
一、explain查询计划概述
explain将Hive SQL 语句的**实现步骤、依赖关系**进行解析,帮助用户理解一条HQL 语句在底层是如何实现数据的查询及处理,通过分析执行计划来达到**Hive 调优,数据倾斜排查**等目的。
官网指路:
语法如下:
explain [formatted|extended|dependency|authorization|] query
- formatted:对执行计划进行格式化,返回JSON格式的执行计划
- extended:提供一些额外的信息,比如文件的路径信息
- dependency:以JSON格式返回查询所依赖的表和分区的列表
- authorization:列出需要被授权的条目,包括输入与输出
** 每个 explain查询计划由以三个部分组成**
- (1) the abstract syntax tree for the query——抽象语法树(AST):Hive使用Antlr解析生成器,可以自动地将HQL生成为抽象语法树
- (2) The dependencies between the different stages of the plan——stage依赖关系:会列出运行查询划分的stage阶段以及之间的依赖关系
- (3) The description of each of the stages——stage内容:包含了每个stage非常重要的信息,比如运行时的operator和sort orders等具体的信息
二、explain实战
explain执行计划一般分为【仅有Map阶段类型】、【Map+Reduce类型】
【Map+Reduce类型】:例如:select —aggr_func —from —where—groupby类型:带有聚合函数的SQL。
这类SQL可以分为如下几类:1.在reduce阶段聚合的sql执行计划、2.在map和reduce都有聚合的sql执行计划、3.高级分组聚合的执行计划。
hive中可以通过配置hive.map.aggr来设定是否开启Combine(map端开启预聚合),【set hive.map.aggr = true】
高级分组聚合指的是:聚合时涉及到rollup、cube等(使用高级分组聚合需要确保Map端reduce开启)。使用高级分组聚合函数的作用:将union多次的作业直接分到一个作业中执行,可以减少多作业对磁盘和网络IO额的消耗,这是一种优化。但是需要注意的是,此类聚合会造成数据极速膨胀,当基表的数据量很大的时候,容易导致map或者reduce任务因为硬件资源不足而崩溃。
ps:group by with rollup的使用见文章:
MySQL ——group by子句使用with rollup-CSDN博客文章浏览阅读456次,点赞7次,收藏9次。MySQL ——group by子句使用with rolluphttps://blog.csdn.net/SHWAITME/article/details/136078305?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170778504216800211571354%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=170778504216800211571354&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-1-136078305-null-null.nonecase&utm_term=rollup&spm=1018.2226.3001.4450
2.1 案例一:Map+Reduce类型
数据准备
create table follow
(
user_id int,
follower_id int
)row format delimited
fields terminated by '\t';
insert overwrite table follow
values (1,2),
(1,4),
(1,5);
create table music_likes
(
user_id int,
music_id int
)row format delimited
fields terminated by '\t';
insert overwrite table music_likes
values (1,20),
(1,30),
(1,40),
(2,10),
(2,20),
(2,30),
(4,10),
(4,20),
(4,30),
(4,60);
执行计划分析
执行如下sql语句:
explain formatted
select
count(t0.user_id) as cnt
, sum(t1.music_id) as sum_f
from follow t0
left join music_likes t1
on t0.user_id = t1.user_id
where t0.follower_id > 2
group by t0.follower_id
having cnt > 2
order by sum_f
limit 1;
生成物理执行计划:
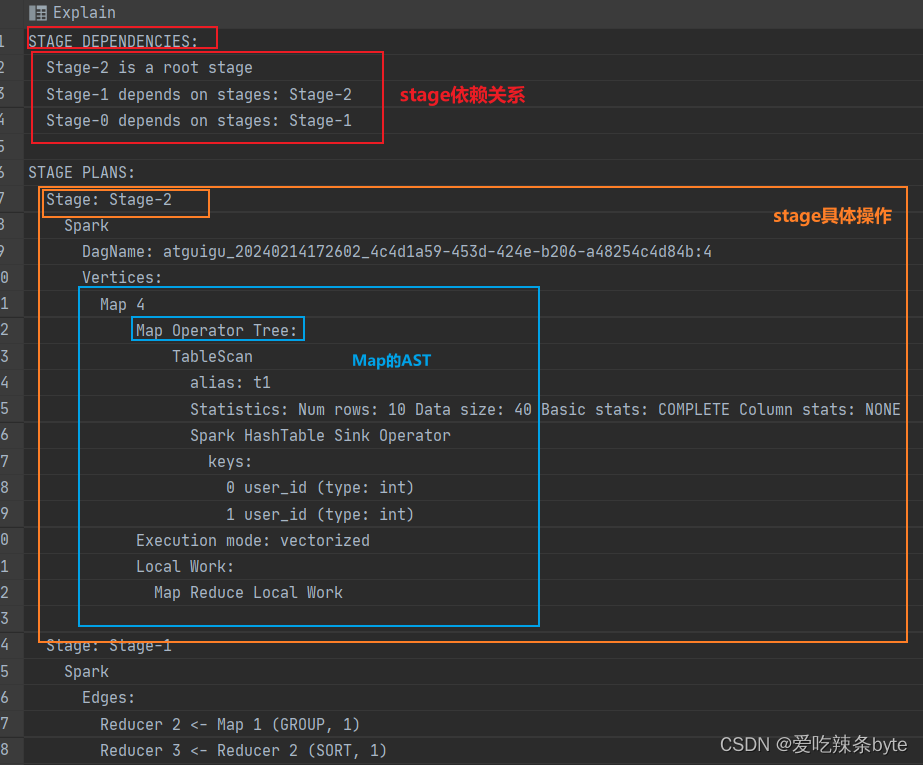
STAGE DEPENDENCIES: --//作业依赖关系
Stage-2 is a root stage
Stage-1 depends on stages: Stage-2
Stage-0 depends on stages: Stage-1
STAGE PLANS: --//作业详细信息
Stage: Stage-2 --//Stage-2 详细任务
Spark --//表示当前引擎使用的是 Spark
DagName: atguigu_20240212112407_cb09efe6-ac6e-4a57-a3a8-1b83b2fbf3a7:24
Vertices:
Map 4
Map Operator Tree: --//Stage-2 的Map阶段操作信息
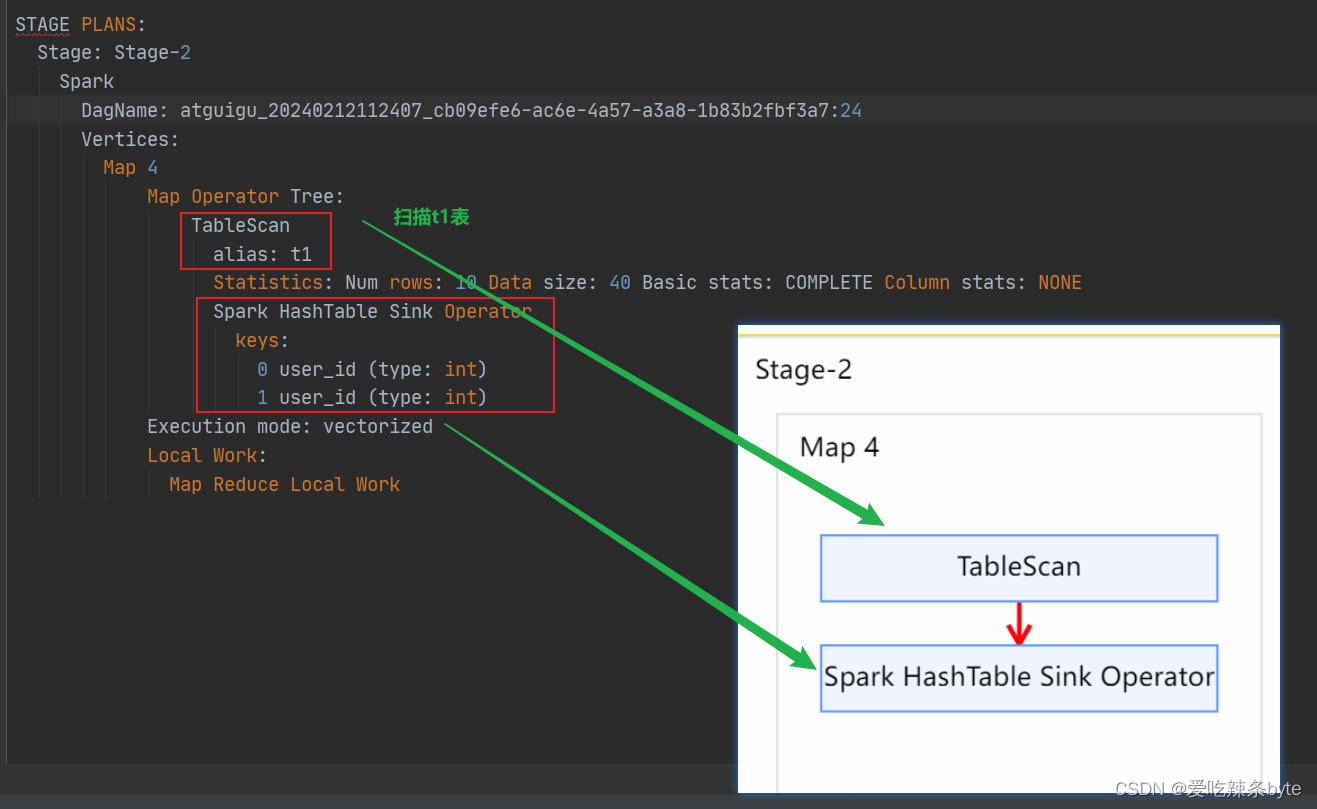
TableScan --// 扫描表t1
alias: t1
Statistics: Num rows: 10 Data size: 40 Basic stats: COMPLETE Column stats: NONE --// 对当前阶段的统计信息,如当前处理的行和数据量(都是预估值)
Spark HashTable Sink Operator
keys:
0 user_id (type: int)
1 user_id (type: int)
Execution mode: vectorized
Local Work:
Map Reduce Local Work
Stage: Stage-1
Spark
Edges:
" Reducer 2 <- Map 1 (GROUP, 2)"
" Reducer 3 <- Reducer 2 (SORT, 1)"
DagName: atguigu_20240212112407_cb09efe6-ac6e-4a57-a3a8-1b83b2fbf3a7:23
Vertices:
Map 1
Map Operator Tree: --//Stage-1的map阶段
TableScan
alias: t0
Statistics: Num rows: 3 Data size: 9 Basic stats: COMPLETE Column stats: NONE
Filter Operator --// 谓词下推(where条件)表示在Tablescan的结果集上进行过滤
predicate: (follower_id > 2) (type: boolean) --// 过滤条件
Statistics: Num rows: 1 Data size: 3 Basic stats: COMPLETE Column stats: NONE
Map Join Operator --//hive默认开启Map Join(set hive.map.aggr=true)
condition map:
Left Outer Join 0 to 1
keys:
0 user_id (type: int)
1 user_id (type: int)
" outputColumnNames: _col0, _col1, _col6"
input vertices:
1 Map 4
Statistics: Num rows: 11 Data size: 44 Basic stats: COMPLETE Column stats: NONE
Group By Operator --//这里是因为默认设置了hive.map.aggr=true,会在mapper先做一次预聚合,减少reduce需要处理的数据;
" aggregations: count(_col0), sum(_col6)" --//分组聚合使用的算法
keys: _col1 (type: int) --//分组的列
mode: hash --// 这里的mode模式是:hash,即对key值进行hash分区,数据分发到对应的task中;
" outputColumnNames: _col0, _col1, _col2" --//输出的列名
Statistics: Num rows: 11 Data size: 44 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator --// 将key,value从map端输出到reduce端(key还是有序的)
key expressions: _col0 (type: int)
sort order: + // 输出到reduce端的同时,对key值(_col)正序排序;+表示正序,-表示逆序
Map-reduce partition columns: _col0 (type: int) --//分区字段
Statistics: Num rows: 11 Data size: 44 Basic stats: COMPLETE Column stats: NONE
" value expressions: _col1 (type: bigint), _col2 (type: bigint)" -- //从map端输出的value
Execution mode: vectorized
Local Work:
Map Reduce Local Work
Reducer 2
Execution mode: vectorized
Reduce Operator Tree:
Group By Operator --// reduce端的归并聚合
" aggregations: count(VALUE._col0), sum(VALUE._col1)" --// 聚合函数的值
keys: KEY._col0 (type: int)
mode: mergepartial --// 此时group by的模式为mergepartial
" outputColumnNames: _col0, _col1, _col2"
Statistics: Num rows: 5 Data size: 20 Basic stats: COMPLETE Column stats: NONE
Select Operator --// 选择列,为下步的Filter Operator准备好数据
" expressions: _col1 (type: bigint), _col2 (type: bigint)"
" outputColumnNames: _col1, _col2"
Statistics: Num rows: 5 Data size: 20 Basic stats: COMPLETE Column stats: NONE
Filter Operator --//过滤
predicate: (_col1 > 2L) (type: boolean)
Statistics: Num rows: 1 Data size: 4 Basic stats: COMPLETE Column stats: NONE
Select Operator --// 选择列,为下步的Reduce Output Operator准备好数据
" expressions: _col1 (type: bigint), _col2 (type: bigint)"
" outputColumnNames: _col0, _col1"
Statistics: Num rows: 1 Data size: 4 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col1 (type: bigint)
sort order: +
Statistics: Num rows: 1 Data size: 4 Basic stats: COMPLETE Column stats: NONE
TopN Hash Memory Usage: 0.1
value expressions: _col0 (type: bigint)
Reducer 3
Execution mode: vectorized
Reduce Operator Tree:
Select Operator
" expressions: VALUE._col0 (type: bigint), KEY.reducesinkkey0 (type: bigint)"
" outputColumnNames: _col0, _col1"
Statistics: Num rows: 1 Data size: 4 Basic stats: COMPLETE Column stats: NONE
Limit
Number of rows: 1
Statistics: Num rows: 1 Data size: 4 Basic stats: COMPLETE Column stats: NONE
File Output Operator --// 输出到文件
compressed: false
Statistics: Num rows: 1 Data size: 4 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat --//输入文件类型
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat --//输出文件类型
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe --//序列化、反序列化方式
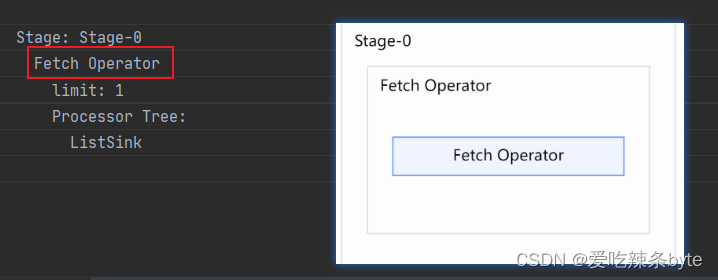
Stage: Stage-0
Fetch Operator --// 客户端获取数据操作
limit: 1 --// limit 操作
Processor Tree:
ListSink
** 采用可视化工具得到stage依赖图及各个stage的执行计划。stage图如下:**

工具:dist
链接:https://pan.baidu.com/s/1EruBmJPovA3A2cHRiFvQ9Q
提取码:3kt7使用方式:126-Hive-调优-执行计划-可视化工具_哔哩哔哩_bilibili
执行计划的理解:
- 根据层级,从最外层开始,包含两大部分:
stage dependencies: 各个stage之间的依赖性
stage plan: 各个stage的执行计划(物理执行计划)
- stage plan中的有一个Map Reduce,一个MR的执行计划分为两部分:
Map Operator Tree : map端的执行计划树
Reduce Operator Tree : Reduce 端的执行计划树
- 这两个执行计划树包含这条sql语句的算子operator:
(1)map端的首要操作是加载表,即TableScan表扫描操作,常见的属性有:
- alisa: 表名称
- statistics: 表统计信息,包含表中数据条数,数据大小等
(2)Select Operator:选取操作,常见的属性:
- expressions:字段名称及字段类型
- outputColumnNames:输出的列名称
- Statistics:表统计信息,包含表中数据条数,数据大小等
(3)Group By Operator:分组聚合操作,常见的属性:
- aggregations:显示聚合函数信息
- mode:聚合模式,包括 hash;mergepartial等
- keys:分组的字段,如果sql逻辑中没有分组,则没有此字段
- outputColumnNames:聚合之后输出的列名
- Statistics:表统计信息,包含分组聚合之后的数据条数,数据大小等
(4)Reduce Output Operator:输出到reduce操作,常见属性:
- sort order :如果值是空,代表不排序;值为“+”,代表正序排序;值为“-”,代表倒序排序;值为“+-”,代表有两列参与排序,第一列是正序,第二列是倒序
(5)Filter Operator:过滤操作,常见的属性:
- predicate: 过滤条件,如sql语句中的where id>=10,则此处显示(id >= 10)
(6)Map Join Operator:join操作,常见的属性:
- condition map: join方式,例如有:Inner Join 、 Left Outer Join
- keys:join的条件字段
(7)File Output Operator:文件输出操作,常见的属性:
- compressed:是否压缩
- table:表的信息,包含输入输出的文件格式化方式,序列化方式等
(8)Fetch Operator:客户端获取数据的操作,常见的属性:
- limit:值为-1表示不限制条数,其他值为限制的条数
接下来拆解explain执行计划
(1)先看第一部分,代表stage之间的依赖关系
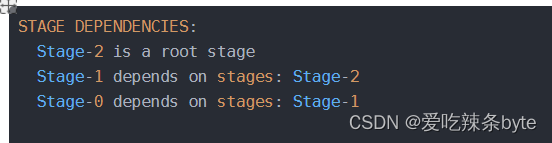
得出stage-2是根,stage-1依赖于stage-2,stage-0依赖于stage-1
(2)stage-2 阶段: 该阶段主要是对t1表进行扫描
(3)stage-1 阶段
Map阶段 1:

Map阶段:首先扫描t0表,其次谓词下推会执行where里面的过滤操作,然后执行mapjoin操作(),由于hive默认是开启预聚合操作的,所以会先在map端进行group by 分组预聚合(局部聚合),与此同时也会自动按照group by的key值进行升序排序。
Reduce 2 阶段:
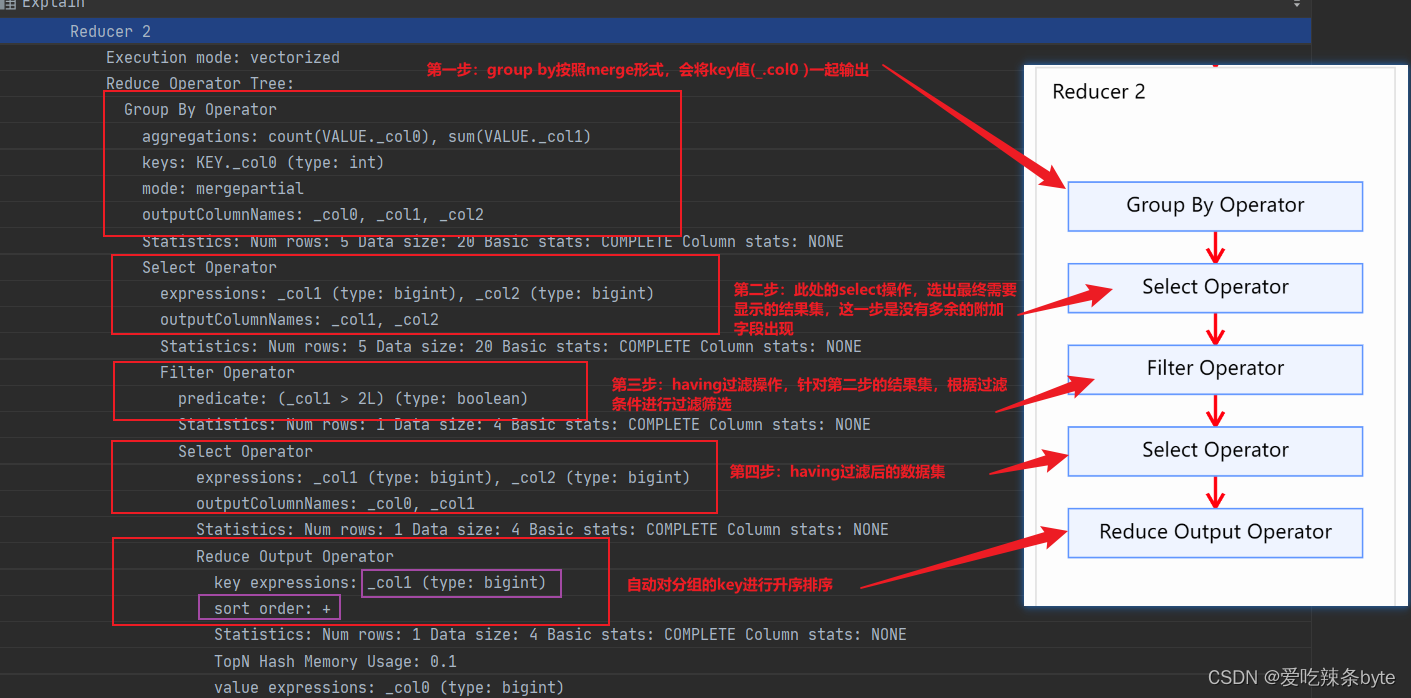
Reduce 2 阶段:该阶段****group by分组聚合为merge操作,将分组有序的数据进行归并操作。group by 后的select操作主要是为下一步的having操作准备数据,having操作会在select的结果集上做进一步的过滤。hive sql 中的select执行顺序不是固定的,但是每一次的selet操作是为下一步准备有效数据。
Reduce 3 阶段:该阶段select最终结果

(4)stage-0 阶段
该阶段主要是执行limit操作。
小结
通过上述的explain执行计划的拆解,得出hivesql的底层执行顺序大致如下:
from->
where(谓词下推)->
join->
on->
select(select中的字段与group by只要不一致就会有)->
group by->
select(为having准备数据,因而having中可以使用select别名)->
having->
select(过滤后的结果集)->
distinct->
order by ->
select->
limit
hive sql 中的select执行顺序不是固定的,但是每一次的selet操作是为下一步准备有效数据。
2.2 案例二:Map+Reduce类型(窗口函数)
数据准备
create database exec5;
create table if not exists table1
(
id int comment '用户id',
`date` string comment '用户登录时间'
);
insert overwrite table table1
values (1, '2019-01-01 19:28:00'),
(1, '2019-01-02 19:53:00'),
(1, '2019-01-03 22:00:00'),
(1, '2019-01-05 20:55:00'),
(1, '2019-01-06 21:58:00'),
(2, '2019-02-01 19:25:00'),
(2, '2019-02-02 21:00:00'),
(2, '2019-02-04 22:05:00'),
(2, '2019-02-05 20:59:00'),
(2, '2019-02-06 19:05:00'),
(3, '2019-03-04 21:05:00'),
(3, '2019-03-05 19:10:00'),
(3, '2019-03-06 19:55:00'),
(3, '2019-03-07 21:05:00');
执行计划分析
执行如下sql语句:
--查询连续登陆3天及以上的用户(字节面试题)
explain formatted
select
id
from (
select
id,
dt,
date_sub(dt, row_number() over (partition by id order by dt)) ds
from ( --用户在同一天可能登录多次,需要去重
select
id,
--to_date():日期函数
-- date_format(`date`,'yyyy-MM-dd')
date_format(`date`, 'yyyy-MM-dd') as dt
from table1
group by id, date_format(`date`, 'yyyy-MM-dd')
) tmp1
) tmp2
group by id, ds
having count(1) >=3;
生成物理执行计划:
STAGE DEPENDENCIES: --//作业依赖关系
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1 --// Stage-1详细任务
Spark --//表示当前引擎使用的是 Spark
Edges:
" Reducer 2 <- Map 1 (GROUP PARTITION-LEVEL SORT, 2)"
" Reducer 3 <- Reducer 2 (GROUP, 2)"
DagName: atguigu_20240212153029_036d3420-d92e-436f-b78d-25a7b67525d3:44
Vertices:
Map 1
Map Operator Tree: --// Stage-1阶段的map执行树
TableScan --// 扫描table1表
alias: table1
Statistics: Num rows: 14 Data size: 294 Basic stats: COMPLETE Column stats: NONE
Select Operator --// 选择列,为下一步 Group By Operator准备好数据
" expressions: id (type: int), date_format(date, 'yyyy-MM-dd') (type: string)"
" outputColumnNames: _col0, _col1" --// 输出的列名
Statistics: Num rows: 14 Data size: 294 Basic stats: COMPLETE Column stats: NONE
Group By Operator --// mapper端的group by,即先在 mapper端进行预聚合
" keys: _col0 (type: int), _col1 (type: string)"
mode: hash --// 对key值(_col0及_col1 )进行hash分区,数据分发到对应的task
" outputColumnNames: _col0, _col1" --// 输出的列名
Statistics: Num rows: 14 Data size: 294 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator --//从map端输出到reduce端
" key expressions: _col0 (type: int), _col1 (type: string)" --//从map端输出的key值
sort order: ++ --//将key及value值从map端输出到reduce端,这里的“++”代表对两个key值( _col0, _col1)都进行升序排序
Map-reduce partition columns: _col0 (type: int) --//分区字段
Statistics: Num rows: 14 Data size: 294 Basic stats: COMPLETE Column stats: NONE
Execution mode: vectorized
Reducer 2
Reduce Operator Tree: --//reduce端的执行树
Group By Operator --// reduce端的group by,即归并聚合
" keys: KEY._col0 (type: int), KEY._col1 (type: string)"
mode: mergepartial
" outputColumnNames: _col0, _col1"
Statistics: Num rows: 7 Data size: 147 Basic stats: COMPLETE Column stats: NONE
PTF Operator --//reduce端的窗口函数分析操作
Function definitions:
Input definition
input alias: ptf_0
" output shape: _col0: int, _col1: string"
type: WINDOWING
Windowing table definition
input alias: ptf_1
name: windowingtablefunction
order by: _col1 ASC NULLS FIRST --//窗口函数排序列
partition by: _col0 --// 窗口函数分区列
raw input shape:
window functions:
window function definition
alias: row_number_window_0
name: row_number --//窗口函数的方法
window function: GenericUDAFRowNumberEvaluator
window frame: ROWS PRECEDING(MAX)~FOLLOWING(MAX) --//当前窗口函数上下边界
isPivotResult: true
Statistics: Num rows: 7 Data size: 147 Basic stats: COMPLETE Column stats: NONE
Select Operator --//选择列,为下一步Group By Operator准备好数据
" expressions: _col0 (type: int), date_sub(_col1, row_number_window_0) (type: date)" --//select选择两个列,_col0, date_sub(_col1,row_number over())
" outputColumnNames: _col0, _col1"
Statistics: Num rows: 7 Data size: 147 Basic stats: COMPLETE Column stats: NONE
Group By Operator --// group by 预聚合
aggregations: count() --// 聚合函数 count()值
" keys: _col0 (type: int), _col1 (type: date)"
mode: hash
" outputColumnNames: _col0, _col1, _col2"
Statistics: Num rows: 7 Data size: 147 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator --// 输出到下一个reducer
" key expressions: _col0 (type: int), _col1 (type: date)"
sort order: ++ --// 输出到下一个reducer前,同时对两个key进行排序
" Map-reduce partition columns: _col0 (type: int), _col1 (type: date)"
Statistics: Num rows: 7 Data size: 147 Basic stats: COMPLETE Column stats: NONE
value expressions: _col2 (type: bigint)
Reducer 3
Execution mode: vectorized
Reduce Operator Tree:
Group By Operator --// group by 归并聚合
aggregations: count(VALUE._col0)
" keys: KEY._col0 (type: int), KEY._col1 (type: date)"
mode: mergepartial
" outputColumnNames: _col0, _col1, _col2"
Statistics: Num rows: 3 Data size: 63 Basic stats: COMPLETE Column stats: NONE
Select Operator --//选择列,为下一步Filter Operator 准备好数据
" expressions: _col0 (type: int), _col2 (type: bigint)"
" outputColumnNames: _col0, _col2"
Statistics: Num rows: 3 Data size: 63 Basic stats: COMPLETE Column stats: NONE
Filter Operator --//过滤条件
predicate: (_col2 >= 3L) (type: boolean)
Statistics: Num rows: 1 Data size: 21 Basic stats: COMPLETE Column stats: NONE
Select Operator --//选择列,为下一步File Output Operator 准备好数据
expressions: _col0 (type: int)
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 21 Basic stats: COMPLETE Column stats: NONE
File Output Operator --//对上面的结果集进行文件输出
compressed: false --//不压缩
Statistics: Num rows: 1 Data size: 21 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat --//输入文件类型
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat --//输出文件类型
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe --//序列化、反序列化方式
Stage: Stage-0
Fetch Operator --//客户端获取数据的操作
limit: -1 --//limit 值为-1:表示不限制条数
Processor Tree:
ListSink
** 采用可视化工具得到stage依赖图及各个stage的执行计划。stage图如下:**

接下来拆解explain执行计划
(1)先看第一部分,代表stage之间的依赖关系
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
得出stage-1是根,stage-0依赖于stage-1
(2)stage-1 阶段
Map阶段 1:
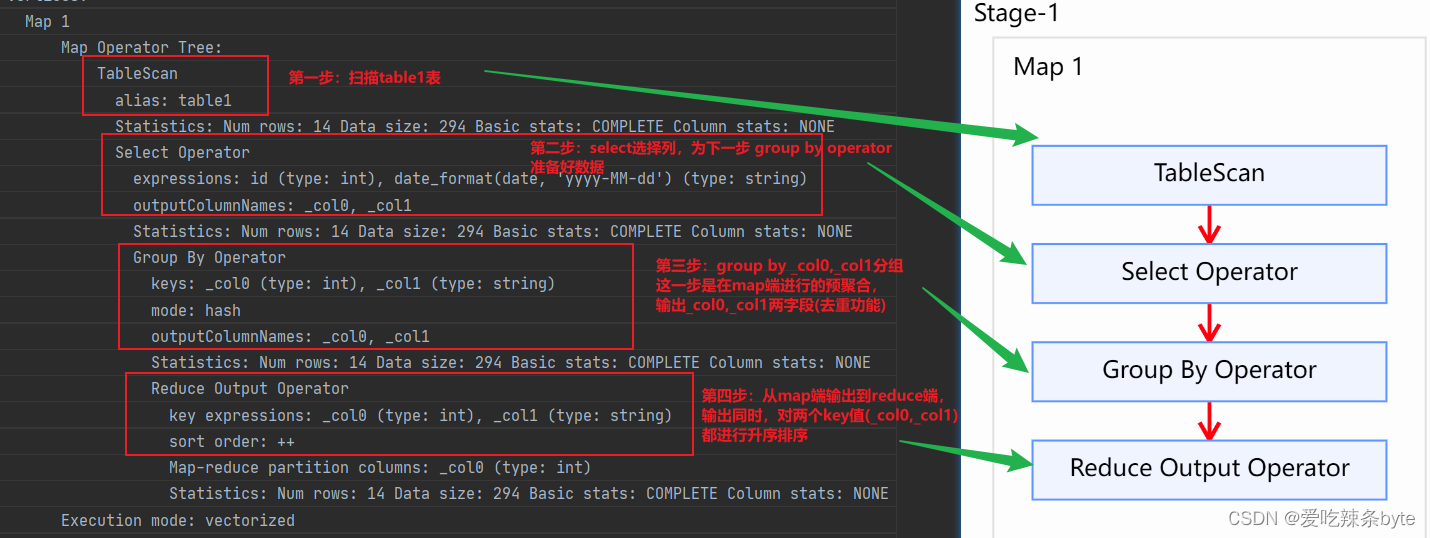
Map阶段:首先扫描table1表,其次select选择器会对下一步的group by 预选数据,为group by operator算子准备数据。然后在map端进行group by 分组预聚合(局部聚合),key及value值从mapper端输出到reducer端前,会自动按照的key值进行升序排序。
Reduce 2 阶段:


Reduce 2 阶段:该阶段group by分组聚合为merge操作,将分组有序的数据进行归并操作。其次进行开窗操作:
date_sub(dt, row_number() over (partition by id order by dt)) ds
开窗后的select选择器,逻辑如下:
select
id,
dt,
date_sub(dt, row_number() over (partition by id order by dt)) ds
select选择列,主要是为下一步的 group by id, ds 分组操作准备好数据集;
Reduce 3 阶段:
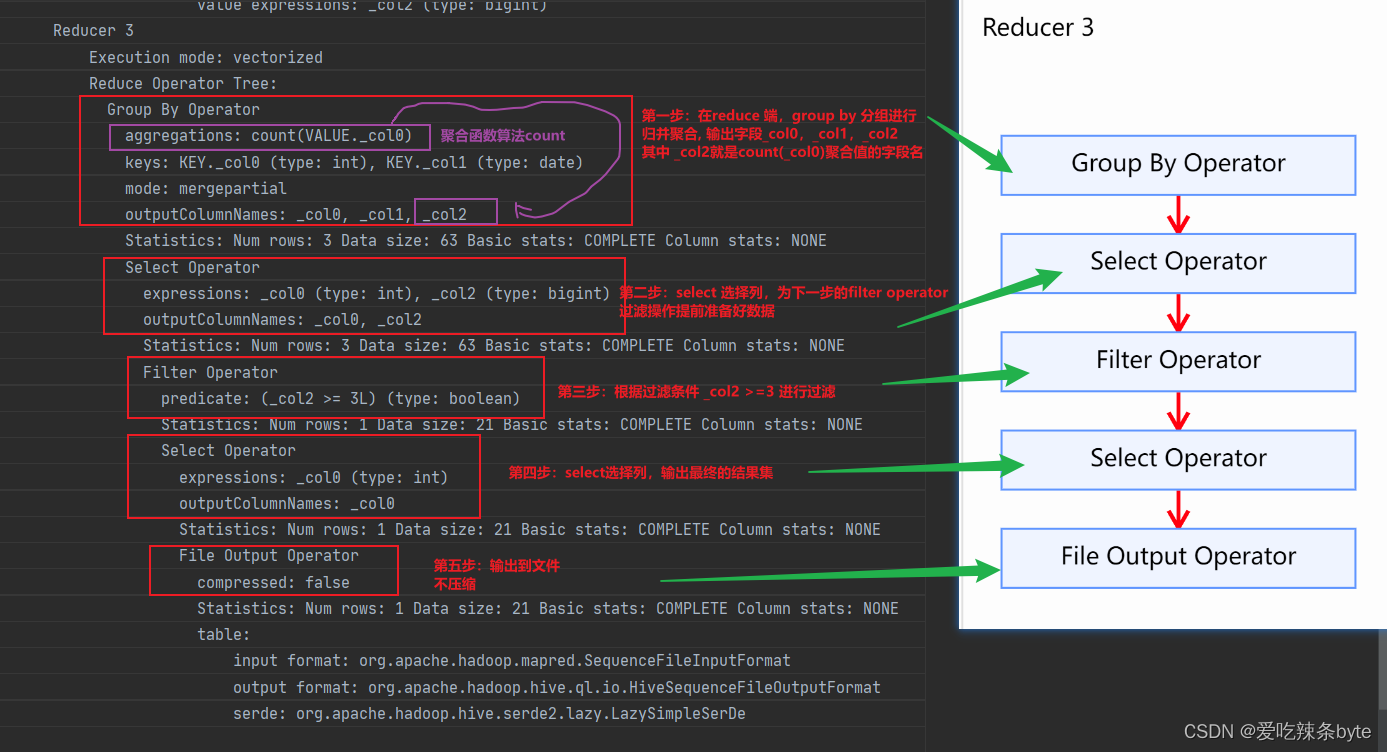
(3)stage-0 阶段
该阶段是客户端获取数据操作

小结
上述案例主要介绍了带有窗口函数的explain执行计划分析
2.3 案例三:Map+Reduce类型(窗口函数)
数据准备
CREATE TABLE t_order (
oid int ,
uid int ,
otime string,
oamount int
)
ROW format delimited FIELDS TERMINATED BY ",";
load data local inpath "/opt/module/hive_data/t_order.txt" into table t_order;
select * from t_order;
执行计划分析
执行如下sql语句:
explain formatted
with tmp as (
select
oid,
uid,
otime,
oamount,
date_format(otime, 'yyyy-MM') as dt
from t_order
)
select
uid,
--每个用户一月份的订单数
sum(if(dt = '2018-01', 1, 0)) as m1_count,
--每个用户二月份的订单数
sum(if(dt = '2018-02', 1, 0)) as m2_count,
-- 开窗函数
row_number() over (partition by uid order by sum(if(dt = '2018-01', 1, 0)))rk
from tmp
group by uid
having m1_count >0 and m2_count=0;
生成物理执行计划:
STAGE DEPENDENCIES:--//作业依赖关系
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS: --//作业详细信息
Stage: Stage-1 --//Stage-1 详细任务
Spark --//表示当前引擎使用的是 Spark
Edges:
" Reducer 2 <- Map 1 (GROUP, 2)"
" Reducer 3 <- Reducer 2 (PARTITION-LEVEL SORT, 2)"
DagName: atguigu_20240212174520_011afb56-73f8-49c1-9150-8399e66507c5:50
Vertices:
Map 1
Map Operator Tree: --//Stage-1 的Map阶段操作信息
TableScan --// 扫描表t_order
alias: t_order
Statistics: Num rows: 1 Data size: 4460 Basic stats: COMPLETE Column stats: NONE
Select Operator --// 选择列,为下一步 Group By Operator准备好数据
" expressions: uid (type: int), date_format(otime, 'yyyy-MM') (type: string)" --//选择的两个列 uid, date_format(otime, 'yyyy-MM')
" outputColumnNames: _col1, _col4" --// 输出的列名,_col1代表uid,_col4代表 date_format(otime, 'yyyy-MM')
Statistics: Num rows: 1 Data size: 4460 Basic stats: COMPLETE Column stats: NONE
Group By Operator ---// mapper端的group by,即先在 mapper端进行预聚合
" aggregations: sum(if((_col4 = '2018-01'), 1, 0)), sum(if((_col4 = '2018-02'), 1, 0))" --//聚合函数算法
keys: _col1 (type: int)
mode: hash --// 对key值(_col1,即uid )进行hash分区,数据分发到对应的task
" outputColumnNames: _col0, _col1, _col2" --//输出的列(uid,m1_count,m2_count)
Statistics: Num rows: 1 Data size: 4460 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator --//从mapper端输出到reducer端
key expressions: _col0 (type: int)
sort order: + --//将key,value从mapper端输出到reducer端前,自动对key值(_col0)升序排序
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 1 Data size: 4460 Basic stats: COMPLETE Column stats: NONE
" value expressions: _col1 (type: bigint), _col2 (type: bigint)" --//输出value值(m1_count,m2_count)
Execution mode: vectorized
Reducer 2
Execution mode: vectorized
Reduce Operator Tree:
Group By Operator --// reduce端的group by,即归并聚合
" aggregations: sum(VALUE._col0), sum(VALUE._col1)"
keys: KEY._col0 (type: int)
mode: mergepartial
" outputColumnNames: _col0, _col1, _col2"
Statistics: Num rows: 1 Data size: 4460 Basic stats: COMPLETE Column stats: NONE
Filter Operator --//having 过滤操作
predicate: ((_col1 > 0L) and (_col2 = 0L)) (type: boolean) --//过滤条件
Statistics: Num rows: 1 Data size: 4460 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
" key expressions: _col0 (type: int), _col1 (type: bigint)"
sort order: ++
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 1 Data size: 4460 Basic stats: COMPLETE Column stats: NONE
Reducer 3
Execution mode: vectorized
Reduce Operator Tree:
Select Operator --// 选择列,为下步的PTF Operator开窗分析操作准备好数据
" expressions: KEY.reducesinkkey0 (type: int), KEY.reducesinkkey1 (type: bigint), 0L (type: bigint)" --// 选择的列为_col0, _col1, _col2,即:uid,m1_count,m2_count
" outputColumnNames: _col0, _col1, _col2" //-- 选择的列:uid,m1_count,m2_count
Statistics: Num rows: 1 Data size: 4460 Basic stats: COMPLETE Column stats: NONE
PTF Operator --//reduce端的窗口函数分析操作
Function definitions:
Input definition
input alias: ptf_0
" output shape: _col0: int, _col1: bigint, _col2: bigint"
type: WINDOWING
Windowing table definition
input alias: ptf_1
name: windowingtablefunction
order by: _col1 ASC NULLS FIRST -//窗口函数排序列
partition by: _col0 --// 窗口函数分区列
raw input shape:
window functions:
window function definition
alias: row_number_window_0
name: row_number --//窗口函数的方法
window function: GenericUDAFRowNumberEvaluator
window frame: ROWS PRECEDING(MAX)~FOLLOWING(MAX) --//当前窗口函数上下边界
isPivotResult: true
Statistics: Num rows: 1 Data size: 4460 Basic stats: COMPLETE Column stats: NONE
Select Operator --//选择列,为下一步File Output Operator准备好数据
" expressions: _col0 (type: int), _col1 (type: bigint), _col2 (type: bigint), row_number_window_0 (type: int)" --// 选择的列为_col0, _col1,_col2, _col3,即:uid,m1_count,m2_count,rk
" outputColumnNames: _col0, _col1, _col2, _col3"
Statistics: Num rows: 1 Data size: 4460 Basic stats: COMPLETE Column stats: NONE
File Output Operator --//对上面的结果集进行文件输出
compressed: false --//不压缩
Statistics: Num rows: 1 Data size: 4460 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator --//客户端获取数据的操作
limit: -1 --//limit 值为-1:表示返回结果不限制条数
Processor Tree:
ListSink
** 采用可视化工具得到stage依赖图及各个stage的执行计划。stage图如下:**

接下来拆解explain执行计划
(1)先看第一部分,代表stage之间的依赖关系
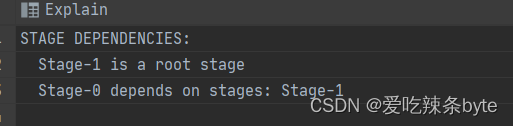
得出stage-1是根,stage-0依赖于stage-1
(2)stage-1 阶段
Map阶段 1:
Map阶段:首先扫描 t_order表,其次select选择器会对下一步的group by 预选数据,为group by operator算子准备数据。然后在map端进行group by 分组预聚合(局部聚合),key及value值从mapper端输出到reducer端前,会自动按照的key值进行升序排序。
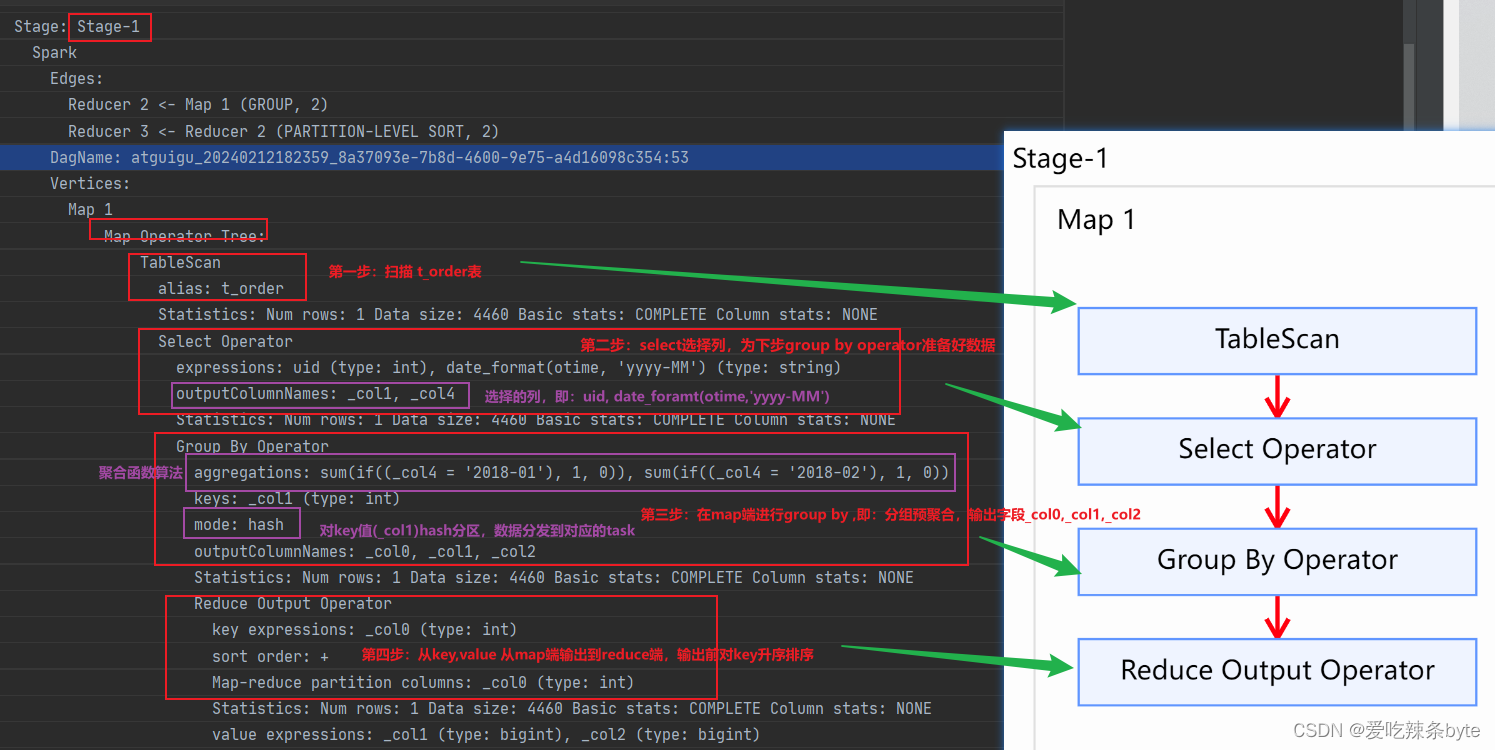
Reduce 2 阶段:
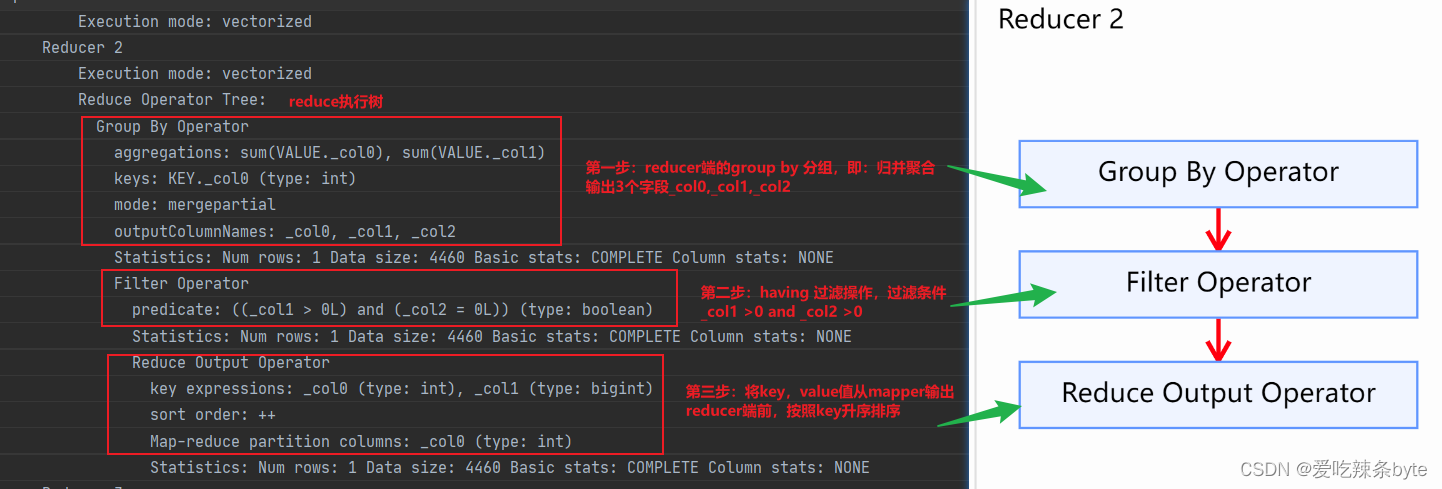
Reduce 2 阶段:该阶段group by分组聚合为merge操作,将分组有序的数据进行归并操作。然后对分组结果进行过滤having ....,逻辑如下:
select
uid,
sum(if(dt = '2018-01', 1, 0)) as m1_count,
sum(if(dt = '2018-02', 1, 0)) as m2_count
from tmp
group by uid
having m1_count >0 and m2_count=0;
Reduce 3 阶段:


Reduce 3 阶段:可以得到窗口函数的执行是在group by,having之后进行,是与select同级别的。如果SQL中既使用了group by又使用了partition by,那么此时partition by的分组是基于group by分组之后的结果集进行的再次分组,即窗口函数分析的数据范围也是基于group by后的数据。
(3)stage-0 阶段
该阶段是客户端获取数据操作
小结
上述案例通过对explain执行计划分析,重点验证了**窗口函数与group by **之间的区别与联系,也验证了**窗口函数执行顺序。**
窗口函数的执行顺序: 窗口函数是作用于select后的结果集。select 的结果集作为窗口函数的输入,但是位于 distcint 之前。窗口函数的执行结果只是在原有的列中单独添加一列,形成新的列,它不会对已有的行或列做修改。简化版的执行顺序如下图:

** Hive窗口函数详细介绍见文章:**
Hive窗口函数详解-CSDN博客文章浏览阅读560次,点赞9次,收藏12次。Hive窗口函数详解https://blog.csdn.net/SHWAITME/article/details/136095532?spm=1001.2014.3001.5501
2.4 案例三:只有Map阶段的类型
select —from—where型
简单的sql执行计划,不包含条件过滤、UDF函数、group by聚合、join连接等操作。由于不需要经过聚合,所以只有Map阶段操作,如果文件大小控制合适的话,可以完全发挥任务本地化执行的优点,即不需要跨节点执行,非常高效。
-- 数据准备
CREATE TABLE t_order (
oid int ,
uid int ,
otime string,
oamount int
)
ROW format delimited FIELDS TERMINATED BY ",";
load data local inpath "/opt/module/hive_data/t_order.txt" into table t_order;
-- 执行sql
explain
select
oid,
uid,
otime,
date_format(otime, 'yyyy-MM') as dt
from t_order where uid > 2
explain执行如下:可以得出该SQL是在本地执行的,没有有转换成MR任务
STAGE DEPENDENCIES:
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-0
Fetch Operator --// 客户端获取数据的操作
limit: -1
Processor Tree:
TableScan --// 扫描表 t_order
alias: t_order
Filter Operator --// 过滤操作
predicate: (uid > 2) (type: boolean) --// 过滤条件
Select Operator --// select选择列,得到最终的结果集
" expressions: oid (type: int), uid (type: int), otime (type: string), date_format(otime, 'yyyy-MM') (type: string)"
" outputColumnNames: _col0, _col1, _col2, _col3"
ListSink
select—fun(col)—from—where—func(col)
只带有普通函数(除UDTF、UDAF、窗口函数),只有Map阶段操作。
参考文章:
https://www.cnblogs.com/nangk/p/17649685.html
Hive Group By的实现原理_hive group by 多个字段-CSDN博客
你真的了解HiveSql吗?真实的HiveSql执行顺序是长这样的_hive 含有tablesample的sql执行顺序-CSDN博客
版权归原作者 爱吃辣条byte 所有, 如有侵权,请联系我们删除。