
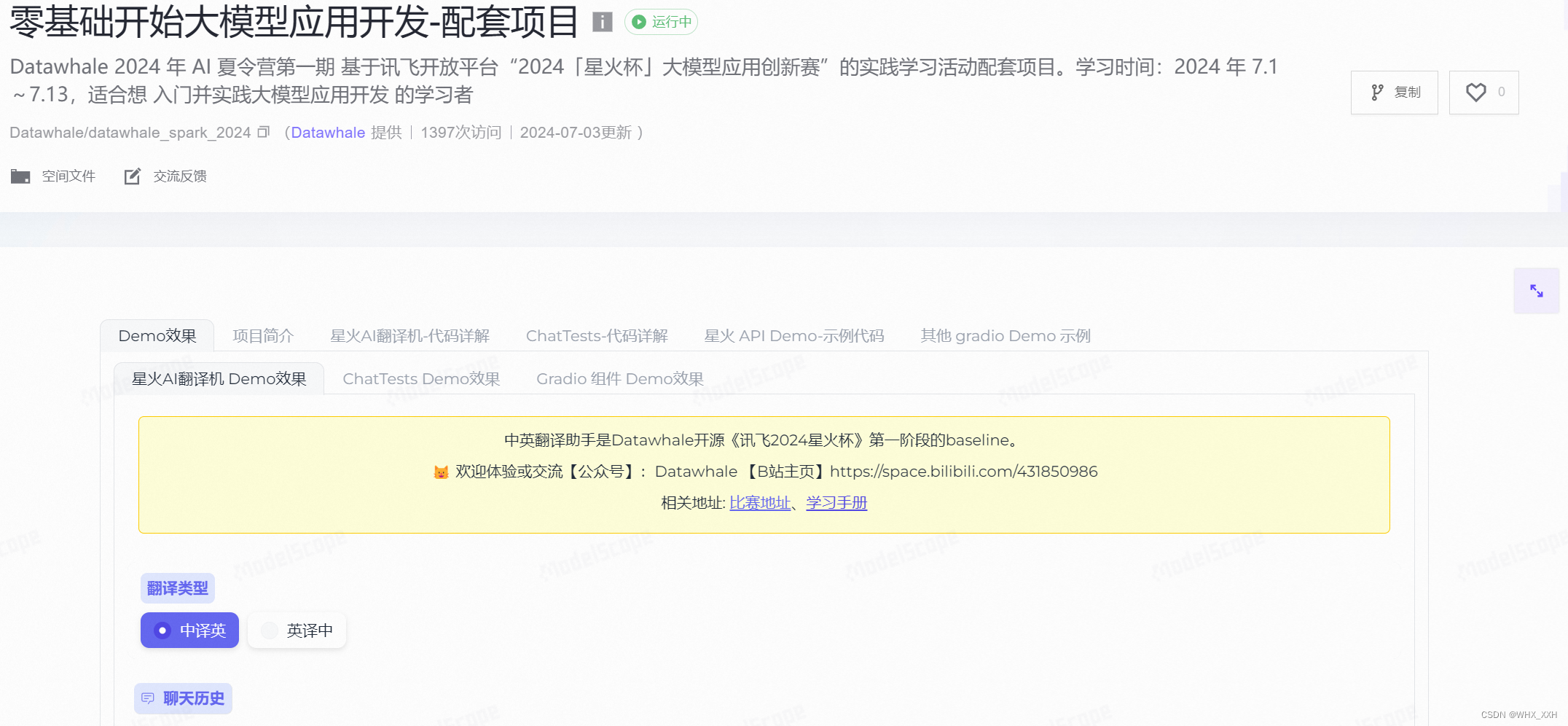
如何从一段代码行对话,变成我们日常使用的APP、小程序、网页等工具?
如果我们想
快速添加常用的Prompt模板、或是想要
拥有一个历史会话功能,应该怎么办?
此时,我们就需要通过代码级开发来自定义前端了,前面大家已经在Task1快速入门了代码级开发,复刻了自己的应用demo,相信下面的内容对你来说也绝对不在话下——
配套魔搭示例代码项目可见:https://modelscope.cn/studios/Datawhale/datawhale_spark_2024
零、预备:了解基础概念
关于开发类的内容,可能会涉及到很多新概念,
为了尽量压缩篇幅,且让大家不用有那么多认知负担,
我们仅会对Gradio框架以及相关术语进行简单介绍,
主要目标是引导大家进入实操,且开始掌握如何解决问题的思路,
大家如果对相关信息有更多的学习需求,可以通过官方文档、浏览器搜索等方式研习。
Gradio 官方文档详见:https://www.gradio.app/
要想拥有更符合心意的应用,需要自己进行开发,即:我们需要把星火大模型的 API 作为一个功能组件,加入到我们自己的应用中去,做出属于我们创意的内容~
创建应用有很多种方式,常见如:网页、浏览器插件、小程序、移动应用程序(App)、桌面应用软件等。
一般来说,小程序、App、企业微信、订阅号服务等还有一定的开发及审核门槛,且需要学习较多的前端甚至UI设计相关的知识,需要具有一定的专业度和人力投入。
因此我们在快速验证功能和设计demo时,往往较优的选择是直接通过 Gradio/Streamlit 快捷开发可交互的demo。
使用 飞桨AI Studio 、魔搭Notebook 等云开发平台,可以减少很多本地环境配置的麻烦。
dwspark、Gradio 、也只需要简单通过pip安装对应的Python库即可。
在学习之前,这里还有几个基础概念你需要知道:
- Python:一种简洁、易读、功能强大的高级编程语言,常言道“人生苦短,我用Python”。Gradio 是基于Python开发并开源的库。
- pip:Python的包管理工具,主要用于安装、管理和卸载Python的第三方库。它是Python开发中不可或缺的工具之一,常用命令:-
pip install xxx、pip install --upgrade xxx、pip uninstall xxx、pip show xxx、pip install xxx==1.1.1、pip list安装指定python库、升级指定python库、卸载指定python库、查看指定Python库的安装情况、安装指定Python库的指定版本、列出所有通过pip安装的Python库- 在使用gradio、streamlit、以及appbuilder-SDK时,记得安装这些库哟~- SDK:即“软件开发工具包”(Software Development Kit),一般会包含一系列工具和文档的集合,旨在帮助开发者更有效地开发特定的软件应用程序。工具可能包括编程语言的库、APIs、开发环境(IDE)、编译器、调试&性能分析工具、相关文档等。- dwspark 就是我们为了方便大家调用星火大模型API而封装开发的SDK
- 飞桨 AI Studio:基于百度深度学习平台飞桨(PaddlePaddle)的人工智能学习与实训社区。它提供了一站式的模型在线开发与应用环境,支持多种编程语言和深度学习框架。- 我们可以在AI Studio上进行python代码编写与运行,且可以免费使用其CPU环境(GPU环境需要付费)- 另外我们的 Gradio 项目完成开发后,还可以通过其进行部署,分享给他人体验
- 魔搭ModelScope:
一、dwspark进阶指南
1、为什么会有dwspark?
官方提供了很多模型,但各自有自己的SDK且调用起来较为麻烦,所以对基础模型进行了代码封装,以方便较为简洁的方式调用这些模型。
具体的模型官方接口文档见下表:
模型文档地址认知大模型星火认知大模型Web API文档 | 讯飞开放平台文档中心文本合成语音语音合成(流式版)WebAPI 文档 | 讯飞开放平台文档中心语音识别文本语音听写(流式版)WebAPI 文档 | 讯飞开放平台文档中心文生图图片生成 API 文档 | 讯飞开放平台文档中心图片理解图片理解 API 文档 | 讯飞开放平台文档中心文本向量化llm embedding 协议 | 讯飞开放平台文档中心
2、如何使用dwspark?
2.1 安装SDK
pip install dwspark
2.2 加载配置
from dwspark.config import Config
# 加载系统环境变量:SPARKAI_APP_ID、SPARKAI_API_KEY、SPARKAI_API_SECRET
config = Config()
# 自定义key写入
config = Config('14****93', 'eb28b****b82', 'MWM1MzBkOD****Mzk0')
2.3 调用模型
# SDK引入模型
from dwspark.models import ChatModel, Text2Img, ImageUnderstanding, Text2Audio, Audio2Text, EmbeddingModel
# 讯飞消息对象
from sparkai.core.messages import ChatMessage
# 日志
from loguru import logger
'''
对话
'''
# 模拟问题
question = '你好呀'
logger.info('----------批式调用对话----------')
model = ChatModel(config, stream=False)
logger.info(model.generate([ChatMessage(role="user", content=question)]))
logger.info('----------流式调用对话----------')
model = ChatModel(config, stream=True)
[ logger.info(r) for r in model.generate_stream(question)]
logger.info('done.')
'''
文字生成语音
'''
text = '2023年5月,讯飞星火大模型正式发布,迅速成为千万用户获取知识、学习知识的“超级助手”,成为解放生产力、释放想象力的“超级杠杆”。2024年4月,讯飞星火V3.5春季升级长文本、长图文、长语音三大能力。一年时间内,讯飞星火从1.0到3.5,每一次迭代都是里程碑式飞跃。'
audio_path = './demo.mp3'
t2a = Text2Audio(config)
# 对生成上锁,预防公有变量出现事务问题,但会降低程序并发性能。
t2a.gen_audio(text, audio_path)
'''
语音识别文字
'''
a2t = Audio2Text(config)
# 对生成上锁,预防公有变量出现事务问题,但会降低程序并发性能。
audio_text = a2t.gen_text(audio_path)
logger.info(audio_text)
'''
生成图片
'''
logger.info('----------生成图片----------')
prompt = '一只鲸鱼在快乐游泳的卡通头像'
t2i = Text2Img(config)
t2i.gen_image(prompt, './demo.jpg')
'''
图片解释
'''
logger.info('----------图片解释----------')
prompt = '请理解一下图片'
iu = ImageUnderstanding(config)
logger.info(iu.understanding(prompt, './demo.jpg'))
'''
获取文本向量
'''
logger.info('----------获取文本向量----------')
em = EmbeddingModel(config)
vector = em.get_embedding("我们是datawhale")
logger.info(vector)
2.4 模型列表
模型名称
调用方式
批式调用对话
model = ChatModel(config, stream=False) model.generate([ChatMessage(role="user", content='对话内容')])
流式调用对话
model = ChatModel(config, stream=True)
model = ChatModel(config, stream=True)
[logger.info(r) for r in model.generate_stream('对话内容')]
文字生成语音
t2a = Text2Audio(config)
model = ChatModel(config, stream=True)
t2a.gen_audio('你好啊', '生成音频地址')
生成图片
t2i = Text2Img(config)
t2i.gen_image('生成图片需求', '图片地址')
图片解释
iu = ImageUnderstanding(config)
iu.understanding('图片理解方向描述', '图片地址')
获取文本向量
em = EmebddingModel(config)
vector = em.get_embedding("需要向量化的文本")
2.5 dwspark代码详解
dwspark主要包含以下几个文件:
- config.py:统一的配置文件
- utils:一些工具类
- models:存放模型的地方- models.ChatModel.py:对话相关模型- models.AudioModel.py:音频相关模型- models.ImageModel.py:图片相关模型- models.EmbeddingModel.py:向量化模型
二、Gradio基础概念入门
基于Gradio开发应用,必须了解 Gradio有输入输出组件、控制组件、布局组件几个基础模块:
- 输入输出组件用于展示内容和获取内容,如:
Textbox文本、Image图像- 布局组件用于更好地规划组件的布局,如:
Column(把组件放成一列)、Row(把组件放成一行)- 推荐使用gradio.Blocks()做更多丰富交互的界面,gradio.Interface()只支持单个函数交互- 控制组件用于直接调用函数,无法作为输入输出使用,如:
Button(按钮)、ClearButton(清除按钮)- Gradio的设计哲学是将输入和输出组件与布局组件分开。输入组件(如
Textbox、Slider等)用于接收用户输入,输出组件(如Label、Image等)用于显示函数的输出结果。而布局组件(如Tabs、Columns、Row等)则用于组织和排列这些输入和输出组件,以创建结构化的用户界面。
大部分输入输出组件都有以下三个参数:
fn:绑定的函数,输入参数需与inputs列表类型对应inputs:输入组件变量名列表,(例如:[msg, chatbot])ouputs:输出组件变量名列表,(例如:[msg, chatbot])- 另外不同的 输入输出组件、控制组件 有不同动作可响应(对应一些.方法,如下面的
msg.submit())
需要注意,Gradio的组件更新,实现交互,都只能通过绑定的
fn进行实现:
fn中需要使用的用户指定的数据来源,均需要放入inputs中,- 需要更新的组件均需要通过
fn*return *回来,并与outputs中的组件类型意义对应对应到 飞桨项目:"一键"跑通大模型应用开发!中的
“体验随机回复应用”的示例代码中即:
# 导入gradio、random、time库,他们的功能大致如名字所示
import gradio as gr # 通过as指定gradio库的别名为gr
import random
import time
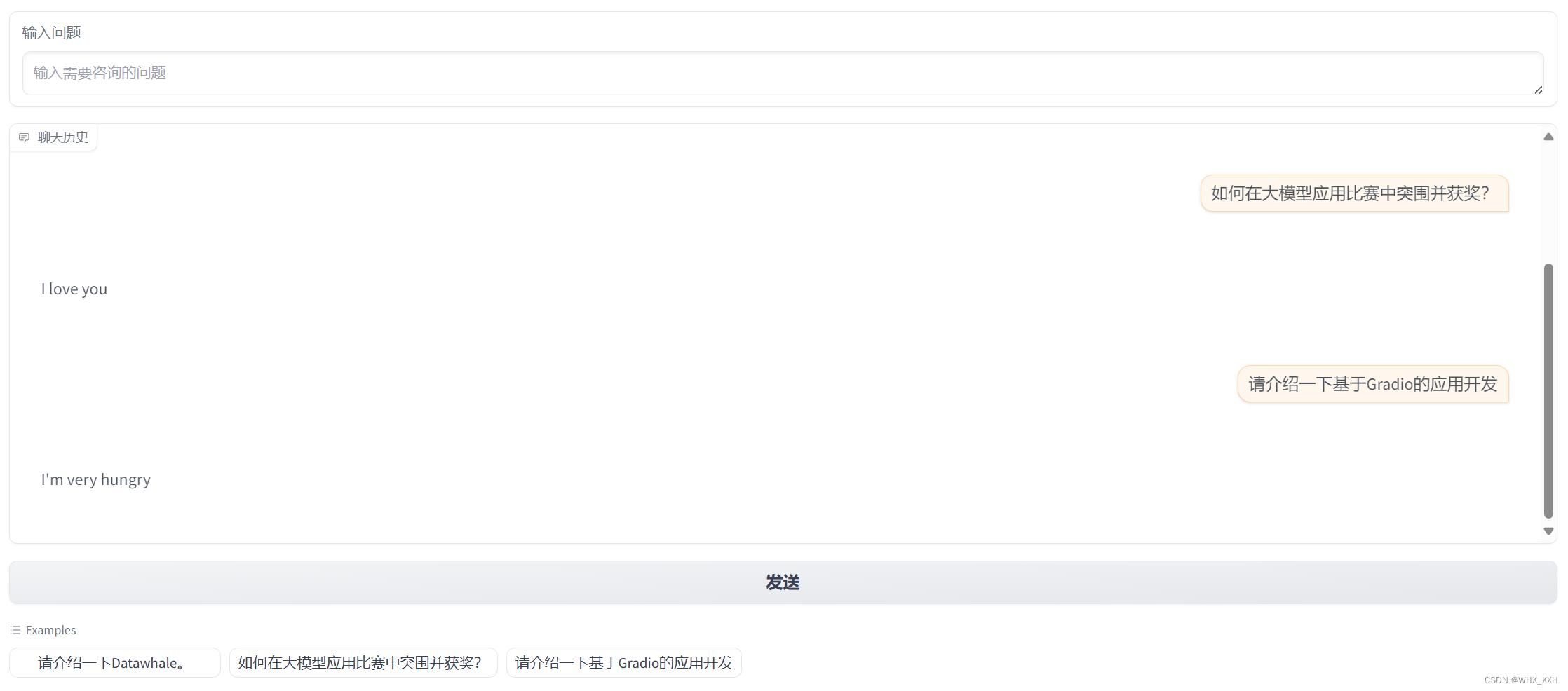
# 自定义函数,功能是随机选返回指定语句,并与用户输入的 chat_query 一起组织为聊天记录的格式返回
def chat(chat_query, chat_history):
# 在How are you 等语句里随机挑一个返回,放到 bot_message 变量里
bot_message = random.choice(["How are you?", "I love you", "I'm very hungry"])
# 添加到 chat_history 变量里
chat_history.append((chat_query, bot_message))
# 返回 空字符,chat_history 变量,空字符用于清空 chat_query 组件,chat_history 用于更新 chatbot组件
return "", chat_history
# gr.Blocks():布局组件,创建并给了他一个名字叫 demo
with gr.Blocks() as demo:
# gr.Chatbot():输入输出组件,用于展示对话效果
chatbot = gr.Chatbot([], elem_id="chat-box", label="聊天历史")
# gr.Textbox():输入输出组件,用于展示文字
chat_query = gr.Textbox(label="输入问题", placeholder="输入需要咨询的问题")
# gr.Button:控制组件,用于点击,可绑定不同的函数触发处理
llm_submit_tab = gr.Button("发送", visible=True)
# gr.Examples(): 输入输出组件,用于展示组件的样例,点击即可将内容输入给 chat_query 组件
gr.Examples(["请介绍一下Datawhale。", "如何在大模型应用比赛中突围并获奖?", "请介绍一下基于Gradio的应用开发"], chat_query)
# 定义gr.Textbox()文字组件 chat_query 的 submit 动作(回车提交)效果,执行函数为 chat, 第一个[chat_query, chatbot]是输入,第二个 [chat_query, chatbot] 是输出
chat_query.submit(fn=chat, inputs=[chat_query, chatbot], outputs=[chat_query, chatbot])
# 定义gr.Button()控制组件 llm_submit_tab 的 点击动作 效果,执行函数为 chat, 第一个[chat_query, chatbot]是输入,第二个 [chat_query, chatbot] 是输出,效果与上一行代码同
llm_submit_tab.click(fn=chat, inputs=[chat_query, chatbot], outputs=[chat_query, chatbot])
# 运行demo
if __name__ == '__main__':
demo.queue().launch()
**运行结果: **

三、星火大模型API进阶指南
官方提供多款星火大模型API的token。其中包括:星火大模型、语音合成、语音识别、图片生成、图片理解、文本向量化以及智能PPT生成。这些模型API让我们能够把更多的注意力放在idea实现和应用开发当中。
下面将介绍大模型的API调用原理及学习使用的思路
API流程(图像生成为例)
如何查看API文档?(图像生成为例)
根据模型需求,进入API接口文档。根据下列步骤查看API关键信息(其他API类似)
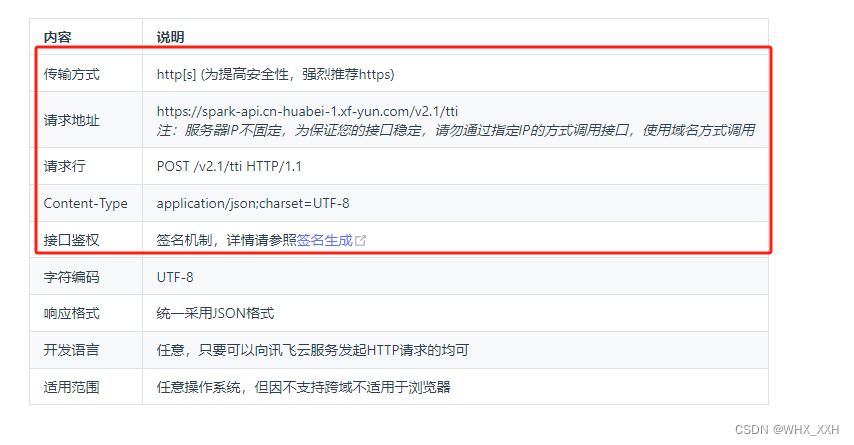
1. 首先需要关注API的接口信息。
这一步主要目的是了解API的网络协议,特别是传输方式、请求地址、Content-Type和接口鉴权4部分。因为讯飞星火不同的模型有不同的调用方式,所以我们需要根据要求调整我们的网络调用协议。
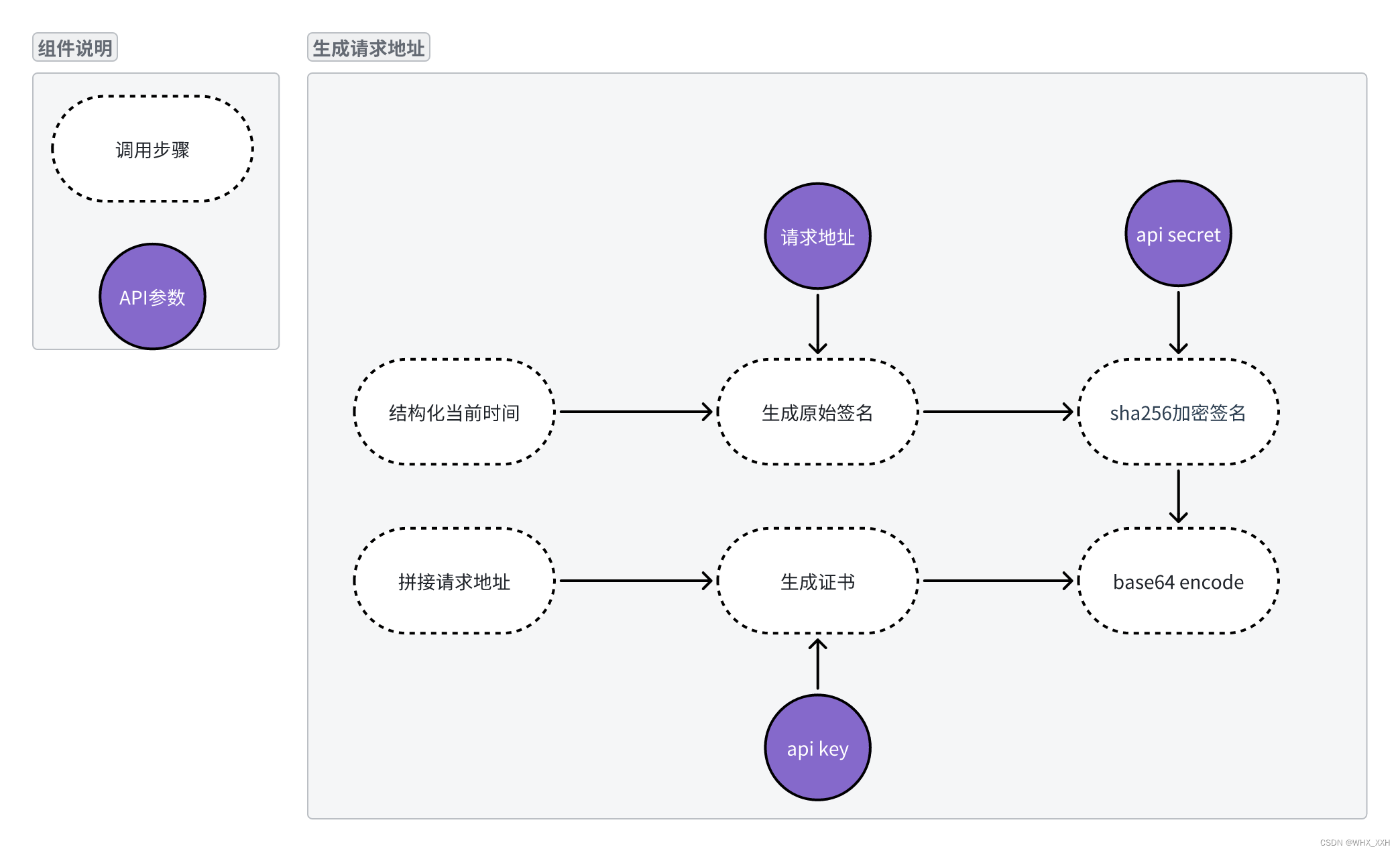
2. 查看鉴权方式
讯飞API有一个特点,就是需要先使用我们的key进行加密鉴权,然后填充新的url进行实际调用。所以我们需要根据鉴权文档步骤,实时调整我们的url。具体方式如图中所示:
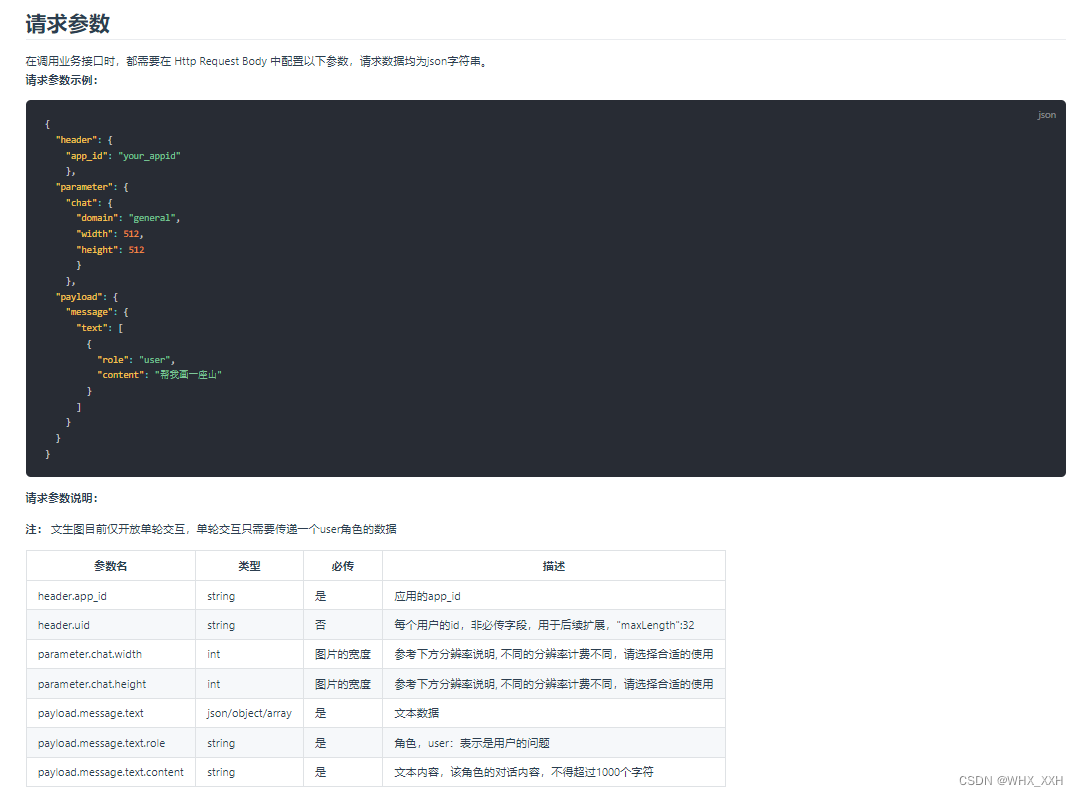
3. 查询调用参数
返回API文档,根据文档查看模型的可用调用参数。具体如下图所示,分别为参数实例与参数说明。为了让我们的应用更加的具有特色,通常更简易针对需求调整API的参数。相同的模型相同的API,在不同参数的调整下可能会有不同的效果。
4. 查询返回结果参数与异常信息码
返回结果参数便于我们针对式的开发我们的模型后处理的代码,而异常信息码则便于我们实现异常处理问题,提高应用高可用。

API文档很复杂,实在看不懂怎么办?
为了降低参赛选手的门槛,我们基于讯飞星火大模型常用的API封装了一个较为简单的SDK包。[点我查看]
1. 安装方法
# 本地安装
pip install dwspark-2024.0.2-py3-none-any.whl
# 线上安装
pip install dwspark
2. 使用方法
from dwspark.config import Config
'''
初始化配置文件(二选一)
'''
# 加载系统环境变量:SPARKAI_APP_ID、SPARKAI_API_KEY、SPARKAI_API_SECRET
config = Config()
# 自定义key写入
#config = Config('14****93', 'eb28b****b82', 'MWM1MzBkOD****Mzk0')
'''
SDK使用示例
'''
# SDK引入模型
from dwspark.models import ChatModel, Text2Img, ImageUnderstanding, Text2Audio, Audio2Text, EmebddingModel
# 讯飞消息对象
from sparkai.core.messages import ChatMessage
# 日志
from loguru import logger
'''
对话
'''
# 模拟问题
question = '你好呀'
logger.info('----------批式调用对话----------')
model = ChatModel(config, stream=False)
logger.info(model.generate([ChatMessage(role="user", content=question)]))
logger.info('----------流式调用对话----------')
model = ChatModel(config, stream=True)
[logger.info(r) for r in model.generate_stream(question)]
'''
文字生成语音
'''
text = '2023年5月,讯飞星火大模型正式发布,迅速成为千万用户获取知识、学习知识的“超级助手”,成为解放生产力、释放想象力的“超级杠杆”。2024年4月,讯飞星火V3.5春季升级长文本、长图文、长语音三大能力。一年时间内,讯飞星火从1.0到3.5,每一次迭代都是里程碑式飞跃。'
audio_path = './demo.mp3'
t2a = Text2Audio(config)
# 对生成上锁,预防公有变量出现事务问题,但会降低程序并发性能。
t2a.gen_audio(text, audio_path)
'''
语音识别文字
'''
a2t = Audio2Text(config)
# 对生成上锁,预防公有变量出现事务问题,但会降低程序并发性能。
audio_text = a2t.gen_text(audio_path)
logger.info(audio_text)
'''
生成图片
'''
logger.info('----------生成图片----------')
prompt = '一只鲸鱼在快乐游泳的卡通头像'
t2i = Text2Img(config)
t2i.gen_image(prompt, './demo.jpg')
'''
图片解释
'''
logger.info('----------图片解释----------')
prompt = '请理解一下图片'
iu = ImageUnderstanding(config)
logger.info(iu.understanding(prompt, './demo.jpg'))
'''
获取文本向量
'''
logger.info('----------获取文本向量----------')
em = EmebddingModel(config)
vector = em.get_embedding("我们是datawhale")
logger.info(vector)
但SDK带来便捷性的同时,它也丧失了个性化的“本领”,同时也难以兼容到讯飞所有的模型产品。所以我们更推荐大家基于API文档开发适合自己的调用方式。
我也想开发自己的调用方式,有没有入门参考?
讯飞为每一个API都打包了一个调用demo,demo通常放在对应API文档的上方。我们可以下载查看demo里面的代码,然后基于demo再进行二次开发。
如有实在不会的,可以在学习群里请教助教。
四、本地pycharm部署星火AI自动翻译机!
1、modelscope项目
项目链接:https://modelscope.cn/studios/Datawhale/Dw_spark_baseline
2、本地pycharm部署

版权归原作者 WHX_XXH 所有, 如有侵权,请联系我们删除。