
文章目录
一.hive的行式存储与列式存储
HIve的文件存储格式常见的有四种:textfile 、sequencefile、orc、parquet ,前面两种是行式存储,后面两种是列式存储。
hive的存储格式指表的数据是如何在HDFS上组织排列的。
如下图,箭头的方向代表了数据是如何进行(写入)组织排列的。
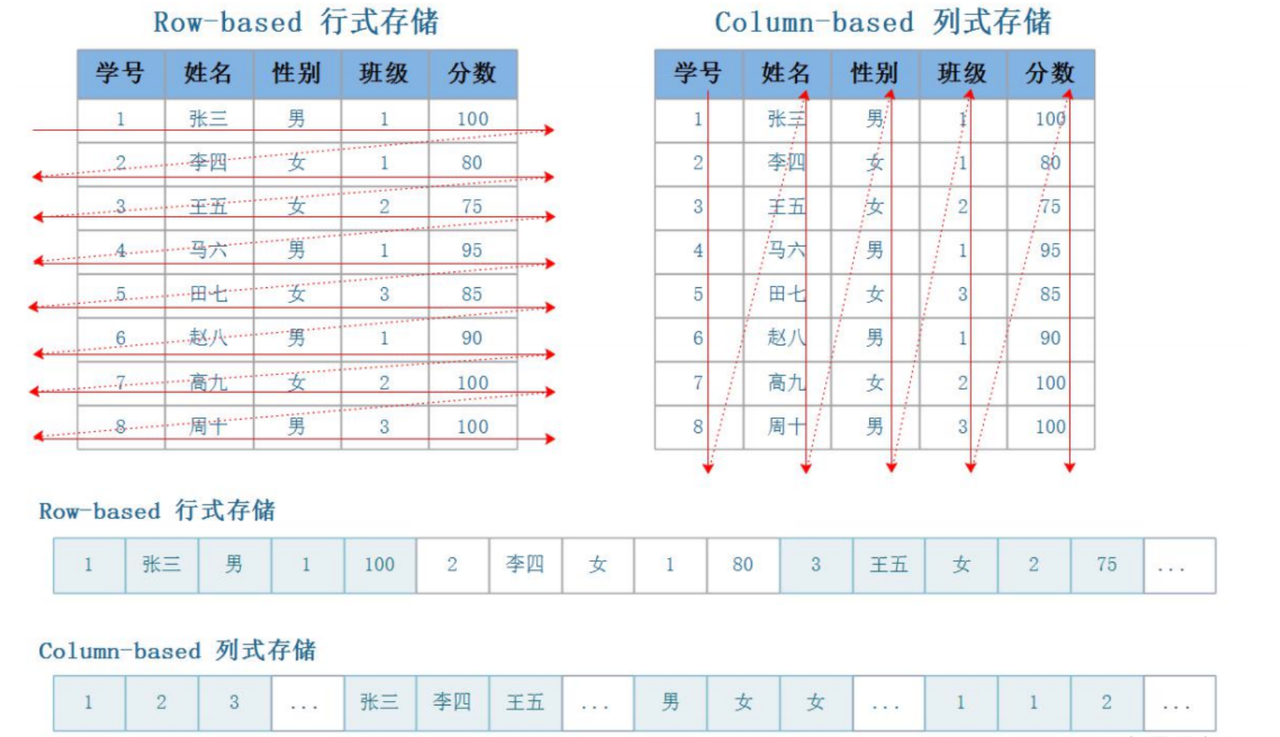
我们讨论一下行、列存储在读写上的特点:
行存储在数据写入和修改上的优势
写入:
行存储的写入是一次完成的,如果这种写入建立在操作系统的文件系统上,可以保证写入过程的成功或者失败,可以保证数据的完整性。
列式存储写入需要把一行记录拆分成单列保存, 写入次数明显比行存储多(因为磁头调度次数多,而磁头调度是需要时间的,一般在 1ms~10ms),再加上磁头需要在盘片上移动和定位花费的时间,实际消耗更大。
修改:
数据修改实际上也是一次写入过程,不同的是,数据修改是对磁盘上的记录做删除标记。 行存储是在指定位置写入一次,列存储是将磁盘定位到多个列上分别写入,这个过程仍是行存储的列数倍。
因为行式存储写入和修改都是一次完成,相比列式存储需要将一行记录进行拆分,行式存储的优势还是比较明显的。
列式存储在数据读取和解析、分析数据上具有优势
数据读取方面:
- 行存储通常将一行数据完全读出,如果只需要其中几列数据的情况,就会存在冗余列,出于缩短处理时间的考量,消除冗余列的过程通常是在内存中进行的。
- 列存储 每次读取的数据是集合的一段或者全部,不存在冗余性问题。
数据解析方面:
- 列式存储中的每一列数据类型是相同的,不存在二义性问题,例如,某列类型为整型 int,那么它的数据集合一定是整型数据,这种情况使数据解析变得十分容易。
- 相比之下,行存储则要复杂得多,因为在一行记录中保存了多种类型的数据,数据解析需要在多种数据类型之间频繁转换,这个操作很消耗 CPU,增加了解析的时间。
所以列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域比较重要。
一般来说,一个 OLAP 类型的查询可能需要访问几百万或者几十亿行的数据,但是OLAP 分析时只是获取少数的列,对于这种场景列式数据库只需要读取对应的列即可,因此这种场景更适合列式数据库,可以大大提高 OLAP 数据分析的效率。
二. 存储格式
1. TEXTFILE
hive默认存储格式,数据不做压缩,磁盘开销大,数据解析开销大。
虽然可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
2. ORC格式
Orc (Optimized Row Columnar)是hive 0.11版里引入的新的存储格式。
可以看到每个Orc文件由1个或多个stripe组成,每个stripe250MB大小,这个Stripe实际相当于RowGroup概念,不过大小由4MB->250MB,这样能提升顺序读的吞吐率。
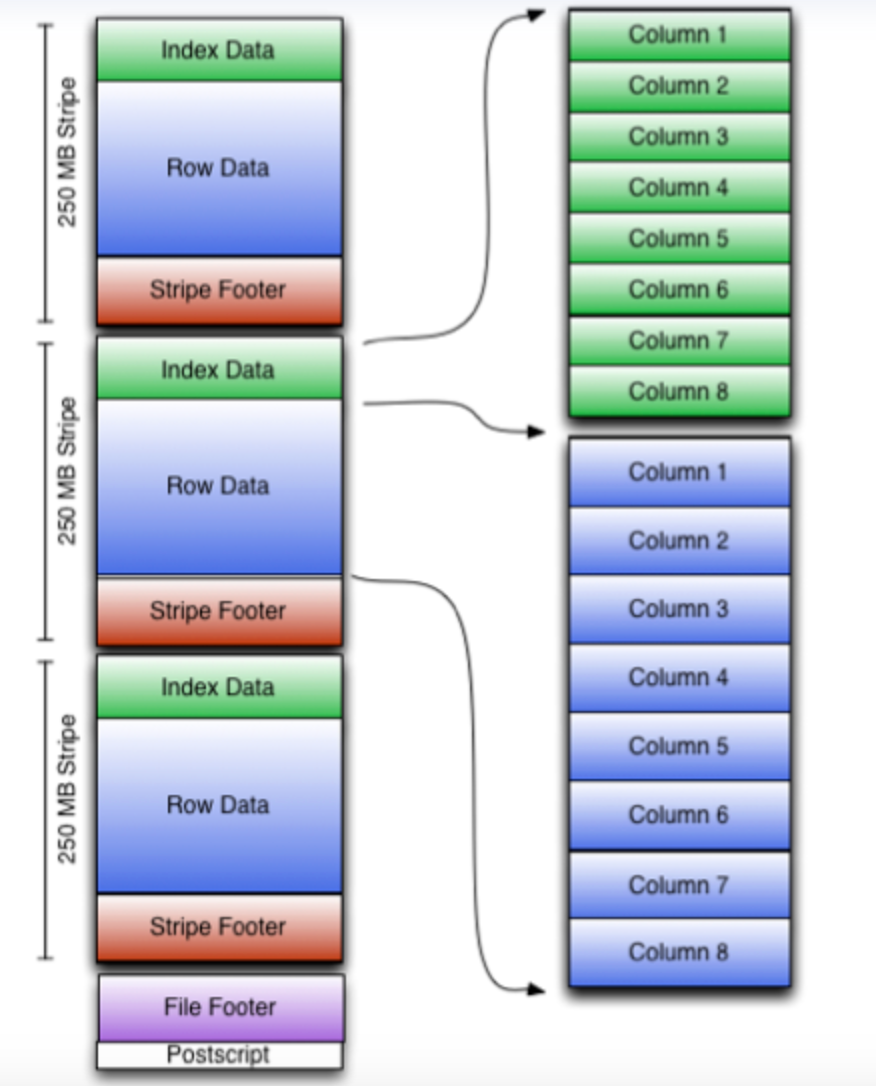
每个Stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer:
- Index Data:默认每隔1W行做一个索引。这里的索引只是记录某行的各字段在Row Data中的offset。
- Row Data:存储具体数据,先取部分行(1万行?),然后对这些行按列进行存储。每个列都进行了编码,分成多个Stream来存储。
- Stripe Footer:存储stripe的元数据信息: - File Footer,存储Stripe的行数,每个Column的数据类型信息等;- PostScript,记录了Stripe的压缩类型以及FileFooter的长度信息等。
数据读取逻辑:
读取文件时,
- 会先seek到文件尾部读PostScript,解析到File Footer长度
- 再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
3. PARQUET格式 ing
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
通常情况下,在存储Parquet数据的时候会按照HDFS的Block大小设置行组(多少行为一组?)大小。
由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。
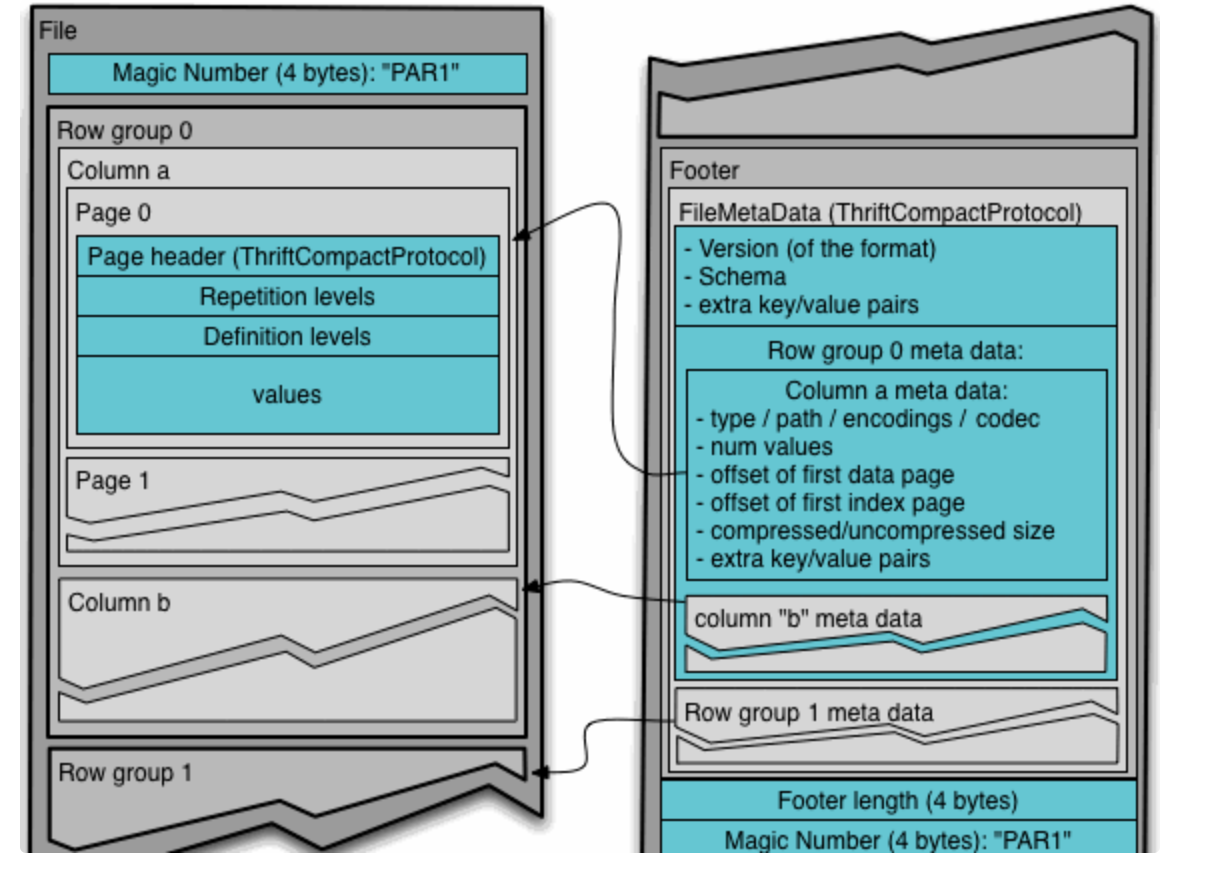
Parquet文件的格式如下图所示:
上图展示了一个Parquet文件的内容,一个文件中可以存储多个行组,
- 文件的首位是该文件的Magic Code,用于校验它是否是一个Parquet文件
- Footer length记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量
- 元数据:包括行组的元数据信息和该文件存储数据的Schema信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据。
- 在Parquet中,有三种类型的页:数据页、字典页和索引页。 - 数据页存储行组中该列的值;- 字典页存储该列值的编码字典,每一个列块中最多包含一个字典页- 索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页。
三. Hive压缩格式
在实际工作当中,hive当中处理的数据,一般都需要经过压缩,使用压缩来节省我们的MR处理的网络带宽。
1. mr支持的压缩格式:
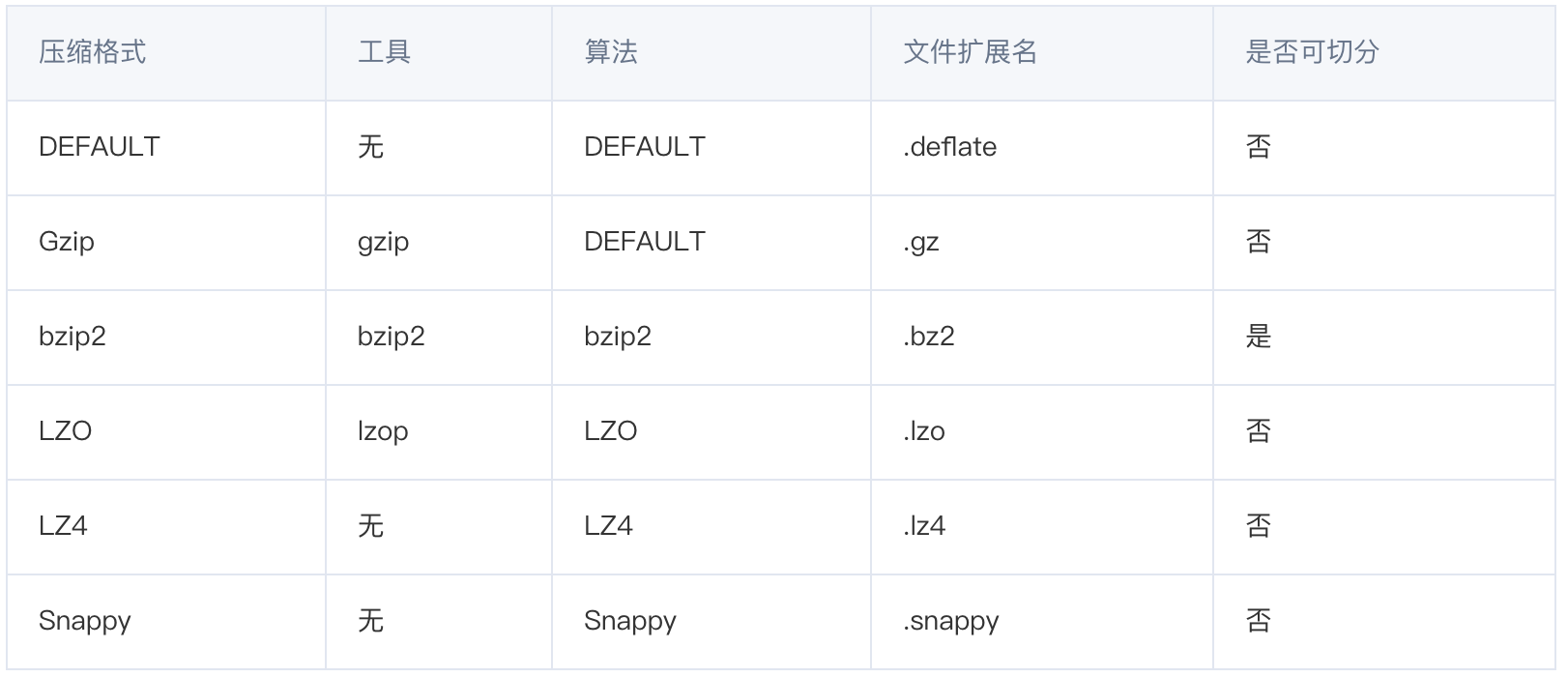
hadoop支持的解压缩的类: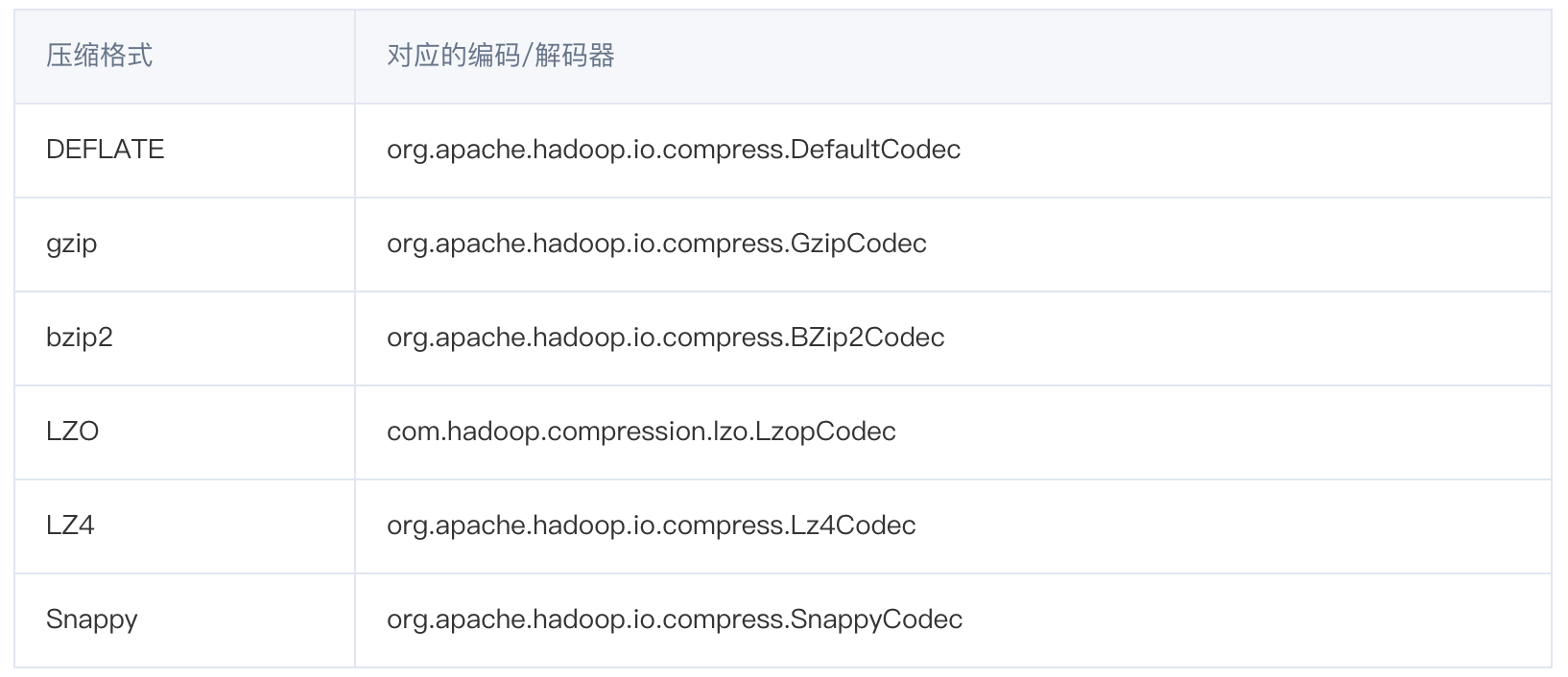
压缩性能的比较: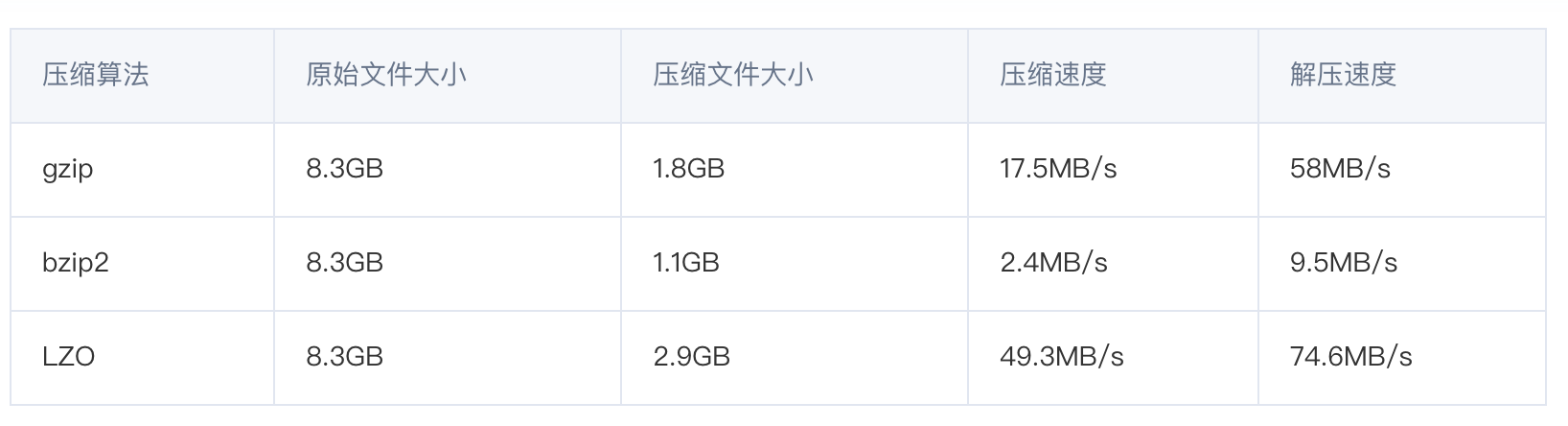
hadoop需要配置的压缩参数:
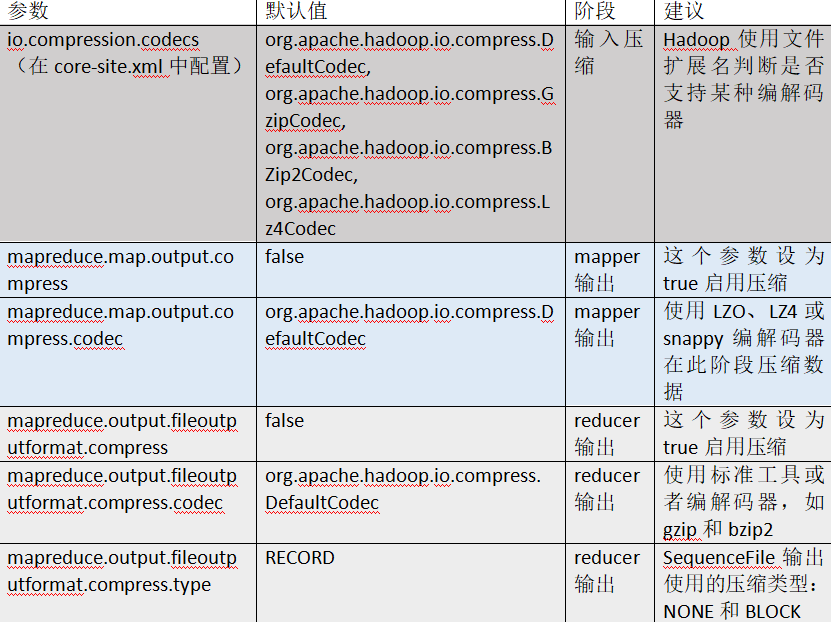
2. hive配置压缩的方式:
2.1. 开启map端的压缩方式:
1.1)开启hive中间传输数据压缩功能
hive (default)>set hive.exec.compress.intermediate=true;1.2)开启mapreduce中map输出压缩功能
hive (default)>set mapreduce.map.output.compress=true;1.3)设置mapreduce中map输出数据的压缩方式
hive (default)>set mapreduce.map.output.compress.codec
= org.apache.hadoop.io.compress.SnappyCodec;1.4)执行查询语句
selectcount(1)from score;
2.2.开启reduce端的压缩方式:
1)开启hive最终输出数据压缩功能
hive (default)>set hive.exec.compress.output=true;2)开启mapreduce最终输出数据压缩
hive (default)>set mapreduce.output.fileoutputformat.compress=true;3)设置mapreduce最终数据输出压缩方式
hive (default)>set mapreduce.output.fileoutputformat.compress.codec
= org.apache.hadoop.io.compress.SnappyCodec;4)设置mapreduce最终数据输出压缩为块压缩
hive (default)>set mapreduce.output.fileoutputformat.compress.type=BLOCK;5)测试一下输出结果是否是压缩文件
insert overwrite local directory '/export/servers/snappy'select*from score distribute by s_id sort by s_id desc;
四. hive中存储格式和压缩相结合
以ORC举例,相关配置参数: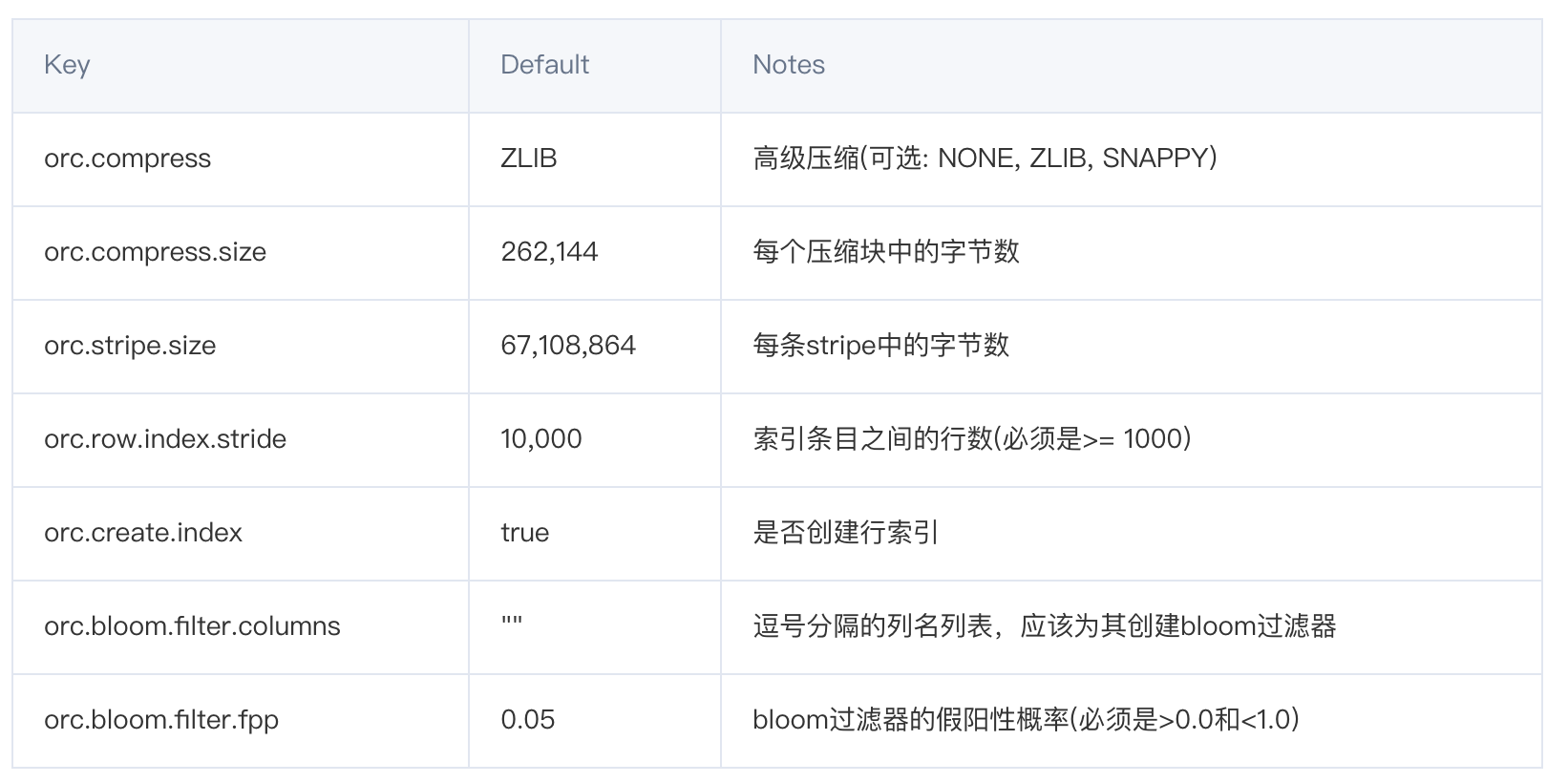
创建一个非压缩的ORC存储方式:
1)建表语句
createtable log_orc_none(
track_time string,
url string,
session_id string
)ROW FORMAT DELIMITED FIELDSTERMINATEDBY'\t'
STORED AS orc tblproperties ("orc.compress"="NONE");2)插入数据
insertintotable log_orc_none select*from log_text ;3)查看插入后数据
dfs -du -h /user/hive/warehouse/myhive.db/log_orc_none;
结果显示:
7.7 M /user/hive/warehouse/log_orc_none/123456_0
创建一个SNAPPY压缩的ORC存储方式:
1)建表语句
createtable log_orc_snappy(
track_time string,
url string,
session_id string
)ROW FORMAT DELIMITED FIELDSTERMINATEDBY'\t'
STORED AS orc tblproperties ("orc.compress"="SNAPPY");2)插入数据
insertintotable log_orc_snappy select*from log_text ;3)查看插入后数据
dfs -du -h /user/hive/warehouse/myhive.db/log_orc_snappy ;
结果显示:
3.8 M /user/hive/warehouse/log_orc_snappy/123456_0
4)实际上:默认orc存储文件默认采用ZLIB压缩。比snappy压缩率还高。
存储方式和压缩总结:
在实际的项目开发当中,hive表的数据存储格式一般选择:orc或parquet。 压缩方式一般选择snappy。
五. hive主流存储格式性能对比
从存储文件的压缩比和查询速度两个角度对比
1. 压缩比比较
(1)创建表,存储数据格式为TEXTFILE、ORC、Parquet
createtable log_text (
track_time string,
url string,
session_id string,)ROW FORMAT DELIMITED FIELDSTERMINATEDBY'\t'
STORED AS TEXTFILE ;
(2)向表中加载数据
loaddatalocal inpath '/export/servers/hivedatas/log.data'intotable log_text ;
(3)查看表中数据大小,大小为18.1M
dfs -du -h /user/hive/warehouse/myhive.db/log_text;...
textfile:结果显示:
18.1 M /user/hive/warehouse/log_text/log.data
ORC 结果显示:
2.8 M /user/hive/warehouse/log_orc/123456_0
Parquet结果显示:
13.1 M /user/hive/warehouse/log_parquet/123456_0
数据压缩比结论: ORC > Parquet > textFile
2. 存储文件的查询效率测试
1)textfile
hive (default)>selectcount(*)from log_text;
_c0
100000Time taken: 21.54 seconds, Fetched: 1row(s)2)orc
hive (default)>selectcount(*)from log_orc;
_c0
100000Time taken: 20.867 seconds, Fetched: 1row(s)3)parquet
hive (default)>selectcount(*)from log_parquet;
_c0
100000Time taken: 22.922 seconds, Fetched: 1row(s)
存储文件的查询效率比较: ORC > TextFile > Parquet
版权归原作者 roman_日积跬步-终至千里 所有, 如有侵权,请联系我们删除。