
写流程详细说明
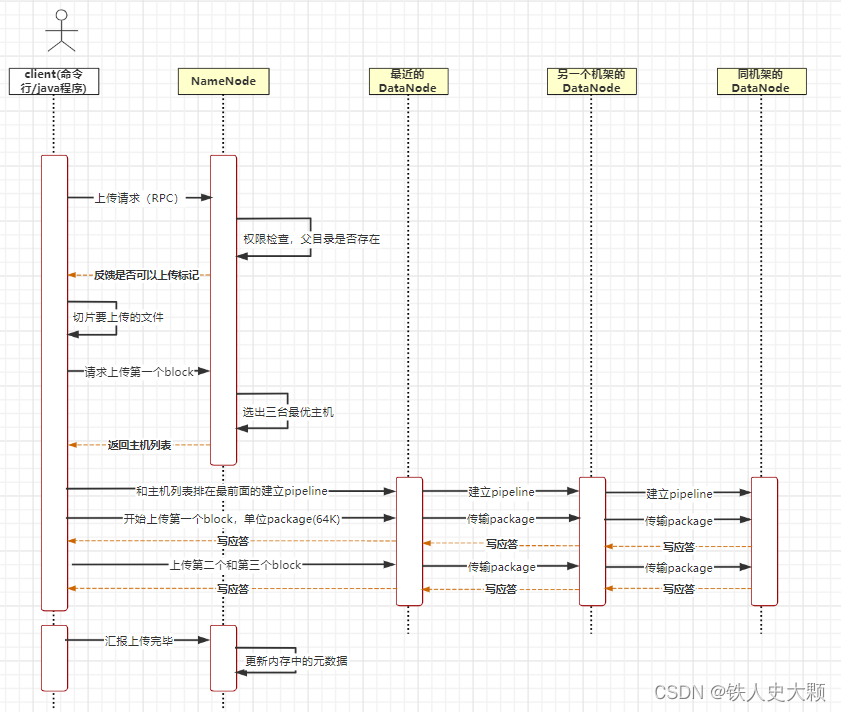
以hadoop fs -put a.txt /这条命令为例,假设副本数为3。
1.客户端执行了命令后,会向NameNode发起上传请求,走的是RPC协议。
2.NameNode收到请求,会校验是否有权限操作,而且会检查目录是否存在。
3.NameNode给客户端反馈是否可以上传的标记。
4.如果可以上传,则客户端会将文件切片,假如是将a.txt切成了三片。
5.客户端发起上传第一个block的请求。
6.NameNode会根据副本放置策略以及主机优秀程度选出三台主机,并将主机列表返回给客户端。
7.客户端和主机列表中排在最前面的主机建立pipeline,最前面的主机又会和第二台主机建立pipeline,第二台和第三台也建立pipeline,形成一个从客户端到三台主机的线性管道。
8.考虑到网络传输性能,客户端上传block时会再次切片,将block切成多个64KB大小的package,一个个的上传。
9.第一台主机收到package,会缓存,然后传给第二台,第二台缓存传给第三台,第三台缓存后返回写应答表示收到了,第二台收到应答,给第一台写应答,第一台收到给客户端写应答。
10.客户端收到写应答,会传下一个package。
11.重复这个过程,直到所有的package传完,三台主机会将缓存中的package合成block,落盘。
12.之后上传第二个和第三个block。
13.都传完后,客户端会向NameNode汇报上传完成。
14.NameNode更新元数据。
面试问答
1.请简述Hdfs写流程
客户端发起写请求,NameNode会进行权限和目录检查,之后选出最优主机,将列表返给客户端。客户端收到后和主机建立pipeline,之后切片文件,依次上传block,完成后通知NameNode完成,NameNode更新元数据。
2.上传是按block为单位上传吗?
不是。考虑到网络性能,是将block切成64KB大小的package进行上传,主机收到后进行缓存,都传输完后,组成block落盘。
3.为何使用pipeline,而不是客户端和三台主机同时建立网络连接?
因为数据以管道的方式,顺序的沿着一个方向传输,这样能够充分利用每个机器的带宽,避免网络瓶颈和高延迟时的连接,最小化推送所有数据的延时。在线性推送模式下,每台机器所有的出口宽带都用于以最快的速度传输数据,而不是在多个接受者之间分配宽带。
版权归原作者 铁人史大颗 所有, 如有侵权,请联系我们删除。