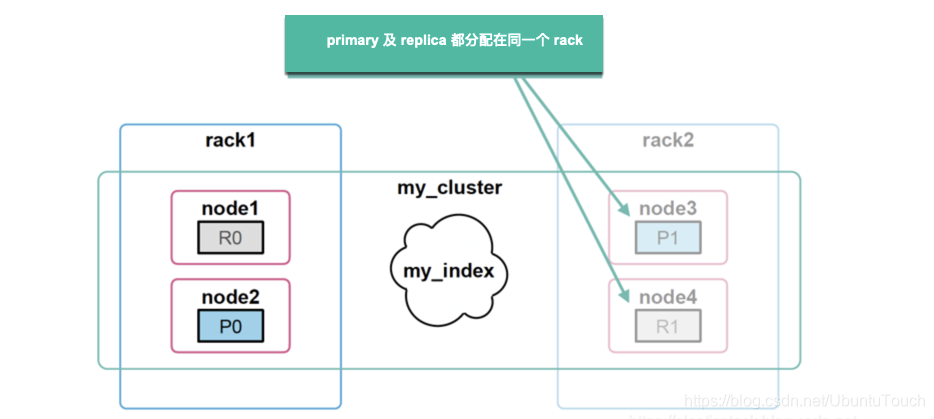
强迫感知(force awareness)
可能是一个机架出现故障,然后你可能没有足够的资源来仅在一个机架中托管主分片和副本分片。 为了防止在发生故障时过载,我们可以使强迫感知。
我们可以指定仅当至少有两个机架都可用时才分配副本。 为此,我们需要在我们的主节点中指定我们将使用 rack_id 作为属性并强制使用 rack_id 值。
cluster.routing.allocation.awareness.attributes: rack_id
cluster.routing.allocation.awareness.force.rack_id.values: rack_one,rack_two
更多阅读:Elasticsearch:为自管的 Elasticsearch 添加分片分配感知。
集群的健康
我们的集群有几种可能的健康状态:绿色、黄色或红色。 这些健康颜色会根据分片分配而变化,红色状态表示特定分片未分配,黄色表示主分片已分配但副本未分配,绿色表示所有分片均已分配。可以使用 Cluster Health API 检索集群健康状况:
GET _cluster/health
此外,我们可以检查单个索引及其分片的健康状况:
GET /_cluster/health/twitter
GET /_cluster/health/twitter?level=shards
如果我们正在处理黄色或红色状态的集群,我们可以使用集群分配解释 API 检查原因:
GET /_cluster/allocation/explain
如前所述,状态与分片分配相关联。 例如,我们可以检查副本分片的状态,“primary”: false,一个索引:
GET /_cluster/allocation/explain
{
"index": "twitter",
"shard": 0,
"primary": false
}
为了解决健康问题,我们可能需要添加新的数据节点或更改索引的分配规则。 在此示例中,我正在配置 twitter 索引,指定其主分片不能保留在名为 “data-node1”的节点上。 该节点将仅用于副本分片。
PUT /twitter/_settings
{
"index.routing.allocation.exclude._name": "data-node1"
}
备份还原
人们可以认为备份就像复制所有节点的数据目录一样简单。 你不应该以这种方式进行备份,因为 elasticsearch 可能会在运行时对其数据进行更改。 为了执行备份,elasticsearch 为我们提供了 snapshot API。 你可以拍摄正在运行的索引或整个集群的快照,然后将该信息存储在其他地方。
此外,快照是增量拍摄的。 每次我们创建索引的快照时,elasticsearch 都会避免复制任何因为较早的快照已存储的数据。 因此,建议你经常为集群拍摄快照。
注册一个存储库
要保存快照,我们需要创建一个存储库。 首先,我们需要为每个主节点和数据节点的 elasticsearch.yml 配置文件中的每个存储库指定可能的路径。
path.repo: ["/mount/backups", "/mount/longterm_backups"]
之后我们可以使用名称注册一个存储库:
PUT /_snapshot/my_backup
{
"type": "fs",
"settings": {
"location": "/mount/backups"
}
}
这也可以从 Kibana 转到管理然后快照和恢复进行配置。
备份集群配置
独立于存储库和未来的快照,我们应该始终备份 elasticsearch 配置文件夹,其中包括 elasticsearch.yml。 在这种情况下,我们可以使用我们的备份工具对该文件夹进行备份。 但是 elasticsearch 安全功能存储在专用索引中。 所以有必要备份 .security 索引。
为了执行操作,启用安全功能,我们需要将角色 snapshot_user 分配给用户或创建一个具有角色 snapshot_user 的用户。
POST /_security/user/snapshot_user
{
"password" : "secret",
"roles" : [ "snapshot_user" ]
}
然后拍摄 .security 索引的快照:
PUT /_snapshot/my_backup/snapshot_1
{
"indices": ".security",
"include_global_state": true
}
恢复集群的安全配置
成功备份我们的安全配置后,我们可以随时恢复它。 只需创建一个具有超级用户角色的新用户:
./bin/elasticsearch-users useradd restore_user -p password -r superuser
删除之前的安全数据:
curl -u restore_user -X DELETE "localhost:9200/.security-*"
并使用新用户恢复安全索引:
curl -u restore_user -X POST "localhost:9200/_snapshot/my_backup/snapshot_1/_restore" -H 'Content-Type: application/json' -d'
{
"indices": ".security-*",
"include_global_state": true
}
'
备份数据
备份数据的最简单方法是执行快照。 默认情况下,快照将复制集群中所有打开和启动的索引:
PUT /_snapshot/my_backup/snapshot_1?wait_for_completion=true
但是我们总是可以只备份一些索引:
PUT /_snapshot/my_backup/snapshot_2?wait_for_completion=true
{
"indices": "index_1,index_2",
"ignore_unavailable": true,
"include_global_state": false
}
在执行快照后,我们可以检查其状态:
GET /_snapshot/my_backup/snapshot_1
恢复快照
最后,在成功执行快照后,我们可以使用 _restore 并指定快照名称来恢复它。
POST /_snapshot/my_backup/snapshot_1/_restore
无论哪种方式,我们都可以恢复一些索引:
POST /_snapshot/my_backup/snapshot_1/_restore
{
"indices": "index_1,index_2",
"ignore_unavailable": true,
"include_global_state": true,
"rename_pattern": "index_(.+)",
"rename_replacement": "restored_index_$1"
}
或者恢复索引并更改其配置:
POST /_snapshot/my_backup/snapshot_1/_restore
{
"indices": "index_1",
"index_settings": {
"index.number_of_replicas": 0
},
"ignore_index_settings": [
"index.refresh_interval"
]
}
删除快照
类似于索引删除快照,需要指定其名称和存储库,向 _snapshot API 发送 DELETE 请求:
DELETE /_snapshot/my_repository/my_snapshot
更多阅读,请参考:
- Elasticsearch:Searchable snapshot - 可搜索的快照
- Elasticsearch:Cluster 备份 Snapshot 及 Restore API
- Elasticsearch:为 snapshot 设置 NFS 共享
- Elasticsearch:Snapshot 生命周期管理
跨集群搜索
另一个有用的配置是启用跨集群搜索。 为此,我们只需要指定每个集群的 IP 地址:
PUT _cluster/settings
{
"persistent": {
"cluster": {
"remote": {
"cluster_one": {
"seeds": [
"127.0.0.1:9300"
]
},
"cluster_two": {
"seeds": [
"127.0.0.1:9301"
]
}
}
}
}
}
执行此配置后,我们可以在远程集群中搜索并在请求中指定其名称:
GET /cluster_one:twitter/_search
{
"query": {
"match": {
"user.id": "carloslannister"
}
}
}
或者同时搜索两个集群:
GET /cluster_one:twitter,cluster_two:twitter/_search
{
"query": {
"match": {
"user.id": "carloslannister"
}
}
}
更多阅读,请参阅:
- Elasticsearch:跨集群搜索 Cross-cluster search (CCS)
- Elasticsearch:跨集群搜索 Cross-cluster search(CCS)及安全
- Elasticsearch:如何为 CCR 及 CCS 建立带有安全的集群之间的互信
- Elasticsearch:如何在不更新证书的情况下为集群之间建立互信
版权归原作者 Elastic 中国社区官方博客 所有, 如有侵权,请联系我们删除。