
前言
大数据监控是指通过大数据技术手段获取、收集、分析数据,并能够准确分析信息,有效预测信息发展动态趋势。大数据监控主要围绕着海量全网数据,大多数需要借助监测系统来协助分析数据。
1. 大数据运维监控体系
监控维度主要监控项底层基础监控机房与网络(路由器、交换机等)、专线、服务器(CPU、内存、IO、磁盘、文件等)各类型日常的基础监控服务状态监控各类型标准组件存活状态(从业务的 SLB、Nginx、Java、Hdfs、Hive、ZK 等组件存活状态)组件性能监控每种组件的 Metrics 性能监控,以 Hive 为例 (QPS、RPC、Metastore Canary、connection 等)Runtime监控顾名思义,模拟客户端去 不间断循环与各式组件发起基本请求与操作,确认组件状态,比如每隔5 分钟去 与 HDFS 交互,完成新增、修改、删除、查询等基本操作,并获得操作结果状态与响应时间。集群指标监控集群的核心指标监控,比如文件大小分布、集群整体计算资源、集群整体存储资源等指标。任务状态监控任务状态、任务占用资源、任务延迟等。趋势预测监控存储与计算同比、环比上涨趋势、小文件同比环比上涨趋势、SLA 趋势预测
其实上面每个维度,都包含了很多的监控项与监控指标,而针对不同的告警维度,它的监控方式也不尽相同,但总体来说,对于大数据监控,分为资源监控和性能监控2方面。
- 一些监控是不断读取它的状态,比如常见的 CPU 、内存,然后设定阈值触发告警动作。
- 一些监控是需要有时序性的聚合统计,比如 HDFS 存储增量,当增量斜率比平时高的时候触发告警动作。
- 一些监控是需要和其他监控做与操作,或者联动,同时满足才会触发告警动作。
针对这些不同的监控指标,单纯的一个监控组件 或者 数据采集方式是不能满足的。 光靠开源的监控手段也无法全部覆盖,所以我们做了各式组件 + 自研的监控脚本与程序去实现整体的监控框架。
整个7 个维度,我们按照不同的框架与组件实现,主要分为两个实现。
2. 大数据运维监控组件
通用大数据台性能监控组件:Grafana + Prometheus + Alertmanager等。
3. 基础监控实现
底层基础监控
基于 Zabbix 的底层基础监控,这部分比较简单,主要是基于 Zabbix + 云监控 对所有的网络、服务器进行实时监控数据收集。
如果同时有不同的事业部/部门进行运维工作,则需要进行分组、分模版、分告警渠道等的形式,实现对不同部门的告警。 但同时为了避免重复维护,尽量复用告警模版。
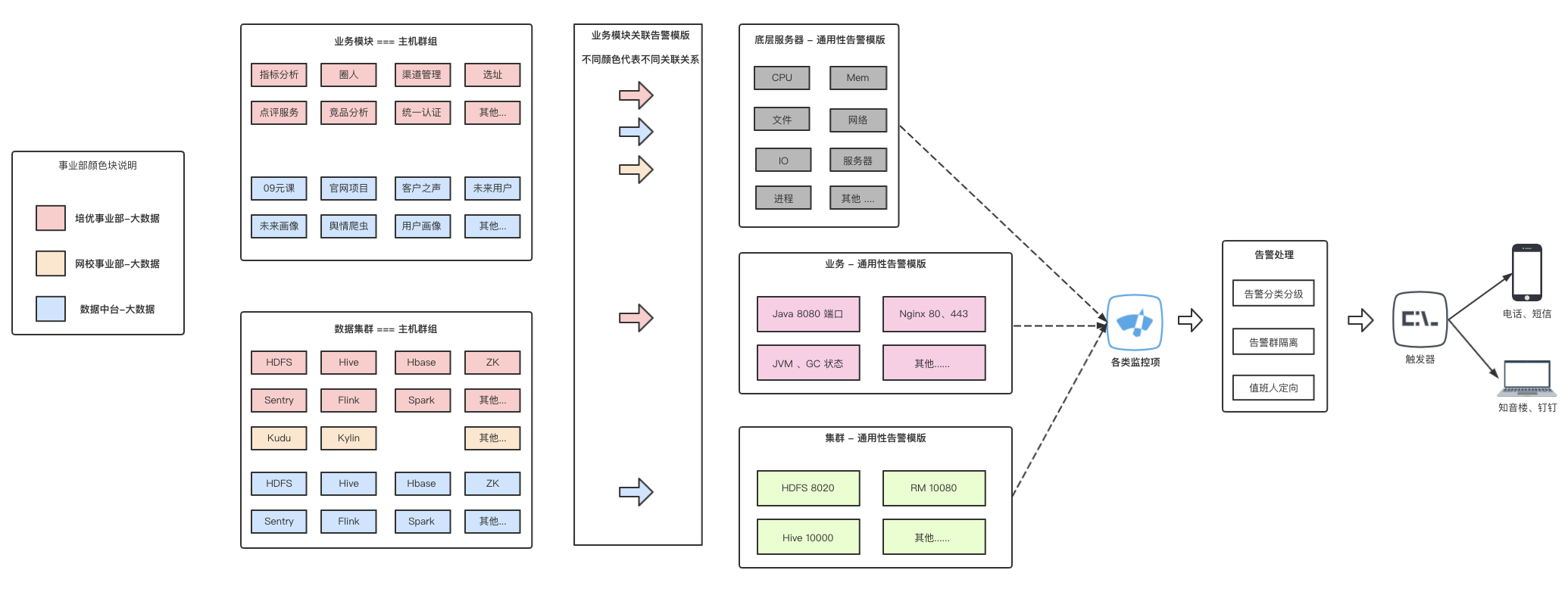
集群性能监控对 大数据 组件的性能监控,我们借助 Prometheus + AlertManager + Grafana 的架构方式。 主要分为四个简要步骤:1. 自建 Flask exporter ,从 Cloudera Manager 的 API 中取出各式组件需要监控的 Metrics 。2. 通过 Alertmanager 对需要的 metrics 进行告警。3. 自建告警系统 + 电话告警 API 供 Alertmanager 调用。4. 将 Prometheus data source 接入 Grafana 做报表展示。
4. 监控组件介绍
Prometheus
Prometheus注重于数据存储及分析,存储采集到的监控数据并以metric的形式保存在其中,且能够将数据落到本地磁盘中,供使用人员二次查询数据。
Prometheus同时附加了强大的计算与分析功能,能够利用各种labels与promql语句来完成多维度的监控数据查询,从而为故障排查与问题定位提供可靠的证据。
监控规则方面,Prometheus可以根据promql来获取数据,并且与固定阈值进行计算比较,若超出正常范围,则标记为告警信息,并且可以分组分标签定义告警描述,供后续Alertmanager使用。
在拓展性方面,Prometheus可以轻松的完成服务发现功能,并拥有每秒上万数据点的监控数据收集与分析的处理能力,完全摆脱了传统监控系统对监控主机数量的要求。目前联通大数据平台机器几千余台,监控实例过十万,监控实例指标过千万,Prometheus优良的性能可以做到完美支撑。
Prometheus特点
① 监控数据存储功能及多维度查询
② 优秀的自定义及第三方监控拓展功能
③ 良好的监控生态圈之常见client库
Alertmanager
Alertmanager的主要作用是对告警进行分类并发送到客户端。Alertmanager在监控系统中的定位是接收Prometheus发送来的告警,并逐一按照配置中route进行分类,并且通过silencing、inhibition的规则计算,最终得到有效告警信息,通过邮件、钉钉、微信等方式发送给各类业务人群。
Alertmanager特点
① 分组
使用分组特性,Alertmanager会将具有共同属性的告警归为一条发送到接收端,清晰明了。
② 抑制
某主机上运行了一个mysql实例,若该主机宕机,则会收到多条关于mysql各项监控的告警信息,但如果配置了抑制用法,只要触发该主机的宕机告警,上面mysql所触发的告警便会被抑制掉,即高级警报将会抑制低级警报。
③ 沉默
比如,某主机硬件主板损坏,但厂商反馈要2天后才能更换主板,一般情况下在更换主板前,该警报会一直大量重复发送。如果此时利用沉默功能,在页面上配置沉默选项即可暂停此告警,待修复完成后取消沉默规则即可
Grafana
Grafana是大数据平台性能监控图形化展示功能的核心组件,也是近年来比较受欢迎的一款监控配置展示工具,其优点在于能对接各种主流数据库,并且能在官网及社区上下载精致的模板,通过导入json模板做到快速的展示数据。
主机监控项:主机监控项概览:内核、内存、负载、磁盘io、网络、磁盘存储、inode占用、进程数、线程数。
图示:

具体监控项举例如下:
主机资源占用:主要从cpu占用、内存占用、负载、线程数多个维度统计同一主机群体。
进程资源占用:通过主机监控大屏和主机资源占用top10定位故障主机的故障时间段和异常指标,只能初步的帮助运维人员排查机器故障的原因。例如,当机器负载过高时,在主机监控大屏中往往能看出主机的cpu使用,读写io、网络io会发生急速增长,却不能定位是哪个进程导致。当重启故障主机之后,又无法排查历史故障原因。因此对于主机层面监控,增加了进程资源占用top10,能获取占用cpu,内存最高的进程信息(进程开始运行时间、已运行时长、进程pid、cpu使用率、内存使用率等有用信息)。这样,当主机因为跑了未经测试的程序,或者因运行程序过多,或程序线程并发数过多时,就能有效的通过历史数据定位机器故障原因。
图示:
平台监控项
平台监控项种类繁多,有hdfs、yarn、zookeeper、kafka、storm、spark、hbase等平台服务。每个服务下有多种角色类别,如hdfs服务中包括Namenode、Datenode、Failover Controller、JournalNode 。每个角色类别下又有多个实例,如此产生的监控指标实例达几十万个。基础监控指标全面多样。所以需要根据集群/平台现状,平台层面需要配置一些比较关键的一些监控项。

借鉴文章:
联通大数据集群平台监控体系
大数据集群平台监控体系
版权归原作者 Jelly lee 所有, 如有侵权,请联系我们删除。