
1 HiveQL 调优
1.1 调优前规划设计
1.1.1 Hive 表文件使用高效的文件格式
我们使用同样数据及SQL语句,只是数据存储格式不同,得到如下执行时长:
数据格式CPU时间用户等待耗时TextFile33分171秒SequenceFile38分162秒Parquet2分22秒50秒ORC1分52秒56秒
注:CPU时间:表示运行程序所占用服务器CPU资源的时间。
用户等待耗时:记录的是用户从提交作业到返回结果期间用户等待的所有时间。
- 建议使用ORC ORC文件格式可以提供一种高效的方法来存储Hive数据,运用ORC可以提高Hive的读、写以及处理数据的性能。以下两种场景需要应用方权衡是否使用ORC: (a) 文本文件加载到ORC格式的Hive表的场景:由于文本格式到ORC,需要耗费较高的CPU计算资源,相比于直接落地成文本格式Hive表而言加载性能会低很多 (b) Hive表作为计算结果数据,导出给Hadoop之外的外部系统读取使用的场景:ORC格式的结果数据,相比于文本格式的结果数据而言其易读性低很多。除以上两种场景外,其他场景均建议使用ORC作为Hive表的存储格式。
- 考虑使用Parquet Parquet的核心思想是使用“record shredding and assembly algorithm”来表示复杂的嵌套数 据类型,同时辅以按列的高效压缩和编码技术,实现降低存储空间,提高IO效率,降低上 层应用延迟。 Parquet是语言无关的,而且不与任何一种数据处理框架绑定在一起,适配多种语言和组 件,能够与Parquet配合的组件有: 查询引擎:Hive、Impala、Pig; 计算框架:MapReduce、Spark、Cascading; 数据模型:Avro、Thrift、Protocol Buffers、POJOs。 对于Impala和Hive共享数据和元数据的场景,建议Hive表存储格式为Parquet。
1.12 Hive 表文件及中间文件使用合适的文件压缩格式
GZip和Snappy,这两种压缩算法在大数据应用中最常见,适用范围最广,压缩率和速度都较好,读取数据也不需要专门的解压操作,对编码来说透明。
压缩率跟数据有关,通常从2到5不等;两种算法中,GZip的压缩率更高,但是消耗CPU更高,Snappy的压缩率和CPU消耗更均衡。
对于存储资源受限或客户要求文件必须压缩的场景,可考虑使用以上两种压缩算法对表文件及中间文件进行压缩
1.1.3 根据业务特征创建分区表
使用分区表能有效地分隔数据,分区条件作为查询条件时,减少扫描的数据量,加快查询的效率。如果业务数据有明显的时间、区域等维度的区分,同时有较多的对应维度的查询条件时,建议按照相应维度进行一级或多级分区。
1.1.4 根据业务特征创建分桶表
分桶的目的是便于高效采样和为Bucket MapJoin及SMB Join做数据准备。
对于Hive表有按照某一列进行采样稽核的场景,建议以该列进行分桶。数据会以指定列的值为key哈希到指定数目的桶中,从而支持高效采样。
对于对两个或多个数据量较大的Hive表按照同一列进行Join的场景,建议以该列进行分桶。当Join时,仅加载部分桶的数据到内存,避免OOM。
1.2 Hive 调优的目标、原则及手段
1.2.1 调优目标
Hive调优的目标是在不影响其他业务正常运行的前提下,最大限度利用集群的物理资源,如CPU、内存、磁盘IO,同时分析集群的性能瓶颈,常规性能瓶颈有CPU密集型、内存密集型、IO密集型、重shuffle型等,参考下文总结,进行针对性优化,对症下药。
1.2.2 调优思路
- 第一步,分析SQL待处理的表及文件,统计待处理的表的文件数、数据量、条数、文件格式、压缩格式,分析是否有更适合的文件存储格式、压缩格式,是否能够使用上分区或分桶,是否有大量小文件需要map前合并。如果有优化空间,则执行优化。
- 第二步,分析SQL的结构,是否有重复的子查询可以存到中间表,是否可以使用相关性优化器,是否出现笛卡尔积需要去除,是否可以使用Multiple Insert语句,是否使用了低性能的UDF或SerDe需要替换。如果有优化空间,则执行优化。
- 第三步,分析SQL的操作,是否可利用MapJoin,是否可使用SMB Join,是否需要设置map端聚合,是否需要优化count(distinct),是否全局排序可以使用局部排序代替,是否可以使用向量化优化、基于代价的优化等优化器。如果有优化空间,则执行优化。
- 第四步,观察SQL启动的MR运行情况,如果map运行缓慢,考虑减小Map处理的最大数据量提高并发度,考虑增大map的内存和虚拟核数;如果是reduce运行缓慢,是否有group by倾斜需要解决,是否有join倾斜需要处理,当大量重复数据做去重时减少Reduce数 量,当大量匹配记录做关联时增加Reduce数量。
1.2.3 调优原则
- 保证map扫描的数据量尽量少 减少map端扫描数量,需要控制待处理的表文件或中间文件的数据量尽量少。优化的方式如:Hive表文件使用高效的文件格式、Hive表文件使用合适的文件压缩格式、中间文件使用合适的文件压缩格式、利用列裁剪、利用分区裁剪、使用分桶。
- 保证map传送给reduce的数据量尽量小 控制map传送给reduce的数据量,是指JOIN避免笛卡尔积、启动谓词下推、开启map端聚合功能。
- 保证map和reduce处理的数据量尽量均衡 保证map处理的数据量尽量均衡,是指使用Hive合并输入格式、必要时对小文件进行合并。保证reduce处理的数据量尽量均衡,是指解决数据倾斜问题。包括解决group by造成 的数据倾斜、解决join造成的数据倾斜。
- 合理调整map和reduce占用的计算资源 合理调整map和reduce占用的计算资源,是指通过参数设置合理调整map和reduce的内存及虚拟核数。根据集群总体资源情况,以及分配给当前租户的资源情况,在不影响其他业务正常运行的条件下,最大限度地利用可使用的计算资源。
- 合理调整map和reduce的数量 合理调整map数,是指通过设置每个map处理数据量的最大和最小值来合理控制map的数量。合理调整reduce数,是指通过直接设置reduce数量或通过设置每个reduce的处理数据量来合理控制reduce的数量。
- 重用计算结果 重用计算结果,是指将重复的子查询结果保存到中间表,供其他查询使用,减少重复计算,节省计算资源,比如使用物化视图特性。
- 使用稳定成熟的Hive优化特性 使用稳定成熟的Hive优化特性,包括:相关性优化器(Correlation Optimizer),基于代价的优化(Cost-based optimization),向量化查询引擎(Vectorized Query Execution),Join相关优化(Map Join、SMB Join),Multiple Insert特性,TABLESAMPLE抽样查询、Limit优化、局部排序(SORT BY、 DISTRIBUTE BY)。
- 使用高效HQL或改用MR 使用高效HQL,包括慎用低性能的UDF和SerDe、优化count(distinct a)。
Select c1,count(distinct c2)from t1 groupby c1;
==数据量大场景下推荐改造为:
Select c1,count(1)from(Select c1,c2 from t1 groupby c1,c2) t2;
对于使用HQL比较冗余同时性能低下的场景,在充分理解业务需求后,改用MR效率
更高。
1.2.4 调优手段
- 利用列裁剪 当待查询的表字段较多时,选取需要使用的字段进行查询,避免直接select *出大表的 所有字段,以免当使用Beeline查询时,控制台输出缓冲区被大数据量撑爆。
- JOIN避免笛卡尔积 JOIN场景应严格避免出现笛卡尔积的情况。参与笛卡尔积JOIN的两个表,交叉关联后 的数据条数是两个原表记录数之积,对于JOIN后还有聚合的场景而言,会导致reduce端处 理的数据量暴增,极大地影响运行效率。 以下左图为笛卡尔积,右图为正常Join。

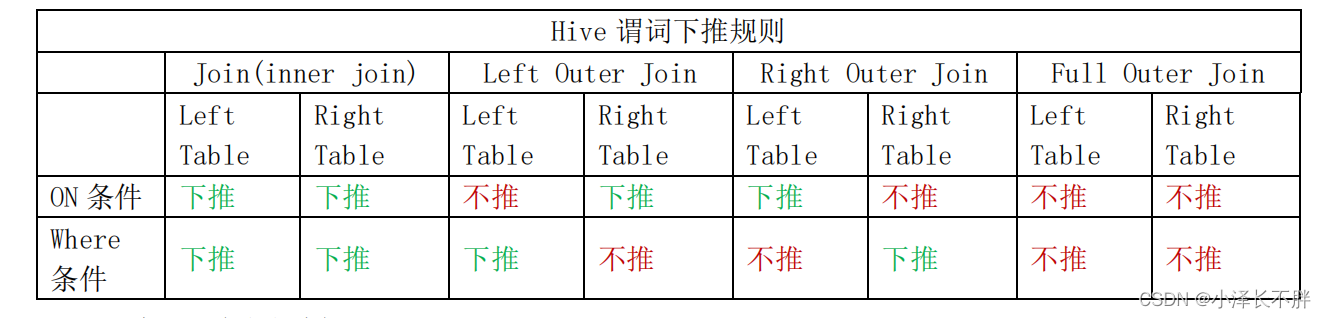
- 启动谓词下推 谓词下推(Predicate Pushdown)是一个逻辑优化:尽早的对底层数据进行过滤以减少后续需要处理的数据量。通过以下参数启动谓词下推。
sethive.optimize.ppd=true;
4. 开启Map端聚合功能
在map中会做部分聚集操作,能够使map传送给reduce的数据量大大减少,从而在一定程度上减轻group by带来的数据倾斜。通过以下参数开启map端聚合功能,可以提升IO密集型SQL性能
sethive.map.aggr=true;
- 使用Hive合并输入格式 设置Hive合并输入格式,使Hive在执行map前进行小文件合并,使得本轮map处理数据 量均衡。通过以下参数设置Hive合并输入格式。
sethive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
- 合并小文件 启动较多的map或reduce能够提高并发度,加快任务运行速度;但同时在HDFS上生成的文件数目也会越来越多,给HDFS的NameNode造成内存上压力,进而影响HDFS读写效率。对于集群的小文件(主要由Hive启动的MR生成)过多已造成NameNode压力时,建议在Hive启动的MR中启动小文件合并。
set hive.merge.mapfiles=true;小文件合并能够使本轮map输出及整个任务输出的文件完成合并,保证下轮MapReduce任务map处理数据量均衡。 - 解决group by造成的数据倾斜 通过开启group by倾斜优化开关,解决group by数据倾斜问题。开启优化开关后
group by会启动两个MR。 第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的; 第二个MR Job再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作。
sethive.groupby.skewindata=true;
- 解决Join造成的数据倾斜 两个表关联键的数据分布倾斜,会形成Skew Join。解决方案是将这类倾斜的特殊值(记录数超过hive.skewjoin.key参数值)不落入reduce计算,而是先写入HDFS,然后再启动 一轮MapJoin专门做这类特殊值的计算,期望能提高计算这部分值的处理速度。设置以下参 数。
sethive.optimize.skewjoin=true;sethive.skewjoin.key=100000;
- 合理调整map和reduce的内存及虚拟核数 map和reduce的内存及虚拟核数设置,决定了集群资源所能同时启动的container个数,影响集群并行计算的能力。 对于当前任务是CPU密集型任务(如复杂数学计算)的场景:在map和reduce的虚拟核数默认值基础上,逐渐增大虚拟核数进行调试(mapreduce.map.cpu.vcores和mapreduce.reduce.cpu.vcores参数控制),但不要超过可分配给container的虚拟核数 (yarn.nodemanager.resource.cpu-vcores参数控制)。 对于当前任务是内存密集型任务(如ORC文件读取/写入、全局排序)的场景:在map和reduce的内存默认值基础上,逐渐增大内存值进行调试(mapreduce.map.memory.mb和 mapreduce.reduce.memory.mb参数控制,注意:此处是一个map或者reduce container申请的 内存,与实际使用内存不一定相等,避免申请过大,浪费主机资源,影响集群整体任务并发),但不要超过当前NodeManager上可运行的所有容器的物理内存总大小(yarn.nodemanager.resource.memory-mb参数控制)。
- 合理控制map的数量 map的数量会影响MapReduce扫描、过滤数据的效率。对于扫描、过滤数据的逻辑比较复杂、输入数据量较大条数较多的场景:根据集群总体资源情况,以及分配给当前租户的资源情况,在不影响其他业务正常运行的条件下,map数量需要适当增大,增加并行处lo理的力度。
- 合理控制reduce的数量 reduce数量会影响MapReduce过滤、聚合、对数据排序的效率。对于关联、聚合、排序时reduce端待处理数据量较大的场景:首先根据每个reduce处理的合适数据量控制reduce的个数,如果每个reduce处理数据仍然很慢,再考虑设置参数增大reduce个数。另一方面,控制能启动的reduce最大个数为分配给当前租户的资源上限,以免影响其他业务的正常运行。
- 将重复的子查询结果保存到中间表 对于指标计算类型的业务场景,多个指标的HQL语句中可能存在相同的子查询,为避免重复计算浪费计算资源,考虑将重复的子查询的计算结果保存到中间表,实现计算一次、结果共享的优化目标。
- 相关性优化,旨在利用下面两种查询的相关性: (a)输入相关性:在原始operator树中,同一个输入表被多个MapReduce任务同时使 用的场景; (b)作业流程的相关性:两个有依赖关系的MapReduce的任务的shuffle方式相同。通过以下参数启用相关性优化:
sethive.optimize.correlation=true;
相关参考:https://cwiki.apache.org/confluence/display/Hive/Correlation+Optimizer
- 启用基于代价的优化 基于代价的优化器,可以基于代价(包括FS读写、CPU、IO等)对查询计划进行进一步的优化选择,提升Hive查询的响应速度。 通过以下参数启用基于代价的优化:
sethive.cbo.enabled=true;
相关参考:https://cwiki.apache.org/confluence/display/Hive/Cost-based+optimization+in+Hive
- 启用向量化查询引擎 传统方式中,对数据的处理是以行为单位,依次处理的。Hive也采用了这种方案。这种方案带来的问题是,针对每一行数据,都要进行数据解析,条件判断,方法调用等操作,从而导致了低效的CPU利用。向量化特性,通过每次处理1024行数据,列方式处理,从而减少了方法调用,降低了CPU消耗,提高了CPU利用率。结合JDK1.8对SIMD的支持,获得了极高的性能提升。 通过以下参数启用向量化查询引擎:
sethive.vectorized.execution.enabled=true;
相关参考:https://cwiki.apache.org/confluence/display/Hive/Vectorized+Query+Execution
- 启用Join相关优化 (a)使用MapJoin。MapJoin是针对以下场景进行的优化:两个待连接表中,有一个表非常大,而另一个表非常小,以至于小表可以直接存放到内存中。这样小表复制多份,在每个map task内存中存在一份(比如存放到hash table中),然后只扫描大表。对于大表中的每一条记录key/value,在hash table中查找是否有相同的key的记录,如果有,则连接后输出即可。 (b)使用SMB Join。
sethive.auto.convert.sortmerge.join=true;set hive.optimize.bucketmapjoin =true;set hive.optimize.bucketmapjoin.sortedmerge =true;
相关参考:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+JoinOptimization
- 使用Multiple Insert特性 以下左图为普通insert,右图为Multiple Insert,减少了MR个数,提升了效率

- 使用TABLESAMPLE取样查询 在Hive中提供了数据取样(SAMPLING)的功能,用来从Hive表中根据一定的规则进行数据取样,Hive中的数据取样支持数据块取样和分桶表取样。 以下左图为数据块取样,右图为分桶表取样:

- 启用Limit优化 启用limit优化后,使用limit不再是全表查出,而是抽样查询。涉及参数如下:
sethive.limit.optimize.enable=true;sethive.limit.row.max.size=100000;sethive.limit.optimize.limit.file=10;
- 利用局部排序 Hive中使用order by完成全局排序,正常情况下,order by所启动的MR仅有一个reducer,这使得大数据量的表在全局排序时非常低效和耗时。 当全局排序为非必须的场景时,可以使用sort by在每个reducer范围进行内部排序。同时可以使用distribute by控制每行记录分配到哪个reducer。
- 慎用低性能的UDF和SerDe 慎用低性能的UDF和SerDe,主要指谨慎使用正则表达式类型的UDF和SerDe。 如:regexp、regexp_extract、regexp_replace、rlike、RegexSerDe。 当待处理表的条数很多时,如上亿条,采用诸如([^ ])([^ ])([^ ])(.?)(".?“)(-|[0-9])(-|[0-9])(”.?“)(”.?")这种复杂类型的正则表达式组成过滤条件去匹配记录,会严重地影响map阶段的过滤速度。 建议在充分理解业务需求后,自行编写更高效准确的UDF实现相应的功能。
22.优化count(distinct)
优化方式如下,左图为原始HQL,右图为优化后HQL。
23.改用MR实现
在某些场景下,直接编写MR比使用HQL更加高效。
- 推测执行 当集群规模很大时(如几百上千台机器组成的集群),个别机器出现软硬件故障的概率就变大了,并且会因此延长整个任务的执行时间(跑完的任务都在等出问题的机器跑结束)。推测执行通过将一个task分给多台机器跑,取先跑玩的那个,会很好的解决这个问题。对于小集群,可以将这个功能关闭,缺点是资源占用率相对较高。对应参数为 mapreduce.map.speculative 是否开启map的推测执行,默认true mapreduce.reduce.speculative 是否开启reduce的推测执行,默认true mapreduce.job.speculative.speculativecap 推测执行的比例,默认10% mapreduce.job.speculative.slowtaskthreshold 判断task需要做推测执行的标准,默认1.0,即单个task的进度与所有task的平均进度相差一倍时,即认为是慢的task,需要推测执 行。 mapreduce.job.speculative.slownodethreshold 判断节点slow的标准,默认1.0,即某个节点的所有map和reduce的进度比其他节点的对应值慢一倍时,即认为是慢节点,从而不给它推测执行任务。
版权归原作者 泽泽野 所有, 如有侵权,请联系我们删除。